ARM计算环境下堆芯程序的移植*
2021-05-11明平洲李治刚余红星
明平洲,李治刚,刘 婷,芦 韡,刘 东,曾 辉,余红星
(1.中国核动力研究设计院,四川 成都 610213;2.中国核动力研究设计院核反应堆系统设计技术重点实验室,四川 成都 610213)
1 引言
堆芯计算涉及到的学科主要有反应堆物理、热工水力、力学和燃料性能等,它们的单学科计算或者多学科耦合计算均用于论证和分析堆芯内部存在的大量异质现象[1]。由于真实堆芯的解析解极难获得,采用不同的数值离散方法对各种物理数学方程进行工程求解成为计算相关研究人员的核心工作[2]。现阶段中国核动力研究设计院引进的基础集群计算设施采用异构设计,国产飞腾处理器组成的计算分区能够通过SLURM集群资源管理系统进行计算作业的分区投递。目前国内高端处理器市场主要有龙芯、飞腾和兆芯等品牌,其中天津飞腾信息有限公司研制的CPU已加入到开放的ARM生态系统,飞腾64位通用处理器产品兼容ARMv8指令集[3],采用28 nm工艺流片,具备高性能和低功耗等特点,定位为中高端Intel至强服务器芯片的替代品。区别于Intel商用处理器使用的X86复杂指令集体系,ARM是典型的精简指令集体系,这使得集群计算机有不同特点的计算资源可使用。不同指令集体系下的处理器存在着不同特点[4],在商用处理器受限或计算资源紧张的情况下,ARM计算资源有可能成为一种补充的数值计算资源。
本文研究移植的4个软件描述为:
(1)NACK-R是使用粗网节块法求解稳态中子扩散方程的C/C++程序[5],常用于充当堆芯燃料管理软件的核心求解器,提供堆芯各个工况点下的通量分布和功率分布。
(2)中国核动力研究设计院堆芯热工水力分析软件CORTH(CORe Thermal-Hydraulics)是用于堆芯热工水力分析的子通道程序,可用于分析研究反应堆及其回路系统中冷却剂的流动特性、热量传输特性和燃料元件的传热特性,且正在持续进行新功能开发和细节改进[6]。
(3)特征线中子输运计算方法具有计算精度高、几何适应性强和形式简单等优点。美国麻省理工学院研制的开源特征线输运程序OpenMOC(Open Method Of Characteristics neutral particle transport code)使用Python和C++进行混合编程,内部的数值计算核心采用C++编程语言,早期版本用于任意二维几何区域的输运计算[7]。
(4)全堆芯的中子物理参数求解在多个层面上存在着均匀化计算。KYLIN2程序现阶段在组件级别为堆芯程序提供组件库的计算,其核心为使用特征线方法的中子输运求解器,具备多种参数的计算功能[8]。
2 计算环境说明
中国核动力研究设计院引进的集群计算机具备多个异构计算结点,使用资源管理软件SLURM划分为多个分布式内存计算区域,其中2类分区分别对应于商业处理器环境和国产飞腾处理器环境。前者在运行稳定性和配套软件上较为成熟;后者面向通用计算,但计算效率和运行稳定性略为不同,这源于ARM处理器结构主要应用于嵌入式数字设备等领域,通用ARM芯片在数值分析计算领域尚处于局部应用状态。
