面向标签传播算法的社团检测研究现状及展望
2021-05-10张应龙夏学文吴泓润
张应龙,夏学文,徐 星,喻 飞,吴泓润,余 鹰
1(闽南师范大学 物理与信息工程学院,福建 漳州 363000)
2(华东交通大学 软件学院,南昌 330013)
1 引 言
社团检测是网络研究分析中的一项重要任务[1,2],它以介观尺度观察和理解网络,有助于分析挖掘团体之间的关系动态、模式和功能,找到隐藏的内在关系与规律并预测复杂网络的行为,从而更好的理解复杂网络.相关术语有社团、社区、图划分、聚团或群组结构等,本文对这些概念统一称之为社团.
自从Newman等人提出社团概念[3]以来,产生了海量的社团检测算法[4],可分为全局优化和局部优化两大类[5]局部优化通过网络的局部拓扑结构特征,来揭示局部或整个网络的社团结构.相较于全局优化方法,局部优化不仅无需整体的网络结构信息及先验知识的辅助,而且在计算代价、挖掘局部社团特性等方面存在更多优势[5,6].
标签传播算法Label Propagation Algorithm(LPA)[7]凭借其简洁原理及近乎线性的时间代价等优点,成为局部优化方法的代表.在过去的十几年中,研究者发表了大量相关的工作.
目前优秀的社团检测综述[4-5,8-11]尚未重点关注LPA算法.文献[4,8]从全局的角度分析了社团检测研究现状.文献[5,11]概括了局部优化的社团检测方法.文献[9,10]重点介绍了动态社团检测方法.尽管这些综述有助于了解社团检测研究现状,然而缺乏对LPA算法这一分支的详细介绍、分析与总结.
鉴于上述,有必要系统分析与总结标签传播算法研究现状、面临问题以及前景,从而为其勾画出一个较为详细和全面的轮廓,为社团检测等相关领域的研究提供有价值的参考.
2 基础知识
2.1 数据集及常用符号
本文所涉真实网络数据集统计信息如表1所示.这些数据集一个共同特点是其上的真实社团结构为已知,更多详情见文献[12].
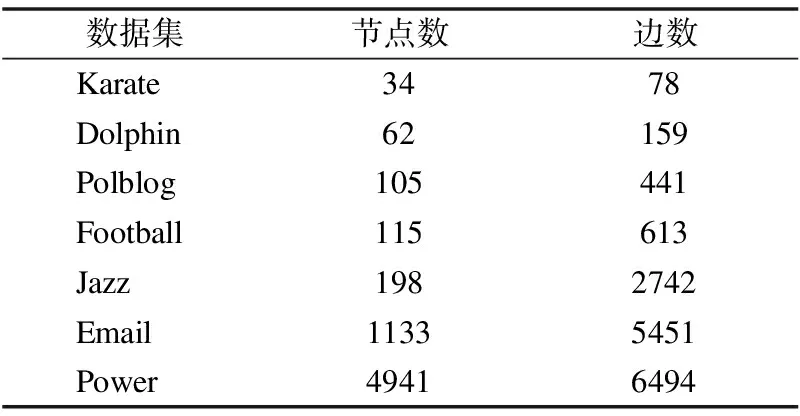
表1 本文所涉及的真实网络统计信息
LFR生成网络[13]是常用的一个评价社团检测的测试基准网络.主要通过节点度数分布γ、社团大小分布β以及混合参数μ等3个参数控制生成基准网络.其中参数μ表示一个节点的所有边中占比1-μ条边属于同一社团,μ越小则生成的基准网络越能呈现出清晰的社团结构.
文中常用符号见表2.

表2 文中常用符号描述
文中用到了如下基于共同邻居和节点度数的节点相似度度量.RA index[14]:
(1)
Edge-clustering coefficient(ECC)[15]:
(2)
这里τ(u)=Nu∪{u}.
2.2 评价指标
如何衡量社团检测结果质量是一个很大挑战.目前存在多种评价指标[4,16],其中典型的评价指标为模块度(Modularity)[17]和NMI(Normalized Mutual Information)[18].
已知算法检测出的社团结构和其对应的不具有社团结构的空模型,模块度基本思想是比较社团内边密度与相应空模型的期望边密度的差值,差值越大表明相应的算法性能越优.模块度定义为:
m为网络边数,Aij为网络的邻接矩阵A的元素,di为节点i的度数,ci为节点i所属的社团,δ为克罗内克函数.
NMI用来评价一个社团划分X与基准划分Y相比的准确程度:
ci为第i个社团,CX和CY分别是X和Y对应的社团数.NMI的值域是0到1,越高代表被评价的算法越准.特殊的,社团划分和基准划分完全一致,则NMI值为1.
