一种弥补群组成员差异的可解释性组推荐方法
2021-05-10吴彦文
吴彦文,宁 彬,李 斌
(华中师范大学 物理科学与技术学院,武汉 430079)
1 引 言
绝大多数推荐系统都是为个人推荐而设计的,通过挖掘个人的兴趣爱好可以向个人推荐电影,音乐,书刊等.在某些情况下针对一个群体也可以使用推荐技术,例如一群朋友聚会计划去餐厅吃饭,可以为群体提供可供参考的餐厅或者餐品信息.传统的组推荐采取群组成员偏好融合的方式,其基本思想是提出融合模型,在用户偏好提取阶段对用户的偏好进行模型融合,但是这种方式不适合群组成员差异度较大的情况.群组差异度较大时,采取去除差异而强行融合成一种偏好,这样会大大降低推荐的准确度.此外,现有的组推荐技术在研究为群组成员提供更为准确的推荐时,忽略了对推荐结果的解释,降低了推荐的透明度以及用户对推荐的满意度[1].为了解决上述问题,本文提出一种弥补群组成员差异的可解释性组推荐方法,将群组划分为相似性群组和差异性群组,对于不同的群组采取不同的推荐方法,并开展数据实验对提出算法的可行性进行验证.
2 相关工作
当前,关于群组推荐的研究主要集中在相似群组的推荐,基于偏好融合的群组推荐,基于群组成员决策的群体推荐等[2,3].
相似群组的推荐是最早的组推荐研究之一.例如王海艳等为了找到具有较高用户相似性的群组,在进行用户关系融合时,将用户的关注信息、兴趣信息、标签信息等多个维度的显式信息都考虑在内[4].上述方法能够有效提高群组推荐的精确度,但对群组中单个成员的偏好考虑较少,降低群组成员对推荐结果的满意度.
在研究融合群组偏好方向,Zhang Yiru等认为不能将群组偏好融合看成是简单的投票问题,从投票视角出发的建模无法构成在大量信息存在下偏好的最优表示,应当考虑偏好关系中的不确定性,并以信念函数理论为基础构建了偏好融合模型[5].胡川等提出一种改进的偏好融合方法,同时通过实验得出了“群组偏好与个人偏好具有相似性”的结论,并将该结论应用在融合模型中,提高了推荐的准确率[6].但是上述的偏好融合方法有一个共同的缺点:在群组差异度较大的情况下群组的偏好融合越困难,并且模型融合的数据越稀疏,群组成员对融合贡献就越少,降低了推荐的精度.
同时,在研究群组决策方向,Delic A等分析了由200人组成的55个群组的决策过程,得出“群组达成决策不仅取决于决策任务的类型,还取决于组成该群组的群组和个人特征”的结论,并以旅行团目的地推荐为例对该结论进行了验证[7];Tran使用注意力机制来捕获组中每个用户的影响,具体来说即使模型通过学习组中每个用户的影响权重,并根据其成员的权重偏好向组推荐项目[8];Nicola Capuano等从模糊数学的角度来评估群组成员的影响力,并在计算群组成员影响力时将用户个性和人际信任考虑在内[9].这些在群组决策方向提出的方法或模型可以动态调整组推荐,但是在群组差异很大的情况会导致共识偏差很大,结果依然会降低推荐满意度.
可见,组推荐方面的研究虽然众多,但组推荐效果却差强人意.而当前用可解释性的推荐方法来解决推荐的满意度是一个热点,张永峰对推荐模型的可解释性做出了研究,他利用词组情感分析技术从大规模的用户评论中提取产品属性词和表达不同情感的属性,引入显式变量,在此基础上提出了一种基于词组情感分析的显式变量分解模型,提高了推荐的满意度[1].这类算法在个人推荐领域得到广泛的应用,但在群组推荐领域应用还较少,Fernando等提出一种群组的协同过滤推荐的计算方法,也指出推荐的可解释性是组推荐新的挑战[10].
综上,本论文拟研究弥补群组成员差异、实现满意度高的组推荐方法.为此,首先提出一种自适应划分群组的方法,通过群组成员差异度计算,把群组分为差异性群组和相似性群组,分而治之.
