基于辅助分类生成对抗网络的纸币红外特征鉴伪算法
2021-05-07陈小静曹语含张学东
陈小静,曹语含,张学东
(辽宁科技大学 计算机与软件工程学院,辽宁 鞍山 114051)
研究纸币识别的软件仍采用“以假鉴假”设计思想,没有实现“以真鉴假”[1]。纸币鉴伪方法主要有模板匹配、支持向量机和神经网络鉴别方法。模板匹配法费时费力,计算成本大,而且阈值的设置存在局限性[2-3];支持向量机方法对大样本的处理以及多分类问题上存在不足[4];神经网络鉴别可以充分学习到图像特征,能较好实现图像分类识别,但要求有足够的样本[5-7],而且对数据集以外的假币识别存在泛化不足的缺点。
Goodfellow于2014年提出生成对抗网络(Generative adversarial network,GAN)模型[8]。近年来对GAN进行改进,不断优化图片的生成质量。监督式生成对抗网络(Conditional generative adversarial nets,CGAN)模型[9]可以根据网络的输入标签生成对应的输出,比传统生成模型效果好且具有多样性。半监督学习使用未标记以及有标记数据一起训练模型,能在少量数据情况下得到比较高的准确率。GAN模型亦可通过半监督式学习优化提供生成数据,被称为半监督式生成对抗网络(Semi-supervised generative adversarial network,SGAN)模型[10-11],能够做到同时训练生成器与半监督式分类器,最终实现更优的半监督式分类器,成像质量更高。王德兴等[12]将深度学习引入GAN,并对其生成图片用分类器进行分类识别,图像的分类准确率好于其他无监督学习算法,证明生成图片的有效性。
GAN中判别器、分类器以及生成器的性能相互影响,存在平衡点。CGAN利用辅助的标签信息增强原始GAN,生成具有特定特征图片,且标签信息越丰富,生成效果越好。SGAN利用判别器或分类器重建标签信息,不仅可以分类还能得到更高质量的图片。结合CGAN和SGAN这二者的优点,得到辅助分类生成对抗网络(Auxiliary classifier generative adversarial network,ACGAN)[13-14]模型,该模型有效提高生成结果的质量,并且使得训练更加稳定。
本文提出一种半监督辅助分类深度生成对抗网络模型用于纸币红外特征鉴伪,利用生成器获取一定量的数据集,并将判别器改为一个分类器,该分类器以半监督方式训练,希望能在一定范围提高未知纸币红外特征鉴伪的准确率以及泛化能力。
1 鉴伪模型
1.1 生成对抗网络模型
生成对抗网络是利用生成器G和判别器D博弈,将随机噪声Z生成预想的信息G(x)的一种生成模型。生成模型是从一个输入空间将数据映射到生成空间,即x=G(z)。通常输入z会满足一个简单形式的随机分布,生成函数G(x)通常是神经网络的形式。生成模型定义一个概率分布函数Pmodel(x;θ),模型分布是通过参数变量θ定义。从真实数据集中采样大量的数据定义概率分布函数Pdata(x)。在实际的计算过程中通过改变参数θ,使生成模型概率分布Pmodel(x;θ)可以近似于真实数据概率分布Pdata(x)。根据训练集可以给出生成模型概率分布函数
