基于深度学习和证据理论的表情识别模型*
2021-05-11徐其华
徐其华,孙 波
(1.西北师范大学商学院,甘肃 兰州 730070;2.北京师范大学人工智能学院,北京 100875)
1 引言
表情是人类在进行社会活动时心理感受和精神状态的自然流露,通过观察一个人的面部细微变化,就能判断出他此时的内心情感。根据心理学家Mehrabian[1]的研究,一个人想要表达出来的全部信息,口头语言只占7%,语言辅助(如语调、语速等)占38%,而面部表情却占了55%,因此大量有价值的信息都可以通过面部表情获取。而且相对于生理信号,面部表情的数据更加容易获得,因此受到更多人的关注。
随着计算机技术、传感技术和通讯技术的发展,高清摄像头的使用越来越普遍,特别是智能手机的广泛应用,获取一小段带有人脸的高清视频是非常容易的事情。通过深度学习技术对带有人脸的高清视频片段进行自动分析,识别出视频中人脸的表情,识别结果不仅能在各种系统中帮助人机进行高效交互,而且还能应用在现实生活中的不同领域。
面部表情是指通过眼部肌肉、颜面肌肉和口部肌肉的变化来表现各种情绪状态,是人类内心情感比较直接的一种表达方式。根据科学家们的研究,人类有7种基本情感,即快乐、悲伤、愤怒、厌恶、惊讶、恐惧和中性。表情识别的研究,实际上可以认为是对这7类情感的模式分类问题。随着人工智能的发展和实际应用需求的推动,基于微视频的自发性表情识别已经取得了不错的研究进展,涌现出了各种各样的表情自动识别模型,如EmoNets[2]、VGG-Net(Visual Geometry Group-Network)[3]、HoloNet[4]、VGG-LSTM(Visual Geometry Group-Long Short Term Memory)[5]和C3Ds(3-Dimensional Convolutional neural networks)[6]等,但总体来说,这些模型在各种表情识别竞赛中都取得了不错的成绩。这些模型的识别准确率还不尽人意,远远低于人类肉眼的识别准确率,还不能在社会各个领域中进行广泛应用。
本文针对表情智能识别过程中存在的一些关键性问题,设计了一个全自动表情识别模型,并在该模型中构建了一个深度自编码网络来自动学习人脸表情特征,并结合证据理论对多分类结果进行有效融合。在一些公开的表情识别库上的实验结果表明,该模型能显著提升表情识别的准确度,性能优于大部分现有的表情识别模型。
2 研究现状
表情识别是在人脸检测的基础上发展起来的,和人脸识别一样,也包括人脸检测、图像预处理、面部特征提取和分类识别等过程。随着深度学习技术的广泛应用,表情识别方法也逐渐由传统的浅层学习方法向深度学习方法过渡。近些年来,表情识别技术的研究得到了学术界持续的重视,与之相关的情感识别竞赛也吸引了越来越多的人参加。其中由国际计算机协会多模态人机交互国际会议ACM ICMI(ACM International Conference on Multimodal Interaction)主办的情感识别大赛EmotiW(Emotion recognition in the Wild)是世界范围内情感识别领域最高级别、最具权威性的竞赛,吸引了世界顶尖科研机构和院校参与,微软美国研究院、Intel研究院、IBM研究院、美国密西根大学、美国波士顿大学、新加坡国立大学、北京大学和爱奇艺等均参加了比赛。该赛事每年举办一次,从2013年开始,迄今已连续举办了8届。国内举办的情感识别竞赛起步比较晚,由中国科学院自动化研究所领头举办的多模态情感竞赛MEC(Multimodal Emotion Recognition),迄今只举办了2次[7,8]。这些竞赛的定期举办,吸引了情感识别研究领域大部分研究机构参加,对该领域的交流和发展起到了巨大的推动作用。