3 LPA算法简介与分析
3.1 社团定义
网络用图G=
集合{ci|ci⊆V,∪1≤i≤kci=V,1≤i≤k}为网络G上一组社团,对于1≤i≤k,1≤j≤k,i≠j,当ci∩cj=∅,即任何两个社团都没有交集,这时为非重叠社团,当存在ci∩cj≠∅时,即存在两个社团有交集,对应称为重叠社团.
3.2 LPA算法
LPA[7]算法无需任何先验信息:社团数以及社团的大小,也无需预先定义和优化目标函数,具体过程为:
a)每个节点赋予一个唯一标签,这时每个节点当作一个单独社团.
b)随机顺序更新节点标签,对于节点v,赋予其最大计数的邻居标签:
(3)
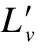
c)重复过程b),直到所有的节点拥有其计数最大的邻居标签时终止迭代.
最终,紧密连接的节点间形成共识采纳相同标签组成一个社团,不同标签的节点组构成不同的社团[7].为了叙述方便,在上下文不引起歧义的情况下,文中把社团和标签等同对待.
LPA有两种更新节点标签方式:同步与异步.
同步更新是指节点x基于上一步,即第t-1步的邻居标签更新其标签:Lx(t)=f(Lx1(t-1),…,Lxk(t-1)),这里x1,…,xk为其邻居,f为标签更新策略函数,例如公式(3).
异步更新:Lx(t)=f(Lx1(t),…,Lxm(t),Lx(m+1)(t-1),…,Lxk(t-1)),这里x1,…,xm为x的邻居且当前迭代里已经被更新,x(m+1),…,xk为x的邻居且当前迭代里仍未被更新.
文献[19]表明异步要比同步收敛的更快,而同步更新得到的结果更稳定,质量更好.
若邻接矩阵为A,则公式(3)可变换为:
(4)
基于公式(4),文献[20]把LPA算法形式化为优化问题,标签传播过程实际是最大化目标函数H:
(5)
例如当更新节点x的标签时,公式(5)变换为:
(6)
由式子(6)可知,公式右端的第1项的值不会发生变化,第2项与公式(4)一致,因此当更新节点x时,H的值不会变小,并且最终使H达到局部最大值.
3.3 存在的问题与挑战
LPA算法简洁、且时间复杂度接近线性:O(n+m),n为节点个数,m为边个数.但存在以下一些问题与挑战,过去的十几年中,研究者主要针对这些问题与挑战对其进行改进.
a)性能有待提高.LPA算法总是选择节点的最大计数的邻居标签作为其标签,未考虑网络的其它特征.例如,不同邻居对节点的影响不同,节点是否处于社团中心等,而这些特征一定程度上影响社团检测的质量.因此,原始LPA算法的性能有待提高.
b)不确定性(Randomness).不确定性是指结果具有不可重复性:每次运行结果可能会不同.导致不确定性的因素之一为平局的解决方案(tie resolution)[7]:当节点v的计数最大的邻居标签(公式(3))具有多个时,则在其中随机选取一个作为v的标签.另外,随机顺序更新节点标签,同样会产生不确定性[21].如图1所示网络,整个网络分为两个社团,然而右端3个节点的不同更新顺序会导致不同结果,若先更新节点3,其计数最大邻居标签有多个:1、4、5,节点的标签有可能选为1,然后更新节点4,其最大标签变为1,这样整个网络划分为一个社团;相反,若先更新节点5,选择其标签为3,接着更新节点4,其标签变为3,节点3的标签保持不变,从而右侧3个节点组成了一个社团.
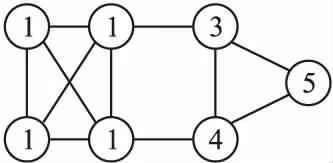
图1 不确定性现象[22]
c)标签震荡现象.同步更新方式会产生标签震荡现象(oscillation problem)[23].这种现象多见于二部图中,其他类型网络也有可能发生这种现象.如图2所示,从其相邻两次迭代标签(节点的颜色)的变化,观察出这种现象使得算法无法收敛.虽然异步更新方式在某种程度能解决上述问题,但这种方式不利并行计算、结果不稳定以及容易产生大的社团.
