Proto-Perf:快速精确的通用处理器原型系统性能评估方法*
2021-05-11黄立波隋兵才王永文
郭 辉,黄立波,郑 重,隋兵才,王永文
(国防科技大学计算机学院,湖南 长沙 410073)
1 引言
众所周知,处理器设计和制造是当今世界上最复杂的项目之一。整个处理器设计和制造的过程包含体系结构设计、处理器前端设计、处理器后端设计、功能验证和性能评估等一系列设计流程。因此,不仅处理器的设计和制造需要巨大的资金投入,而且一款处理器从开始设计到最终投向市场,整个项目研发的周期通常需要几年的时间。最近,得益于RISC-V架构处理器的快速发展,硬件敏捷开发方法逐渐成为一种流行的趋势。采用敏捷开发方法设计处理器在一定程度上简化了体系结构设计、处理器前端设计和功能验证,从而缩短了处理器的研发周期。但是,处理器前端代码在sign-off之前的性能评估和验证始终是一个相当耗费时间的流程,进而会拖延整个项目的进度。
通常来讲,工业界和学术界常常使用一些标准的测试程序集来评估处理器的性能。这些标准测试程序集分别从不同角度对整个处理器系统进行评价,包括计算峰值、访存延迟、分支预测和片上缓存等。例如,SPEC CPU2000/2006/2017是一系列通用处理器标准测试程序集,主要测试处理器运行通用应用程序的能力,而LINPACK则主要用来评估处理器的浮点计算能力,常常被用来作为超级计算机系统的一个评价指标。测试人员通过完整地运行整个测试程序集可以获得相应的测试报告。通过测试报告,测试人员可以清楚地了解处理器的性能,也可以比较不同处理器间的性能差异。
处理器原型系统的早期性能验证一方面可以帮助设计人员尽早发现处理器设计和实现阶段存在的缺陷,另一方面也可以帮助设计人员探索处理器体系结构可优化的空间。目前,通用处理器的设计及研发前期的主要验证平台包括软件模拟器[1 - 3]、FPGA原型系统[4 - 6]和硬件仿真器[7,8]等。相比于真实的处理器芯片,这些平台的一个共同特点是运行频率非常低,从几兆赫兹到几十兆赫兹不等。在这种情况下,一个在真实芯片上运行一天的测试程序集,在这些处理器验证测试平台上,常常需要运行几周或几个月的时间。这就导致设计人员无法及时分析RTL实现的处理器性能,延长了处理器性能验证的周期,进而拖延了整个项目进度。因此,在处理器原型系统上完整地运行测试程序集进行性能测试是不可行的。
另一方面,虽然已经有一些软件模拟器开始支持快速精确的处理器性能评估[9,10],但是软件模拟器的实现与实际RTL设计代码存在巨大的差异,导致通过软件模拟器获得的性能测试结果无法反映RTL实现的处理器的真实性能。因此,实现快速精确的早期处理器性能评估是实现硬件敏捷开发的一项迫切需求。
程序分析领域的研究发现,程序执行具有明显的阶段性特征,并且很多执行阶段会在整个程序执行过程中不断重复出现。因此,如果能够在测试前充分分析测试程序,并抽取出每个阶段的指令序列,那么就可以只在处理器原型系统上执行这些指令序列,从而减少程序执行时间。在测试完各阶段的所有指令序列后,可以根据每个阶段指令序列的性能以及该阶段在程序中所占比重推测出处理器原型系统运行整个程序的性能。基于这个思想,本文提出一种快速准确的处理器原型系统性能评估方法Proto-Perf。
本文的主要贡献如下所示:
