基于快速神经网络架构搜索的鲁棒图像水印网络算法
2021-06-03王小超张雷余元强胡坤胡建平
王小超,张雷,余元强,胡坤,胡建平
(1.天津工业大学数学科学学院,天津 300387;2.天津大学 智能与计算学部,天津 300350;3.中国科学院大学,北京 100049;4.东北电力大学 理学院,吉林吉林 132012)
随着互联网和通信技术的快速发展,信息传播和共享愈发频繁和重要,人们对知识产权与信息安全亦越来越重视。为预防信息传输中图像被非法篡改和恶意传播,常用图像水印技术对图像进行版权保护和防伪认证[1-2]。
深度学习具有提取图像非结构化特征的优势,已成为图像处理领域的一种重要方法,并在图像水印算法中被广泛关注和应用。VERMA 等[3]提出结合支持向量机与主成分分析的特征提取算法;SUN等[4]提出在BP 神经网络中应用Arnold 变换的水印嵌入算法;CHEN 等[5]提出在卷积神经网络中加入中值滤波的思想;MUN 等[6]提出一种基于自编码器的神经网络结构。以上算法主要针对简单的水印字符图像。BALUJA 等[7]提出一种三层式图像嵌入与恢复网络,能嵌入与宿主图像相同复杂度的彩色图像,甚至可同时嵌入多张水印图像,展现了深度学习在图像信息隐藏中的潜力。该网络由3 个子网络组成,每个子网络由线性的全卷积层结构堆叠而成,能同时训练隐藏和复原过程。隐藏网络和复原网络需防止图像隐藏的信息被他人随意提取和篡改。然而该算法的训练网络需要大量计算资源,通常需要使用多个GPU 连续训练数天乃至数周才能达到较好的效果,如在ImageNet 数据集下进行实验,使用单个GPU 需连续训练5 d 才能达到最佳性能。
神经网络架构搜索[8](neural architecture search,NAS)是一种自动设计网络技术,旨在帮助网络设计人员有效设计合适的网络结构,应对不同的场景和数据。预先给定网络结构或超参数的搜索范围,通过一定的搜索策略搜索最佳网络结构和参数,常见的搜索策略有强化学习NASNet[9]、ENAS[10]、Path-level NAS[11]、进化算法[12]、AmoebaNet[13]、微分近似[14](DARTS)等,这些算法通常需要花费很长时间才能获得较满意的结果。ZHENG 等[15]提出的多项式分布学习快速神经网络架构搜索(multinomial distribution learning for effective neural architecture search,MDLNAS)算法在搜索速度和性能上优势显著。