Spark效用感知的检查点缓存并行清理策略①
2022-05-10宋一鑫于俊洋王锦江
宋一鑫,于俊洋,何 欣,王锦江
(河南大学 软件学院,开封 475004)
Spark 是主流基于内存的大数据计算框架,因其低延时,高性能,生态丰富被广泛使用[1].传统的机器学习系统正在迁移到Spark 平台上,利用并行计算和内存迭代等特点提升训练效率,优化Spark 框架执行效能可以节约用电成本,降低碳排放[2-4].基于内存迭代计算不具有稳定性,易发生数据丢失,在多次迭代计算中,RDD 数据丢失会导致高度冗余计算,Spark 引入检查点机制避免因内存数据丢失导致的重复计算问题.Spark 检查点备份过程是在作业计算完成后触发且需要根据检查点RDD 血统依赖重新计算备份数据结果集,具有较大计算开销.在实际使用中,为了避免检查点写入HDFS 时的RDD 重算过程,一般在作业初次计算时将需要保存为检查点的RDD 进行缓存,在写入HDFS时从缓存中读取检查点RDD 数据.然而,检查点缓存数据需要由编程人员手动清理,而在Spark 框架中检查点执行过程对编程人员是透明的,过早清理检查点缓存数据可能无法避免检查点写入HDFS 时的重复计算问题,太迟清理检查点缓存数据影响内存使用,所以检查点缓存数据清理策略就成为一个值得研究的问题.为此,本文建模推导出检查点缓存在大量检查点环境下不具有可扩展性,并提出基于效用熵的检查点缓存并行清理(PCC)策略,通过在效用最佳时间点自动清理失效检查点缓存数据,达到避免重复计算效果,同时优化内存占用和程序执行效能.
1 相关工作
基于内存计算的缺点是数据易丢失且对内存资源要求较高,高效容错机制可以提升作业恢复执行效率,提高内存利用率[5].目前国内外学者针对并行计算框架容错效率优化研究做了大量工作.
针对检查点容错效率优化,易会战等[6]提出基于异步缓存的异步检查点技术,主要思想是将检查点备份过程分为两步,第一步将需要备份的数据写入内存,第二步通过帮助程序异步写入磁盘,节省同步写入的时间开销.Ying 等[7]针对Spark 作业内检查点选择问题建模作业恢复模型,提出关键RDD 权重计算公式,优先最大权重 RDD 实现容错优化.Zhu 等[8]提出分离Spark 检查点选择和写入时机的策略,选择作业间重用RDD 作为待写入检查点,当堆栈区老生代负载超过阈值,将所有待写入的检查点写入HDFS,降低垃圾全回收次数,提高容错效率.
容错机制涉及多级存储,针对缓存级别优化,Duan 等[9]提出分布式缓存替换策略,以计算代价、分区大小、使用次数等建立清理权值,当内存不足时优先清理低权值分区,实验证明有效提升内存利用率,缺点是该策略无法感知分区数据是否使用完毕,未使用的检查点缓存数据可能被清理.刘恒等[10]提出考虑任务的Locality Level 因素综合计算代价、分区大小、使用次数、RDD 生命周期等参数建立分区清理权值,优先清理低价值分区,实验证明整体效率优于LRU 策略,但是由于检查点缓存被后台作业引用,该策略无法收集相关权值参数.More 等[11]提出利用闪存优势提升缓存性能,但需要增加硬件设备,有一定开销成本.廖旺坚等[12]提出适当用基于DAG 图重算代替缓存的策略优化内存消耗,但是应用场景有限,仅当RDD 计算代价很小时该策略有效,对检查点数据来说并无效果.赵俊先等[13]立足单节点、大内存服务器环境,针对内存不足频繁调用垃圾回收机制且大内存使得垃圾回收开销巨大问题,拆分原本主要服务各节点间的数据传输序列化功能和缓存功能,提出非序列化RDD 存储结构减小序列化带来的计算开销,利用堆下存储区域无垃圾回收特点降低垃圾回收开销,提升缓存效率,从而提升作业整体执行效率,然而单节点环境影响Spark并行执行能力,应用场景有限.卞琛等[14]构建用户程序RDD 结构树记录缓存引用待使用次数,当树节点引用值为零时,清理缓存RDD,实验证明该策略有效提升缓存利用率.但由于检查点缓存是Spark 后台检查点作业引用,结构树无法感知运行状态,故尚不能对检查点缓存起到清理优化效果.
