近代广东海关档案名称规范档的语义模型构建*
2021-05-11王卉
王 卉
0 导言
近代广东海关档案数量浩繁,具有珍贵的原始价值和研究价值,1980年代开始受到学界关注。由于近代广东海关系统的国际化特征,其形成的历史档案存在语言与书写多样的现象,给各类档案名称的文字表达和识别带来了极大困难。当前,随着档案开放和社会信息化进程加快,历史档案的利用需求越来越大,如何对近代广东海关档案中的各类名称及其变体形式进行规范控制,确保档案信息检索点的一致性和关联性,已成为亟需解决的问题。基于此,本文以国内外相关理论和实践成果为参照,通过解析近代广东海关档案中的语言文字一致性、同音异义词的辨别以及中英译意的转化等问题,分析其中的逻辑语义关系,进而构建广东海关档案名称规范档,以期为海关档案的开发利用提供参考。
1 研究与实践综述
名称规范档,是指一种对描述记录中的名称标目进行规范控制的工具,处理范围包括人名、机构团体名、著作题名等[1],主要作用在于通过对名称中同义词、多义词及不同文种名称之间的转换进行处理、规范,以方便相关信息的标引和检索,促进信息资源的共享。针对档案信息资源的开发利用,名称规范档不仅有助于聚合同一名称的变体形式,而且为构建以关联数据为基础的语义关系网提供规范化的数据源。正是鉴于规范记录在档案著录中的重要地位,国内外较早就很重视名称规范档的建设。1993 年,国际档案理事会档案著录标准特别委员会就开始考虑档案著录过程中检索点的规范问题,于1996年发布第1版《国际标准—团体、个人和家族档案规范记录》[简称ISAAR(CPF)],明确规定档案内容著录的标准,且将档案规范记录(Archival Authority Records)作为独立的标准。加拿大的《档案著录规则》(Rules for Archival Description)对人物、机关团体的标目及参照关系等进行了规范。英国国家档案馆在ISAAR(CPF)基础上编制《人名、地名和机构名称著录规则》(Rules for the Con‐struction of Personal, Place and Corporate Names)。
