基于高光谱成像技术的小麦籽粒品种鉴别方法研究
2021-05-26吴永清贺媛媛郭波莉巨明月张影全孙倩倩
吴永清 李 明 贺媛媛 郭波莉 张 波 巨明月 张影全 孙倩倩
(中国农业科学院农产品加工研究所;农业农村部农产品加工重点实验室,北京 100193)
小麦是重要的粮食作物之一,产量仅次于水稻位居第二位,是中国主要粮食作物之一[1]。小麦品种鉴别在作物育种、市场流通、粮食加工等领域均具有十分重要的意义。高光谱成像结合图像(形态、纹理等特征)和光谱信息,可同时快速、无损检测样品的物理(颜色、大小、形状和质地等)和内部组成成分的化学和分子信息(水分、脂肪、蛋白及其他氢键物质)[2],已广泛用于水稻[3,4]、玉米[5,6]、大豆[7,8]的鉴别研究,在实现小麦籽粒品种快速无损鉴别方面具有可行的理论基础。
近年来,国内外已有基于高光谱成像技术对小麦品种鉴别方面的研究报道,但仍处于初步探索阶段。Mahesh等[9]采集了加拿大西部种植的8个小麦品种籽粒的960~1 700 nm波长范围的高光谱信息,比较不同比例的训练集、测试集和验证集的建模效果,研究发现,模型性能随着训练集比例增大而提高。董高等[10]利用最小二乘-支持向量机(LS-SVM)和最小二乘判别(PLS-DA)算法对单粒小麦850~1 700 nm波长范围的高光谱信息建立分类模型,实现了强筋、中筋、弱筋3个单籽粒小麦类型之间的分类。丁秋[11]等采集了10个品种共500个小麦籽粒388~1 009 nm波长范围的高光谱图像,运用主成分分析法提取3个特征波长,提取特征波长下小麦籽粒图像的形态特征和纹理特征,应用贝叶斯(Bayes)判别分析法进行建模,训练集和预测集的整体正确判别率分别为98%和100%。张航等[2]基于400~1 000 nm和900~1 700 nm波长范围的高光谱信息建立了小麦品种的主成分分析-支持向量机(PCA-SVM)分类模型,结果发现900~1 700 nm波长范围建模效果优于400~1 000 nm,其中3个品种间种子分类正确率平均达到95%以上,4个品种间种子分类准确率在80%左右,6个品种间种子分类准确率在66%左右。Bao等[12]采集了5个小麦品种874~1 734 nm波长范围的高光谱信息,采用变量标准化算法(SNV)、多元散射校正(MSC)和小波变换(WT)等进行光谱预处理,应用主成分分析(PCA)、连续投影法(SPA)和随机森林(RF)提取特征波长,基于全波长和特征波长建立线性判别(LDA)、支持向量机(SVM)和极限学习机(ELM)分类模型。发现基于全波长的ELM模型性能最佳,训练集和预测集分别为91.3%和86.26%。目前高光谱成像技术应用于小麦籽粒品种鉴别的模型正确判别率、稳定性以及重现性等问题尚需要进一步的研究和探讨。
