文献整理学术传统对古籍数字化的参照价值(之三)
——以“版本源流考订”为例*
2021-05-11李明杰高晓文
李明杰,卢 彤,高晓文
版本源流有两重含义:一是广义的版本源流,指的是文献制作方式的演变源流,如写本源流、拓本源流、刻本源流、石印本源流;二是狭义的版本源流,指的是单种文献(含丛书)在传抄、翻刻等传播过程中形成的错综复杂的版本传承关系。本文探讨的即为狭义的版本源流。对单种文献版本演变源流的考订,其意义不仅在于梳析历代同书异本之间的传承脉络,更在于从现有的存本中发现和推荐善本。我国文献整理向来有考订版本源流的传统,积累了大量相关的研究成果。这些成果有的以分散形式呈现,如文献中附载的大量序、跋、叙录、校勘记;有的以集中形式出现,如版本目录、版本学专著,以及今人发表的版本学论文。这些既有的版本源流考订成果,如果能在古籍数字化系统中以一种恰当形式呈现,既可以避免后来的研究者进行重复性劳动,也可为读者指明可供利用的善本。为此,本文结合实例,探讨“版本源流考订”这一文献整理传统对于古籍数字化的参照价值。
1 “版本源流考订”的文献整理学术传统
文献在产生之初,就因在记录、传播等各个环节出现的主观或客观因素,产生同书异本现象。所谓版本是指同一种文献在讲诵、铸刻、抄写、传拓、印刷、摄录等不同形式的传播过程中,因书名卷数、篇章次序、文字内容、装订形式等方面的差异而形成的不同物质形态[1]。同一种文献因版本的不同,其学术价值、文物价值和审美价值也大不相同。从研究和利用文献的目的出发,人们都希望读到内容与文献初始面貌较为接近的版本。但在没有祖本的情况下,什么样的版本与文献的初始面貌最为接近,哪些类型的版本从文本的整体性来看最为可靠,这就需要对文献的各种版本进行鉴别和比较,对其源流进行梳理和考订。
早期对文献版本源流的考订与佛经的整理有极大关系。佛经自东汉明帝时传入中国以来,主要依赖口译笔受的方式传播,但因译出多门,传承派别有异,再加经文前后学说改易,各种译本极为混乱,因此有学者萌发了追讨“正本”的想法。中国历史上第一位汉族僧人朱士行,“常于洛阳讲《道行经》,觉文章隐质,诸未尽善,每叹曰:‘此经大乘之要,而译理不尽,誓志捐身,远求大本。’遂于魏甘露五年(260年),发迹雍州,西渡流沙。既至于阗,果得梵书正本。”[2]晋代时佛经的版本问题更为复杂,支敏度在整理《合维摩诘经》时,发现有支恭明、竺法护、竺叔兰三家译本,“余是以合两令相附,以明所出为本,以兰所出为子,分章断句,使事类相从。令寻之者瞻上视下,读彼案此,足以释乖迂之劳,易则易知矣。若能参考校异,极数通变,则万流同归,百虑一致。”[3]支敏度提出的“万流同归,百虑一致”是中国古代版本源流考订思想的最早表达。
唐初雕版印刷技术发明以后,经五代初步发展,至两宋大规模应用,文献传播效率和传播范围得到极大提升,但也加剧了同书异本现象的产生,导致学者更加重视版本源流的考订。入宋以后,以序、跋或书目解题的形式对文献版本源流进行考订已成为学术常态。