硬件描述:飞腾FT-1500A是基于ARM64位架构的服务器芯片,面向计算服务器市场。在本单位购置的集群计算机上,每个逻辑上的飞腾计算结点使用1个飞腾FT-1500A处理器,具备16个处理器核心,每个处理器核心运行单个线程。每个飞腾计算结点上的内存为32 GB,具备16 MB的缓存。根据供应商提供的文档可以获知该通用计算处理器的主频为1.6 GHz。
软件描述:围绕麒麟操作系统建立系统环境,关联集群计算机的各个软件层次。其中开发环境主要为GCC 4.9.3,安装Glibc 2.19、make 4.0和开发工具链Binutils 2.24.90[9]。
待移植程序或软件的部分数值求解内容依赖于第三方数值函数库,因此移植过程需要围绕2类软件进行移植、修订和测试。一类是底层系统软件,用于为上层的堆芯数值计算提供通用计算功能,在ARM计算环境中摆脱对商业处理器环境中的函数库依赖;另一类是堆芯计算本身的求解内容,需要进行程序代码改写和修订,从而以同一套程序代码适应不同硬件的计算环境。表1统计了真实移植过程所涉及的软件。
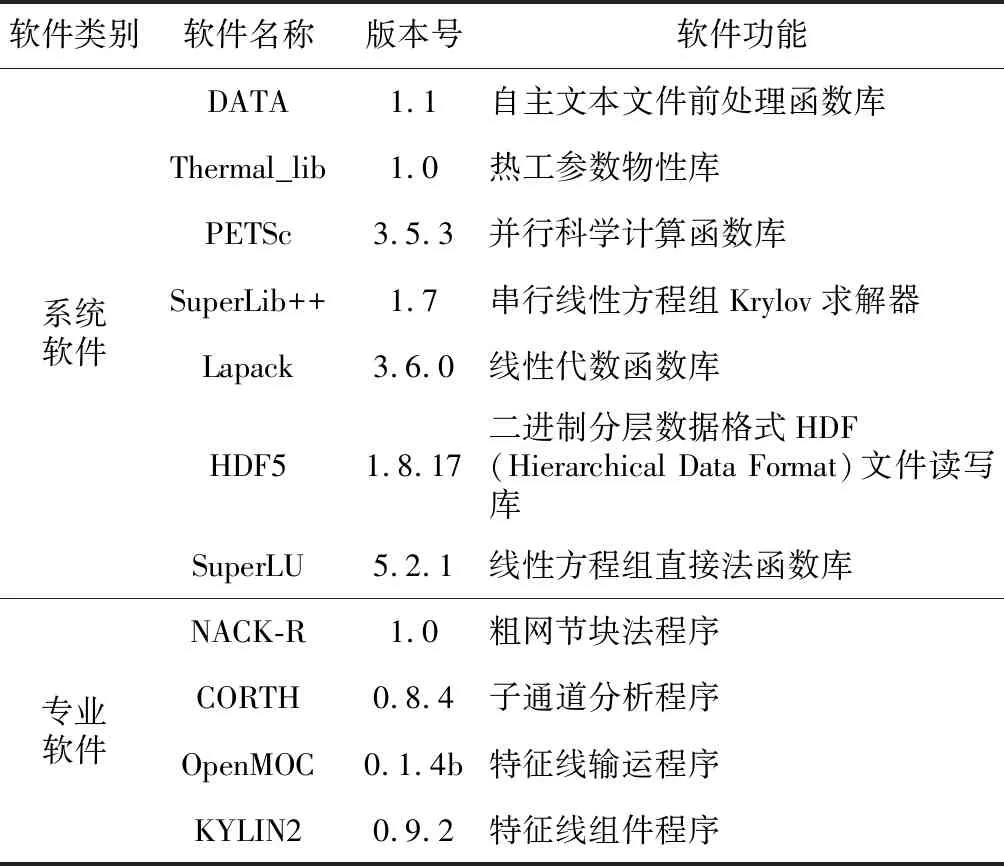
Table 1 Softwares to be ported
本文首先验证飞腾处理器在ARM环境中进行移植的可行性和正确性,记录上述软件的移植过程和数值实验。然后利用OpenMP对KYLIN2程序并行进行优化,论证单结点多个飞腾处理器核心的并行能力。这里选取的对比对象为Intel商用处理器,其中Intel商用处理器的主频约为飞腾处理器主频的2倍,理论上飞腾处理器的串行运行效率为Intel商用处理器串行运行效率的一半。分析KYLIN2程序并行优化时,按照最多使用12个处理器核心进行讨论。
3 移植和测试
整个移植工作采用自底向上的流程以适应由飞腾处理器所构建的集群计算机单结点ARM计算环境。测试过程将对比Intel商用处理器所在计算环境和ARM计算环境的效率、数值稳定性和正确性。
3.1 系统软件的移植
参与数据前后处理的DATA函数库和HDF5读写库直接使用ARM计算环境提供的C/C++编译器进行编译,然后使用软件提供的基准程序进行测试,确保文本文件或二进制文件的正确读写。
参与数值计算的PETSc、SparseLib++、Lapack和SuperLU在移植过程中重点用于求解线性方程组和参与特征值计算等数值问题,这些函数库由多个模块组成,底层依赖于向量、矩阵和索引集等数据结构,内部采用C/C++语言和Fortran语言混合编程。本文将其移植到飞腾计算结点后使用GNU编译器(gcc,g++和gfortran)以及基于GNU编译器生成的并行编译器(mpicc,mpicxx和mpifort)进行编译,能够正常生成静态库和动态库。与此同时,基于已获取的热工分析相关线性方程组的研究工作[10],本文使用移植的库进行线性方程组求解例题的测试,以证明飞腾处理器构建的ARM通用计算环境能够正常完成基本的数值计算,且收敛精度均可达到预期。
