基于互信息特征提取的食品安全信息新词识别
2021-05-07马强路阳李菲
马强,路阳,李菲
(黑龙江八一农垦大学电气与信息学院,大庆 163319)
新词又称未登录词,是指未包含在分词词典中的词语。食品安全信息来源广泛多样,包含大量新词,这些信息是了解、监管、以及应对食品安全突发事件的重要依据[1],信息的理解对于分析、挖掘和应用至关重要,如事件检测[2]、舆情分析[3]等。新词严重影响分词准确率,因此对食品安全文本中的新词进行识别是食品安全信息处理的迫切需求。
当前,分词技术在通用文本处理中已经取得良好的效果[4],基于词典的方法通过结合规则消除歧义切分[5-6],此方法缺点是需要领域词典,识别未登录词是该方法面临的主要问题。基于统计机器学习的方法将分词视为序列标注问题[7],方法有隐马模型、最大熵和条件随机场[8],该类方法能平等地看待词典词和未登录词[9],缺点是受训练语料限制[10]。基于深度学习的方法多采用字标注的方式,如LSTM[11],分词效果进一步提升[12],缺点是需要大量的标注语料。在食品安全文本处理中,领域特殊性使得分词无法达到预期的效果,如消费者的评价和投诉信息用词不受约束,依个人喜好而定;媒体、消费者组织的报道中,包含食品名称谐音词、食品检测参数的外文转义词、缩略词等。针对食品安全领域文本处理需求,快速建立高准确率的领域分词器是主要内容。
通过相关研究工作的比较,提高分词准确率最有效的策略是在现有分词器中,集成领域词典。与构建语料相比,词典的构建更为容易,其中关键的问题是识别新词。新词识别通常采用将统计与规则相结合的方法[13]。互信息(Pointwise Mutual Information,PMI)是衡量词串是否成词常用的统计量,它反映了字与字之间的结合紧密程度[14],该方法缺点是可能过高估计总是相邻出现但词频较低的字串间的结合强度[15]。文献[16]改进互信息方法识别web 中的新词。文献[17]向PMI 方法中引入邻接熵,解决垃圾词串的过滤问题。文献[18]采用支持向量机对候选词语进行过滤。文献[19]以信息量加入人工规则进行新词发现。由于食品安全信息文本来源广泛、内容多样以及PMI 方法需要确定阈值等缺陷,用于新词识别的效果并不理想。在PMI 方法的基础上,引入BP 神经网络模型,挖掘词汇可以利用的潜在特征,过滤垃圾词串以提高准确率。将提取的新词以用户自定义词典的形式加入现有的分词系统中,提升食品安全信息文本分词效果。
1 方法
1.1 总体技术框架
快速构建食品安全领域信息分词系统的有效策略是改进现有分词系统,向现有的分词系统添加自定义词典。自定义词典中词语的质量与规模,对分词系统的准确率有很大影响。提升食品安全文本分词系统性能的关键在于全面和准确提取食品安全信息文本中的特有词语,主要探讨食品安全信息中新词的识别,并将识别的新词加入到分词系统中,以提升文本分词效果。总体技术框架如图1 所示。

图1 总体框架Fig.1 framework
食品安全语料采集是针对食品安全信息数据源开发爬虫器,从数据源中爬取文本,形成原始粗语料。新词识别过程是应用互信息新词提取方法,从这些文本中提取候选新词及统计量。利用所提取的候选新词、统计量特征及人工标注的部分数据,得到新词识别训练数据,使用BP 神经网络建模,利用BP 神经网络新词识别模型过滤候选词中的垃圾串,得到食品安全新词。将新词加入到用户词典中,得到新的词典系统。应用新的词典集成到支持自定义词典的分词工具中优化分词器。最后输入待切分文本,利用优化后的分词系统实现对输入文本的切分。
1.2 互信息新词特征提取
互信息是信息论中的概念,用来计算两个事件的相关度,两个事件AB 的互信息计算见公式(1)。将文本处理中的两个词串AB 看作是互信中的事件,便可以计算词串间的互信息,用于判断字符间的凝聚性。它体现了汉字之间结合的密切程度,当某些字符结合的紧密程度大于某一给定的阈值时,认为这些字符组成的字串可能构成一个词。
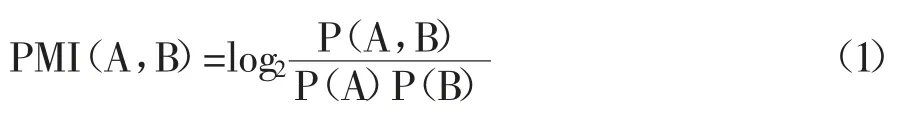
公式中,P(AB)为字串AB 在语料中出现的概率,P(A)为字(或字串)A 在语料中出现的概率,P(B)为字(或字串)B 在语料中出现的概率。例如,当字串AB 长度length(AB)=2,A 代表前一个字,B 代表后一个字;当字串AB 长度length(AB)=3 时,A 代表前1(或前2)个字,B 代表后2(或后1)个字;当字串AB长度length(AB)≥3 时依此类推。
互信息具有这样的性质:如果PMI(A,B)>0,有P(A,B)>P(A)P(B),表示AB 一起出现的概率大于A 和B 单独出现的概率,说明AB 更有可能成为一个词。随着PMI(A,B)值的增大,AB 间相关度更高,成词可能性更大。反之,表明AB 相关度低,结合成词可能性小。
利用互信息方法提取新词的基本流程是:首先对食品安全语料进行预处理,预处理后得到语句片段,每个语句均由汉字字符组成。然后对所有语句片段统计互信息计算所需要的统计量,包括单字A/B的频次、字串AB 的频次、所有单字的总频次、所有字串的总频次。在统计量的基础上计算单字、字串的概率。最后将计算值带入互信息公式中,得到每个字串的互信息值。根据互信息值,对字串进行过滤,将大于0 的字串作为新词保存到字典中。基于互信息的食品安全新词识别的详细描述如算法表1 所述。