(1)本文提出一种基于动态程序分析和基本块向量聚类分析的处理器原型系统性能评估方法Proto-Perf,该方法可以显著缩短程序测试的时间,同时可以提供较高精确度的性能测试结果。
(2)Proto-Perf使用简单,并且可以跨不同处理器验证平台工作。
(3)实验结果表明,Proto-Perf可以在非常短的时间内精确地测算出处理器原型系统的性能。
本文的其余部分为:第2节介绍快速精确的通用处理器FPGA原型系统性能评估方法的研究动机,第3节介绍Proto-Perf性能评估方法,第4节介绍Proto-Perf在处理器FPGA原型系统上的实验测试结果,最后第5节对全文进行总结。
2 研究动机
实现快速精确的通用处理器FPGA原型系统性能评估的首要任务是减少测试程序集的运行时间。一种最简单的降低性能评估时间开销的方法是减小测试数据集的大小,比如对于SPEC CPU2006的程序,使用test规模的数据集进行测试,或者减少测试程序集中测试程序的数量。那么,完整的测试程序集性能就需要依据缩减后的测试程序集的性能进行推算。Phansalkar等人[11]提出了一种使用统计学方法建立SPEC CPU2006测试子集的测试方法。这种方法虽然一定程度上减少了程序集的测试时间,但是测试结果的精确度却下降了很多。而且,即使测试子集中的程序数量相比于完整测试程序集减少了很多,但是对于处理器FPGA原型系统来说,完整测试该子集仍然需要大量的时间。
目前,一部分通用处理器制造商,比如Intel和ARM,已经在软件模拟器上广泛使用SimPoint[12]机制来分析和预测下一代处理器体系结构的性能提升。该方法的主要思想是通过程序分析将原应用程序的指令序列划分为多个指令序列片段,从中选择出一些有代表性的指令序列作为测试样例,最后通过在软件模拟器上执行这些测试样例来获得测试程序的性能。每个程序的测试样例都是根据程序本身的执行特点从具有相似程序行为的指令序列中抽取出来的,因此这些测试样例在程序行为的表现上与原应用程序几乎一致,从而保证模拟器只需执行这些测试样例就可以在短时间内获得精确的性能数据。但是,使用软件模拟器进行性能评估只能在处理器项目研发前期作为探索处理器架构设计的一种方法,并不能检测处理器前端设计中是否引入了性能缺陷。另外,在芯片流片之前,验证处理器原型系统的性能、进一步优化处理器设计并确保设计的处理器能够达到预期性能指标是非常必需的工作。因此,设计一种面向硬件验证平台的快速精确的性能分析方法是非常重要的。
3 Proto-Perf性能评估方法
本节主要介绍面向通用处理器原型验证系统的性能评估方法Proto-Perf。Proto-Perf主要包含生成代码基本块向量、筛选程序指令流片段、生成程序指令流片段检查点和计算处理器原型验证系统性能等步骤。
3.1 生成代码基本块向量
Proto-Perf性能评估方法降低程序测试时间开销的基本思想与Intel和ARM在软件模拟的性能评估中应用的方法相似,即执行应用程序部分指令流序列而不是整个应用程序。因此,从应用程序指令流中筛选出来的指令流序列的覆盖率就决定了最终使用Proto-Perf方法计算出来的处理器性能的精确度。在程序分析领域,动态程序分析是一项比较成熟的技术,它在预先执行整个应用程序的过程中捕获应用程序的动态行为,从而可以掌握应用程序的行为特点。代码基本块是一段连续的程序指令序列,只有一个入口指令和一个出口指令,是程序分析中构成指令流序列最基本的单元。通过分析每个指令流序列的代码基本块构成就可以确定每个指令流序列的程序行为特点,因此具有相似代码基本块构成的指令流序列就可以划分到一类。
