一种多核处理器直连接口QoS的设计与验证*
2021-05-11周宏伟潘国腾周海亮
罗 莉,周宏伟,周 理,潘国腾,周海亮,刘 彬
(1.国防科技大学计算机学院,湖南 长沙 410073;2.武警贵州省总队,贵州 贵阳 550081)
1 引言
随着大数据计算、数据中心和集成电路技术的飞速发展,多核处理器支持直连接口实现共享主存的对称多处理器SMP(Symmetric MultiProcessing)系统已经成为主流。直连接口负责实现处理器芯片间的直连,也可用于实现备份和冗余,提高系统容错能力和性能。处理器之间直连接口设计不仅需要满足低延迟、高带宽,还必须满足高可靠的服务质量QoS(Quality of Service)保障。处理器直连接口提供的QoS保障,能够实现可靠、实时、完整和顺序到达的数据传输。
本文提出了一种面向多核处理器的直连接口的QoS设计方案,接口采用信用机制设计避免了拥塞,利用虚通道技术、优先级的仲裁调度策略避免了死锁、拥塞的传输问题,同时,滑动窗口重传协议维护了数据传输的顺序性和正确性。模拟结果显示,QoS设计的正确性,为多个处理器的直接互连提供了稳定的鲁棒性,移植到FPGA原型验证平台,顺利通过了测试。目前,该芯片已成功流片。
2 相关工作
处理器直连接口能够实现处理器之间直接互连,国内外市场上大多数高端服务器产品都支持多个处理器以直接互连的方式构建多路服务器系统。
Intel公司[1]推出了一种高速、点到点的处理器间互连总线QPI(Quick Path Interconnect),集成于Intel的服务器处理器中。Intel Xeon E5系列和E7系列分别集成了2个和3个QPI总线接口,可实现多路处理器的直连。IBM公司[2]的p系列服务器采用IBM Power5+高性能处理器,通过处理器直连通道互连,最大支持32路处理器。AMD[3]的超传输HT(HyperTransport)总线,实现了一种高速、双向、低延时、点对点的直连接口。NVIDIA的NVLink支持连接多个GPU。IBM公司[4]的Power9处理器通过NVLink可以直接与NVIDIA GPU互连,实现高性能计算(HPC)系统。
上述直连接口技术并不是通用协议,相关技术不开放,不能作为国产处理器的直连接口技术。为此,自主设计并实现芯片直连接口是不可避免的选择,王锦涵等[5]将PCI-E的总线技术运用在国产处理器的片间直连中,可以实现自主可控的芯片直连接口,达到处理器直连的目的。周宏伟等[6]提出了一种面向多核微处理器的互连接口的设计方案,基于精简的PCI-E 总线协议,采用高速串行数据传输技术,支持Cache一致性报文和大块数据传输报文,能够用于实现4 路处理器的直接互连。王云霏等[7]针对国产服务器的处理器间互连的直连接口,为了降低片间通信带宽需求,设计了一种基于Token 协议和目录协议的混合一致性协议,目的是在带宽资源受限系统中具有更好的系统性能。