面部表情特征提取在整个表情识别过程中具有非常重要的作用,特征提取的好坏直接影响着最终的识别准确度。在广泛使用深度学习技术提取表情特征之前,研究者们主要提取一些传统的手工特征,如基于纹理信息变化的Gabor特征[9,10]和局部二值模式LBP(Local Binary Pattern)特征[11],以及在两者基础上扩展的LGBP(Local Gabor Binary Pattern)特征[12]和LBP-TOP(Local Binary Patterns from Three Orthogonal Planes)特征[13];基于梯度信息变化的尺度不变性特征变换特征SIFT(Scale Invariant Feature Transform)[14]、方向梯度直方图HOG(Histogram of Oriented Gradient)特征[15,16]和局部相位量化LPQ(Local Phase Quantization)特征[17],以及在这3种特征上扩展的特征,如Dense SIFT、 MDSF(Multi-scale Dense SIFT Features)[18]、 PHOG(Pyramid of Histogram Of Gradients)[19]等。这些传统的手工特征在刚提出时,都取得了不错的效果。但是,这些特征在提取时容易受到干扰,对光照强度、局部遮挡和个体差异都非常敏感,而且提取的特征向量维度一般比较大,需要和其它的特征降维方法结合使用。
随着深度学习技术的应用,基于深度神经网络的面部特征自动学习方法逐渐成为热门。这类方法从局部到整体对面部信息进行统计,得到一些面部特征的统计描述,简称为深度学习方法。深度学习方法本质上就是研究者们首先构建一个深度神经网络,然后利用大量样本进行训练,让机器自动统计其中的变化规律,从而学习出有效的特征表示。深度学习方法不同于浅层学习方法,它将特征学习和分类识别结合在一起,不需要单独提取出特征之后再进行分类。集特征提取和分类识别于一体的深度神经网络模型近些年发展得比较快,比较典型的模型如表1所示。基于深度学习技术的特征学习方法虽然对旋转、平移和尺度变换都有着很强的鲁棒性,但也有着所有特征提取方法共同的缺陷:易受到噪声干扰。而且深度学习还需要大量的样本进行训练,如果样本量太少,效果则不如别的方法好。

Table 1 Facial expression recognition models
基于深度神经网络的特征学习方法虽然是现在使用的主流特征提取方法,但它也不能完全替代传统的手工提取方法,大部分研究者的做法是同时使用多种方法提取特征,然后进行特征级融合,或者先对每个特征进行分类识别,再进行决策级融合。也有研究者先提取传统的手工特征,再将这些特征融入到深度神经网络进行特征再学习[29 - 31]。本文构建的表情识别模型也提取了多种特征,并使用证据理论方法进行决策级融合。
3 面部表情特征提取