MDLNAS 将每个搜索空间看作一个联合多项分布,最优的网络结构依据概率最大原则获得。网络在每个批次的训练集前依据概率随机采样,对神经元进行操作,并在训练一个批次后对网络结构进行评估,根据评估结果更新网络结构。一个训练批次对应一个评估批次,保留每个神经元操作的权重参数,避免因网络结构变动出现需重新训练网络的问题,从而提高搜索效率。
本文在BALUJA 等[7]工作基础上,将嵌入网络中每层子网络内的全卷积结构设定为神经单元结构,其中结构单元内节点间的运算操作由MDLNAS 算法确定[15]。通过修改MDLNAS 算法中的更新策略,使其适用于处理图像水印嵌入任务。MDLNAS 算法得到的网络,其网络权重数明显较文献[7]中网络的低,网络训练速度显著提升。在CIFAR-10 和ImageNet 数据集上的测试结果表明,本文提出的网络结构嵌入效果相对较好。在图像嵌入中,本文提出的网络结构对图像空间信息的依赖性较文献[7]中的网络结构低,能更好地保持隐藏图像的信息;在模型推理速度上,本文提出的网络结构推理速度较文献[7]中的网络结构提高了3 倍以上,并且训练得到的模型在新数据集上拥有更强的泛化能力。最后,大量对比实验结果表明,本文提出的图像水印网络对抵抗旋转、白噪声、水平镜像和上下翻转等攻击均具有显著的鲁棒性。
1 算法流程
1.1 网络架构搜索
文献[7]中的网络由3 层子网络构成,即预备网络、隐藏网络和复原网络.每个子网络均为线性连接的全卷积结构。首先确定网络架构搜索空间,在3 层式深度图像嵌入网络的基础上,将每个线性连接的全卷积层结构子网络设计为一个神经结构单元。如图1 所示,单元中拥有2 个输入节点、4 个中间节点和1 个输出节点,2 个输入节点I1和I2分别为单元的先驱节点和先驱的先驱节点在经过一层卷积后的特征张量。中间节点Bi(i=1,2,3,4)由I1,I2和B1,B2,…,Bi-1经过各自边运算操作后按元素级相加而成。将B1,B2,B3,B4节点的张量在深度方向进行拼接操作,得到输出单元。图1 中每条黄色边在实际训练过程中由预定义的神经元操作采样而成,完整的网络结构如图2 所示。
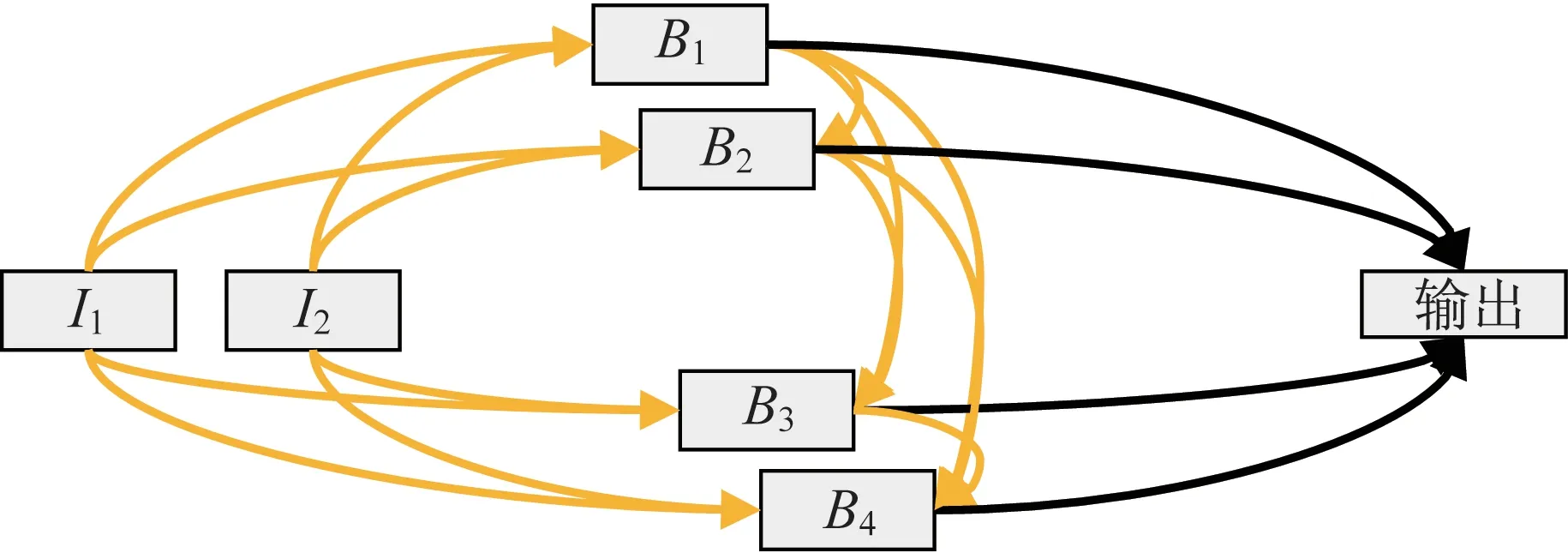
图1 神经网络结构Fig.1 Neural network structure

