MSDL-IEW:面向文本分类的密集度感知主动学习算法
2021-04-17TRANBaphan马菲菲明晶晶余秦勇李全兵王永利
TRAN Baphan,马菲菲,明晶晶,余秦勇,杨 辉,李全兵,王永利
(1.南京理工大学计算机科学与工程学院,南京210094;2.中电科大数据研究院有限公司,贵阳550022;3.提升政府治理能力大数据应用技术国家工程实验室,贵阳550022;4.南京供电公司,南京210000;5.中国电子科技网络信息安全有限公司,成都610041)
引 言
随着互联网技术的迅速发展,信息数据呈指数趋势增长,更多的人可通过互联网进行消息的接收和传播,产生了越来越多的新闻标题、微博评论和产品评价等即时性文本信息,很难在短时间内得到大量的已标注数据,因此文本信息的自动分类成为当前的研究热点[1]。传统的文本分类算法依赖于已标注数据作为模型的训练集,其分类性能也会随着训练集规模增大而逐步提升,然而上述的即时性文本分类任务面临的重大问题是极少的已标注数据和大量的未标注数据[2],因此传统的文本分类方法不适于解决即时性文本分类任务。
为了解决无法即时标注及成本过高的问题,主动学习得到众多的国内外学者的广泛关注。主动学习算法可以从未标注样本集中选择最有价值的样本交由专家进行标注,从而在不损失训练精度的情况下减少标注样本的代价[3]。主动学习中常用的采样策略可以分为以下几种:基于不确定性的采样策略、基于版本空间缩减的采样策略、基于模型改变期望的采样策略以及基于误差缩减的采样策略[4]。聂嘉贺[5]基于主动学习算法采用RCNN模型作为分类器,提出了一种基于主动学习的文本分类框架,同时结合数据挖掘技术和深度文档向量模型,改进了初始样本选择算法,能从未标注数据集中选取出更能代表样本空间的样本。黄永毅等[6]以支持向量机文本分类方法为基础,提出基于主动学习的交互式支持向量机文本分类方法,即依据已知样本设计分类规则,然后通过主动学习提取不确定样本,二次构建交互式分类器。但现有工作未考虑离群点对分类模型造成的影响,泛化能力不强。因此,本文在构建初始训练集时选择更具代表性的样本加入,引入密集度更好地覆盖整个样本空间。
本文提出了一种面向文本分类的不确定性主动学习算法,为了增加已标注样本的代表性,本文利用隐含狄利克雷分布(Latent Dirichlet allocation,LDA)算法的思想对未标注样本集进行密集度计算,从样本集中密集度高的样本群进行取样,相较于随机选取初始训练集更能体现选取样本的代表性;在后续选取待标注样本时,考虑到在传统主动学习算法中,无法量化样本的不确定程度,本文在对已标注样本进行训练时引入加权项,加快分类模型训练,重复上述步骤,直至分类器达到预期准确度。
1 基于MSDL-IEW的主动学习文本分类模型
