一种面向图神经网络的图重构防御方法
2021-06-04陈晋音黄国瀚张敦杰张旭鸿纪守领
陈晋音 黄国瀚 张敦杰 张旭鸿 纪守领
1(浙江工业大学网络空间安全研究院 杭州 310023) 2(浙江工业大学信息工程学院 杭州 310023) 3(浙江大学控制科学与工程学院 杭州 310007) 4(浙江大学计算机科学与技术学院 杭州 310007)
随着深度学习的兴起,图神经网络(graph neural network, GNN)成为了获取图节点特征和关系的有效工具之一.图神经网络可以通过训练获得节点或连边的低维表达,并应用在不同下游任务中,例如:节点分类[1]、链路预测[2]、图分类[3]、社区发现[4]等.尽管图神经网络在图表示学习领域取得了的成功,但是一些研究[5-7]表明:图神经网络容易受到对抗样本的攻击,即对抗样本中加入的扰动是经过精心设计并且是细微的,具有隐蔽性且能使得GNN失效.已有研究表明:现实应用已经受到攻击,例如在电子商务领域,网络水军集中撰写大量的虚假评论将使电商平台的点评系统和推荐系统产生错误判断,给真实的消费者错误的消费引导;在社交媒体网络中,虚假新闻如果不能被有效检测,则有可能导致谣言传播并引起恐慌.因此,如何提高图神经网络的鲁棒性至关重要.
目前,已经提出了许多对抗攻击算法用于图神经网络漏洞发现,主要策略包括:添加连边或删除连边[5-7]和添加虚假节点[8-9].这些攻击的目的在于通过操纵某些节点或连边,直接或间接影响目标节点的表达,或使图神经网络模型的全局性能下降.针对这些对抗攻击,研究者提供了不同的防御策略:1)对抗训练[10-11],将对抗样本和干净样本混合训练模型,提升模型对已知对抗攻击的防御能力;2)对抗扰动检测[12],通过发现对抗样本与干净样本的差异实现对抗扰动检测;3)基于注意力机制的模型加固[13-14],通过学习注意力机制实现对抗样本的惩罚,从而训练获得鲁棒的GNN模型;4)图纯化[15-17],通过对对抗扰动进行剔除并纯化图结构,从而保证模型的输出准确性.此外,在样本输入模型进行训练之前,对扰动图进行纯化降低攻击带来的影响,是一种可行且有效的方法[15-17].总结已有的防御方法,依然存在3个问题:1)已有不同的对抗攻击方法通过增删连边生成对抗网络,这些对抗样本的扰动是否存在一定的规律;2)已有很多防御方法会牺牲正常样本的分类效果达到防御的目的,如何确保GNN模型在正常样本性能的前提下,尽可能消除对抗性攻击的影响;3)如何从图的结构、特征等方面的变化上对防御方法的有效性进行分析.
针对3个问题,本文首先分析了不同对抗攻击方法的对抗样本,通过攻击实验观察得到对抗攻击添加的连边对应的节点对之间往往具有低结构相似度和低特征相似度的特点.基于实验观察,提出一种基于节点共同邻居数和特征相似度的图重构方法,通过删除低相似度的可疑连边以最小化对抗连边带来的影响;其次,通过连接节点特征相似度较高的节点以获得图数据增强,重构1个有利于图神经网络分类任务的新图.由于图卷积网络(graph convolutional network, GCN)[18]和基于注意力机制的图注意力网络(graph attention network, GAT)[19]在图表示学习领域中被广泛使用,因此,将其作为本文实验的目标模型.为了测试方法的有效性,本文采用了3种有效的攻击方法来生成对抗网络,即NETTACK[5],Metattack[20],DICE[21].实验验证了本文提出的基于图重构的图神经网络防御方法能够有效地降低攻击者的性能,并提高图神经网络在干净图数据节点分类任务上的性能.
总结本文主要工作包括3个方面:
1) 提出了一种图重构防御方法GRD-GNN,根据图的结构信息(即节点的共同邻居数)和节点自身特征相似度来筛选并降低对抗连边带来的影响.
2) 从多角度对方法的有效性进行分析,并通过图神经网络提取的信息的可视化,对GRD-GNN有效性进行了直观解释.
3) 在3个真实数据集上进行测试,并与最新的一些防御方法进行对比.大量的实验验证了本文提出的方法在保证干净样本分类任务的前提下比已有的防御方法取得更好的防御性能.
1 相关工作
本节简要介绍图神经网络对抗攻击和防御方面的相关工作.
1.1 面向图神经网络的攻击
已有研究表明:图神经网络容易受到对抗扰动的攻击,这些攻击根据模型的结构精心设计微小的扰动并添加到原始网络中,从而使得图神经网络失效.针对节点分类任务,Zügner等人[5]首次提出面向图数据的对抗攻击算法NETTACK,针对目标节点的置信度得分在目标函数的指导下迭代生成对抗连边和特征.为了进一步降低模型的全局性能而不是仅针对个别目标,他们提出了一种基于元梯度的对抗攻击方法Metattack[20],能大幅度降低图神经网络模型的全局分类性能;此外,Dai等人[6]提出的基于强化学习的对抗攻击方法RL-S2V和Chen等人[7]提出的快速梯度攻击方法FGA也被证明是有效的图对抗攻击方法;此外,不同于一般方法中添加或删除连边的方式,Greedy-GAN[8]利用生成对抗网络(generative adversarial networks, GAN)生成一些与真实节点相似的虚假节点并插入到网络中;类似地,Sun等人[9]也通过添加虚假节点和连边的方式毒化数据集来降低图神经网络的性能;在没有目标模型任何信息的情况下,黑盒攻击方法GF-Attack[22]通过攻击图过滤器生效;对于链路预测任务,IGA[23]通过图自编码器(graph auto-encoder, GAE)[24]的梯度信息对目标连边进行隐藏,从而使其进行错误预测;Zhou等人[25]通过删除图中的连边来攻击图的局部相似度和全局相似度;针对社区发现任务,Chen等人提出了基于遗传算法的Q-Attack方法[26]和进化扰动攻击EPA[27].综上所述,现有的图对抗攻击方法主要是通过添加或删除图中的关键连边,从而降低GNN模型在各项任务中的性能.
