基于FPGA的高效可伸缩的MobileNet加速器实现*
2021-05-11萧嘉乐梁东宝陈弟虎
萧嘉乐,梁东宝,陈弟虎,粟 涛
(中山大学电子与信息工程学院,广东 广州 510275)
1 引言
近些年来,深度卷积神经网络DCNN(Deep Convolutional Neural Network)模型在分类和识别任务上具有远超传统算法的正确率,被广泛应用于机器视觉领域。而FPGA由于可定制的并行逻辑和相对较高的能耗效率,在加速DCNN任务方面具有一定优势。在大多数基于FPGA的DCNN实现中,有2个主要研究方向:一是实现的FPGA尽可能地去适配不同网络架构。文献[1]尝试通过参数化设计来为所有可能的网络实现一个通用的计算结构。二是针对某一个网络结构进行深度优化,文献[2,3]探索了适用于具有残差模块网络的新的映射策略,例如ResNet和Xception。
本文针对的是嵌入式领域的硬件加速器应用,MobileNet网络以其低计算量和参数量被广泛用于嵌入式领域,但MobileNet网络的计算特点使其对现有的加速器(文献[4,5])利用率不高,具体表现在比较难达到硬件所具有的理论峰值性能,而嵌入式领域硬件资源往往有限,这个问题急需解决。还有一点,嵌入式领域的硬件资源差异较大,针对MobileNet网络的加速器还需要具备一定的可伸缩性,即针对不同的资源限制,都能获得较高的利用率。
本文的主要贡献有:
(1)设计了一个具有一定可伸缩性的MobileNet硬件加速器结构,对于0~4 000的乘法器开销都能保持70%以上的计算效率。
(2)在加速器结构上实现了基于MobileNet的Hourglass网络,最终的计算效率高于其他MobileNet网络加速器的。
本文的组织如下所示,首先介绍了深度可分离卷积和MobileNet网络的背景知识;接着描述加速器结构,主要包括计算阵列和片上缓存器;再接着探索了该加速器架构的设计空间;然后给出了加速器性能的实验分析与对比;最后是总结。
2 背景介绍
2.1 深度可分离卷积
深度可分离卷积首先是在文献[6]中提出的。在这种卷积中,标准的卷积操作被拆分为2个步骤:逐层卷积和逐点卷积。逐层卷积首先在不同通道的输入特征图上分别提取特征,然后进行逐点卷积,以1×1卷积的方式组合不同通道中的结果。标准卷积、逐层卷积和逐点卷积之间的差异如图1所示。其卷积输入的特征值的行数为H、列数为W、输入通道数为IC,经过卷积窗口为K×K的卷积后,输出通道为OC。