苏颂《补注神农本草总序》考订了《神农本草》自两汉以来的版本流变过程:先由两汉的三卷本至南梁的七卷本、唐二十卷本,再由唐本分为宋本和后蜀本,而宋本又有详定和重定之别;沈晦《柳先生集序》不仅叙述了柳宗元文集的版本源流情况,还对各版本的异同、优劣、选取底本的依据等都作了说明;吴若《杜工部集序》不仅指明《杜工部集》的建康府本是李端明本、鲍钦止本互校的结果,还对二本中“称樊者”“称晋者”“称荆者”“称宋者”等的版本来源进行了说明;吴正子《笺注评点李长吉歌诗外集》不仅指明了李贺诗集的秘阁本与姚氏本、贺铸本与宣城本的源流关系,并且通过篇卷的考察,论证了鲍本与宣本源自同一版本[4]。宋代还出现了版本目录和版本学专著,关于版本源流的考订以更加集中的形式表现出来。晁公武《郡斋读书志》和陈振孙《直斋书录解题》均有大量考订一种文献版本源流的内容。南宋淳祐年间出现第一部考订版本源流的专著——曹士冕的《法帖谱系》,其在考订版本源流基础上,第一次用谱系图的形式形象地揭示《淳化阁法帖》众多版本的传承关系。
及至明清,受雕版印刷技术成熟、商品经济萌芽、宋元旧椠收藏价值提高等因素影响,士人讲求版本的风气达至鼎盛。对藏书家而言,对版本源流的考订有助于揭示文献的收藏价值。特别是乾嘉时期考据学兴盛,促使藏书家更加重视版本,在购求藏书时必须具备鉴别真伪与版本考订的能力。孙从添在《藏书记要·鉴别》中云:“夫藏书而不知鉴别,犹瞽之辨色,聋之听音。虽其心未尝不好,而才不足以济之,徒为识者所笑,甚无谓也。”[5]学者更多地把考订版本源流作为文献整理的辅助手段,透过比较版本间的差异来解释特定版本的学术价值,达到指明善本的目的。余嘉锡云:“一事也,数书同见,此书误,参之他书,而得其不误者焉。一语也,各家并用,此篇误,参之他篇而得其不误者焉。文字音韵训诂,则求知于经。典章官制地理,则考之于史。于是近刻本之误,宋元刊本之误,以及从来传写本之误,罔不轩豁呈露,瞭然于心目,跃然于纸上。”[6]这一时期(特别是清代)版本源流考订成果的形式更加丰富,除序言、题跋、书目解题(以《四库全书总目提要》为代表)、版本学专著(以《书林清话》为代表)外,还出现了大量的读书记、善本书志等,如钱曾的《读书敏求记》、丁丙《善本书室藏书志》、王国维的《传书堂藏善本书志》。
2 “版本源流考订”学术传统对古籍数字化的参照价值
版本源流考订的学术传统至今有其现实意义,尤其是对古籍数字化而言,因为从本质上讲,古籍数字化仍属于古籍整理的范畴,必然要遵循古籍整理原有的学术范式。但从古籍数字化实践看,很长一段时期内以技术为先导,缺乏对古代文献整理学术传统的借鉴。之前笔者曾撰文论及古籍数字化过程中种种学术失范的现象[7],此不赘述。仅从版本源流考订的学术传统来看,其价值缺失在古籍数字化中主要表现为以下几个方面。
第一,底本选择未能参照版本源流考订的成果。底本选择是古籍数字化的一个关键环节。因为底本选择的不慎,一旦劣本化身千万,不仅使善本因错失入选数据库的机会而被湮没,还会将劣本的错讹放大和扩散,贻误读者,严重的还将拦腰截断前代学人对单种文献的整理成绩。遗憾的是,在古籍数字化实践中,由于缺少版本学专业的指导,人们对底本的选择往往遵循易获得性原则,如不少古籍数据库选用《四库全书》本作为底本就是例证。实际上对于很多古籍而言,四库本的内容经过四库馆臣的篡改和抽换,并不是最善的版本。因此,古籍数字化之前底本的选择,应遵从版本学研究的规律,借鉴前人版本源流考订的成果,从现有存本中择出最优良的版本。