与此同时,我国也开展了对名称规范档的实践。比如,1999年1月由岭南大学发起的合作项目,即“中文名称规范控制”,是香港中文名称规范工作小组在规范控制的基础上,构建反映中文人名和机构名特征的“香港中文名称规范数据库”(简称HKCAN);台湾建构的“明清档案人名权威系统”整理了明清人物传记资料,记录了史料来源的脉略线索,较完整地呈现了明清时期相关的人物信息以及内容关联;上海图书馆数字人文平台建构的“人名规范库”不仅提供了人名规范控制服务,也提供人物资料服务,动态地呈现了实体间的关联关系,为社会网络分析提供了便利。但整体而言,无论是在编目规则还是在资料库建置上,国内各馆藏机构均缺乏规范化的标准[2]。目前可见的档案著录参考规范仅有《DA/T 18-1999档案著录规则》,缺少针对档案信息的规范控制规则。台湾大学洪一梅指出,就数量而言,档案是唯一的;就性质而言,档案内容具有多元性;档案典藏的时间、空间范围不同,牵涉到的词汇即有不同,同时人名权威资料必须再区分为明清人物、民国人物,而且同是清代档案内阁大库与淡新档案,典藏单位对权威档功能的需求不同,建立的权威框架就不同[3]。这意味着档案机构在针对馆藏建构规范档过程中,既需要遵守国家通用标准,也需要考虑不同档案文献的特性,应基于具体的档案文献情况来描述多元化内容。
就近代广东海关档案来说,虽然目前已完成全文数字化扫描工作,但尚没有形成数字化的目录数据库,不能提供机检目录,故在利用时只能依靠手工检索,效率较低,耗时耗力。尤其是对那些不熟悉档案内容或者需要进行大范围信息查找和统计的利用者来说,很难进行全面且准确的信息检索和定位。为解决这一问题,需通过构建海关档案名称规范档,解决档案信息查找过程中的信息模糊问题,有效地控制不规范的信息表达。
2 近代广东海关档案中名词的特点和规范需求
外籍税务司制度下的中国海关,是一个特殊的国际性机构,其档案的形式与内容也呈现出独特的风格。综观近代广东海关档案的文献记录,大都混合使用了拉丁文字和象形文字,前者含有罗马字母和汉语拼音,后者包括繁体字和简体字。这些语言文字的混合使用,导致了文字多样与同音异义现象,是近代广东海关档案名称规范化过程中首要解决的问题之一。
2.1 多样化的语言文字