与以往工作不同,本文重点在于通过优化Spark检查点缓存清理过程提升容错效率.
2 基于检查点缓存效用熵的并行清理策略
2.1 问题建模与分析
本节抽象出来相关属性和定义,分析检查点执行流程,并推导出现有检查点缓存清理方法随着检查点数量增多,其失效缓存清理时延和空间占用增大,不具有可扩展性.
定义1.作业检查点.作业检查点Checkpointi由三元组(mark_ti,write_ti,sizei)描述,表示该作业中第i个检查点在执行过程的时间属性和空间属性.其中,mark_ti为检查点标记的时间,write_ti为检查点写入HDFS 时间,sizei为检查点空间占用大小.
定义2.作业检查点缓存.作业检查点缓存CA-Checkpointi三元组(write-cti,clean-cti,sizei)描述,表示作业第i个检查点缓存的时间属性和空间属性.其中,write_cti为检查点缓存写入时间,claen_cti检查点缓存清理时间,sizei为检查点空间占用大小.CA-Checkpointi的写入时间需要满足write_cti<write_ti,即检查点缓存写入时间需要早于检查点写入HDFS 时间.
定义3.内存资源槽.内存资源槽Sloti使用三元组(start_ti,end_ti,size_maxi)描述,表示第i个内存资源槽在start_ti,end_ti时间范围内,内存空间上限为size_maxi.
检查点执行流程.设第i道作业中,检查点集合为Jobi={Checkpoint1,Checkpoint2,···,Checkpointn}.检查点执行分3 个阶段,第一阶段中cache()算子由于懒执行机制并不执行,checkpoint()算子依次将Checkpointn标记并移交给管理器.遇到action()算子后进入第二阶段,计算真正触发,cache()算子将Checkpointn数据写入缓存中,等待action()算子完成.第三阶段,启动检查点线程读取Jobi中CA_Checkpoint集合信息并依次写入HDFS 内,作业i完成,清理所有Checkpoint缓存.
定义4.失效检查点缓存.若CA_Checkpointi满足(claen_cti≥write_ti)∩(write_cti>mark_ti)∩(sizei≤size_maxi)∩(write_cti≥start_ti)∩(claen_cti≤end_ti),则称严格满足失效检查点缓存LA_Checkpointi条件.
定义5.失效检查点缓存清理时延.第i个失效检查点缓存时延delayi表示CA_Checkpointi清理出内存时间与Checkpointi写入HDFS 时间的时间差:
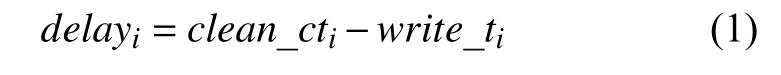
推论1.随着检查点数量增加,失效检查点缓存清理时延增大.
证明:设第一个检查点写入HDFS 用时为t1,第二个用时为t2,依次类推,最后一个为tn,第一个检查点缓存释放消耗时间为tm1,第二个时间为tm2,依次类推,最后一个时间为tmn,结合式(1)可知,当有n个检查点时,第k个检查点失效缓存清理时延为:
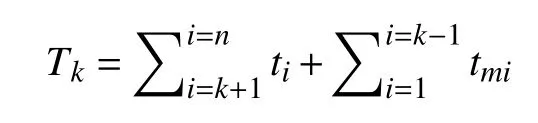
当有n+j个检查点时,第k个失效检查点缓存清理时延为:
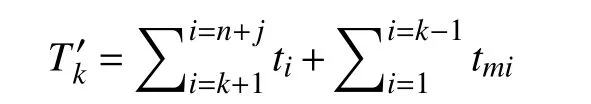
证明完毕.
推论2.随着检查点数量增加,失效检查点缓存占用总空间增大.
证明:设第一个检查点RDD 大小为size1,第二个大小为size2,依次类推,第n个为sizen.