为明确高光谱成像技术对小麦籽粒品种鉴别的可行性和有效性,本研究利用高光谱成像技术采集小麦籽粒光谱和图像信息,优选不同部位光谱、预处理方法和特征波长提取方法;在此基础上,建立基于光谱信息、形态特征信息、光谱和形态特征信息结合的分类模型,构建小麦品种快速、无损、有效、稳定的鉴别技术。
1 材料与方法
1.1 实验材料
选取黄淮冬麦区的6个主栽品种:师栾02-1、济麦22、周麦27、藁优2018、郑麦366、矮抗58 的籽粒作为实验材料,同一品种各选100粒匀称、完好无损的籽粒作为实验样本,完成后将每种样本单独密封于标记好的自封袋保存。
1.2 实验方法
1.2.1 高光谱信息采集
实验所用仪器为高光谱图像采集系统(Hyperspec®VNIR-E),其有效光谱的范围为400~1 000 nm,共184个波段。采集高光谱图像信息时,小麦腹沟朝下,统一采集小麦籽粒背面的信息。
1.2.2 光谱信息和形态特征提取
运用ENVI软件中的ROI工具提取感兴趣区域和形态特征。在胚、胚乳部位各选择一个边长为20像素的正方形区域作为感兴趣区域(如图1所示),选择的胚、胚乳、胚和胚乳部位混合感兴趣区域的平均反射值作为样品的原始光谱信息。形态特征包含小麦籽粒长、宽和长宽比,其中长是小麦籽粒上距离最长的两端点之间长度的像素数,宽是小麦籽粒上垂直于长度两端点之间连线中最长线长度的像素数,长宽比是小麦籽粒长度和宽度像素数的比值。

图1 小麦籽粒不同部位ROI提取示意图
1.2.3 光谱数据分析方法1.2.3.1 光谱预处理和特征波长提取
本实验选取移动窗口平滑法(MA)、归一化(NL)、一阶求导(1stDer)、基线校正(BL)、变量标准化算法(SNV)5种方法对胚乳区域的原始光谱进行预处理,采用竞争性自适应重加权算法(CARS)和连续投影算法(SPA)进行特征波长提取,分别建立LDA、SVM和K最邻近(KNN)模型并进行预测,筛选最优的光谱预处理和特征波长提取方法。
1.2.3.2 样本集划分
6个小麦品种样本共600粒,根据Kennard-Stone算法按照3∶1划分训练集和预测集,训练集450粒小麦籽粒用于判别模型的建立,预测集150粒小麦籽粒用于判别模型的验证。
1.3 光谱数据分析软件
本研究采用ENVI 5.1、The Unscramber X 10.3、Matlab R2019b等软件进行光谱数据分析。
2 结果与分析
2.1 不同小麦籽粒部位光谱对建模效果的影响
由表1可知,基于胚乳和胚、胚乳部位混合光谱建立的LDA模型的预测集正确判别率均为79.3%,但基于胚乳部位光谱建立的SVM和KNN模型的预测集正确判别率均高于胚、胚乳部位混合光谱所建模型。因此,确定基于小麦胚乳部位光谱建立的模型性能最佳。故后续的研究均基于胚乳部位的光谱进行。

