基于密码学的致病基因安全定位方案
2021-04-22黄秀珍周潭平李宁波
黄秀珍 周潭平 李宁波
0 引言
基因是指导人类生命活动的密码,人类的一切生命活动和生理现象都几乎与基因直接相关[1]。基因数据可以被广泛应用于医疗保健、生物医学研究及身份鉴定等领域[2-3],具备很高的研究价值。随着生物医学的不断发展及基因组测序成本的不断下降[4],越来越多的人有能力获取自己的基因数据。个体的基因数据带有浓厚的个人隐私特征[5],如果保护不当,可能会引发基因歧视[6]、司法犯罪等问题。同态加密能够对基因数据进行加密保护,且大部分的同态加密方案都基于格上的困难问题构造,具备较好的安全性,因此,利用同态加密开展对基因数据的保护和安全分析,近些年逐渐引起了学者们的关注。
2014年,Lauter等[6]利用同态加密对基因数据进行保护,并研究了如何利用一些常用的基因分析算法对密态的基因数据进行分析。同年,Bos等[3]研究了同态加密在处理敏感的私人医疗数据和基因数据方面的应用,并利用同态加密对密态数据进行预测分析,从而预测一些疾病的发病概率,文献[3,6]基于NTRU[7]型类同态加密方案进行密态运算,可能受到子域攻击,无法保证基因数据安全。2015年,Lu等[8]利用基于环上的误差学习问题(ring learning with error problem,RLWE)的同态加密来开展全基因组关联研究(genome-wide association studies,GWAS)上的安全外包计算。同年,Kim等[9]利用同态加密方案BGV12[10]等方案对基因数据进行保护,对密态的基因数据进行GWAS上的最小等位基因频率计算,以及DNA序列间的汉明距离和近似编辑距离计算。2016年,Wang等[11]利用同态加密对基因数据进行保护,对密态的基因数据进行逻辑回归分析,并提出一个治疗框架,利用小的样本数量来进行安全的罕见变异分析,上述文献[3,6,9,11]基于单密钥全同态加密方案,无法应用于多方来源基因数据场景下的密态运算。2017年,Kim等[12]利用多项式环上的同态加密对基因数据库进行加密,并研究了如何对基因数据库进行密态的查询和匹配,但该方案无法对基因数据进行统计分析。
2017年,Jagadeesh等[13]在《Science》上发表JWB+17方案。该方案利用现代密码学中的安全多方计算技术:Yao混淆电路[14-16]+不经意传输[17-19],以及基于频率的临床遗传学相关内容,利用对称加密对患者的基因数据进行保护,并利用两云模型将两方参与的安全计算扩展到多方参与的安全多方计算,从而在不泄露患者基因隐私的前提下,实现对单基因疾病[20-22]患者的致病基因定位。能否定位致病基因,对一些基因疾病的预防和治疗具有重大意义。JWB+17方案中用来对致病基因定位的电路有3个:Intersection电路、MAX电路和SET DIFF电路,并通过两云模型将两方参与的安全计算扩展到多方参与的安全计算。经过对该方案进行分析,发现其存在以下缺陷。(1)致病基因定位电路方面:原方案中3种电路仅适用于单基因疾病致病基因定位,应用范围较窄;SET DIFF电路虽然实现了相应功能,但是不够精简,影响方案效率。(2)为避免Yao协议的运行过程中参与方需实时在线且通信量大的问题,JWB+17方案使用了两云模型。一方面,两云模型中需要一个比较强的假设:即两个云之间不会合谋,这个假设对于实际情况而言较强,安全隐患较大。另一方面,两云模型的引入,需要使用比平凡Yao协议更加复杂的gabled电路[23-24],降低了方案效率。此外,两云模型在执行Yao协议过程中,gabled电路不能重复使用,这会造成较大的通信量[25-26]。
目前,对于基因数据的密态处理解决方案中,存在安全性薄弱、无法处理多方来源的基因数据或者通信代价高的缺陷。密码学中,多密钥全同态加密(multi-key fully homomorphic encryption,MKFHE)支持对不同用户(不同密钥)的密文进行任意的同态运算,运算之后的结果由参与计算的用户联合解密[4],具备强大的密态计算能力(支持对基因的密文数据直接运算,因此可以保证患者的密文数据计算过程中的安全),且通信代价较低。基于以上分析,本文考虑利用密码学中新兴技术MKFHE对患者的基因数据进行密态操作,实现对多方来源的数据进行密态处理的致病基因安全高效定位。
1 致病基因定位方案整体结构和基础部件
方案拟解决如下问题:多家医院的研究人员希望定位某个疾病的致病基因的位置信息,但是每家医院的基因数据样本都太少,无法进行有效的统计分析,因此考虑将所有合作医院的基因数据进行汇总并分析。基因数据的分享对患者的隐私带来严重的安全隐患,有助于医疗数据的共享[27-28],本文使用MKFHE技术构造了致病基因安全定位方案,可保证基因数据在统计计算过程中的安全性。实际场景的整体流程如图1(两家医院数据整合为例)。