1)对于相似性群组,本文采用融合偏好,依据决策权重生成推荐列表.其大体过程是通过群组成员间信任值计算出成员在群组中的决策权重,然后结合群组成员预测评分得到成员个人推荐列表和不推荐列表,并对成员列表项目的得分进行决策权重加权,最后对全部群组成员的推荐和不推荐列表进行混合,生成群组的TopN项推荐列表.
2)对于差异性群组,其成员的偏好具有多样性,为了弥补群组成员的差异,本文提出一种考虑成员信任值的群组LDA模型(Group LDA Model Considering Member Trust Value).该模型先根据观点检测,对群组成员偏好和观点概率分布建模,构建出<概念;主题;情感>三元组,然后利用该模型对候选项目进行评分预测,选取最高概率的评分作为对该项目的评分,其次结合概念、主题和情感标签生成可解释性推荐词组,最后根据预测评分结合可解释性词组生成群体推荐列表,以期提高推荐的精度和满意度.
3 问题定义
本文根据群组成员之间的差异性情况采用不同的推荐策略,对本文问题给出形式化的定义如下.首先,系统中用户由U={u1,u2,…,uU}表示,项目由E={e1,e2,…,eE}表示,R={Ri,j}U×E指用户ui对项目ej的评分值组成的矩阵.另外,有关群组信息,系统中的群组由G={g1,g2,…,gG}来表示,其中,如果Gl,i=1表示用户ui加入了群gl,否则Gl,i=0.系统中用户的评论由由D={d1,d2,…,dD}表示.任意评分Ri,j都与用户ui对项目ej的评论du,i相关联.给定对项目ei的评论Di,每一条评论d∈Di都由一组词语表示,即d={w1,w2,…,w|d|}.
对于任意一条评论,按照如下标准定义其中包含主题、特征和情感.定义一个主题z作为分词的概率分布,一条评论存在K个主题,z⊆{1,2,…,K}.定义一个概念为围绕着主题特征的严格指示词,由c表示,一条评论包含一个概念.情感定义为概率分布在正面和负面的情感标签.每一个分词wj都附有情感标签lj,当分词wj表示负面情绪时lj=-1、当分词wj表示正面情绪时lj=1.本文将一条评论所包含的观点v定义为有限混合三元组由概念、主题和情感组成<概念;主题;情感>,v=〈c,z,l〉.同时由于评论都是较短文本,本文假定在每个用户评论d中仅存在一个观点vd.
项目e∈E可以表示为视点上的混合,项目e中的观点的概率分布由πe表示,主题在观点上的概率分布由μ表示,概念在观点上的概率分布由λ表示.对于用户评论中的分词,本文由φ表示概念,主题和情感标签上的概率分布,该分布由超参数β上的Dirichlet分布导出[11,12].
为了更好的描述本文所提出的弥补群组成员差异的可解释性组推荐方法,给出下面一些定义.
定义1.评分矩阵X∈RM×N通过正交非负矩阵分解得到3个非负矩阵,表示如式(1)所示.其中,U∈RM×K表示用户的潜在特征、E∈RL×N表示项目的潜在特征、S∈RK×L为评分矩阵X的特征矩阵.
X≈USET
(1)
定义2.若群组中两用户ui和uj同时加入的群组gii,j,可以表示为式(2),gii,j的集合则由GIi,j表示.