图2 图像水印网络结构Fig.2 Image watermarking network structure
预备网络:在网络开始时,标准化后的输入S,先通过1 层卷积将特征通道数增至48 层(记作T),然后将2 个预处理层(全卷积层)分别作为单元的输入I1、I2。将单元的输出和T经拼接操作后依次经过ReLu 激活函数、卷积和Tanh 激活函数得到预备网络的输出。
隐藏网络:首先对预备网络的输出和被嵌入宿主图像的标准化张量H进行拼接,剩下的网络拓扑结构同预备网络,最终得到Tanh 激活函数下的3 通道张量,即嵌入后图像的标准化张量H′。
复原网络:以隐藏网络的输出H′作为输入,余下的网络拓扑结构同预备网络,最终得到3 通道张量,即复原后图像的标准化张量S′。
网络结构搜索过程中使用的损失函数定义为

其中,H与H′、S与S′越接近损失函数值越小、嵌入与重建效果越好,系数β用于平衡宿主图像和嵌入图像重建的损失。式(1)中,|H-H′|的大小不影响复原网络的更新权重,因为复原网络不参与重建宿主图像H的过程。而β|S-S′|的大小影响3 个子网络的更新权重。
本文中的NAS 网络架构由3 个子网络内单元中的节点间操作决定。单元内部每个中间节点间的连接由8 种预定义的操作构成(3×3 最大池化、3×3 平均池化、跳跃连接、3×3 深度可分离卷积、5×5深度可分离卷积、3×3 空洞卷积、5×5 空洞卷积、无连接)。
每2 个节点有M种可能的操作,本文中M设置为8 。在初始化阶段,将选择每种操作的概率初始化为均匀分布

由概率分布即可将M个概率值{pj}转换为二进制门控单元{gj},即

由门控单元决定2 个节点之间的操作,即

由式(2)可知,在对节点间操作进行选择时只需进行矩阵乘法运算,运算效率高。在得到操作选择的结果后,需对操作进行评估。如果操作A 优于操作B,则操作A 具有更少的训练批次和更低的损失函数值。
本文将2 个节点之间的训练批次向量记为He,损失向量记为Hl,它们均为M维向量。矩阵ΔHe与ΔHl分别表示节点间训练批次的差值和准确率的差值,即

用式(3)更新2 个节点之间操作的概率分布,即

其中,Π(p)为示性函数,当p为真时,函数值为1,否则函数值为0。
包括2 个主要搜索过程,如图3 所示。(1)在训练集上先依据概率选择每个节点的连接操作,完成一个批次的训练,使用随机梯度下降更新网络参数;(2)固定网络权重参数,在验证集上用网络计算损失函数,并利用迭代更新公式计算下一种操作被选择的概率。具体算法步骤如下:

图3 NAS 算法流程Fig.3 NAS algorithm flow
输入:训练集Dt,验证集Dv,训练次数E,网络模型F。
Step1令k=1,初始化所有M种操作的概率;
Step2对每一个单元中的边依据概率采样选择操作;
Step3用一个批次的Dt训练网络;
Step4令k=k+1,在Dv上计算网络的损失函数值,并用式(4)更新概率;
Step5若k<E,则返回step2;若不满足,则输出概率向量。
1.2 水印网络的实现
在该网络架构中嵌入图像水印。该图像水印网络由预备网络、隐藏网络和复原网络三部分组成。
预备网络:在嵌入水印图像过程中,为使嵌入后的图像尽可能地与被嵌入网络保持较高的相似度,同时能顺利地从嵌入后的图像中恢复被隐藏的图像,要求在嵌入过程中将隐藏图像以高度压缩的形式嵌入宿主图像。此项任务由预备网络实现:输入原始的待嵌入图像,输出带嵌入图像信息的高维特征张量。
隐藏网络:该网络将宿主图像与隐藏图像的特征编码进行深维度拼接,通过卷积网络输出带有隐藏图像信息的融合图像。该层网络在嵌入隐藏图像特征信息的同时尽可能使输出的图像与宿主图像相似。
复原网络:该网络将获得的融合图像进行特征分离,提取被隐藏图像的信息并以图像形式输出,使复原图像与隐藏图像尽可能相同。
1.3 实验参数
NAS 算法参数设置:学习方法为随机梯度下降法,学习率的调整对网络模型的收敛起决定作用,学习率太小,网络收敛过慢,易陷入局部最小;学习率过大,会因每次更新参数幅度过大导致网络无法收敛。本文采用余弦退火算法[16]调整学习率,其优点是能有效消除参数抖动的影响。初始学习率设为0.025,调整范围为[0.001,0.9],权重衰减设置为0.000 3,动量设置为0.9。在实验中,训练阶段采用梯度裁剪,防止梯度过大导致网络训练不稳定,阈值设为5,总训练批次为100,一个批次的训练样本为32。
水印网络的参数设置:学习器为Adam,学习率固定为0.001。在损失函数计算式中,β设为0.75,总训练批次为100,一个批次的训练样本为32。
1.4 训练结果
实验图像来自CIFAR-10 公开数据集。该数据集共有600 000 张彩色图像,图像大小均为32×32,共有10 个类别,每个类别有60 000 张图像,其中,50 000 张图像为训练集,10 000 张图像为测试集。在模型训练前,为防止固定的训练样本与训练顺序导致过拟合或权重更新的方向被固定,每次训练前打乱排序,进行重采样,以保证原始图像和嵌入图像有相同的选中率。
本文的水印网络算法,参数量较文献[7]大大减少,从473 560 个减至36 218 个,减少了92%以上,能在较少的参数量下取得较好的性能,网络结构的训练速度更快,能在更短的时间内达到更优的效果。
图4 显示的为NAS 算法中损失函数值的变化情况,搜索训练过程中,损失函数值呈稳定下降趋势,表明NAS 算法的搜索效率高、收敛效果好。

图4 NAS 算法中损失函数的变化Fig.4 Change of loss function in NAS algorithm
图5 为本文算法与文献[7]的水印网络在测试集上的损失函数随训练批次的变化情况。由图5 可知,经80 个训练批次后,本文算法的损失函数趋于稳定,而文献[7]的损失函数仍有较大波动,说明本文算法具有更稳健的收敛性。

图5 本文算法与文献[7]算法训练过程对比Fig.5 Comparison between this paper and paper[7]of the watermark network training process
2 实验结果与分析
2.1 评价指标
通过范数距离L1、均方根误差、峰值信噪比和结构相似性指标等客观评价各算法得到的水印图像与隐藏图像的相似性。范数距离L1指标具有很好的稀疏性,表示两幅图像的相似程度;均方根误差用于衡量数值向量之间的差异,值越小说明图像的复原效果越好;峰值信噪比(peak signal to noise ratio,PSNR)越大,表示两幅图像越接近,可接受下限的PSNR 值为20~25 dB,具有较好的图像隐蔽性[17-18];结构相似性(structural similarity,SSIM)[19]用于衡量两幅图像的相似度,其较PSNR 更符合人眼对图像质量的感知。SSIM 的取值范围为[0,1],值越大,表示两幅图像的相似度越高。
2.2 实验结果
表1 为本文算法和文献[7]算法在两类数据集上的实验结果,在SSIM 指标上两者表现相近,在不同数据集上SSIM 指标均能维持在0.9 以上。图6为水印网络在CIFAR-10 数据集上两组实验的对比结果,可见本文算法与文献[7]算法得到的图像隐藏与重建效果均较好,提取的复原图像完整准确。

表1 宿主和融合图像相似性的各度量指标Table 1 Various metrics for the similarity of host and fusion images