当有k个检查点时,最后一个检查点写入HDFS后,失效检查点缓存占用空间为:
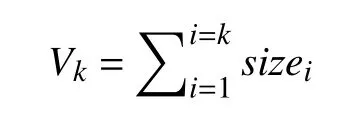
当有k+j个检查点时,最后一个检查点写入HDFS后,失效检查点缓存占用空间为:
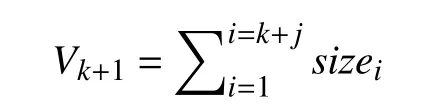
证明完毕.
2.2 最佳清理时间点计算
本节提出检查点缓存效用熵定义,量化检查点缓存效用和占用的内存资源槽匹配度,利用效用最佳匹配原则计算最小化资源占用时的最佳清理时间点,为算法设计与实现提供理论依据.
定义6.检查点缓存累加和.检查点缓存累加和刻画在内存资源槽S loti内,作业运行过程中第i个检查点缓存占用内存槽大小情况:
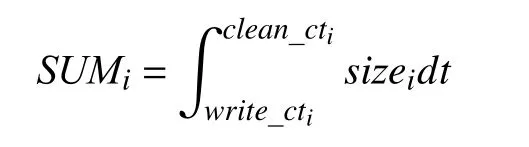
定义7.检查点缓存效用熵.衡量检查点缓存和内存资源槽的匹配程度,用检查点效用函数值Fr(CA_Checkpointi)和检查点缓存累加和SUMi比值表示.对检查点缓存CA-Checkpointi,其效用为write_ti时写入HDFS过程节省的检查点RDD 重算代价Ft(CA_Checkpointi),故效用函数表示为:
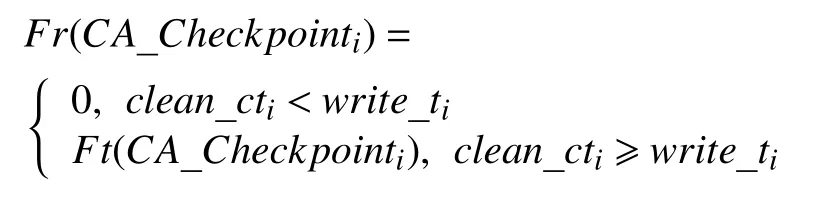
执行器m内检查点缓存效用熵记为:
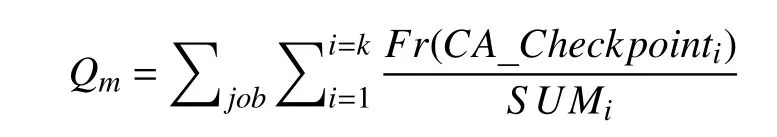
检查点缓存效用熵越大,说明检查点缓存与内存槽越匹配,内存资源槽利用率越高,故检查点缓存清理的优化目标函数为:

定理1.效用最佳匹配原则.在保证检查点缓存效用的前提下,当且仅当claen_cti=write_ti,检查点缓存效用熵最大.
证明.若不影响检查点缓存效用,则检查点缓存数量k、缓存大小sizei均保持不变,效用值Fr(CA_Checkpointi)>0,此时claen_cti≥write_ti.
由定义2、定义4 可知,write_cti<write_ti,sizei>0,故SUMi>0.此时需min(SUMi),结合定义6 可知,claen_cti=write_ti时SUMi取最小值.
证明完毕.
2.3 算法设计与实现
上节基于效用熵概念,通过效用最佳匹配原则证明给出避免检查点重复计算,同时最小化其内存占用时长的检查点缓存清理时间点是检查点写入HDFS 时刻,本节结合Spark 检查点实现原理和编程接口给出具体算法设计与实现步骤.
检查点缓存并行清理(PCC)算法初始化一个空的检查点对象集合,通过插入后台监听代码片段捕获程序运行中设置的检查点对象,对检查点对象集合中元素状态改变监听.通过分析Spark 检查点源码可知,在检查点数据写入HDFS 系统时,检查点RDD 的完成状态标志发生改变,此刻立即清理该RDD 占用的内存空间.具体步骤如下:
(1)在主进程中启动后台监控程序,建立RDD 监听集合.
(2)依次扫描作业中所有检查点RDD,并将其对象引用添加到监听集合中.
