基于LSTM神经网络的人体动作识别
2021-05-13杨世强杨江涛王金华李德信
杨世强,杨江涛,李 卓,王金华,李德信
基于LSTM神经网络的人体动作识别
杨世强,杨江涛,李 卓,王金华,李德信
(西安理工大学机械与精密仪器工程学院,陕西 西安 710048)
人体动作识别为人机合作提供了基础支撑,机器人通过对操作者动作进行识别和理解,可以提高制造系统的柔性和生产效率。针对人体动作识别问题,在三维骨架数据的基础上,对原始三维骨架数据进行平滑去噪处理以符合人体关节点运动的平滑规律;构建了由静态特征和动态特征组成的融合特征用来表征人体动作;引入了关键帧提取模型来提取人体动作序列中的关键帧以减少计算量;建立了以LSTM神经网络为基础的Bi-LSTM神经网络的人体动作分类模型,引入注意力机制以及Dropout进行人体动作分类识别,并对神经网络的主要参数采用正交试验法进行了参数优化;最后利用公开数据集进行动作识别实验。结果表明,该模型算法对人体动作具有较高的识别率。
动作识别;融合特征;LSTM神经网络;注意力机制;Dropout
近年来人工智能技术取得了长足发展,已逐渐地应用于机械制造等领域。动作识别是人机交互的基础,通过人机交互合作可以提高人机合作制造系统柔性,对制造业发展有积极促进意义。动作识别也可应用于智能安防、智能家居、智能医疗等领域。
特征提取是动作识别的基础,主要方法有基于深度图像和基于骨架数据的特征提取2种方法。Kinect深度相机可以采集到图像的深度信息,唐超等[1]提出了基于深度图像特征的人体动作识别方法,使用方向梯度直方图、时空兴趣点和人体关节位置3种特征进行分类识别。许艳等[2]将深度特征与骨骼特征相结合,用多模型概率投票进行人体动作识别。基于骨骼点特征描述法的动作识别数据量小、鲁棒性好。文献[3]提出局部聚集描述子向量算法和分类池模型,利用骨骼关节进行分类。田联房等[4]提出一种基于人体骨架序列使用模板匹配检测异常行为,再利用动态时间规整识别的算法。YANG等[5]使用深度优先树遍历顺序重新设计骨骼表示,提出双分支注意结构,实现对不可靠联合预测的过滤。ZHANG等[6]提出包括关节间距离和关节到关节所构成平面距离等几何特征来描述运动。LIU 等[7]使用不同颜色像素点在图像平面上的移动轨迹表示骨架关节点序列时空变化。
在提取有效特征的基础上,采用有效的分类器进行动作分类。ZOLFAGHARI等[8]提出高效卷积网络,结合采样策略,利用帧间冗余性快速分类,且网络模型的层数较少。DONAHUE等[9]利用融合长时递归层和卷积层的长时递归卷积网络(long-term recurrent convolutional,LRCN)进行人体动作识别。SONG等[10]介绍了基于长短记忆网络(long short-termmemory network,LSTM)的端到端的时空注意力模型,对关节点和不同帧赋予不同关注度。沈西挺等[11]结合二维卷积神经网络、三维卷积神经网络和长短期记忆神经网络用于动作的分类。虽然诸多的学者都取得了一定的研究成果,但动作识别的准确性仍然有待提高。
本文基于三维骨架数据,构建了由静态特征和动态特征组成的融合特征;建立了基于LSTM神经网络的动作识别模型,引入注意力和Dropout机制提高了识别率;最后使用正交试验法对神经网络参数进行了优化。
1 人体动作的特征描述
1.1 基于人体3D骨架信息
使用Kinect深度摄像机,采集人体20个骨骼关节点的三维坐标信息,图1(a)为简化人体骨架模型。为不影响动作完整性的同时降低计算量,从Kinect相机采集的20个关节点中选取了对人体动作影响较大且具有明显变化的13个关节点进行特征的构建,分别为:头、锁骨、左肩、右肩、左手肘、右手肘、左手腕、右手腕、腰、左膝盖、右膝盖、左脚踝、右脚踝。经过选取的人体骨架模型如图1(b)所示。
1.2 人体骨架3D数据的去噪
在一般情况下,人体在运动时,身体所有的关节点随时间的变化在空间中应该是光滑曲线,不应该存在明显的突变点。但原始数据在采集过程中难免会因为干扰原因产生噪声,采用均值滤波算法对原始的3D骨骼数据进行平滑处理,消除所采集数据中的突变点,符合人体关节点运动的平滑规律。
针对骨骼数据采用均值滤波算法,选取一个关于时间的窗口,对于某时刻数据,滤波后的值是前面一段时间与该时刻后面一段时间数据总和的平均值。原始骨骼数据的某一点空间3个维度中的维度滤波过程的计算式为
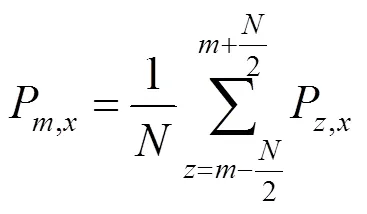
1.3 人体动作特征表示
从人体动作序列中提取合适的特征描述人体运动状态是人体动作识别的关键问题。人体3D骨骼关节点描述的人体动作差别是通过其关节点相对位置变化来反应的。由于用原始关节点数据描述人体动作是非常抽象的,而从运动序列中提取关节点的静态和动态特征组成的融合特征可以更形象地描述人体的动作。人体动作视频通常由一系列帧完成,静态特征即建立在每个帧上的特征。静态特征由肢体夹角和相对距离构成,肢体夹角指在某一帧内,2个肢体之间形成的夹角,此特征可以非常清晰地描述人体的姿态。肢体夹角选取了人体运动时具有明显变化的11个角度进行计算,将肢体视作一个向量,从某一关节点指向另一关节点,夹角2由向量2,3和2,9构成(图1(b))。肢体夹角为