本文旨在研究面向多核高性能微处理器的直连接口QoS设计,能够实现处理器直连通信可靠、实时、完整和顺序到达的数据传输。
3 支持SMP的直连部件
对称多处理器系统SMP中所有处理器共享一个统一的地址空间,具有相同的地址空间视图。系统的分布式内存和I/O资源为所有的处理器共享,易于构建单一映像的操作系统,并为上层应用提供统一、高效的编程接口。
通过高速处理器互连接口,多个处理器可以方便地实现SMP系统。为了达到更高的带宽,避免对共享资源的竞争,目前主流多处理器之间的连接链路普遍采用点到点的直连链路。如图1所示,直接互连的处理器的数目最常见的是2~4个。
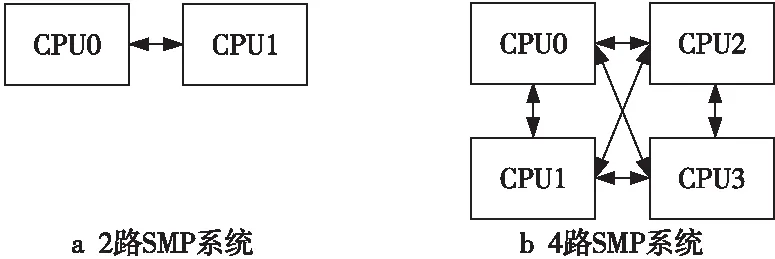
Figure 1 SMP system interconnected by direct connection interface图1 通过直连接口互连的SMP系统
设计多个直连接口支持多个处理器芯片直连,也可用于实现备份和冗余,以提高系统容错能力和性能。3个直连接口最多支持 4路处理器直连的拓扑结构;2个处理器可以相互连接构成2路直连的多处理器系统,连接时可以使用1个直连接口,如图1a所示的2路SMP系统,也可以把3个直连接口都连接上,以提高传输带宽和容错能力;4个处理器则可以相互连接构成 4 路多处理器系统,如图1b所示,当部分处理器发生故障时,可以降级为 3 路或2 路多处理器系统。
在SMP互连体系结构中,处理器互连接口一般分为多个层次,但与传统的Internet 中使用的OSI 7 层协议[8]不同。传统的OSI 7 层协议由于协议层次多,各层协议功能重复、复杂,处理器间的互连通常采用功能精简、结构合理的互连网络协议,其协议主要包含了传输层、数据链路层和物理层。本文的研究目标是面向多核处理器的直连接口,协议层次如图2所示,包含应用层(Application Layer)、传输层(Transport Layer)、数据链路层(Link Layer)和物理层(Physical Layer)。
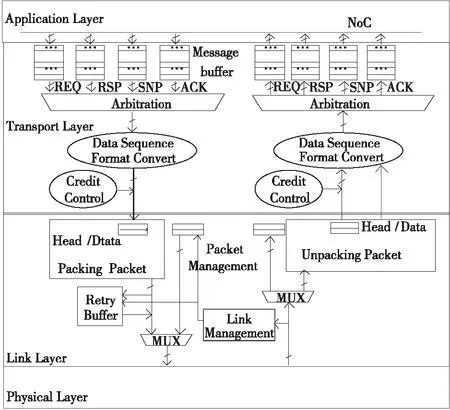
Figure 2 Hierarchy of direct connection interface图2 直连部件的层次结构
应用层在本文的处理器芯片中是片上网络NoC(Network on Chip)接口,负责向直连部件发送NoC待传输的报文,报文类型划分为请求(REQ)、响应(RSP)、监听(SNP)和应答(ACK)4类,并接收直连部件输出的报文。