表1 基于不同小麦籽粒部位光谱建立的模型判别结果
2.2 不同光谱预处理对建模效果的影响
由表2可知,与基于原始光谱(RAW)建模效果相比,研究采用的大部分光谱预处理方法能提高LDA和SVM的建模效果,但只有4种方法或组合对KNN建模效果有提高作用。单一预处理方法整体上优于组合预处理方法,其中单一处理的1STDer最优,基于其处理的光谱建立的SVM模型训练集和预测集的正确判别率分别为83.6%和84.0%。因此,基于原始光谱和1STDer处理后的光谱进行后续特征波长提取方法筛选的研究。
2.3 不同波长提取方法以及全波长对小麦品种鉴别的影响
2.3.1 竞争性自适应重加权算法
CARS算法(设置蒙特卡罗采样次数N=100,五折交叉检验)在MatlabR2019b软件中运行的结果如图2所示,图2中表示为波长变量优选过程中各波长变量回归系数的变化趋势,“*”所对应的位置即为RMSECV值最小处对应波长变量子集最优,子集中分别包含了34和41个波长变量,即基于原始光谱和1STDer处理后的光谱进行CARS特征波长提取的特征波长分别为34和41个。
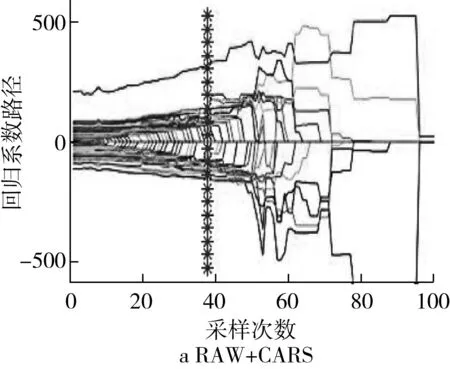
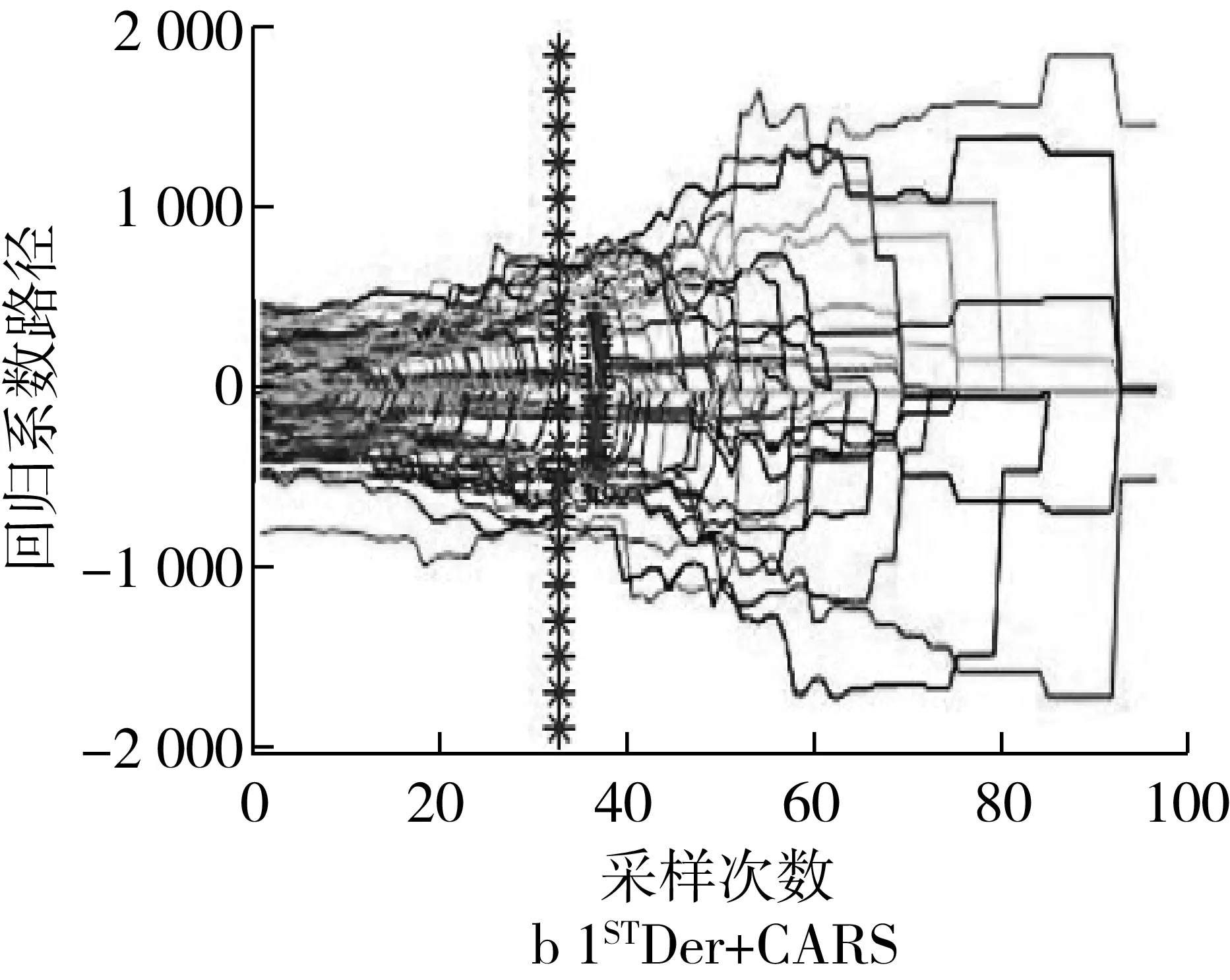
图2 CARS算法提取特征波长
2.3.2 连续投影算法
本研究采用SPA算法基于原始光谱和1STDer处理后的光谱进行特征波长提取,结果发现当特征波长数为33和39个时,RMSE值达到最小值分别为1.083 7和1.176 6,即基于原始光谱和1STDer处理后的光谱进行CARS特征波长提取的特征波长分别为33和39个。
2.3.3 判别模型的建立与预测分析
由表3可知,基于特征波长建立的模型的效果整体上优于全波长。SPA的降维程度高于CARS,但建模效果CARS优于SPA。由2.3.2可知,光谱1STDer预处理能提高建模的效果。但由表3可知,基于原始光谱进行特征波长提取的建模效果优于经过1STDer预处理的光谱,其中建模效果最佳的为RAW-CARS-LDA模型,其训练集和预测集的正确判别率均为84.7%。故采用RAW-CARS提取的特征波长的光谱进行后续的基于光谱信息、形态特征、二者结合建立的模型对小麦籽粒品种鉴别的影响研究。

表3 基于不同特征波长提取方法建立的模型判别结果
2.4 基于光谱信息、形态特征、二者结合建立的模型对小麦籽粒品种鉴别的影响