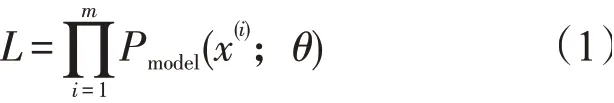
式中:L是噪声经过生成模型后在训练集上的概率。L越大说明生成模型越好。即寻找一个θ*使得L最大化
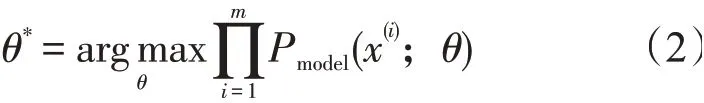
对每个Pmodel(x;θ)取对数
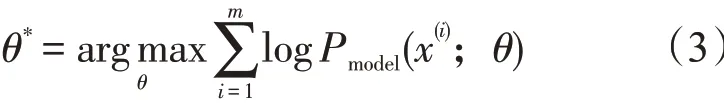
将式(3)转化为求概率分布函数的期望值
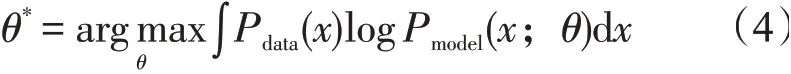
在不影响求解的情况下减去一个与θ无关的常数项
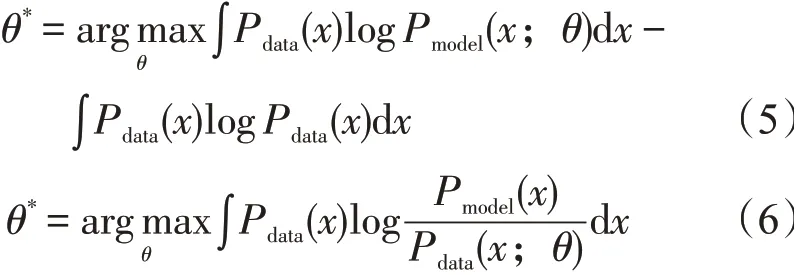
设两个概率分布为J和G,对应的概率密度函数为J(x)和G(x),计算概率分布之间相似程度的KL散度定义式
得到
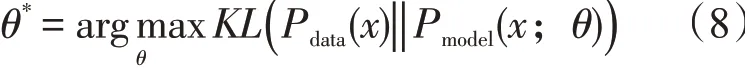
当Pmodel(x;θ)趋近于Pdata(x),生成模型就成功了。
生成对抗网络模型就是实现Pmodel(x;θ)逼近Pdata(x)的过程,它可以把简单分布映射成复杂分布。但经过一个神经网络难以计算最终的生成空间分布Pmodel(x;θ),所以用代价函数表示模型生成过程,故以判别器为例,固定生成器,代价函数写作J(D),J(D)越大说明鉴别真伪效果好,生成的图片越接近样本数据集
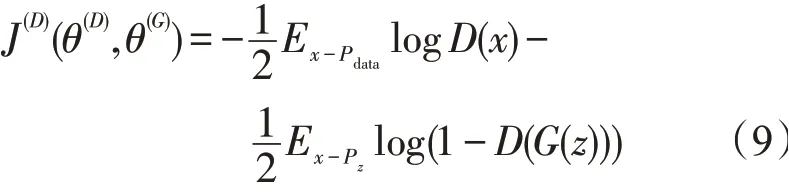
生成器写作J(G),生成器和判别器可看作零和博弈的关系,综合代价为零,故可设置价值函数V来表示J(D)和J(G)
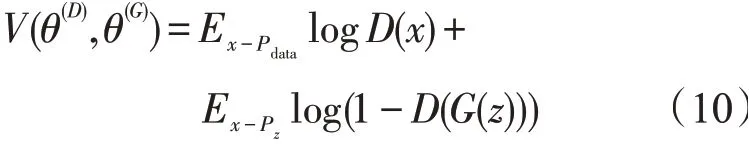
现在把问题变成了需要寻找一个合适的V(θ(D),θ(G)),使得J(G)和J(D)都尽可能小,也就是说通过判别器和生成器二者博弈,可以求出理想的判别器D*()和生成器G*(),生成数据判为真的概率为Pg(x)。
固定生成器寻找D使得V最大,令f(x)=V,求f(x)最大值
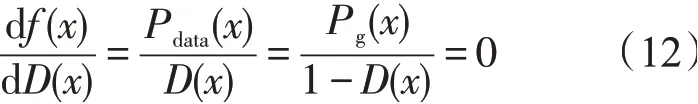
理想判别器
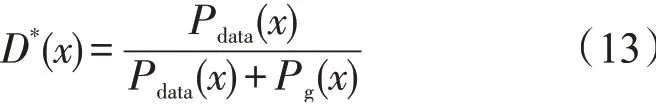
判别器D*(x)值在0-1范围。
将D*(x)带入式(11)
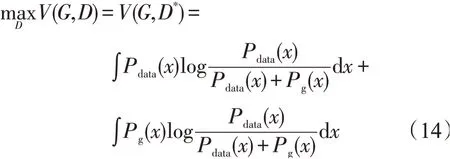
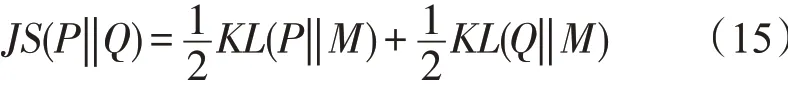
将式(14)转化为JS散度形式
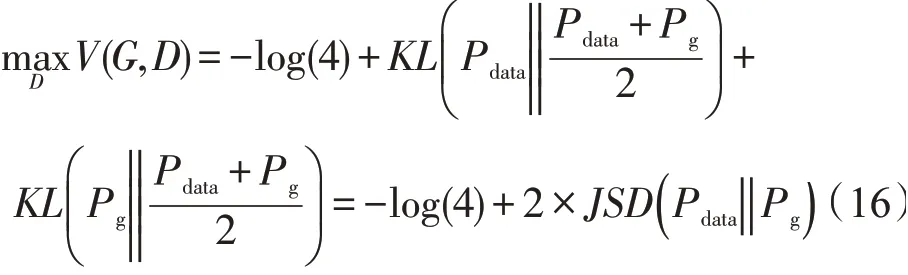
当Pg=Pdata时,达到生成最优解G(*)。此刻生成器和判别器达到纳什平衡,生成的数据判别器已分不清真假。
1.2 辅助分类生成对抗网络