传输层接收应用层的报文(Message),按照链路层需要的格式,将其转换成链路层需要的数据序列(Data Sequence),并根据接收方和数据链路层的状态,将转换好的数据序列发送给数据链路层。同时传输层接收数据链路层的数据序列,并将其转换成应用层需要的报文格式,缓冲后发送给应用层。传输层结构主要包括报文缓冲(Message Buffer)、四选一仲裁(Arbitration)、数据序列格式转换(Data Sequence Format Convert)和信用控制(Credit Control)。
链路层接收传输层的数据序列,将其转换成适合链路传输的微包(Packet)格式,并根据链路管理(Link Management)状态,将微包发送到物理层。链路层同时接收物理层的微包,并将其转换成传输层需要的数据序列。链路层还具有微包的CRC校验和出错重传等功能。链路层结构主要包括微包打包(Packing Packet)、微包解包(Unpacking Packet)、微包管理(Packet Management)、链路管理(Link Management)、重传缓冲(Retry Buffer)和二选一开关(MUX)。
物理层将微包转换成串行的码流,通过SERDES(串行/解串)发送和接收。SERDES技术因其传输速率高、抗干扰能力强等优点已成为主流的高速接口物理层规范。
4 直连部件的QoS设计
通过高速处理器互连接口实现SMP系统,用于未来的高性能计算机和数据中心,直连接口必须提供处理器之间低延迟、高带宽和高可靠的QoS保障。
所谓服务质量(QoS)是指网络在传输数据流时要满足的一系列服务请求,如Internet仅提供尽力而为(Best Effort Service)的传输服务,尽力发送的机制对报文传输时的可靠性、实时性、完整性、到达的顺序性,以及传输的时延无法提供任何保证。尽力而为不能达到直连接口的QoS要求,处理器之间建立的直连传输链路,不仅需要提高数据的吞吐率,还必须提供保障服务,避免死锁和拥塞,保障数据的完整性和到达的顺序性。
为解决互连传输拥塞,本文采用了基于信用的流控机制。相比传统的空、满溢出流控方式,采用基于信用的流控能精确判断流量,同时利于后端实现。
处理器互连接口的输出都是点到点传输,分时共享链路传输的独占资源。为了避免事务之间相互依赖而导致的死锁,本文设计了基于事务类型的4个虚通道、固定优先级的仲裁调度,同时采用等待时间控制“饥饿”状态,有效提供了QoS保障。
链路层通信的QoS要求传输具有可靠性和完整性,本文利用滑动窗口重传协议实现无差错的链路层通信;利用CRC校验技术检测错误,自动地对丢失的微包、错误微包请求重发。
4.1 接口信用机制设计