Figure 1 Comparison of three kinds of convolution图1 3种卷积方式的对比图
文献[7]证明,深度可分离卷积具有较少的权值和卷积运算,同时可获得与标准DCNN网络相当的精度。考虑到一般使用的标准卷积核为3×3,那么深度可分离卷积的权值量和计算开销均会是标准卷积的1/9~1/8。
2.2 MobileNet网络
本文主要研究MobileNetV2网络,该网络以其低权值存储和计算开销同时还能保持高识别准确度被应用于嵌入式领域。其计算过程可抽象为表1所示的步骤。其中,CONV为标准卷积,IRB(Inverted Residual Bottleneck)为倒残差瓶颈;模块avgpool为平均池化操作,t为缩放系数,c为输出通道数,n为重复次数,s为步进。
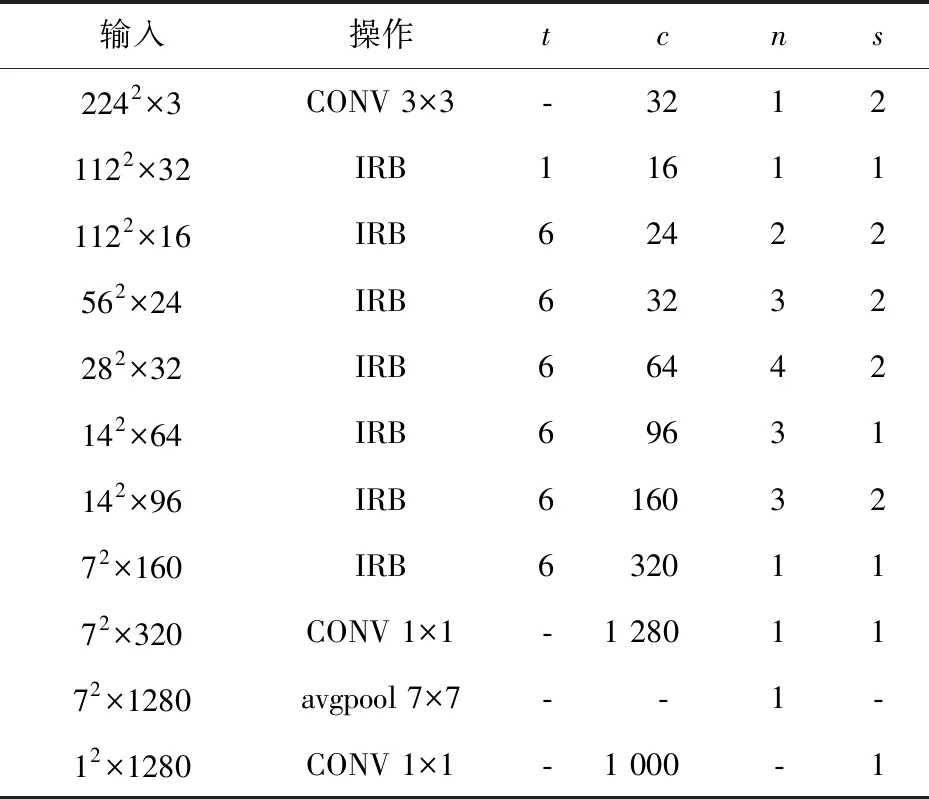
Table 1 The structure of MobileNetV2
MobileNetV2网络的主要组成部分是倒残差瓶颈模块,其是由深度可分离卷积衍生而来的,具体操作过程如图2所示。
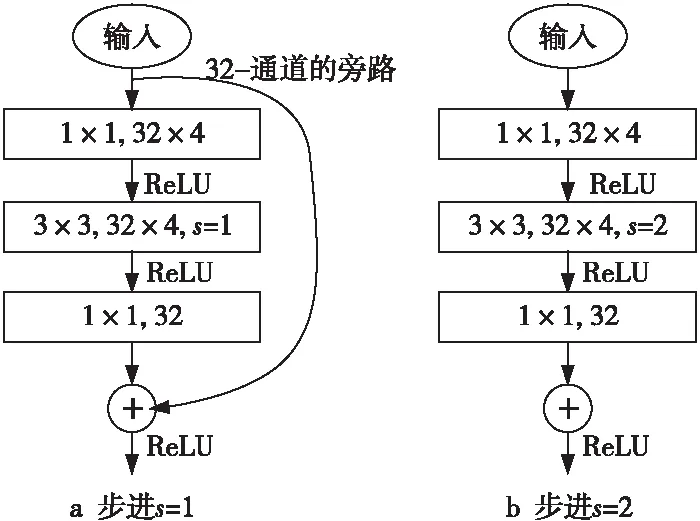
Figure 2 Procedure of two kinds of inverted residual bottlenecks图2 2种倒残差瓶颈模块操作过程图
以通道数c为32,缩放系数t为4为例,对于s=1的模块,需要进行1次扩张层计算(逐点卷积),再通过1次特征提取计算(逐层卷积)和1次压缩层计算(逐点卷积)。这个过程中特征值通道会先扩张至32×4再压缩至32,最后将原始输入旁路与计算结果相加得到一个倒残差瓶颈模块的计算结果。而s=2的模块只是少了旁路相加这一部分。
3 高效可伸缩MobileNet加速器硬件设计
3.1 整体结构
图3显示了高效可伸缩MobileNet加速器的结构,在加速器中,控制模块通过AXILite总线从嵌入式处理器接收控制指令,并将其转换为加速器中其他模块的内部控制信号。并行计算阵列负责堆叠式沙漏网络的所有计算。缓存器模块负责外部存储器和片上缓存器之间输入特征值和权值以及输出结果的传递。数据聚集-发散模块作为特征值、权值缓存与外部存储之间的桥梁,充当着类似直接内存访问的工作。