图1 致病基因安全定位整体流程Figure 1 The overall process of secure location scheme of pathogenic genes
(1) 患者到医疗机构进行基因测序,获取各自的基因数据。具体过程见1.1节。
(2) 医疗机构将患者的基因数据进行同态加密后,上传到云服务器。
(3) 医疗机构对云上的加密基因数据进行分析处理(通过对加密数据同态运行相关的函数布尔电路实现),得到最终的分析结果(密态)。
(4) 医疗机构对最终的分析结果进行解密,得到有关致病基因变异位置的信息。
1.1 基因数据预处理
将参与者的基因数据转化为MKFHE方案所能处理的数据类型,是执行本方案的前提,对参与者的基因数据进行预处理的方法如下[13]。
研究对象首先到医疗机构进行基因测序,获取各自的基因数据。医疗机构根据当前已研究发现的所有的基因变异数据库(数据库中包含了基因变异的位置信息和变异信息),将研究对象的基因数据与其进行比对,若其在相应的位置发生变异,则将该位置的值设定为“1”,反之则设定为“0”,由此每个研究对象可以得到一个关于自身基因变异信息的比特串[13]。预处理的过程见图2。

图2 基因数据预处理示意图Figure 2 Schematic diagram of the pre-processing of genetic data
1.2 底层多密钥全同态加密方案
密码技术是信息安全的核心技术,早期密码技术研究的重点在于保证信息存储和传输过程中的安全。而MKFHE是对不同用户(不同密钥)的密文进行任意的同态运算,运算之后的结果由参与计算的用户联合解密[28],因此可以较好地解决多用户密文进行同态计算的问题。
2019年亚洲密码学年会上,Chen等[29]提出并实现了MKFHE方案CCS19。相对于其他类型的MKFHE方案(NTRU型、GSW型、BGV型),CCS19具有加解密和自举过程速度快,支持高效处理比特数据,同态逻辑电路,密文规模随用户数量呈线性增长的优点,更加适合致病基因定位。对于安全参数l,令C为深度为L的运算电路,CCS19多密钥全同态加密方案E=(Setup,KeyGen,Enc,Extend,Eval,Dec)由以下算法组成。
(1) 初始化算法pp←MKFHE.Setup(1λ,1K,1L):输入安全参数l,参与计算的用户数量的上界K,电路深度的上界L,输出公共参数pp。
(2) 密钥生成算法(pki,ski,eki,evki)←MKFHE.Key Gen (pp):输入公共参数pp,输出每个参与方的公钥pki,私钥ski,密文扩展所需的密钥eki,以及同态运算所需的密钥evki(i=1,…,K)。
(3) 加密算法ci←MKFHE.Enc (pki,mi):以第i个参与方为例,输入其公钥pki以及待加密的明文mi,输出密文ci,该密文包含了相关的私钥以及电路层级信息。
CCS19方案的正确性:输入t个对应着相同用户集S的密文序列(ci,S,evki)i∈[t]和任意的深度为L的电路C,令μi= Dec (skS,ci,S),则以下公式表达了MKFHE方案的正确性。
1.3 致病基因定位函数
本节对JWB+17方案中的3种致病基因定位函数进行介绍[13]。
1.3.1 MAX函数
MAX函数[13]用来定位所有的患者中发生变异次数最多的突变基因。该函数对所有患者(预处理之后)的基因数据进行求和,求和结果中最大的数值所对应的基因位置标为1,其余标为0,见图3。

图3 MAX函数示例Figure 3 Example of MAX function
以两名患者为例,分别输入各自的n比特的基因数据x=(x1,…,xn)和y=(y1,…,yn),MAX函数输出b=(b1,…,bn),其中:
bi=EQ(MAX(ADD(x1,y1),…,
ADD(xn,yn)),ADD(xi,yi))
(2)
ADD函数对输入的基因数据进行算术求和,MAX函数输出所有输入数据中的最大值,EQ函数对输入的两个数据进行比较操作(若相等,输出1,反之,输出0)。
1.3.2 Intersection函数
Intersection函数[13]用来定位患者中共同发生的突变基因,即只有在某个基因位置所有的患者都发生变异,则该位置被标记为1,反之,标记为0,见图4。