每一幅面部表情图像都来自于视频中的一帧,在这帧图像中,除了人的面部信息,还有大量的背景信息。在进行特征提取时,需要先进行面部检测,只提取人物面部的特征。背景信息对人物情感识别没有太大的帮助作用,需要剔除。本文采用开源的人脸检测算法DSFD(Dual Shot Face Detector)[32]来完成人脸检测,通过该算法,可以将视频转换成面部表情图像序列。
3.1 SA-DAE表情识别模型
基于微视频的表情识别,都是一个视频对应一个表情标签,不进行单视频帧标注。大部分研究者在进行面部表情特征提取时,通常的做法是将整个视频的表情标签默认为每个帧的标签,再进行深度神经网络模型训练。这样做有很大的缺陷,会造成大量的图像样本标注错误。针对此种情况,本文将自适应注意力模型与自编码网络相结合,构建了一个SA-DAE(Self-Attention Deep AutoEncoder)模型。该模型不仅可以以非监督方式提取面部表情特征,还能对传统的卷积神经网络进行改进,在不增加参数规模的前提下,最大可能地获取全局信息。
本文构建的SA-DAE网络如图1所示,该模型是对原始的自编码网络的一种改进,将原来的全连接层全部改成了卷积层或反卷积层,并在其中加入了自注意力层。模型训练好后,输入一幅新的人脸图像,经过编码网络就能提取出该人脸的面部行为特征。
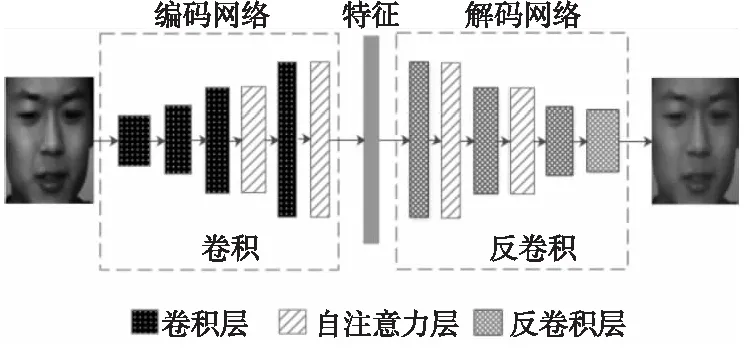
Figure 1 SA-DAE network model图1 SA-DAE网络模型
通过人脸检测后,每个微视频就转换成了一个人脸图像序列,然后将序列中每一幅人脸图像输入到已经训练好的SA-DAE网络中,根据自编码网络的特性,对每帧图像进行非监督特征提取。
3.2 自注意力机制
卷积神经网络的核心是卷积操作,不同于全连接,它以局部感受野和权值共享为特点,对某个区域进行卷积操作时,默认只与周围小范围内区域有关,与其它部分无关。卷积操作的这种特性大大减少了参数量,加快了整个模型的运行过程,因此相对于全连接层,实现卷积操作的卷积层一直是深度神经网络中的首选。但就因为这些特性,导致了卷积操作的弊端:会丢失一些空间上的关联信息。如果一幅图像中2个区域离得比较远,但却是相互关联的,比如人脸具有对称性,在进行表情识别时,左右眼角、左右嘴角是有空间联系的,卷积操作忽略了这一个问题,默认这2个区域无关联,从而丢失一些至关重要的空间关联信息。解决方法就是扩大卷积核,但卷积核太大时,参数量又会呈直线上升。为了在参数量和卷积范围之间找到一个平衡,本文模型引入自注意力机制,该机制既考虑到了非局部卷积问题,又考虑到了参数量问题,具体实现如图2所示。
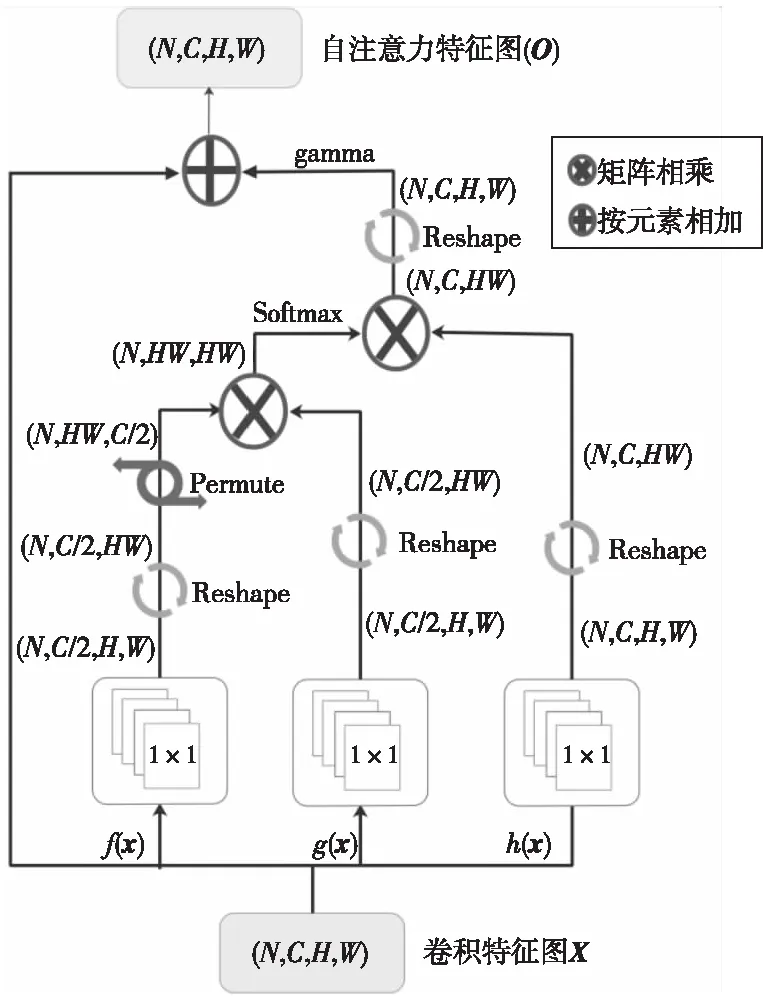
Figure 2 Flow chart of Self-Attention图2 Self-Attention层实现流程
经过前一层的卷积操作后,会得到很多的卷积特征图(Convolutional Feature Maps),在进行下一层的卷积操作之前,SA-DAE模型将这些卷积特征图输入到一个自注意力层中,提取这些图中包含的全局空间信息。实施细节主要包括:
(1)自注意力层的输入是该批次所有图像卷积操作后得到的特征图X∈RN×C×H×W,是一个4维的张量,其中,N和C分别表示图像的批次大小和通道数量,H和W分别表示每幅特征图的高度和宽度。自注意力层将每幅特征图分别进行f(x)、g(x)和h(x)变换,这3种变换都是普通的1×1卷积,差别只在于输出通道数量不同。变换之后再分别进行Reshape操作,即将特征图进行序列化,张量由4维变成3维,以便于后继的矩阵运算。这一阶段的操作如式(1)所示:
F=Reshape(f(x))=Reshape(Wfx)
G=Reshape(g(x))=Reshape(Wgx)
H=Reshape(h(x))=Reshape(Whx)
(1)
其中,x∈RW×H表示单幅图像卷积后的特征图,Wf、Wg和Wh分别表示3种卷积变换时的权值参数,F、G和H分别表示此阶段3种操作后得到的3个张量。
(2)接着,自注意力层将张量F的后2维进行转置,并和张量G进行张量相乘,这步操作主要用来计算特征图任意2个位置之间的信息相关性,然后再通过Softmax函数进行归一化。这个阶段操作公式如式(2)所示:
S=Softmax(FT·G)
(2)
其中S∈RN×HW×HW为归一化后的相关性张量。
(3)最后,将H和S进行张量相乘,主要作用是将计算出的信息相关性作为权重加权到原位置的特征信息上,随后通过Reshape变换将3维的结果张量恢复成4维,得到自注意力特征图(Self-Attention Feature Maps)。最终模型把全局空间信息和局部邻域信息整合到一起,融合得到加入了注意力机制的特征图。此阶段的操作如式(3)所示:
O=X+γ(Reshape(H·S))
(3)
其中,X表示自注意力层的原始输入,O表示自注意力层的输出。自注意力层的最终输出兼顾了局部邻域信息和全局空间相关信息,这里引入了一个参数γ作为平衡因子,表示全局空间相关信息相对于邻域信息所占的权重,γ刚开始时初始化为0,为的是让模型首先关注邻域信息,之后随着训练的迭代,再慢慢把权重变大,让模型更多地关注到范围更广的全局空间相关信息。
4 表情自动识别模型
4.1 Dempster-Shafer证据理论融合策略
不同的特征表征着不同的辨别信息,将这些信息的分类结果进行融合,可以有效地互补。本文除了使用SA-DAE网络自动提取面部表情特征,还通过其它成熟的特征提取算法提取了一些传统的手工特征,如LBP-TOP、HOG和DSIFT等,使用不同的特征进行分类会得到不同的分类结果,这就需要采用信息融合方法对不同的分类结果进行融合。
某一个样本应该分在哪一类,这是不确定的,同一个样本,通过不同的特征信息进行分类,也有可能分在完全不同的类。这种模式分类的不确定性和模糊性,刚好与不确定性推理原理相吻合,因此本文将不确定推理方法中的D-S(Dempster-Shafer)证据理论引入到分类结果融合策略中。
在经典的D-S证据理论中,Θ表示识别框架,它包含了n个不相容的命题,数学符号表示为Θ={Aj│1≤j≤n},Ω=2Θ是Θ的幂集,函数m:2Θ→[0,1]将所有命题的幂集全部映射到一个概率值(取值为0~1),满足下列2个条件:
m(Φ)=0
(4)
(5)
其中,函数m()称为基本概率分配BPA(Basic Probability Assignment)函数,也称为mass函数。Φ表示空集或Ω中不存在的命题,Ai表示Ω中的任意一个命题,m(Ai)表示在识别框架中证据对某个命题Ai的精确信任度,也可以认为是证据在命题Ai处的概率。D-S证据理论的融合规则如下:
(6)