gii,j={Gl,i=1∧Gl,j=1}
(2)
定义3.如果任意两个用户ui和uj的共同加入群集GIi,j≠∅,表明用户ui和用户uj之间具有社交关联性[13],那么就认为在群组决策时,用户ui会对用户uj的做出的决定有一定信任值,并且这种信任关系是相互的.群组gl中任意两用户ui和uj的信任值Ti,j可以表示为式(3):
Ti,j=Trust(ui,uj),GIi,j≠φ
(3)
4 弥补群组成员差异的可解释性组推荐方法
4.1 弥补群组成员差异的可解释性组推荐框架
本研究充分考虑了群组成员间可能存在较大的偏好差异,在组推荐过程中引入群组成员差异度计算,并以此为基础将群组分为差异性群组和相似性群组,对两种性质的群组采用不同的推荐方法.本文所提出的方法框架如图1所示.本文所提的弥补群组成员差异的可解释性组推荐方法主要包括以下步骤:
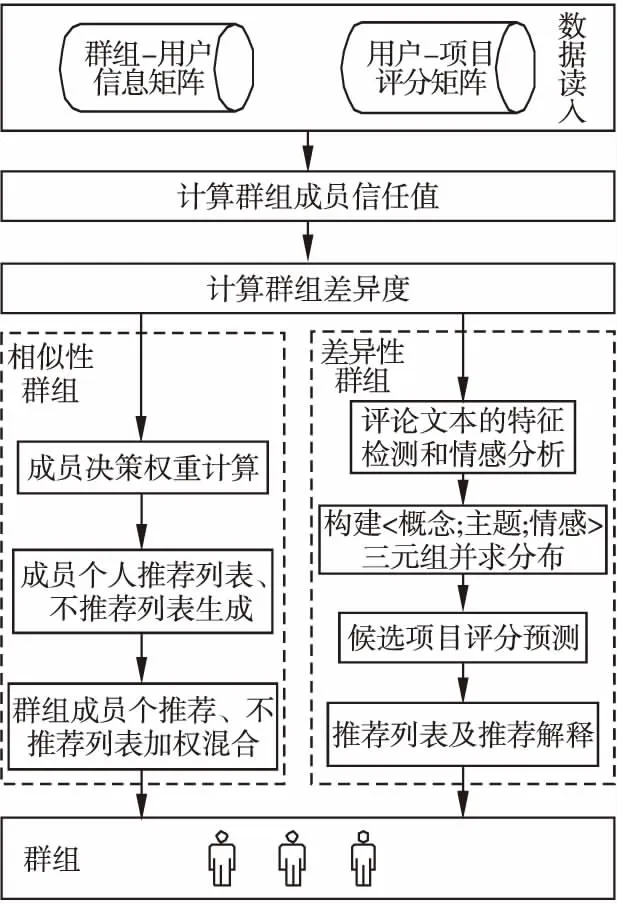
图1 推荐框架
1)衡量用户间信任值.计算任意两用户之间的信任值,将同时考虑用户分别加入群组的数量、用户同时加入群组的数量、用户同时加入群组的规模等信息.
2)计算群组中用户之间的差异度.任意两个用户之间的差异性从他们之间的信任值、用户过往体验过的物品和用户对该物品的打分中得出.
3)相似性群组的推荐.相似性群组的推荐过程包括成员决策权重计算、个人推荐和不推荐列表的生成和决策权重混合的群组TopN推荐列表生成.
4)相似性群组的推荐.相似性群组的推荐包括对用户评论的特征检测和情感分析、构建<概念;主题;情感>三元组及其分布的求取、候选项目评分预测,最后生成TopN推荐和对推荐结果的解释.
4.2 建立基于群信息的用户信任关系矩阵
不同层次的社会信任关系对用户决策的影响不同[14].本文通过用户的群组信息来计算任意两用户的信任值,群组信息包括每个用户分别加入的群组数量、两用户同时加入群组的数量以及两用户同时加入群组的规模信息都被考虑在内.某个群组规模很小,说明这个群组的所有成员可能具有较高的亲密度,则可以认为加入该群组的用户ui会对同样加入该群组的用户uj拥有较大的信任值.相反,如果用户ui和用户uj如果都在某个规模较大的群组,则认为群组成员之间的关系比较松散、互相之间的信任值也较低.本文计算用户ui和用户uj之间的信任值为式(4):
(4)
其中,|gl|表示群gl内拥有的成员数目.
4.3 群组成员差异度的计算
本文依据对群组成员间差异度的计算将群组分成差异性群组和相似性群组,针对两类的群组采用不同的推荐策略.
在一个群组中如果用户ui和uj对项目ek的打分都属于系统高分或者低分,认为他们具有相似性,如果用户ui对项目ek打高分、而用户uj打低分,则认为他们具有差异性.用户ui和用户uj的差异性可以用余弦相似度来计算,见式(5):
(5)
其中,Eui∪Euj表示用户ui和用户uj打分项目的交集,same(Eui∩Euj)表示用户ui和用户uj打同样高分或低分的集合,contrary(Eui∩Euj)表示用户ui和用户uj打相反分数的集合.