Figure 3 Block diagram of the accelerator system图3 硬件加速器结构图
3.2 数据排布方式
特征值数据具有3个维度,分别是行、列和通道。考虑一个维度为x×x×x的特征值块,传统的行优先数据排列(这意味着数据首先沿行方向排列,然后依次沿列和通道方向排列,如图4a所示,其中序号表示其在特征值缓存中的排布顺序)适用于通道分离的逐层卷积,而在MobileNet网络中,逐点卷积在整个计算中占据了很大一部分。逐点卷积对来自不同通道的特征图进行卷积,并一次生成一幅特征图。此时若仍使用行优先数据排列则会由于输入不连续,给逐点卷积带来数据获取上的困难,降低计算效率。为了解决这些问题,本文使用通道优先的排布方式(这意味着数据首先沿通道方向排列,然后依次沿行和列方向排列,如图4b所示)。在本文设计的硬件加速器中片上缓存器和片外存储所储存的权值、特征值数据均以通道有限的排布方式存在,而行优先的数据排列只会存在于并行计算阵列的计算过程中,这会在第3.3节中详细介绍。

Figure 4 Two kinds of data arrangement图4 2种数据排布方式示意图
3.3 并行计算阵列
针对MobileNet网络基本结构为1次逐点卷积、1次逐层卷积和再一次逐层卷积的特点,本文使用的计算阵列结构如图5所示,其中CVA(ConVolution model A)计算阵列适用于第1层的逐点卷积;CVB(ConVolution model B)计算阵列适用于第2层的逐层卷积;CVC(ConVolution model C)计算阵列适用于第3层的逐点卷积。