ACGAN是基于GAN提出的,GAN为了生成安全样本,可能会生成相同类型的图片欺骗判别器,利用标签信息能够防止这种现象,使得生成样本基本相同。标签的存在可以让判别器关注到生成的类别,防止模式崩溃问题。例如,用MNIST数据集训练网络时,为了安全只生成其中一个数字,就发生了模式崩溃问题。ACGAN结合了SGAN监督的思想以及CGAN的条件信息辅助分类思想,综合判别器学习到的特征可以提升分类器的性能或优化判别器,达到同时训练生成器和分类器的目的,不仅可得到质量较高的图片,训练稳定,还能拥有一个分类器实现对图像的识别。
ACGAN对小样本数据集训练任务有一定优势,通过生成的数据可以补充一定量的样本集,模型本身通过少量样本就能较快地收敛,很好地完成模型训练。已有研究在训练好的MNIST数据集上进行测试,分类正确率能达到98%[15]。
1.3 基于辅助分类生成对抗网络的纸币红外特征鉴伪模型
本文的模型基于ACGAN建立,由生成器和判别器对抗训练得到高质量图片,可做为样本数据,缓解小样本问题,且加入半监督设计也就是训练时既有带标签又有无标签数据,使得模型具有较好泛化能力。
图1是模型生成器网络结构,包括卷积层、卷积核数目以及结构设置。图2是模型判别器网络结构和参数的设置。生成器和判别器参数根据红外纸币数据设计。为了提取多量的特征就需要多层卷积,但要考虑过拟合问题。

图1 生成器网络结构Fig.1 Network structure of generator
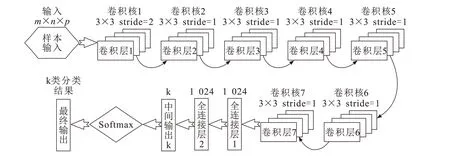
图2 判别器网络结构Fig.2 Network structure of discriminator
红外纸币鉴伪模型结构如图3所示。生成器G和判别器D博弈训练,随机噪声Z和标签C生成带标签的接近数据集分布的数据G(X1),G(X1)和标鉴数据X2经过D判断真假,优化生成网络和判别器网络,生成模型特征抽取后形成的分类器C,输出该数据类别为真币还是假币;带标签的数据集X2经过判别器对数据的分类,并优化分类器;将不带标签的数据集X3送往鉴判别器可以优化分类器,通过训练提高其分类的置信区间,最终实现纸币半监督分类。
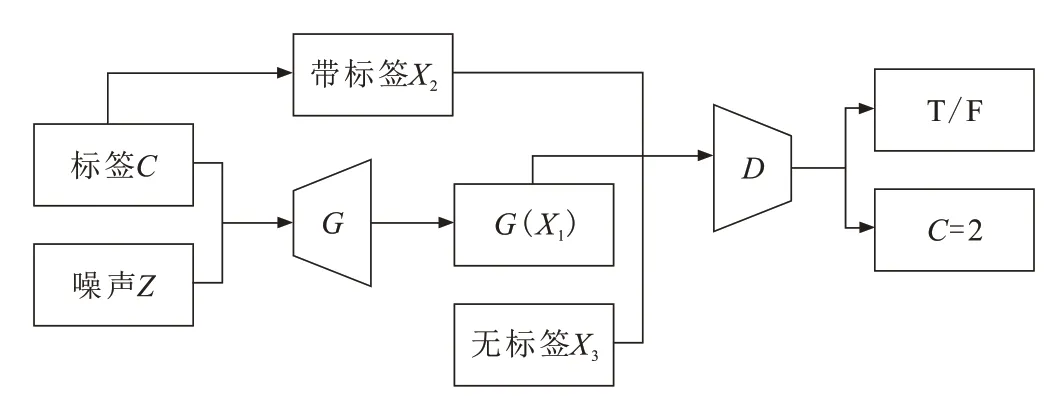
图3 红外特征纸币鉴伪模型Fig.3 Identification model for infrared characteristics of paper currency
2 实验过程与分析
2.1 数据集选择
本文选用的数据集是在聚龙公司采集的红外图像。数据集共有900张,其中真币800张,假币100张。训练集550张,其中500张真币,50张假币。验证集225张,其中真币200张,假币25张。测试集125张,其中真币100张,假币25张。生成数据取100张,具有真币特征数据50张,具假币特征数据50张,做训练集样本。利用基于Python的kreas学习框架,在CPU和win10系统环境下进行实验。
传统的教学多以教师讲授为主,以教师为主体,易于控制教学的进程,逻辑性和系统性相对较强,学生遵循教师的讲解,易于快速形成知识结构和体系.然而,这种教学方法不利于调动学生的积极性和主动性,学生的参与意识不强,因此需要改变授课方式.