(3)监听RDD 引用集合中检查点的状态,检测集合中检查点完成状态是否发生改变.
(4)对集合中完成状态发生改变的RDD 立即释放缓存空间,并从该集合中删除该RDD 引用.
(5)检测集合中剩余RDD 的状态,重复(3)(4),直至集合为空.
(6)所有作业运行完毕,后台监听程序退出.具体执行过程如算法1所示.

算法1.检查点缓存并行清理算法输入:检查点RDD 对象 CheckPointRDD.初始化:QUEUE ← new List<RDD>;// 初始化清理队列作业线程:1.WHILE( CheckPointRDD NOT IN QUEUE)2.CheckPointRDD.cache();3.CheckPointRDD.checkpoint();

4.QUEUE.append(CheckPointRDD);5.END WHILE监控线程:6.WHILE TRUE 7.FOR qs IN QUEUE 8.IF qs.checkpointed()THEN 9.qs.unpersist();//释放失效检查点缓存空间10.QUEUE.pop(qs);//删除已经释放空间的RDD 引用11.END IF 12.END FOR 13.IF QUEUE.size()== 0 THEN 14.break;15.END IF 16.END WHILE
算法1 中检查点状态监听队列及时删除已经释放空间的检查点对象引用,提高队列元素扫描速度,避免出现内存泄露问题.同时,该算法通过后台监控线程响应检查点状态改变事件从而触发检查点清理动作,其异步并行过程不影响作业线程执行.从整体执行过程看,检查点缓存完成重算效用后,此刻效用熵最大,立即被清理出内存,避免失效缓存占用和累积问题.
3 实验验证与分析
3.1 实验环境设置
实验环境用14 台节点服务器创建14 个Spark 计算节点的计算集群,使用Cloudera Manager 管理和监控集群,启动参数按Spark 默认配置,服务器配置如表1所示.

表1 节点服务器配置参数
3.2 检查点缓存清理时间点分析
实验设置检查点大小均为1 GB,通过监听单道PageRank 作业执行中每个检查点写入HDFS 时刻,每个检查点缓存清理时刻,分析PCC 策略在选择清理时机上的特点以及PCC 策略缩短检查点缓存清理时延的效果.
如图1(a)所示,检查点写入HDFS 的时刻呈现分批次,逐个写入的特点,且次序大的检查点写入HDFS时刻晚于次序小的检查点.对比图1(a)和图1(b),通过基于PCC 算法优化的程序,检查点缓存清理时间是逐批次进行,每当检查点写入HDFS 后,即时清理失效检查点缓存,检查点缓存清理时延近似为0.未优化的程序检查点缓存清理时间是在最终所有检查点写入HDFS 完毕后开始清理.对比基于PCC 算法优化的程序和未优化的程序检查点缓存清理情况,未优化的程序存在失效检查点缓存长时间占用情况,且随着检查点个数增加,未优化的程序累积失效检查点缓存增多,失效检查点缓存数据清理时延增大,验证了推论1,推论2.观察图1(c),由于失效检查点缓存存在累积效应,使用PCC 算法优化后,缓存清理时延总和随着检查点个数增多,缩短明显.
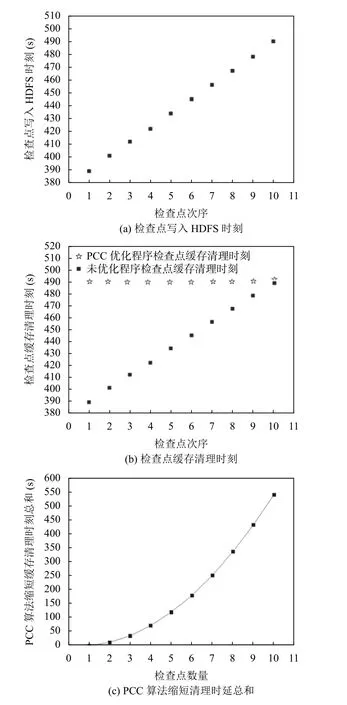
图1 检查点写入HDFS 时刻、缓存清理时刻和PCC 算法缩短清理时延总和
3.3 失效检查点缓存空间占用分析
实验采用基于公平调度的模式并行提交3 个pagerank 作业,每个作业用(网页数量/亿,迭代次数/次,检查点个数/个)三元组表示,作业一、二、三依次为(1.2,10,30)、(1.2,15,30)、(1.2,30,30),测试在多作业并行执行环境下,失效检查点缓存内存占用情况.