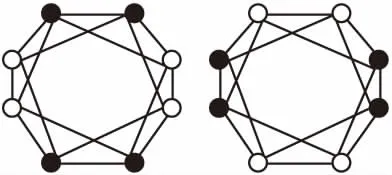
图2 标签震荡现象[24]
d)平凡检测(trivial detection)问题.检测算法有时把整个网络当作一个社团.这可从公式(5)得到解释:社团越大,H的值越大,特别的,当所有节点具有相同的标签时,H具有全局最优值;更多的时候,会产生大的社团(monster community)[19].社团结构不明显的网络更会导致平凡检测[7].
e)重叠社团检测.真实网络中,社团间具有重叠性,即节点可以属于多个社团.这些重叠节点是社团间桥梁,在信息互通及社团演化方面起着重要作用.分析社团重叠结构有助于理解复杂网络.由于LPA算法原理简洁,因此有必要利用其原理研究如何检测重叠社团.
f)动态社团检测.在线社会网络研究中,社团演化检测是一个十分关键的核心问题,它对于在介观尺度下观察在线社会网络结构特征、预测演化趋势、掌控网络势态、发现网络异常群体事件等具有重要意义[9].如何运用LPA算法的优势进行动态社团检测的研究是十分有意义.
上述问题不是单独存在,有时相互交织在一起,例如图1所示的不确定的例子中,其中一个结果就产生了平凡检测现象.针对以上存在问题,研究者提出了系列改进的LPA算法.
4 基于LPA的社团检测算法
按前述问题的分类,本节介绍和分析解决相应问题的LPA算法.在基于LPA原理基础上提出了各种策略构成了这些算法.相应的优秀算法是各种策略的组合,没必要单独评价某一策略的优劣,故文中在综述现有研究内容(策略)后,比较与评价了同一问题下的代表性算法.
4.1 提高算法性能
现分析导致LPA算法性能不高的原因及相应解决对策.
对于社团而言:内部节点间链接关系更稠密,不同社团的节点间链接关系更稀疏.其中一类方法引入如下策略[26]:直接邻居间链接越稠密对应的贡献值就越大,越有可能处于同一社团.边(u,v)的局部边介数(local edge betweenness)[27]是另一类衡量局部链接稠密程度的度量:经过(u,v)的所有长度不超过h(h>0)的最短路径的个数.局部边介数值越小,对应的节点之间越稠密,越有可能处于同一社团,文献[28]在更新节点u时,计算u的du条边的长度为2的局部边介数,在边介数值小的1+du/2条边所关联的邻居中选计数最多的标签Lu赋予u,这样在原有算法基础上进一步考虑了局部链接稠密性.
LPA标签传播过程中,节点等同对待其所有邻居,然而真实网络中,不同邻居对其具有不同影响力,因此等同对待邻居不能真实反映网络特征.针对该问题,研究者引入了基于链接的节点间的相似性进行区分不同邻居的重要性,例如,文献[14]在更新节点标签时,把与其具有最高相似性值(公式(1))的邻居标签更新为其标签.
节点在网络中所起的作用不同,有的节点处于社团中心,有的节点则不然,然而LPA算法没有考虑这种节点的中心性.因而,研究者提出了节点中心性概念,文献[29]把节点及其邻居的度数之和定义为节点的密度,密度越大表明不仅节点本身重要而且其被重要的节点包围,那么密度值大的节点最有可能为核心点,核心点把标签传递给邻居,从而形成种子区域,然后进行标签传播.
改进的算法主要从以上3方面提高社团的质量.然而这些算法没有解决不确定性、平凡检测等问题,而且后续介绍的算法中都有蕴含这些优秀思想,但为了强调这些思想,故汇总在此.基于上述原因对本节所涉算法不进行分析比较.
4.2 不确定性(Randomness)
4.2.1 平局问题引发的不确定性
解决平局问题有如下方法:1)当存在多个最大计数标签时,不再随机选择,而是按某种规则在其中选择一个标签;2)不以最大计数为标准选择标签,采用新的标签传播规则.
首先分析第1大类方法:在多个最大计数标签中选择链接密度高的标签.
存在多个不同定义的链接密度,对于节点u,文献[30]定义其邻居v的绝对链接密度为:suv=1+mNv,这里mNv表示v的邻居集合Nv中相互链接的边数,然而,该方法倾向于识别出大社团,甚至可能导致平凡检测问题发生[31].基于此,文献[31]定义了邻居v新的链接密度:LDuv=⎣α/suv」,参数α的作用是平衡高链接密度的和稀疏的邻居区域.针对不同的网络如何取相应的α的值是该方法存在的问题.而文献[32]则基于包含了链接密度的信息[33]定义重要节点,但该算法时间复杂度高为O(n2).文献[15]则在其中选择一个同时属于其偏好邻居节点集的标签,否则在候选标签中随机选一个,节点u的偏好(高链接密度)邻居节点定义为:
这里σ(u,v)为公式(2),ρu=(∑v∈Nuwuv)/(n-1).
第2大类方法是建立系列新的标签传播机制:更新最相似的邻居标签为节点标签.