由表4可知,基于特征波长的光谱信息建立的模型中,LDA模型效果最佳,其训练集和预测集的整体正确判别率均为84.7%。基于形态特征建立的模型整体效果比基于特征波长的光谱信息建立的模型差,其中KNN模型最佳,其训练集和预测集的整体正确判别率分别为55.8%和50.7%。基于特征波长的光谱信息和形态特征结合建立的模型,其训练集和预测集的整体判别率分别为91.8%和86.0%,分类效果优于单一使用光谱信息或形态特征建模效果。因此,结合光谱信息和形态特征结合建立的LDA模型能够有效的实现小麦籽粒品种鉴别。
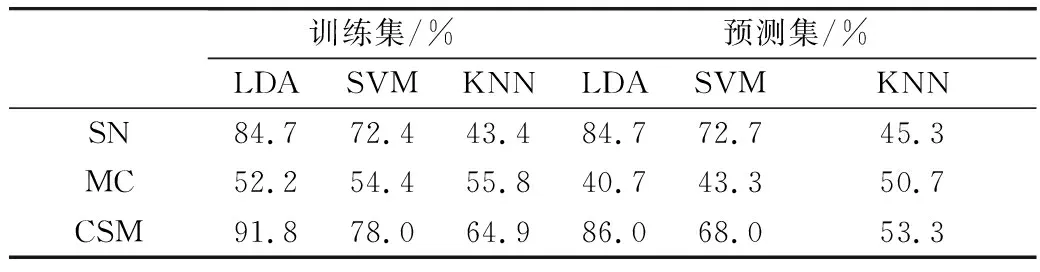
表4 基于光谱信息、形态特征、二者结合建立的模型判别结果
3 讨论
本研究比较了基于胚、胚乳、胚和胚乳混合部位光谱所建模型效果,发现胚乳部位光谱所建模型性能略优于胚部位以及胚和胚乳混合部位光谱,与董高等[10]的研究一致。这可能由于小麦籽粒胚和胚乳表面纹理不同所致,胚部位表面凹凸不平,反射光的不规律性使得胚区域的光谱数据存在一定随机误差,其光谱不能很好的反映胚区域的物质特性。此外,不同部位光谱所建模型性能的差异也可能由于小麦籽粒胚和胚乳部分化学成分不同。小麦籽粒胚部纤维含量高,而胚乳主要由蛋白和淀粉粒组成[13,14]。
不同预处理方法对模型的判别精度有较大影响,本研究比较了MA、NL、BL、1STDer、SNV对小麦籽粒光谱预处理的效果,其中经过1STDer预处理之后的模型判别效果最好。这可能由于本研究中的6个小麦品种的原始光谱波段差异小且中存在大量与样本自身性质无关的冗余信息,这会干扰到所建模型的判别精度和预测模型的效果,而1STDer能消除基线平移、背景的干扰、分辨重叠峰、提高分辨率和灵敏度[15]。Bao等[12]的研究发现,与原始光谱建立的小麦品种鉴别模型相比,WT、SNV、MSC 3种预处理方法对模型性能均没有提高作用。因此,应根据光谱特征选择适当的预处理方法,也突出了进行预处理方法筛选的重要性。
特征波长提取不仅可以简化小麦品种鉴别研究中模型结构,而且可以剔除不相关、低贡献的波长,提高运算速度,降低设备开发成本。CARS算法将每一个波长作为单独的个体,利用自适应重加权采样技术筛选出PLS模型中的回归系数绝对值大的波长,淘汰回归系数绝对值小的波长,并采用交叉验证选出PLS模型中均方根误差值最小的变量子集,即为最优波长变量子集[16]。SPA是一种采用前向选择特征波长的算法,通过SPA提取到的特征波长具有共线性小和冗余度低的性能,但却可以代表大多数样本的光谱信息[17]。本研究中SPA的降维程度高于CARS,但建模效果CARS优于SPA,因为经SPA法剔除了过多信息,其中包含了大量有用信息。CARS算法基于胚乳部位原始光谱提取了34个特征波长,仅用了全波长的18.5%波段,但训练集和预测集的正确判别率分别提高了6%和5.4%,说明CARS是基于高光谱技术的小麦品种鉴别研究有效的特征波长提取方法。