解决网络拥塞的办法通常是采用流量许可控制,当接收一个新的数据流时许可承诺是有效的,如果一个新的数据流所请求的网络资源超出可用网络资源,许可承诺会被置为无效。
为确保直连部件协议层次间发送/接收报文的顺利进行,需要确保发送方在发送报文时接收方有足够的空间接收报文,发送方和接收方必须有一个有效的流控机制,以协调报文的发送和接收。
本文在协议层次输入端口和输出端口上均设计了报文缓冲区,为保证缓冲区不发生上溢和下溢,必须对进入缓冲区的报文进行流控。 传统的缓冲区流控策略是使用缓冲区的空信号和满信号来判断缓冲区是否发生上溢和下溢,本文采用基于信用的流控,精确控制流量,较好地避免了拥塞。
图3所示是直连部件支持的通用接口信用机制。图3中Sender是发送方,Receiver是接收方,在数据的源端维护一个信用计数器,初始值设置为缓冲区深度,当数据源发出一个微报信号Send,信用减1;当缓冲区中消耗 1 个微包时,释放 1 个信用,当信用释放信号Release到达数据源端时,信用计数器加 1。Sender在发送报文时,每个时钟周期都可以将Packet传输给接收方,接收方有一个输入缓冲区,这个缓冲区能够缓冲N个Packet,只要接收缓冲区有足够的空间,发送方就直接发送新的Packet给接收方,发送方通过一个信用计数器(Credit Counter)来确认是否可以发送Packet给接收方。
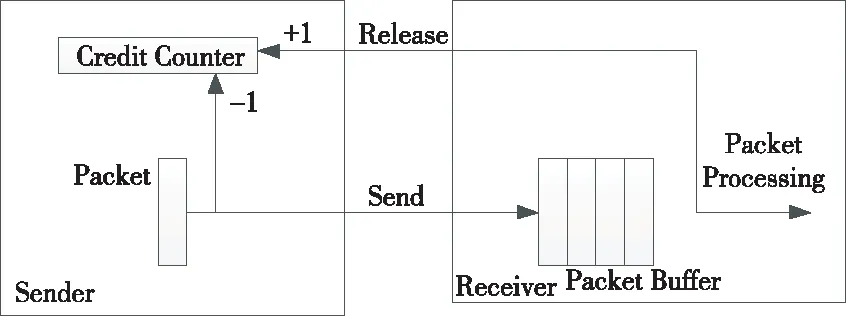
Figure 3 Universal credit mechanism for direct connection interface图3 直连部件的通用接口信用机制
初始时,信用计数器的值等于接收方缓冲器的深度,发送方在发送Packet前必须检查信用计数器的值,只要信用计数器的值大于0,发送方就可以发送Packet,每发送一个Packet,发送方就将信用计数器的值减1。接收方会将收到的Packet缓存在接收缓冲区中,同时接收方的内部处理逻辑也会不断消耗处理缓冲区中的数据,接收方每消耗掉缓冲区的一个Packet,就会通过Release信号向发送方发送一个脉冲信号,发送方收到Release脉冲,就将信用计数器的值加1。
这种信用机制应用于直连部件的每个层次接口,如应用层与传输层接口、传输层与数据链路层接口、数据链路层与物理层的接口。
相比传统的缓冲区空满的流控策略,信用流控可以不必考虑数据源端和缓冲区端之间的距离,二者之间可以任意增加中继,非常有利于芯片物理实现的后端设计。
4.2 传输层的QoS设计
传输层将接收的应用层报文,按照链路层需要的格式,转换成链路层需要的数据序列,并根据接收方和数据链路层的状态,将转换后的数据序列发送给数据链路层。传输层还接收数据链路层的数据序列,并将其转换成应用层需要的报文格式,缓冲后发送给应用层。