采用主动学习算法解决文本分类问题总体上来说分为3个阶段:(1)初始训练集的构建;(2)待标注文本采样;(3)设定终止条件[7]。针对已有方法的不足,本文对基于不确定性的主动学习文本分类方法进行了改进,提出基于MSDL-IEW(Measure sample density by LDA information entropy weighting)的主动学习文本分类算法,该算法的整体模型结构如图1所示。首先,通过LDA算法得到样本的主题分布,并计算密集度,选取样本密集度高的样本加入到初始训练集中,训练一个初始分类器;然后采用最大熵策略采样,选择出“价值”最大的多个文本;然后,读取其对应样本类别标签标注,并计算其权重,加入训练集重新学习一个新的分类器;重复上述过程,直到分类器性能不再提升。
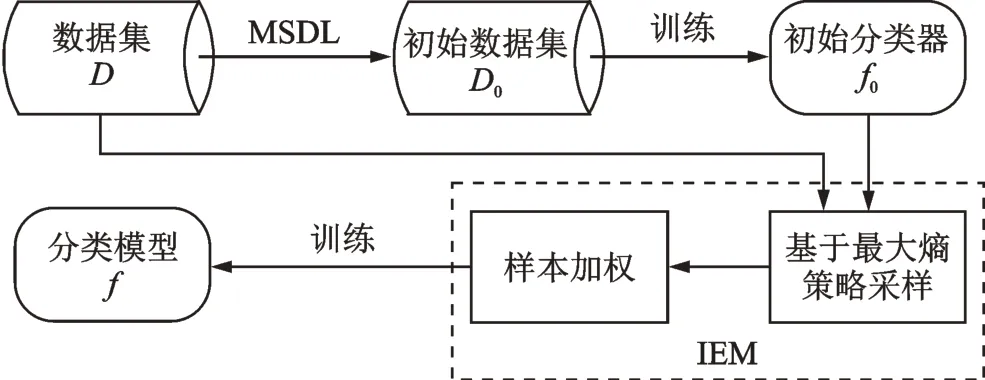
图1 MSDL-IEW主动学习算法框架Fig.1 MSDL-IEW active learning algorithm model
1.1 基于MSDL的初始训练集选择策略
对于文本分类任务,体现文本类别的特征不一定会显示地出现在文档中,因此提取出文档的主题对文本分类十分重要,本文采用LDA模型计算主题分布[8],并进一步计算数据集的样本密集度,从而可以将具有代表性的样本加入到初始训练集中。LDA是一种对离散数据集建模的概率主题模型,是一种对文本数据的主题信息进行建模的方法,通过对文本进行一个简短的描述,保留本质的统计信息,有助于高效地处理大规模的文档集。本文中LDA模型可将语料中的每个文档中的信息转换为主题向量,根据每个文档的主题向量进一步计算文档间的语义距离,模型的各符号含义如表1所示。
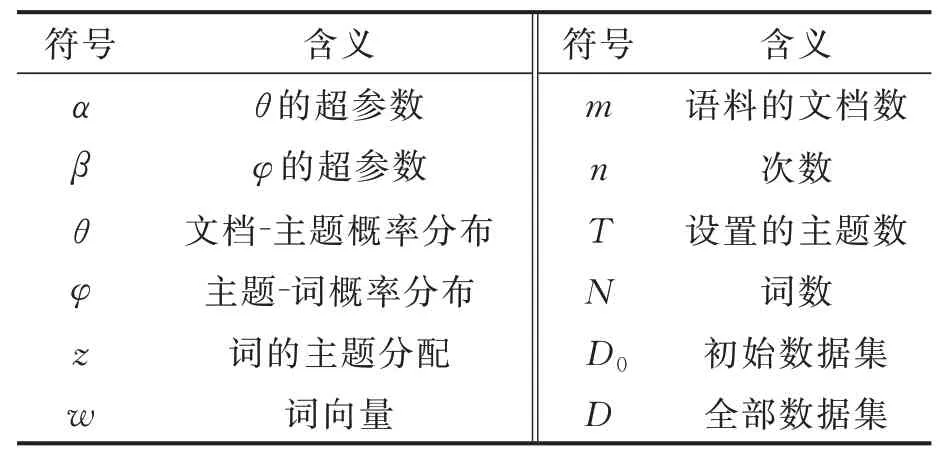
表1 MSDL算法中各符号的含义Table 1 Symbolic meaning in MSDL algorithm
针对传统主动学习算法可能选出离群点的问题,本文将样本的代表性加入样本价值的度量中,提出MSDL算法(Measure sample density by LDA)进行初始样本集的选取,即结合LDA算法对样本进行密集度计算,并在密集度较高的样本群范围内进行采样,MSDL算法描述见算法1。
算法1Measure sample density by LDA
输入:主题个数T,超参数α、β,数据集D,初始训练集的文档个数m0
输出:初始训练集D0
1.随机初始化文档中每个词w的topic编号z
2.while not Gibbs采样收敛
3.for eachxi∈D
4.for eachw∈xi
5.重新采样w的topic
6.根据Dirichlet分布用式(1,2)得到该文档一个主题分布概率θ
7.for eachp∈θ
8.for eachq∈θq≠p
9. 利用式(3,4)计算文档间距离djs(p,q)
10.利用式(5)计算文档的密集度ρtext(p)
11.for eachxi∈D
12.if len(D0)<m0
13.D0←xi
14.else