3.2 NACK-R
NACK-R是用于堆芯燃料管理分析的C/C++版本的粗网节块法扩散计算程序(CORCA-3D扩散计算模块的参考原型),本文将其移植到ARM环境中,并参照NACK-F的测试内容,使用4个例题进行对比测试,计算结果主要统计有效增殖因子keff和例题的运行时间(各个粗网节块的通量值也进行了对比,计算结果保持一致)。Intel商用处理器的计算环境和飞腾处理器的计算环境所使用的编译器均选择g++。
编译的优化选项首先选取为O0,保证不引入编译器的特定优化行为,统计结果如表2所示。
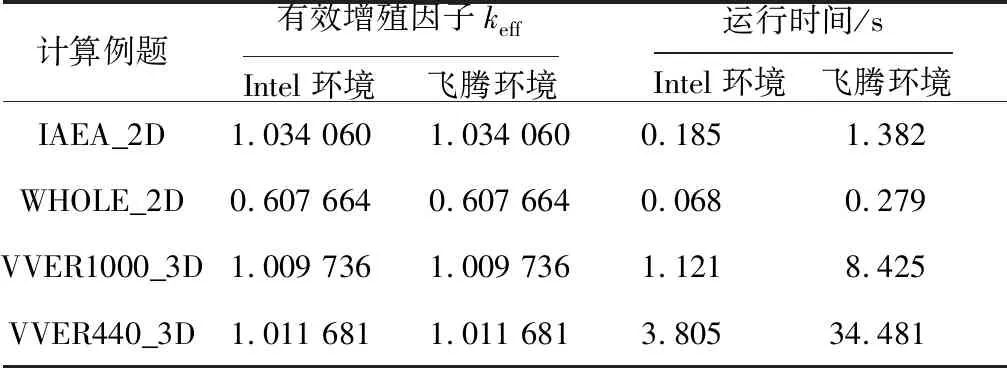
Table 2 Test Comparison of NACK-R using O0 optimization in Intel environment and Phytium environment
编译的优化选项为O2,相应的统计结果如表3所示。

Table 3 Test comparison of NACK-R using O2 optimization in Intel environment and Phytium environment
编译的优化选项为O3,相应的统计结果如表4所示。
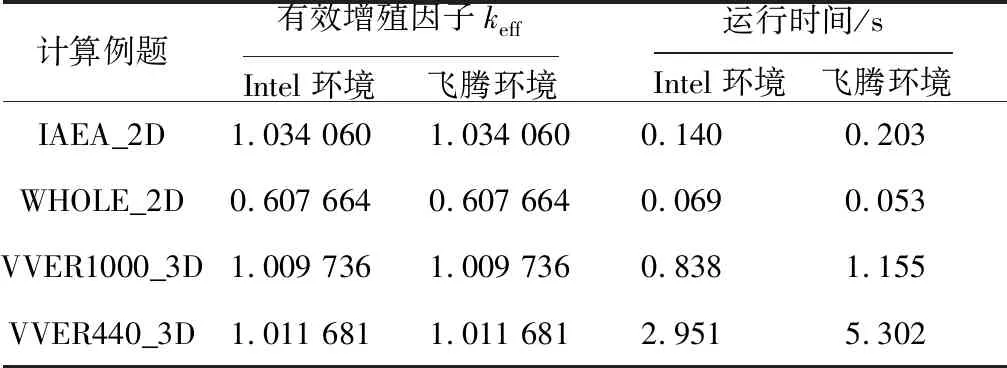
Table 4 Test comparison of NACK-R using O3 optimization in Intel environment and Phytium environment
该程序移植使用C/C++编程语言,从统计数据来看,串行运行时飞腾处理器随着编译优化等级的变化能够持续对效率进行改善,O3优化等级比起O2优化等级仍然有10%左右的性能提升。Intel商用处理器在O3优化等级和O2优化等级的计算效率基本相同。整体上Intel商用处理器性能高于飞腾计算结点的飞腾处理器,O0优化等级情况下数据量较小时两者相差约7倍,在数据量较大时相差约9倍,高于频率之间的2倍差异。随着编译优化等级的提升,飞腾处理器本身的运行效率有了较大提升,2种处理器之间的性能差异在缩小,这表明C/C++数值计算程序在使用精简指令集的情况下可以通过编译优化等级的改变来明显提升计算效率,此时2种硬件之间性能差距也接近频率差距的2倍。移植和测试结果也表明2种硬件环境中的数值计算结果保持一致,遵循IEEE的浮点数标准规范。
3.3 CORTH
CORTH程序采用矩阵形式求解具有滑速比的四方程均匀流模型,可以实现按照全堆芯栅元级别划分子通道的数值计算,求解整个堆芯的焓升和压降。本文移植的CORTH版本为0.8.4,其主要编程语言为C/C++。为了保证数值稳定性以及Intel处理器环境和飞腾处理器环境能够针对同一套程序代码进行编译,向ARM环境的移植过程需要对CORTH 0.8.4版本完成以下2方面的代码修订工作:
(1)去除Intel 商业函数库MKL(Math Kernel Library)的依赖。CORTH程序使用MKL函数库内的mkl_dcsrgemv函数对能量守恒和动量守恒形成的线性方程组进行迭代求解,这里将求解函数替换为SparseLib++提供的GMRES函数。该函数同样使用广义最小残差的Krylov子空间方法来迭代求解线性方程组,能够获得与原函数mkl_dcsrgemv相同的计算精度,且串行计算效率更高。
(2)编译过程需要在ARM环境中重新编译CORTH程序使用的第三方内容,例如2.1节列出的DATA类和热工物性函数库。该移植过程涉及到Fortran和C++混合编程,为了获得不同硬件环境中程序代码的一致性,需要按照GNU编译器推荐的标准混合编程规范重写计算函数的声明,例如热工物性函数库中的func函数,重写的头文件声明如下所示:
#ifdef__cplusplus
extern"C"
{
#endif
externdoublefunc_(double*,double*,double*);
#ifdef__cplusplus
}
#endif
它在Intel处理器环境和ARM处理器环境中均能够被正确识别和混合编程应用。
当C/C++编程语言内调用Fortran语言形式的热工物性函数接口时,需要在函数名称func后添加下划线“_”,且形参均为引用传递。
完成CORTH移植后,本文针对ACP1000的堆芯构造4种子通道划分的例题进行串行计算的正确性和效率测试。2种硬件环境下均使用GNU编译器,根据3.2节的移植分析结论,编译优化等级统一设置为O2。

Table 5 Results and running time of CORTH
从表5的统计数据来看,引入SparseLib++的迭代法后,其数值稳定性和正确性在以飞腾结点代表的ARM环境和Intel处理器环境中保持一致,表明了飞腾处理器具备通用计算的特点。计算性能方面,Intel处理器明显高于飞腾处理器,但不同的问题规模下飞腾处理器与Intel处理器的效率差距始终保持在3~4倍,略高于两者之间的处理器频率差异。这是由于ARM环境中飞腾处理器具有更小的缓存,间接影响CORTH程序在执行数值计算时的性能。
3.4 OpenMOC
本文将中子输运的偏微分方程转换为常微分方程,然后使用特征线形式进行数值求解。相比其它中子输运理论数值计算方法,特征线方法具有计算精度高、几何适应性强和形式简单等优点。麻省理工学院研制的二维特征线输运程序OpenMOC使用Python和C++进行混合编程,内部的数值计算核心采用C++语言编程,用于任意二维几何区域的输运计算。本文将OpenMOC 0.1.4b版本移植到ARM环境之后使用C5G7 1/4堆芯问题进行串行运行测试,以探究特征线方法的运行特点。在Intel处理器环境中使用相同程序对比验证,记录keff的数值和计算效率。各个网格栅元的通量经过可视化显示后可以快速观察2种环境中运行结果是否相同。图1所示移植结果表明在Intel处理器与飞腾处理器上的计算保持一致。
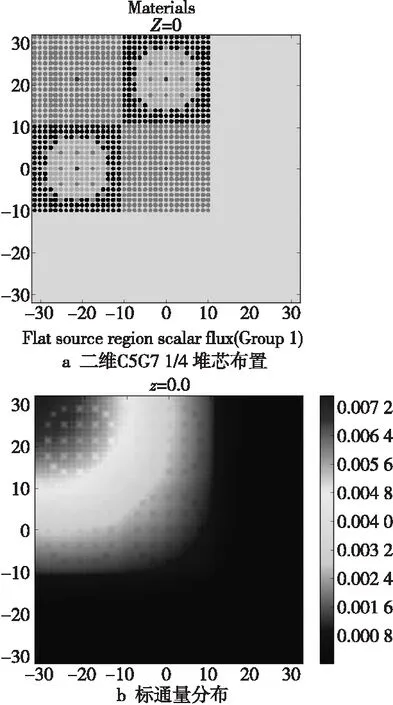