而Bao等[12]研究采用SPA、主成分分析载荷(PCA loading)和随机蛙跳(RF)3种方法提取了全波长5%、18%、25%的波长,相比基于全波长的光谱建立的ELM模型的预测集正确判别率86.26%,基于SPA、PCA loading、RF 3种方法提取的波长建立的模型的正确判别率分别降低了15.72%、14.26%、3.02%。因此,应根据特定光谱选择适当的特征波长提取方法。
本研究基于特征波长的光谱信息和形态特征结合建立的模型,预测集正确判别率为86.0%,比单一使用光谱信息、形态特征所建LDA模型分别提高1.3%和45.3%,董高等[10]分别基于6个品种小麦籽粒的胚和胚乳光谱信息和形态特征结合建立的LS-SVM模型的正确判别率分别为98.89%和100%,比仅使用光谱信息建立的LS-SVM模型分别提高3.33%和1.11%。同是进行6个小麦品种的品种鉴别,本研究的判别正确率低于董高等[10]研究,而影响进一步提高正确率的原因可能在于:其一,采用的形态特征参数数量较少,本研究仅采用长、宽和长宽比3个参数,而董高等[10]的研究采用了小麦籽粒长、宽、长宽比、离心率、矩形度、圆形度、周长、面积、胚乳面积、胚面积以及二者面积比等12个参数;其二,光谱采集的波长范围不同,张航等[2]的研究表明900~1 700 nm波长范围所建模型的小麦品种鉴别效果优于400~1 000 nm波长范围所建模型。本研究采用的波长范围为400~1 000 nm,而董高等[10]采用的波长范围为850~1 700 nm。故后续研究可增加形态特征参数的数量以及将波长范围扩大至2 500 nm,以获得更多的化学成分的光谱信息,从而进一步提高本研究的6个小麦品种鉴别模型的正确判别率。
4 结论
本研究基于高光谱成像技术进行6个小麦品种的品种鉴别研究,得到以下结论。
基于胚、胚乳和胚、胚乳部位混合光谱所建模型中,胚乳部位的建模效果最佳,其训练集和预测集的正确判别率分别为78.7%和79.3%。
采用MA、NL、BL、1STDer、SNV 5种预处理方法以单一和组合的方法对光谱进行预处理,所建模型中,单一处理建模效果优于组合,其中1STDer效果最佳,其训练集和预测集的正确判别率分别为83.6%和84.0%。
利用CARS和SPA算法进行特征波长提取,CARS建模效果优于SPA,基于原始光谱进行特征波长提取的建模效果优于经过1STDer预处理的光谱,其中RAW-CARS-LDA建模效果最佳,其训练集和预测集的正确判别率均为84.7%。
基于特征波长的光谱信息和形态特征结合建立的LDA模型,分类效果优于单一使用光谱信息或形态特征信息建模效果,训练集和预测集的正确判别率分别为91.8%和86.0%。