15.ifρtext(xi)>min{ρtext(xj)|xj∈D0}
16.D0←xi
17.D0.del(xj)
算法1的时间复杂度为O(Niter),其中Niter为最外层迭代次数,为文档的平均长度。
通过对变量z进行Gibbs采样[9]间接估算θ和φ


通过计算文本的相似度进而得到数据的密集度,由于文本的主题分布是文本向量空间的映射,因此在文本的主题表示情况下,计算两个文本的相似度可以通过计算与之对应的主题概率分布来实现。以JS距离[10]公式为标准来度量文本p和q之间的相似度。
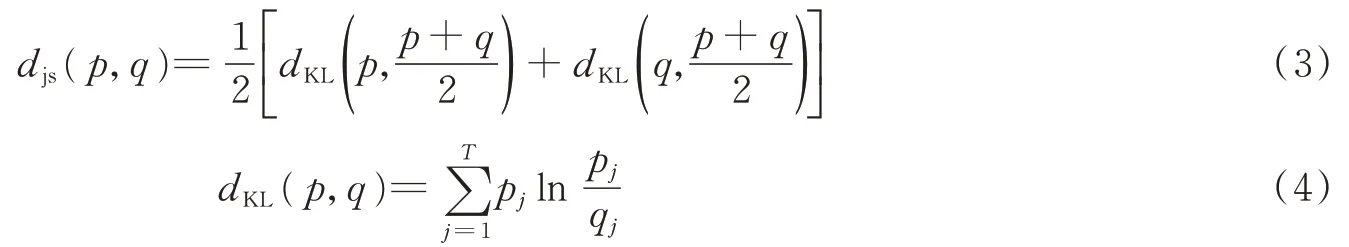
根据计算出的文本间相似度,在整个数据集范围内,针对样本p的周围样本的密集度进行计算,根据初始样本集需求,按照密集度递减顺序选取样本。文档p的密集度计算公式为

式中:ε代表度量样本p和q之间距离是否相近的阈值,Nε(p)代表与样本p距离小于阈值的样本个数。
1.2 基于信息熵的样本加权
在传统基于不确定的主动学习算法中,假设已有部分已标注样本集D={x1,x2,…,xn}⊂Rd,其中DL为已标注样本集,未标注样本集为Du=D-DL,系统以已标注样本DL为训练集训练出初始分类器,然后在未标注样本Du中根据不确定性选择部分样本进行标注并将其加入到训练集中,从而训练出新的分类器,整个过程循环多次,直到分类器的某种评价指标达到预设值或循环次数达到预设值为止。
上述基于不确定性的采样(Uncertainty sampling)过程是使用分类器直接估计未标记样本的后验概率值,选择最难被分类器区分的样本[11]。信息熵[12]是基于不确定性采样中最常用的方法,即基于最大熵(Maximum entropy,ME)原则采样,样本的信息熵越大则其不确定性越大,而对当前分类器来说就是最不能确定其所属类别的样本。信息熵的定义为
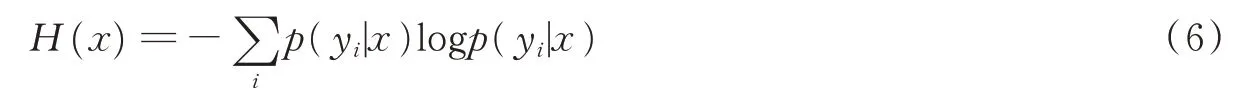
式中p(yi|x)表示在给定样本x的情况下其标签属于yi的可能性。
在上述MSDL算法中,为减少离群点对模型的影响,基于样本密集度选取初始训练集。在后续选择待标注样本时,使用分类器直接估计未标记样本的后验概率值,选择最难被分类器区分的样本,但传统的基于最大熵的样本选择策略无法量化每个样本对分类器的重要性。为此,本文使用加权算法对样本进行重要性标注,形成一种基于信息熵加权(Information entropy weighting,IEW)的主动学习算法。对整个未标注样本集的样本信息熵Z-score规范化[13]后,每个样本的加权系数计算定义为

式中:H(x)为样本x的信息熵,n为未标注样本集的样本个数,IEW(x)表示基于信息熵计算的每个样本权重,xi∈Du代表未标注样本中的第i个样本。
算法2Information entropy weighting for active learning