1.2 面向图神经网络的防御
一方面攻击的方法层出不穷;另一方面,研究者们开始注重模型漏洞的发现和加固,即如何采取有效的防御方法来增强图神经网络模型对对抗攻击的鲁棒性.针对防御方法的对象不同,防御方法可分为2类,即针对输入数据的转换的防御方法和针对模型结构的防御方法.针对数据转换的防御,Dai等人在文献[6]中提出了在训练过程中随机丢弃一些连边进行对抗训练来达到防御对抗攻击的效果,实验证明了这种方法对于模型鲁棒性提高的作用不明显;Wu等人[15]根据节点之间的Jaccard相似度利用贪心算法寻找相似度低的连边,并通过设置阈值的方式删除连边达到防御效果,但是Jaccard相似度适用于2进制特征而忽略了特征中潜在的数值大小;Entezari等人[16]通过研究NETTACK的扰动性质,发现NETTACK仅影响图的高秩(低奇异值)部分,据此提出了一种基于奇异值分解(singular value decomposition, SVD)的图纯化方法,该方法仅使用了top-k个奇异值对扰动图进行过滤,从而达到滤除对抗连边的效果,然而,由于仅考虑了前top-k个奇异值,因此存在丢失一些关键信息的风险;Jin等人[17]根据图的稀疏性、低秩性和节点的特征平滑设计了一种鲁棒的图神经网络Pro-GNN,在中毒图的基础上重新构建干净图,实验证明,Pro-GNN具有良好的抵抗中毒攻击的能力,然而由于Pro-GNN需要迭代地构建干净图并交替地进行优化,这使得Pro-GNN的复杂度变高,训练时间较长,且需要占据较多的计算资源;在针对模型结构的防御方法中,Zhu等人[14]利用高斯分布对噪声的容忍度,将其作为图卷积层中节点的隐层表示,并根据方差为邻居节点分配注意力权重,由于被攻击节点对其他节点的影响的方差大,并被分配了较小的注意力权重,因此可以降低不良影响的传播,该方法是对方差进行平滑而起到防御作用的,具有较强的通用性,但是该方法对不利影响的吸收能力也是有限的,对于一些较强的攻击,针对性不强,因此该方法的防御能力是有限的;此外,Chen等人[10]提出了使用平滑蒸馏和平滑损失函数的方法来实现梯度隐藏,并对模型进行对抗训练,从而增强了图神经网络模型对基于梯度的对抗攻击方法的鲁棒性,该方法对基于梯度的对抗攻击方法具有较好的防御性能,但也需要生成大量对抗样本进行训练,防御代价较高;Tang等人[13]设计了一种具有惩罚性聚合机制的图神经网络PA-GNN,通过限制扰动连边的消息传递从而使聚合函数更专注于真实的邻居节点,由于需要预先使用对抗样本和注意力机制训练一个具有惩罚能力的元模型来对PA-GNN进行初始化,因此该方法的复杂程度较高;Jin等人[28]强调了现有GCN模型的Laplacian算子在空间域中信息融合范围有限以及在谱域中的不良伪像,并进一步提出了一种可变幂算子替代Laplacian算子,得到可变幂网络,可同时不同距离的特征变换函数和全局参数,从而提高图神经网络的鲁棒性.
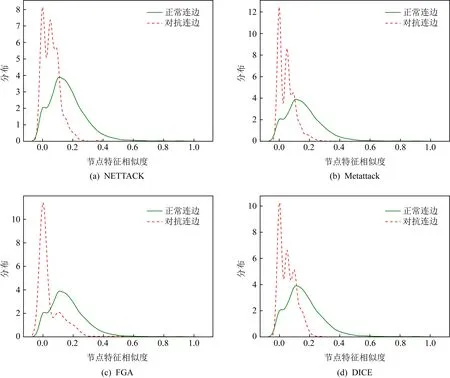
Fig. 1 The distribution of node features similarity图1 节点特征相似度分布
综上所述,现有的面向图神经网络的防御方法主要可以分为针对输入数据的转换的防御方法和针对模型结构的防御方法.尽管这些防御方法取得了一定的效果,但是仍存在局限性和挑战.针对输入数据的转换防御方法需要对输入图进行预处理,而预处理后的图的质量将直接影响GNN模型的性能.理论上这种防御方式对任何种类的对抗样本都有一定的防御效果,但是其缺点在于可能增加模型对干净样本的误报率,即使GNN模型损失一定的性能获取对对抗攻击的鲁棒性.如何提高GNN模型在干净样本上的性能是该类方法的主要挑战.针对模型结构的防御方法需要从模型内部结构进行改进,这提高了模型的复杂性,尤其是与对抗训练相结合的防御方式需要更多的计算资源与训练时间.
2 基于图重构的图神经网络防御方法
2.1 动 机
在提出本文的方法之前,首先观察4种攻击算法生成的不同对抗样本的结构相似度和节点特征相似度,以Cora数据集为例,结果如表1和图1所示.由表1可知,大部分对抗连边所连接的节点对之间几乎不存在共同邻居(common neighbors, CN),这说明了它们周围的结构相似性较低.此外从节点自身属性特征考虑,如图1所示,这些被对抗连边所连接的节点属性特征也具有低相似度的特点.在此基础上,本文提出了一种面向图神经网络的图重构防御方法GRD-GNN.
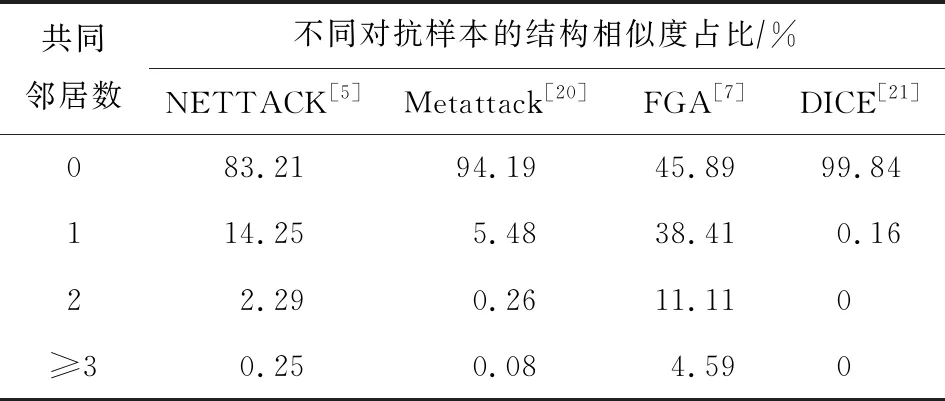
Table 1 The Proportion of Structural Similarity of Node Pairs Connected by Adversarial Edges
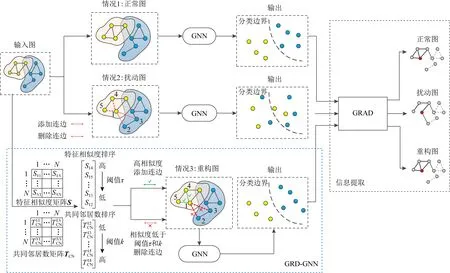
Fig. 2 The framework of GRD-GNN algorithm图2 GRD-GNN算法框架图
2.2 目标模型


(1)
(2)
其中,VL是带有标签的节点集合,|F|是图中节点的标签数,Y是真实标签矩阵.