第二,版本源流信息在古籍数字化过程中被遗失。从现有的古籍数字化成果来看,人们往往把注意力集中在古籍正文的数字化转换上,而对正文之外的其他副文本缺乏足够的重视,有时甚至直接删略,如序言、题跋、校勘记、注释、批语等等。而这些写于不同时期的副文本,反映了该书在不同历史阶段成书、翻刻、整理、传阅的经过,保存了不少关于该书原始的版本源流信息,加上传统的书目解题,都是后人考订该书版本源流的重要参考资料。因此笔者建议,在古籍数字化整理过程中,不仅要保留文献中的各种副文本信息,甚至还应将历代书目关于该书的版本著录信息及书目解题,与正文一并作为数字化的内容。
第三,对前人版本源流考订成果未能有效开发利用。对一书版本源流考订的结果,是历代版本学家经科学考订后给出的客观描述或主观判断,既有对微观的文献载体形态特征的著录,也有宏观的版本源流梳理;既包含了与文献整理和传刻相关的历史人物、地理、时间等信息,也包含了比较不同版本之间内容与形式差异的描述,具有丰富的语义内涵。但如果只是对序言、题跋、校勘记、书目提要等进行数字文本的转换,读者很难从中获取直接的版本源流考订成果。如果借助现代信息技术手段,对这些零散的版本源流信息进行数据加工,使之以直观的形式呈现出来,则能极大地方便读者参考与利用。
文献学家对版本源流进行考订,其最终目的是为读者或研究者提供可靠的版本。从读者与研究者利用文献的角度而言,“可靠”的版本至少有两层含义:一是在文字上最接近“原本”;二是在内容和语义上最接近“原本”。文字上最接近“原本”的版本,一指抄写或翻刻次数较少,在出版时间上与祖本较为接近的本子;二指那些经过精心校勘,尽量把文献在各种不同形式的传播环节中有意或无意产生的错误降至最低。内容和语义上最接近“原本”的版本,是指那些经过名家标点和注释的版本。现存文献因为与成书之初的年代相隔久远,对于后世的读者来说,可能因为文字本身的发展演变以及地理名称、行政区划、职官制度的更替变迁而产生隔阂。因此,把历代名家注疏与批校等内容以副文本的形式加入原有的文献之中,可以满足后世读者准确把握和理解文献内容与语义的需求。
版本学家考订一书的版本源流,梳理一书历代版本之间的传承关系,可以让后来者参照其研究成果,考察某一特定版本与祖本的亲疏远近,根据版本信息提供的线索定位该版本在整个版本谱系中的位置,以便从中选择最可靠的版本。尽管这类研究成果很多,但从目前古籍数字化产品看,版本源流考订的成果尚未得到充分的数字化利用。若能对其中的版本源流谱系进行合理的组织与加工,使谱系图从二维的平面图像转为计算机可识别的元数据资源,把经过加工的版本源流信息嵌入已有的古籍数据库检索平台,提供检索结果的可视化输出,或以RDF等信息描述框架建立类似人名规范库的开放资源,则可极大地方便研究者自由获取古籍版本信息。
3 “版本源流考订”学术传统在古籍数字化实践中的应用