Figure 1 Core layout and flux distribution of 2D C5G7 quarter core图1 二维C5G7 1/4堆芯的布置和标通量分布
2种硬件环境下的编译器均选择GNU编译器,编译过程支持C++0x特性。固定C5G7例题的数值计算分辨率参数(能群数7,方位角个数16,特征线间距0.1 cm),编译优化选项首先取为O0等级,OpenMOC性能对比如表6所示。

Table 6 Test comparison of OpenMOC using O0 optimization in Intel environment and Phytium environment
编译优化选项为O2等级,OpenMOC性能对比如表7所示。

Table 7 Test comparison of OpenMOC using O2 optimization in Intel environment and Phytium environment
编译优化选项为O3等级,OpenMOC性能对比如表8所示。

Table 8 Test comparison of OpenMOC using O3 optimization in Intel environment and Phytium environment
上述测试完成之后可以明确,OpenMOC在飞腾结点和Intel处理器环境中的计算结果保持一致,但在每种编译优化等级条件下飞腾结点的计算效率均低于Intel处理器的计算效率,比值相差约为3~4倍,高于两者之间的频率差异。随着编译优化等级的提升,2种计算环境中的效率差距有所缩小,不同于3.2节移植程序的特点,O2选项和O3选项在2种硬件环境下对于计算效率的改善相差不大,说明OpenMOC程序编程实现的特征线方法使用O3的优化等级并不会对生成的可执行程序的效率有更好的改善。
3.5 KYLIN2
KYLIN2程序使用二维特征线输运算法集成燃耗计算用于生成组件截面库,本文选取0.8.8版本KYLIN2移植到ARM环境中,源代码按照多个目录进行组织,每个目录代表一个功能模块,其整体计算步骤如下所示:
(1)计算参数的初始化和内存空间分配;
(2)读取输入文件;
(3)获取计算基干的数据库文件;
(4)判断计算类型,执行组件计算或燃料分支计算;
(5)判断燃耗步是否结束,结束则整个计算完成,否则转回步骤(2)。
移植过程的主要工作分为2个方面,一方面是重写编译脚本来对这种多目录组织的源代码进行定制编译和链接,规范化整个程序的软件结构和执行顺序;另一方面是移植和修订程序使用的第三方内容。在飞腾计算环境中不能使用MKL函数库,因此需要对KYLIN2的程序代码进行调整,去除依赖性。为了不破坏已有的程序代码,在移植修订过程中通过宏开关来对改动代码进行处理,宏的判断标准为是否是ARM64硬件平台。
#ifdef__aarch64__
(新增的修订代码)
#else
(原有代码)
#endif