基于以上思想,Proto-Perf性能评估方法将应用程序切分为多个具有相同指令流长度的指令流序列,这些指令流序列由多个代码基本块构成。因此,Proto-Perf采用代码基本块向量的方式来记录每个指令流序列中所包含的代码基本块,如图1所示。每一个代码基本块向量都记录了所代表的指令流序列包含了哪些代码基本块以及每个代码基本块在该指令流序列中执行的次数。图1以代码基本块的形式展示了一个代码指令流序列,并假设整个程序中一共有6个代码基本块。从图1中可知,这段代码包含3个代码基本块(B1、B2和B3)。根据执行序列就可以很容易得到代码基本块向量。图2为Proto-Perf性能评估方法的整体基本流程,其中生成代码基本块向量的步骤中代码块向量表记录了指令流序列P1~P6的代码块向量。目前,已经有许多开源的工具支持开发代码基本块向量生成的功能,例如Pin[13]和Valgrind[14]等。
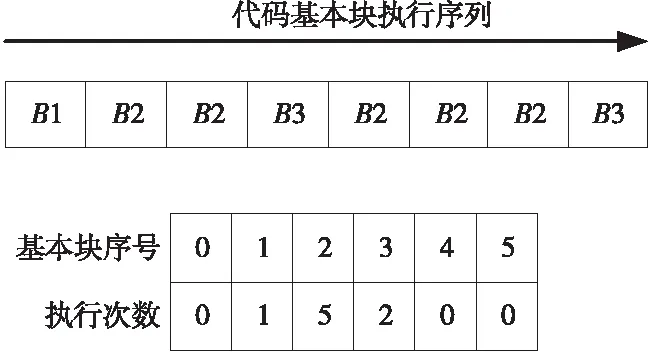
Figure 1 Generating code basic block vector from code basic block sequence图1 由代码基本块序列生成代码基本块向量
3.2 筛选程序指令流片段
通过记录代码基本块向量,Proto-Perf基本掌握了每个指令流序列的程序行为特征。如果有2个代码指令流序列代码基本块向量的特征相似,那么这2个指令流序列就具有相似的程序行为特征。因此,Proto-Perf性能评估方法采用聚类分析(K-Means)算法[15]将应用程序中具有相似程序行为特征的指令流序列进行归类。具体方法如下所示:首先使用线性随机投影方法降低代码基本块向量的维度。由于一个应用程序通常包含成千上万个基本块,导致代码基本块向量维度过高,从而导致聚类算法复杂度加大。因此,在聚类分析之前先降低代码基本块向量的维度可以加速聚类分析。其次,设定最大的聚类数量K,并在[1,K]内使用不同k值进行K-Means算法分析。第3步,从不同k值的分析结果中选择最优的结果对代码基本块向量进行分类。最优结果的选择标准是,既要满足贝叶斯信息准则BIC(Bayesian Information Criterion)[16],同时还要求k值尽量小,也就是说,在所有结果中选择最接近已知最高得分的最小k值分类。最后,归类完成后,从每一类中选择出一个指令流序列构成应用程序的样本集合。该样本集合几乎具有所有的应用程序行为特征。图2筛选程序指令流片段的步骤中首先根据代码基本块向量将指令流序列进行聚类,划分为4大类:P1和P4,P2和P6,P3,P5。然后,从每一大类中选择出一个指令流序列构成最终的样本集合。
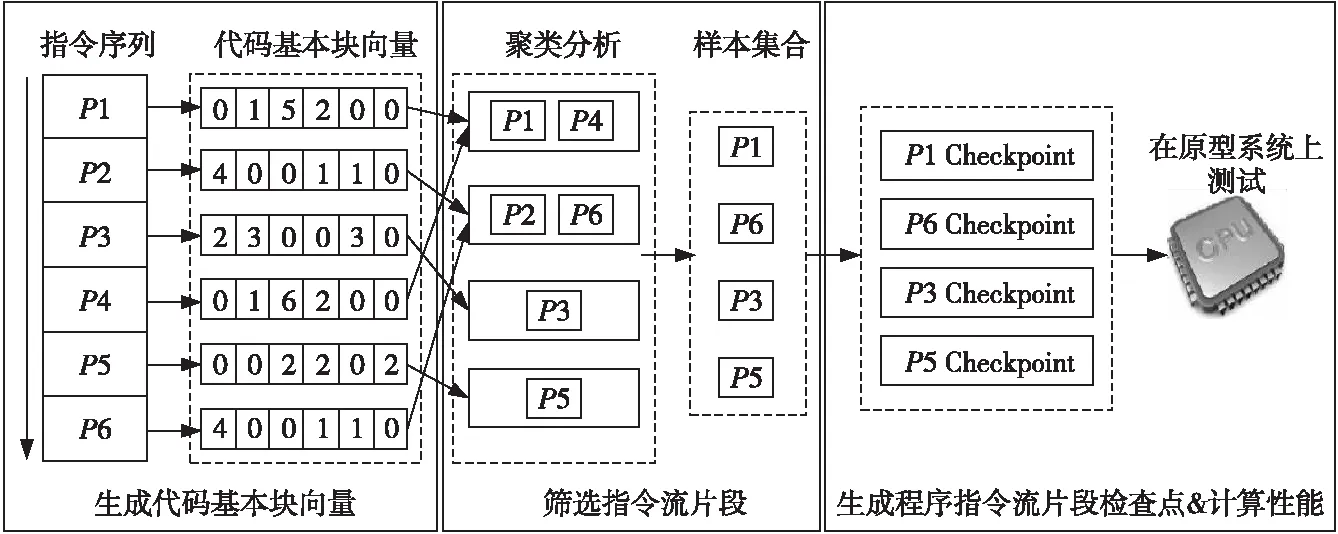
Figure 2 Workflow of Proto-Perf图2 Proto-Perf性能评估方法基本流程
3.3 生成程序指令流片段检查点
