面向多服务价值链的业务资源双边匹配模型
2021-06-01孙林夫任春华
余 洋,孙林夫+,任春华,韩 敏,3
(1.西南交通大学 信息科学与技术学院,四川 成都 610031;2.西南交通大学 制造业产业链协同与信息化支撑技术四川省重点实验室,四川 成都 610031;3.成都信息工程大学 软件工程学院,四川 成都 610225)
0 引言
多服务价值链是多条以核心企业为中心的服务价值链条构成的有机集合体,它通过一系列的价值活动,将原本局限于单条服务价值链内企业间的业务协作拓展到多条服务价值链间,从而有效整合不同服务价值链上企业的业务资源并实现服务业务的高效协作[1-2]。多服务价值链涵盖了多条产业链的服务业务协作关系,并具备纵横双向协同性、资源优化均衡性和数据价值增值性等特征。
第三方云平台为多服务价值链上的供应商集群、经销商集群、服务商集群、4S店集群和物流商集群等整合业务资源与开展业务协作提供支撑[3-5]。随着第三方云平台上企业数量的不断增多,其业务协作呈现爆发式增长,从而积累了大量的业务资源,包括产品资源、服务资源、流程资源和数据资源等。这些业务资源中蕴含着巨大的潜力和丰富的价值,将给多服务价值链上的企业带来变革性的发展,同时也带来了严重的信息过载问题。因此,在第三方云平台环境下,如何快速精准地从纷繁复杂的海量信息资源中获取高质量有价值的业务资源,是多服务价值链上的企业盘活业务资源并提升其价值的关键难题之一。
本文以解决上述问题为目标,提出一种面向多服务价值链的业务资源双边匹配模型,该模型融合供需双方的个性化业务需求,从海量信息资源中为需求方筛选出最令供需双方满意的业务资源,该资源的质量可能不是最好的,但却能让供需双方的协作效果达到整体最优。
1 相关工作
在云制造领域,国内外诸多学者主要从研发任务、服务质量(Quality of Service, QoS)和业务资源等方面对匹配问题展开了大量研究,并取得了丰厚的研究成果。
在研发任务方面,杨续昌等[6]为提高任务和人员的综合满意度,提出一种基于聚类分析和双边匹配的产品开发任务分配方法,该方法先通过聚类算法进行属性特征相似人员的聚类,再通过任务评价排序方法进行最优任务集的评价决策,最后利用双边匹配理论在每个聚类群内的任务和人员之间进行精确匹配;程丽军等[7]针对云任务和资源匹配环节脱节问题,提出一种基于改进知识迁移极大熵聚类算法的云端融合任务—资源双边匹配决策模型(Task-resource Matching Decision