应用层的报文与片上网络的报文格式一致。多核处理器Cache一致性协议和片上互连结构采用了紧耦合设计,片上互连网络连接了主存、Cache、核和I/O设备等,Cache一致性消息通过片上网络报文进行传输,片上网络的报文可划分为请求、监听请求、监听应答和读写响应4种类型。
进入链路层的各类事务必须分时共享链路传输的独占资源,因此不可避免地会将各类事务统一排队处理。为了避免死锁,传输层与应用层之间采用虚通道方式,虚通道是一种避免网络死锁的常用技术。
传输层与应用层的传输数据根据传输的报文类型,定义4个虚通道:请求(REQ)通道、响应(RSP)通道、监听(SNP)通道和应答(ACK)通道。虚通道设计避免了不同类型的事务混合在一起互相等待,若一个虚通道被阻塞,则其他的虚通道还能继续通向输出端口,最大限度地减少了由于事务之间相互依赖而导致的死锁。
分时共享链路传输的独占资源,为了避免因为事务之间相互依赖而导致的死锁,本文设计了固定优先级的仲裁调度,根据优先级选择调度哪一个虚通道占用链路层传输。一个Cache事务的生命周期通常是{请求,响应}、{请求,监听请求,监听响应,响应}、{请求,监听请求,监听请求,…,监听请求,监听响应,…,监听响应,响应}的事务序列,优先级最高的是响应通道,其次是监听响应、监听请求和请求通道。基于优先级调度的仲裁方式保障了响应事务、监听响应事务及时得到处理。
当出现连续不断的、稳定的监听响应、响应传输时,可能会导致监听请求或者请求通道得不到仲裁调度,从而出现 “饥饿”现象。传输层的仲裁选择调度采用固定优先级设置,通道的“饥饿”现象同样存在,为了避免这种情况,监听通道请求和请求通道都设置等待计时器,若监听请求通道或者请求通道的报文等待时间大于门限设置时间,优先级调整为最高,仲裁调度器会选中该通道报文输入链路层。
传输层采用虚通道技术、基于优先级的仲裁调度策略避免了死锁,同时利用等待时间控制饥饿状态,有效提供了QoS的保障。
4.3 数据链路层的QoS设计
链路层将接收的传输层数据序列转换成适合链路传输的微包(Packet)格式,并根据链路管理(Link Management)状态,将微包发送到物理层。同时将接收的物理层微包转换格式后输入到传输层。
链路层传输的信息单位是微包,是芯片间链路传输层的信息传输、校验、重传、流控的最小单位,微包的类型分为报文微包和管理微包,管理微包有链路初始化微包、链路初始化响应微包和空微包。空微包是链路空闲时发出的微包,携带了滑窗的序列号。链路层通信的QoS要求每个微包传输具有可靠性和完整性,本文利用滑动窗口重传协议实现无差错的链路层通信;采用CRC校验技术检测错误,自动地对错误微包请求重发。
