一种基于离散数据从局部到全局的网络重构算法*
2021-05-06徐翔朱承朱先强
徐翔 朱承 朱先强
(国防科技大学, 信息系统工程重点实验室, 长沙 410073)
1 引 言
网络作为复杂系统的抽象已经广泛存在于现实世界, 从生物界的食物网[1]到大脑中的脑网络[2]、现代社会中的电力网络[3]、Internet[4]、社交网络[5]等等.网络中的节点代表系统中的实体要素, 网络中各节点间的连边表示系统中各实体之间的相互作用关系.然而, 人们一般对现实中的复杂系统知之甚少, 不了解系统内部的相关结构, 例如, 生态系统中各个物种之间的相互影响关系以及大脑中各个部分之间的相互作用关系等.虽然系统中各要素之间的作用关系较难获得, 但随着系统的逐渐演化, 与系统行为相关的演化数据会被保留下来.例如, 在生态系统演化的过程中, 不同演化时期存在的物种种类和物种数量可以获得; 2019 年末到2020 年初爆发的新型冠状病毒在不同城市和国家的感染情况数据[6]也可以得到.通过对系统演化过程中产生的相关数据进行分析和处理, 可以对系统中隐藏的结构和动态过程进行挖掘, 这类研究问题被称为动力学网络重构[7-12].在现实世界, 很多网络中的数据能够体现网络上的动态过程, 例如: 交通网络中的流量、车速, 社交网络中的点赞数、转发数等.网络的结构具有自适应性质, 网络结构自适应辨识问题[13]对网络结构重构具有一定的帮助.综上, 如何根据网络上可观测的相关数据对未知结构的网络进行拓扑重构是一个重要且有研究价值的问题.
目前, 对网络拓扑进行重构的工作较为丰富,包括格兰杰因果关系(Granger Causality)[14-17]方法, 通过因果推断来判断变量之间的关系, 该方法对成对变量具有较好的适用性, 变量数量达到三个或者以上时, 推断的结果可能会出现错误.压缩感知(compress sensing)[10,18,19]方法通过将网络上的动力学过程转化成压缩感知方法能够处理的欠定线性系统, 利用可观测到的时间序列对网络的拓扑进行重构.压缩感知被广泛应用于电子工程尤其是信号处理中, 用于获取和重构稀疏或可压缩的信号.该方法的优势是通过获取少量的信号数据重构出原始信号.除此之外, 相关性方法能够根据网络节点之间的相关性进行网络拓扑重构.文献[20]针对网络噪音干扰问题提出了一种结合QR 分解(QR decomposition)和压缩感知的方法对网络进行结构重构.相关性方法在其他领域也有很多应用[21,22], 该方法的优点是简单快速, 适合大规模网络拓扑重构问题, 但对数据的数量和质量要求较高.
在面对网络结构重构问题时, 一些工作基于信息论[23]进行研究.与简单的利用相关系数作为节点相关性的依据相比, 与信息论相关的指标能更好地反映不同条件下节点之间的相关性程度.常用的基于信息论的指标有互信息[24](mutual information)、传输熵[25](transfer entropy)和因果熵[26,27](causation entropy)等.文献[28]利用传输熵对无线传感网的拓扑进行了推测, 但该网络的规模较小.网络重构的方法还有很多, 文献[29,30]较为详细地综述了相关的方法.
本文通过借鉴文献[31]中利用SIR 模型产生网络数据的方法进行网络拓扑结构还原, 产生数据的具体方法将在第3 节阐述.通过利用产生的初始数据, 我们的贡献有以下几点: 第一, 与传统的利用相关性指标[32]进行节点相关性计算不同, 首先统计被相同感染节点同时感染的不同节点数量, 然后再统计任意两个节点同时被感染的数量, 综合考虑了疾病在节点间的传播过程以及网络中不同节点之间的相互作用, 更加全面地刻画了网络节点之间的相关性; 第二, 与基于时序数据网络重构[33,34]方法不同, 我们的方法只需要离散的数据,即对数据之间的时间相关性没有要求, 较大程度降低了获取数据的难度; 第三, 使用了从局部到全局的结构重构方法, 充分利用了每条数据对网络结构的影响, 提高了网络拓扑重构的准确性且计算复杂度较低.
2 网络重构问题描述
网络重构问题根据对网络初始结构的了解程度可以分为两类: 一类为已知部分初始网络结构, 对剩余未知部分进行推理或预测, 这类问题一般被称为链路预测[35]问题; 另一类为对初始网络结构完全未知, 一般需要知道网络上的动力学过程或能够获取网络上的观测数据.
针对网络结构部分已知的情况, 可以利用链路预测相关方法进行网络结构的重构, 典型的链路预测方法包括最大似然估计[36]和概率模型[37]等.链路预测的思想是对给定的一个网络, 为网络中没有连边的节点对 (x,y) 赋予一个得分值Sxy, 对网络中所有没有连边的节点对的得分值按照从大到小排序, 排在最前面的节点对形成的连边概率最大.链路预测的思想可以用于网络拓扑重构, 需要做的是尽可能保证每条链路预测准确性以及预测链路的完整性.利用链路预测中的相似性[38]概念, 通过对相似节点进行判断从而获得相似节点间的连边关系.
对网络进行重构有以下几点困难: 第一, 网络结构的复杂性, 实际中的很多网络具有节点数量多、连接关系复杂的结构特点; 第二, 网络各节点之间的交互关系一般为非线性; 第三, 关于网络动态过程的数据较难获得, 包括数据的数量和质量.同时, 在获取网络数据过程中还会存在一定的干扰数据, 即噪声会对网络重构的精度产生影响; 第四, 实际存在的网络大多数为时序动态网络, 且存在双层甚至多层的结构, 因此如何对时序网络和多层网络结构进行重构[39]也是一个重要的问题.
3 基于离散数据的网络重构算法
3.1 网络数据
网络上的动力学过程有很多, 我们采取了经典的SIR 疾病传播过程[40]来产生网络数据, 具体过程如下.
在未知网络中任选一个节点作为感染节点, 设置疾病传播概率β=0.2 , 节点恢复概率µ=1 , 一定时间之后, 统计网络中最终稳定状态下被感染节点的数量, 这一过程产生了网络的一条数据, 以此类推, 重复上述操作, 可以获得关于网络的多条数据信息.文献[41]使用了和本文相似的数据形式,不同的是该论文产生数据使用的动力学过程与本文不同, 且网络中节点的状态会以一定的概率相互转移, 即使用的是非终态数据.

