注意力孪生网络在生物医学文本相似性上的应用
2021-05-21安宏达李正光吴镝郑巍
安宏达,李正光,2,吴镝,郑巍
(1.大连交通大学 软件学院,辽宁 大连 116028;2.大连理工大学 计算机科学与技术学院,辽宁 大连 116023 )*
近年来,随着医学信息的快速发展积累了越来越多的医学文本,然而在这些庞大的数据中经常会有很多语义相近但文本描述却截然不同的句子,这无疑给医学研究带来很多不必要的麻烦.文本语义相似性评估成为解决这一问题的主要技术.
文本相似性,指的是对文本或句子之间相似程度的评价.最早的评估方法主要利用信息检索技术[1]等从文档中抽取文本结构,然后预测文本相似性.除此之外,还有词频共现自动评估算法[2]、单词(或字)与文本混合评估、短文本语义相似性抽取[3]等方法.这些方法都是通过检索或者神经网络的方法分别抽取两个句子的相似特征进行比较,但是这些方法只是单独抽取每个句子的相似特征,在抽取特征时没有考虑到两个句子间的影响.
孪生网络[4]通过两个共享参数的子网络同时抽取两个输入句子的语义特征对句子的相似性进行评估.不过,孪生网络结构在文本相似问题上虽然优于信息检索和词频共现的方法,但是它仍有很大的提升空间.注意力机制可以对孪生网络输出的两个语义特征再次加工,将与语义相关的特征放大,把无关的噪音缩小,这无疑可以提高预测的准确率.注意力机制主要可分为自注意力机制[5]和交互式注意力机制.自注意力机制可以将自身文本中有用的部分扩大,无用的部分缩小,以此让模型快速学习到有用的特征,其主要应用在文本分类[6]、命名实体识别等任务.交互式注意力机制则是增强两个句子间的相关语义特征,以提高两个句子间语义相似的部分.
1 实验方法
本文提出了一种基于注意力机制的孪生网络,网络结构如图1所示.整个网络结构可分为输入层、嵌入层、孪生网络层、注意力层和语义距离计算(图中的注意力层展示了自注意力机制和交互式注意力机制,这两个机制之间没有关系),本部分将主要针对这五个网络层进行介绍.

图1 基于注意力机制的孪生网络
1.1 实验数据与预处理
本文在实验中使用DBMI和SICK数据集:
(1)DBMI数据:DBMI评测中任务一“Clinical Semantical Textual Similarity”(简称ClinicalSTS)的数据集,是关于临床医疗文本的文本相似性评估数据.DBMI数据集包含训练集1400条,测试集412条.验证集255条.数据集中的标签为0~5之间的小数,标签中分数越大说明两个句子的语义相关性越大,反之则越小.
(2)SICK数据:SICK(Sentences Involving Compostional Knowledge)数据集将每个句子对及其相应分数作为一条数据,其中包含训练集4500条,测试集4805条以及试验集500条.数据集中的标签为1~5之间的小数,其余与DBMI数据相似.
在数据预处理方面为方便数据集转换,本文在实验中将DBMI与SICK的标签同比例缩小为0~1之间的小数.除此之外,由于SICK数据中训练集数量小于测试集数据的数量,我们对数据集进行了调整.最后实验中训练集6000条、验证集1235条、测试集2570条.
1.2 词向量嵌入模型
词向量(Word embedding)又被叫做词嵌入,是一种将词语或单词转化为数值向量(Vector)的过程.句子中的每个单词通过预训练被表示成一个实数值向量,再将同一个句子中的所有向量表示组合到一起成为一个可以表示句子语义特征的矩阵.相比较于其他的文本表示方法,词向量模型的向量表示所包含的语义信息更加丰富.因为实验数据为医学类数据,因此本文选用Pubmed 词向量,该工具使用对Pubmed上医学论文的标题和摘要进行训练得到.本文在实验中选用Pubmed 2018版400维的词向量.