在目前的广东海关档案文献中,专有名词多样化主要体现在罗马拼音系统上。当前,较完整的罗马拼音系统有50种[4],涉及中英语音转写的有22种,出现在近代广东海关档案文献中较完整的有马礼逊系统(Morrison System,1879)、威妥玛-翟理斯系统(Wade-Giles System,1892)和邮政拼音系统(Postal Spelling System,1906)。多种拼音系统的混用使档案文献中专有名词的表达不能达成统一。比如:
人 名: 程 学 启, Ch’eng Hsueh- ch’i(Genteral Ching)
地名:厦门,(Amoy,Hsia-men,Samen)
职位名:知县,(Che hsien,Chih-hsien,District Magistrate)
机构名: 京师馆, Ching- shih Kwan(Ching-shih kuan)(see also Tsing-shih Kwan)
这些文字散布于海关档案文献之中,使得同一专有名词不同形式的变体难以关联与聚合,进而导致海关档案数据库构建中的信息流失。
2.2 同音异义词
基于档案专有名词的形式特征及其分类情况,近代广东海关档案中的同音异义主要包括一音多词(一词多义)和一词多音(一义多词)两种情况。
(1)一音多词(一词多义)。在语言文字识别中,判断汉语词义的关键是声调和语境。没有声调,往往导致词义的模糊;没有语境,仅通过读音则无法辨别词汇的含义。近代广东海关档案中的拼音词汇,大多从中文专有名词音译而来,因而在书写形式上没有音调标注,以致仅仅凭借拼音则通常无法辨识词汇的含义。例如,在档案中读到“Hoo Chow”一词时,只知道它是专有名词,基本上不能辨认它属于人名、地名、机构名还是职位名,即便是参考专有名词对照词典,如果没有相关历史背景供借鉴或参照,则无法确认该罗马文字所指代的含义。通过查询《华英词典》《中国近代海关常用词语》以及相关的海关档案文献,方知“Hoo Chow”对应的汉字有3种情况:实物为“护照”、地名有“湖州”、机构名称有“湖州府”。显然,这种情况对使用罗马文字检索档案信息的用户造成不便,至少在某种程度上,信息检索的查准率不高。
(2)一词多音(一义多词)。一词多音可以分为两类情形:一类是指多音字现象,如“长”字有“chang”“zhang”两种发音;二类是指因地域差异而同一汉字读音不同,如“厦”字可以发音为“xia”“a”“sia”。第二类现象在近代广东海关档案中更为普遍。比如:
人名:“长善”(Chang Shen,Chang Shan)
地名:“中国”(China,Chung-kuo)
职位名:“監察御史”(Chien-ch’a yüshih,His Excellency Censor)
机构名:“广州府”(Kwang chow foo,Kuang-chou fu,Canton Prefecture)
对这种存在多语种、异文本的档案文献,如果按照现在的汉语拼音规范来进行信息检索,不能保证所检索的信息就是用户所需要的信息。面对这种情况,需要将一词多音的表达形式进行关联,使其在数据库建设的过程中或是进行档案回溯性检索时,极大限度地保证档案信息资源检索的完备性和准确性。
2.3 翻译问题
近代广东海关档案中的部分专有名词还有相对应的英文对译。虽然罗马拼音和英文对译都是拉丁字母,但罗马拼音是从形式角度来展现,拼音本身并无实际意义;英文对译是从内容角度进行的翻译,由字母构成的单词可以传达具体的含义。具体例子参见表1。
从表1中可以发现,15个专有名词的汉字以繁体字形式呈现。从拼音形式看,这些名词的表示方式不止一种,差别迥异。以“副总办”为例,其两种拼音“Foo Keen Tuhi”和“Fuchien-tu”并无形似之处,但在海关档案中都是“副总办”的拼音书写形式。这种情况的出现是由汉语方言的差异以及语音演变所导致的——虽汉字相同,但发音相异;从音节书写上看,“副”字的发音“foo”和“fu”没有本质上的区别,但文本写法上又大有不同。从语义角度看,在英文档案中,“副总办”译为“assistant superintendent”。除此之外,档案中还有另外两种罗马文字的语音转写,即“Foo Keen Tuhi”和“Fu-chien-tu”。当然,像“差事”“知县”“俸禄”“监督”“举人”“钦差”“帮办”“宰相”“总兵衔”等专有名词都采用了类似的表达形式。
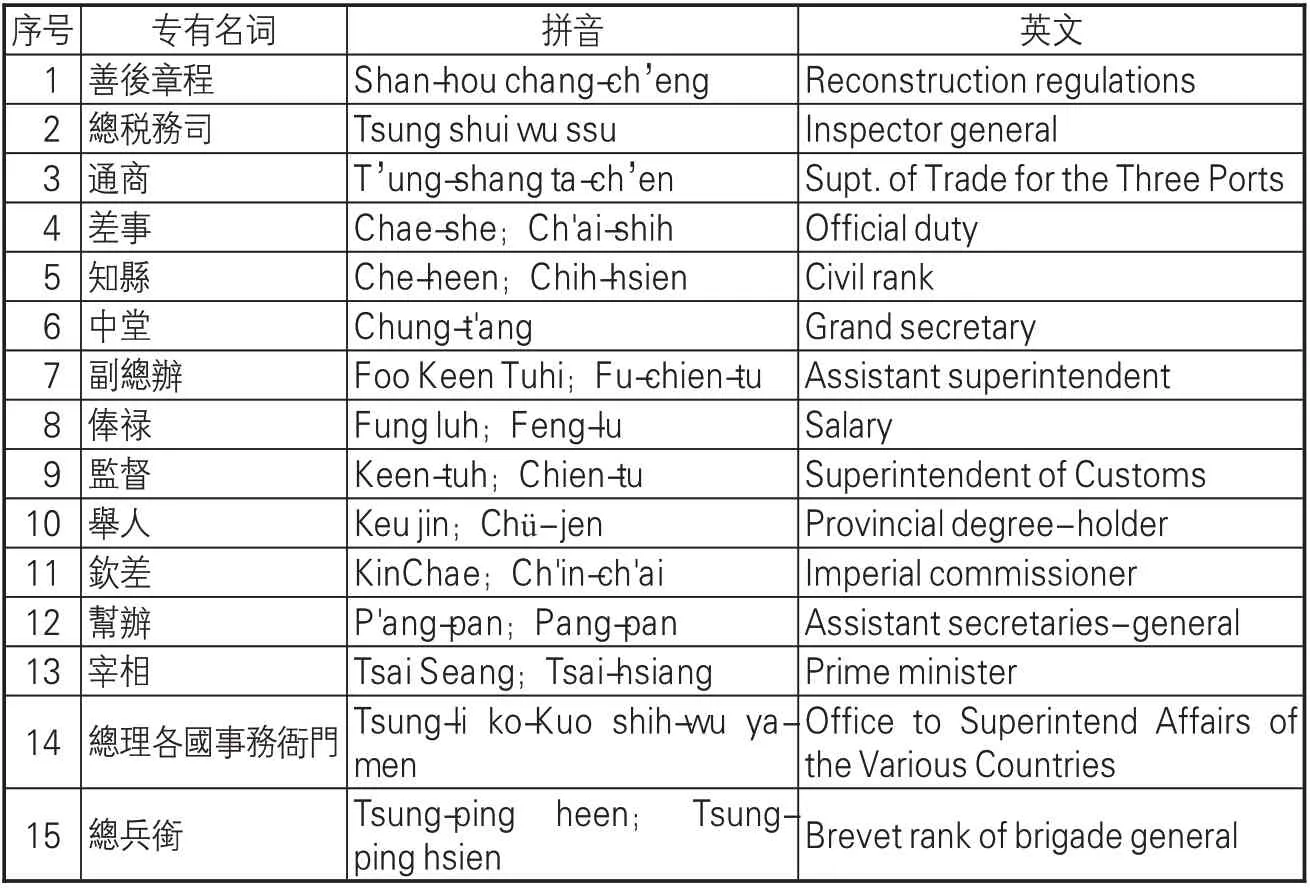
表1 近代广东海关档案中的专有名词的表达形式

图1 名称复杂性展示图[5]
