融合重要性采样和池化聚合的知识图推荐算法
2021-05-10梁顺攀王荣生原福永张熙瑞
梁顺攀,涂 浩,王荣生,原福永,张熙瑞
1(燕山大学 信息科学与工程学院,河北 秦皇岛 066004)
2(河北省软件工程重点实验室(燕山大学),河北 秦皇岛 066004)
1 引 言
由于互联网上的信息逐渐演变为多源异构信息,图神经网络(GNN)因其更强大的数据表达能力得到广大研究者的密切关注.基于GNN方法的模型也产生了许多的优化变种.一些方法侧重于对采样策略的设计.如PinSage[1]方法使用随机游走的方法进行邻域采样,在大规模图网络中取得了不错的效果.另一些方法侧重于如何聚合邻居节点的特征,如GAT[2]方法采用注意力机制学习相邻节点的特征权重并聚合,通过度量每个邻居节点与中心节点之间特征向量的相关性然后偏向性的聚合不同邻居的特征.
同时,也有越来越多的学者将GNN应用到知识图推荐系统中.Rex等人将GNN应用于二部图推荐模型[3],并将其部署在Pintereset上.Wang等人提出了RippleNet[4]和KGCN[5].RippleNet是一个向外传播模型,它在基于每个用户的潜在首选项的路径中扩散用户的兴趣项,以生成用户表示.KGCN利用邻域聚合来计算项目表示.此外,可以将邻居聚合扩展到多层节点之外,并允许模型捕获高阶和远程实体依赖关系.Wang等人提出知识图注意力网络(KGAT)[6],在知识图上利用注意力网络,递归地生成用户和项目嵌入表示.这些方法也遇到了一些新的问题,如,当GCN聚合邻居节点时,图卷积网络存在邻居爆炸问题.在基于GNN的推荐模型中,当前层中每个节点的表示是从其邻居的上一层表示中聚合出来的.随着跳数的增加,多跳邻居会消耗大量的计算资源.为了解决这个问题,现有的基于GNN方法的知识图推荐算法,如PinSage,RippleNet和KGCN,均采用“固定邻域”策略,在每一层模型只采样固定大小的邻居,而不是使用完整的邻居集,以减少计算成本.
除了邻居爆炸问题,基于GNN的知识图推荐模型,如KGCN,Pinsage,当图形特征的阶数增加时,大量的噪声实体和模型参数维数的增长将导致训练过程难以收敛.Tai等人提出了一种基于阶段训练框架GraphSW[7].在每一个阶段,只用KG中一小部分实体而不是大规模实体以此来探索关键信息,分批次进行训练,后续的批次可以共享前一批次学习到的权值.该框架在加速模型的训练上取得了不错的效果,但并未直接解决以上问题.因此,本文针对以上问题从邻域采样和邻域聚合两个角度进行了探索,提出了基于关系紧密度的采样策略和平均池化聚合策略,在选择邻域时,依据关系紧密度来衡量不同邻居对当前节点的重要程度,选择对当前节点更重要的邻居进行采样,换言之,采样更有可能带来有价值信息的邻居,这种方式可以减少随机采样带来的不确定性,也可以预先给模型一个训练导向,加速训练过程.而在聚合邻域时,本文使用mean-pooling聚合代替均值聚合,其可以更有效的捕捉更关键的信息而减少因维数增加产生的大量噪声.最后,本文在KGCN模型上应用本文所提出的策略,并采用GraphSW框架加速训练过程,对5个真实数据集(BookCrossing,MovieLens-1M,LFM-1b 2015,Amazon-book 和Yelp 2018)进行了实验.结果表明,本文提出的策略可以帮助KGCN更快的从KG中收集到更关键的信息,并改进其在所有数据集上的推荐性能.
本文的主要贡献如下:
1)本文提出了一种基于关系紧密度的启发式采样策略,通过重要性采样选取更具代表性的邻域节点.
2)本文提出了一种基于池化操作的聚合策略,通过一种可学习的差异化聚合方式更好的聚合邻域信息,进而得到当前节点的嵌入表示.
3)在真实数据集上的实验结果表明本文提出的改进模型KGCN-PL可以有效的提升推荐效果.
2 基于重要性采样和池化聚合的知识图推荐算法
2.1 本文改进后的模型
在结合重要性采样和池化聚合方法之后,本文提出的改进模型KGCN-PL如图1所示.首先通过计算关系紧密度作为邻居的重要性并以此作为采样标准对邻居进行筛选,其中中心灰色节点为待训练节点,外围灰色节点则为被采样邻居节点,白色节点为非采样邻居节点.然后根据所采样邻居节点进行池化聚合,并结合自身节点特征聚合成新的节点表示.最后将聚合得到的项目嵌入与用户嵌入相乘得到最终预测结果.采用Graph-SW框架加速训练,对输入节点进行分批次训练,第一批初始权重随机,后续批次使用上一批次训练权重作为初始权重.最终得到所有预测结果.KGCN-PL算法流程如算法1所示.
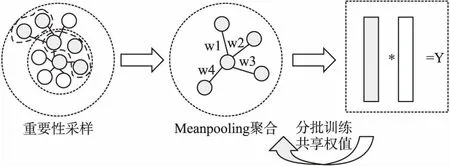
图1 KGCN-PL模型图
算法1.KGCN-PL算法
输入:数据集用户-项目交互矩阵Y、知识图g、邻域采样集合S(e)、参数Θ
输出:预测用户项目交互概率
F(u,v|Θ,Y,G)
1.使用Graph-SW框架分T批次训练.
2.for i=0,…,Tdo
3. while KGCN-pl[i]未收敛 do
4. for(u,v)inYdo