图6 图像测试结果Fig.6 Image test result
为分析图像嵌入时隐藏图像的空域信息,考虑像素周围点对该点的复原影响,首先,定义像素点之间的切比雪夫距离:

其中,dij为(xi,yi)和(xj,yj)的像素距离。不断更新融合图像参考点(l,k)周围的像素值,并将其代入复原网络,得到复原图像S′,最后计算S′与S在(l,k)处的范数距离L2。如图7 所示,原始网络(文献[7]网络)在6 像素距离以内对参考像素的复原影响较大,在6 像素距离以外影响微小;而本文算法的水印网络在各像素距离下影响均较原始网络小,并在3 像素距离下产生的差异可控制在0.2 以下。经比较可知,本文算法的水印网络对空域的依赖更低,即在应对图像局部篡改时,本文算法的水印网络隐藏图像复原的稳定性更高。

图7 不同像素距离下修改周围像素对参考像素的影响Fig.7 Effect results of modifying surrounding pixels on reference pixels at different distances
为清晰展现2 个网络在CIFAR-10 数据集中的图像隐藏效果,在数据集上取部分示例图像并通过像素差可视化融合图像与宿主图像的差异。由图8可知,本文算法网络与文献[7]算法网络的融合图像差异较小,在放大10 倍和20 倍后,可隐约看到被隐藏图像的轮廓。

图8 本文算法与文献[7]算法的融合图像与宿主图像可视化Fig.8 Pixel difference between the fusion image and the host image both this paper and paper[7]放大倍数分别为1,10 和20 倍。Magnify is 1 times,10 times and 20 times,respectively
深度神经网络作为一种高度复杂的非线性系统,在固定的数据集上存在过拟合现象。本文算法将ImageNet 训练集上的模型应用于COCO 数据集和CelebA 数据集,以便客观体现模型的泛化能力。另外,由表2 可知,本文算法在2 种不同数据集上得到的SSIM 指标均在0.9 以上,且在2 种数据集不同指标的对比上,本文算法网络的泛化能力均优于文献[7]。表明本文算法具有更好的泛化性。

表2 ImageNet 数据集上训练得到的网络泛化能力Table 2 Generalization ability of the network trained on ImageNet
此外,为体现NAS 算法水印网络在前向推理中的时延,在CIFAR-10、ImageNet 数据集上分别对文献[7]算法和本文算法进行了测试,实验环境为单张NVIDIA RTX2060,实验结果如表3 所示,本文算法网络训练速度较文献[7]算法提升了3 倍以上。