表1 基于互信息的新词特征提取Table 1 Feature extraction of new words based on mutual information
在实际处理中发现,单纯依据阈值大小得到的新词集合中含有很多垃圾字串。针对新词提取的精度需要对互信息模型进行改进。
1.3 基于BP 神经网络的新词识别
互信息模型识别新词时,依据字串互信息阈值大小对字串进行过滤,在阈值为0 时,得到的新词集合中存在很多垃圾字串,因此需要提高互信息新词识别的纯度。在互信息计算时得到一些统计量,包括单字频次、概率,字串频次、概率,以及字串互信息等。这些统计量和候选新词是否被最终判定为新词有很大关系,因此可以在互信息模型统计量特征的基础上对得到的候选新词集合做二分类。常用的分类算法有逻辑回归、SVM、决策树、反向传播(Back Propagation,BP)神经网络等。BP 神经网络模型构造简单,在分类问题中有广泛的应用[20],是信息处理、数据分析、数据挖掘的常用方法。BP 网络模型通过梯度下降法获得代价函数的最小值,具有任意复杂的模式分类能力和优良的多维函数映射能力[21],可以完成分类任务。在互信息特征提取的基础上,融入BP 神经网络模型,过滤互信息得到的候选新词中的垃圾串,提高新词发现的准确率。
BP 神经网络属于有监督学习算法,需要构造训练数据。将互信息模型得到的新词作为候选词语,统计得到每个候选词语相关的字频、词频以及PMI 值等信息作为特征,所选特征见表2。
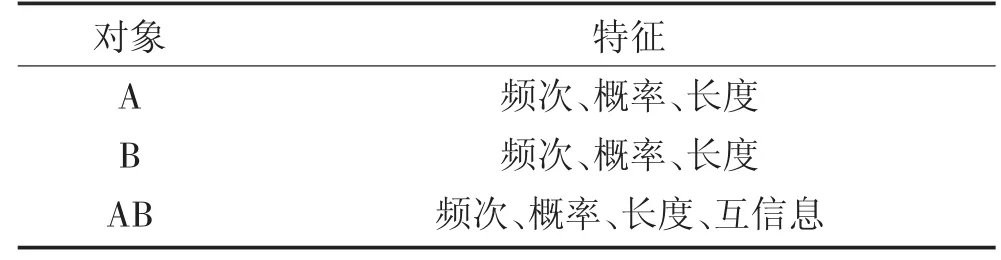
表2 BP 神经网络新词识别特征Table 2 New words recognition features of BP neural network
对部分候选词语是否成词进行标注,连同其统计量特征作为神经网络模型的训练样本。BP 网络模型的训练中训练集越大,训练所得模型泛化能力越强,识别效果越好。但训练集越大,人工标注的成本也越高。因此采用逐步扩大训练集规模的方法,逐步添加人工标注的新词训练样本,以便得到满足条件的最小训练集。当训练模型的新词识别准确率波动基本不变时,认为趋于稳定,用达到平衡点的样本量作为训练集大小来抽取最终的训练样本,训练神经网络模型的参数。融入BP 神经网络模型的新词发现流程如图2 所示。

图2 基于BP 神经网络的新词识别框架Fig.2 New word recognition process based on BP neural network
首先根据算法1 中的互信息特征提取方法提取输入语料中的新词。这些新词集合中包含垃圾词串。然后利用BP 神经网络过滤新词集合中的垃圾串,将每个词语都作为候选新词,记录每个候选新词的统计特征以及是否成词的部分人工标注结果,作为BP神经网络模型的训练集。调整训练集规模,当模型识别准确率趋于稳定时不再增加训练数据。训练得到BP 神经网络模型。最后利用BP 神经网络模型中进行候选词分类,得到新的新词集合。具体算法描述如算法表3 所述。