此外,为了验证本文提出方法的通用性,本文还在GAT模型[19]上进行实验.与GCN模型不同的是,GAT模型在卷积层中引入了注意力机制,为不同的邻居节点分配不同权重.节点i的隐层表达为
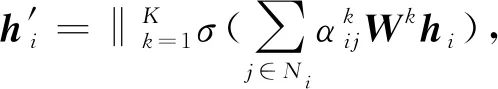
(3)
其中,Wk是与输入相关的线性变换的权重矩阵;K代表独立的注意力机制的数量;a∈R2M,M是节点特征的维数.此外,值得注意的是权重矩阵W是共享的.GAT模型的最终输出层被定义为
(4)
此处δ(·)在节点分类任务中为softmax函数或sigmoid函数.
2.3 GRD-GNN算法框架
本节对本文提出的基于图重构的GRD-GNN算法的具体细节进行详细介绍.GRD-GNN的框架图如图2所示,当GNN模型的输入为一张正常图时,输出正常,并应用于图关键结构提取等任务,获得正常的目标节点相关的关键子图;当GNN模型的输入为1张扰动图时,模型的分类性能下降,由解释器GRAD提取的目标节点相关子图与正常图不一致;GRD-GNN的输入无论是正常图还是扰动图都将依据节点特征相似度和共同邻居数进行图重构,具体步骤为根据输入特征相似度阈值τ和共同邻居数阈值k,删除低于相似度阈值的连边,并连接具有高相似度的节点,输出重构图,并作为GNN模型的输入,获得正常的输出,并由解释器GRAD提取目标节点相关的关键子图,此时输出与正常图比较,验证GRD-GNN的有效性.
更具体地,GRD-GNN算法主要分为2个步骤:
1) 滤除对抗扰动.通过构建结构相似度和节点特征相似度对图中的连边进行贪心搜索,查找可疑连边,删除相似度得分低于给定阈值的连边,达到清除图中对抗连边的效果.
2)
图增强.在步骤1)的基础上,利用节点自身特征的相似度进行排序,在保证节点在输入图中的度值情况下连接高节点相似度的连边,达到图增强的效果.
1) 滤除对抗扰动.共同邻居数[29]是复杂网络研究中的1种经典的结构相似度算法.2个节点的共同邻居数越少,则说明两者在网络中的关系越疏远.因此,CN常用于评估节点对之间的结构相似度.NCN被定义为

(5)
其中,Γ(i)表示节点i周围的邻居节点集合,Γ(j)表示节点j周围的邻居节点集合.则CN关于邻接矩阵A表达形式为
TCN=AA,
(6)
此外,为了从节点自身属性上衡量2个节点之间的相似性,本文采用了余弦相似度来计算2个特征向量之间的距离,得到特征相似度矩阵S.节点i和节点j之间的余弦相似度可以表示为
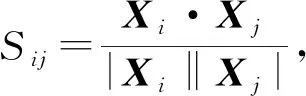
(7)
其中,X为节点的特征,|·|代表取模运算.
在上述相似度计算的基础上进行可疑连边筛选和滤除,将θdel定义为删除连边操作:
(8)

(9)
2)
图增强.在KNN(k-nearest neighbor)算法[30]的启发下,本文根据节点对的余弦相似度进行图增强.本文定义了选择矩阵Λ进行增强连边的选择:
Λij=Sij×(-2eij+1),
(10)
式(10)表明当连边eij存在时忽略该连边,仅考虑图中不存在的连边作为候选连边集.

(11)
e′为需要添加的连边,通过上述方式最终获得经过重构后的增强图G′及对应的邻接矩阵A′.
算法1.GRD-GNN算法.
输出:重构后的邻接矩阵A′.
① 根据式(6)计算结构相似度矩阵TCN;根据式(7)计算节点特征相似度矩阵S;
② foreijin连边集合do
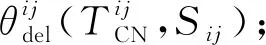
end for
④ 计算选择矩阵Λij=Sij×(-2eij+1);

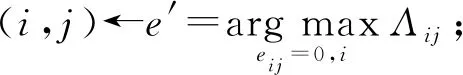
num+=1;
end for
⑥ return重构图G′及对应邻接矩阵A′.
2.4 GRD-GNN有效性分析
为了能更直观地解释GRD-GNN算法的有效性,本文从防御前后图结构的度分布情况、节点属性特征分布情况和模型提取的embedding信息等多个角度进行分析.其中,重构图的度分布应当尽量与干净图一致;图中节点的特征相比扰动图应当有更高的相似度;模型提取的重构图的embedding信息应当与干净图相似,从而说明GRD-GNN的有效性.
本文实验中还使用了基于梯度的可解释性方法GRAD[31]对图神经网络在攻击前后和防御前后提取到的图关键结构进行了可视化.进行防御后GRAD提取的关键子图应与从干净图中提取的关键子图相似或一致,从而说明GRD-GNN的有效性.其中GRAD是一种基于梯度和显著性映射的解释方法,图神经网络损失函数的梯度被用于解释图神经网络的行为.
3 实验与分析
为了验证本文提出的基于图重构的图神经网络防御方法的有效性,本文在3个真实数据集和2种图神经网络模型上进行实验,并与最新的防御方法进行比较,验证本文方法的有效性.