表3 单张图像在前向推理中的时延Table 3 Delay of each image in forward inference
2.3 鲁棒性实验
为验证本文算法的鲁棒性,对嵌入水印后的图像分别进行旋转、椒盐噪声、高斯噪声、水平镜像、上下翻转等攻击,并分别在CIFAR-10 和ImageNet 数据集上进行测试。表4 和表5 分别为在CIFAR-10和ImageNet 数据集上融合图像遭受不同程度的旋转(5°,10°,15°)、高斯噪声(均值0,标准差0.001,0.005,0.01)、椒盐噪声(1%,3%,5%)、上下左右翻转、中值滤波(3×3)、高斯滤波(3×3,标准差0.02,0.04)、伽马校正(γ=0.3)、移除像素行(裁剪比例20%)等攻击后的隐藏图像提取结果。
表4 为文献[7]算法与本文算法在CIFAR-10数据集上受不同类型、不同强度攻击时的鲁棒性对比。由表4 中的对比数据可知,本文算法在受旋转、椒盐噪声、水平镜像、上下翻转和移除某行(列)等攻击时较文献[7]算法具有更强的鲁棒性,但在受高斯噪声、高斯滤波、伽马校正等攻击时优势不显著。由于CIFAR-10 数据集图像尺寸较小、图像信息量小、不具复杂的网络结构构造特征,使得本文利用NAS确定的网络结构难以体现优势;并且较小的图像分辨率使得图像在受微小攻击时,噪声会被额外放大。故用更大的数据集ImageNet 进一步验证本文算法的鲁棒性和有效性。
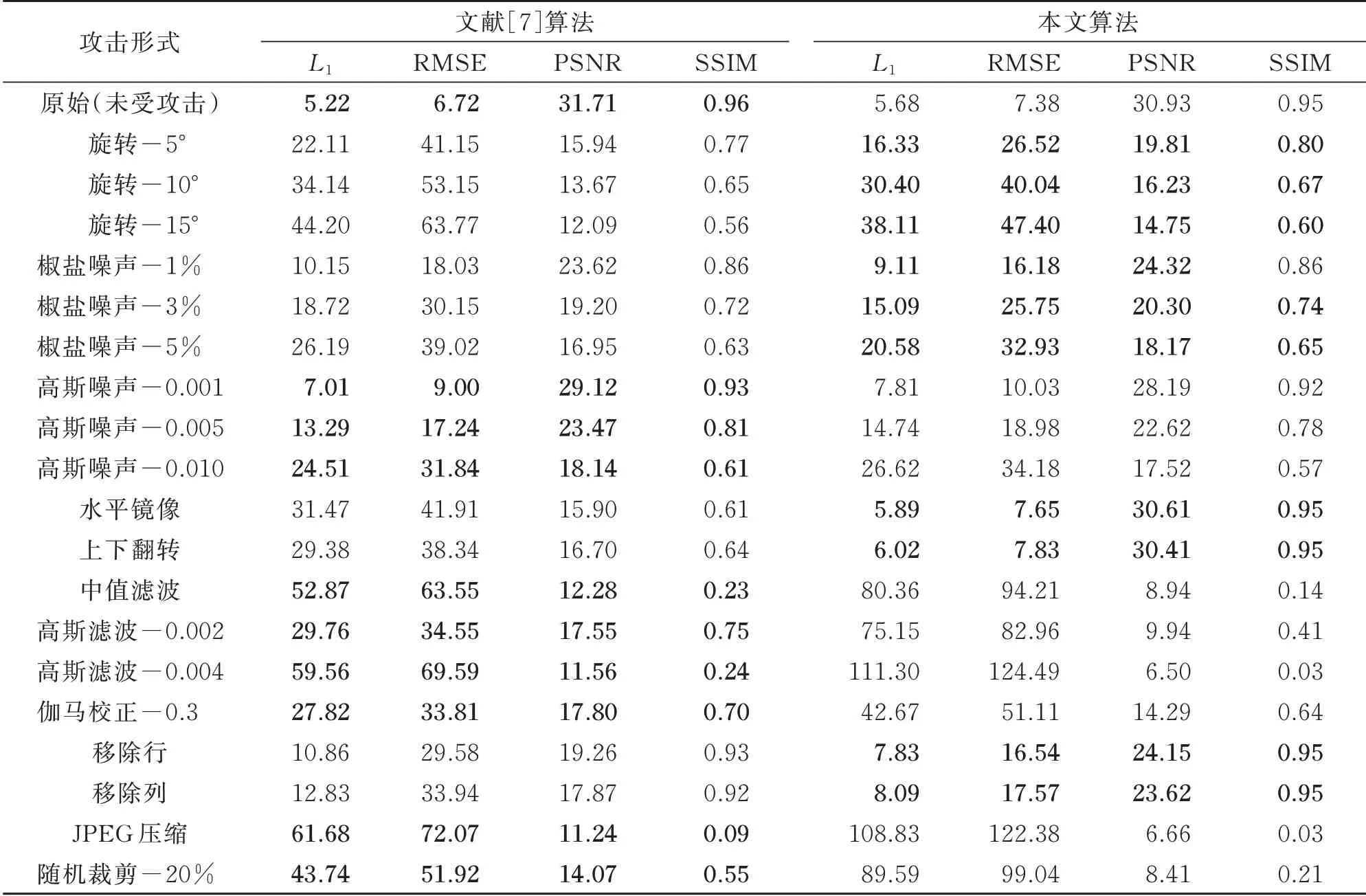
表4 文献[7]算法与本文算法在CIFAR-10 数据集上的对比Table 4 Comparison of paper[7]and this paper on the CIFAR-10 data set