目前国内关于中文古籍版本领域本体较具影响力的研究成果,有武汉大学信息管理学院邓仲华等依据版本学领域知识构建的“学习型古籍版本知识库”和上海图书馆夏翠娟等从循证学角度构建的“中文古籍联合目录及循证平台”。邓仲华等的“学习型古籍版本知识库”研究成果是针对本体语言与本体构建技术运用于古籍版本知识数据的结构化组织与系统化存储上的探索性研究,以此作为构建古籍版本数据库的基础,鉴于非专业与专业研究者的不同需求,该数据库面向非专业用户设计,目的是方便用户了解、使用和查询古籍版本学基础知识,由古籍版本术语库、古籍版本学史库、单书版本源流库、广义版本源流库等4部分组成,将版本学领域的知识以语义网的表现形式予以组织与揭示[8]。夏翠娟等的“中文古籍联合目录及循证平台”使用的“古籍循证”概念是基于“循证实践”与“循证社会学思想”而生发出的一种版本学领域的数字人文学理念。与传统版本学依靠经验为主的版本鉴定方法不同,该理念以古籍目录的记载和古籍文献中的内容事实(包括物理证据、内容证据、历史证据与关联证据)为依据,将科学的研究方法与研究人员的经验结合起来,以解决特定研究问题。该平台根据不同学科领域的研究需求,将所收录的机构古籍馆藏目录、现代古籍联合目录,与我国历代不同来源、不同格式的古籍目录,按照FRBR的“作品-内容表达-载体表现-单件(WEMI)”四层模型与BIBFRAME 的“作品-版本-单件(WII)”三层模型的基本结构,提出了中文古籍书目框架的“作品-版本-单件”+“注释”+“分类”的“3+2”古籍书目框架模型,实现了联合目录检索、循证研究等研究辅助功能[9]。
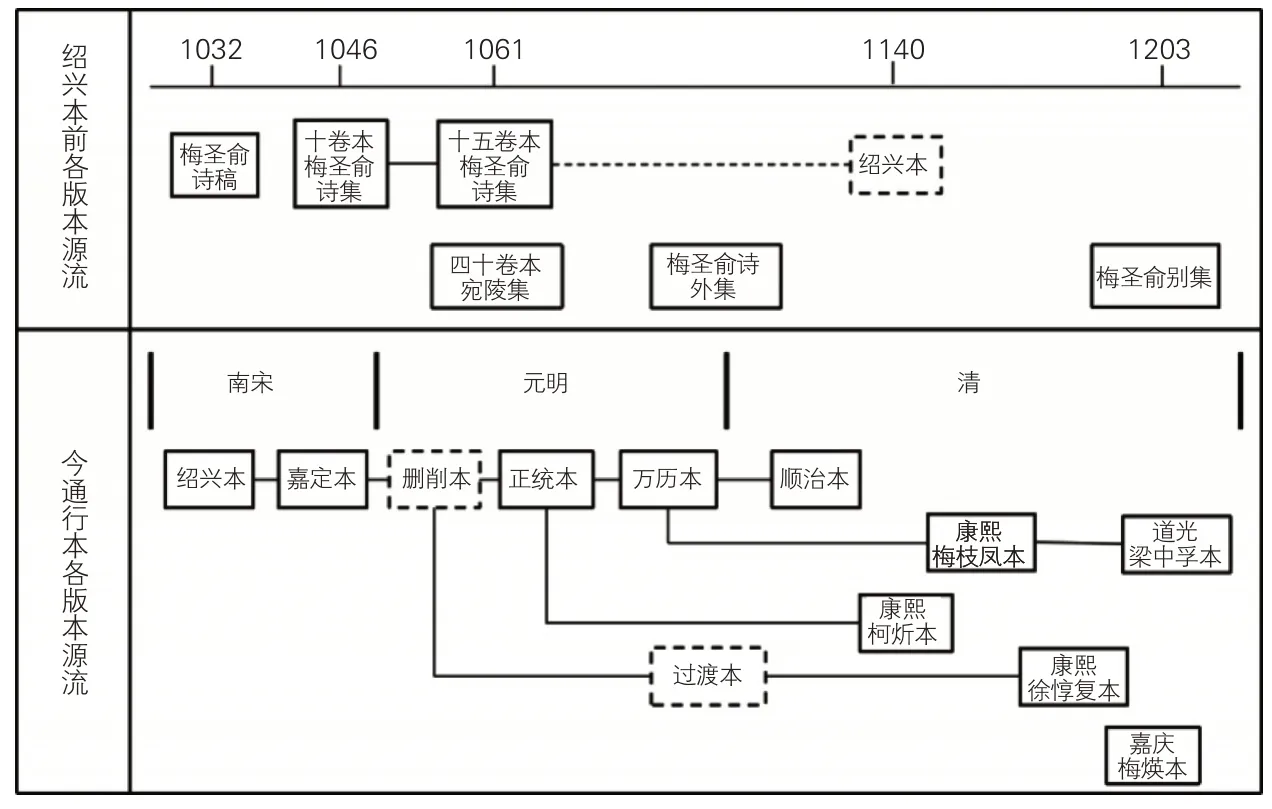
图1 《宛陵集》版本源流谱系图
相较于上述两种研究成果,本文研究实践与其异同点在于:第一,不以版本学的领域知识为对象构建学习型古籍版本知识库,而是以具体的版本源流研究成果为描述对象构建研究辅助型的古籍版本知识库;第二,不以历代官修目录、史志目录与古籍联合目录等书目信息为著录对象进行基于“群体”的大规模循证研究,而是以近代具体的版本源流考据成果(主要指版本源流考订的学术文章与专著)为研究对象,以本体方法揭示一种文献各版本与责任者之间的语义关系;第三,不论版本存佚,同样以“作品-版本-单件”的古籍书目框架为基础,来揭示一种文献完整的版本源流谱系以及其中的责任者关系。基于上述异同之处,本文尝试以本体构建法,将“版本源流考订”学术传统嵌入古籍数字化实践中,为开发符合专业研究习惯的古籍数字化产品提供参考方案,构建面向专业用户的研究型版本源流知识库。通过本体类、本体属性与本体实例设计,以RDF 资源描述框架将古籍版本源流信息表现为细粒度的语意结构,以充分揭示同书异本之间的源流关系,在新的数字环境下践行版本源流考订的学术传统。
3.1 实验数据来源与内容分析
本文选择笔者关于梅尧臣《宛陵集》版本源流的考订成果作为本次实验的数据来源和揭示对象。根据传世序跋、书目提要及各家文集的记载,笔者对宋代诗人梅尧臣《宛陵集》绍兴本之前的各家稿本系统、各刻本的祖本、绍兴本之原貌、绍兴本之后的历代刻本源流进行考辨和梳理,以版本源流谱系形式揭示《宛陵集》稿本的形成经过以及众多刻本之间的源流关系,参见图1。
在进行版本源流知识库的结构设计之前,需先提取出其中所欲揭示的信息,并以关系型数据数据库结构予以表示。在版本源流谱系中,人物、作品、版本、评价及其之间的关系是重要的信息单元,应分别为其设计数据表与数据类型,并定义表间关系。本次实践的表间ER图与各表数据类型如图2所示。