输入:初始训练集D0,预期分类器查准率τ,每次迭代采样文本数c
输出:分类模型f
1.初始化已标注训练集DL=D0,待标注样本集Dcandidates=∅
2.f0←learn(D0)
3.whilef.auc>τandDuis not NULL
4.Dcandidates←{argmaxx∈DuH(x)}c
5.Du.del(xi∈Dcandidates)
6.for eachxi∈Dcandidates
7.DL←IEW(xi)*xi
8.f←learn(DL)
9.returnf
算法2的时间复杂度为O(Miter(m-c*Miter/2)),其中Miter为最外层迭代次数,m为文档的个数。
综上所述,本文提出了一种面向文本分类的不确定性主动学习算法。首先,在挑选初始训练集时引入MSDL算法,基于密集度度量选择具有代表性的样本;接着,根据IEW算法按照最大熵策略挑选待标注样本,并计算每个样本的权重,将带有权重的样本加入到模型中训练,在保证目标样本具有不确定性的基础上,又可减少模型训练的迭代次数。
2 实验验证
2.1 实验环境及数据
2.1.1 实验环境
操作平台:Win10;CPU:Intel双核4.0 GHz;内存:16 GB;硬盘:1 TB;开发语言:Python。
2.1.2 实验数据
数据集采用Sogou实验室提供的分类语料库[14],该数据集在文本分词、新闻分类等任务中经常作为标准数据集,实验中采用的文本为财经、健康、教育、军事、体育5大类,每个类别中有2 000篇文档,共10 000篇文档。
2.1.3 实验评价
评价分类方法常用查准率(P)和查全率(R)。查准率用于表示分类的正确性,即检测出分类文档中正确分类的文档所占的比率;查全率表示分类的完整性,即所有应分类的文档中被正确分类的文档所占的比率,表达式分别为

同时为了综合评价分类效果,使用F值

2.2 实验步骤
为了证明本文所提的MSDL-IEW算法的有效性,本文对比了传统的主动学习算法。对原始样本进行预处理,包括清洗数据、分词和去停用词。选用朴素贝叶斯分类器为基本分类器。MSDL-IEW中使用MSDL算法选择出初始训练集,对分类器进行训练,使用IEW算法对未标注样本进行样本选择并加入权重项,标注后加入到训练集中再次训练,依次迭代。实验运用五折交叉验证方法来选取模型参数,实验中的对比方法包括:
(1)Random+ME。在样本集中随机选择出初始训练集,对分类器进行训练,使用基于最大熵(ME)策略采样,将样本直接进行标注后加入到训练集中再次训练,依次迭代。
(2)MSDL+ME。在样本集中使用MSDL算法选择出初始训练集,对分类器进行训练,使用基于最大熵(ME)策略采样,将样本直接进行标注后加入到训练集中再次训练,依次迭代。
(3)Random+IEW。在样本集中随机选择出初始训练集,对分类器进行训练,使用IEW算法对未标注样本进行样本选择并加入权重项,标注后加入到训练集中再次训练,依次迭代。