Model, TMDM),该模型先改进历史聚类中心知识和历史隶属度知识的引入方式,再将聚类结果应用于云任务和资源的双边匹配决策优化模型,从而实现任务与对应类型资源的快速匹配;李颖新等[8]针对研发设计任务与知识资源之间的双边匹配问题,提出一种面向云制造模式的研发设计任务与知识资源双边匹配总体框架,该框架包括构建双边匹配满意度评价指标体系、处理多指标满意度评价信息和求解多目标双边匹配决策模型等关键步骤,从而提升产品设计任务执行的效率和质量;Lu等[9]针对双边云市场中用户任务需求和服务商资源的匹配问题,提出一种真实的双重拍卖机制,并通过Lyapunov优化技术最大程度地减少用户的成本,使云服务商和用户都能从中受益;Li等[10]针对云制造平台上复杂产品开发任务匹配过程中偏好信息存在的模糊性和不确定性问题,提出一种基于双犹豫模糊偏好信息的双向匹配模型,该模型先构造双犹豫模糊偏好信息评价矩阵,并将其转化为满意度矩阵,再构建一个使满意度最大化、双方代理差异度最小的多目标双向匹配优化模型,最后求解出最优的匹配结果。
在QoS方面,马文龙等[11]针对云制造环境下的服务选择匹配问题,提出一种基于QoS感知的云服务选择模型,该模型先建立了QoS信息感知和量化机制,再根据变精度粗糙集理论计算QoS评价指标的权重,最后采用制造云服务选择算法获得QoS综合性能排序,从而能够准确地为用户选择最佳服务;赵金辉等[12]针对服务提供方和需求方的按需互选问题,提出一种基于QoS的云制造服务双向匹配模型,该模型先利用可变模糊识别方法计算多指标信息的综合满意度,再以供需双方的服务满意度为最大化求解目标,利用隶属度函数的加权和方法将其转化为单目标线性规划模型进行求解,从而为用户选择双方都满意的最佳服务;马仁杰等[13]针对云制造服务的匹配推荐问题,提出一种基于区间和灰色关联度的云制造服务资源综合匹配方法(Service Resources Matching Method, SRMM),该方法先采用区间数对QoS信息进行描述,再采用灰色关联度计算QoS匹配相似度,最后对服务资源类型、描述和质量信息进行匹配、过滤和排序,得出服务推荐的结果;Ran等[14]为满足计算密集型应用程序随时间变化的计算负载,提出一种动态确定实例购买量的策略,用于保证QoS的同时最大程度地降低总计算成本;Xue等[15]为评估和优化服务匹配策略的适应性,提出一种基于计算实验的服务匹配策略评价框架,从供应方和需求方的角度设计了4种服务匹配策略,并在不同场景下验证了服务匹配策略的性能。
在业务资源方面,盛步云等[16]针对中小企业云制造服务平台存在的搜索智能度和搜索精度较低的问题,提出一种面向中小企业云制造服务平台的供需智能匹配引擎,该引擎先建立分行业的制造服务资源本体库,再采用语义推理的方式进行服务能力的智能匹配,从而使中小企业云制造服务平台更好地服务于广大中小制造企业;赵道致[17]针对云制造平台上的碎片化资源匹配问题,提出一种考虑主体心理预期的云制造资源双边匹配机制,该机制先