如图2所示,3 道作业先后分别出现失效检查点缓存占用情况.且多作业环境下,未优化程序失效缓存占用总和出现累积的负面效应.观察PCC 优化程序失效检查点缓存总和可知,每当出现检查点缓存失效情况,PCC 算法立即清理失效检查点缓存,内存槽被释放,有效避免失效检查点缓存累积,提高内存利用率.
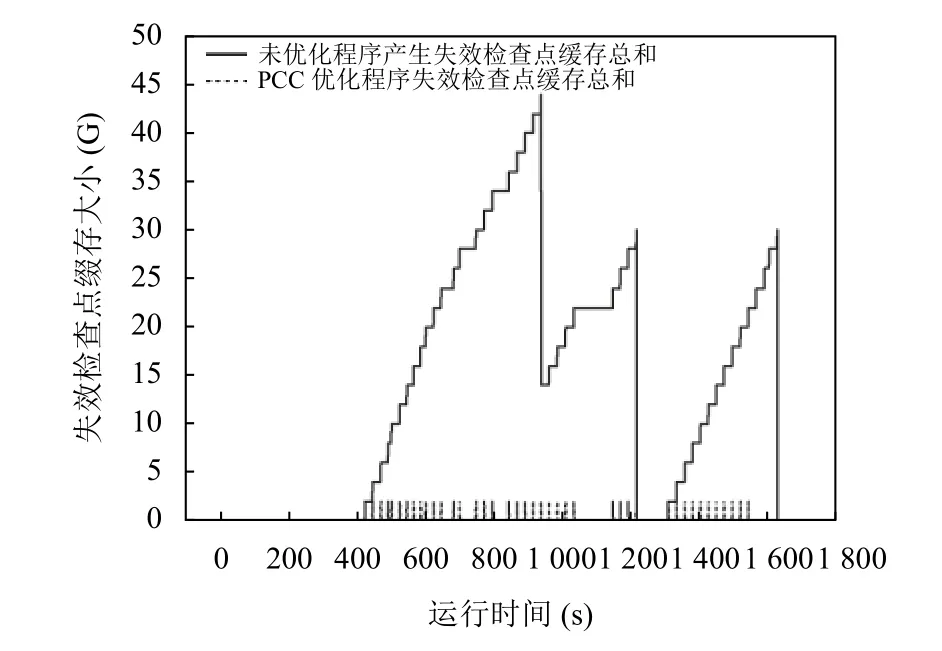
图2 失效检查点缓存占用空间
3.4 程序执行效能分析
实验采用公平调度模式测试top-n 任务,K-means任务和PageRank 任务下3 作业同时提交,每个作业用三元组表示,设置实验组如表2所示,每个实验组内作业一为最短作业,作业三为最长作业,A 组、B 组、C 组、D 组、E 组实验依次增加计算规模和检查点个数,测试在多作业并行执行环境下,失效检查点缓存对长作业执行的影响.通过后台监控进程收集程序执行时间、GC 时间等实验结果数据,使用数显电表记录程序执行前后服务器用电量大小.

表2 实验组设置
图3 显示不同实验组中,各任务下3 道作业并行执行时,使用PCC 优化程序和未优化的程序对执行时间、用电量和GC 时间的影响.