将成员之间的信任值考虑进来,本文采用带信任度权值的余弦相似度.带信任度权值的余弦相似度计算公式如式(6)所示:
(6)
计算整个群组用户的差异度,如式(7)所示,如果simgl大于0,则认为群组gl为相似性群组,反之则为差异性群组.
(7)
5 基于决策权重的相似性群组推荐方法
对于相似性群组,本文采用基于评分预测的方法的生成的个人推荐列表和不推荐列表,然后通过决策权重加权来生成群组的TopN推荐结果.
计算用户ui在群组gl中的决策权重由用户在群组中的平均信任值给出,如式(8)所示.当用户ui群组中的平均信任值越高,群组中其它用户在做决策时会更加考虑用户ui的决定.
(8)
在计算群体中各个成员的决策权重之后,利用预设个人推荐系统进行评分预测.本文将系统中评分多的成员分成一组,并将组内成员的评分作为源评分矩阵;将群组gl中所有成员分为另一组,并将该群组中成员的评分作为目标矩阵,利用源矩阵对目标矩阵评分,预测得到群组中每个成员的项目评分列表.具体步骤如下:
第1步.抽取目标矩阵用户偏好S.
(9)
(10)


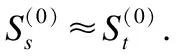
(11)
(12)
(13)
(14)
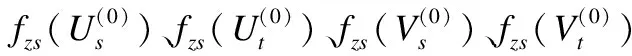
第3步.评分预测
(15)
O为目标最优函数, ‖·‖F表示Frobenious矩阵范式.
评分预测矩阵R同样可以可以表示为R=U1S1E1.其中,U1、S1、E1由式(15)通过梯度下降法的优化算法、使用非负性的KKT互补条件求解得到[16].
在得到群组中每个成员的项目评分列表后,将预测评分属于系统高分的项目作为该成员的推荐列表、预测评分属于系统低分的项目作为该成员的不推荐列表.每个成员的推荐列表进行决策权重的加权后,对群组内所有成员的推荐和不推荐列表混合、出现在多个成员的项目的得分进行叠加形成群组推荐列表和不推荐列表,最后剔除同时在群组推荐列表和群组不推荐列表的项目、将群组推荐列表中剩余的项目按评分排序后作为TopN推荐结果.
6 用于差异性群组的可解释性推荐方法
对于差异性群组,用户偏好存在较大的差异,个人推荐列表中包含的项目重合度较低,最终生成的群组TopN推荐列表评分普遍不高、群组成员对推荐结果的满意度也不高.因此,本文提出一种考虑成员信任值的群组LDA模型,该模型通过对评论短文本的特征检测和情感分析提取构建<概念;主题;情感>三元组,然后应用Gibbs EM采样近似得到模型中随机变量的后验分布[17],最后依据分布对候选项目进行评分,将评分高的项目作为推荐结果、并结合三元组生成推荐解释.
第1步.特征检测及情感分析
本文对推荐平台中使用描述性关键字作为活动的概念,Ci特征存在于活动e的评论中.为了从群成员评论d∈Di中提取出其对应的概念,本文使用word2Vec来计算给定概念c∈Ci和群成员评论d之间的相似度.由于分词的质量随着训练数据量的增加而显着增加,本文对word2Vec的训练使用维基百科的数据进行训练.然后使用训练好的word2Vec模型来预测群成员评论中给定的概念e和评论中每个字符的相似度.相似度计算公式见式(16):
(16)
其中Nd表示评论中的字符数.给定候选概念εi,与d最相似的概念将被视为相关概念.通过根据候选概念和群成员评论之间的相似性对文档进行排序,找到每个群成员评论的相关概念,并在评论文本中选取一个合适的观点为主观点vd,表示为<概念;主题;情感>三元组.
第2步.Gibbs EM采样
由于随机变量之间存在着未知关系,本文使用Gibbs EM采样去条件近似得到随机变量的后验分布.采样的目标是近似得到后验分布p(V,Z,L|W,ε,R,F).采样程序分为3个步骤:
1)给定群成员u和活动e,采样观点f(u,e)的条件概率,给定当前的观点状态,即P(f(u,e)=y|f(u,e),W,V,R);
2)给定推断主题和情感标签的值,在每个d∈D中对观点v的条件概率进行采样,即P(vd=v|V-d,ε,W,Z,R);
3)给定当前的观点状态,对于字符wj,用情感来对主题zj的条件概率进行抽样,情感标签lj转换标签xj,即p(zj=k,lj=l,xj=x|v,X-j,L-j,Z-j,W,R,F).