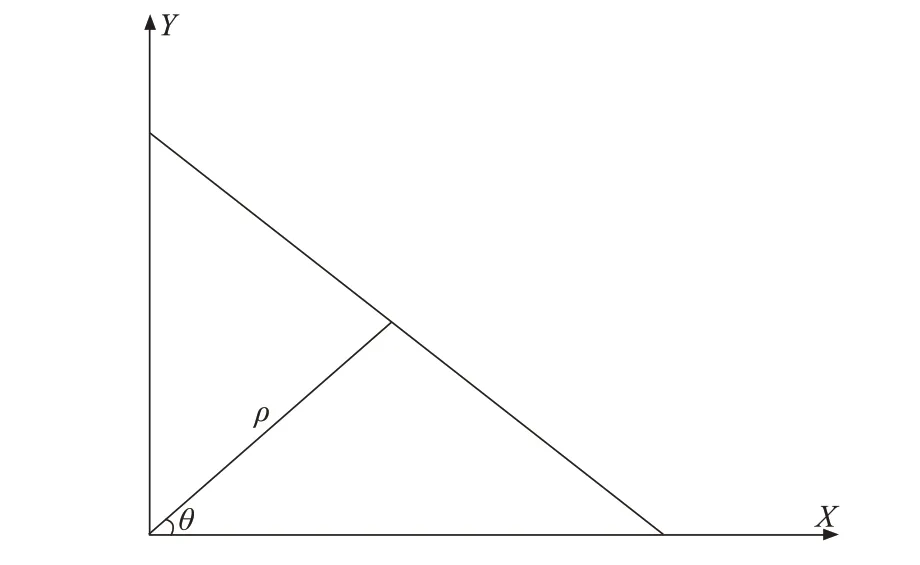
图4 霍夫变换原理图Fig.4 Schematic diagram of Hough transform
2.2 数据集预处理
根据四条边界线的交点可得纸币倾斜角,根据像素点坐标可以推出图像位置关系。(X0,Y0)是纸币旋转前像素点的坐标,(X1,Y1)是旋转之后的坐标,旋转前后的位置关系
纸币数据采集中,由于光照、纸币位置等因素,图像存在倾斜问题,需要进行倾斜校正预处理。采用霍夫变换进行倾斜校正,原理如图4所示。
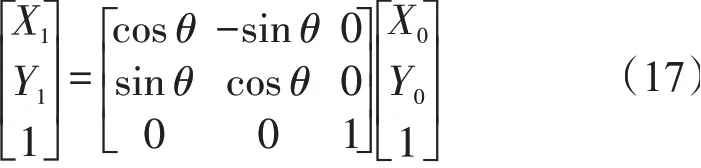
经过霍夫变换倾斜校正后的红外特征纸币,再对其边缘用Canny算子切割,效果如图5所示。对处理后的纸币进行模型的训练测试。
2.3 网络训练
基于改进ACGAN网络来完成纸币红外特征鉴伪。网络结构含有两全连接层,卷积核为3×3,步长调整为1,激活函数选择Leaky ReLU函数。判别器网络卷积结构和生成器相同,全连接层改为3个,判别层可以输出样本的类别概率。
超参数不需要数据来驱动,可以在训练前或者训练中人为进行调整,包括学习率(learning rate)、批样本数量(batch size)、迭代次数等。学习率直接控制着训练中网络梯度更新的量级,学习率衰减或者增大能帮助模型有效地减少震荡或者逃离鞍点。生成器学习率设为0.000 5,判别器学习率设为0.000 1。过小的批样本数量,例如batch size为1,即每个样本都去修正一次梯度方向,样本之间的差异越大越难以收敛。而过大的批样本数量,会使得梯度方向基本稳定,容易陷入局部最优解,降低精度。minibatch是一次更新所用的数据条数,每个minibatch都是随机的样本,增加了生成数据的多样性,本文设minibatch数为16。为避免过度训练造成的过拟合,如果性能在一段时间内不再提升,会采用提前停止的方式终止迭代。
在训练形式上采用半监督方式,综合生成器、判别器以及分类器三者相互作用相互优化的特 点,将判别器改为分类器,同时保留判别器对纸币 的真假数据的鉴别功能。由生成对抗网络原理,模型优化就是让生成器和鉴别区损失都最小。整个模型损失包括生成数据的真假以及分类损失
带标签样本数据的分类损失Lc,C表示类别
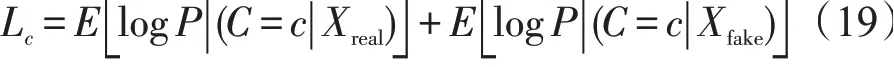
无标签数据分类损失用香农熵Lu表示,X为无标签数据,n是分类数目