链路层通信遇到数据传输或者接收错误时,需要进行重传,重传协议为滑动窗口重传协议(Sliding Window Retry Protocol),滑动窗口机制在重传协议中维护了发送和接收2个窗口。发送窗口实际上是维护重传缓冲区的读写控制和发送方序列号,而接收窗口实际上是维护接收方的序列号。
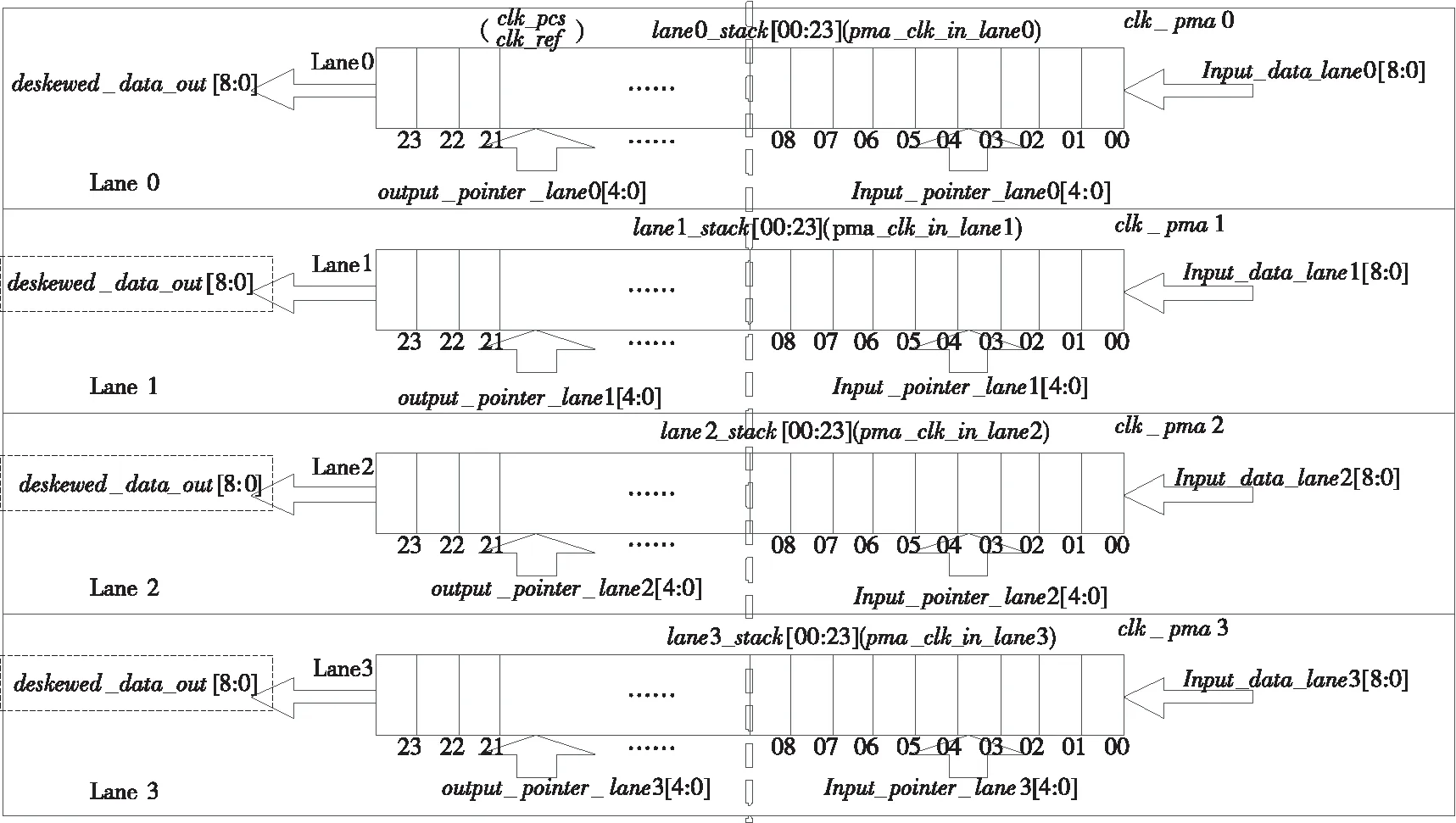
Figure 4 Calibration mechanism of frequency skew图4 频率偏斜校准机制
接收窗口的大小设计为1,可以顺序接收发送方发出的报文,任何序列号不等于接收窗口所对应序列号的报文都会被丢弃。接收窗口保障了接收报文的顺序正确性和无重复的报文序列。
CRC循环冗余校验码简称循环冗余码,是一种检错概率高且易于硬件实现的检错码。为了保证报文传输过程的正确性,发送方在将要发送的微包上附加一个CRC校验码,接收方则根据CRC校错码对微包进行差错检测,若发现错误,就返回请求重发的应答,发送方收到请求重发的应答后,便重新传输该微包。本文使用滑动窗口机制,高效地实现了重传协议中的重传缓冲区和收发序列号管理。
数据链路层实现的滑动窗口重传协议解决了数据传输的出错、丢失、乱序和重复问题,CRC校验检查传输数据的正确性,如果出错自动发起重传,保障了链路层每个微包传输的可靠性和完整性。
4.4 物理层的QoS设计
物理层包括物理编码子层PCS(Physical Coding Sublayer)和物理媒介适配层PMA(Physical Media Attachment)。其中PCS为数字电路,PMA也可以被称为串并转换电路(SERDES)。PCS基于64 B/66 B编码技术、扰码传输技术和频率偏斜校准机制,物理层传输速度可以达到 25 Gbps。
图4所示是PCS子层频率偏斜校准机制,是频率补偿与延迟修正合二为一的校准机制。PCS子层的每个通道(Lane)有一套独立的数据栈(Stack)。数据栈具有弹性缓冲的功能,用于调节每个Lane从PMA层恢复出来的时钟(pma_rcvr_clk_in_lane[i])和PCS子层的时钟clk_ref之间的时钟频率偏差;数据栈也可作为纠正Lane与Lane之间传输延迟偏斜的缓冲器使用。将弹性缓冲和延迟纠正缓冲合二为一,能够降低PCS层的物理资源需求,减小物理层的面积。
直连接口的设计包括应用层、传输层、数据链路层和物理层的PCS子层,本文利用S2C公司的VU440开发板,实现了FPGA原型验证平台,限于篇幅,在此不做详述。
4.5 模拟平台和功能验证