具体描述如下:给定用户u和活动e,首先在不带(u,e)对f-(m,e)的采样得到fu,e.因此对于用户u对活动e的观点,得到p(f(u,e)=y|f(u,e),W,V,R)如式(17)所示:
p(f(u,e)=y|f(u,e),W,V,R)∝
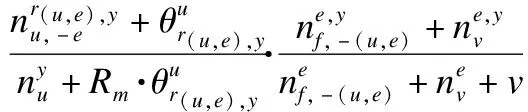
(17)
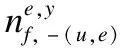
(18)
其中Tu,u′表示用户u和u′之间的信任值;Fu表示群组中的信任关系.
对于用户u为活动e撰写的评论d,推断所有其他随机变量都得出观点vd=v的条件概率,即式(19):
p(vd=v|V-d,ε,W,Z,R)∝
(19)
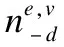
p(zj=k,lj=l,xj=x|v,X-j,L-j,Z-j,W,R,F)∝
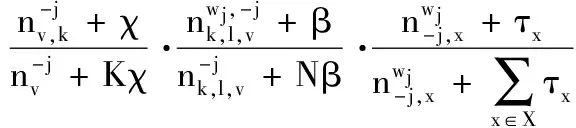
(20)
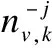
给定上述的条件概率,针对每个评分r估计群组中用户的观点分布θr,v,每个项目e的观点分布πi,主题的概率、观点和分词所表示的情感φ,观点在概念上的分布λ和主题在观点上的分布μ,针对每个评分r估计群组中用户的观点分布θr,v计算如式(21)所示:
(21)
第3步.推荐结果及解释生成
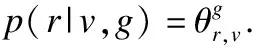
(22)
对每个候选评分r排序p(rg,e=r|g,e),可以选择具有最高概率的评分作为预测频分,同时选取有高概率得高分的候选项目作为推荐结果TopN,并结合观点三元组<概念;主题;情感>进行解释.
7 实 验
7.1 实验数据集
本文在实验中使用了Amazon Fine Food Reviews数据集.该数据集最早于2013年由Kaggle发布,并在2017年5月1日对该数据集发布了更新版本,本文使用的是这一更新版本(见表1).该数据集包含256059个用户、74258件商品和568454条评论.评论信息不仅包括文本,还包括用户对商品的数字评分,数字评分从1~5.但是该数据集并不包含群组信息,本文借鉴文献[18]中的方式对数据集重构、进行群组划分:如果用户ui和用户uj购买了相同的商品,则将用户ui和用户uj划分到以该商品建立的一个群组.通过群组划分,重构的数据集中的256059个用户共形成了10619个群组,规模最大的群组有913个成员,规模最小的群组有10个成员.本文从重构的数据集中随机选择80%的数据作为训练集,20%的数据作为测试集.

表1 数据集群组信息
7.2 评价指标
对于推荐效果的评估,本文使用平均绝对误差MAE(Mean Absolute Error)、准确率Precision@N和召回率Recall@N作为的评价指标.
MAE计算如公式(23)所示:
(23)
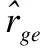
精确率和召回率表示如公式(24)和公式(25)所示:
(24)
(25)
其中,erecommend表示向群组g推荐的商品的集合,ebuy表示在测试集中群组g所有用户购买过的商品的集合.
7.3 参数设置
对于一个给定的群组,首先会计算群组差异度simgl,进行群组类别的判定,然后根据群组所属的类别采用对应的推荐策略.
通过群组划分共得到10619个群组,计算每个群组的差异度,最终这10619个群组中有8316个相似性群组、2303个差异性群组.
对差异性的群组,本文提出了一种考虑成员信任值的群组LDA模型.在LDA主题模型中,主题的数量会对实验有很大的影响.为找到本文所提出模型的最佳参数,在重构的数据集上使用Recall@10下的召回率进行实验,来对主题个数的影响进行评估.实验结果如图2所示.可以看出,主题数量K应设置为20.