图1 网络初始二值数据矩阵Fig.1.Initial binary data matrix of the network.
为了更加直观地表示网络数据并便于后续的相关计算, 将网络中被感染的节点状态设置为“1”,未被感染的节点设置为“0”, 则可以得到网络初始二值数据矩阵, 数据格式如图1 所示.其中每一行代表不同的数据, 即不同的感染节点, 每一列表示网络中不同的节点.从该数据矩阵可以看出, 不同数据之间相互独立, 不存在时间上的相关性, 即数据是离散的.
3.2 相关定义
为了更方便地介绍我们提出的基于离散数据的网络重构算法, 给出以下相关定义.
定义1二值数据矩阵
给定一个图G=(V,E,S) ,V表示图中的节点集合,E表示图中的连边集合,S表示图中各节点的状态集合, 当节点j被第i次选取的感染源节点感染时,Sij=1 , 反之Sij=0.二值数 据 矩 阵SM×N=(Sij)M×N, 其中M表示网络中数据的数量,N为网络节点数量.
例如, 一个拥有16 条数据8 个节点的网络的二值数据矩阵可表示如下:

定义2相同感染源数量
给定一个图数据矩阵SM×N, 定义网络中任意两节点的相同感染源数量为SikSij,k /=j(当k=j时 规 定nkj=0 ), 其 中Sik表示节点k在第i次选取感染源节点时的状态,Sij表示节点j在第i次选取感染源节点时的状态,M表示数据数量.两节点的相同感染源数量越大,则两节点间的相似性越高, 两节点间存在连边的概率越大, 反之亦然.例如, 图2 中n12=4.
定义3相同感染源矩阵
给定一个二值数据图G=(V,S) 和图数据矩阵SM×N, 称AG=(nkj)N×N, k /=j(当k=j时规定nkj=0 )为相同感染源矩阵,nkj为节点k和节点j的相同感染源数量,N为二值数据图节点数量.
例如, 图2 所示数据矩阵对应的相同感染源矩阵为