Figure 5 Structure of the convolution-layer parallel computing array图5 卷积层级并行计算阵列结构图
(1)CVA计算阵列。
该模块用于加速计算倒残差瓶颈模块中的膨胀层。如图5所示,该计算阵列的并行计算有3个维度:同时满足Ccalca个计算通道的并行计算;每个计算通道内满足La行特征值的并行计算;而每个计算行中满足Nmulta个输入通道的同时计算(这是由于逐点卷积计算过程中是优先进行通道间的卷积的)。所以,CVA的最小堆叠单元为并行的Nmulta个乘法器与1个Nmulta输入1输出的加法树。还需要注意的是,该计算阵列的输入数据格式是通道优先的数据排布,而输出格式是行优先的数据排布,以保证后续逐层卷积的数据读入的连续性。
(2)CVB计算阵列。
该模块用于计算倒残差瓶颈模块中的逐层卷积模块(通道分离的3×3卷积)。与CVA计算阵列类似,CVB计算阵列也可以分为计算通道Ccalcb、计算行数Lb和并行乘法数Nmultb3个维度。不同的是,在该模块中,最小堆叠单元被固定为并行的3个乘法器与3输入1输出的加法树,这是由于每个时钟周期CVB模块都能从CVA模块的输出获取3行1列的特征值,因此CVB模块若要完成1次3×3卷积则需要3个周期。此外,最小单元还需要添加行缓存模块,这是由于3×3卷积计算带来的行相关性,需要将本行计算需要的1或2行特征值缓存以用于下一行计算。而在数据排布方面,CVB模块输入的数据是按照行优先的方式排布,而输出的数据是按照通道优先的方式排布。
(3)CVC计算阵列。
该模块用于加速倒残差瓶颈模块中的最后一层逐点卷积,整体结构上与CVA模块相似,其区别是该层的数据输入是按照通道优先的方式排布,输出也是按照通道优先的方式排布。
(4)ADD累加阵列。
ADD累加阵列用于处理倒残差瓶颈模块中的支路残差求和部分。该阵列只有2个并行维度:并行计算通道数Ccalc和并行计算的行数LADD。ADD阵列的最小单元是1个二输入的加法器。该阵列的计算不改变数据排布方式,均为通道优先的排布方式。
3.4 其他计算操作的处理
(1)标准卷积。
如图1所示,标准卷积的操作实际上可拆分为1次逐层卷积和1次逐点卷积,其中需要考虑这2层卷积的权值。逐层卷积可直接沿用标准卷积中的权值,而对于逐点卷积权值,则需要生成对应的0-1矩阵来代表不同计算通道之间的累加。标准卷积的过程则可以映射到以上计算阵列中的CVB和CVC模块。
(2)ReLU激活操作。
ReLU操作使用的是f(x)=max(0,x)函数,在网络中是可选的,该过程仅在计算单元输出阶段将负数结果替换为零。
3.5 缓存器设计
(1)乒乓权值缓存器。
权值缓存器使用乒乓缓存机制处理,即将权值缓存器分为等大的2个部分:权值缓存器0和权值缓存器1,如图6所示。当其中一个从外部存储读取权值时,另一个缓存器可作为计算阵列的输入,以此将从片外读取权值的时间隐藏在计算时间内,提高计算效率。
(2)分时复用的特征值缓存器。
特征值缓存器同样被分割为2个大小相同的可分时复用的缓存器。每个缓存器均可作为计算阵列的输入、输出缓存。例如,在计算第n个倒残差瓶颈模块的任务时,缓存器0作为计算阵列的特征值输入缓存,缓存器1则作为输出缓存;而在计算第n+1个倒残差瓶颈模块的任务时,则相反。这样在完成一幅图像处理时可减少特征值缓存器与外部存储的数据交换,节约带宽。
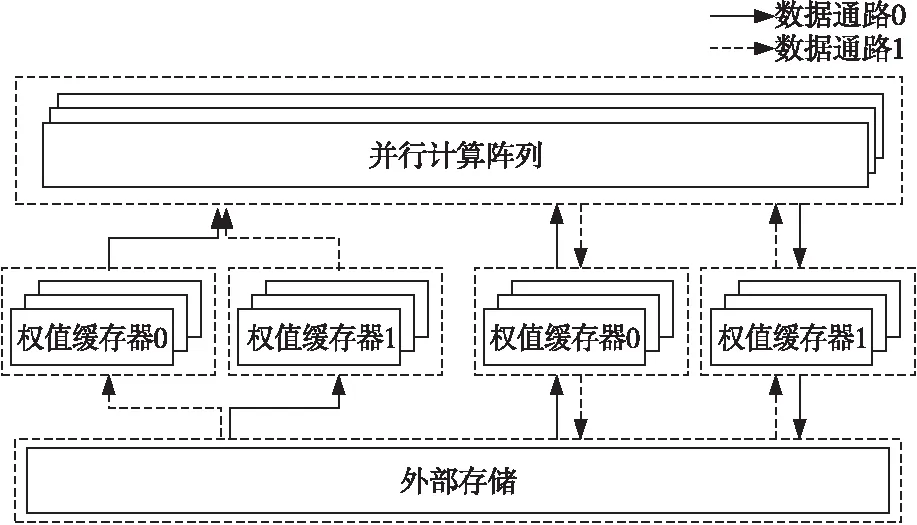
Figure 6 Structures of the weight and feature buffers图6 权值和特征值缓存器示意图
3.6 数据的分块策略
数据的分块处理是指将一层卷积分割为若干层卷积进行计算,因为片上缓存器大小是固定的,为适应不同分辨率的特征图像,数据需要分块处理。如图1所示,逐层卷积前后特征值通道不变,而逐点卷积由于涉及到通道之间的累加,所以卷积前后通道数会改变,因此数据的分割会发生在逐点卷积的输出部分,即CVA与CVC计算阵列的输出部分。若用Cfst_o表示倒残差瓶颈模块中第1层逐点卷积的输出通道数,Ctrd_o表示第3层逐点卷积的输出通道数,则可以得到分块的次数DA和DC:
(1)
(2)
其中ceil表示向上取整函数。
得到分块的次数后,可以将一幅图像的加速处理操作抽象成如图7所示的循环操作。其中需要考虑DA与DC循环的计算次序问题。图7列出的2种计算次序分别是DA循环优先和DC循环优先,其中Layer_MAX表示MobileNet网络的最大计算层数:Hlayer和Wlayer分别表示第layer层的特征值的行数和列数,则可以看出采取DC循环优先的方式可以减少CVA与CVB阵列中的重复计算。

Figure 7 Two computing orders
3.7 设计空间搜索
为了验证本文设计的硬件加速器在不同硬件资源约束下的可伸缩性,定义了一个表征参数计算效率:

(3)
由于不同卷积神经网络加速器的实现会因资源占用以及使用的工艺不同导致工作频率有差异,而计算效率这一参数可以抛开这2个差异,对加速器结构的效率做出一个正确的评价。通过修改3.3节中提到的并行度参数(并行度直接反映出所用乘法器的数量),可以得到如图8所示的乘法器数量与计算效率之间的关系图。可以看出,当乘法器资源从0~4 000变化时,本文设计的计算架构可以保持70%以上的计算效率,在这个范围内具有一定的可伸缩性。同时还可以发现,随着硬件资源的增加其计算效率的最高值在下降,这是由于随着并行度的增大而网络的尺寸不变,那么在进行小尺寸计算时(并行尺寸大于特征图尺寸时)则会出现部分资源闲置,从而使计算效率下降。