本类方法主要基于共同邻居定义节点间的相似性,例如直接计算节点间的共同邻居数[21].在基于共同邻居的基础上,研究者引入了节点度数[14,34-35]定义相似性,例如文献[14]和文献[35]基于公式(1)定义节点相似性,而文献[34]定义如下相似性:σ(u,v)*dv,σ(u,v)见公式(2).文献[35]更新v的标签时,不仅要求具有最相似性的邻居标签,而且增加了限制条件:v加入该社团能增加模块度值.特殊的,文献[23]基于了更多因素定义了节点间的相似性度量CNP[36].
与以上算法不同,文献[37]为每个节点保留来自邻居的多个标签.算法通过Inflation操作使得标签隶属系数大的更大,小的更小,然后进行Cutoff操作:过虑掉小于指定阈值的隶属系数的标签.
4.2.2 随机顺序引起的不确定性
现有主要措施为:1)从中心点出发更新节点标签;2)固定更新顺序.
第1大类算法思想首先需确定中心节点,然后标签由中心节点按一定的传播规则向外扩散[22,38-41].部分工作以节点度数定义核心节点[22,38,40],度数越大越有可能成为核心节点,也有工作依据节点密度值[39]来定义核心节点:
这里di为节点i的度数.其次面临的问题是如何选取中心节点,基本思路为选取最大度数(密度值)且互不直接相连(相似)的核心节点作为中心节点.工作[22,39]需要人为设置k个中心点,为了避免人为指定k,工作[38]选取邻居区域度数最高的节点作为中心节点且保证中心节点间互不为邻居,但该工作对大规模网络的处理能力有限.工作[40]则规定中心点间的距离不小于网络的平均距离,而平均距离需要求所有节点对的距离,这会产生昂贵的时间代价.
第2类依据节点的邻居链接密度值从小到大固定更新顺序:工作[42]定义密度值Cohesion Index:
CI(u)=nSim(u)/CC(u)
工作[44]认为节点在开始迭代时要比结束时表现出强的传播性,开始时,节点有可能把其标签传播邻居,从而形成社团,然而,在最后几次迭代中,节点不能有效的把其标签传播出去.为此节点按访问顺序逆序设置其传播强度,从而降低访问顺序对结果的影响.
4.2.3 小结
表3为代表性算法采用的策略及时间复杂度,表中符号‘/’表示与原算法LPA保持一致.需要注意的是,在解决平局策略相应标有的‘/’,尽管仍是随机选择,已与原算法的随机选择的含义不同.例如表中算法WILPAS,把与节点v最相似邻居的标签更新为其标签,这种相似性不仅基于与邻居的共同邻居,而且与邻居的节点度数有关,因此存在多个最相似邻居标签机率很低,某种程度上解决了平局问题引发的不确定性.从表中算法采用的策略可知,一大部分算法能够同时解决平局问题和随机顺序引发的不确定性.

表3 解决不确定性的LPA算法策略,O1核心节点向外扩展,O2固定顺序,S最大相似性邻居标签,D高链接密度的邻居标签,F最大计数
时间复杂度方面,表中u表示合并社团次数,d为节点度数.时间复杂度为O(n2)及以上的算法已不适合处理大型网络.
LDPA可能导致平凡检测问题发生[31],BLDLP和ASCD-LPA需要人为设置参数.
表4中数据来源于前述相关论文,“-”表示缺乏相关数据.表中可知性能最好的几个算法为WILPAS,CenLPA,LPA-S与TS.在LFR生成网络中,WILPAS的性能优于CenLPA[34],而LPA-S与TS算法时间代价高,不适合处理规模大的网络数据.

表4 解决不确定问题的代表性算法的在真实网络上NMI值
综上,能够快速处理大规模网络数据,且相对稳定的基于LPA算法首推WILPAS.
4.3 标签震荡现象
标签震荡本质是使得标签更新迭代无法收敛.
由于随机的异步更新方式能够避免标签震荡,但会导致差的性能、弱鲁棒性以及不适合并行计算.LPA-SYN算法[45]采用同步更新的方式,利用概率更新策略来避免标签震荡.文献[45]的观点认为标签震荡产生的主要原因是采用计数最大的邻居标签,然而在真实世界中,节点很大概率选择邻居中计数最大的标签,也存在机会(概率)选择其他标签包括当前自己的标签.
文献[24]了半同步LPA算法.该算法分为两阶段:第1阶段着色,使得任何相邻节点的颜色不同,得到l个不同颜色的划分D={D1,D2,…,Dl}.第2阶段标签传播阶段,重复以下操作直到达到终止条件:按划分的下标j从小到大依次对Dj中的每一个节点v做如下处理,
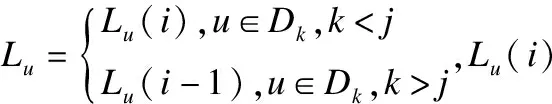
基本的迭代终止条件是与上次迭代比较,所有节点的标签没有发生变化.由于标签震荡,这样的终止条件有时会失效.文献[7]提出如下终止条件(c1):每个节点的标签与其最大计数的邻居标签一致.如果存在多个最大计数的标签,且该节点的标签同样为最大计数的标签,这时保留该标签[20],否则随机选一个,文献[24]记这种版本的半同步LPA为LPA-Prec.