在构建近代广东海关档案数据库的过程中,音节构成、书写文字、英文对译所造成的书写不一致的情况(如图1),致使无法将同一档案内容的变体信息进行关联,以至档案用户在开发利用档案信息资源时,无法将档案的证据价值与情报价值充分发挥,在一定程度上造成了档案文献资源的闲置与不能充分利用。按照信息著录和检索的要求,近代广东海关档案名称规范数据必须建立在规范控制的基础之上。因此,借鉴国内外信息组织的有益经验,建立近代广东海关档案名称规范档势在必行。
3 近代广东海关档案名称规范数据的语义模型构建
综观国内外名称规范档的建设经验,建立近代广东海关档案名称规范档,首先需要明确、清晰地表达名称规范数据,建构不同名称数据之间的关系(见图2)。对此,笔者认为,可以结合《中国档案主题词表》和现有相关的近代广东海关专有名词词典,借助叙词表中的语义关系以及Schema.org 层次结构,将近代广东海关档案中的各类名称进行分类;再根据不同的逻辑关系,对不一致的名称表述形式进行归类,保证同一名词之不同变体形式的全面性和关联性。
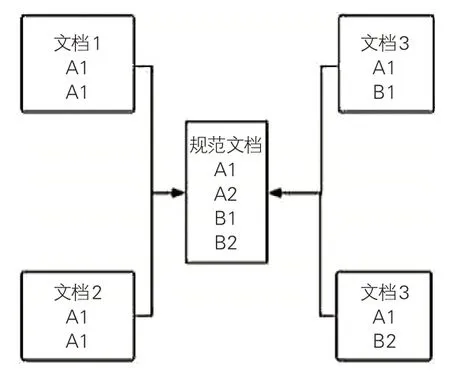
图2 近代广东海关档案名称控制规范的框架模型
3.1 明确对象
构建名称规范档语义模型的目的,在于明确档案用户关注的对象,从实体和属性关系的角度厘清各类名称之间的语义关系,为规范化描述准备。因此,针对近代广东海关档案名称不一致的问题,首先应解决哪些名称需要建立规范档,以及如何架构不同词汇之间关系的问题。在构建近代广东海关档案规范数据语义模型的过程中,核心概念集的确定是最重要也是最基础的工作。因此,在参考近代期刊元数据方案的基础上,将人物、地点、机构、职位4 个类别作为核心概念。其中,人物是档案文献所涉及的具有代表性的人物,像海关税务司李泰国、赫德等;地点主要是指该档案中所记载的、与各地区海关相关的地点名称以及地理区域等;机构是指具有一定历史地位的中国近代政府机构,由于机构是极其重要的资源,将其作为单独的概念类别,有助于把机构组织的相关信息进行聚类以及对其进行结构化、规范化地呈现,如机构负责人、机构地点、机构的管辖区域及功能等。在这4 类核心概念的基础上,以人名档、地名档、机构档(包含职衔信息)为基点作为语义关联,建构近代广东海关档案名称规范档语义模型框架。参见图3。