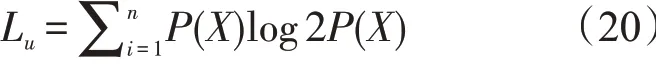
通过Lu衡量分类器对于无标签数据分类的不确定度。因此本模型收敛就是优化判断真假数据损失Lu及分类损失Lc两者和最小。
2.4 实验结果
图6是训练过程中模型的损失变化图。模型损失总体趋势先上升后下降,之后趋于稳定。显示了网络模型生成器和判别器对抗学习中,鉴伪模型由训练到平衡的过程。
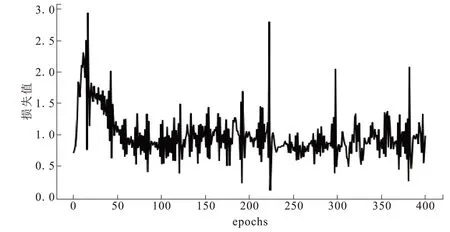
图6 模型损失变换图Fig.6 Diagram of model losstransformation
图7为模型生成器产生的样例图。通过调节参数,降低模型损失,生成和样本数据逐渐接近的图像,图7a是模型迭代早期输出的样例图,图7b是模型迭代完成产生的样例图。生成的图像具有样本的特征,可以做样本数据,解决小样本数据训练困难的问题。
本文数据正负样本差异较大,正确率就会变得比较片面,故选择精确率、召回率、F值(F-Measure)做评价指标。F值定义为精确率和召回率的调和平均值。精确度为预测假币的样本中标签为假币的比例,即真币误判为假币。召回率为真实标签是假币的样本被预测为假币的比例,表示假币被正确分类的程度。分类器能把所有假币都分类正确,也就是容易把真币错误归到假币范围中,也就是说召回率变高,精确度就会变低,故用F值对结果综合评价。

图7 生成器产生的样例图Fig.7 Samplesgenerated by generator
测试结果如表1所示。CNN模型召回率低,F值低,假币误判的可能性变大,说明样本不平衡使得该模型出现模型偏移问题。ACGAN模型虽然对不平衡数据处理能力较CNN好,但对纸币分类精确度需要进一步加强。本文基于生成对抗网络的红外纸币模型具有较好的准确度和泛化性,针对小样本不平衡的红外特征纸币数据分类,有较好的处理能力。
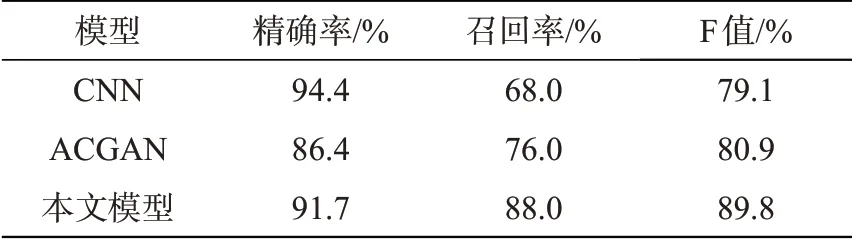
表1 模型测试结果Tab.1 Model test results
3 结论
本文采用半监督辅助分类生成对抗网络鉴伪算法用于纸币红外特征鉴伪。在ACGAN基础上优化生成对抗网络结构,对网络进行超参数调节,经过生成网络和对抗网络博弈得到分类器。生成器将随机噪声生成特定类别的数据,扩充样本数据集,解决样本不均衡问题。半监督方式进一步提高了分类的准确度和泛化性,提高了对未知假币的识别率。