6.eu[0]←e,∀e∈ε[0];
7. fork= 1,…,Hdo
8. fore∈E[k]do
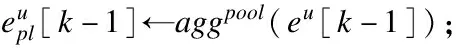

11. end
12. end
13.vu←eu[H];
16. 梯度下降更新参数;
17. end
18. returnF,w
19.end
20.returnF;
21.Function 获取邻域集合:
22.ε[H]←v;
23.for k = H-1,…,0 do
24.ε[k]←ε[k+1];
25. for e∈ε[k+1]do
26.ε[k]←ε[k]∪S(e);
27 end
28.end
2.2 基于关系紧密度的采样方法
基于GNN的推荐模型通常使用随机的固定大小的邻居采样方式,由于计算资源有限,使用少量样本模拟全部样本固然可行,但是随机采样的方式会导致模型效果的不稳定,很容易丢失重要的邻居节点信息.本文考虑在采样过程中更有针对性的选择相对重要的邻域节点以使模型更容易的学到用户偏好.具体来说,本文计算网络中所有节点与中心节点之间的关系紧密度,值越高则说明该节点对于中心节点越重要,即为本文的采样目标节点.在没有获取节点具体特征的情况下,常用的计算关系紧密度的指标有CN系数(common neighbors)[8],Adamic/Adar系数[9],RA系数(资源分配系数)[10]等,相关公式如下,其中Sxy代表邻域节点y和中心节点x的关系紧密度,Γ(x)表示节点x的1阶邻居节点集合,k(i)为节点度值.
CN共同邻居数公式如式(1)所示:
Sxy=|Γ(x)∩Γ(y)|
(1)
AA系数公式如式(2)所示:
(2)
RA系数公式如式(3)所示:
(3)
其中CN系数直接比较共同邻居的数量,以共同邻居的数量考量关系紧密度,共同邻居数越多,节点间关系更紧密.RA系数在共同邻居数的基础上引入了度值的考量,对共同邻居的影响加以区分,认为共同邻居的度值越高越有价值.AA系数对RA系数中的度值计算做了取对数处理,它考虑到可能存在某些节点的度数过高对关系紧密度的计算带来干扰,比如一个节点与大部分节点相连,那么它必然成为很多节点的共同邻居,而它的度值很大,使得其它共同邻居的作用变得很小,这使得度值大小反而不利于计算关系紧密度,故而对其取对数处理可以缩小度值的绝对值,这样可以有效的考虑度值因素带来的影响,而又不使其影响过大.
考虑到推荐场景中知识图中节点共同邻居数量并不多,度值大的节点仅仅表示该实体特征比较平均,而计算度值会带来指数级的计算量成本,故而本文采用CN系数作为关系紧密度计算标准.
通过计算关系紧密度,即可获取一个按关系紧密度排序的节点列表,选取固定大小的前n个节点作为本文选择的邻域.考虑到推荐数据集通常比较稀疏,节点度值通常较小,对采样影响较小,为便于计算,本文采用CN系数作为采样标准.具体算法流程如算法2所示.实验结果表明,加入了采样策略后的推荐模型可以在较少批次下的训练达到随机采样更多批次下后的训练效果,模型会更快的收敛.分析认为,加入重要性采样因素,实际相当于给推荐模型指导了一个方向,使其更易于找到更突出的特征,减少模型维数增长带来的噪声.
算法2.重要性采样算法
输入:实体e,知识图G,e的邻域S(e)
输出:e的n阶采样邻域Sk(e)
1.for i = 0,…,ndo
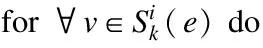
2. 计算cal[v1]=S(v1)∩S(e)
3. end