3.1 实验环境
实验环境是:Python3.6开发,运行环境的CPU为i7-7700K 3.5 GHz×8,GPU为TITAN XP 12 GB,内存为16 GB×4 memory (DDR4),开发及实验的操作系统为Ubuntu 16.04 (OS).
3.2 数据集及评价指标
本文在3个图神经网络研究中常用的真实数据集上评估GRD-GNN的防御性能,分别是Cora,Citeseer,Pubmed,与文献[17]相同,本文采用了3个数据集中的最大连通图作为实验对象.表2总结了3个数据集的基本统计信息:
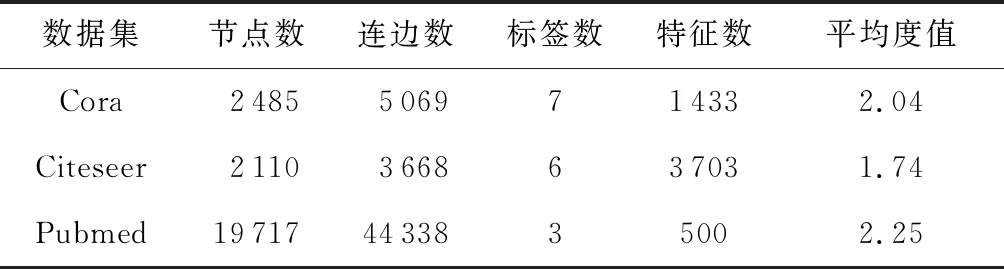
Table 2 The Basic Statistics of Graph Datasets表2 图数据集的基本统计信息
1) Cora数据集.Cora数据集是1个引文网络数据集,包含了大量机器学习相关的论文,共分为7类.其中共有2 485篇文章和5 096条引用记录.每个节点包含1 433条特征.
2) Citeseer数据集.Citeseer数据集也是1个引文网络数据集,它包含了2 110篇文章和3 668条引用关系,共分为6类,含有3 703个特征.
3) Pubmed数据集.Pubmed数据集是1个生物邻域相关的引文网络,包含了19 717篇文章、44 338条引用关系和500个特征,分为3类.
本文实验的评价指标采用模型的预测准确率(accuracy)和分类裕度(classification margin, CM),其中CM指标表示为

(12)

3.3 攻击方法
在本文实验中,使用了3种经典的、具有较强攻击性能的对抗攻击算法,即NETTACK算法[5]和Metattack算法[20]和DICE算法[21].下面对这3种算法进行简要介绍:
1) NETTACK[5].NETTACK算法首先根据重要的数据特征选择候选的连边和特征,其次设计了2个评估函数用于评估在修改候选连边和特征后的目标置信度变化,最后通过修改得分最高的连边或特征,并迭代地更新对抗网络.
2) Metattack[20].Metattack将输入的网络G作为一个超参数,构建成Bi-level的优化问题,并利用基于网络连边的元梯度进行对抗网络的迭代更新,是一种无目标攻击算法.
3) DICE[21].DICE对目标节点随机断开b条连边,再随机连接K-b条连边,其中K是目标节点原有的连边数.
3.4 对比防御方法
为了验证GRD-GNN的有效性,本文将其与GCN和其他4种防御方法进行比较,分别为RGCN[14],Jaccard_based[15],SVD_based[16],Pro-GNN[17].下面对4种防御方法进行简要介绍:
1) RGCN[14]. RGCN利用了高斯分布对扰动的容忍性,将图卷积层的隐层节点表示为高斯分布以吸收对抗攻击带来的影响.此外还利用方差为邻居节点分配注意力权重,具有高方差的节点将受到惩罚.
2) Jaccard_based[15]. Jaccard_based通过计算节点特征的Jaccard相似度,并设置一定的阈值对连边进行筛选、删除,最终得到1张经过净化的图.
3) SVD_based[16]. SVD_based旨在将受扰动的图进行SVD分解,通过截取top-k个高奇异值(低秩),重新组成1张新的没有扰动的图.
4) Pro-GNN[17].利用了图的低秩、稀疏性和节点特征的平滑特性,从受扰动的图和模型参数中学习到1张干净的图来防御对抗攻击.
此外,在本文的实验中还设置了1组对照CND(common neighbor delete),即仅在共同邻居数的指导下进行连边删除.
3.5 防御实验
在防御的过程中需要解决2个主要的问题,即:1)在干净样本上,需要保持图神经网络模型的性能.2)在第1个问题的基础上尽可能地消除对抗攻击带来的影响.
1) 在干净样本上的分类性能
首先,为了验证防御方法在干净样本(未添加扰动)上对图神经网络模型的性能影响,本文在GCN模型上对各防御方法进行测试,结果如表3所示:

Table 3 Accuracy of Different Defense Methods on Clean Data表3 不同防御方法在干净数据上的准确率
由表3可知,大部分的防御方法都能较好地保持GCN模型的分类性能,在规模较小的数据集Cora和Citeseer中,SVD_based和对照组CND的性能下降较为明显,其原因在于,两者均对图结构有较大程度的改变,因此对GCN模型的分类性能具有较大的影响.而在较大规模的Pubmed数据集中,两者对图的改动对整体图结构的影响相比Cora,Citeseer较小,因此,仍能一定程度保持GCN模型的分类性能.本文提出的GRD-GNN方法虽然没有得到最优的分类效果,但是在整体上均能保持与仅有GCN模型相近的性能.这也验证了GRD-GNN能较好地保持GCN模型的性能.
2) 针对目标攻击的防御效果
根据节点的数据特征(例如度分布、中心性等)可以对节点在图中的重要程度进行划分.攻击者常对一些具有高价值的目标进行攻击,目标攻击的目的在于使模型对目标节点的分类错误,以获得对攻击者而言的最大收益.因此,能否对目标节点进行有效保护使检验防御方法对目标攻击方法的防御能力的重要指标之一.本节实验即是验证各个防御算法对目标攻击的防御效果.

Table 4 Accuracy of Different Defense Method Against NETTACK Based on GCN表4 在NETTACK攻击下不同防御方法基于GCN模型的准确率
实验中,本文采用了具有较强攻击能力且具有良好隐蔽性的图对抗攻击算法NETTACK.由表2可知,3个数据集中的节点平均度值较低,分别为2.04,1.74,2.25,因此设置每个目标节点都将受到1~5条扰动连边的攻击(5条扰动连边的添加可视为较大程度的扰动),以测试防御算法对不同程度扰动的防御能力.实验采用模型节点分类准确率(accuracy)作为指标,结果如表4所示.