其中,为11个肢体夹角,=1,2,···,11;为第一个肢体向量;为第二个肢体向量。基于此,人体的一个动作可以表示为

构建相对距离时可选取影响人体运动身体变化较大的8个关节点,即左手肘、右手肘、左手腕、右手腕、左膝盖、右膝盖、左脚踝、右脚踝。通过计算这8个关节点与腰关节点之间的距离,可得8组距离d,9,=4,5,7,8,10,11,12,13,代表8个关节点的编号。考虑到不同个体的身高差异性,采取归一化思想,对得到的8组距离统一除以锁骨关节(编号2)与腰关节(编号9)之间的距离2,9,以最大可能的消除人体身高差异,具体计算为

其中,,9为8个关节点与腰关节点间消除身高差后的距离。d,9为消除身高前的距离,腰关节点与锁骨关节点之间的距离取决于不同个体。这样,基于相对距离特征,人体的一个动作可以表示为

在静态特征的构建中,虽然实现了对每一帧动作的表述,但是对于近邻帧之间的变化量却无法表达,使用动态特征,如关节动能和肢体夹角的角加速度等,可以更加有利地进行人体动作的分类。
关节动能特征描述选取人体骨架模型中人体动作时信息贡献较大的13个关节点(图1),根据动作序列中相邻2帧的数据,关节动能的计算为

其中,E,t为第个关节点第+时刻与第时刻2帧之间的动能,=1,2,···13,为2帧之间的时长;m为动能计算公式中的系数,可视为常数;(,,)为关节点在三维空间中的坐标值。基于关节动能特征,人体的一个动作可以表示为

由于动态特征是基于原始数据2帧之间计算得出的,因此,动态特征相比静态特征在时间维度上少一个。
肢体夹角的角加速度特征构建中,同样取与肢体夹角构成中相同的11个角度,=1,2,···11,加速度特征基于这11个角度进行建立。肢体夹角的角加速度特征计算为

其中,,t为第个夹角第+时刻与第时刻2帧之间在动作过程中的角加速度;为2帧之间的时长;,t为第个肢体夹角在第时刻的角度。基于肢体夹角的角加速度特征,人体的一个动作可以表示为

基于骨架模型简化,融合静态特征和动态特征使得原始骨骼数据中的60维数据降低为由11个肢体夹角、8个重要关节点的相对距离、人体模型中所有13个关节点的关节动能以及11个肢体夹角的角加速度构成的43维,在原始动作特征最大程度保留的情况下,降低了数据维度。在4个人体动作特征完成后,进行特征融合,即将静态特征中的第一帧舍弃以达到与动态特征相同的帧数。基于静态和动态特征组成的融合特征,人体的一个动作就可以表示为

1.4 关键帧提取模型
关键帧是原始动作序列中能够反映动作内容的帧。在实际中,人体的动作序列通常由很多帧构成,在动作识别中,这些帧对识别的贡献率并非相同。因此,需剔除对一个动作序列变化不明显的帧,在提高动作识别的准确率的同时减少计算量。