5.end

2.3 基于池化操作的聚合方法
在KGCN中,提出了3种聚合方式,即Sum,Concat和neighbour,然而三者的区别仅在与是否保留自身节点的特性,以及邻居和自身的结合方式,主要针对邻域与自身的聚合.在邻域的聚合方式上均使用均值聚合,这种直接求均值的聚合方式可能会丢失很多特征信息,在KGCN中也提出了一种策略,使用用户嵌入和关系矩阵相乘求得用户关系评分,从而获取一个用户偏见权重,类似于GAT方法,但是由于关系矩阵是随机采样后的矩阵,所以其并不能表示用户真正的兴趣偏好,经实验验证该方法对有效捕获邻居特征并无明显帮助.受GraphSage[11]的启发,本文发现在邻域聚合过程中,使用对称可训练的函数可能有益于更好的捕捉邻域的不同方面的特征,本文在实验几种聚合方法后,使用mean-pooling方法作为邻域聚合方法.在这种池方法中,每个邻居的向量通过一个完全连接的神经网络独立地输入;在此转换之后,平均池化操作被应用于跨邻居集聚合信息,如式(4)所示.
(4)

Meanpooling方法通常用于卷积层之后,作为特征提取层聚合新的特征.如图2所示,本文将其应用于全连接层结构之后充当特征提取层.简单来说,首先为邻域中的每个节点表示计算特征向量,然后引入一个全连接层学习权重信息,再通过均值池化将邻域向量聚合.最后与自身节点表示进行聚合以保留部分原始信息,如式(5)所示.该方法有效地捕获了多层邻居的不同方面特征,并将其聚合到节点表示当中.

图2 池化聚合示例图
(5)
3 实验与结果
在本节中,为了评估本文所提出的两种改进策略的有效性,本文在KGCN中使用本文的改进策略,并使用分级训练Graphsw框架得到本文的改进模型KGCN-PL.在CTR任务中,使用MovieLens-1M和Book-Crossing2个数据集与基于知识图嵌入的模型CKE[12],SHINE[13],基于链路的模型PER[14],KGCN原模型以及仅使用GraphSW框架的KGCN-SW这5个近年提出的效果最优异的知识图推荐模型进行对比评测.另外,为了验证所改进模型的泛化性能,在Top-K任务中,使用5个数据集与KGCN以及KGCN-SW进行了详细的对比评测.
3.1 评价指标
为了更直观的体现本文所提出的两种改进策略的作用,本文使用在KGCN论文中所使用的同时也是推荐系统在CTR任务中最常用的指标AUC进行验证.另外,在Top-K任务中,也使用常用指标Recall进行验证.
3.2 数据集
本文在CTR和Top-K任务中一共使用了5个数据集(Book-Crossing,MovieLens-1M,LFM-1b 2015,Amazon-book,Yelp 2018)验证本文提出的方法,下面简单介绍一下各个数据集的基本情况.
MovieLens-1M:MovieLens-1M数据集是电影推荐中广泛使用的基准数据集,该数据集包含大约6036名用户,总共2445个条目,100万条评分记录(从1到5).
Book-Crossing:Book-Crossing数据集是从book-crossing社区收集的.它包含139746条评分记录(从0到10)对应14967个项目和17860名用户.
LFM-1b 2015:LFM-1b 2015是关于记录艺术家、专辑、音轨和用户的音乐以及个人收听事件信息的数据集.数据集包含总共有15471个项目,12134用户以及300万条的评分记录.
Amazon-book:Amazon-book是关于用户对图书产品的偏好的数据集.它记录关于用户、项目、等级和时间戳的信息.数据集包含9854个项目,7000名用户以及50万条评分记录.
Yelp2018:Yelp2018是Yelp挑战赛2018年版的数据集,是关于当地企业的.数据集包含16000名用户,14000个项目和120万条评分记录.
3.3 实验和结果
在本节中,本文分别针对CTR和Top-k两个任务分析评估本文所提出的策略的有效性.在CTR任务中,本文首先选取数据丰富的Movielens-1M和数据相对稀疏的Book-crossing两个数据集将本文提出的改进模型KGCN-PL与5个近年来表现优异的相关基线模型进行对比评测.如图3和图4所示,其中CKE使用实体嵌入方法学习知识图谱中的实体特征,由于未能直接将知识图谱中的实体特征用于推荐任务,因此效果比较差.SHINE原本为处理社交网络信息而设计,这里用于处理知识图谱信息,效果不是很好,这可能与社交网络和知识图谱本身的结构差异有关.而PER过于依赖元路径的设计,在没有专家设计元路径的情况下在两个数据集均取得了最差的效果.KGCN-PL在信息更丰富的Movielens-1M数据集上取得了一定的优势,由于有效数据很丰富,KGCN本身也可以在多轮训练后在该数据集上取得很好的效果,此时KGCN-PL在训练速度上会更有优势.在数据较为稀疏的Book-Crossing数据集上,本文的KGCN-PL获得了更明显的优势,这证明了本文所提出的策略在捕获重要特征,且在弥补数据稀疏性上有一定的作用.此外,为了验证本文的改进策略的泛化性能,本文在Yelp2018、LFM-1b2015、Amazon-book3个数据集上与KGCN和KGCN-SW进行进一步对比评测,如图5、图6和图7所示,实验结果表明KGCN-PL在以上3个数据集上与KGCN相比同样取得了有效的提升,这证明了本文提出的改进策略具有很好的泛化性能.
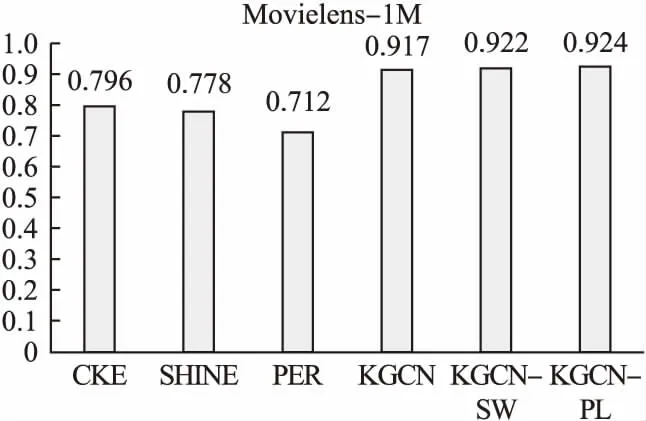
图3 MovieLens-1M AUC对比柱状图
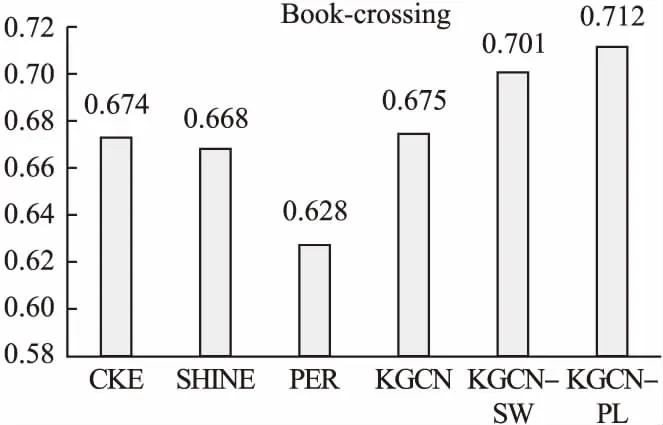
图4 Book-crossing AUC对比柱状图

