基于神经网络的多标签情绪分类研究
2021-05-12吴妍秀
吴妍秀
(四川大学计算机学院,成都610065)
0 引言
随着全球网络社交媒体的快速发展,越来越多用户在推特、微博等社交平台上发布内容,分享自己的个人观点、态度及情绪,挖掘海量文本中的此类信息变得尤为重要,使情绪分类成为热门研究方向。情绪分类具有很高的应用价值,它可以为舆情分析[1],个性化推荐,股票预测[2]等任务提供支持。
情绪具有多种分类方式:Ekman 等人[3]将基础情绪划分为joy、sadness、anger、fear、disgust、surprise 六类,在SemEval-2007 竞赛task 14: Affective Text[4]任务中,1250 条新闻标题被以这六种情绪进行标注;Plutchik[5]提出了八种基础情绪的分类,分别为acceptance、anger、anticipation、disgust、joy、fear、sadness、surprise。如表1所示,一段文本中可能包含多种情绪,且情绪之间具有关联,识别句子中同时存在的多种情绪仍是一项具有挑战性的任务。
多标签分类任务的定义为:假设X=Rd为d 维的样本空间,Y={y1,y2,…,yq}为存在q 个标签的标签空间,多标签分类任务从训练集中学习函数映射h:X→2Y。