(1)人物(Person)。人物是古籍版本流传过程中的责任者,人物数据表存储与作品、版本及研究成果产生关联的人物信息,包括人名、其他名称、朝代与职业等,表间关系以责任方式(Act)连接。不同的责任方式与连接的实体所对应的是不同的人物类型,与作品相关联的人物是指作者或曾参与该作品内容创作的责任者,如注疏者、编纂者;与版本相关联的人物是指参与改变作品载体形态的责任者,如出版者、作序者与刻工;与评价结果相关联的人物是指曾对该作品的特定版本做出鉴定的版本研究者。
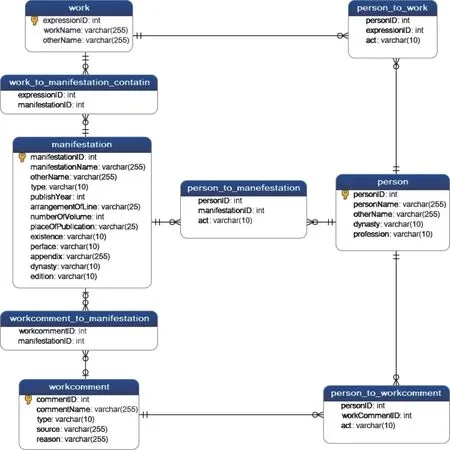
图2 表间关系与数据类型
(2)作品及其内容表达(Work)。在FRBR的定义中,作品(Work)是一个抽象的实体,由作品的实现方式或内容表达(Express)来识别,作品本身只存在于不同内容表达的共性内容之中,而内容表达能反映同一作品在不同实现方式之间存在的知识或艺术内容的区别[10]。为方便操作,本文简化了作品与内容表达之间的层级关系,以作品为实体建立数据表,并创建“其他名称”数据项来存储抽象作品下的具体内容表达,以达到根据作品层面聚集载体表现的目的。
(3)版 本(Manifesta‐tion)。版本对应的FRBR实体为载体表现(Mani‐festation),是一部作品内容表达的物理体现,即“同书异本”。实践中建立版本数据表以存储版本的各种外在特征,包括版本名称、其他名称、版本类型、行款、序跋、版次、存佚情况、卷数、出版地、出版年、附录等信息;同时建立版本与作品间的表间关系,表示两者的从属关系。
(4)版本评价(Work Comment)。版本评价是历代版本研究者对某一文献特定版本所给出的评价结果,因评价者与其所处时代的善本观而异。实践中建立版本评价数据表,包含评价出处(各类版本研究成果)、评价理由(内容精粗、版式优劣等)与评价结果(善本、劣本等)。此外,构建该表与人物表及版本表的表间关系,表示该评价的责任者与评价对象的关联。
3.2 研究型版本源流知识库的结构设计
本次实验根据W3C发布的OWL本体描述语言,采用自顶向下的方式进行研究型版本源流知识库的类、属性与实例的结构设计。
3.2.1 本体类设计
本体的推理是藉由描述个体所属的类,并由类成员关系所继承的属性来达成,虽然个体的属性可透过个别声明赋予,但本体的个体推理功能仍大多是基于对类的推理。本文定义了版本、人物、作品、评价等类别。版本源流知识本体类结构如图3所示。
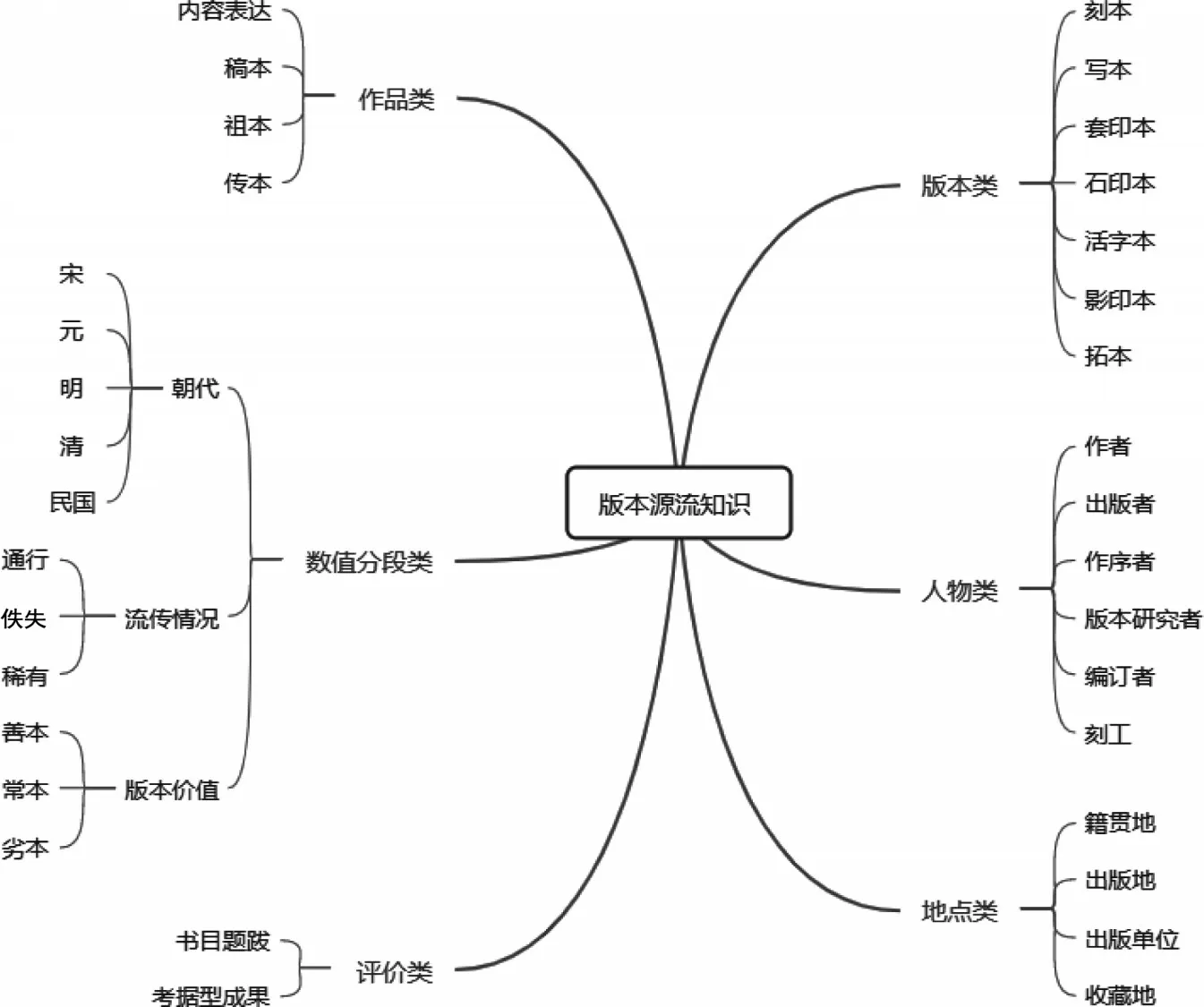
图3 版本源流知识本体类结构
(1)版本类(Edition)。根据文献的具体制作工艺将版本类分为如下子类:写本(Transcript Edition)、刻本(Block Printed Edition)、套印 本(Chromatograph Edition)、影印本(Photocopy Edition)、拓 本(Copy of Rubbings)、活 字 本(Movable Type Edition)、石印本(Lithographed Edition)及钤印本(Sealing Style Edition)。