由表4可知,随着扰动的增加,在大部分情况下,GRD-GNN在各个数据集上均能取得最佳效果,由于对比算法.甚至在每个节点上的扰动增加到5条连边时,模型对目标节点的分类准确率仍能达到与在无扰动情况下相近的性能.这说明GRD-GNN能够有效地防御对抗攻击.
实验从模型的分类准确率角度验证了本文提出方法的有效性,这是一种宏观的性能体现.此外,能否使图神经网络对节点进行更加令人信服的分类也是体现防御方法性能的一个方面.本文实验中引入了CM[5]指标来对防御方法的防御能力进行微观上的评判.需要说明的是,CM指标代表了目标节点与正确分类边界的距离,因此,当节点被正确分类时,其对应的模型输出置信度应当越高越好.为了更明显地对比,实验中采用了添加5条连边的扰动进行攻击,结果如图3所示.
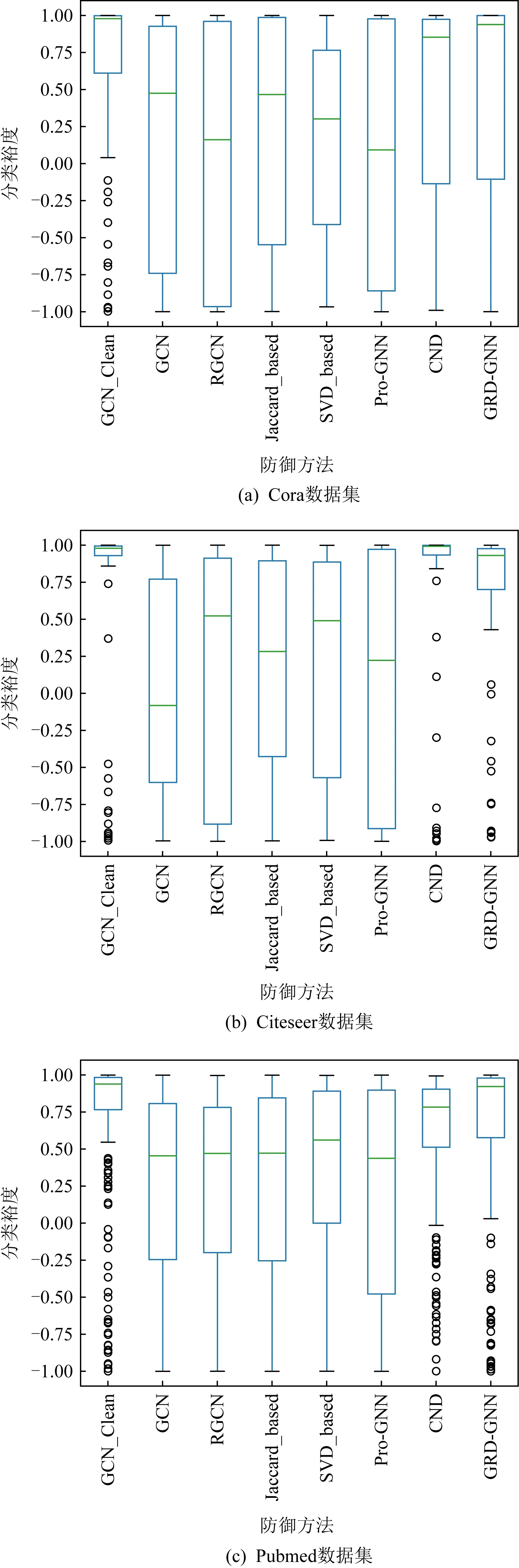
Fig. 3 The boxplot of Classification Margin on three datasets图3 3个数据集上的Classification Margin箱线图
图3表明相比其他对比算法,除去对照组CND,GRD-GNN的箱体更短一些,这说明其数据更集中,且与未经过扰动的GCN模型的输出更接近,节点被正确分类的置信度更高,防御的性能更好.而在Citeseer数据集上略低于对照组CND的原因可能在于,相比Cora,Pubmed数据集,Citeseer数据集更稀疏,CND对图结构的改动更大一些,其中也包括了在无扰动图中自身携带的一些噪声,且目标节点的度值较大,因此即使在损失了相当一部分模型的整体性能的情况下,CND仍能对目标节点进行较好的分类.
3) 针对无目标攻击的防御效果
在针对图神经网络的对抗攻击方法中,有一类攻击者注重于通过修改少数连边而使图神经网络模型的性能大幅下降,而不是仅针对某一些节点的攻击,例如Metattack就是其中一种强力的攻击算法.在针对无目标攻击的防御实验中,本文采用了Metattack和DICE对图神经网络进行攻击,并在Metattack攻击达到修改网络中25%连边和DICE达到修改网络中50%连边的高强度攻击情况下对各防御方法进行性能测试,实验的评价指标为模型的节点分类准确率.在图结构中,对关键节点的保护是至关重要的,这样的节点数量在网络中占的比重不大,对攻击者而言却又具有较高价值.因此,实验中通过对节点的度值进行节点重要性排序,实验中取度值在前50%的节点集合进行测试,模拟在高强度攻击的情况下防御方法对关键节点的保护能力.实验的结果如图4和图5所示.