针对本文研发的面向多核处理器的直连接口,功能验证平台开发了测试单部件回环、双部件互连的软模拟验证环境,通过功能点测试,保障了QoS设计的正确性。功能验证平台是基于UVM(Universal Verification Methodology)[9]方法学实现的验证平台,UVM是一个通用的验证方法学,UVM的一个关键特性就是开发了一系列可重用的验证组件UVC(UVM Verification Components)。UVM以systemVerilog语言为基础,已经成为业界标准,目前3大EDA厂商的工具都支持UVM。
单部件回环验证环境结构如图5所示,该环境重点测试了错误注入、模拟通路传输错误和通路延迟,激发链路层重传相关操作。DUT(Device Under Test)是本文研发的面向多核处理器的直连接口部件,phy_monitor是用于检查物理层接口协议的检查器。
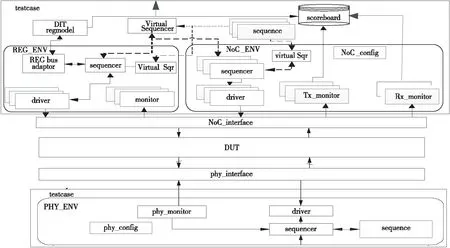
Figure 5 Loop back verification environment for one DUT component图5 单部件回环验证环境
testcase是测试用例集,DVB_config、NoC_config和phy_config定义了约束化的随机方式。env是UVM验证方法学中引入的一个容器类,当调用 run_test 函数时,可以传递参数给env容器类,使得 UVM 能够自动地创建组件实例,大大减少了代码的冗余。env主要包含sequence、driver、monitor和scoreboard等组件,sequence组件的主要功能是用于产生各种激励;sequencer组件主要是将sequence产生的激励和各种transaction类传递给驱动器driver。验证平台实现了基于env实例化的NoC_ENV、REG_ENV和PHY_ENV,是模拟NoC行为、寄存器配置和物理层接口的功能。
NoC_ENV.driver模拟NoC的BFM(Bus Function Model)行为,是时钟精确的NoC模型,实现了NoC片上网络4类报文数据的随机发送。
REG_ENV.driver模拟了寄存器配置的BFM行为,例如配置重传超时计数器上限值、最大连续重传次数上限值和达到max_retry_counter后链路是否复位等。
PHY_ENV.driver模拟了物理层接口的BFM行为。
scoreboard负责对仿真运行结果进行自动比对,对比对结果进行分类汇总,提供完整的错误信息并控制仿真器在出错时的运行状态,即停顿等待、关闭终止还是继续运行。
monitor检查寄存器配置的正确性,Tx_monitor和Rx_monitor除了监控DUT的输入输出,还完成了覆盖率统计收集,phy_monitor是物理层协议的检查器。