(2)人物类(Person)。包括某一种古文献的各类责任者,根据责任方式将其分为如下子类:作者(Author)、 出 版 者(Publisher)、 整 理 者(Reviser)、作序者(Prefacer)、版本研究者(Scholar)、刻工(Worker)等。作者指作品的原作者,整理者指历代参与加工作品的内容表达者,如注疏者、校勘者、编纂者。
(3)作品类(Work)。与前文中对作品及内容表达的简化操作相同,便于达到根据作品实现版本聚类的目的。本文在作品类下创建内容表达(Expression)、稿本(Manuscript)、祖本(Original Edition)与传本(Inherit Edition)4 个子类。为区分稿本与刻本,以祖本表示现存刻本源流中各系统的最古刻本,祖本有其所依据的稿本,传本则代表各祖本系统下的子本。
(4)评价类(Work Comment)。有书目题跋类(Bibliography)与考据型成果类(Research Result)两个子类。
(5)其他。包括地点类(Location)与数值分段类(Value Partition)。地点类包括籍贯、出版单位、出版地、收藏地等与版本有关的地理信息;数值分段类是一种用于完善各类描述的特殊类,它不属于OWL或其他本体语言,而是一种设计模式,是对建模过程中反复出现的问题的解决方案[11]。本文创建了朝代、评价结果(善本、劣本、常本)与流传情况(佚失、稀有、通行)等数值分段子类。
3.2.2 本体属性设计
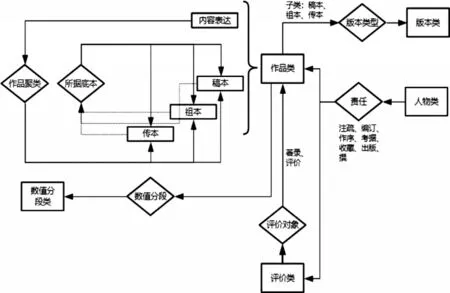
图4 类和对象属性的实体关系图
属性是指关于类成员的一般事实和关于实例的具体事实,分为对象属性(Object Properties)和数据类型属性(Datatype Properties)两类,前者表示两个类的实例间关系,后者表示类的具体特点和事实,用于将实例关联到数据类型[12]。本文关于类和对象属性的ER见图4。
(1)对象属性。本文定义了多个对象属性,同时根据情况创建逆属性,包括:
第一,责任方式(Act)。指不同责任者对不同作品所做的行为,由于责任者因其责任方式而异,因此藉由属性定义域、值域的设定与本体的推理,可以透过属性推知实例所属的类。本文中,责任方式的定义域为人物(Person);值域为作品(Work)或评价(Work Comment);子属性包括:撰(Write)、注疏(Annotate)、编订(Revise)、作序(Preface)、考据(Research)、收藏(Own)与出版(Publish)。
第二,所据底本(Ancestor)。指版本源流谱系中各版本所参校的版本,其逆属性为子本(Offspring)。所据底本的定义域为作品类中的稿本(Manuscript)、祖本(Original Edition)与传本(Inherit Edition),其中稿本与祖本的值域为稿本,传本的值域为祖本或传本。在《宛陵集》版本源流中,刻本的祖本“绍兴本”所据底本为稿本“十五卷本梅圣俞诗集”,而传本“嘉定本”所据底本为“绍兴本”。
