一种高效的车体表面损伤检测分割算法
2021-04-17林少丹陈志德朱可欣
林少丹,冯 晨,陈志德,朱可欣
(1.福建船政交通职业学院信息与智慧交通学院,福州350007;2.福建师范大学数学与信息学院,福州350007;3.台湾中山大学资讯工程系,高雄80424)
引 言
车体表面损伤检测可以用于车辆损害评估。传统车辆修复主要依赖于人工识别,在面对车辆轻微的划痕、裂缝或部分形变等车体表面的损伤时,完整检测的难度较大、效率较低。本文研究一种更为高效的车体表面损伤检测分割算法,能够大量应用到汽车车体表面美容、维修、车辆保养和车辆鉴定等涉及车体表面检测与识别方面的应用。
在物体目标图像识别领域,基于卷积神经网络的目标检测已经超越传统目标检测方法,成为当前目标检测的主流方法。单阶段目标检测将提取和检测合二为一,直接得到物体检测的结果,提高算法的效率,如YOLO、SSD等算法。而现有的实例分割算法,如:Fast-RCNN、Mask-RCNN等采用多阶段语义分割网络提高分割精度,但在实际车体表面损伤检测过程中,由于视角、遮挡和姿态等因素导致算法可用性受限。因此设计高准确率、高效率的车体表面损伤检测分割算法具有重大意义。
近年来,随着实例分割算法的不断推出,已有诸多研究将深度学习算法迁移至车辆检测领域中。Chen等[1]使用YOLO的7个卷积层来检测单个类,解决了车牌检测问题,该算法车辆检测的准确率达到约98.22%,车牌识别的准确率达到78%;Hu等[2]通过多任务学习在两个CNN中利用多种判别线索,提出了一种细粒度车辆类型识别的方法,将多个线索进行组合输入到卷积神经网络;吴迪等[3]通过对颜色表示方法的深入研究,使用特殊的颜色空间合并与分解方法,提出了在室外正常光照条件下基于支持向量机的车辆颜色识别的方法;Zaarane等[4]针对现有智能交通系统中视频车辆车型识别方法存在的误检率高、效率低的问题,提出一种基于二维离散小波变换(Two-dimensional discrete wavelet transform,2D-DWT)的两阶段实时车辆检测算法;王威等[5]提出了一个基于Mask-RCNN目标定位及掩膜生成算法;苏欣欣等[6]针对传统无损检测技术在罐车内壁裂纹检测中效率低、抗干扰能力差等问题,提出一种基于卷积神经网络的热成像裂纹识别方法;Lu等[7]提出了一种基于YOLO网络的视频对象实时检测算法,通过图像预处理消除图像背景的影响,训练快速的YOLO模型进行目标检测,获取目标信息,减少了参数的数目,大大缩短了目标检测的时间;叶玉婷等[8]提出了一种基于侧面轮廓的实时车型分类系统,该分类系统分为3个部分:侧面轮廓处理、车型模板建立和实时车型匹配;Jamtsho等[9]提出使用YOLO的实时车牌本地化,消除了看上去与LP相似的假阳性,在LP定位之前执行了车辆检测,单个卷积神经网络的整体平均精度为98.6%,而车辆和LP的训练损失为0.0231;Zhang等[10]提出了一种基于轻量级CNN的车辆颜色识别方法,结果表明该方法识别率提高了0.7%以上,达到了95.41%,而特征向量的维数仅为18%,内存占用只有0.5%;Fu等[11]提出了一种新的网络结构——基于残差学习的多尺度综合特征融合卷积神经网络(Multiscale comprehensive feature fusion convolutional neural network,MCFF-CNN),用于颜色特征提取;Huynh等[12]提出了一种基于准自主视觉的方法来检测关键连接中的螺栓松动,并提出了一种基于区域卷积神经网络(Regional convolutional neural network,RCNN)的深度学习算法,以自动检测并裁剪连接图像中的可能螺栓。