由于筛选出的指令流序列不是连续的指令流,而是广泛分布在应用程序指令流的不同阶段,因此需要记录执行样本集合中指令流序列前的程序状态,这样才能保证在处理器原型系统上只需运行样本集合中指令流序列,同时还使得Proto-Perf性能评估方法能够在不同的原型系统上使用。图2筛选程序指令流片段的步骤中样本集合由指令流序列P1、P3、P5和P6构成,所以指令流序列P1、P3、P5是不连续的。一旦这些指令流序列的检查点生成之后,Proto-Perf性能评估方法可以在不同的处理器原型系统上重复使用这些检查点,无需再重新生成检查点。
然而,由于检查点生成过程需要完整执行整个程序,因此考虑到在处理器原型验证系统上生成检查点需要巨大的时间开销,Proto-Perf性能评估方法使用与被测试处理器原型系统具有相似架构的真实处理器芯片来生成检查点,以此来缩短检查点生成时间。
3.4 计算处理器原型验证系统性能
Proto-Perf性能评估方法使用检查点恢复技术将样本集合中的指令流序列在处理器原型系统验证平台上执行,并记录处理器执行每个指令流序列时平均每条指令执行需要的周期数CPI。另外,在筛选程序指令流片段的步骤中,Proto-Perf会记录样本集合中每个指令流序列对整个程序性能所贡献的比重。依据以上2个数据,Proto-Perf可以计算处理器原型系统的平均每条指令执行需要的周期数CPI=∑CPIi*Weighti,其中CPIi为处理器执行样本集合中第i个指令流序列时平均每条指令执行需要的周期数,Weighti为样本集合中第i个指令流序列对整个程序性能所贡献的比重。
4 实验结果与分析
本节介绍使用Proto-Perf性能评估方法在处理器FPGA原型系统上进行测试的实验环境和实验结果。
4.1 实验环境
本文实验测试中使用的通用处理器FPGA原型系统是正在进行的一项处理器开发项目,其工作频率设定为25 MHz。另外,我们选取了一个已经量产并且与正在开发的处理器具有相同体系结构的处理器芯片(2.6 GHz)用作生成程序指令流片段检查点的平台。此外,我们基于一些开源软件工具构建了Proto-Perf性能评估方法的工具链。其中,使用Valgrind作为生成代码基本块向量的工具;使用SimPoint软件筛选程序指令流片段;使用Linux操作系统的CRIU工具[17]在真实芯片平台上生成指令流序列检查点,以及在处理器FPGA原型系统上恢复指令流序列执行。
SPEC CPU2006测试程序集[18]是一个获得了工业界和学术界广泛认可的专门用来测试和评价通用处理器、内存子系统和编译器性能的综合基准测试套件。该测试集包含了12个整数测试程序和19个浮点测试程序。将测试集完整地在处理器上运行一遍,可以获得处理器的SPEC得分,并且可以将产生的结果报告上传到SPEC官方网站。然而,若要获得准确的处理器性能,就必须使用Ref测试数据集作为测试数据。目前由于FPGA工作频率较低,完整测试所有程序需要较高的时间成本。因此,作为验证Proto-Perf性能评估方法有效性的实验,本文对11个应用程序分别使用Proto-Perf性能评估方法和完整运行程序的方式进行了测试。其中11个应用程序的详细情况如下所示:
(1)456.hmmer是用C语言实现的基于隐马尔可夫模型的生物序列分析程序;