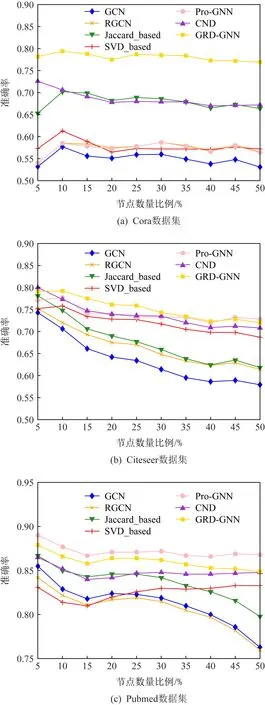
Fig. 4 Accuracy of nodes with different degrees under Metattack (25% edges are modified)图4 在Metattack(修改25%的连边数)攻击下不同度值节点的准确率
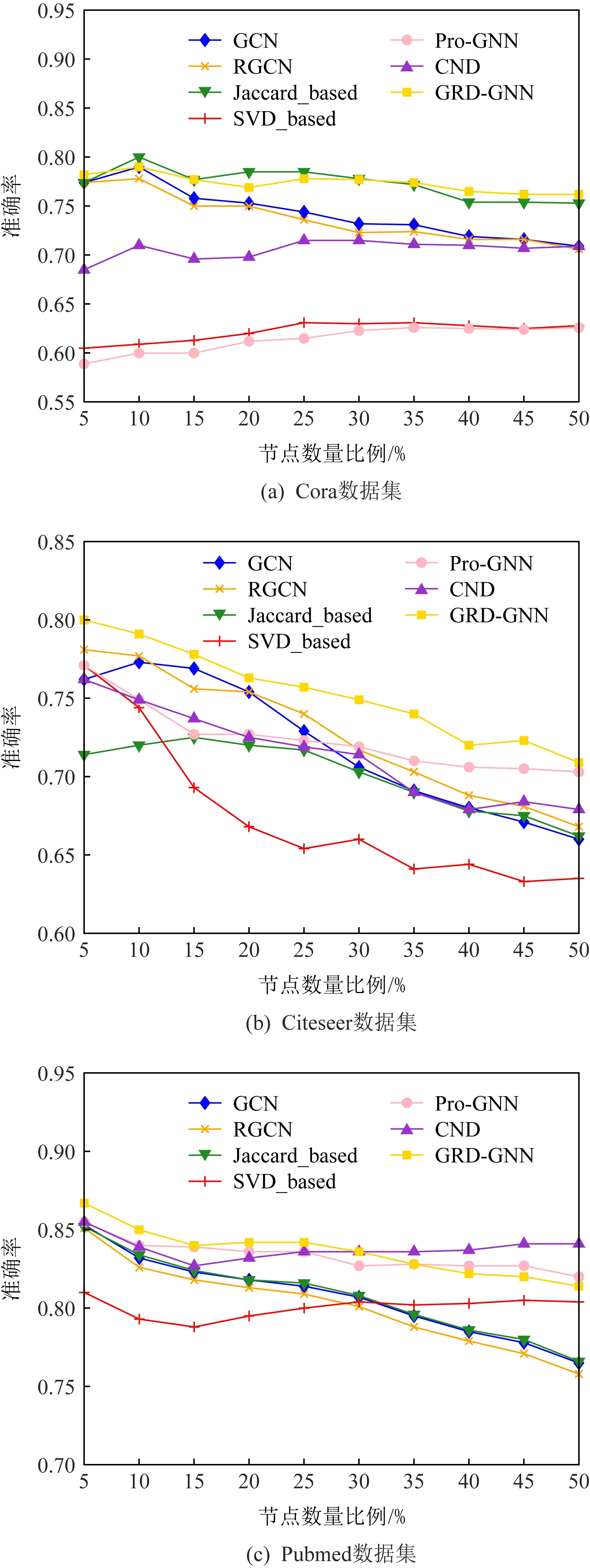
Fig. 5 Accuracy of nodes with different degrees under DICE (50% edges are modified)图5 在DICE(修改50%的连边数)攻击下不同度值节点的准确率
分析图4可知,高度值节点对Metattack的攻击容忍性较高,而度值较低的节点更容易受到对抗攻击的影响,因此Accuracy曲线总体呈下降趋势.从图4中可以看到,在大多数情况下,GRD-GNN算法均能取得较好的效果,尤其是在Cora数据集上的性能提升尤为明显,在Pubmed数据集上的性能虽然略逊于Pro-GNN,可能是由于Pro-GNN方法更加复杂,但这也大大增加了Pro-GNN的计算资源消耗,在时间成本上,GRD-GNN比Pro-GNN更加占据优势.此外,在Pubmed数据集上,CND,SVD_based在度值较小的节点上的分类准确率略有上升,原因在于两者对图的修改程度比较大,而这种修改对低度值节点的影响大于对高度值的影响.如图5所示,由于DICE的随机性,使得其对其防御难度增加,但是在大多数情况下,GRD-GNN均能取得最好的性能,但是基于扰动存在于图的高秩部分条件的SVD_based性能明显下降.这说明了SVD_based具有更加苛刻的限制条件.
4) 防御通用性
作为一种对输入图进行重构的方法,GRD-GNN算法可以匹配不同的图神经网络,是一种通用的图神经网络防御方法.同样地,Jaccard_based,SVD_based是对扰动图进行纯化,因此也适用于各类图神经网络.由于模型限制和硬件条件限制,在本节实验中,采用Jaccard_based,SVD_based,GRD-GNN这3种方法进行对比,在图注意力网络GAT模型上进行测试.实验中的扰动设置与针对目标攻击的防御效果和针对无目标攻击的防御效果的实验相同.实验结果如表5、图6和图7所示.
结合表5、图6和图7,在大多数情况下,GRD-GNN相比其余2种图纯化方法都能取得最佳效果.无攻击情况下,3种防御方法均使GAT的分类性能下降,其中SVD_based在Cora,Citeseer数据集上使模型性能大幅下降,而Jaccard_based,GRD-GNN均能较好地保持GAT模型在干净样本上的分类性能;在NETTACK攻击场景中,当攻击所添加的扰动较小时,对GAT模型攻击性尚未体现,因此GRD-GNN的对NETTACK的防御能力没有充分体现;在扰动程度较大时,相比其他2种防御方法,GRD-GNN的优势得以体现,尤其是在Citeseer,Pubmed数据集上,甚至能取得与无攻击情况下相近性能,在Cora数据集上也能获得较大的准确率提升.与实验的结果类似,GRD-GNN都能取得较好的效果,而在Metattack攻击场景中,GRD-GNN在3个数据集上相比于另外2种防御方法取得了很大的优势.实验证明了GRD-GNN可以有效地加载在其他图神经网络上,以提高图神经网络对对抗攻击的鲁棒性.

Table 5 Accuracy of Different Defense Method Against NETTACK Based on GAT

Fig. 6 Accuracy of GAT with different degrees under Metattack (25% edges are modified)图6 在Metattack(修改25%的连边数)攻击下不同度值GAT的准确率

Fig. 7 Accuracy of GAT with different degrees under DICE (50% edges are modified) 图7 在DICE(修改50%的连边数)攻击下不同度 值GAT的准确率
3.6 有效性分析
3.5节主要对GRD-GNN与其他防御方法进行比较,测试了不同攻击场景、不同模型上的性能,本节将进一步从不同角度探究GRD-GNN方法的有效性原因.