基于多属性评价计算出资源供求双方之间的满意度,再基于满意度计算匹配主体的偏好序,最后基于偏好序求解最优的匹配结果;鬲玲等[18]为保证用户能够快速准确地检索到满足设计需求的服务资源,提出一个基于本体的设计需求和服务资源的多层次语义匹配模型,该模型将匹配过程分为基本信息匹配、功能属性匹配和服务质量匹配3个阶段,并给出每层的匹配内容和相似度算法;Zhang等[19]针对云制造中具有容量约束的聚合资源的资源服务匹配问题,提出一种改进遗传算法,从而确保所有任务的总成本和时间最低;Halima等[20]针对定价策略可能会导致违反时间限制和超出预算限制的问题,提出一种将云资源分配给受时间限制的业务流程活动的方法(Business Process Activity Method, BPAM),从而确保业务流程活动的资源需求与云资源能够正确匹配;He等[21]从用户和云服务提供商利益的角度出发,提出一种新的资源双边匹配策略,该策略先根据属性特征对资源和任务进行聚类,以减少资源检索的范围,再根据双边匹配算法(Bilateral Matching Algorithm, BMA)为任务匹配到适合的资源,以提高双方的满意度。
上述研究成果虽然从不同角度对匹配问题进行了深入研究,但是不能完美地应用于多服务价值链环境下的业务资源匹配,而且在匹配过程中普遍存在精度较差与耗时较长等问题。因此,本文提出一种面向多服务价值链的业务资源双边匹配模型,通过该模型来解决这一系列问题,并为需求方提供令供需双方最满意的业务资源。
2 业务资源双边匹配模型
在多服务价值链环境下,本文以满足供需双方的满意度为目标,结合模糊理论、欧几里得度量、层次分析法(Analytic Hierarchy Process, AHP)和熵权法(Entropy Weight Method, EWM)[22-23],构建面向多服务价值链的业务资源双边匹配模型(Business Resource Bilateral Matching Model, BRBMM),再从业务资源和企业信用的角度将BRBMM转换为基于业务资源和企业信用的多目标优化模型,最后求解出令供需双方最满意的业务资源,并将其相关信息返回给需求方,从而不仅维护了需求方的利益,还满足了供给方的需求。为更好地描述BRBMM,本节给出以下概念与定义:
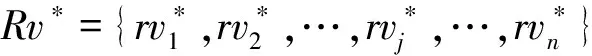
(1)

(2)
业务资源双边匹配实质是考虑供需双方(即需求方与供给方)满意度的优化方法,使其在业务资源匹配过程中获得令供需双方最满意的业务资源(即最大化供需双方的满意度)。由此可知,供需双方的满意度评价是实现业务资源双边匹配的核心环节之一,同时业务资源双边匹配的精确度依赖于科学合理的评价和计算供需双方的满意度。业务资源双边匹配的过程如图1所示,主要包括:①构建供需双方的满意度评价指标体系;②处理供需双方的满意度评价指标数据;③求解多目标优化模型;④输出最优结果,即最优业务资源。