在实际场景下的车体表面损伤检测过程中,所拍摄的多数相关图像存在背景复杂、车体表面形状差异较小以及拍摄角度造成相似度高等问题,因此在进行损伤检测时,传统的模型仍存在以下两方面问题:(1)效率较低,对于实际场景下的应用带来了诸多的不便;(2)目标查准率相对较低,检测效果较差。为了解决上述问题,本文提出了一种基于YOLACT++的车体表面损伤检测算法,通过对YOLACT++进行改进,生成一种单阶段语义分割网络。
1 相关工作
2019年Bolya等[13]首次提出一种实时的实例分割算法——YOLACT,在MS-COCO数据集上检测帧率达到33帧/s的性能,作者通过实验对比研究了不同主干网络架构、原型数量以及图像分辨率等所导致的速度与性能之间的差异,并在此基础上提出了一种新颖的FAST-NMS方法,在性能损失可以忽略不计的情况下,比传统NMS方法快12 ms。在YOLACT基础上,Bolya等[14]提出了YOLACT++,它通过将可变形卷积合并到骨干网络中,并增加了一个快速掩码的评分计算分支——MASKIOU-NET,YOLACT++模型可以在MS-COCO数据集上以33.5帧/s的速度实现34.1 map,在保持准确率的同时也提升了算法的实时性。
1.1 YOLACT++模型
YOLACT++主要由BackBone、PedictionHeader、ProtoNet和SemanticSegmentation 4个部分组成,采用3通道550像素×550像素的图像作为输入到主干网络,通过FPN(Feature Pyramid network)输出到PedictionHeader和ProtoNet两个并行处理分支。ProtoNet分支使用全连接网络生成1组原图像大小的原型掩膜,并与MaskIOU-Net生成的掩膜特征向量结合生成目标原型掩膜。PredictionHeader分支用于预测实例检测时生成的每个anchor的掩膜系数的向量、分类向量和anchor-box向量。最后,经过Fast-NMS处理后,将2个分支进行线性组合进行语义分割并生成目标掩膜。实验表明,将原型掩膜与掩膜模板系数线性组合可产生高质量的目标掩膜。
YOLACT++利用擅长产生语义向量的全连接层和擅长产生空间相干掩膜的卷积层来分别产生“掩膜系数”和“原型掩膜”,因为原型掩膜和掩膜系数都是独立计算的,所以主干网络的计算开销主要来自合成步骤,通过这种方式,可以在特征空间中保持空间一致性,同时使模型保持了单阶段的高效性,提高了算法的实时性,因此主干网络的优化是提升模型计算速度的有效优化方法。
1.2 YOLACT++的Loss函数
YOLACT++损失函数主要包含分类损失、边界框回归损失和Mask损失3部分损失函数相加所得,即有

式中:Lclass、Lbox和Lmask分别为分类损失函数、预测框损失函数和掩膜生成损失函数,其中掩膜生成损失函数由通过取得目标原型Mask与相对应的原型Mask系数相乘,加入非线性激励函数后,YOLACT++采用预测的Mask和真实的Mask两者像素集的二值交叉熵生成Mask的损失函数值,其求导过程为