文献[24]提出了一种方案保证算法的收敛性.该方案定义了标签的优先级(标签用整数表示),当标签l>l*,那么l比l*更具优先,若存在多个最大计数的标签6时,则取最高优先级的标签,相应版本的LPA记为LPA-MAX[24].同步的LPA-MAX产生的标签震荡现象不超过两趟,因此给出一个简化版的c1的终止条件,记为c2:如果每个节点的标签与其上一次迭代或上上一次迭代相同,则算法终止.文献[24]把LPA-Prec和LPA-MAX的策略结合起来得到的半同步的LPA记为LPA-Prec-Max.
LPA-SYN最大的问题是在计算标签概率时需要人工设定参数,不同的网络结构需要设定不同参数[24,45].LPA-Prec要比其他算法更稳定,而LPA-max最不稳定但最快,LPA-Prec-Max是好的折衷[24].综上所述,代表性算法推荐LPA-Prec-Max.
4.4 平凡检测(trivial detection)问题
LPA算法在标签传播过程中存在类似的“马太效应”.有些“强”社团会变得越来越大,甚至整个网络最终变成一个社团.
4.4.1 基于引导标签的方法
导致平凡检测深层原因复杂,至今仍没有完全探究清楚.其中一个可能的原因是在传播过程中对标签缺乏针对性的引导.为了避免发生平凡检测问题,研究者主要通过3种不同策略引导标签传播.
第1种策略通过传播跳数控制标签的影响力[19]:
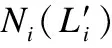
由于δ需要人为设置,文献[46]提出了动态跳数衰减策略:按标签发生变化的节点比例设置δ.文献[46]工作同时又采用了节点偏好策略:把节点分为社团核心点和社团边界点,在此基础上提出了系列算法.
第2种策略是在迭代早期优先扩展小社团.文献[7]结果表明5次迭代后95%的节点达到了其最终状态,因而杜绝平凡检测需要早期干预,优先扩展小社团.在第t次迭代时,只统计v的满足如下条件的邻居标签的计数[47]:邻居标签对应的社团成员数小于c(t),这里c(t)=n([kt/T]+1)/k,T为总迭代次数,t为第t次迭代,k为参数(文中k取50、100和200).t越小,迭代越处于早期,c(t)值也越小,越优先扩大小的社团.在此基础上,工作[48]又定义了不同的c(t).
第3种策略与上述策略不同,通过如下条件来抑制社团扩张:社团内部链接密度强度达到一定条件时,免除该社团参与标签传播或社团合并过程[12].该条件在推迟形成大的社团方面起着关键作用.
4.4.2 基于公式的方法
文献[20]通过修改目标函数H(公式(5))来避免平凡检测:H′=H-λF,λ是F的权重,所有节点具有相同标签时,F的值最大,因此F是用来抵消H从而避免平凡检测;F的不同选择,对应不同算法:LPAr[20]与LPAm[20].文献[20]没有解决随机性.
LPAm倾向于陷入弱的局部模块(modularity)最大值,而且算法不稳定[49].为此,文献[49]提出了一个改进的算法LPAm+解决弱的局部模块最大值问题:组合使用LPAm和合并社团的方法.该方法在模块值方面要优于LPAm,并且更稳定,然而更耗时间.结合最大隶属系数[50]和LPAm,文献[51]提出的LPAbp算法很好抑制了平凡检测问题,但仍然没有解决结果的不确定性.文献[52]针对LPAm+存在的问题:在社团结构不明显的网络中容易陷入局部模块值大,设计了基于启发性的LPA算法.该算法“以退为进”,在某些时段,允许合并的社团不增加模块值,从而避免陷入局部模块最大,使得下一阶段能够更好的增加模块值,但该算法需要针对不同网络,人工确定参数,算法代价高O(mnlogn).
4.4.3 采用网络构造的方法
LPAp算法[53]把标签传播转换为网络构造过程,而网络构造过程中,渗流转变(percolation transition)被认为导致产生大的连通分量,另一方面,渗流转变可以被终止[54],因而把阻止平凡检测的方法对应为在网络构造过程中防止渗流转变现象发生.然而该算法的不确定性问题仍然没有解决.