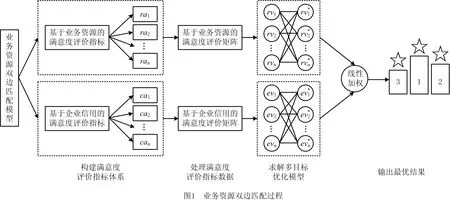
2.1 构建满意度评价指标体系
在多服务价值链环境下,BRBMM既要考虑需求方对业务资源的要求,还要兼顾供给方对企业信用的偏好。因此,本节从业务资源和企业信用两个角度对供需双方所需的满意度评价指标展开分析。
(1)基于业务资源的匹配分析
基于业务资源的匹配是从海量信息资源中为需求方寻找满足自身业务需求的最优业务资源。在多服务价值链环境下,业务资源的优劣受诸多因素影响,主要表现在两个方面:①业务资源的品质、价格和时效;②供给方的服务力、履约力和响应速度。综上所述,基于业务资源的满意度评价指标体系如表1所示。
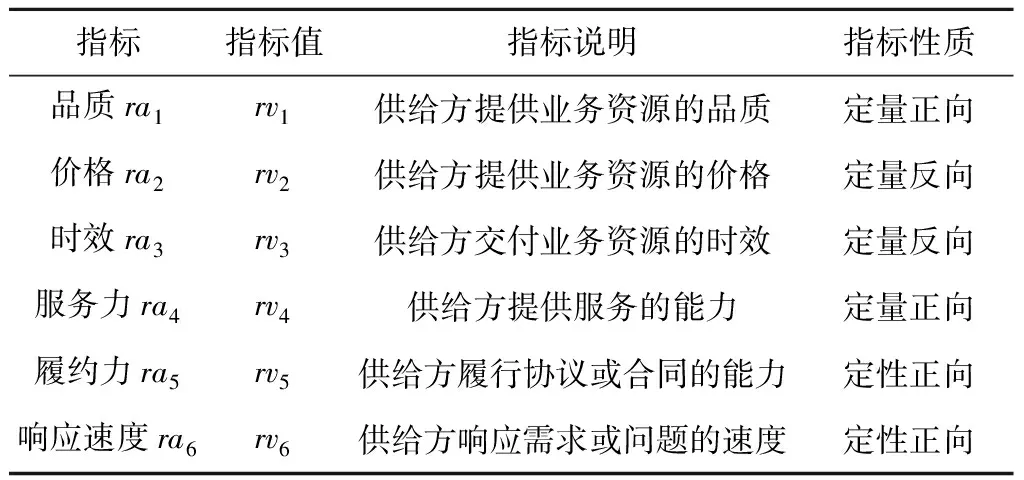
表1 基于业务资源的满意度评价指标体系
表中,ra1表示品质,其指标值rv1由业务资源的总销量Ns和因质量造成的退货量Nr决定,计算公式如式(3)所示;ra2表示价格(单位:元),其指标值rv2由业务资源的价格Pr和协作成本Cc决定,计算公式如式(4)所示;ra3表示时效(单位:h),其指标值rv3由响应耗费时间Tr和交付耗费时间Tt决定,计算公式如式(5)所示;ra4表示服务力,其指标值rv4由交付业务资源的及时率So和投诉率Sc决定,计算公式如式(6)所示;ra5表示履约力,其指标值rv5由需求方定性决定;ra6表示响应速度,其指标值rv6由需求方定性决定。
(3)
rv2=Pr+Cc;
(4)
rv3=Tr+Tt;
(5)
rv4=So+(1-Sc)。
(6)
(2)基于企业信用的匹配分析
基于企业信用的匹配是从诸多需求企业中为供给方遴选出符合供给方偏好的最优需求企业。在多服务价值链环境下,企业的信用主要受信誉度、付款速度和协作潜力的影响。综上所述,基于企业信用的满意度评价指标体系如表2所示。

表2 基于企业信用的满意度评价指标体系
表中,ca1表示信誉度,其指标值cv1由供给方定性决定;ca2表示付款速度,其指标值cv2由供给方定性决定;ca3表示协作潜力,其指标值cv3由历史协作的数量与金额、历史交易的数量和金额等定性决定。
上述指标根据性质划分为定量指标和定性指标,定量指标和定性指标根据指标类型划分为定量正向/反向指标和定性正向/反向指标。正向指标可称为效益型指标,取值越大越好;反向指标可称为成本型指标,取值越小越好。
2.2 处理满意度评价指标数据