2.3 实验结果分析
为了验证本文提出的MSDL-IEW算法是否可达到减少人工标注样本的目的,在上述数据集上进行实验,分别从P、R、F值进行分析,结果如图2所示。
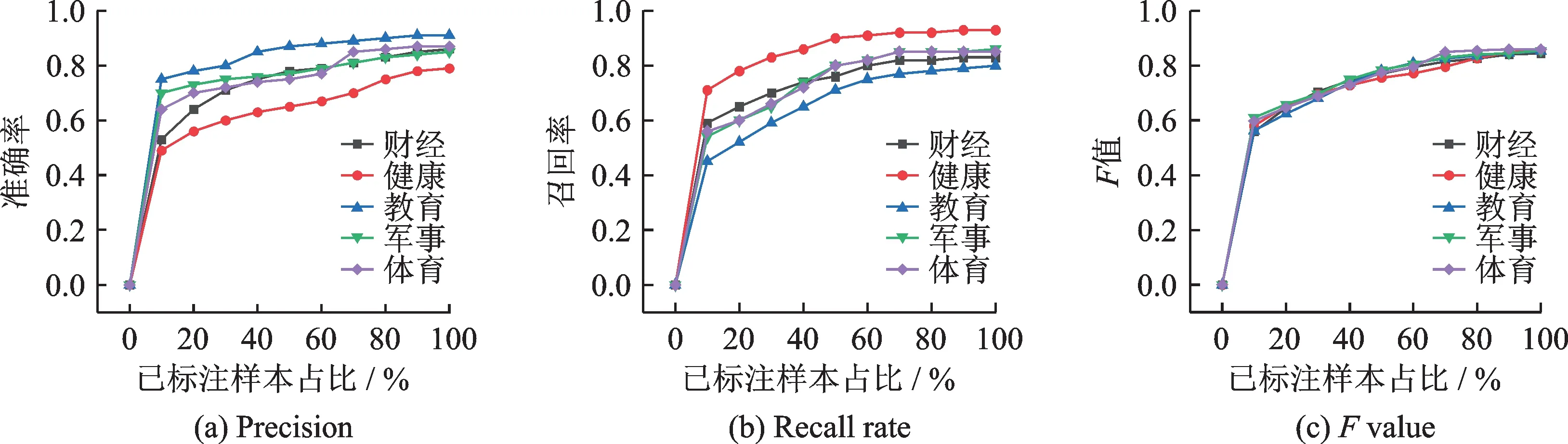
图2 已标注样本数量对查准率、召回率、F值的影响Fig.2 Influence of the number of labeled samples on the precision,recall rate and F value
从图2可以看出,随着标注样本数量的增加,文本分类的各项评估指标逐渐升高,在标注70%样本之后,各指标不再呈明显上升趋势,说明本文提出的MSDL-IEW主动学习算法可有效地减少人工标注的代价。为了进一步分析本文算法的性能,进行对比实验,在标注样本占比为70%时,各对比算法的评估指标结果如表2所示。
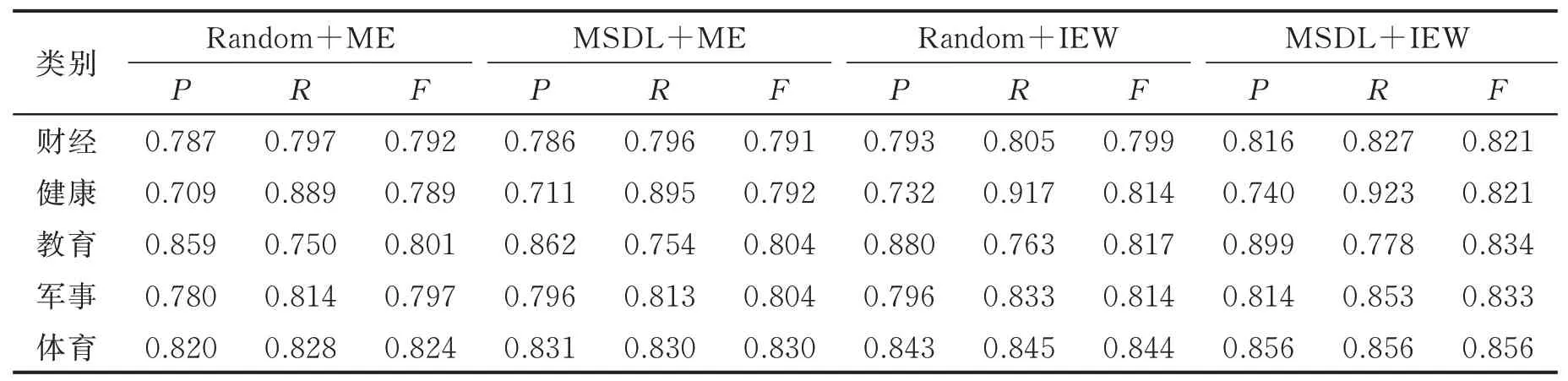
表2 标注样本为70%时各算法的实验结果对比Table 2 Comparison of experimental results of each algorithm when the labeled sample is 70%
由表2可以得出:本文提出的算法在查准率、召回率和F值3个指标上相较于其他算法都表现更好。从Random+ME和MSDL+ME的对比实验中,可看出MSDL相较于传统随机构建初始训练集的方式在各个评价指标上均表现得更为优异,说明MSDL样本选择算法可有效地避免孤立点样本对算法的影响;在Random+IEW和Random+ME的对比实验中,由于传统的Random+ME算法采用基于最大熵的样本选择策略,无法量化每个样本对分类器的重要性,导致模型收敛速度慢,然而本文提出的Random+IEW算法使用加权方式对样本进行重要性标注,这种基于信息熵的样本加权方式可有效地加快模型训练。将MSDL-IEW与传统的主动学习策略Random+ME对比,结果表明MSDL-IEW算法可有效提高算法的查准率和召回率。综上所述,本文提出的MSDL-IEW算法相比于传统主动学习算法更具优势,可以改善主动学习算法中训练集代表性不足的问题,提高分类效果。
3 结束语
本文针对样本标注代价高的问题,提出了一种面向文本分类的不确定性主动学习方法,首先设计MSDL算法选取初始训练集,即通过LDA算法对样本密集度进行计算,从样本集的群体中选择密集度高的部分样本作为初始训练集,建立初始分类器,可保证初始分类器具有一定的代表性;接下来为了加快模型训练速度,本文引入了基于信息熵的样本加权策略,实验表明,IEW策略相较于传统最大熵样本选择策略更优;最后,实验结果表明,本文所提出的算法在查准率、召回率和F值3个指标上均有提升,融合了代表性和不确定性,从而提高了分类器的性能,使用70%的标注样本可接近全部标注样本的训练结果,可有效减少标注样本的成本。