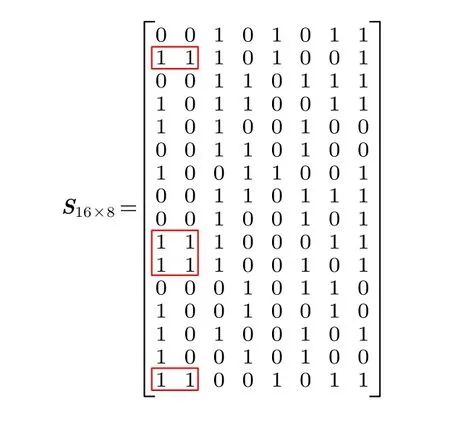
图2 节点1 和节点2 的相同感染源数量Fig.2.The same number of infection sources in node 1 and node 2.
定义4二值数据子图
给定一个二值数据图G=(V,S) 和图数据矩阵SM×N, 针对任意数据i, 称节点集合V i={vj|Sij=1}中的节点构成的图为二值数据子图Gi.例如, 由S16×8可以得到数据1 对应的子图节点集合为
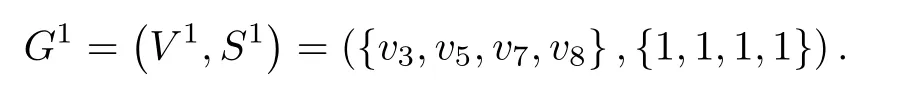
定义5子图相同感染源矩阵
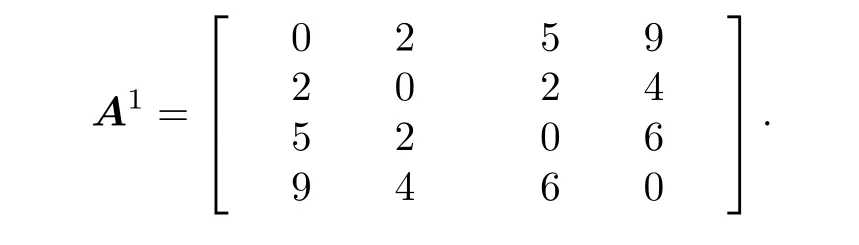
给定一个二值数据子图Gi, 称Ai=(nkj)Ni×Ni,(当k=j时规定nkj=0 )为二值相同感染源矩阵, 其中k,j ∈V i,Ni为第i次选取感染源节点时对应的二值数据子图节点数量.
例如, 图2 数据矩阵中数据1 对应的子图相同感染源矩阵为
3.3 子图重构
给定任意数据i对应的子图相同感染源矩阵Ai, 对矩阵中每一行进行最大共同数据数搜索, 对最大数据数处两节点进行连边, 得到重构子图其中Vi为子图节点集合,Ei为子图连边集合,npq为节点p和节点q的相同感染源数量; 当出现多个相同的最大共同数据数时, 依次选取其中的每个最大值对应的两节点进行连边, 对得到的不同子图进行度方差计算, 并将度方差值小的子网络作为最终子网的结构, 度方差计算公式为
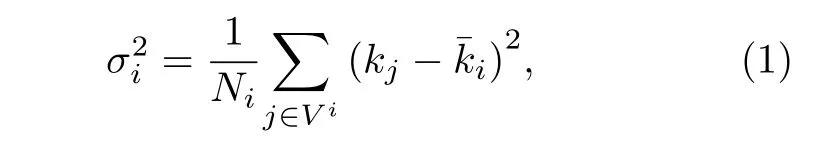