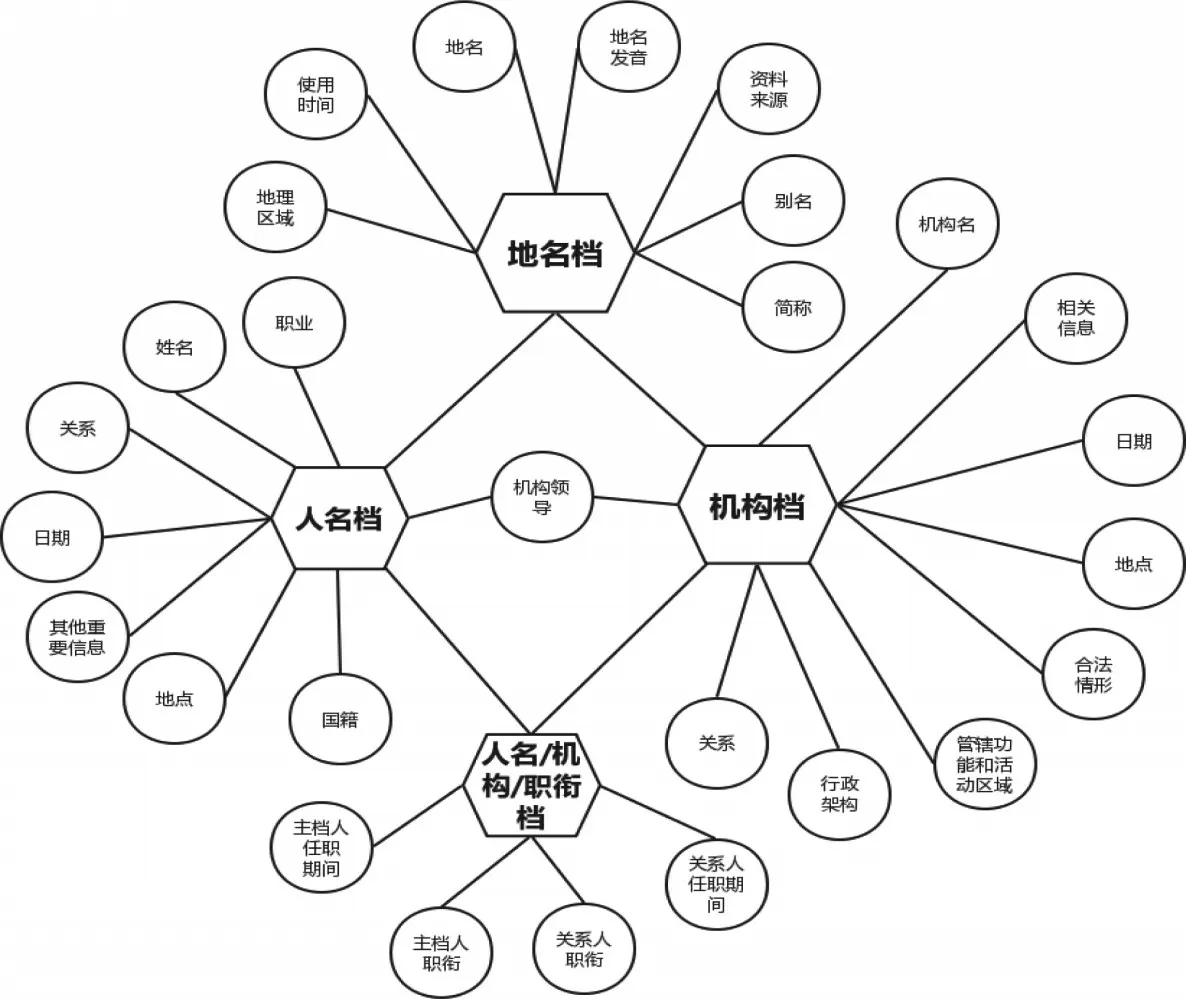
图3 近代海关档案名称规范档之关联图

图4 Schema.org类型层次结构
3.2 确定属性
除需要考虑概念、名称外,名称规范档的创建还应逐步转到对实体的描述上,如人物(Person)、组织(Organization)、地点(Place)、事件(Event)、 产 品(Product)、 评 论(Review)[6]等。基于这种考虑,可以参考Schema.org的类型层次结构(见图4)[7],根据该框架所描述的事物类型,按照一定的层次结构进行组合,每一类都有自己的属性,子类继承父类的属性[8]。针对近代广东海关档案各类实体信息,在来源原则的基础上,确定核心概念及其层次结构,通过属性进行概念的描述,进而建立不同概念之间的联系。参见表2-4。
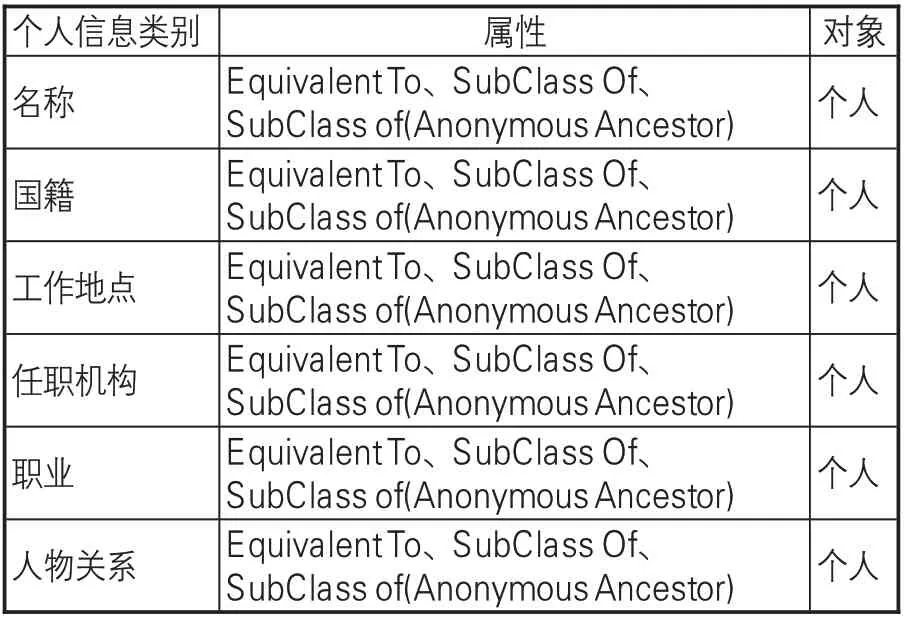
表2 基于“个人”的属性

表3 基于“地点”的属性
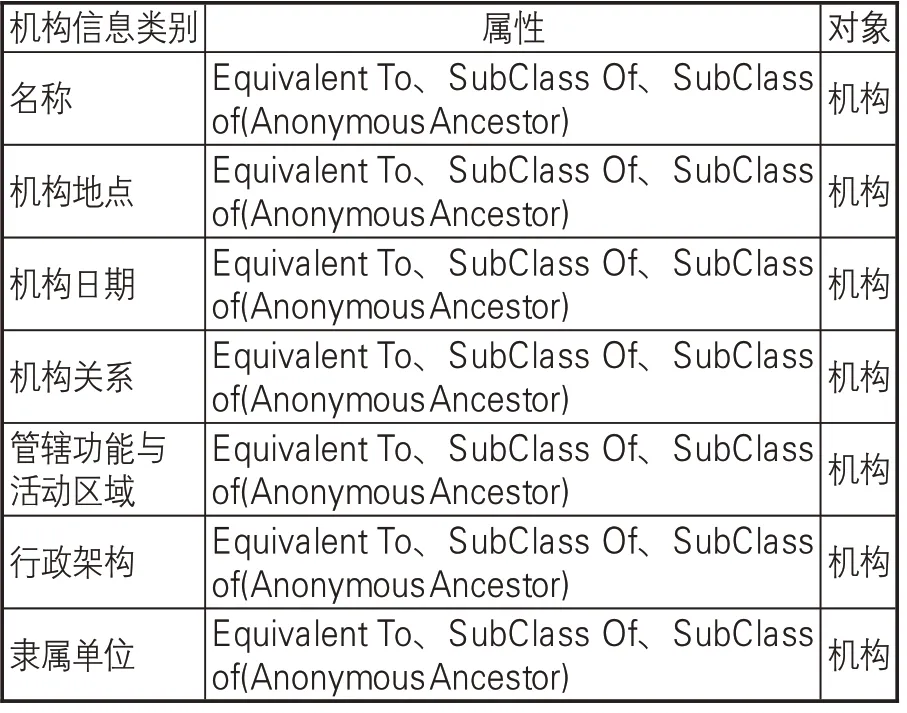
表4 基于“机构”的属性
3.3 定义实体关系
近代广东海关档案名称的实体关系,是指各类名称实体及其相应的逻辑关系。在海关档案开发问题上,参考规范化范式的叙词表,通过限定词汇的内容(概念)和形式(系统),展示概念术语之间的语义关系及其范围大小之间的逻辑关系,进而构建海关领域规范化、完整的词表模型[9]。基于近代广东海关档案中的人名、地名、机构名、职位名等不同的表达形式,对比分析《中国档案主题词表》和中国近代广东海关专有名词词典,参照叙词表相关的语义分类,可以得出近代广东海关档案名称之间存在的主要语义关系[10]。
根据上文描述的各类实体信息,借助由斯坦福大学研发的本体编辑工具Protégé对近代广东海关档案为中心的各类实体以及名称实体概念与属性关系进行形式化描述,建立以海关机构为中心的语义网络,并以.owl的形式进行保存。在该工具中,“OWL:Thing”被默认为顶级类别,它是包含所有类别的上义词;在此基础上,建立下义词。在OWL 语言中,“subclass of”连接上下义关系,根据中国近代海关档案本体的应用目的,即描述以中国近代海关机构为核心的概念与术语,如“海关机构”是“海关监督”与“税务司署”的上义词,“税务司署”又是“征税部门”“船钞部分”“邮政部门”“教习部分”的上义词,采用自顶向下的方式来建立基于近代广东海关档案中的各种概念以及相应的层次关系,进而构建其基本框架,如图5。