1) 原图与重构图的度分布比较
首先通过图的度分布情况来评判GRD-GNN重构图的优劣.由于NETTACK针对目标节点进行攻击,且添加的扰动相较于网络连边数量不多,因此对图的度分布影响不大,故本文对Metattack攻击(修改25%连边)进行分析.如图8所示为干净图、经过Metattack扰动图、CND重构图和GRD-GNN重构图的度分布情况.各数据集呈现明显的幂律分布,因此,经过重构后的图也应当保持幂律分布的特性.其中,CND对图结构有明显的破坏,这是其使GCN模型总体性能下降的原因之一.观察经过Metattack攻击的图可知,Metattack对低度值的节点影响较大.而经过GRD-GNN重构后的图分布与干净图更为接近,说明GRD-GNN能在一定程度上消除Metattack对图结构的影响.

Fig. 8 Degree distribution of graphs图8 图的度分布
2) 原图与重构图的节点相似度分布比较
从连边对应节点的特征相似度考虑,具有相同标签的节点应当具有高相似度.同样使用Metattack(修改25%连边)进行攻击,对图中两两节点之间的特征相似度分布进行分析,如图9所示.
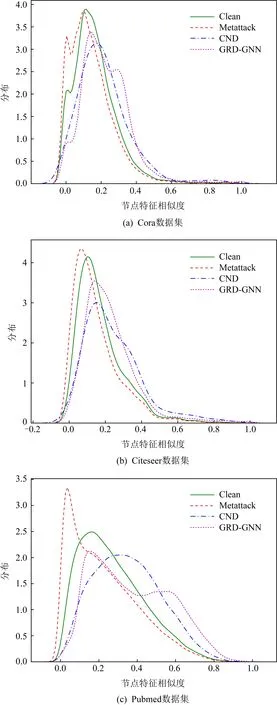
Fig. 9 Node similarity distribution in the graph图9 图中的节点相似度分布
由图9可知,在Metattack的攻击下,大量的不相似节点将被连接在一起,因此,节点间的相似度分布与干净图相比偏低.而CND根据节点的结构相似度对连边进行删除,可以有效地删除一些对抗连边,但是同时也导致了正常连边的缺失.GRD-GNN在连边删除的基础上基于节点特征相似度对图进行重构,因此GRD-GNN重构图的节点特征相似度分布较高,且图结构更加完整,更有利于图神经网络模型的分类性能提升.
3) 防御前后embedding对比
本实验对GCN模型提取到的embedding利用t-SNE方法映射到2维空间进行可视化,以此判断模型生成的embedding的质量.由于NETTACK是对部分目标节点进行攻击,在t-SNE图中难以观察到,因此本实验采用无目标攻击的Metattack作为攻击者,以Cora数据集为例,结果如图10所示.
比较图10(a)(b),GCN和GRD-GNN在干净图上都能分辨出明显的7个簇,但是GRD-GNN重构出的分布较为分散,这与GRD-GNN在干净图上的分类准确率较GCN模型略有下降的实验结果相对应.对比图10(a)(c),在Metattack的攻击下,GCN模型提取的embedding质量明显下降,不同类别之间的类间距离缩小,不同类别的节点混杂,这是在Metattack攻击下,GCN模型节点分类准确率大幅下降的原因.最后比较图10(a)(c)(d),即比较防御前后的效果,可以发现,GRD-GNN能明显提升GCN在攻击下的embedding提取质量,同类节点间更加紧凑,类与类之间距离增大,因此使GCN模型的分类性能得以恢复,这也直接证明了GRD-GNN的有效性.相同的结论也能在Citeseer,Pubmed数据集上得出.
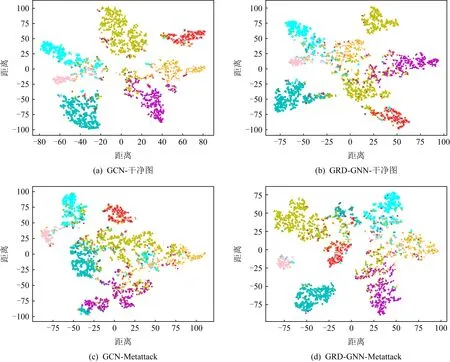
Fig. 10 t-SNE of embedding generated by GCN (Cora)图10 GCN生成的embedding的t-SNE图
3.7 图关键结构可视化及解释
在很多情况下,图神经网络常被作为黑箱模型使用.近年来,许多工作试图探索图神经网络究竟学习到了什么,而这对于提高模型的透明度,减少模型出现系统性错误的风险有重要作用.因此,通过对比图神经网络在攻击前后和防御前后学习到的关键结构,也可以对防御算法的优劣进行评判.图11为基于GRAD解释方法提取的与目标节点相关的重要子图.以Cora数据集为例,图11(a)~(c)为在NETTACK攻击下,防御前后提取到的子图,可见NETTACK添加扰动后与干净图有较大的区别,这也是因为NETTACK是一种目标攻击,对目标节点的连边修改较多,而由GRD-GNN重构的图结构虽然与干净图相比并不是完全相同,但是结构上更加相似.在Metattack攻击场景中也能得到相似的结论.需要说明的是Metattack为无目标攻击,因此对目标节点的扰动可能不大.如图11(e)所示,Metattack攻击下提取到的子图中出现了环结构,这在干净图中是没有的,GRD-GNN重构图中提取到的子图与干净图基本一致.由于DICE的随机性,GRD-GNN重构图中提取到的重要子图虽然与干净图不太一致,但是任能保留一些主要结构,如图11(g)(i)中的环结构.