最终的人体动作关键帧提取模型将上述2部分进行合并相加,可得

其中,为13个关节点;为11个夹角;和为上述2项的权重系数;E,t为第帧的第个关节点的动能;a,t为第帧的第个夹角的角加速度值。
接下来将人体的每个完整动作序列中的帧通过以下条件进行约束筛选,筛选原则为

其中,max为一个序列动作中计算得出的最大加权求和值;min为最小的加权求和值;e为常数。在计算时,max与min均是针对某一个动作序列中的数据进行筛选,当进入下一个动作序列后,根据其数据的不同,重新计算max和min。通过该方法,将所有的人体动作序列筛选一遍,可得每个动作序列中符合要求的帧。
2 基于LSTM的人体动作识别
在人体动作识别特征构建的基础上,首先搭建LSTM神经网络分类器进行人体动作识别分类,随后再构建Bi-LSTM神经网络分类器,引入注意力机制和Dropout来完善优化网络结构与性能,进一步提高识别率。
2.1 基于LSTM的人体动作识别
使用LSTM神经网络进行识别分类的网络输入为2个静态特征和2个动态特征组成的融合特征,利用训练集训练得到合适的网络参数,再对测试集进行识别分类。图2搭建的是基于LSTM神经网络人体动作识别训练模型。

图2 基于LSTM的动作识别模型
网络输入的是由所提取的静态和动态特征融合的4个特征,每个人体动作特征是一个43维数据,数据长度因每个动作的帧数不同而不同。在输入前,为了便于处理,统一将每组用于训练或测试的数据进行等长处理,即按照每组中序列最长的序列对剩余的序列进行补零操作。在每个时间帧中,输入网络的数据是一个43维的向量。随后,通过LSTM层的计算,将中间值送入到输出层,输出层所使用的为Softmax函数,对该动作进行判断,输出属于每个动作标签的概率,对应概率值最高的即为网络最终的输出类别。
LSTM神经网络的前向计算过程如下:
根据LSTM输入的人体动作数据,时刻遗忘门为


时刻输入门i为

其中,为输入门权重矩阵;为输入门的偏置项。
时刻长期记忆状态为


时刻输出门o为

其中,为输出门权重矩阵;b为其偏置。
最终可得LSTM网络的时刻输出值为

2.2 Bi-LSTM神经网络
LSTM神经网络只能进行单向学习,而Bi-LSTM是LSTM的改进型,将前向及后向连接到同一输出。Bi-LSTM神经网络结构由一个向前和一个向后传播的LSTM构成,正向与反向无相互连接,就实现了2个相互独立的隐藏层之间信息数据的双向传播。正因为此,使得其对于信息的提取学习相较于LSTM神经网络更加的全面。
图3为基于Bi-LSTM神经网络的人体动作识别结构主体模型。图中,Bi-LSTM神经网络的正向及反向LSTM的单元结构与原理相同。Bi-LSTM将2层的LSTM输出通过下式融合,再通过Softmax函数得出识别结,即



图3 基于Bi-LSTM动作识别模型
2.3 注意力机制
动作识别中,人体所有参与模型建立的关节点都对动作的识别分类产生着影响,采取注意力机制对这些关节点的重要性进行评判,突出人体动作特征中的重要信息,降低了对于识别分类不明显数据的关注度。注意力机制通过加权求和,从而找出对动作识别最重要的关节点,提升整个识别网络模型的计算效率。
特征提取中,得到的人体动作序列是一个43帧数的矩阵形式,在识别中将动作帧统一按照最长处理。针对于网络输出的个特征向量,按照下式,变换后的向量ʹ为

其中,为调整前的特征向量;为权重,在注意力机制中,重点为计算出合理的。首先计算得分值Score,即
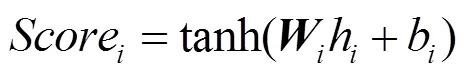
其中,和b分别为权重和偏置,接下来将得到的个得分值Score, (=1,···,),送入一个Softmax函数,得到最后的权重值,即