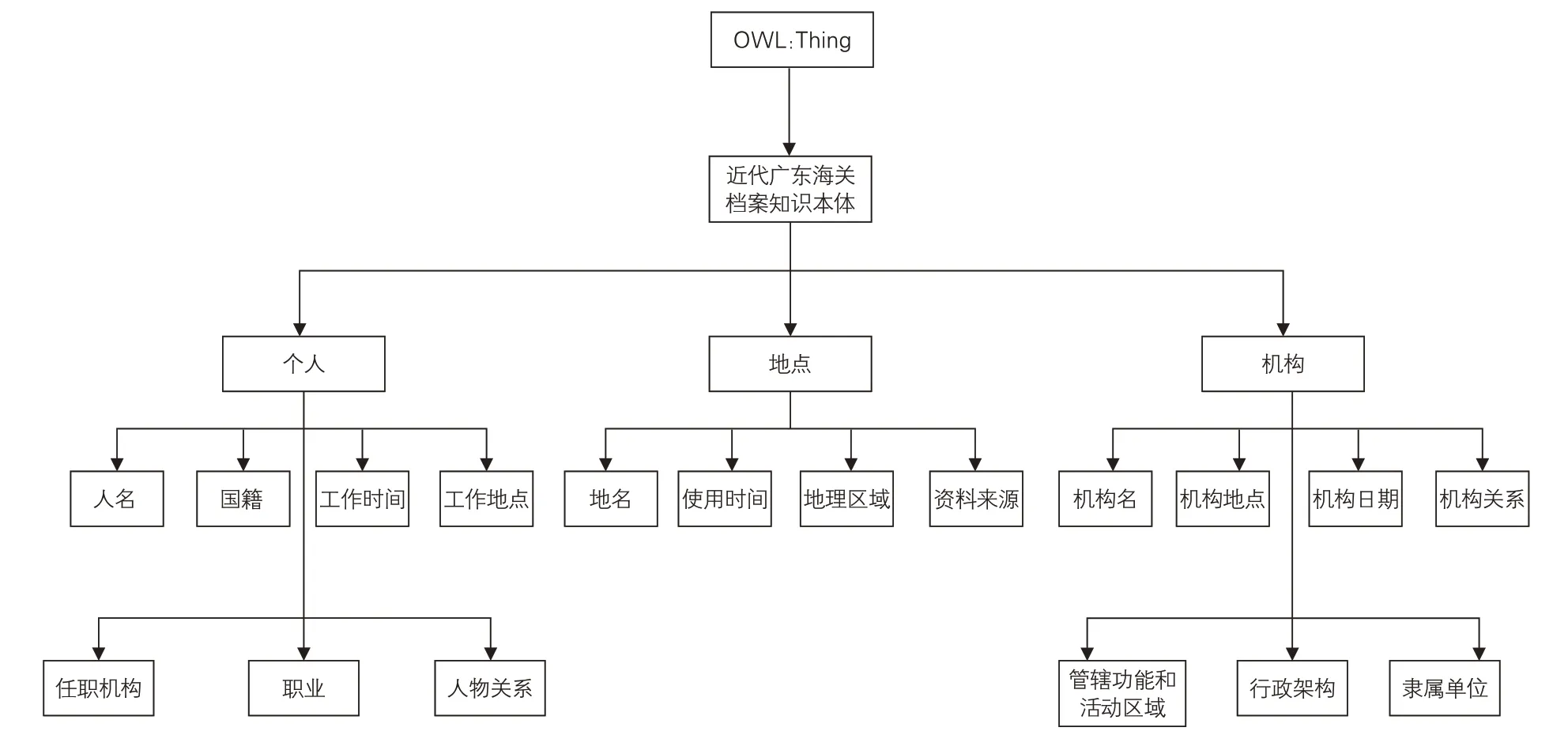
图5 近代广东海关档案知识本体的概念层次结构
3.4 语义模型呈现
名称规范数据模型是准确描述名称以及各类款目的重要基础,为近代广东海关档案著录本体的构建提供了参考框架。根据上文所述的名称属性及其各类关系,可以总结出近代广东海关档案名称规范档的规范信息(表5)[11]。
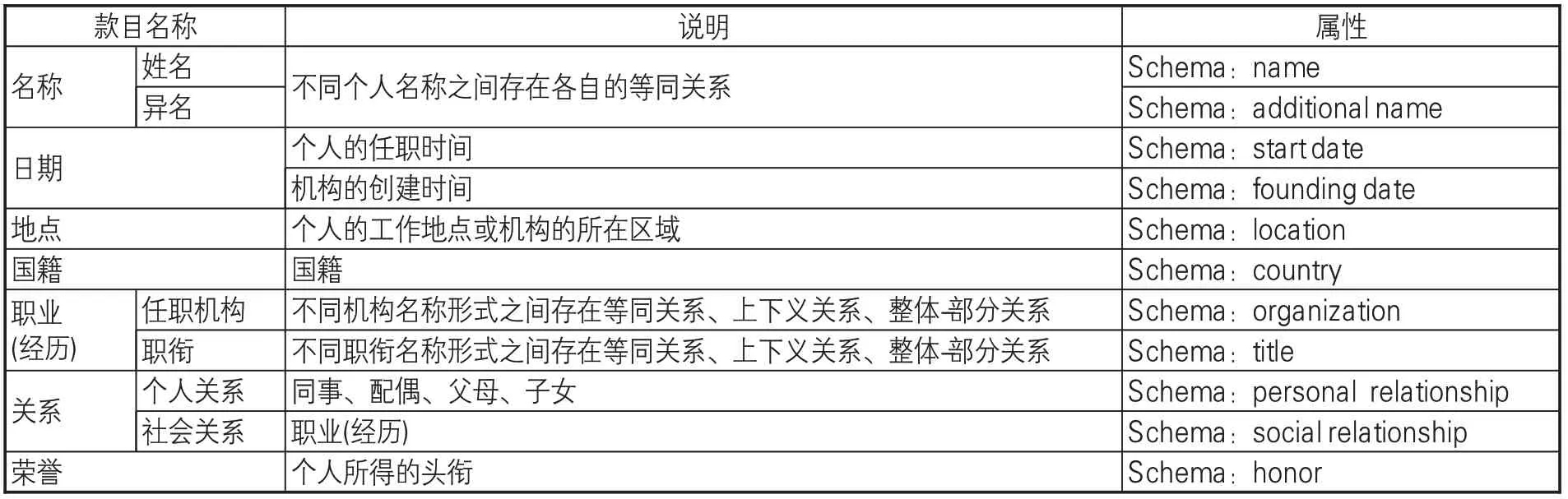
表5 近代广东海关档案名称规范档的相关属性、关系及其RDF映射
结合现有的Schema.org词汇表,包括人物(person)、地点(place)、组织(organization)、关系(relationship)等,以一定的层次结构将档案中的各类实体信息组织起来,并通过RDF映射关系进行列表描述,得出近代广东海关档案名称属性与关系模型,具体如图6-7所示。
以上模型是建立在近代广东海关档案名称规范数据的基础上,从来源原则的角度,保证了信息的准确性和一致性。在此基础上所形成的语义模型,不仅可以满足传统检索环境下的信息识别,同时也为网络环境下的信息交换与互操作性提供了框架基础。
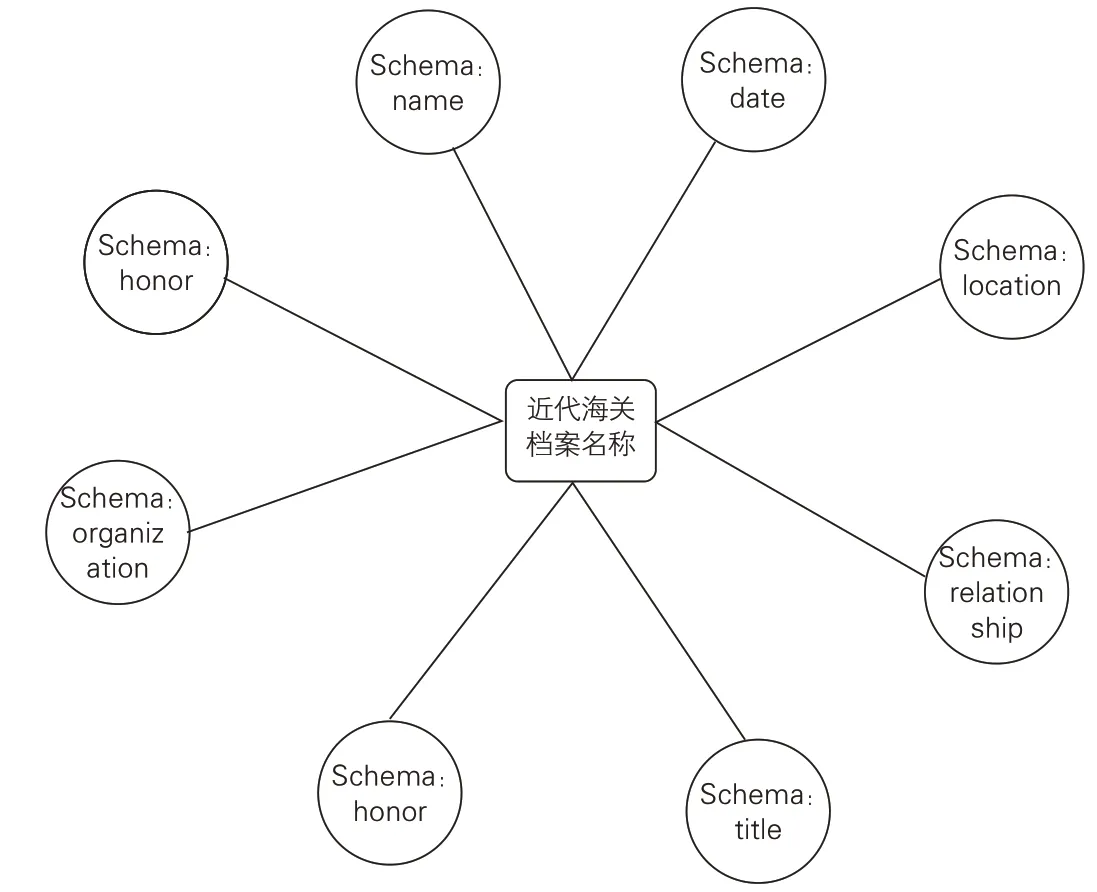
图6 近代广东海关档案名称规范数据实体属性模型
3.5 基于近代广东海关档案(粤海关)的实例分析
本研究以粤海关档案为对象,时间跨度为1861-1949 年,探析近代广东海关档案中的类与属性特征。考虑到粤海关档案不同类别信息的原始性与完整性,特别选取粤海关副税务司“卢力飞”与粤海关文案“叶凤仪”的人事类档案作为分析案例(见图8-9)。“卢力飞”与“叶凤仪”分别是粤海关机构的洋员与华员,人名变化主要包括3种情形:
中文:卢力飞、叶凤仪
拼音:Lu Lifei、Yeh Fêng-i
英文:R.de.Luca、无