图4 Intersection函数示例Figure 4 Example of Intersection function
以两名患者为例,分别输入各自的n比特的基因数据x=(x1,…,xn)和y=(y1,…,yn),Intersection函数输出b=(b1,…,bn),其中bi= AND (xi,yi),AND函数表示对输入的基因数据进行“与”运算。
1.3.3 SET DIFF函数
SET DIFF电路[13]研究对象为父母正常,子代患病的家庭,用来定位父母未发生而子代发生的突变基因,即只有父母均发生变异,而孩子发生变异的位置,才会输出1,见图5。

图5 SET DIFF函数示例Figure 5 Example of SET DIFF function
以三口之家为例(父母和1个孩子),分别输入父母的基因数据x=(x1,…,xn)和y=(y1,…,yn),以及孩子的数据z=(z1,…,zn),SET DIFF函数输出b=(b1,…,bn),其中bi= AND (zi,EQ(0,ADD(xi,yi)))。
SET DIFF函数可以通过加法器、比较相等电路以及与门电路实现[13]。其电路实现形式见图6。

图6 SET DIFF函数电路结构示意图Figure 6 Schematic diagram of SET DIFF function circuit structure
2 研究方案
2.1 定位电路设计
定位电路的设计是本文核心内容。在设计定位电路时,一方面需要考虑电路具有实现基因定位的功能,另一方面需要结合使用的具体密码方案特点。兼顾这两个方面才能更加安全准确地实现致病基因定位。
2.1.1 SET DIFF函数电路实现形式优化
SET DIFF函数可以由相对较为复杂的加法门电路、与门电路以及比较相等电路来实现,为了提高SET DIFF函数的门电路实现效率,本方案对该函数的电路实现结构进行了简化,通过3个简单的“与”门电路、“或”门电路和“非”门电路,即可实现原有函数的功能,从而较大程度地降低了电路的复杂度,提高了电路的实现效率。经过优化后的SET DIFF函数如下。
以三口之家为例(父母和1个孩子),分别输入父母的基因数据x=(x1,…,xn)和y=(y1,…,yn),以及孩子的数据z=(z1,…,zn),输出b=(b1,…,bn),其中bi=AND (NOT(OR(xi,yi)),zi)。优化后的电路实现结构图见图7。

图7 优化后的SET DIFF函数电路结构示意图Figure 7 Schematic diagram of optimised SET DIFF function circuit structure
2.1.2 ITH-intersection(门限定位)函数
基因中的一个或者多个位置的恶性变异,都有可能会引发基因疾病,以帕金森病为例,该疾病可能由135个基因位置的恶性变异引起,任何几个基因位置的突变都可能会引发疾病。原JWB+17方案中所使用的3种致病基因定位函数,只能针对单基因疾病进行定位诊断,适用范围较窄。为了能够针对多基因疾病进行分析研究,本研究设计了ITH-intersection函数(门限定位函数),该函数的研究对象为患同一种基因疾病的患者,通过设置合适的阈值,能够输出可能导致患病的多个基因数据的位置以及该位置具体变异的患者个数,扩展了致病基因定位的适用范围。
输入m个患者的基因数据yj=(yj,1,…,yj,n),其中j∈{1,…,m}。输出Z=(z1,…,zm),其中zj=(zj,1,…,zj,n),zj,i= MULT(ADD (y1,i,…,ym,i),LT (l,ADD (y1,i,…,ym,i))),j∈{1,…,m},i∈{1,…,n},LT 函数表示当左侧的输入小于右侧输入时,输出1,否则输出0,LT (x,y)函数可以通过加法函数ADD(y,-x)构造,ADD(y,-x)输出的最高位就是需要的结果。ITH-intersection电路的具体实现形式如图8所示。在实际实验过程中使用AND函数代替MULT函数以提升效率,令s=ADD (y1,i,…,ym,i),si表示s的第i个比特,则zj,i=AND(si,LT (l,ADD (y1,i,…,ym,i)))。

图8 ITH-intersection(门限定位)函数电路结构示意图Figure 8 Schematic diagram of function circuit structure of ITH-intersection
2.1.3 ITop-k 函数
除了门限定位函数,本文还设计了ITop-k函数,该函数能够输出所有患者中变异次数最多的前k个基因位置以及该位置对应的变异次数排序值(当多个位置变异次数相同时,输出相同的排序),可以用于多基因疾病的致病基因定位。
输入h个患者的基因数据xj=(xj,1,…,xj,n),j∈{1,…,h},输出b=(btop-k,1,…,btop-k,n)。ITop-k函数对应的电路实现结构较复杂,很难用图形展示,其具体过程见算法1。