1.3 孪生网络
孪生网络(Siamese network)是一种可以共享神经网络参数的网络框架,在这个框架内拥有两个共享参数并且结构相同的子网络.孪生网络结构主要应用于对输入序列的相似性预测,两个子网络的输入X与Y分别对应预测相似性的两个序列.通过子网络训练捕捉语义信息得到语义特征G(X)与G(Y),而语义特征就是判断两个句子语义相似性的依据.
对于孪生网络的子网络,由于选择的数据多属于像临床医学文本这样的长篇幅句子,而循环网络在处理长度大的序列效果更好.本文选择的孪生网络框架子网络就是在循环网络中表现较好的Bi-LSTM(Bi-directional Long Short-Term Memory)网络.Bi-LSTM由前向LSTM和后向LSTM组成,LSTM(Long Short-Term Memory)模型结构可分为遗忘门,记忆门和输出门,模型通过遗忘门将无用信息丢弃,通过记忆门保存有用信息,最后由输出门输出结果,具体公式如下:
(1)
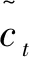
1.4 注意力机制
孪生网络的两个输出虽然可以分别表示两个输入句子的语义,但是由于句子中往往会存在很多的噪音,从而导致结果并不理想.为解决这一问题,本文引进注意力机制(Attention mechanism).注意力机制可以对孪生网络输出的两个语义特征再次加工,通过训练注意力权重(Attention weight)扩大语义相关的部分,减小与语义无关的噪音,将噪音对语义特征的影响降到最低.注意力机制主要可分为自注意力机制(Self attention mechanism)和交互式注意力机制(Interactive attention mechanism).本文在实验中使用了一种自注意力机制的网络和三种交互式注意力机制的网络.其中的三种交互式注意力机制分别为交互式注意力网络(Interactive attention network)、混合交互式注意力网络(Merge interactive attention network)、单独交互式注意力网络(Single interactive attention network).
1.4.1 自注意力网络(Self attention network)
自注意力网络是通过计算输入X=[x1,x2,x3,…,xi](i∈[1,N])中每一个单词xi对句子中其它单词的权重α,来预测xi在X中的影响程度,其中α=[α1,α2,α3,…,αi](i∈[1,N]),N表示输入X的长度,权重αi的计算公式如下:
(2)
其中,f表示分数计算函数,计算公式如下:
f(xi)=tanh(xi·W+b)
(3)
式中,tanh表示激活函数,W表示权重矩阵,b表示偏执项,xi表示分数计算函数f的输入.
最后,将得到ci=αixi,而自注意力网络输出C表示如下:
(4)
C就是自注意力网络的输出,表示输入序列X中的每一个单词按照影响程度放大或缩小后的结果.
1.4.2 交互式注意力网络
交互式注意力网络[8]计算过程与自注意力网络相似.X=[x1,x2,x3,…,xi](i∈[1,N])表示句子A的序列,Y=[y1,y2,y3,…,yi](i∈[1,N])表示句子B的序列,α是X的注意力权重,β是Y的注意力权重:
(5)
f(xi,yavg)和f(yi,xavg)分别表示序列X和Y的分数计算函数,计算公式如下:
(6)
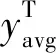
(7)
Cx是序列X的注意力网络输出,Ty是序列Y的输出,最后将Cx和Ty放入到曼哈顿距离公式中计算两个序列X与Y的差异.
1.4.3 混合交互式注意力网络
混合交互式注意力网络相比于交互式注意力网络(IAN)不再区分序列X和Y的注意力权重,而是两个序列X和Y分别乘以相同的混合注意力权重,这种乘以相同的权重矩阵的方法可能会增强两个句子间的语义关联度.具体运算公式如下:
(8)
其中,Wx和Wy表示X和Y的权重矩阵,Wmerge表示X和Y混合特征的权重矩阵,bmerge为偏执项.