第三,作品聚类(Con‐tain)。指一个作品包含多个版本,定义域为内容表达(Expression),值域为稿本、祖本与传本;逆属性为组成(Constitute),定义域为稿本、祖本与传本,值域为内容表达。如《宛陵集》由稿本“十卷本梅圣俞诗集”、祖本“绍兴本”与众多传本(如“正统本”“万历本”“顺治本”)所组成。
第四, 版本类型(Edition)。表示不同版本的载体形式,定义域为稿本、祖本与传本,值域为版本类。如稿本十卷本《梅圣俞诗集》的载体形式为写本,传本“正统本”为刻本。
第五,评价对象(Object)。指书目提要与版本研究成果所研究的特定版本,子属性有著录(Record)与评价(Apprise),定义域为评价类,值域为作品。如《郘亭知见传本书目》著录了元代翠岩精舍本。
第六,数值分段属性(Partition Value)。用来表示一些常用的特性划分,如评价结果、流传情况、时期等,定义域为稿本、祖本与传本,值域为数值分段类。如《梅尧臣集编年校注》的评价结果为善本,流传情况为通行本,时期为现代;“删削本”的流传情况为佚失,时期为元代。
(2)数据类型属性。是通过数据值来描述实例的事实信息,如邓仲华等人在《论中文古籍版本本体库的构建》一文中定义了多种描述版本相关信息的数据类型属性,包括与人物相关的姓名、字、号、成就、思想、流派、籍贯、朝代、及代表作品;与版本源流相关的源流简介、祖本名称、祖本简介、传本名称及传本简介;与版本相关的版本名称、版本全文出版者、出版时间、馆藏、和版本简介等信息[8],以上属性基本涵盖本次实践描述一书版本源流之所需。
3.2.3 本体实例设计
实例是类的具体成员,类则代表实例的集合,是一组人类思维概念组成的对象,因此类被用来对一些具有共性的实例进行分组,以便统一调用[13]。本文根据《宛陵集》的版本源流关系,将各类实例设计如下:
(1)人物类实例。作者实例为《宛陵集》作者梅尧臣;出版者实例为姜奇方、徐惇复、李士琪、李文江、柯炘、梁中孚、梅枝凤、汪伯彦、袁旭及迟日豫等人,为各传本的出版者;整理者实例为欧阳修、谢景初。其中,欧阳修为《梅圣俞诗稿》、十五卷本《梅圣俞诗集》的整理者,谢景初为十卷本《梅圣俞诗集》整理者;版本研究者实例为傅增湘、朱东润、汪远孙、莫友芝、钱泰吉等人,是曾对《宛陵集》进行著录及研究的学者。
(2)作品类实例。内容表达实例为《宛陵集》,又称《宛陵先生文集》;稿本实例为《梅圣俞诗稿》、十卷本《梅圣俞诗集》、十五卷本《梅圣俞诗集》等;刻本祖本实例为绍兴本,又称绍兴十年宣州军学本;传刻本实例包括嘉定十六年宁国府本、翠岩精舍本、过渡本、正统四年本、万历四年本、顺治十六年本、康熙八年本、康熙二十六年会庆堂本、康熙四十一年白华书屋本、道光十年本、梅尧臣集编年校注等。
(3)评价类实例。评价类实例包括《宋元旧本书经眼录》《振绮堂书录》《藏园订补郘亭知见传本书目》《甘泉乡人稿》《甘泉余稿》《郘亭知见传本书目》,以及本次实验依据的笔者关于梅尧臣《宛陵集》版本源流考订的成果。
(4)地点类实例。籍贯实例为宣城,是梅尧臣的出生地;出版单位实例有会庆堂、宣州军学、白华书屋、宣城(官刻)、翠岩精舍等。