在多服务价值链环境下,由于履约力、响应速度、信誉度、付款速度和协作潜力等定性指标难以通过精确的数值进行客观评价,只能由企业基于实际情况以主观的方式表述其属于“优”的程度。显而易见,在实际的业务场景下,经典集合理论已经无法处理上述模糊现象。模糊理论以模糊集合为基础,以处理不确定的事物或概念模糊为研究目标,从传统的精确集合、精确关系及演绎推理中扩展而来,可以处理客观事物中的模糊信息,因此模糊理论成为定量处理模糊性和系统不确定性的一种可行的方法[23-25]。
本文采用极优、较优、一般、较差、极差等模糊语言词汇对履约力、响应速度、信誉度、付款速度和协作潜力等定性指标进行主观评价,为使上述模糊语言词汇能够转换为精确的数值来反映定性指标的实际评价情况,本节引入模糊理论对这些模糊语言词汇进行量化处理,其相关概念与计算公式如下:
定义3二元关系A:U→[0,1],xA(x)表示集合A的特征函数是论域U到单位区间[0,1]的一个映射,其中A为U的模糊子集,函数A(x)为模糊集A的隶属函数(又称x为模糊集A的隶属度)。同理,设论域为所有定性指标集,则为QASU中的第k维定性指标,且
定义4语气算子实质是对隶属函数A(x)进行变换,将Hλ作为语气算子定量描述模糊语言词汇的隶属函数,则加上语气算子前缀后的隶属函数记为HλA(x),其计算公式为[23]
(7)
式中:λ表示模糊语言词汇级别;Nλ为选择λ级别模糊语言词汇评价x需求方(供给方)的数量;Nt为参与评价x的需求方(供给方)的总数量;HλA(x)为λ级别模糊语言词汇的隶属度,每一维定性指标的不同模糊语言词汇级别拥有不同的隶属度,具体内容如表3所示。

表3 不同模糊语言词汇的隶属度
定性指标评价值由所有模糊语言词汇的隶属度构成,其计算公式如式(8)所示。根据供需双方的满意度评价指标体系可知,上述定性指标均为正向指标,因此需求方和供给方分别对业务资源和企业信用设定相应的模糊语言词汇并进行量化即可。
(8)
式中Qask为第k维定性指标评价值。
采用式(3)~式(8)对原始数据矩阵RV和CV进行量化,形成量化后的满意度评价矩阵RV′和CV′:
(9)
(10)
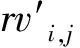
由于供需双方的满意度评价指标体系存在诸多指标且量纲均不相同,为求解业务资源与企业信用的双边匹配满意度,BRBMM一方面需要将所有指标值无量纲化以消除量纲的影响,另一方面需要将反向指标值转换为正向指标值以消除指标类型不统一的影响。本文分别采用式(11)和式(12)求解正向指标和反向指标的无量纲值,同时采用最大值作为衡量业务资源与企业信用优劣的标准,因此业务资源与企业信用越优,双边匹配的满意度就越高。
(11)
(12)
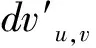
(13)
(14)