其中表示第i条数据对应子图的度方差值;kj表示子图中节点的度值;表示子图的平均度值,Ni为子图节点数量.例如, 数据1 对应的子图重构过程如图3 所示.
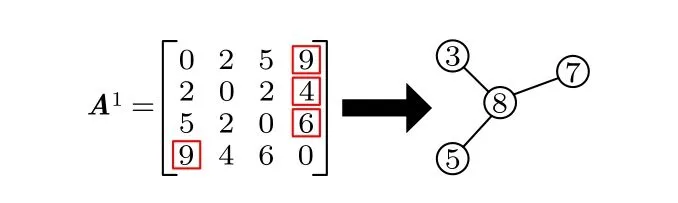
图3 子图重构过程Fig.3.Subgraph reconstruction process.
3.4 子图叠加
对所有数据得到的重构子图Gi进行叠加, 即对子图Gi中的相同节点进行重叠, 最终得到图G的拓扑, 即其中V表示图G的节点集合,E表示图G的连边集合,M表示数据数量,Ei为第i条数据对应重构子图的连边集合,V i为第i条数据对应重构子图的节点集合, 子图叠加过程如图4 所示.对所有数据得到的子图进行叠加得到网络全局拓扑, 即得到网络的邻接矩阵A.
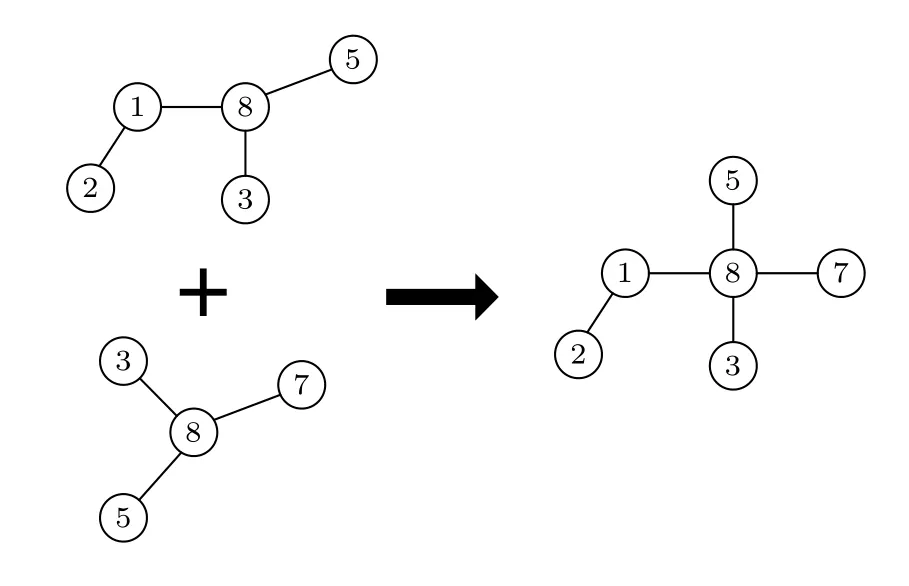
图4 子图叠加过程Fig.4.Subgraph superposition process.
子图叠加数学计算过程如下:

网络重构算法流程如下所示:
AlgorithmNetwork Topology Reconstruction
Input:Binary data matrixSM×N
为主动适应高等教育国际化的要求,加快研究生培养国际化进程,拓展研究生的国际视野,提高研究生培养质量,中国药科大学自2013年起在同类高校中率先面向博士生研究生正式开设本校第一门国际化公开课《Scientific Methodology》,迄今已经6年,其中2013~2017年共开设18门公开课,每门课程资助5万元,投入经费90万元。2018年已正式立项7门,每门课程同样资助经费5万元。已经开设的中国药科大学研究生国际化公开课详情参见表1。