表3 基于BP 神经网络的新词识别Table 3 New word recognition based on BP neural network

续表3 基于BP 神经网络的新词识别Continued table 3 New word recognition based on BP neural network
2 实验与结果
2.1 数据
研究主要采集食品新闻报道中的资讯评析作为实验数据,同时也收集相应的食品抽检信息、食品违法违规案例信息。这些信息和消费者息息相关,包含了食品的制作、包装、食用注意、营养构成、添加剂、保质变化等重要有价值信息。
(1)实验数据采集自互联网食品监管网站、《中国食品安全报》、《中国食品报》等媒体2017 年至2019 年的相关报道信息1 500 份。
(2)停用词典:选自哈尔滨工业大学停用词表。
(3)分词词典:选自结巴分词词典。
2.2 实验设计
99%以上的词语长度都在5 字及以内,在食品安全文本上发现5 字以上的新词也较为常见,为了尽可能识别更多新词,在实验中设定最大词长为6。
(1)划分实验数据。将1 500 份食品安全信息文本中的1 200 份用于新词识别统计量的提取及BP神经网络模型的训练,剩余300 份用于新词识别效果评价。
(2)使用算法1 互信息新词识别提取候选新词,统计候选新词的词特征。
(3)建立神经网络模型结构。确定训练集规模后,设计神经网络模型,根据输入到网络的特征个数,BP 神经网络输入层节点个数为10,第一隐含层个数为8,第二隐含层个数为5,输出层节点为2。
(4)训练神经网络模型。将步骤(2)中得到的新词集合的词语作为候选词语,将统计量(字频、词频、PMI 值等)特征作为自变量进行建模,训练集的大小从200 条开始,每次以100 条递增,并用随机抽取的200 条标注数据作为校验集,当测试结果准确率趋于平衡时停止训练。
(5)使用神经网络预测。将新词集合(除训练用的词语外)分别输入模型,基于其中的统计特征,进行进一步成词判断,得到新的新词集合。
(6)评价新词识别效果。
2.3 实验结果
以准确率(Accuracy)、精准率(Precision)、召回率(Recall)和F1 值4 个指标衡量新词发现方法的性能。不同规模训练集情况下,新词识别结果如表4、图3 所示。在互信息模型提取字串的基础上,利用BP 神经网络进行过滤,新词预测效果有很大改善,其准确率达80.0%,召回率达80.1%。

表4 不同训练集下BP 神经网络新词识别统计Table 4 New words recognition statistics of BP neural network under different training sets

图3 不同训练集下BP 神经网络新词识别能力Fig.3 New words recognition ability of BP neural network under different training sets
BP 神经网络训练过程中损失变化,如图4 所示。

图4 BP 神经网络训练与预测损失Fig.4 BP neural network training and prediction loss
将BP 网络模型对测试集进行预测,将预测的新词和相应的标记值导入进行ROC 分析,得到BP 网络新词识别模型的ROC 曲线,如图5 所示。ROC 曲线中AUC 值分别为0.816。所使用的特征和方法对新词识别具有明显的识别能力。

图5 BP 网络新词识别模型的ROC 曲线Fig.5 ROC curve of BP network new word recognition model
部分新词提取情况见表5。

表5 提取的部分新词Table 5 Examples of new words
从表5 可以看出,BP 神经网络模型确实能过滤垃圾串并提取一些不太常见且普通词典中不存在的词语,如一些专业词语,丰富了食品安全信息分词词典。
依据表2 所选特征,分别对比逻辑回归(logistics regression,LR)、决策树,新词识别准确率见表6。

表6 不同算法新词识别对比Table 6 Comparison of new word recognition based on different algorithms
在选定的特征下,采用过滤方法对比单独使用互信息提取新词可以提高准确度。在不同的过滤方法下,BP 方法得到的新词准确率最高,同时我们注意到LR 和决策树C4.5 方法在执行时效率更高。算法在不同的特征下结果可能不同,对于不同特征下垃圾字串的过滤还需进一步研究。
3 结语
主要研究食品安全领域新词的识别,以期提高分词系统对该领域文本处理的准确性。由于食品安全领域中没有成熟的标注语料,所以无法使用有监督的方法,如统计机器学习方法和深度神经网络方法直接训练得到分词模型。同时,人工标注食品安全语料耗时费力。采用基于互信息提取的候选词统计特征和BP 神经网络方法进行新词识别和过滤,实验结果表明,采用的方法对候选新词进行了有效过滤,新词识别效果明显,可以取得新词识别准确率(0.806)。我们标记了部分候选词是否是新词,作为实验的样本,测试样本结果与标记的结果较为接近,证明了标记的样本数据具有可靠性。尽管本方法可以提高食品安全文本中新词提取的准确率和召回率,但仍无法准确提取全部新词,因此还存在很大的提升。在与其他垃圾串过滤的方法对比中,以频次、概率、长度、互信息等主要特征的BP 网络方法过滤方法具有最高的准确率,关于特征的选取以及和其他方法的结合使用还需进一步验证。我们将在此基础上,进一步提高新词识别的精确度,利用自学习方法逐渐扩大面向食品安全的文本语料,为有监督方法提供可靠的数据。