2.4 Dropout机制
在人体动作识别模型的训练过程中,当训练样本较少时容易出现过拟合,有必要对网络使用Dropout防止过拟合来实现正则化效果。
对神经网络输入的人体动作特征数据,输出为,首先随机删除神经网络隐藏层中的一些神经元,输入层以及输出层的神经元保持不变;然后输入动作特征数据,数据通过神经网络向前传播;再将网络的损失值进行反向传播,在所有的训练样本中的一部分执行完此过程后,并在保留的神经元上再进行参数的更新。重复此过程,恢复之前去掉的神经元,再次从隐藏层随机选择一些神经元进行删除,记录删除神经元参数,再进行部分样本的训练。
3 实验仿真与分析
用MSR Action 3D及UTKinect Action 3D 2个人体动作数据库对上述模型的可行性进行实验验证。实验环境配置为:Intel i5-3337U 1.8 GHz,4 G内存,Windows7 64位系统。实验仿真使用基于TensorFlow 1.9.0的框架,编程语言使用Python 3.5及MATLAB R2017b实现。
3.1 MSR Action 3D数据库实验与分析
对于MSR Action 3D数据库划分为AS1,AS2和AS3 3个组,采取3种验证方法对本文算法进行评估,Test One取所有人做的1/3动作数据为训练集,其余2/3为测试集;Test Two取所有人做的2/3动作数据为训练集,其余1/3为测试集;Cross subject test 为交叉验证,取1/2的实验对象为训练集,1/2的实验对象为测试集。在LSTM神经网络的人体识别模型中,参数设置:学习率为0.001,=0.001,模型迭代次数为1 000,batchsise为5,网络输入节点为43,隐藏层节点为80。
图4是在MSR Action 3D数据库的AS1数据集中,单独使用Test One测试方法得到的肢体夹角、相对距离、关节动能和肢体夹角的角加速度时的识别结果,红色为正确的动作类别,蓝色为识别的动作类别。
从上述结果得出4个动作特征的识别率分别为52.59%,60.74%,83.70%和82.22%,2个动态特征识别率远高于2个静态特征识别率,但单一使用动态特征也无法得到很高的识别率,有必要进行多特征融合进行动作识别。
图5为AS1组中进行关键帧提取与未进行关键帧提取的对动作识别率的影响。识别的最终结果使用混淆矩阵图进行表示,图中在对角线上为得到正确识别分类的人体动作,反之,未在对角线上的为错误分类的动作类别。在未进行关键帧提取的动作数据中分类正确识别率为90.37%,进行关键帧提取后的动作正确识别率有所提高,为91.85%。


图4 4个特征的识别结果((a)肢体夹角的识别结果; (b)相对距离的识别结果;(c)关节动能的识别结果; (d)肢体夹角的角加速度的识别结果)

图5 关键帧提取前后的识别效果对比((a)未进行关键帧提取的动作识别;(b)关键帧提取后的动作识别)
表1为动作特征数据在LSTM与基于Bi-LSTM神经网络并加入注意力机制以及Dropout后的识别结果对比。该实验除引入的Dropout参数外,其余参数设置与前保持一致。可以看出,加入Bi-LSTM神经网络注意力机制以及Dropout后,识别率有所提高。

表1 MSR Action 3D数据库LSTM与Bi-LSTM+Attention以及Dropout网络识别率对比(%)
表2为对MSR Action 3D数据库3个分组数据集中的AS1组、AS2组和AS3组使用Bi-LSTM+ Attention网络以及Dropout进行识别分类,得到的结果。平均识别率为89.15%。
3.2 正交试验法
实验中发现神经网络参数设置的不同对于人体动作最终识别率影响较大,有必要对于神经网络的主要参数进行优化,以获得良好的动作识别分类效果。本文采用正交试验法对Bi-LSTM+Attention+ Dropout神经网络中的3个主要参数:学习率、批量数以及隐藏层节点数进行优化。正交试验的因素水平见表3。

表2 MSR Action 3D数据库三组数据识别率对比(%)

表3 试验的因素与水平
根据表3中的各因素所取的水平设计正交试验(每种因素在不同的水平下),试验结果见表4。

表4 网络参数试验及结果
采用直观分析法,根据25次正交实验的结果计算得出125次全面实验中的最优参数组合。通过计算可知,当人体动作识别网络中的3个主要参数学习率、批量数以及隐藏层单元的神经元数量在A4B2C3时,即当3个参数分别取0.005 0,10和80时,动作识别率最高为95.56%。
3.3 优化结果与分析
经正交试验法优化3个参数后,再对MSR Action 3D数据库进行实验,动作识别分类结果与其他现有人体动作识别分类算法进行对比,见表5。