卢力飞与叶凤仪两位海关人员的中文名称资源标识符分别是:http://www.semanticweb.org/wanghui/ontologies/2020/3/untitled-ontology-15#和http://www.semanticweb.org/Wanghui/ontol‐ogies/2020/3/untitled-ontology-15#。
而其对应的拼音标识符分别为:http://www.semanticweb.org/wanghui/ontologies/2020/3/untitled-ontology-15#Lu_Lifei 和http://www. semanticweb.org/wanghui/ontologies/2020/3/untitledontology-15#Yeh_Fêng-i。
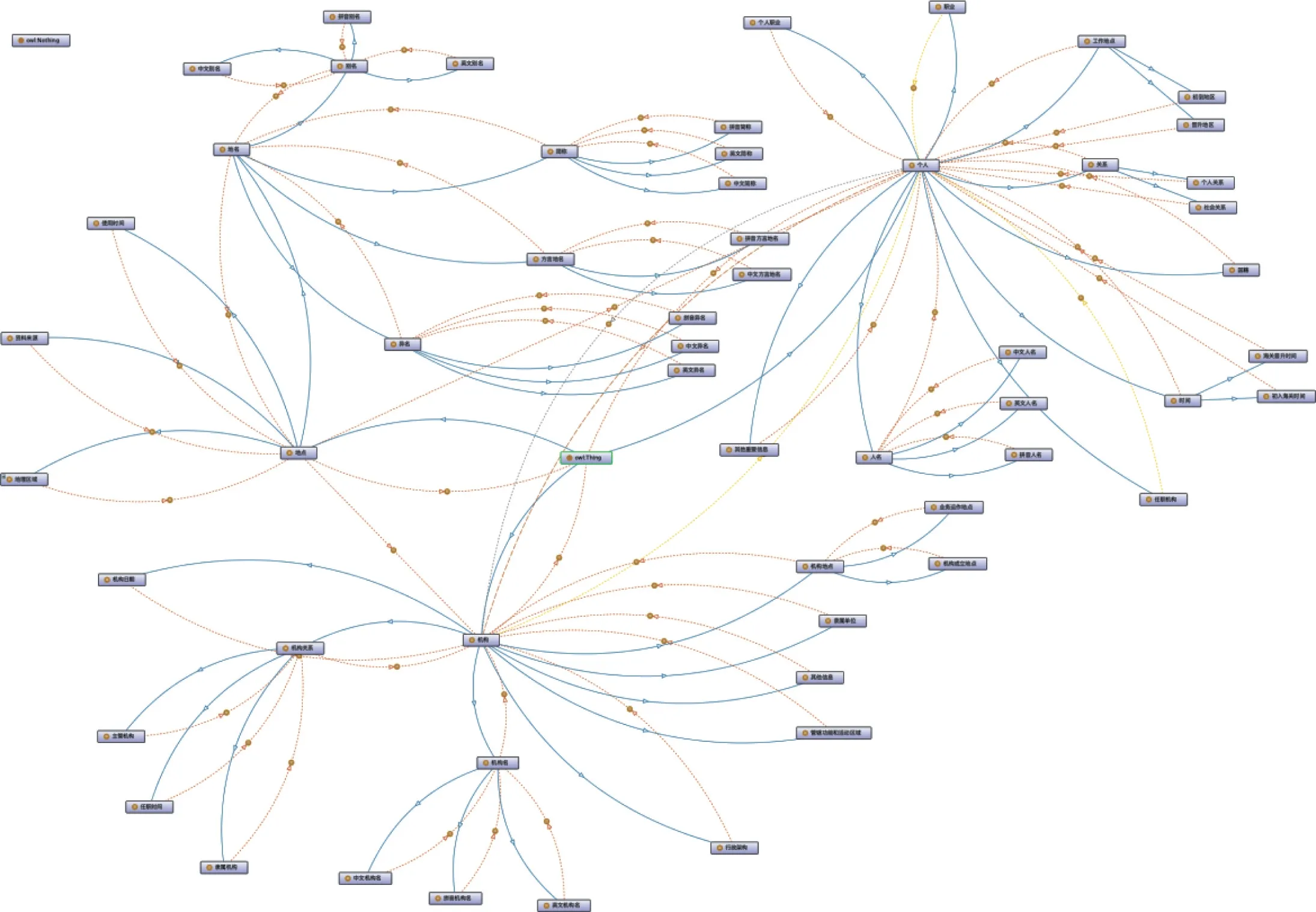
图7 近代广东海关档案名称规范数据关系模型
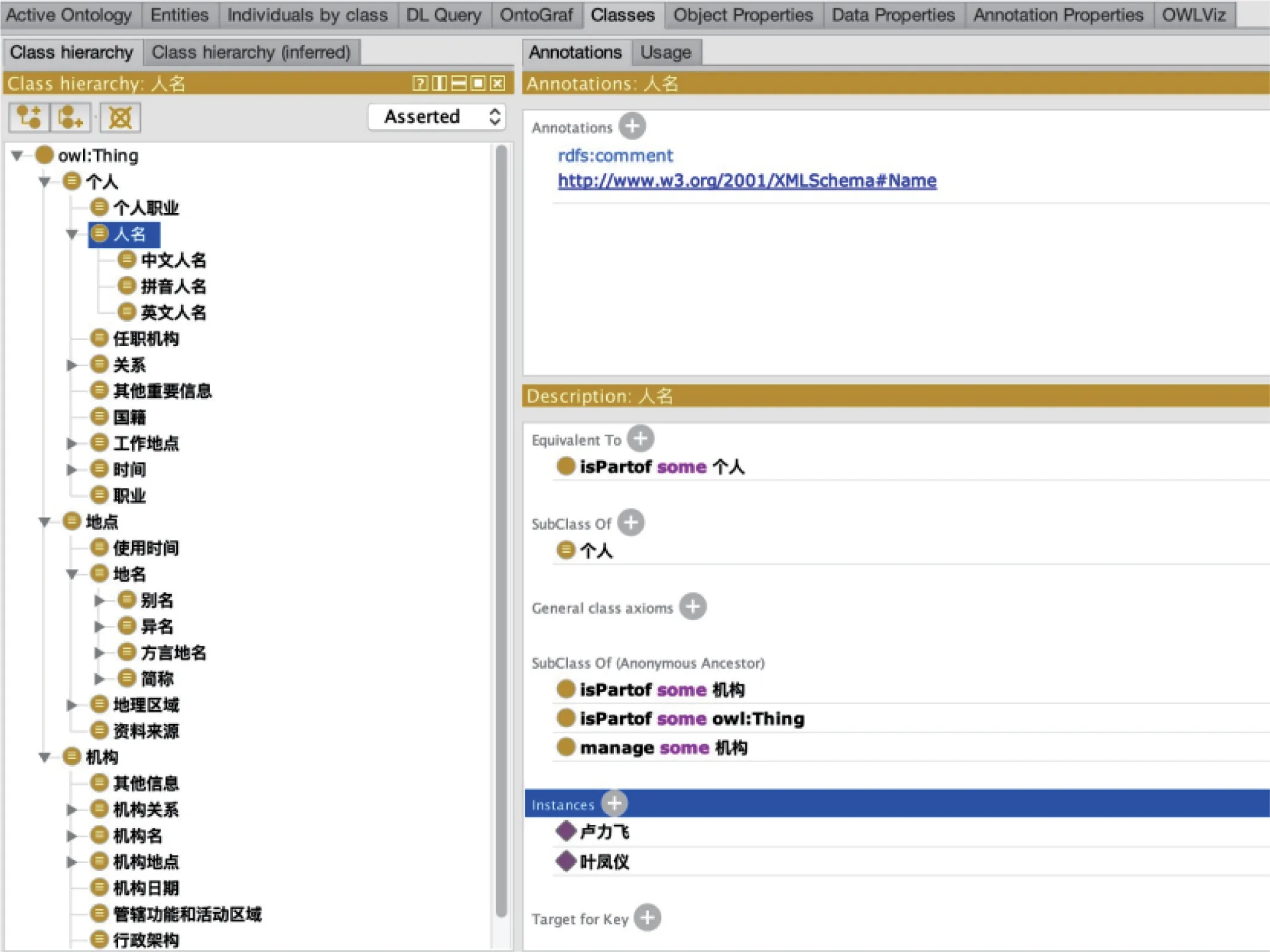
图8 粤海关档案实体信息实例分析——“卢力飞”与“叶凤仪”

图9 粤海关档案实体信息——“卢力飞”与“叶凤仪”
当然,除定义名称,根据粤海关档案的具体记载,其他的相关信息也可以通过资源描述框架rdfs:comment进行整合。
近代广东海关档案内容层次的划分是建立在中国近代海关机构不同类别的基础之上,本文根据档案所涉及的主体信息,对近代广东海关档案实体的类与属性进行了分析。在Protégé工具的辅助下,结合各类实体的属性特征,用OWL形式化语言构建近代广东海关档案规范信息,为后续进一步研究中国近代海关档案著录本体与关联数据信息奠定了基础。
4 结语
本文从构建名称规范档的角度探讨海关档案中各类名称的语义关系,从传统角度开发利用档案信息资源,以保证档案信息形式的逻辑性和内容的完整性,同时,在数字网络环境下,通过对档案数据进行语义转换和数据关联,实现信息时代背景下数据资源充分的开发利用,促进多元异构数据环境下信息的传递和知识共享。此外,依据上述的属性和关系,结合现已成熟的词汇集,对近代广东海关档案专有名词的实体和属性关系进行映射与描述,增强海关档案名称规范数据之间的语义关联,有效地实现海关档案数据资源的关联、共享和最大利用。