算法1:ITop-k电路输入:h个用户的比特串xj=(xj,1,…,xj,n),j∈{1,…,h}。输出:b=(btop-k,1,…,btop-k,n)。1:xtop-1,i=ADD(x1,i,…,xh,i), 1≤i≤n2:for r=1,…,k-1btop-r,i=1btop-r,i = EQ(MAX (xtop-r,1,…,xtop-r,n),xtop-r,i ),1≤i≤nbtop-r,i=ADD(btop-r,i,-btop-j,i)xtop-(r+1),i=MULT(btop-r,i,xtop-r,i),1≤i≤n3:btop-k,i = EQ(MAX (xtop-k,1 ,…,xtop-k,n),xtop-k,i),1≤i≤n4:btop-k,i=ADDkj=1(MULT(j,btop-j,i)),1≤i≤n5:b=(btop-k,1,…,btop-k,n)6:end for
2.2 基于MKFHE的致病基因定位方案计算流程
按照MKFHE方案密态计算的框架,结合具体的定位函数,得到基于MKFHE的致病基因定位方案计算流程,整体流程见图9,伪代码见算法2。
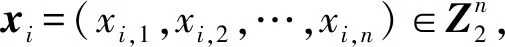
(2) 基因数据预处理。将参与者的基因数据转化为MKFHE方案所能处理的数据类型,具体方法见1.1节。
(3) 数据加密。研究对象i利用公钥pki对基因数据xi进行逐比特同态加密,得到密文序列{ci,j←MKFHE.Enc(xi,j)}j = 1,…,N,并将密文数据上传到云端。



算法2:基于MKFHE的致病基因定位算法输入:xi={xi,j},pki,eki,evki,i∈[N],j∈[n] 。输出:{c′j}j=1,…,N。1:for i=1,2,…,N,j=1,2,…,n ci,j ←MKFHE .Enc (xi,j )2:for i=1,2,…,N,j=1,2,…,n ci,j ←MKFHE.Extend(ci,j ,(pk1 ,…,pkN ),eki )3:for j=1,2,…,n c′j←MKFHE.Eval(C,(c1,j ,pk1,evk1),…, (cN,j ,pkN ,evkN ))4:for j=1,2,…,n mj←MKFHE.Dec(sks=sk1,…,skN),c′j)5:end for

图9 云环境下致病基因安全定位计算流程Figure 9 Computation process of secure location scheme of pathogenic genes in Cloud

表1 本方案与JWB+17方案在效率方面的对比Table 1 Efficiency comparison of our scheme with JWB+17 scheme
3 实验分析
本文对两方参与的Intersection电路、SET DIFF电路,每个用户输入48比特的信息进行了测试;对三方参与的ITH-intersection电路,每个用户输入48比特的信息进行了测试。主要测量了计算的时间及通信量。实验环境如下,笔记本:DELL precision 7530,系统:Ubuntu 18.04 STL,CPU:Intel(R) Core(TM) i7-8750H 2.20 GHz,内存:16 GB。实验结果见表1,本文方案与JWB+17方案[13]整体的对比见表2。

表2 本文方案与JWB+17方案整体对比Table 2 Functional comparison of our scheme with JWB+17 scheme
测试结果显示,本文方案的通信量相比JWB+17方案大幅降低,但运行的时间更长。因此,本文方案更加适用于带宽受限的系统。虽然JWB+17也尝试通过两云模型的方式,降低带宽,但是这种模式无法抵抗两云的合谋攻击,安全性假设太强。此外,JWB+17方案中的混淆电路无法重复使用,每次进行新的运算时需要重新构造混淆电路。而在本文方案中,用户密文可以重复使用,只需要上传一次密文即可。因此,相比于JWB+17方案中各个机构需要实时在线运行协议,本文方案可以支持离线操作,操作更加便利。
4 讨论与结论
本文基于密码学中的多密钥全同态加密技术,结合基于频率的临床遗传学相关内容,提出一种对不同患者基因数据进行致病基因安全定位的方法,该方法可以支持对多方来源的数据进行密态处理,在一定程度上解决了不同医疗机构希望共享基因数据又希望保护本机构中患者隐私的矛盾。
实验结果表明,相对于JWB+17方案,本方案可以支持对多基因疾病进行分析,扩大了目前基因数据密态处理的应用范围,方案大幅降低了数据通信量,更加适用于带宽受限的系统。后期,拟进一步优化底层方案,使得方案可以应用于对大规模用户的场景。