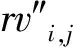
2.3 求解多目标优化模型
在多服务价值链环境下,业务资源双边匹配的目的是使参与匹配的需求方和供给方都能获得最大满意度。在RV″和CV″的基础上,求解业务资源和企业信用双边匹配最大满意度问题的实质是一个多目标优化问题。因此,本节将BRBMM转换为基于业务资源和企业信用的多目标优化模型,并从业务资源和企业信用角度出发为多目标优化模型构建相应的目标函数,通过线性加权的方法求解多目标优化模型。
常用的相似度计算方法包括欧几里得度量、余弦相似度和Pearson相关系数等。欧几里得度量通常用于计算多维空间中两个点之间的真实距离,适用于计算属性向量的相似度;余弦相似度通过计算两个向量的夹角余弦值来评估其相似度,适用于计算向量空间的相似度;Pearson相关系数通常用于刻画变量间线性关系的强弱,适用于定量度量[26]。
由于业务资源和企业信用涉及的数据均为结构化数据(即属性向量),本文选用欧几里得度量计算理想值和评价值的相似度。此外,因为多服务价值链上不同需求方与供给方考虑的角度不同,他们对业务资源或企业信用涉及的各个指标的偏好也有一定差异,所以本文采用AHP计算业务资源和企业信用涉及的评价指标的主观权重,用以体现需求方与供给方的需求和偏好。然而,仅采用主观权重无法体现业务资源和企业信用涉及的各个指标在客观方面的差异,当需求方经验不足时,若需求方与供给方设定的权重不合理,则会导致业务资源或企业信用评价值的可信度偏低,因此本文选取部分业务资源和企业信用的历史数据作为推理样本,采用EWM计算业务资源和企业信用涉及的评价指标的客观权重。综上所述,本文采用主客观权重来反映各个指标的重要程度。
根据供需双方满意度最大的需求和供需双方的满意度矩阵(RV″和CV″)构建BRBMM:
maxF1(rsi)=1-
(15)
maxF2(rsi)=1-
(16)
rsi∈RS。

式(15)和式(16)实质上是多目标优化模型的目标函数,因此本节将BRBMM转换为基于业务资源和企业信用的多目标优化模型,并采用线性加权法对上述两个目标函数进行加权处理,形成新的目标函数(如式(17)),并通过求解新的目标函数获得最优结果。
maxF(rsi)=θ1×F1(rsi)+θ2×F2(rsi)。
s.t.
θ1≥0,θ2≥0,θ1+θ2=1;rsi∈RS。
(17)
式中:θ1为基于业务资源匹配的权重;θ2为基于企业信用匹配的权重。默认θ1=θ2=0.5,在实际业务环境中,其取值可以根据供需双方的需求而定。
3 模型的实现方法
BMA是实现面向多服务价值链的BRBMM的关键算法,用于从海量信息资源中为需求方筛选出最令供需双方满意的业务资源,算法流程如图2所示。