其中,Ai,Aj,Ak都表示任意一个命题,即Ai,Aj,Ak∈Θ, (m1⊕m2)(Ai)表示第1个证据和第2个证据在命题Ai处的融合。如果所有命题间都是相互独立的,则在Ai处的融合概率就是2个证据的概率乘积,即m1(A1)×m2(Ai),如果2个命题有交集(即Aj∩Ak=Ai,例如复合表情间就存在交集),且交集为命题Ai,则在Ai处的融合概率是所有相交元素的概率乘积之和。α表示归一化因子,反映了证据之间的冲突程度,计算公式如式(7)所示:
(7)
其中,Aj∩Ak=∅表示2种命题间无交集(相互独立),则二者的mass函数值乘积就可以用来衡量证据间的冲突程度。当α趋近于0时,表示两证据之间无冲突,可以完全融合;反之,当α趋近于1时,表示两证据之间高度冲突,融合效果会很差。

Figure 3 Model for multi-feature facial expression recognition图3 多特征面部表情识别模型
在具体的表情识别模型中,每个命题即是一种表情类别,每个特征即为一个证据。mass函数则代表某个特征对某种表情的信任度,即在某种特征下,视频被分为该类表情的概率。在本文提出的表情自动识别模型中,先利用随机森林算法对每个特征分别进行分类,每个特征的分类结果为一个7维的概率向量,向量中的每个值表示视频在该特征情况下分类为某种表情类别的概率。如果有m个特征,则最终的分类结果为一个m×7的矩阵。模型再通过D-S证据理论的融合规则,把多个不同的分类结果向量融合成一个概率向量。
4.2 表情识别总体模型
表情的自动识别,需要经过人脸检测、特征提取、特征聚合、分类识别和结果融合等流程,本文将这些分散的模块结合在一起,就构成了一个全自动表情识别模型,模型结构如图3所示。在经过人脸检测得到微视频中人脸图像序列后,该模型能自动学习深度神经网络特征,也能提取一些传统的手工特征;随后通过一个长短期记忆网络LSTM(Long Short-Term Memory)将多个帧级特征聚合成视频级特征,再分别经过随机森林分类得到不同特征的分类结果;最后经过D-S证据理论对分类结果进行融合后,即可得到最终的面部表情识别结果。
5 实验结果及分析
5.1 数据集
本文在中国科学院自动化研究所构建的CHEAVD2.0数据库上进行了实验,实验结果与第2届多模态情感识别竞赛(MEC 2017)的参赛结果进行了对比。CHEAVD2.0数据库的数据来源于影视剧中所截取的音视频片段,每一个音视频片段分别标注为一些常见情感(高兴、悲伤、生气、惊讶、厌恶、担心、焦虑)及中性情感中的一种。整个数据库将被分为训练集、验证集和测试集3部分,在文献[8]中,中国科学院自动化研究所的研究者们对这个数据库的建库过程、数据来源和数据划分进行了详细的说明。同时,他们对库中的每一段音视频也进行了特征提取和分类,并将分类结果作为该库的基线水平,以便其它研究者进行对比分析。由于本文未收集到测试集的标签,因此本文用训练集来进行整个表情识别模型的训练,用验证集来验证模型的性能。在进行SA-DAE模型训练时,本文使用了迁移学习方法,先用大型人脸库CeleA进行初步训练,训练出来的模型参数再用CHEAVD2.0数据库进行微调。
5.2 评价指标
考虑到样本数据分布的不均衡性,本文以宏观平均精确度MAP(Macro Average Precision)作为模型的第1评价指标,以分类准确度ACC(Accuracy)作为第2评价指标。2个评价指标的公式如式(8)~式(10)所示:
(8)
(9)
(10)
其中,s表示表情的类别数,Pi表示第i类表情的分类准确度,TPi和FPi分别表示在第i类表情上分类正确的样本数量和分类错误的样本数量。
5.3 实验结果分析
针对每一个视频,本文分别提取了SA-DAE、CNN、DSIFT、HOG、HOG-LBP和LBP-TOP 6种特征。其中CNN特征是采用VGG网络模型经有监督训练提取出来的特征,HOG-LBP特征是仿照LBP-TOP算法提取出来的特征,由xy面的HOG特征与yz、xz的LBP特征串联而成。各特征在验证集上的分类结果如表2所示。

Table 2 Feature classification and recognition results on verification set
各特征提取出来后都通过随机森林算法进行分类,在验证集上的分类结果如表2所示。其中,a表示随机森林算法中决策树的数量,b表示随机森林算法中决策树的深度,针对不同的特征,这2个参数的取值并不相同,需要在训练集上进行交叉搜索训练得到。
根据结果显示,在宏观平均精确度(MAP)评价指标上,SA-DAE特征的分类效果优于其它特征的,但在分类准确度(ACC)的评价指标上,SA-DAE特征和传统的DSIFT、HOG特征,分类效果没有太大的差别。
在决策级融合阶段,本文先将所有的特征按照分类准确度从高到低进行了排序,然后将准确度最高的SA-DAE特征作为基础,按照顺序将其它特征逐项融合进来。SA-DAE、DSIFT和HOG 3个特征融合之后,分类效果有了较大的提升,但融合进第4个特征后,分类效果出现了下降,因此本文又以SA-DAE+DSFIT+HOG的融合特征作为基础,与剩下的特征进行穷举组合,最终得到不同特征融合的分类结果,如表3所示。在宏观平均精确度(MAP)评价指标上,SA-DAE、DSIFT、HOG、HOG-LBP 4种特征的证据理论融合效果最好,达到了53.39%,在分类准确度(ACC)的评价指标上,SA-DAE、DSIFT、HOG、HOG-LBP和CNN 5种特征融合效果优于其它特征融合策略的。
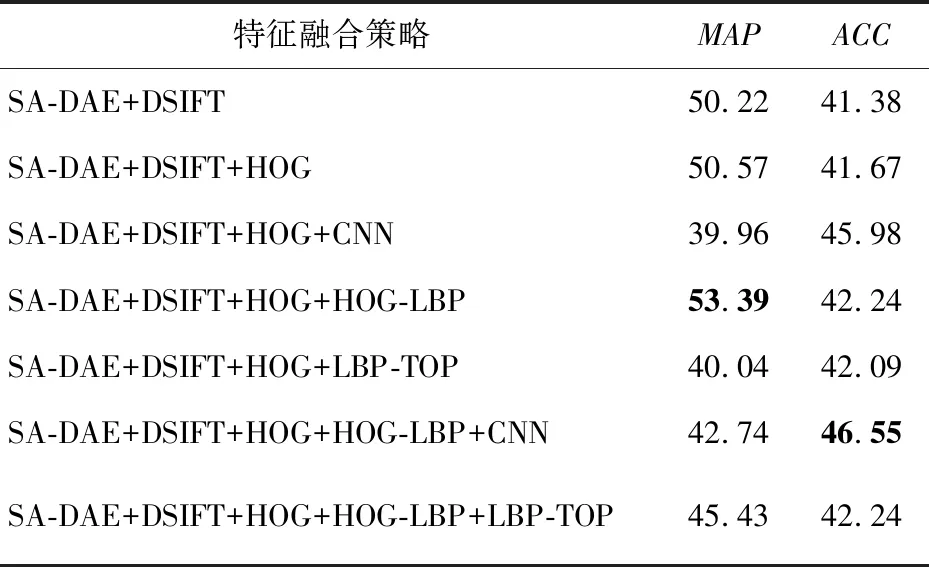
Table 3 Feature fusion classification and recognition results on verification set
最后,本文将提出的表情识别模型也应用到了数据库的测试集上,并根据数据库提供方反馈的识别结果,与数据库的分类识别基线水平进行了对比(如表4所示),本文提出的模型不管是在验证集上还是在测试集上,识别准确度都取得了不错的效果,远远超过了基线水平。
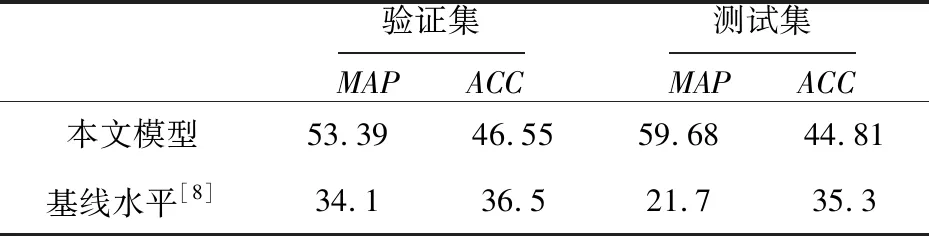
Table 4 Classification and recognition results on verification set and test set
6 结束语
本文结合深度自编码网络、自注意力模型和D-S证据理论,构建了一个表情自动识别模型。实验结果显示,该模型提取的非监督深度学习特征的分类效果优于其它特征的。在多特征分类结果融合方面,该模型也取得了不错的成绩,识别效果远远高于基线水平。但是,模型识别的准确度还远远落后于人类肉眼的识别能力,表情自动识别在现实生活中的应用,还有很长的一段路要走。