Output:Network topologyG
4 实验结果分析
4.1 网络重构指标
采用真正例率(true positive rate, TPR)和假正例率(false positive rate, FPR)分别表示网络重构的准确率和误差, TPR 指标越高, FPR 指标越小则说明网络重构的效果越好[42-43].TPR 和FPR指标计算公式如下:

其 中TP(true positive), FP(false positive), TN(true negative)和FN(false negative)分别表示真正例数、假正例数、真反例数和假反例数.
4.2 三种网络重构效果分析
为了验证本文算法的适用性, 针对不同规模的WS 小世界网络、BA 无标度网络[44]和ER 随机网络[45]进行了网络重构实验, 网络的相关拓扑属性如表1 所列, 其中N表示网络节点数量,E表示网络连边数量,〈k〉表示网络的平均度,C表示网络的集聚系数,〈l〉表示网络的平均路径.

表1 三类网络的基本拓扑特征Table 1.Basic topological features of the three types of networks.
4.2.1 WS 小世界网络实验
图5 为不同规模的WS 小世界网络重构实验效果.由图5 可以发现, 随着网络数据的增加, 不同节点规模的WS 小世界网络重构效果也越来越好, 且最终都能够完全重构出网络的拓扑.还可以发现, 随着网络规模的增加, 需要的网络数据量也随之增加, 但从最终达到平衡的数据数量来看, 需要的信息数量与网络节点呈线性变化, 即对网络数据数量的需求与网络节点数量是同一个数量级.从对WS 小世界网络的重构实验结果可以看出,本文算法对网络拓扑还原具有较高的准确性, 能够适应不同规模的网络, 且对网络数据数量的要求不高.

图5 不同规模的WS 小世界网络重构实验效果Fig.5.Experimental results of WS small world network reconstruction with different scales.
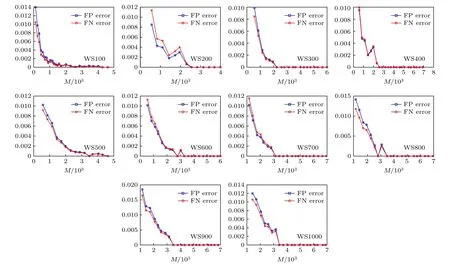
图6 不同规模的WS 小世界网络重构误差分析Fig.6.Error analysis of WS small world network reconstruction with different scales.
为更直观地反映算法的重构效果, 定义了多边重构误差eFP和少边重构误差eFN指标, 计算公式如下:

如图6 所示, 在不同节点规模的WS 小世界网络重构实验过程中, 随着实验数据的增加, 网络重构实验的多边重构误差eFP和少边重构误差eFN逐渐减小, 最终趋近于0, 该实验误差分析进一步说明了本文算法的准确性.

图7 WS 小世界网络不同平均度值对网络重构实验效果的影响Fig.7.Influence of different average degrees of WS small world network on network reconstruction experiment.