调用的MKL求解函数LAPACKE_dgesv用于求解Ax=B,其中A和B为矩阵。实质为使用LAPACKE中的求解函数,安装Netlib提供的LAPACK和LAPACKE,替换MKL求解函数。调用MKL求解函数PARDISO,该函数使用直接消去法求解稀疏线性方程组Ax=b,其中A为矩阵,b为右手向量。使用SuperLU软件(SuperLU软件较为知名,是由劳伦斯伯克利国家实验室研制的稀疏矩阵直接法求解函数库)来应用直接消去法进行求解,替换MKL的求解函数。
移植完成之后,可在Intel结点和飞腾结点上使用同一套KYLIN2程序代码。本文使用表9列举的2个组件例题进行数值测试和验证,统计相应的计算结果来论证其正确性和计算效率。

Table 9 Assembly testing examples for KYLIN2 program
正确性方面的对比按照燃耗深度与有效增殖因子(keff)的关系图给出,计算效率则给出同一例题在不同计算环境中的总运行时间。2个例题均需要迭代多个燃耗步,有限增殖因子随燃耗深度的变化趋势如图2所示,其中参考解选取的是原始KYLIN2程序使用MKL函数库在Intel环境中的运行结果,根据3.4节的分析结果,统一选取的编译优化选项为O2等级。图2中横坐标均为“燃耗步数”,纵坐标均为“有效增殖因子”,二者均无单位。
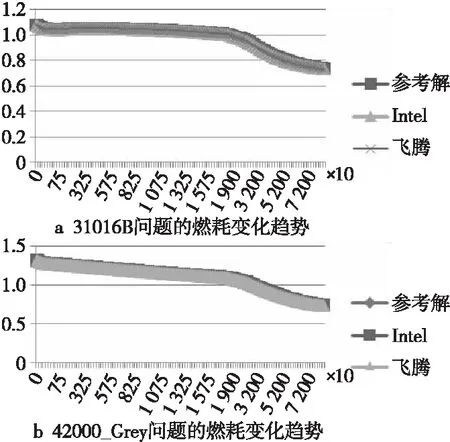
Figure 2 Burn-up change trend graph of two examples图2 2个例题的燃耗变化趋势图
从图2中可以看到,2种硬件环境中增殖因子随燃耗深度的变化趋势互相吻合,经过较长时间的迭代计算之后数值稳定性均未发生变化。2个例题在2种硬件环境中的串行运行时间如表10所示。
根据以上的移植和测试,可以得出KYLIN2程序运行这2个例题在飞腾计算环境与Intel计算环境中的效率差距在6~8倍,远高于处理器频率之间的差别。这一方面是由于组件计算过程中使用的数据量较大;另一方面是由于ARM精简指令的运行方式在数值计算的细节上相比Intel处理器略有不足,KYLIN2程序可供优化的数值操作较多。尽管如此,KYLIN2程序底层的数值求解方法的替换对数值稳定性没有影响,飞腾计算结点上数值计算的准确性与Intel计算环境没有明显差异。
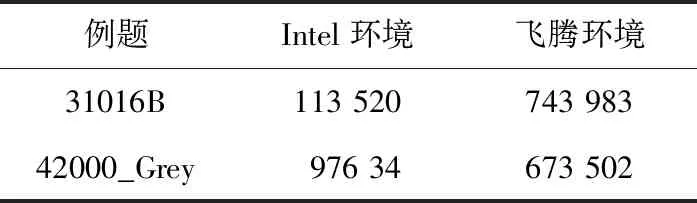
Table 10 Serial running time of two examples
4 KYLIN2的OpenMP并行优化
实际工程应用需要反复调用KYLIN2,生成不同工况点下的大量组件截面库,计算效率成为了应用的瓶颈。由飞腾处理器构建的集群计算机结点通常具备多个处理器核心,具备共享式内存并行的能力。对KYLIN2的输运计算模块编写相应的OpenMP共享式内存并行版本KYLIN2-OpenMP,一方面在飞腾处理器为代表的ARM计算环境中提升KYLIN2程序的计算效率;另一方面也用于论证单个飞腾计算结点的并行性能,增强国产芯片的实用性。本文使用2种常见于学术论文的组件基准例题(压水堆组件AFA3G和C5G7基准例题UO2组件)进行测试,给出对正确性和计算效率的对比结果。