表1 SemEval2018 task 1[6]数据集中的推特及对应情绪
1 研究现状
1.1 多标签分类任务
多标签分类任务主要采用问题转化或算法适应的方法,问题转化方法将多标签分类问题转化为其他较为熟悉的分类问题,算法适应方法采用现有的机器学习技术加以改进来处理多标签数据。
二元关系法(BR)[7]将多标签分类问题分解为q 个独立的二分类问题,每个二分类任务对应标签空间中一个可能的标签;多标签K 近邻(MLKNN)[8]采用K 近邻算法作为基础处理多标签数据,通过邻居节点的标签信息利用最大后验进行预测。上述两种方法为一阶方法,单独预测每个标签,忽略了标签的共现性,未考虑标签之间的关联,造成信息丢失。
基于排序的方法有排序-SVM[9]及校准的标签排序算法(CLR)[10],排序-SVM 算法采用最大间隔来处理多标签数据,对q 个线性分类器进行优化,最小化排序损失,并利用核函数解决非线性情况;CLR 将多标签分类问题转化为标签排序问题,为每个标签对构建二分类器,共构建q(q-1)/2 个二分类器,通过人工插入的阈值标签得到最后的分类结果。上述两种方法为二阶方法,只考虑了两个标签之间的共现性,未考虑真实世界中的标签关联不止存在于二者之间。
分类器链(CC)[11]将多标签分类问题转化为链式的多个二分类问题,链中前一个分类器的分类结果将输入后续的分类器中;标签幂集(LP)[12]将问题转化为单标签多分类问题,每个可能的标签组合被视为一个单独的标签,使标签数量级增长至2q。上述两种方法为高阶方法,可以考虑标签之间的关联,但CC 在训练过程中使用teacher forcing(即分类器的输入为上一个分类器的黄金标注,而不是其输出的实际预测结果)会导致预测时的暴露误差,LP 转化问题的方式使标签数量呈幂级增长导致计算困难。
1.2 情绪分类任务
早期使用基于词典与规则的方法解决该问题:Balahur 等人[13]构建了一个能触发情绪的常识规则库EmotiNet,该规则库记录了各种触发情绪的事件,进而对没有明确提到情绪词汇的文本进行识别。但是人工构建词典及规则费时费力,覆盖率仍不够理想,且无法探测新词。
Almeida 等人[14]将BR、CC、LP、MLKNN 等多标签分类任务的方法直接用于情绪多标签分类,传统的多标签分类方法存在未考虑标签关联或计算复杂的问题。
Li 等人[15]统计了Ren-CECps 数据集[16]中的标签共现频率及上下文出现相同标签的频率,提出了依赖因子图(DFG)模型,可以建模情绪标签及上下文之间的相关性。Zhu 等人[17]提出了语料库融合的方法利用两个情绪语料库,首先对两个语料库进行有监督的分类任务,然后根据语料库内约束和语料库外约束对预测结果进行优化。
2 神经网络方法
近年来,基于神经网络的方法快速发展,从传统机器学习人工提取特征的方式变为自动学习特征,由于自然语言序列输入且不定长的特性,可以使用循环神经网络RNN 这类神经元节点按时间序列连接的神经网络,而长短时记忆网络LSTM 及门控循环单元GRU改进了RNN 梯度消失的问题,使用LSTM 或GRU 编码输入句子成为了主流。
Abdul-Mageed 等人[18]利用hashtag 信息对语料进行远监督标注,使用GRU 对文本进行细粒度的情绪多分类任务;Matsumoto 等人[19]利用emoji 表情符号监督标注语料,分别实验BiLSTM、BiGRU、CNN 三种神经网络的分类效果,最终效果BiLSTM 及BiGRU 优于CNN。上述研究虽然使用远监督学习解决了人工标注语料费时费力,且标注数据不足的问题,但是将情绪分类看作普通的多分类问题,未考虑真实世界中的情绪分类应为多标签分类问题。
Yu 等人[20]通过迁移学习,利用情感分类任务提升样本较少的多标签情绪分类任务的效果,编码端使用BiLSTM 将句子编码至两个特征空间,分别为共享空间及情绪任务专有空间,通过双向注意力正交优化,捕获情感词及情绪专有词的信息,最后将两个隐藏向量拼接传入多层感知机进行分类,但需要人工设定阈值得到最后的多个标签。Jabreel 等人[21]拼接句子和标签,形成句子标签对集合,使用标签嵌入作为查询向量计算每个词的注意力,输入BiGRU 进行联合编码,将多标签分类问题转化为由同一个分类模型解决的二分类问题。上述研究未考虑标签与标签之间的共现相关性。
在LSTM 的基础上,可以使用Seq2Seq[22-23]进行多标签分类任务,将多标签分类问题转化为序列标注问题,该模型为编码-解码结构,编码端使用BiLSTM 提取输入句子的特征,注意力机制通过聚焦文本序列的不同词,对词的隐藏状态求和生成上下文向量;解码端每个时刻接收上一个时刻的隐藏状态,及上一时刻的标签嵌入和该时刻由编码端得到的上下文向量的拼接,将生成过的标签进行mask 操作从而避免重复生成,最终按序列生成情绪标签。该研究将解码端接收的上一时刻的标签嵌入改为了概率值加权的标签嵌入,减弱模型teacher forcing 造成的暴露误差。
Fei 等人[24]提出了潜在情绪记忆网络得到先验的情绪分布,其中的潜在情绪模块使用变分自编码器重构输入的词袋来学习情绪分布;记忆模块使用潜在情绪模块得到的参数矩阵作为查询向量,对输入句子计算注意力,捕捉对应情绪相关的上下文特征。模型使用了多跳BiGRU 得到输出,每个时刻输出一个情绪标签的二分类结果,潜在情绪模块得到的情绪分布矩阵及情绪特征矩阵为整个模型共享,记忆模块仅针对Bi-GRU 的每个时刻。
3 数据集及评价指标
3.1 数据集
近年来,由于该任务受到广泛关注,有多个研究及竞赛提出并标注了数据集,如:SemEval-2007 数据集、NLPCC-2014 数据集、Ren-CECps 数据集、SemEval-2018 数据集等。
目前使用较多的情绪多标签分类数据集为英文微博文本的SemEval-2018 task 1 的竞赛数据集及中文博客的Ren-CECps 数据集。如表2 所示,SemEval-18 数据集已划分训练集、验证集、测试集,情绪标签为disgust、anger、joy、sadness、optimism、fear、anticipation、pessimism、love、surprise、trust 十一类;CEC 数据集为未划分的结构化数据,情绪标签为joy、hate、love、sorrow、anxiety、surprise、anger、expect 八类。
统计得出的句子对应标签个数如表3 所示,两个数据集的每个句子样例均包含一种或多种情绪。

表2 数据集情况

表3 情绪标签数量的分布情况
3.2 评价指标
针对多标签分类问题,除了传统的F1 值度量以外,可以使用汉明损失[25]、杰卡德系数进行度量。汉明损失用于评价被误分类的样本标签对:
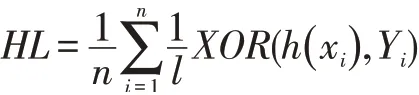
其中n 代表样本个数,l 代表标签个数,Yi为真实标注,h(x)i为预测结果,汉明损失越小,代表模型预测结果越准确。
杰卡德系数用于衡量两个标签集合之间的相似性:
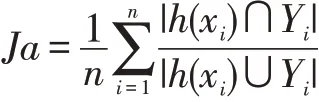
当集合Yi、h(x)i都为空时,Ja 定义为1。杰卡德系数越大,代表模型预测结果越准确。
4 结语
本文对基于神经网络的多标签情绪分类方法进行了研究。多标签情绪分类对于业界挖掘用户信息有很大帮助,神经网络的发展使该任务的效果有了进一步提升。但由于神经网络的黑盒特性,仍有很多特征提取及解码方式值得探索。