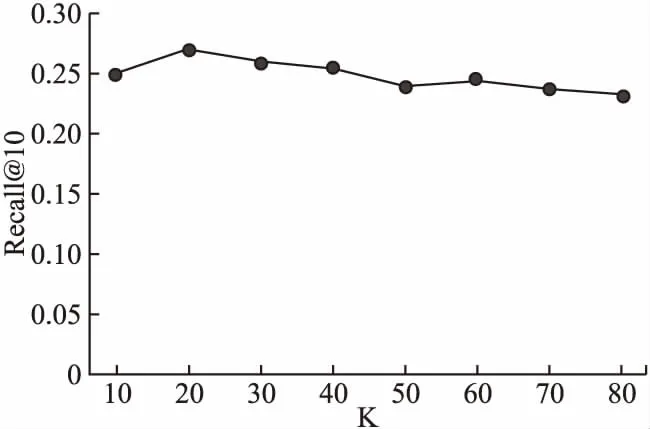
图2 不同主题数量的Recall@10
7.4 整体表现
本文使用3个对比方法,分别是AVE-CF、GD-MVL、和PF.
1)AVG-CF:群组中所有成员对项目评分的平均值作为群组对该项目的评分,然后利用项目相似性来生成推荐[2].
2)GD-MVL:采用群组发现的思想,在计算相似度矩阵时考虑了包括用户的兴趣信息和标签信息在内的多个维度的信息[4].
3)PF:在偏好融合时考虑群组中成员对群组偏好有不同的影响程度,同时还考虑了项目热度,最后利用群组的相似性来生成推荐[19].
为了评估本文所提出方法在不同数据稀疏度下的表现,选取最优参数,使用MAE作为评价指标,在Amazon Fine Food Reviews重构数据集开展了实验,实验结果如表2所示.从实验结果可以看出,使用群组成员对项目的平均分作为预测得分的AVG-CF方法总体表现最差,GD-MVL和PF在不同稀疏度下表现接近.本文所提出的方法在数据稀疏时,对于群组的不同情况能自适应采用评分数据跨域填充或者采用基于群组评论情感分析的评分预测策略,所以能更好的的应对数据稀疏性问题.
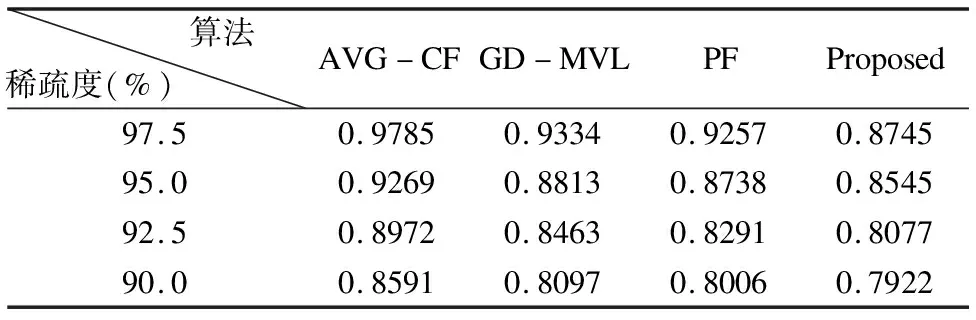
表2 不同稀疏度下各算法的MAE
为了更好地验证本文提出算法的推荐效果,选取最优参数,继续在 Amazon Fine Food Reviews重构数据集进行推荐准确率和召回率的实验,设置向群组推荐商品的数量N分别设置为5、10、15和20.实验结果如图3、图4所示.
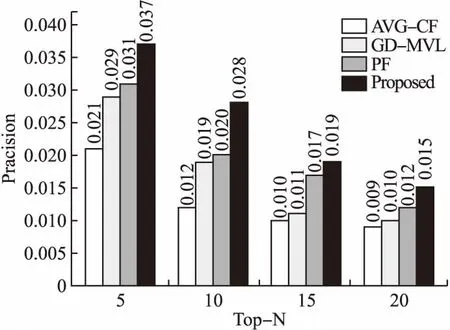
图3 Top-N精准率

图4 Top-N召回率
从图3、图4中可以看出:基于协同过滤的AVG-CF算法表现较差,因为数据集中绝大多数用户只有10条以下的购买、评论记录,造成数据非常稀疏.本文所提出的算法在数据集上效果最好,其次是PF,因为PF同样考虑了群组中的成员对于决策有不同的影响权重.由于没有考虑成员偏好存在较大差异性的情况,所以在N值较小时,PF的准确率还要差一些.GD-MVL将最具有相似性的用户划分到一个群组,因此对于相似性较高的群组推荐效果是很好的,但是成员相似度不高的群组,推荐效果不太理想,所以整体的正确率表现一般.