4.4.4 基于记忆的方法
MemLPA[55]算法在标签更新时,节点除了采纳新标签之外,还记录保存了所有邻居标签.每个节点维护一个用来存储标签的列表,列表中每个元素记录相应标签的计数.迭代更新时,选取该节点列表中计数最大的标签作为该节点的标签,而这个计数不仅是当前邻居标签所贡献,而且还考虑了历史状态中标签的贡献值,这种策略防止最终结果返回单一大的社团.
4.4.5 小结
表5为为解决平凡检测问题算法的时间复杂度,由表可知基本保持线性时间复杂性.

表5 解决平凡检测问题的算法时间复杂度
涉及到基于引导标签的方法有LPAD[19]、DPA[46]、CLPA[47]以及SSCLPA[12]等,总体而言该类方法优于其他算法.
ODLAP[45]性能要比LPA略好,而DDALPA[46]检测质量较差,BDPA(与DPA)优于这3个算法[46].在较小的网络上,BDPA性能比LPAD[19]要好,当网络增大时,LPAD倾向发现大的社团,modularity值更大.DPA算法无论在时间还是检测质量上都要优于这些算法,在少部分真实网络上(表6),LPAm检测的社团质量优于DPA,但其消耗了更多的时间[46],因此,DPA是以上算法中比较好的选择.
尽管SSCLPA是确定性算法,并且性能也相当不错[12],但在在生成网络(LFR),当μ=0.8附近时,SSCLPA检测质量低;在真实网络中,如表6所示,DPA算法的质量优于SSCLPA和MemLPA.而文献[47]实验表明CLPA优于DPA,尤其是网络结构不明显的情况下.综上,推荐使用CLPA算法.
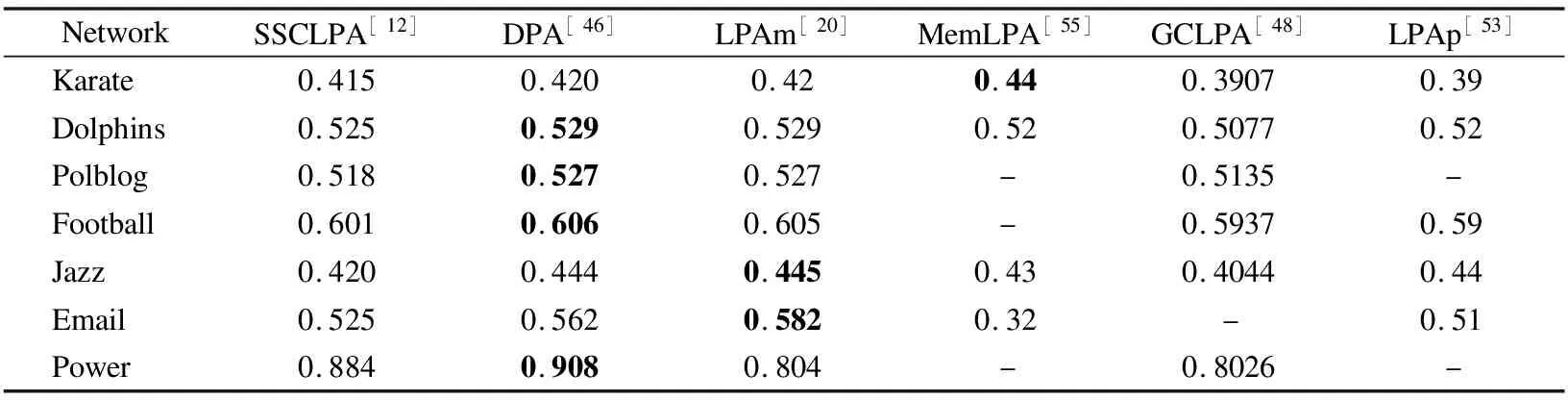
表6 算法在真实网络中的modularity值
4.5 重叠社团检测
为了检测重叠社团,节点处理并记录多个标签.若某个节点拥有多个标签,那它属于多个社团.
具体的,每个节点x关联一组(c,b),c表示社团的标识(标签),b是隶属系数:反映x属于社团c的概率.第t次迭代时,通过某种方式把邻居标签传给x,例如bt(c,x)=∑y∈Nxbt-1(c,y)/|Nx|,然后删去所有小于规定阈值的隶属系数(c,b),对剩余的隶属系数进行规约,使其满足隶属系数之和为1.
目前的算法可分为:1)多标签传播算法:节点的所有标签都参与了传播;2)单标签传播算法:虽然节点拥有多个标签,但按一定规则只选择一个标签参与传播.
4.5.1 多标签传播算法
算法COPRA[50]通过参数r来控制社团的重叠程度:节点最多同时属于r个社团.每次迭代后删去所有小于阈值1/r的隶属系数(c,b),然后进行规约.