表5 MSR Action 3D数据库参数优化后识别率与其他算法对比(%)
从实验结果可以看出,对神经网络的学习率、批量数以及隐藏层单元的神经元数3个参数进行优化后,基于Bi-LSTM+Attention+Dropout神经网络取得了较高的识别率,在MSR Action 3D数据库中的9组实验中,有4组识别率高于相比的3种方法,平均识别率达到92.64%,高于其余3种86.82%,90.78%和92.16%,而在交叉验证的3组实验中,平均识别率达到86.97%,高于相比的4种74.67%,78.97%,81.23%和85.47%。UTKinect Action 3D数据库中也取得了95.96%的识别率,表明深度学习算法具备提取人体动作特征深层次特征的能力,有利于动作识别。
在UTKinect Action 3D数据库中,使用优化后的参数对人体动作进行重新实验,得到的最终识别率与其他人体动作分类算法的对比见表6。由于本文采用的是深度学习算法,其对于数据量的要求较大,而本文数据有限,故对识别率有一定影响。

表6 UTKinect Action 3D数据库识别率与其他算法对比(%)
4 结 论
本文基于人体三维骨架模型,融合静态特征与动态特征,构成动作特征描述方法,经关键帧提取模型对动作序列关键帧进行筛选。建立了基于LSTM神经网络的人体动作识别模型,针对LSTM神经网络在人体动作分类中存在的不足,使用基于Bi-LSTM神经网络的分类器,并引入注意力机制以及Dropout可进一步提高对于人体动作特征的识别性能。通过对神经网络主要参数使用正交试验法进行优化,使得基于Bi-LSTM+Attention+Dropout神经网络的分类器相对于LSTM神经网络分类器有更加优异的表现。
[1] 唐超, 王文剑, 张琛, 等. 基于RGB-D图像特征的人体行为识别[J]. 模式识别与人工智能, 2019,32(10): 901-908. TANG C, WANG W J, ZHANG C, et al. Human action recognition using RGB-D image features[J]. Pattern Recognition and Artificial Intelligence, 2019, 32(10): 901-908 (in Chinese).
[2] 许艳, 侯振杰, 梁久祯, 等. 深度图像与骨骼数据的多特征融合人体行为识别[J]. 小型微型计算机系统, 2018, 39(8): 1865-1870. XU Y, HOU Z J, LIANG J Z, et al. Human action recognition with multi-feature fusion by depth image and skeleton data[J]. Journal of Chinese Computer Systems, 2018, 39(8): 1865-1870 (in Chinese).
[3] CARBONERA LUVIZON D, TABIA H, PICARD D. Learning features combination for human action recognition from skeleton sequences[J]. Pattern Recognition Letters, 2017, 99: 13-20.
[4] 田联房, 吴啟超, 杜启亮, 等. 基于人体骨架序列的手扶电梯乘客异常行为识别[J]. 华南理工大学学报: 自然科学版, 2019, 47(4): 10-19. TIAN L F, WU Q C, DU Q L, et al. Recognition of passengers’ abnormal behavior on the escalator based on human skeleton sequence[J]. Journal of South China University of Technology: Natural Science Edition, 2019, 47(4): 10-19 (in Chinese).
[5] YANG Z Y, LI Y C, YANG J C, et al. Action recognition with spatio–temporal visual attention on skeleton image sequences[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2019, 29(8): 2405-2415.
[6] ZHANG S Y, YANG Y, XIAO J, et al. Fusing geometric features for skeleton-based action recognition using multilayer LSTM networks[J]. IEEE Transactions on Multimedia, 2018, 20(9): 2330-2343.
[7] LIU M Y, LIU H, CHEN C. Enhanced skeleton visualization for view invariant human action recognition[J]. Pattern Recognition, 2017, 68: 346-362.
[8] ZOLFAGHARI M, SINGH K, BROX T. ECO: efficient convolutional network for online video understanding[M]// Computer Vision – ECCV 2018. Cham: Springer International Publishing, 2018: 713-730.
[9] DONAHUE J, HENDRICKS L A, GUADARRAMA S, et al. Long-term recurrent convolutional networks for visual recognition and description[J]. 2015 IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2015: 2625-2634.
[10] SONG S, LAN C, XING J. An end-to-end spatio-temporal attention model for human action recognition from skeleton data[C]//Conference on Artificial Intelligence. San Francisco: AAAI, 2017: 4263-4270.
[11] 沈西挺, 于晟, 董瑶, 等. 基于深度学习的人体动作识别方法[J]. 计算机工程与设计, 2020, 41(4): 1153-1157. SHEN X T, YU S, DONG Y, et al. Human motion recognition method based on deep learning[J]. Computer Engineering and Design, 2020, 41(4): 1153-1157 (in Chinese).
[12] LI W Q, ZHANG Z Y, LIU Z C. Action recognition based on a bag of 3D points[C]//2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition - Workshops. New York: IEEE Press, 2010: 9-14.
[13] XIA L, CHEN C C, AGGARWAL J K. View invariant human action recognition using histograms of 3D joints[C]//2012 IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops. New York: IEEE Press, 2012: 20-27.