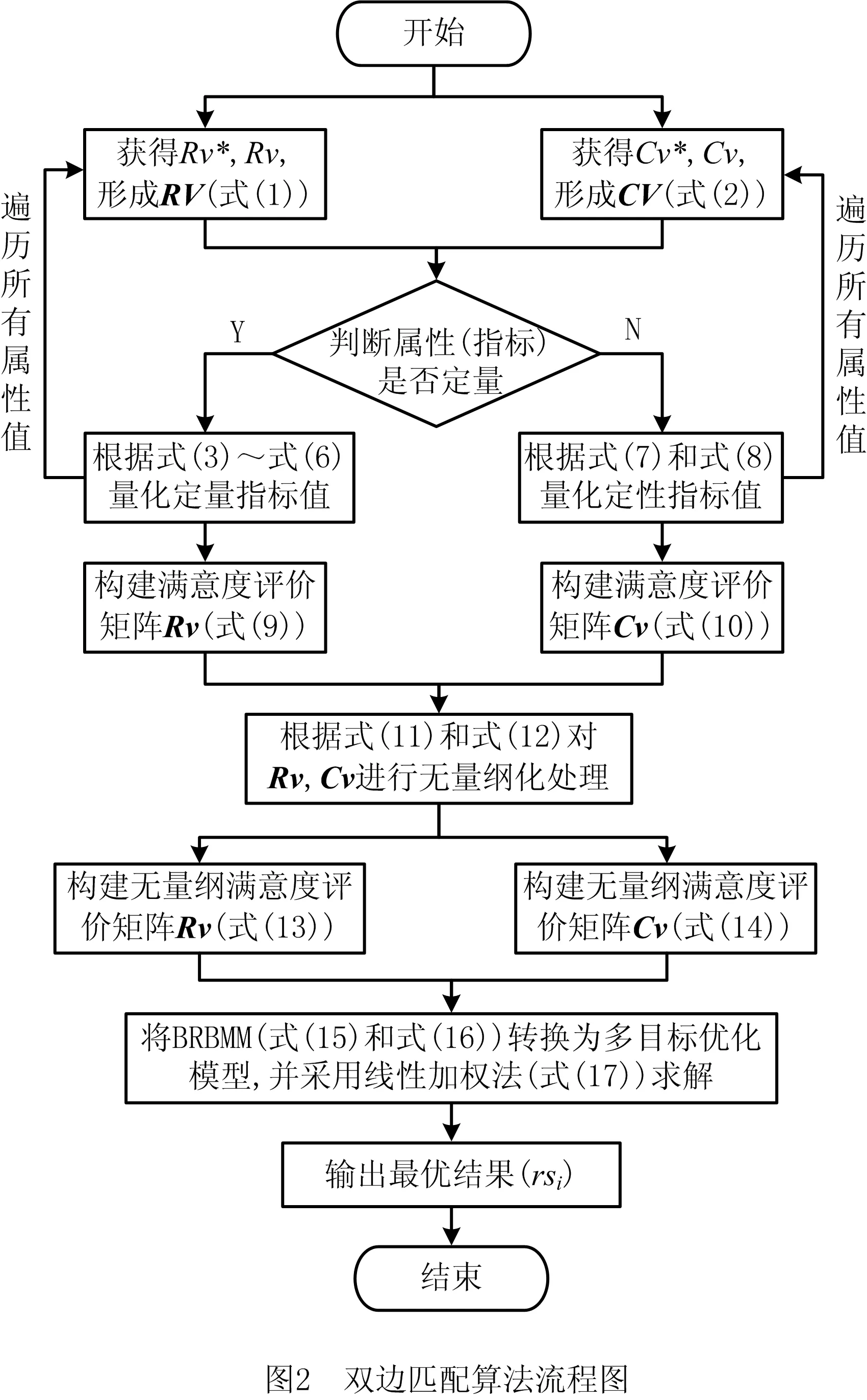
算法1双边匹配算法BMA。
输入:Rv,Rv*,Cv,Cv*。
输出:rsi。
步骤1获取基于业务资源匹配的所有数据集,包括云服务平台中所有业务资源各个属性的评价值集Rv、需求方定义业务资源各个属性的理想值集Rv*,形成基于业务资源的原始数据矩阵RV(式(1));获取基于企业信用匹配的所有数据集,包括供给方定义企业信用的各个属性的理想值集Cv、云服务平台中企业信用(需求方)各个属性的评价值集Cv*,形成基于企业信用的原始数据矩阵CV(式(2))。
步骤2在RV和CV的基础上,判断属性(指标)的性质是否为定量指标,是则采用式(3)~式(6)计算定量指标值;否则采用式(7)和式(8)量化定性指标,得到定性指标值。根据所有的定量指标值和定性指标值形成相应的满意度评价矩阵,即基于业务资源的评价矩阵RV′(式(9))和基于企业信用的评价矩阵CV′(式(10))。
步骤3采用式(11)和式(12)对满意度评价矩阵RV′和CV′进行无量纲化,形成与之对应的无量纲满意度评价矩阵,即基于业务资源的无量纲满意度评价矩阵RV″(式(13))和基于企业信用的无量纲满意度评价矩阵CV″(式(14))。
步骤4根据供需双方满意度最大的需求和供需双方的满意度矩阵(RV″和CV″)构建BRBMM(式(15)和式(16)),将其转换为基于业务资源和企业信用的多目标优化模型,并采用线性加权法对多目标优化模型的两个目标函数(式(15)和式(16))进行加权,形成新的目标函数(式(17))。
步骤5求解新的目标函数,为需求方筛选出令供需双方最满意的业务资源rsi,并将rsi相关的信息返回给需求方。
4 实验和结果
本文以多服务价值链上的某个企业(需求方)基于“基于ASP/SaaS的制造业产业价值链协同平台”进行业务资源双边匹配为例展开实验分析[27]。实验对象为汽车售后服务业务的配件数据资源,实验环境为标准千兆局域网且不考虑传输延迟,客户端的计算机配置为Intel Core i7-4770 3.4 G,16 G内存,操作系统为Windows 10;服务器端的计算机配置为Intel Xeon E5-2666 2.9 G,32 G内存,操作系统为Windows Server 2016。

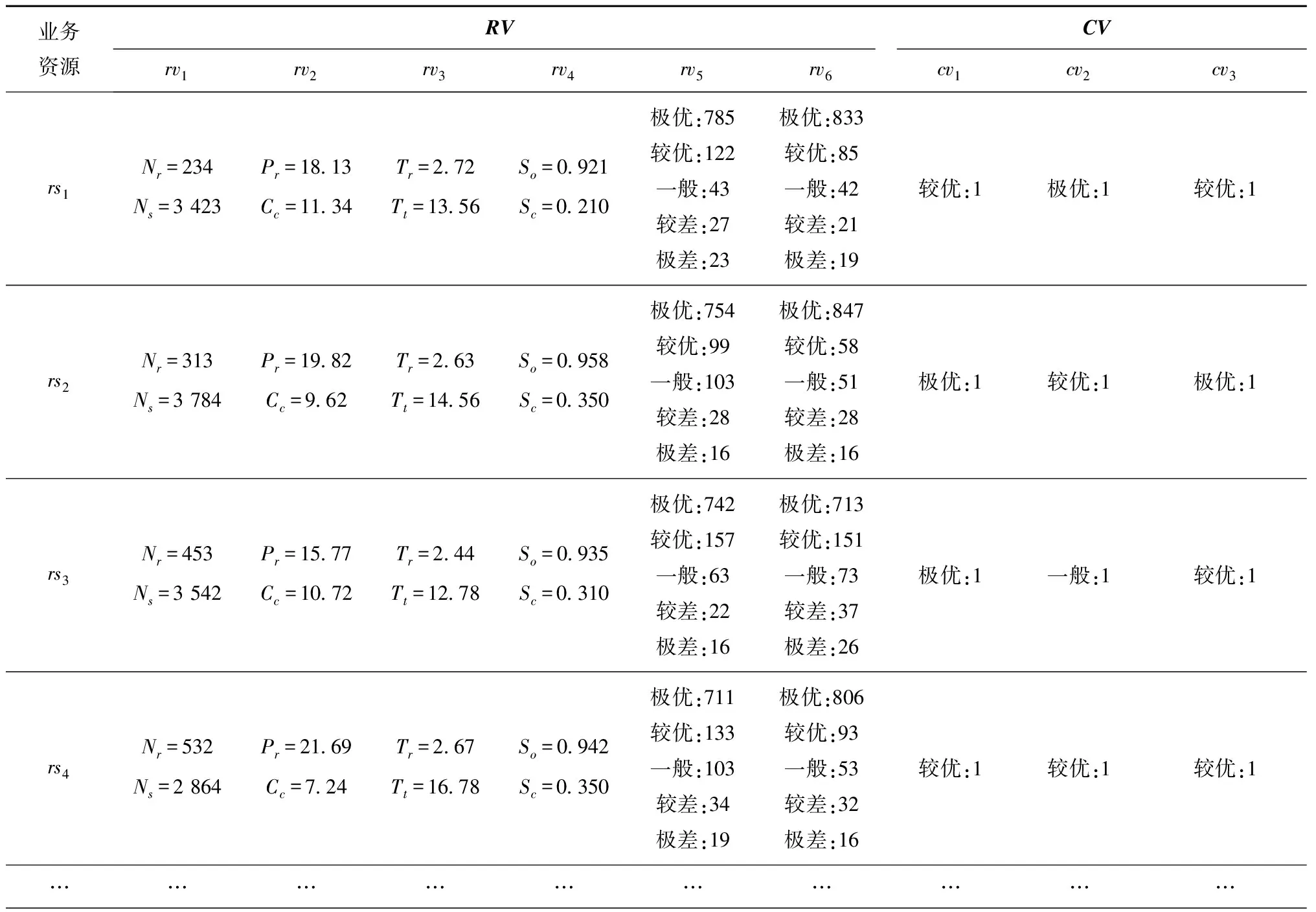
表4 原始数据矩阵
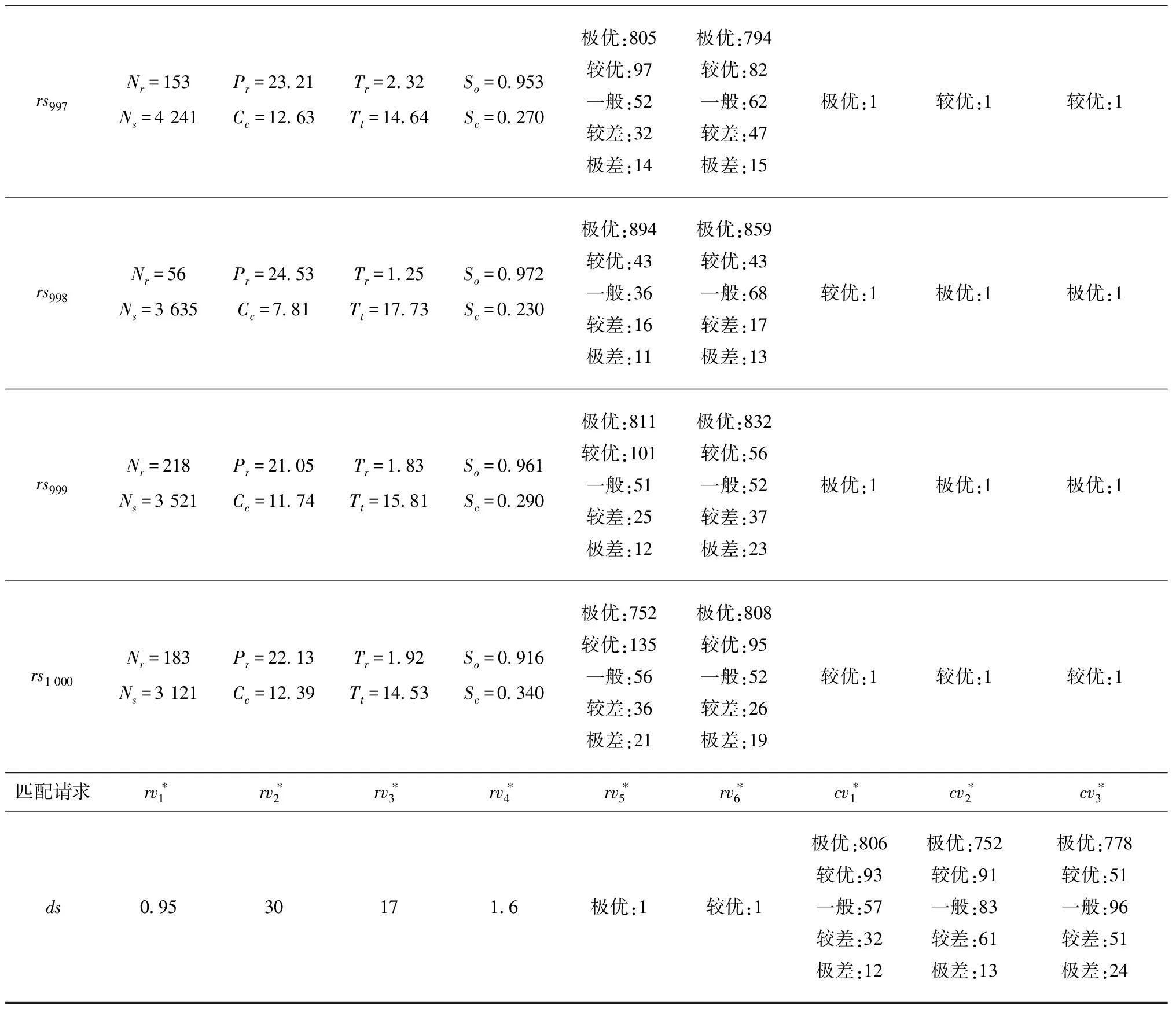
续表4

采用式(3)~式(8)对所有定量指标和定性指标的取值进行量化,构建相应的满意度评价矩阵RV′和CV′,如表5所示。
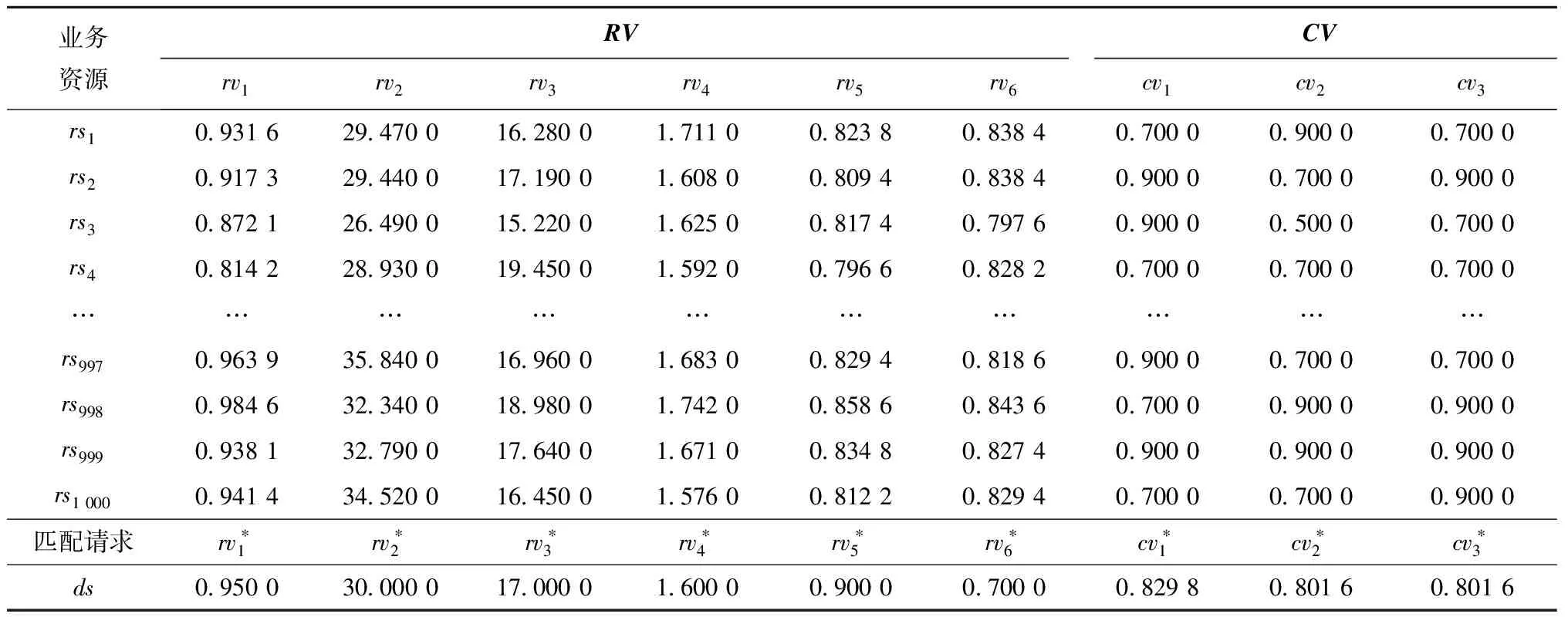