当有多个sequence需要按一定次序发送transaction给对应的sequencer时,使用Virtual Sequencer来进行调度。
图6所示是2个直连部件连接的验证环境,重点测试微包正确打包、解包功能、链路管理功能和重传协议功能。
直连部件的验证功能点如表1所示,测试寄存器配置、NoC报文传输、NoC报文压力、注错、链路管理、物理层接口检查的功能正确性。本文采用受约束随机产生激励和定向激励的验证策略,发现了设计中较多缺陷,其中敏化了多个高质量的滑动窗口重传协议的设计缺陷。NoC报文压力测试和注错测试重点验证直连部件的QoS设计,测试1 000万个NoC报文传输,拥塞和饿死场景没有发生。注错测试是在链路传输数据中注入错误,例如微包初始化错误、微包序号错误、空报文错误、微包的净荷数据植入一位错,都能引起正确重传。
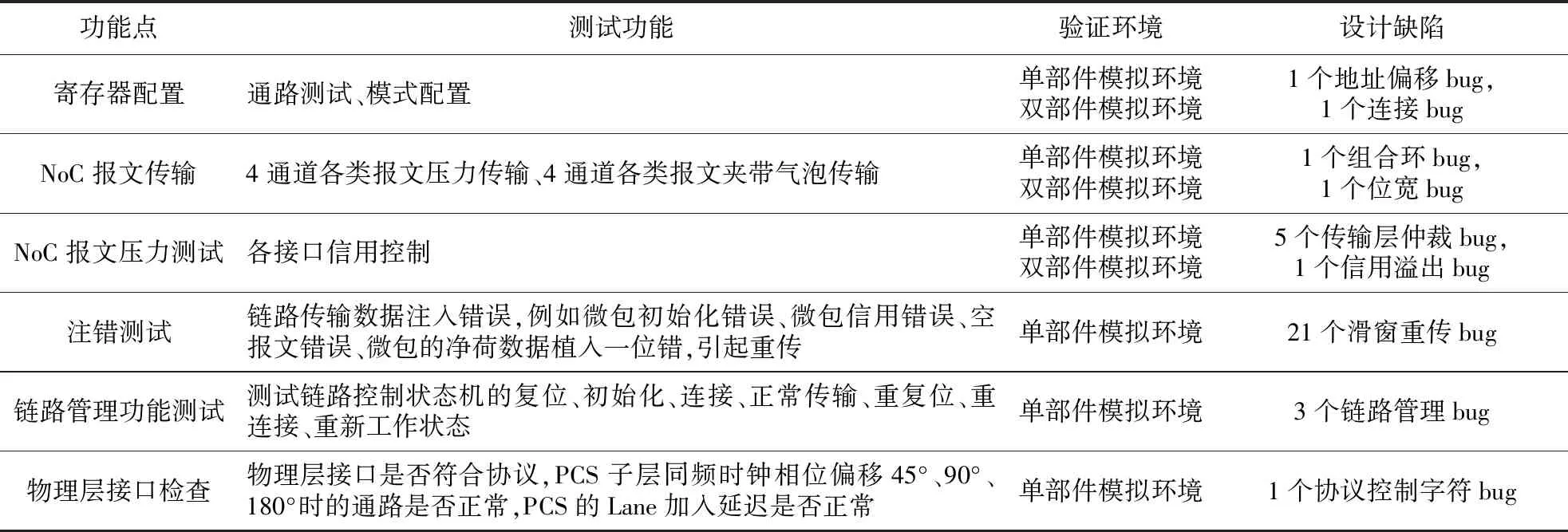
Table 1 Verification function points of direct connection interface
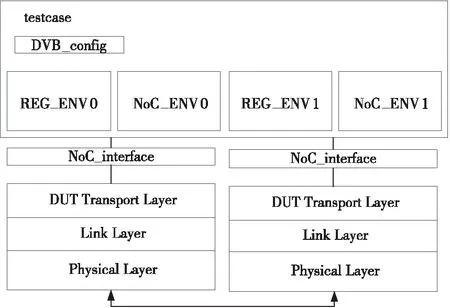
Figure 6 Verification environment for two DUT components图6 2个直连部件连接的验证环境
直连部件的延迟性能如图7所示,直连部件主频设计为1.5 GHz,在传输层和数据链路层信用都有效情况下,传输层和数据链路层的延迟为7.5 ns;在传输层和数据链路层信用无效的情况下,延迟为15 ns;当链路传输数据中注入错误产生了重传时,延迟为21 ns。物理层PCS子层时钟相位偏移45°、90°、180°时,直连部件都可以正常工作;物理层PCS子层输出的的各个通道(Lane)之间偏移延迟(skew)允许最多5个PCS子层时钟周期,直连部件可以正常工作。直连部件通过软模拟功能验证后,移植到FPGA原型验证平台测试,达到了预期目标。目前,该芯片已成功流片。
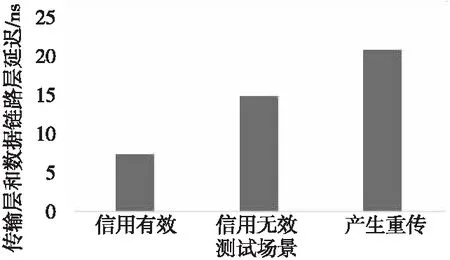
Figure 7 Latency performance of direct interface图7 直连部件延迟性能
5 结束语
本文主要研究高性能处理器直连接口的QoS设计,通过直连接口实现跨芯片的一致性报文有效、可靠传输。本文详细阐述了直连接口各个协议层QoS设计的关键技术,基于UVM方法学构建了单部件和双部件验证平台,模拟验证了QoS设计的正确性,移植到FPGA原型验证平台,顺利通过了测试。实现处理器芯片直连,是提升高性能多路服务器的主流方向,具有良好的应用和研究前景。