Figure 8 Relationship between multiplier occupation and calculation efficiency of hardware accelerator图8 硬件加速器的乘法器占用与计算效率的关系
4 实验结果与分析
采用XILINX Zynq-7000 ZC706开发板作为实验平台,实现了上述加速器。该开发板拥有218 600个LUT、545个Block RAM和900个DSP。下面将讨论实现结果和性能比较。
本文采用的数据精度为16位定点,根据以上讨论,并行计算阵列参数如表2所示,其中x在不同的模块中分别可表示为a、b、c和add,而所占用的资源如表3所示,其中特征值缓存器的大小为12 Mb,而权值缓存器的大小为3.25 Mb。在该硬件加速器上完成了基于MobileNetV2的Hourglass网络处理,该网络被广泛应用于人体姿态识别。硬件加速器可工作在150 MHz的工作频率下,且实现了6.11 ms处理一幅图像的工作效率,而该网络的计算量约为0.953 Gop,通过计算得到本文设计的硬件加速器的性能约为156 Gop/s,计算效率约为61%。计算效率略低于3.7节设计空间探索中所得到的70%,这是由于随着网络的层数加深,卷积的尺寸变小,通道数增加,数据分割后的单次计算时间小于单次计算所需要的权值的传输时间,因此即使使用乒乓缓存机制也无法隐藏传输时间,对计算效率造成了一定的影响。
表4给出了本文设计的硬件加速器与其他MobileNet加速器实现的对比结果,可以看出本文设计的硬件加速器在计算效率上优于其他实现的。

Table 2 Parameters of parallel computing array

Table 3 Resource utilization
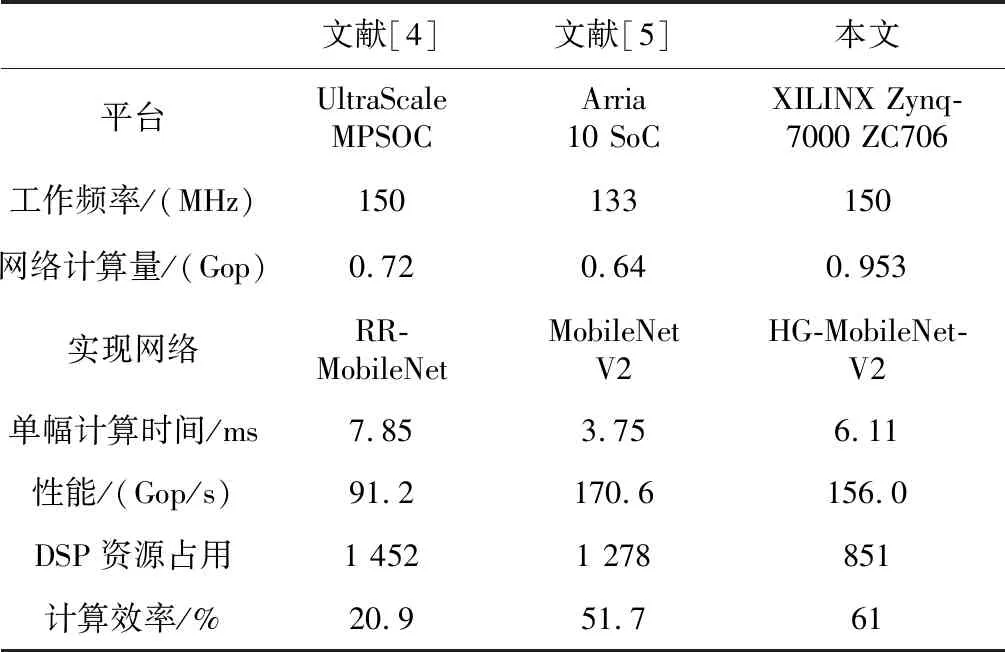
Table 4 Comparison of experimental results
5 结束语
本文提出了一个适用于MobileNet神经网络的硬件加速器结构,其具有一定的可伸缩性,在不同的硬件资源开销下能保持70%以上的计算效率,并用Hourglass-MobileNet网络给予了验证。但是,该结构仍存在着一些问题,例如在卷积尺寸较小时无法隐藏权值读取时间,这是以后的工作中需要解决的问题。