多标签传播算法都是基于COPRA算法基础上进行改进.改进的算法可分为两大类.
第1类,首先抽取“rough core”:最小极大团(smallest maximal clique).对同一rough core节点赋予相同标签[56,57],然后进行标签传播.工作[56]采用同步的方式对所有节点进行标签传播.而工作[57]保持最小极大团内的节点标签不变,利用相似度作为权重,四周扩散标签.
第2大类考虑了节点在网络中所处位置以及相互之间相似性不同,导致所起的作用也不同.为此在标签传播时考虑了不同邻居不同作用[58-61].
4.5.2 单标签传播算法
单标签传播算法同样可分为两类.一类是基于占优势标签的方法[62-64].该类方法把节点的最大隶属系数对应的标签定义为占优势标签,只有占优势标签参与传播,标签传播中同样考虑了不同邻居的不同作用.另一类是基于SLPA的方法[65,66].在标签传播过程中节保留了其所有标签.标签传播规则为:节点x为listener时,其每个邻居依据特定speaking规则(例如计数最大的标签)发出一个标签,x根据listening规则从邻居中接受一个标签:当前迭代中它所观测到的最流行的标签(例如:计数最大).
4.5.3 小结
表7列举了相关算法的技术细节.在标签传播策略中,除了SLPA,其余算法都是在COPRA的标签传播规则:

表7 代表性重叠社团检测算法采用策略
bt(c,x)=∑y∈Nxbt-1(c,y)/|Nx|
的基础上额外考虑了所列的信息.每次节点x的标签更新结束后,删除小于特定阈值的隶属系数的标签,r为全局设定的参数,而其它的阈值设置更为科学合理.SLPA则保留了所有标签直到迭代结束后集中处理:删掉小于指定阈值的隶属系数的标签.
算法NALPA计算复杂度为O(n2),尽管复杂度高,但其检测质量较高[61].在不确定性方面,算法PLPA与SLPA接近[60],但其适合在社团结构模糊的网络(LFR网络为μ>0.3)中检测重叠社团[60].LINSIA是确定性算法,然而其性能较差[61].
算法LPAMNI、COPRA、SLPA和DLPA都需要设置参数,其中LPANNI借鉴了DLPA和WLPA[67]的一些优点.在真实网络中,依据稳定性与社团的检测质量,SLPA、COPRA和DLPA稳定性差,而WLPA较好,LPAMNI为最好[64].在不同规模和重叠密度、以及社团结构较模糊(μ=0.3)的LFR网络中,LPANNI、DLPA 和SLPA检测质量较好,其中LPAMNI最好.而稳定性方面LPAMNI和WLPA最好,DLPA次之,COPRA和SLPA最差[64].
综上,忽略时间因素,NALPA性能最好;综合时间与性能,推荐LPAMNI;当处理社团结构模糊的网络(LFR网络为μ>0.3),推荐PLPA.
4.6 动态社团检测
网络分为6种状态[68]:生成(birth),壮大(growth),收缩(shrink),合并(merge),分割(split)和消失(death)(见文献[69]).
现有工作主要是对发生变化的节点集进行相应的如下操作:1)使用现有的各种LPA算法更新;2)提出新的标签更新策略.
4.6.1 基于现有的LPA算法的动态更新
在发生变化的节点集上,使用现有的基于LPA算法进行标签更新[25,70-72].这些方法除了使用不同的基于LPA的方法之外,最大的区别是对变化的节点集的定义.工作[71]定义变化节点集为发生变化的节点集合.而工作[25]和[72]则把其定义为发生变化的节点及其邻居的集合.工作[70]进一步扩充了变化的节点集合,使其包含了变化节点所属社团的所有节点.
4.6.2 基于新策略的动态更新方法
针对动态环境下存在的一些问题,研究者提出了系列标签更新策略[63,69,73-74].例如,为解决动态环境下的平凡检测问题,基于边的权重和随传播跳数增加而标签影响力减弱这两个因素,工作[73]设计了标签更新策略;针对新节点很少有机会创造新社团,工作[74]结合LPA和信息扩散CID模型[75]设计标签更新策略;针对基于团(clique)的算法[69,76]在动态社团检测存在如下两个缺陷:1)每次网络变化,需重新计算团(clique);2)大小至少为k的团才能组成社团,这就导致大量的外围节点不属于任何社团,为此工作[69]把节点划分为核心节点和外围节点基础上设计标签传播策略;为避免相邻网络快照的社团结果变化剧烈,工作[63]结合最近一次网络快照和当前网络标签情况进行标签传播.
为了有效进行动态更新标签,除了工作[63],大部分工作只在发生的变化的节点集上运用相应的标签更新策略.