3.3 利用Protégé构建研究型古籍版本源流的领域本体模型
基于上文的结构设计,本文以Protégé(5.5.0)为工具进行研究型古籍版本源流的领域本体的构建。具体实验效果如图5所示。
(1)区间显示版本源流相关知识的各父类及子类,包括人物类、作品类、版本类、数值分段类及评价类。
(2)区间展示根据《宛陵集》版本源流信息设计的各类的具体实例。
(3)区间显示选定实例所属的类,如会庆堂本属传刻本类,且属数值分段类中的清代类。
(4)区间显示与选定实例相关的对象属性及数据类型属性,如会庆堂本的对象属性“所据底本”(hasAncestor)为万历四年本,而数据属性则描述其版本载体特征。
Protégé中的OntoGraf插件可将所构建的本体进行可视化,展示本体中类、属性与实例之间的结构关系。如图6所示,在OntoGraf界面中以“宛陵集”为检索词进行检索,其结果显示与《宛陵集》相关的类与实例,右键点击类或实例,可选择所欲呈现的关系属性。右键点击各个实例的“所据底本”(hasAncestor)属性,即可呈现出版本之间的源流关系。
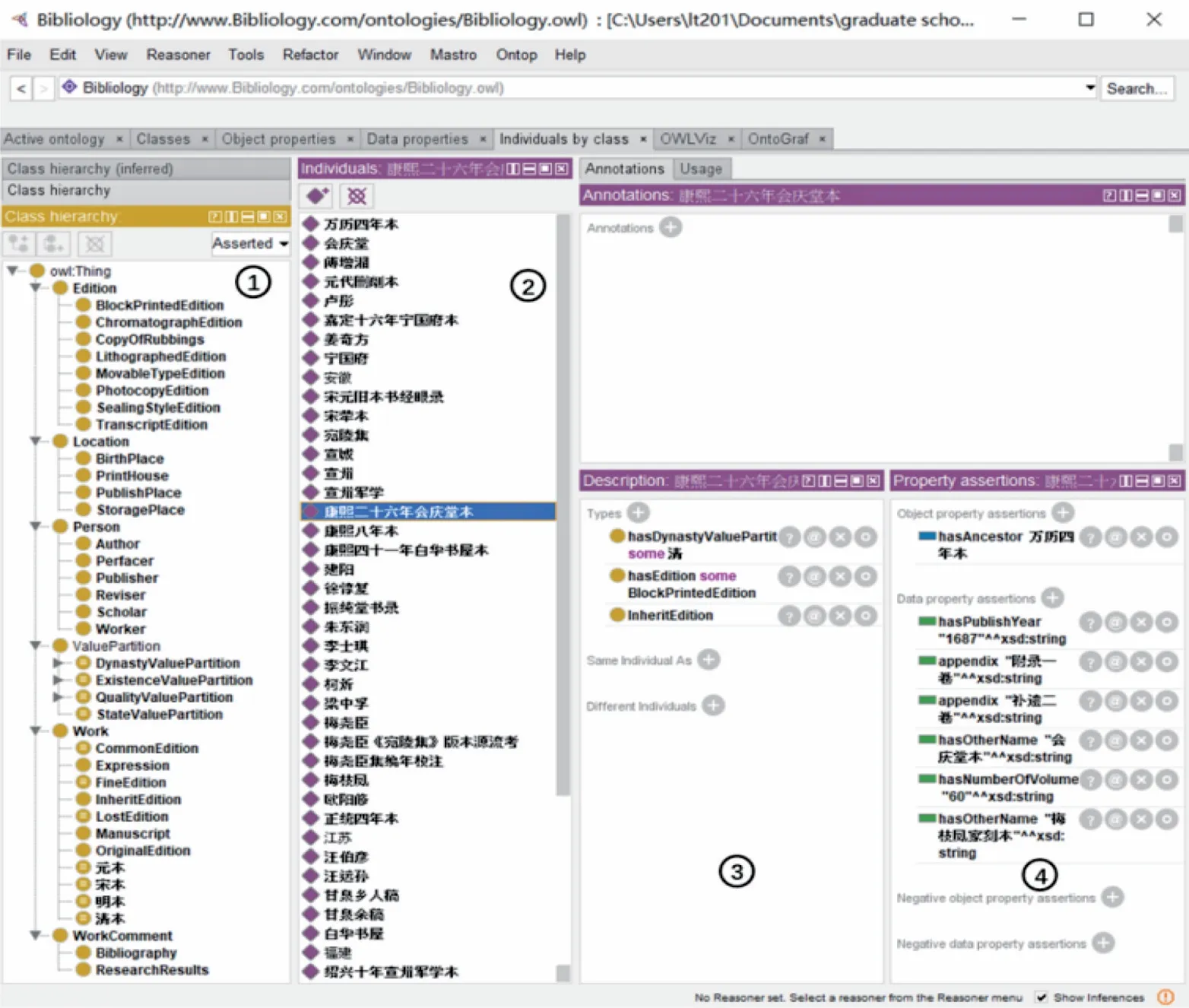
图5 研究型版本源流知识库实现
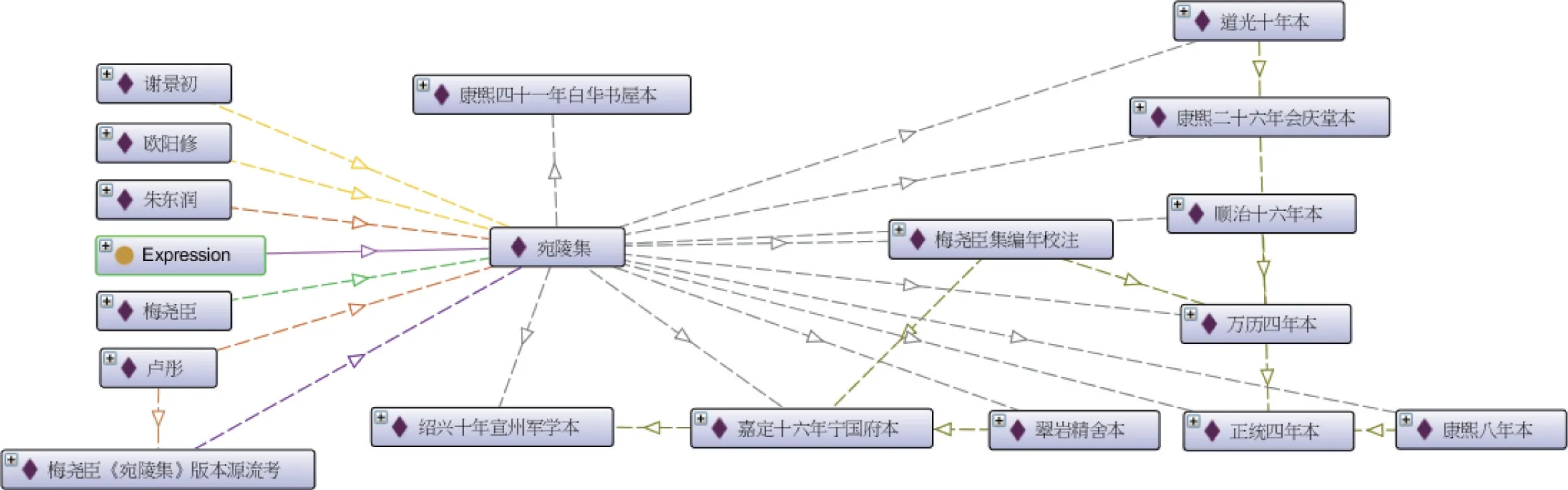
图6 以OntoGraf呈现的《宛陵集》的聚类关系
4 结语
版本源流考订是我国文献整理悠久的学术传统,它对梳析同书异本之间的传承关系,发现和推荐善本具有重要的意义。对古籍数字化而言,版本源流考订一方面可帮助我们选择精良的底本;另一方面,前代学者考订版本源流的成果也可以数字化的形式呈现在古籍数据库中,以帮助读者在从事人文历史研究时选择善本。版本源流考订成果的数字化,既包括对古籍的序言、题跋、校勘记、书目提要、版本学论著等纸质文本的数字化,也包括对这些成果的数据加工和可视化呈现。
为了在数字环境下践行版本源流考订的学术传统,本文完成了针对版本源流谱系的关系型数据库结构设计,并基于本体开发工具Protégé完成了以RDF资源描述框架为基础的本体建模。由于关系型领域知识的数据库建设需要大量的人力物力,因此目前并没有基于古籍版本研究成果构建的开放资源可供利用。未来与古籍版本源流考订成果相关的本体研究,是在构建完备的关系型数据库前提之下,利用W3C 的RDB2RDF 工作小组所制定的R2RML、D2RQ,将关系型数据库映射为RDF 格式的数据,如此便能以SPARQL访问非RDF数据库,或通过Web将数据库内容作为关联数据访问,或将数据库的内容转换为RDF 格式并予以保存,或使用Apache Jena API访问非RDF数据库[14]。
在版本源流谱系的可视化呈现上,目前有许多开源工具可供利用。例如,基于开放源代码框架Adobe Flex 编写的RelFinder[15],可提取并可视化RDF数据中所选对象之间的关系,交互探索对象之间的关系,具有突出显示和过滤功能,以支持全局和详细级别的可视化分析,并可与提供标准化SPARQL 访问的任何RDF 数据集一起使用[16],嵌入RelFinder即可以SPARQL查询语言实现对RDF数据的查询和可视化呈现。