[14] CIPPITELLI E, GASPARRINI S, GAMBI E, et al. A human activity recognition system using skeleton data from RGBD sensors[EB/OL]. [2020-06-21]. http://www.hindawi.com/ journals/cin/2016/4351435/.
[15] 杨世强, 罗晓宇, 李小莉, 等. 基于DBN-HMM的人体动作识别[J]. 计算机工程与应用, 2019, 55(15): 169-176. YANG S Q, LUO X Y, LI X L, et al. Human action recognition based on DBN-HMM[J]. Computer Engineering and Applications, 2019, 55(15): 169-176 (in Chinese).
[16] NÚÑEZ J C, CABIDO R, PANTRIGO J J, et al. Convolutional Neural Networks and Long Short-Term Memory for skeleton-based human activity and hand gesture recognition[J]. Pattern Recognition, 2018, 76: 80-94.
[17] VEMULAPALLI R, ARRATE F, CHELLAPPA R. Human action recognition by representing 3D skeletons as points in a lie group[C]//2014 IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2014: 588-595.
[18] LIU J, SHAHROUDY A, XU D, et al. Spatio-temporal LSTM with trust gates for 3d human action recognition[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2018, 40(12): 3007-3021.
[19] ANIRUDH R, TURAGA P, SU J Y, et al. Elastic functional coding of human actions: From vector-fields to latent variables[C]//2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). New York: IEEE Press, 2015: 3147-3155.
[20] WANG C Y, WANG Y Z, YUILLE A L. Mining 3D key-pose-motifs for action recognition[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). New York: IEEE Press, 2016: 2639-2647.
[21] ZHU Y, CHEN W B, GUO G D. Fusing spatiotemporal features and joints for 3D action recognition[C]//2013 IEEE Conference on Computer Vision and Pattern Recognition Workshops. New York: IEEE Press, 2013: 486-491.
Human action recognition based on LSTM neural network
YANG Shi-qiang, YANG Jiang-tao, LI Zhuo, WANG Jin-hua, LI De-xin
(School of Mechanical and Instrumental Engineering, Xi’an University of Technology, Xi’an Shaanxi 710048, China)
Human action recognition provides the basic support for human-computer cooperation. Robots can enhance the flexibility and production efficiency of manufacturing system by recognizing and understanding the operator’s action. To resolve the problem of human motion recognition, the original 3D skeleton data was smoothed and denoised to conform to the smooth rule of human joint-point motion based on 3D skeleton data. The fusion feature composed of static and dynamic features was constructed to represent human action. The key frame extraction model was introduced to extract the key frames in human action sequences to reduce the computing load. A Bi-LSTM neural network model based on LSTM neural network was established to classify human actions, and the attention mechanism and Dropout were utilized to classify and recognize human actions, with the main parameters of the neural network optimized by the orthogonal test method. Finally, the open data set was employed for the action recognition experiment. The results show that the proposed model algorithm has a high recognition rate for human actions.
action recognition; fusion features; LSTM neural network; attention mechanism; Dropout
TP 391.4
10.11996/JG.j.2095-302X.2021020174
A
2095-302X(2021)02-0174-08
2020-07-21;
21 July,2020;
2020-09-12
12 September,2020
国家自然科学基金项目(51475365);陕西省自然科学基础研究计划项目(2017JM5088)
National Natural Science Foundation of China (51475365); Natural Science Basic Research Program of Shaanxi Province (2017JM5088)
杨世强(1973–),男,甘肃白银人,副教授,博士。主要研究方向为智能机器人控制、行为识别等。E-mail:yangsq@126.com
YANG Shi-qiang (1973–), male, associate professor, Ph.D. His main research interests cover intelligent robot control, behavior recognition, etc. E-mail:yangsq@126.com