图5 Yelp2018AUC对比柱状图

图6 LFM-1b2015 AUC对比柱状图
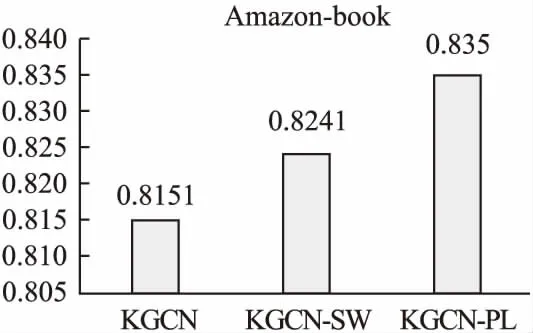
图7 Amazon-book AUC对比柱状图
在Top-K任务中,本文取K=25和K=50两种情况,在5个数据集上进行实验.如表1所示.结果表明,本文的KGCN-PL在所有数据集上与KGCN以及KGCN-SW相比推荐效果均有提升.其中在更有说服力的R@25上与之前效果更好的KGCN-SW对比在MovieLens-1M,Book-Crossing,LFM-1b 2015,Amazon-book,Yelp2018上分别取得了2.5%,8.1%,15.2%,14.3%,3.6%的提升,这进一步证明本文所提出的策略是具有泛化性的,并且在数据稀疏的数据集上可以提供更多帮助.

表1 在各个数据集中进行Top-K任务的Recall@25 和Recall@50的结果
4 总 结
本文提出了基于重要性的采样策略和基于池化操作的聚合策略,并将其应用在最新的GNN知识图推荐模型中,分别从邻域采样和邻域聚合两个角度有效的缓解维数增多带来的噪声问题以及模型难以收敛的问题.实验结果表明,使用本文提出的两种改进策略后,模型在准确度和效率方面优于现有的最新的基于知识图的推荐模型.因此,本文的方法是可行且高效的.在今后的工作中,本文考虑在保证训练效率的情况进一步探索非固定邻域采样方法.