ImageNet 是用于计算机视觉研究的大型数据库,实验中将所有数据集中的图片统一转换为224×224 大小。文中将ImageNet 中的验证集作为数据集。表5 为文献[7]算法与本文算法在ImageNet 数据集上的实验结果对比,由表5 可知,除受伽马校正攻击外,在受其他不同类型、不同强度攻击时,本文算法的各项指标均优于文献[7]算法,其中,在受伽马校正攻击时,在SSIM 指标上本文算法效果更佳。
此外,图9 更能直观体现本文算法的优势。由图9 可知,未受任何攻击时,在CIFAR-10 数据集上,原始网络的各项指标略优于本文网络,但在对嵌入图像做旋转、添加椒盐噪声、水平镜像、上下翻转、移除行(列)后,本文算法的4 项指标均优于原始网络,其中,对嵌入图像进行水平镜像和上下翻转后,本文的水印网络优势尤为明显,并且变换对模型的复原结果影响较小,SSIM 指标在变换前后保持一致(维持在0.95)。由表5 和图9 可知,在ImageNet 数据集上,本文算法表现更好,在经过各种噪声的干扰后,本文算法在SSIM 指标上的结果均优于文献[7]算法,说明本文算法具有更强的鲁棒性,并且对椒盐噪声、随机移除行(列)有更强的适应性。
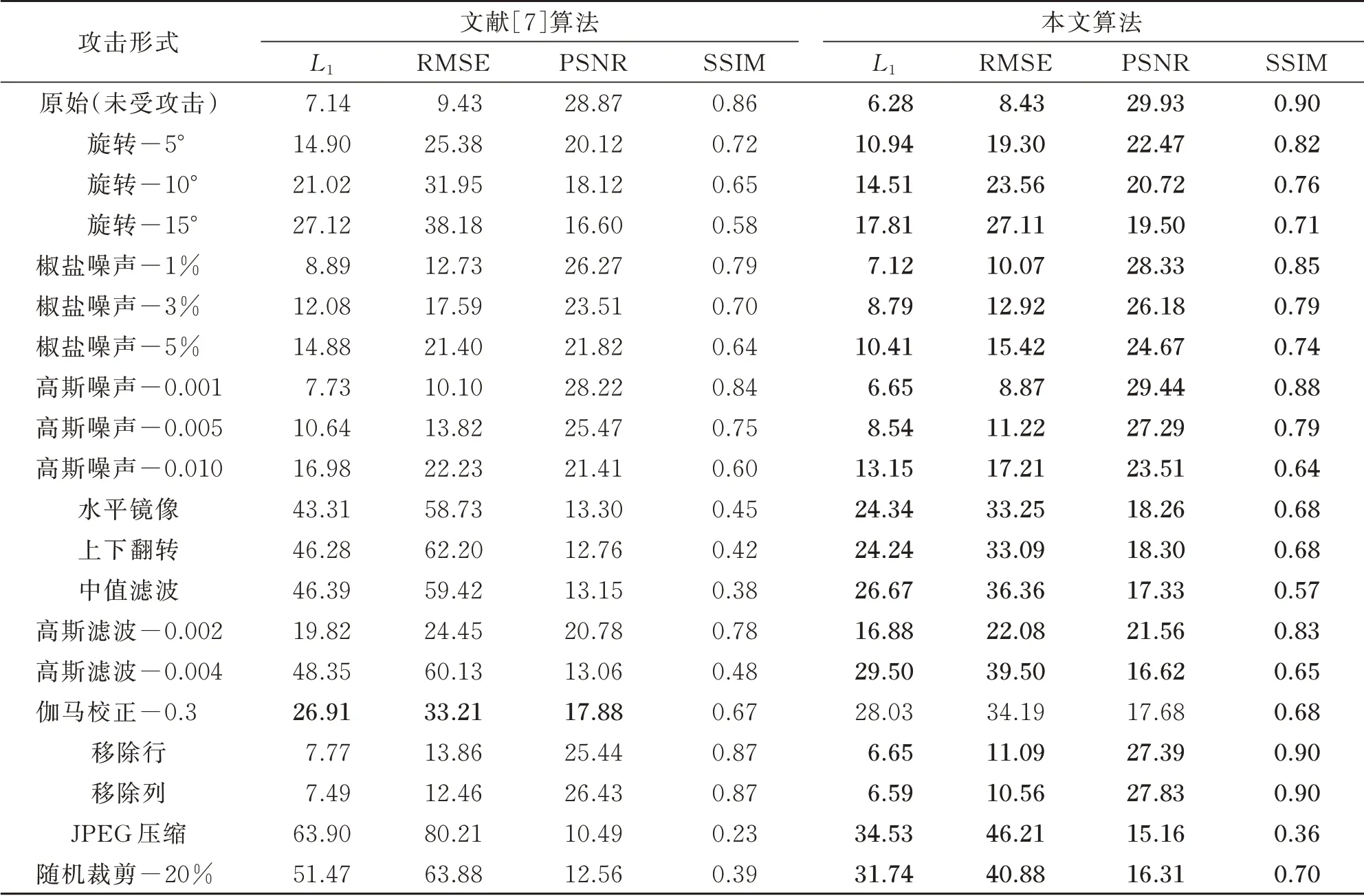
表5 本文算法与文献[7]算法在ImageNet 数据集上的对比Table 5 Comparison of paper[7]and this paper on the ImageNet data set