表5 满意度评价矩阵
为消除不同指标的量纲带来的影响,本文采用式(11)和式(12)对表5中的指标值进行无量纲化处理,得到的无量纲满意度评价矩阵如表6所示。

表6 无量纲满意度评价矩阵
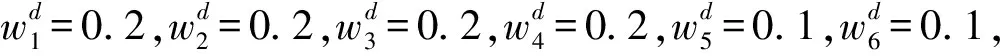
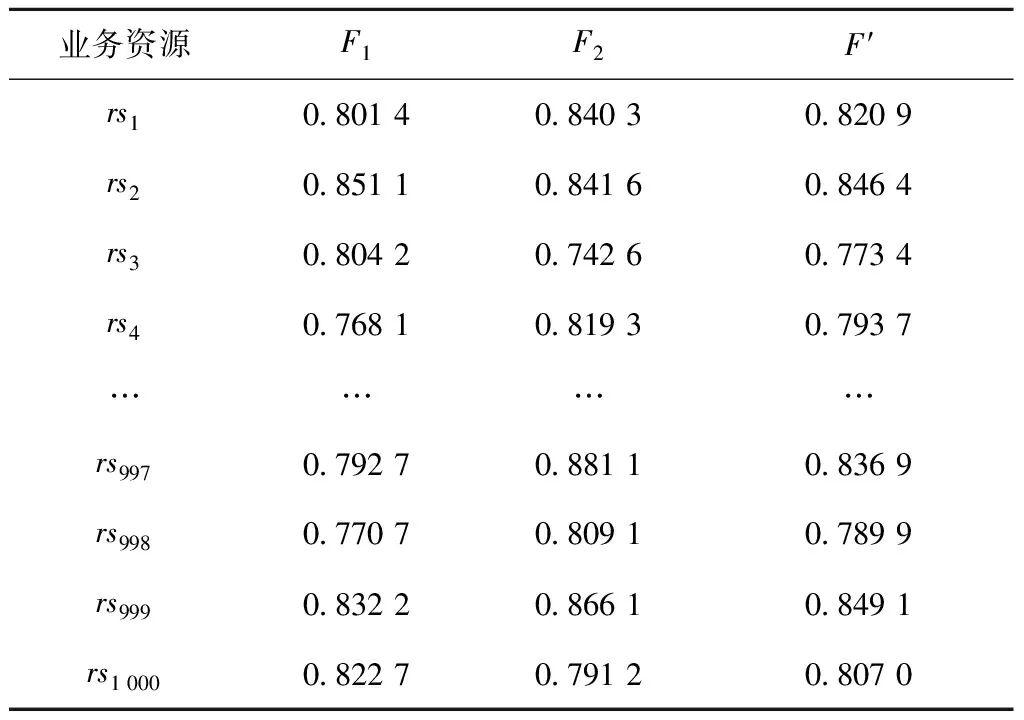
表7 不同维度匹配的满意度
分别对表7中不同维度匹配的满意度进行排序,得到配件数据资源的优劣,如表8所示。

表8 配件数据资源的排序结果
由表8可知,在F1排序中,rs2的满意度最高,该资源最能满足需求方的要求,但在F2排序中的顺序相对靠后,可能导致rs2的供给方不愿意与需求方开展配件资源业务协作;在F2排序中,rs997的满意度最高,该资源需求方的企业信用最能满足供给方的要求,但在F′排序中顺序相对靠后,可能导致需求方不愿意与rs997的供给方开展配件资源业务协作;在F′排序结果中,rs999的满意度最高,且在另外两类满意度排序中均处第2位,因此业务资源双边匹配能够很好地兼顾供需双方的要求,使供需双方协作的满意度达到最大,从而提升多服务价值上企业间的整体协作效果。
综合评价指标F是一种结合准确率和召回率的评价指标。F值可以反映双边匹配的综合能力,F值越大,其匹配的质量越高,因此本文引入综合评价指标评估BRBMM的性能。综合评价指标的计算公式为
(18)
式中:P为准确率;Nd为F′≥0.7的业务资源数量;Nv为F1≥0.7的业务资源数量;R为召回率;Na为所有的业务资源数量。
在匹配质量实验分析中,将本文提出的BRBMM分别与TMDM[7],SRMM[13],BPAM[19]进行对比。在相同的实验配置条件下,对同一个需求方发起的双边匹配请求重复执行10次,取其平均值进行对比,配件数据资源数量与F值的关系如图3所示。

由图3可见,随着配件数据资源的逐渐增多,相应的F值逐渐减少,可得二者之间的关系成反比例,同时得出BRBMM的F值高于另外3种模型,因此本文所提模型在多服务价值链环境下的匹配质量更优。
5 结束语
在多服务价值链环境下,为帮助企业快速精准地从纷繁复杂的海量信息资源中获取高质量有价值的信息,本文提出一种面向多服务价值链的BRBMM。该模型先构建供需双方的满意度评价指标体系,再处理供需双方的满意评价指标数据,最后求解多目标优化模型,使需求方获得的业务资源最合适且最有价值,同时最令供需双方满意。以汽车售后服务业务的配件数据资源为例,通过实验分析验证了所提模型的合理性与有效性。
未来主要的工作包括两方面:①进一步完善面向多服务价值链的BRBMM,提高供需双方的体验度;②将推荐算法融入BRBMM,通过收集需求方的特征数据为其推荐感兴趣的业务资源。