4.6.3 小 结
表8为动态社团检测算法分类.RWSALPA和SBSALPA检测出的社团质量较高,而且RWSALPA要比SBSALPA更具优势,在高度重叠的社团网络中,RWSALPA、SBSALPA比SLPAD、DLPAE 更好[73];然而RWSALPA和SBSALPA算法时间复杂性高O(nm),丧失了LPA算法的接近线性的时间复杂性的优点,因此二者不适合处理大规模数据.CIDLPA性能优于SLPAD与DLPAE,而SLPAD优于LabelRankT算法,尽管CIDLPA要比SLPAD和DLPAE处理时间方面稍慢,但三者的时间复杂性基本相同,因此综合起来推荐CIDLPA检测大规模动态重叠社团[73];以上算法都是检测动态重叠社团,而DLPAE能够检测非重叠社团,因此在检测动态非重叠社团方面推荐DLPAE算法.所有动态检测的方法,随着快照增加,性能在降低,原因是只关注变化的部分,而忽略整体的网络.动态社团检测仍然属于研究的起步阶段.

表8 动态社团检测算法
4.7 其他算法
本节简介由于没有明显特征而无法归纳到以上6个分类之中的方法.
文献[77]提出了基于边标签的传播算法,文献[78]利用图的一些简单特征(带权度数,聚类系数),采用机器学习的方法把边分为3大类:社团内的边,社团间的边,无法判断的边;把属同一社团的节点聚合起来,进行标签传播.文献[80]将LPA思想应用到二部图的网络粗化(network coarsening)策略中,使相应算法的复杂度降低为线性.基于一组种子节点(seed vertices),文献[80]利用LPA策略检测相应的一个最佳局部社团.文献[81]在分布式系统进行基于LPA的社团检测.
5 总 结
以时间为跨度单位总结LPA算法的发展,第1阶段(2007-2010)为开始阶段,在LPA算法发表一年后出现了一些工作,主要集中在解决LPA的平凡检测问题[19-20,49],另外提出了首个基于LPA的重叠社团检测算法CORPA以及解决标签震荡问题的改进算法[24].
第2阶段(2011-2015)为发展阶段,算法集中在解决不确定性、重叠社团检测、动态检测以及解决平凡检测问题上.其中大部分工作是为了解决不确定性问题,重叠社团检测方面,首次提出了单标签算法SLPA,期间也出现了动态网络上的社团检测算法,这阶段尽管关于平凡检测的算法很少,但提出了较为优秀的算法DPA以及代表性算法CLPA.
第3阶段(2016-2020)为逐渐成熟阶段,这一时期的工作更为细致,产生了表9所列的大多数代表性算法:WILPAS、LPANNI、PLPA和CIDLPA.总体来讲,该阶段大部分的工作集中在重叠检测、解决不确定性问题以及动态网络上的社团检测.
尽管表9列出了代表性算法,但是其它算法的优秀设计思想同样值得借鉴.这里给出这些代表性算法使用场景的建议,对于非重叠社团检测,当网络的社团结构较明显时建议使用WILPAS算法,若该算法无法收敛或网络为二部图时,采用LPA-Prec-Max算法,社团结构不明显时采用CLPA,重叠社团检测推荐LPAMNI,当处理社团结构模糊的网络(μ>0.3),推荐PLPA.动态网络上的重叠社团检测推荐CIDLPA、非重叠社团检测推荐DLPAE.

表9 代表性算法
6 展 望
LPA算法的收敛性至关重要,对于作者合作网络,原始LPA算法迭代10000次后仍有10%节点的标签发生变化[46],为了防止无限迭代下去,一般设置一个最大迭代次数.探讨基于LPA算法在复杂网络中收敛性仍然是一个开放性问题.
基于LPA的算法主要集中在提高社团检测质量,解决不确定性、标签震荡现象以及平凡检测等问题上.这些算法只针对其中的若干个问题,在保持现有时间复杂度不变以及保证质量前提下,如何设计LPA算法使得同时解决不确定性、标签震荡现象以及平凡检测问题需要继续深入探索.
目前,基于LPA算法主要应用在同构网络.同构网络已不足以应对现实中问题,异构网络在生活中普遍存在[82,83].另外,真实世界的许多复杂网络中都存在对立的关系,尤其是在信息、生物和社会领域,这些网络表示为符号网络[84].如何将LPA思想移植到异构网络和符号网络进行社团检测有很大的研究空间和较高的研究价值.
最近,研究者结合机器学习和LPA方法[66,78]进行社团发现,然而这些方法没能有机的融合机器学习和LPA,机器(深度)学习成为当下的研究热点,涌现出众多的优秀思想,如何借鉴这些优秀思想,使其与LPA有机融合,在超大网络中快速有效检测社团是未来值得研究的一个方向.