图9 本文算法与文献[7]算法在ImageNet 和CIFAR-10 数据集下的SSIM 对比Fig.9 This paper compares PSNR and SSIM with the paper[7]in the two data sets
2.4 算法局限与未来工作
本文算法在高强度高斯噪声下,SSIM 指标偏低。这是由于被隐藏的图像以另一种二维分布方式表示在融合图像上,常见的几种旋转变换对信息分布影响不大,而高斯噪声与融合后图像中的隐藏信息分布较为接近或产生的干扰破坏分布信息致使网络恢复过程变得困难。后续将考虑在复原网络前加入一层具有自动识别图像噪声分布能力的去噪网络[20-21],以提高在特定分布噪声攻击下图像的复原能力。
3 结语
利用深度学习在大量数据集中自动学习并且提取复杂特征的优势,采用3 层网络结构,结合多项式分布学习神经网络架构搜索的思想,在每个子网络中分别加入神经结构单元,通过MDLNA 算法快速确定网络的最优结构,实现水印图像的高效嵌入与鲁棒提取。相较原始线性网络结构,本文算法的网络结构具有更丰富的表达能力,无须人工调整和干预,节省了调节参数的时间,降低了设计和调整网络的难度。精简的网络结构使得本文算法较文献[7]算法在模型参数上缩减了92%以上,这有利于将图像水印网络部署在低内存的嵌入式设备中,具有重要的现实意义。大量实验结果表明,本文提出的图像水印网络算法在CIFAR-10 数据集上对抵抗椒盐噪声、旋转、翻转、移除像素行(列)等攻击具有显著优势,其中对水平镜像、上下翻转具显著鲁棒性。在ImageNet 数据集上对抵抗椒盐噪声、上下翻转、中值滤波、高斯滤波等具有显著优势,特别对随机移除行(列)、椒盐噪声有较强的鲁棒性。