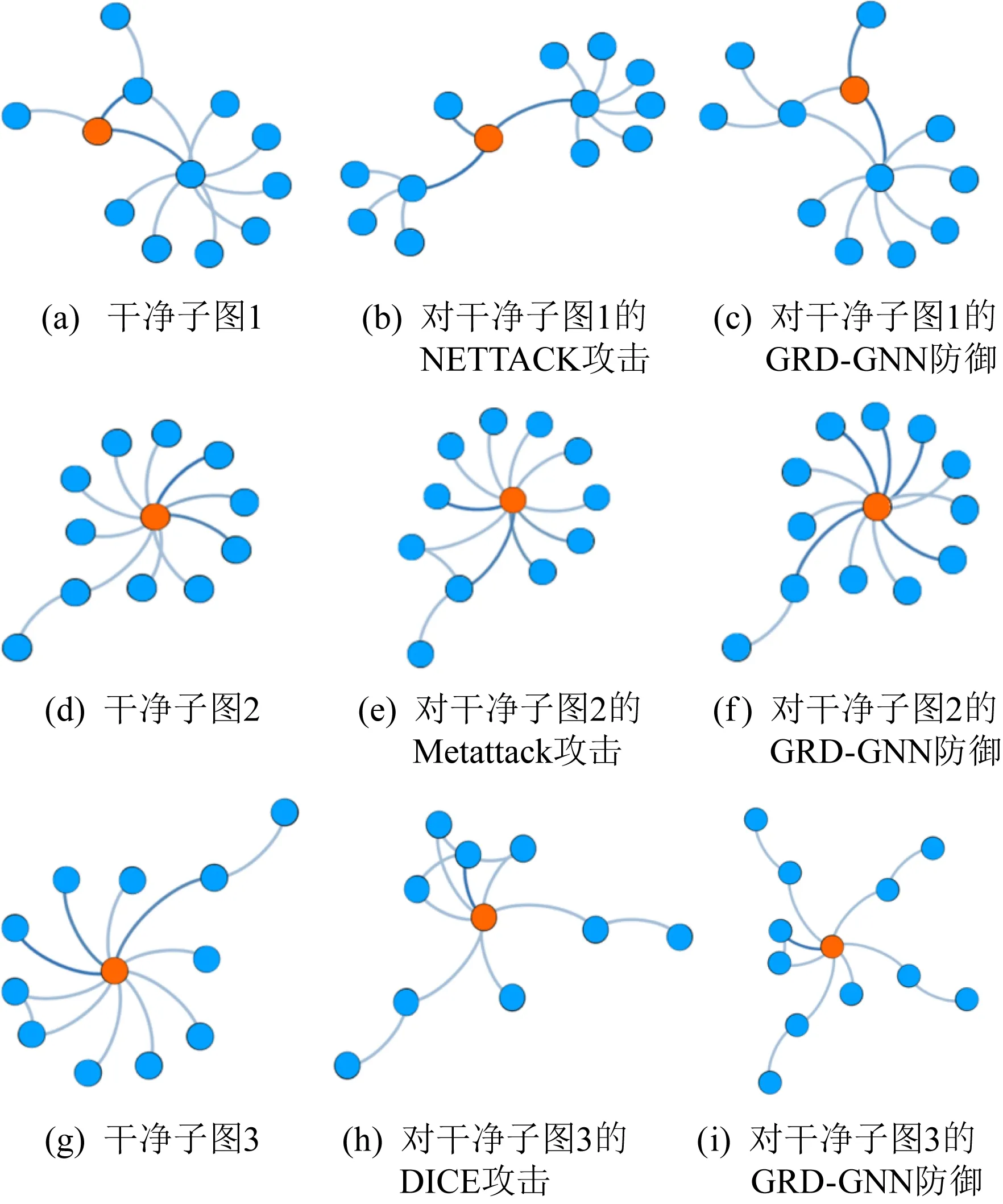
Fig. 11 Important graph structure related to target node based on GRAD explainer (Cora)图11 基于GRAD解释方法的目标节点相关的重要子图(Cora)
3.8 参数敏感性分析
本节主要对GRD-GNN的2个参数(即结构相似度阈值k和节点特征相似度阈值τ)的敏感性进行分析.实验中,本文在固定某个阈值的条件下,改变另一个阈值来研究不同的阈值对GRD-GNN性能的影响.本实验中以Cora数据集为例,在NETTACK添加5条连边的攻击和Metattack修改图中25%连边的情景下分别进行测试,其中结构相似度阈值k由0~3设置,步长为1;节点特征相似度τ由0~0.3设置,步长为0.05.GRD-GNN的性能变化如图12所示.为所有参数选择合适的值,可以提高GRD-GNN的准确率.当随着结构相似度阈值k的提高,GRD-GNN性能下降,这是由图的稀疏性导致的,即结构相似度阈值k的值越高,更有可能删除图中相对重要的连边,导致图神经网络模型性能下降.而节点特征相似度τ过小或过大都会损坏模型的性能.因此,较小的结构相似度阈值k和适当的节点特征相似度τ可以有效地提高GRD-GNN的防御性能.根据结构相似度阈值k和节点特征相似度τ对不同数据集的敏感性不强,故本文中采用网格搜索的方式对阈值进行优化,从而获得局部最优值.本文实验设置结构相似度阈值k参数集合为[0,1,2,3],节点特征相似度τ参数集合为[0,0.05,0.1,0.15,0.2,0.25,0.3].

Fig. 12 Parameter sensitivity analysis图12 参数敏感性分析
4 总 结
本文首先观察了4种攻击算法生成的不同对抗样本的结构相似度和节点特征相似度,发现对抗连边倾向于连接结构相似度和节点特征相似度较低的节点.在此观察的基础上,本文提出了一种基于图重构的图神经网络防御方法.这是一个通用的防御框架,可以接入到图神经网络的输入部分来达到输入数据转换的防御效果.本文提出的GRD-GNN算法在确保GNN模型在干净样本上的性能的同时,对输入的扰动图进行重构,获得滤除对抗连边的增强图,从而提高GNN模型对对抗攻击的鲁棒性.本文在3个真实数据集上进行大量实验,验证了本文提出的基于图重构的图神经网络防御方法取得了最佳的效果.此外,本文还从度分布、节点属性特征分布和GNN模型提取的embedding信息等多个角度分析了方法的有效性,并且使用图神经网络解释方法对防御方法的有效性进行可视化解释.但是在实验中,尽管引入了图增强机制,但是GRD-GNN还是降低了GNN模型在干净样本上的部分性能,因此在未来的工作中,我们将致力于保持甚至提高GNN模型在干净样本上的性能,并进一步降低对抗攻击带来的影响,提高GNN模型对对抗攻击的防御能力.