先对KYLIN2程序不使用粗网加速算法的情况进行统计,根据3.4节和3.5节的讨论,编译优化选项选为O2等级,相应的计算结果和串行计算效率统计如表11所示。飞腾计算结点在求解AFA3G组件问题时耗时较长,与Intel环境中的耗时相差1个数量级(10倍)。

Table 11 Results and running time of KYLIN2 without GCMFD表11 无粗网加速的KYLIN2运行结果和时间统计
粗网加速算法将减少数值迭代次数,缩短串行运行时间。表12统计相应的运行时间,编译优化选项仍然选为O2等级。

Table 12 Results and running time of KYLIN2 with GCMFD表12 粗网加速的KYLIN2运行结果和时间统计
特征线方法内数值方法的局部改变并不会改变程序内数据的内存布局,处理器之间的性能差异仍然保持在1个数量级左右。现阶段实际应用KYLIN2程序时往往在Intel处理器环境中使用单个处理器核心来运行例题,表12中数据表明飞腾处理器不能直接应用于堆芯程序的研发阶段,因其有可能降低程序的运行效率。考虑到KYLIN2程序在特征线非模块化布置情况下,对组件问题的能群循环参数引入OpenMP共享式内存并行是论证ARM环境中使用飞腾处理器多个处理器核心的较好选择。特征线方法内能群并行的OpenMP并行算法伪代码列举如下:
setcurrent←0;
setangular_flux←0;
#pragma omp parallel for default(shared) private(current) schedule(guided)
forg=1:GROUPS
forray=1:RAYS
forp=1:POLARS
current←FC(g,ray,p);
#pragma omp parallel reduction(+:sum)
angularflux←sweepFC(g,ray,p,current);
current←FB(g,ray,p);
#pragma omp parallel reduction(+:sum)
mesh_angular_flux←sweepFB(g,ray,p,current);
endfor
endfor
endfor
该算法中函数FC和FB不存在数据争用的情况,遍历特征线更新角中子通量密度的操作sweepFC和sweepFB需要使用OpenMP的互斥操作。KYLIN2-OpenMP多线程版本在2种硬件环境中进行了较多测试,限于篇幅这里仅给出C5G7 UO2组件例题不使用粗网加速算法的统计结果(AFA3G组件例题有类似结果)。实验时考虑使用的最多处理器核心数量为12个,线程数取值参数取为1,2,4,8或12。2种硬件环境中的计算结果保持一致,这里重点分析计算所消耗的时间。