图8 不同规模的BA 无标度网络重构实验效果Fig.8.Experimental results of BA scale-free network reconstruction with different scales.
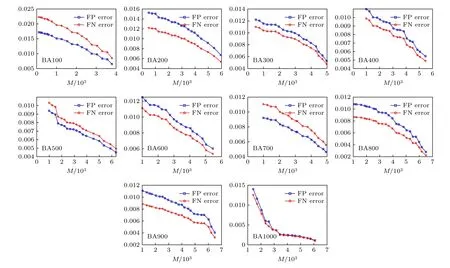
图9 不同规模的BA 小世界网络重构误差分析Fig.9.Error analysis of BA scale-free network reconstruction with different scales.
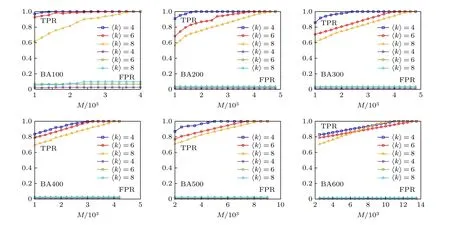
图10 BA 无标度网络不同平均度值对网络重构实验效果的影响Fig.10.The influence of different average degree values of BA scale-free network on network reconstruction experiment.
4.2.2 BA 无标度网络实验
从图8 可以看出, 与WS 小世界网络类似, 随着网络数据的增加网络重构效果也越来越好.图9展示了实验误差曲线, 总体上来说网络重构误差随着实验数据的增加逐渐减小.从图10 可以看出,在相同网络数据的情况下, 网络平均度值越大, 网络的重构效果越差, 且平均度值越大网络重构需要的数据越大.
4.2.3 ER 随机网络实验
图11 展示了不同规模的ER 随机网络重构效果, 相比同等规模的WS 小世界和BA 无标度网络, ER 随机网络需要更多的网络数据.图12 展示了两种重构误差的变化情况, 可以发现, 两种重构误差变化的趋势基本一致, 误差随实验数据的增加逐渐减小.除此之外, 对具有不同平均度值的ER随机网络进行网络重构实验, 发现网络重构的效果与网络的平均度值基本没有关系, 从图13 可以发现三条曲线基本重合.

图11 不同规模的ER 随机网络重构实验效果Fig.11.Experimental results of ER random network reconstruction with different scales.

图12 不同规模的ER 小世界网络重构误差分析Fig.12.Error analysis of ER random network reconstruction with different scales.
4.2.4 三种网络对比实验
为了更直观地比较不同网络重构效果, 同时对WS, BA 和ER 网络进行网络重构实验, 实验结果见图14.从图14 可以看出, 在相同网络数据下可以发现WS 和BA 网络的重构效果类似, ER 网络则需要更多的网络数据.
4.3 三种实际网络重构效果分析
为了更好地说明本文算法的适用性, 选取了三个实际网络进行网络重构实验, 三个网络的具体属性数据如表2 所列.其中, Euroroad 和Minnesota 为公路网数据集, 相关数据可以在http://networkrepository.com/road.php 上获取; Power Grid 数据集由Duncan Watts 和Steven Strogatz 编制, 数据可在http://cdg.columbia.edu/cdg/datasets 上获取.

图14 三种不同网络在相同数据下的重构效果对比Fig.14.Comparison of reconstruction effects of three different networks under the same data.

图15 三个实际网络重构实验效果Fig.15.Experimental results of three practical network reconstruction.

图16 三个实际网络重构误差分析Fig.16.Error analysis of three practical network reconstruction.

表2 三个实际网络的基本拓扑特征Table 2.Basic topological characteristics of three practical networks.
图15 展示了三个实际网络的重构效果, 可以发现网络边数(节点)越多, 重构网络需要的数据越多, 随着使用数据的增加, 网络的重构效果也逐步提高.图16 展示了三个实际网络对应的重构误差变化曲线, 可以看出, 三个实际网络的重构误差随着数据量的增加都呈现下降趋势, 最终都趋近于0.
5 总结与展望
针对网络结构完全未知, 网络上的动力学过程已知的网络结构重构问题, 提出了一种基于离散数据从局部到全局的网络重构算法.通过在网络上模拟SIR 疾病传播过程来产生网络数据, 利用产生的数据从局部还原到全局叠加, 最终重构出整个网络的拓扑.我们提出的算法具有快速, 简单的优势,且适用于不同网络类型.为了验证算法的准确性和适用性, 在具有不同节点数量的WS, BA 和ER 网络上进行了仿真实验, 实验结果表明我们的方法能够准确地还原出不同规模大小的网络拓扑.为了验算法的适用范围, 还对三个实际网络进行了重构实验, 由实验结果可以发现, 本文提出的算法同样可行.目前我们研究的对象属于单层静态网络, 以后的工作可能会考虑如何对动态和多层网络进行拓扑重构.