1.4.4 单独交互式注意力网络
在实验中,由于两个输入序列的分数计算函数相似,在计算序列差异上会有影响,单独交互式注意力网络将序列X乘以序列Y的自注意力权重,反之亦然.其余计算与自注意力网络相同.
(9)
其中,β是序列Y的自注意力权重,α是序列X的自注意力权重,Cx和Ty分别表示序列X和序列Y的单独交互式注意力网络输出.
1.5 语义距离计算
在得到经过注意力机制增强后的两个语义表示后,用曼哈顿距离公式计算两个句子的语义距离,并以此作为句子对语义相似性的依据.
2 实验结果与讨论
本文实验使用Ubuntu 18.04系统,Python 3.7.3,tensorflow 1.14.0以及Keras 2.1.5,具体试验参数如表1所示.
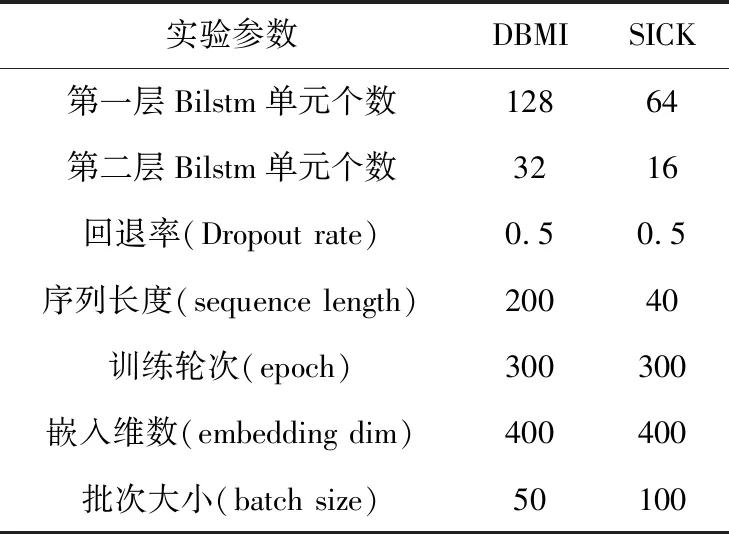
表1 实验参数设置
实验中所用参数如表1所示,参数因为DBMI数据集和SICK数据集的差异性而略作调整.由于SICK数据中的句子普遍比DBMI数据短,所以降低了序列长度和孪生网络子网络这个两层Bilstm的单元(Units)个数.同时因为SICK数据中的训练集数量明显高于DBMI数据,所以提高了每一批次的大小(batch size).
2.1 DBMI数据注意力网络实验结果比较
在本部分将使用DBMI数据对方法中的四种注意力网络进行实验结果对比,其中的孪生网络(SN)为实验的基线方法(孪生网络中的子网络采用两层Bilstm网络),其余方法分别为孪生网络加自注意力网络(SN-SAN)、孪生网络加交互式注意力网络(SN-IAN)、孪生网络加混合交互式注意力网络(SN-MIAN)、孪生网络加单独交互式注意力网络(SN-SIAN).
表2是对四种注意力网络的试验结果对比,评价方法分别为皮尔森相关系数(Pearson)、斯皮尔曼相关系数(Spearman)和均方差(MSE).通过
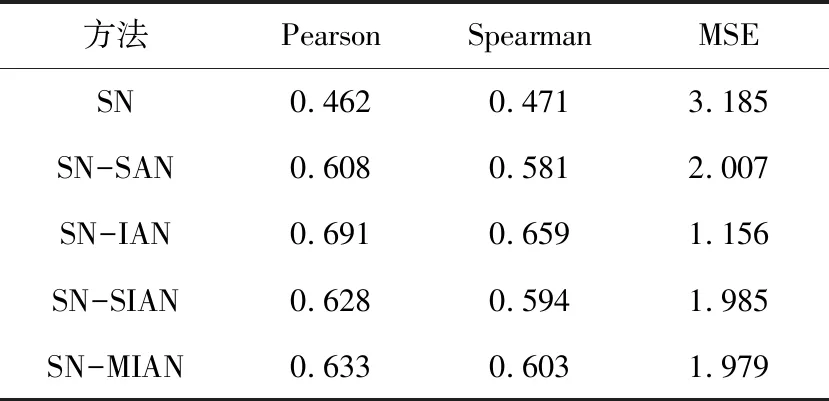
表2 DBMI注意力网络结果对比
对表中数据分析可知,注意力机制对实验结果有很大提升,本文提出的孪生网络加交互式注意力网络(SN-IAN)要优于其它方法,并且相比于孪生网络(SN)皮尔森相关系数提升了0.27.