(2)400.perlbench是用C语言编写的Perl语言解释器;
(3)445.gobmk是用C语言实现的一个围棋游戏;
(4)401.bzip2是用C语言实现的压缩/解压缩程序;
(5)471.omnetpp是用C++语言实现的离散事件仿真器OMNeT++;
(6)464.h264ref是用C语言编写的视频压缩程序;
(7)437.leslie3d是用Fortran 90语言实现的计算湍流的计算流体力学程序;
(8)434.zeusmp是用Fortran 77语言编写的统一磁场的3D冲击波模拟程序;
(9)436.cactusADM是用Fortran 90和ANSI C语言实现的物理广义相对论;
(10)481.wrf是用Fortran 90和C语言实现的WRF模型;
(11)465.tonto是用Fortran 95语言实现的量子晶体学的Hartree-Fock波函数。
4.2 实验结果
图3展示了分别采用上述2种测试方法得到的处理器FPGA原型系统运行SPEC CPU2006应用程序的CPI和Proto-Perf性能评估方法相比于实际运行得到CPI的误差。 Proto-Perf的误差主要来自以下3个方面:首先,Proto-Perf的主要性能误差来源于方法本身使用指令流片段集合来计算整个应用程序的性能。Proto-Perf为了缩短FPGA系统的运行时间,对每个应用程序进行分析并根据程序执行特征筛选出可以反映应用程序性能的指令流片段集合。由于指令流片段集合并不能完全代表整个应用程序的行为,因此通过指令流片段集合得到的性能数据必然会在一定程度上损失精确度。其次,Proto-Perf在生成和恢复检查点时会引入一些误差。Proto-Perf的指令流片段使用执行的指令数来设置检查点的位置,但是由于CRIU在生成检查点时需要执行CRIU checkpoint程序,这就导致最终生成的检查点与实际需要产生检查点的位置之间存在一定偏差。同理,Proto-Perf恢复检查点后需要继续执行一段程序来计算该指令流片段的CPI,然而恢复检查点需要执行CRIU restore程序,同样会带来检查点的偏差。不过,通过设置warmup等手段可以减小这部分误差。最后,Proto-Perf分别使用一款已上市的处理器和一个正在研发的处理器FPGA原型系统来分别生成和执行指令流片段集合。虽然这2款处理器在体系架构上非常相似,但是微体系结构层次上存在的一些区别还是会导致程序行为的不同,进而使得生成的指令流片段集合与程序在处理器FPGA原型系统上表现的特点稍微不一致,从而引入部分误差。实验结果表明,与完整运行程序得到的CPI相比,使用Proto-Perf性能评估方法计算得到的CPI产生的误差非常小。在11个测试程序中,平均绝对误差为1.53%,其中最大绝对误差为7.86%。
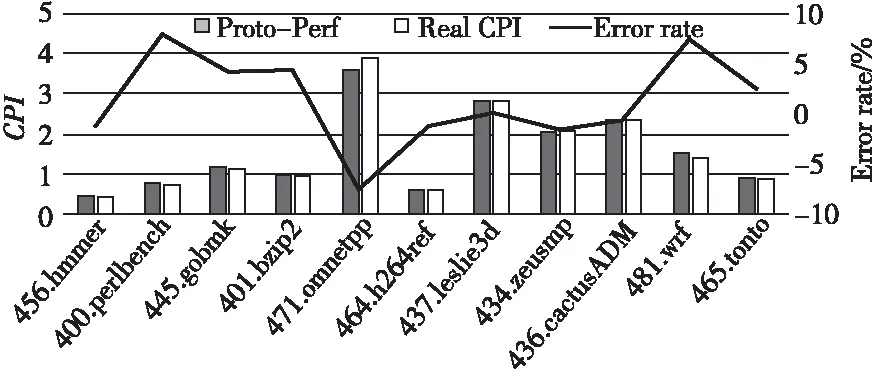
Figure 3 CPI of processor prototype system tested by Proto-Perf and running the program completely图3 使用Proto-Perf性能评估方法和完整运行程序的方式测试处理器原型验证系统的CPI