如图3所示,2种硬件环境下C5G7组件例题的计算效率在O2优化等级下均通过多线程并行取得效率的提升(处理器核数超过8个之后并不能带来计算效率的改善,这是由于C5G7例题的能群循环结构只有7个,超过数量7之后OpenMP并行增益达到上限)。使用单个线程运行时飞腾计算结点耗时11 123 s,在Intel环境中耗时1 205 s。使用8个线程时飞腾计算结点运行时间为1 598 s,Intel环境下的运行时间为120 s。整体趋势上飞腾计算结点的计算效率与在Intel环境中的计算效率差距在缩小,且使用8个线程后飞腾处理器运行C5G7组件例题的效率与参照对象Intel处理器的单核运行时间接近。当集群计算机的商用计算资源紧张时,由于国产计算结点使用人数较少,此多线程并行版本的临时解决方案可达成使用ARM计算环境临时替换商用计算环境来执行工程计算任务的需求(现阶段商用处理器计算结点经常使用单线程来运行KYLIN2程序)。
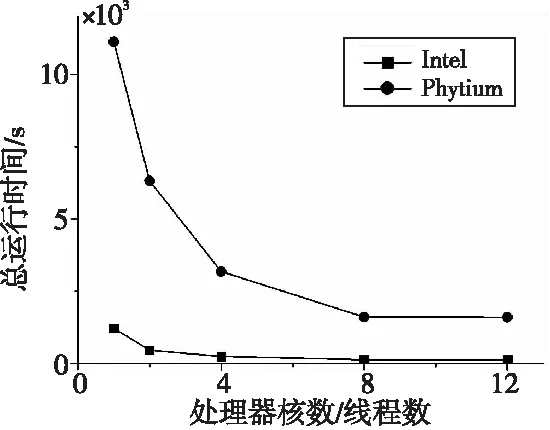
Figure 3 Running time of assembly example after OpenMP programming图3 引入OpenMP并行后的组件例题运行时间
5 结束语
在内部集群计算机的飞腾计算结点上进行堆芯程序的移植和测试,探讨国产芯片构建的计算环境应用于工程计算的可行性,形成的结论为:
(1)所有的程序均移植成功,由飞腾处理器构建的ARM计算环境具备通用计算的特点,适用于堆芯数值计算程序的研制和运行。移植的程序在飞腾计算结点上的串行计算效率均低于在参照对象Intel处理器上的串行计算效率,且不管在何种编译优化等级条件下,计算时间的比值均超过处理器频率之间的2倍差异,小规模堆芯例题的差异保持在3~4倍,较大规模堆芯例题的串行计算效率差异更大。
(2)移植过程的堆芯程序能够在不同硬件环境中获得一致的计算结果(偏差范围内),确保了数值计算的稳定性。
(3)飞腾计算结点上的数值计算运行效率较低,一方面是由于底层函数库为了适应精简指令集特性和通用计算的特性,需要执行更多的指令来完成某些数值计算;另一方面也由于飞腾处理器本身与参照对象Intel处理器之间的硬件架构差异。Intel商用处理器的复杂指令集存在多种复合指令,完成部分计算需要更少的指令周期,但通过对KYLIN2程序进行局部的OpenMP多线程优化,可以使得国产飞腾处理器对应的ARM计算环境能够临时替换商用处理器的串行运行环境,成为工程计算的补充资源。
现阶段各个样本程序在集群计算机的飞腾计算结点上逐步开展移植和运行,以期充分利用这部分计算资源。国产处理器及其生态环境持续发展拓宽了核反应堆工程计算与计算机科学的融合领域。横向借鉴日本、美国等经验,核反应堆工程计算在后续发展过程可以覆盖更多的计算硬件,提升适用性和交叉验证,更快和更准确地为反应堆设计和应用进行服务。本文形成的结论和记录的技术细节将随着后续在国产计算结点上开展程序研制和移植的工作进行深化和扩展。
致 谢
本研究工作感谢中国核动力研究设计院设计所九室提供的样本程序和集群运行环境,同时也感谢相关人员对论文的建议。