2.2 SICK数据方法比较
因为DBMI数据暂时还没有发布评测结果,所以用SICK数据与其他方法比较.目前使用SICK数据的文章有很多,我们在其中选择pos-LSTM-n[9]、Multi-Perspective CNN[10]、Siamese GRU Model[11]这三种方法与我们的方法做对比.
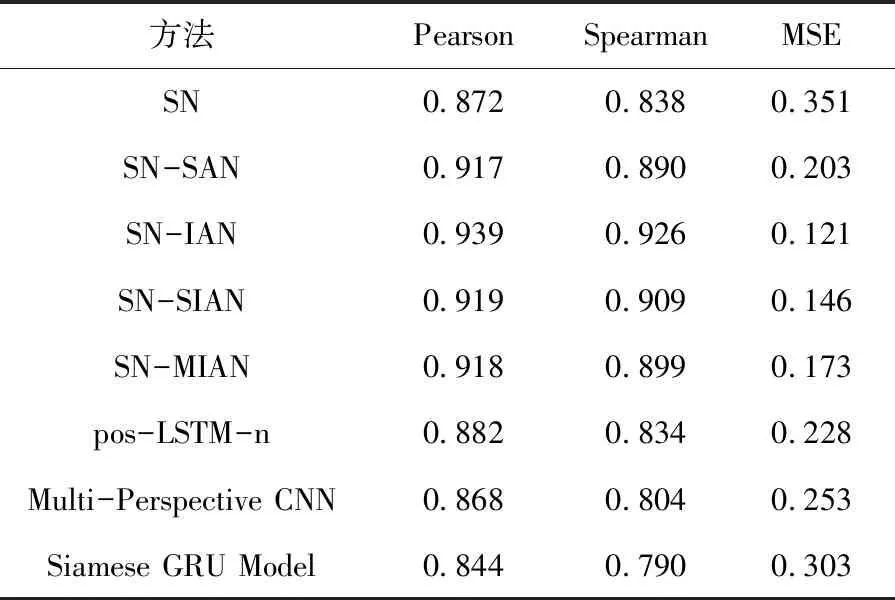
表3 SICK数据其它方法结果对比
对表3的结果分析可知,孪生网络加注意力机制的结果要优于使用SICK数据的其它方法,而本文提出的SN-IAN优于其它方法,并且在皮尔森相关系数上的结果比SN高0.07,证明我们提出的方法是有效的. 此外,本文所使用的孪生网络(SN)的内层网络为BiLSTM且皮尔森系数高于使用门控循环单元(GRU)作为内层网络的孪生网络模型(Siamese GRU Model),证明BiLSTM网络作为孪生网络的内层网络要优于GRU网络.
3 结论
通过实验结果对比以及数据分析,可以得出以下结论.
(1)对孪生网络输出的语义特征用注意力网
络进行加工处理对于孪生网络的实验结果有提升作用且效果很大;
(2)在文本相似性任务中,交互式注意力机制的效果要比自注意力机智的效果更好;
(3)在交互式注意力机制中,交互式注意力网络要比混合交互式注意力网络与单独交互式注意力网络效果更好.