图4展示了在配置不同K值(30/20/10)的情况下,Proto-Perf为11个应用程序生成的检查点总数以及测试性能得到的平均误差。从图4中可以看出,随着K值从30下降到10,生成的检查点总数呈现出明显的下降趋势,而测试性能得到的平均误差出现明显的上升。这是因为随着生成的检查点数减少,筛选出来的检查点无法更全面地覆盖程序执行行为,从而导致测试得到的性能与实际性能偏差增大。但是,从图4中还可以看出,随着K值从30下降到10,性能平均误差增长幅度会减小。这是因为生成的检查点数下降间接地减少了生成和恢复检查点的次数,从而减少了Proto-Perf来自这方面的误差。
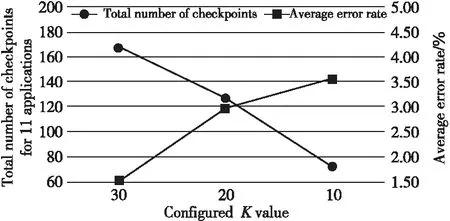
Figure 4 Total number of checkpoints generated and average error rate tested by Proto-Perf with different maximum K value图4 配置不同的K值,Proto-Perf为11个应用程序生成的检查点总数和测试的平均性能误差
表1比较了11个应用程序在处理器FPGA原型系统验证平台上分别采用完整运行的方式和Proto-Perf方法的运行时间。实验结果表明,在验证平台工作频率设定在25 MHz的情况下,Proto-Perf方法的运行时间显著低于完整运行应用程序的时间。
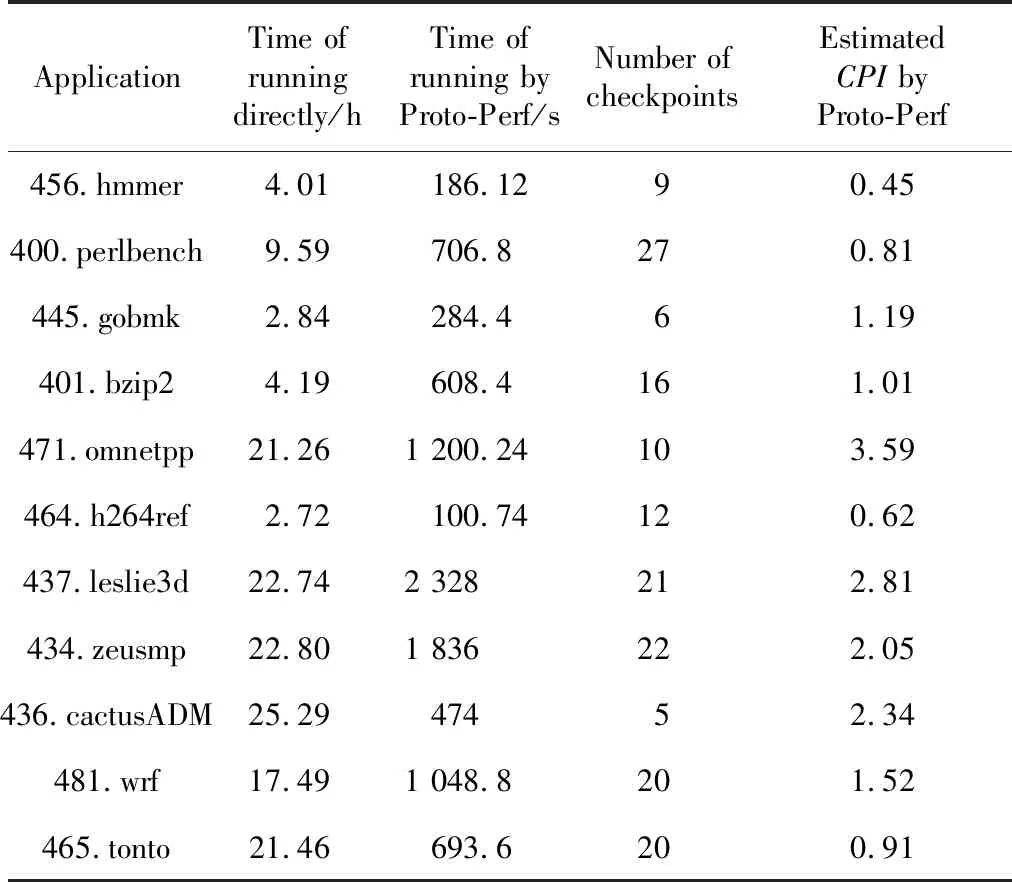
Table 1 Comparison time of running applications on processor prototype system directly with Proto-Perf method
从表1中还可以看出,虽然有的程序完整运行时间比较接近,但是使用Proto-Perf方法运行的时间会相差几倍。这是因为Proto-Perf方法的运行时间主要与每个应用程序的检查点数量、恢复检查点后执行的指令条数和处理器执行该程序的CPI有关。在实际中,恢复检查点后执行的指令条数在本次实验中固定为109条,因此执行时间只与检查点数量和处理器执行该应用程序的CPI相关。例如,437.leslie3d和436.cactusADM 2个应用程序完整执行时间相近,但Proto-Perf的执行时间相差了4.9×。这是因为437.leslie3d的检查点有21个,而436.cactusADM只有5个。另外,虽然481.wrf和465.tonto生成的检查点数量一样,但是Proto-Perf执行481.wrf和465.tonto得到的CPI分别为1.52和0.91,因此导致Proto-Perf执行481.wrf的时间反而比执行465.tonto的时间长。
5 结束语
本文提出一种快速精确的通用处理器原型系统性能评估方法Proto-Perf。Proto-Perf性能评估方法通过将应用程序指令流划分为多个指令流片段,从这些指令流片段中选择出能够代表程序特性的指令流片段作为样本集合,并在处理器原型系统的验证平台上运行这些指令流片段,从而得到处理器原型系统的CPI。实验结果表明,与完整运行程序得到的CPI相比,使用Proto-Perf性能评估方法的平均绝对误差为1.53%,并且所有应用程序在验证平台上的运行时间显著下降。