7.5 可解释性
表3为本文提出的算法在Amazon Fine Food Reviews数据集上生成的示例视点.第1列出了与视点相对应的概念;第2列列出观点中的主题,第3列和第4列列出每个主题的正面和负面标签的概率,第5列列出每个观点的预测评分及其概率.
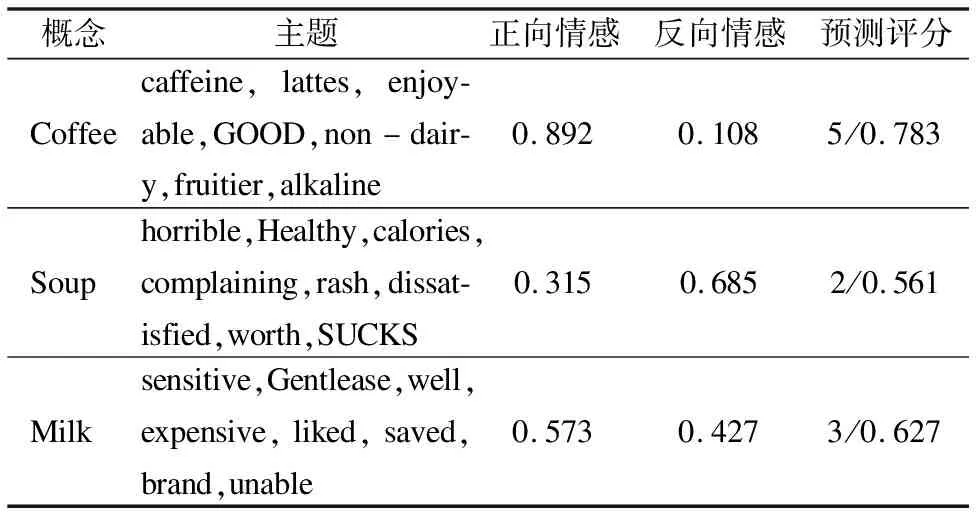
表3 生成观点示例
在表3的示例观点中,看到带有相关主题和相应情感标签的概念.对于每个观点,第2列中的相关主题有助于解释第一列中的概念,并且情感标签会告知用户观点中的观点.另外,也可以看到对于每个观点,预测的评分与情感极性一致.
8 总结与展望
本文考虑到在组推荐任务中群组成员偏好可能相差较大,将群组划分为相似性群组和差异性群组.在对群组进行划分时,本文把群组成员的偏好和成员间的社会信任关系同时考虑进来.对相似性群组本文采用基于决策权重的群组推荐方法;对差异性群组提出了一种考虑成员信任值的群组LDA模型.该模型有两个关键部分:观点检测和评分预测.从用户评论中构建观点三元组<概念;主题;情感>,同时提取观点的概率分布,然后利用该模型对候选项目进行评分预测,选取概率较高的评分作为预测评分,最后依据评分得到推荐列表,同时结合观点给出推荐结果的解释.
在实验部分,本文所提出的方法已经被证明是有效的.在使用3个基准数据集进行测试时,发现相对于其它方法有较大的提升.本文还表明,群组划分和社会信任关系的使用可以提高推荐的准确性.与以前使用的简单的基于主题解释相比,使用<概念;主题;情感>三元组可以为群组成员提供的更多信息解释,从而提升满意度.
本文工作的局限性在于使用社会信任关系的维度较低,当前社交网络中还广泛存在众多其它社会化信息,这些信息对组推荐也有一定的影响,因此多维度社会化信息的筛选以及在组推荐中有效的融合策略需进一步研究.同时在差异性群组的推荐中,本文提出的模型是基于主题模型构建,因此主题之间的条件独立性原则上可能导致多余的观点和主题,如何降低这一冗余也将是下一步工作的重点.