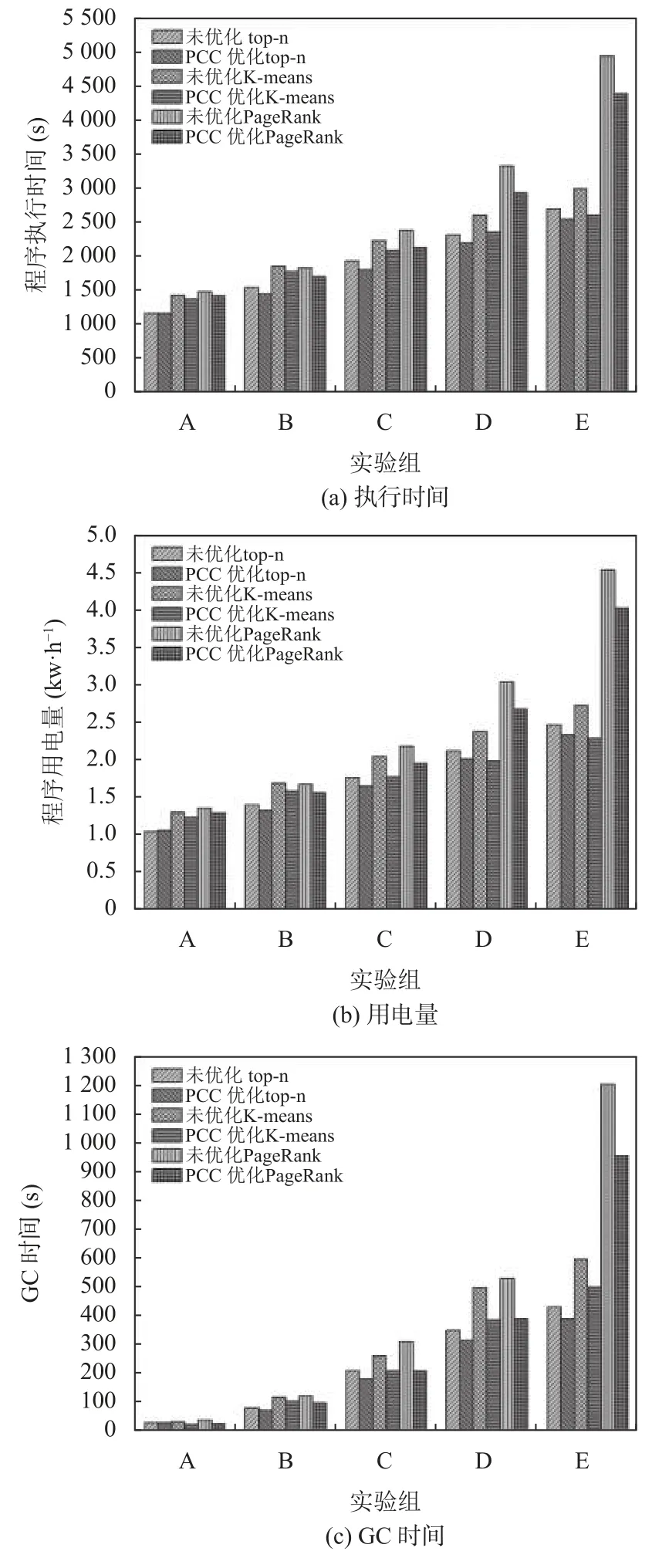
图3 程序执行时间、用电量和GC 时间
如图3所示,随着最大迭代轮次和检查点数量的增加,作业执行时间不断增加,GC 时间、用电量也不断增加.A 组中top-n 作业检查点数量为1,PCC 未表现出优化效果,K-means 和PageRank 作业检查点数量大于1,PCC 开始表现出优化效果.随着最大迭代轮次和检查点数量的增加,PCC 优化3 种任务的效果逐渐明显,且3 种任务均在E 组出现最显著的优化效果,其中top-n 作业执行时长缩短6.3%,GC 时间缩短9.3%,用电量节约5.2%,K-means 作业执行时长缩短9.7%,GC 时间缩短17.1%,用电量节约9%,PageRank 的执行时长缩短10.1%,GC 时间缩短19.5%,用电量节约9.5%.
4 结论与展望
针对编程人员清理缓存不及时可能引起的Spark作业检查点失效缓存长时间累积占用资源问题,通过分析检查点执行流程,推导出随着检查点数量增加,失效检查点缓存存在累积现象,影响内存利用率.本文提出一种基于检查点缓存效用熵的并行清理策略,保证检查点缓存效用前提下,最小化资源占用.实验结果表明,PCC 策略即时自动清理失效检查点缓存数据,避免失效检查点缓存累积,有效提升内存利用率,且随着计算规模和检查点数量增加,程序执行时间、用电量和GC 时间优化效果明显.下一步研究方向是不同作业负载下缓存管理策略对程序执行性能影响.