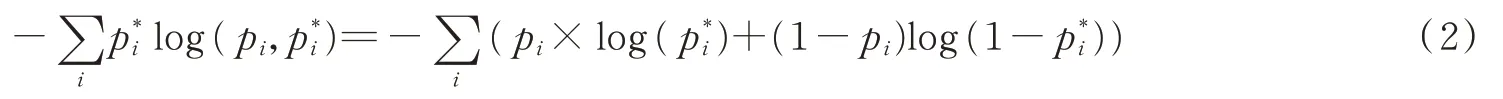
式 中:pi为通过预测的Mask值;p*i为原数据集中标注的Mask值(实际的Mask值)。生成Mask的损失值通过非线性激励函数sigmoid[15]后所得,即

通过激励函数sigmoid得到Mask的损失值,其sigmoid激励函数为
sigmoid函数曲线如图1所示。
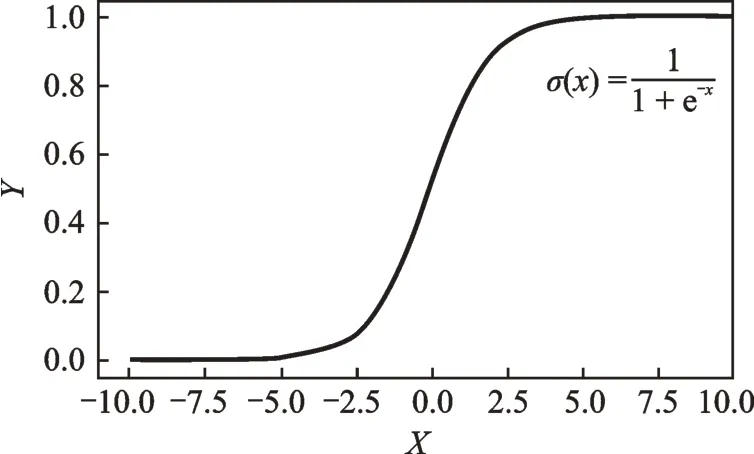
图1 Sigmoid激励函数曲线Fig.1 Sigmoid activation function curve
2 基于改进YOLACT++的车体表面损伤检测
本文为解决车体表面的损伤检测的精度和效率问题,提出了一种改进的YOLACT++的车体表面的损伤检测模型,算法结构如图2所示。在该算法中采用了EfficientNet作为主干网络,使得YOLACT++网络层次变深,提高了效率和精度,同时为解决Mask生成梯度损失值较高、Mask精度较低等问题,通过对Mask损失函数进行优化,降低梯度损失值并提高生成Mask精度。
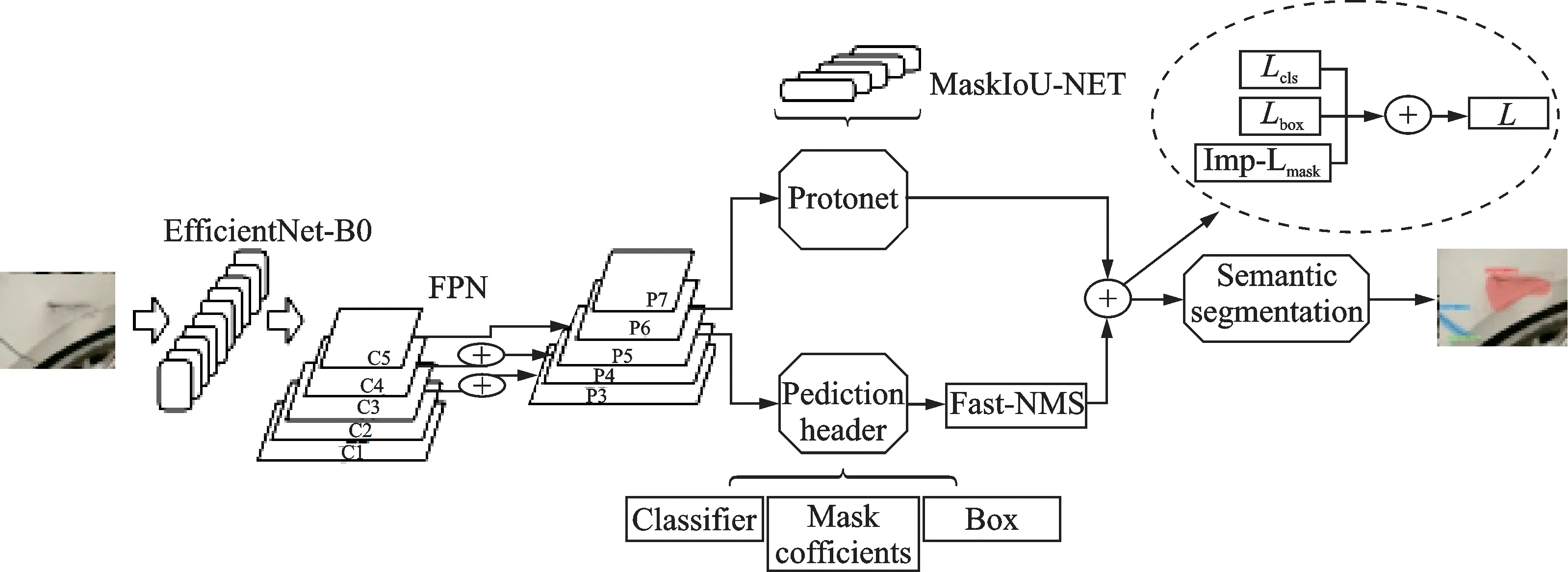
图2 基于改进YOLACT++的车体表面的损伤检测Fig.2 Damage detection of car body surface based on improved YOLACT++
2.1 主干网络优化
在对车体表面损伤目标定位的YOLACT++结构中,根据越深的网络效果越好原则进行主干网络选择,采用EfficientNet-B0+FPN作为用于特征映射的基础主干网络,选择C1、C2、C3作为与EfficientNet的对接层,并设置每个层相应输入通道数,增加anchors数量,从而提高目标检测的准确率。
EfficientNet[16]提出了尺度均匀缩放所有维度的方法,根据图像的深度、宽度、分辨率形成有效复合系数φ,动态调整网络深度和宽度,定义如下:depth:d=αφ;width:w=βφ;resolution:r=γφs.t.α·β2·γ2≈2,α≥1,β≥1,γ≥1。
本算法采用EfficientNet的特性,形成适用YOLACT++的主干网络的深度和宽度参数,从而有效地提升YOLACT++的效率和准确性。实验中需要注意的是计算模型所对应的接入层数及参数,即有
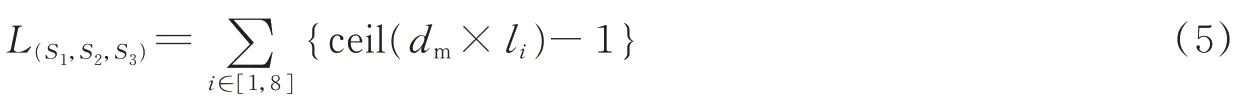
式中:L(S1,S2,S3)代表3个阶段对应的层数;dm代表模型的深度系数;li代表层数;ceil代表取整函数。可以通过宽度系数计算出各模型的输入通道数,即

式中:Im代表模型输入通道数;wm代表模型的宽度系数;b为EfficientNet-B0的输入通道数320,作为一个基线系数。
通过式(5,6)计算得到在YOLACT++时选择的接入层为[4,10,15],以及所需的EfficientNet-B0的EfficientNet深度系数、宽度系数分别为1.0和1.0,输入通道数为320。
2.2 Loss函数改进
YOLACT++采用sigmoid函数作为二值交叉熵的激励函数的优点在于,它的输出映射在(0,1)内单调连续,适合用作输出层且容易求导,但是因为软饱和性,一旦输入落入饱和区,导数就会变得接近于0,很容易产生梯度消失[17]。当预测值与实际值相差较大时,采用交叉熵损失函数造成误差增大。
本算法采用交叉熵与L1范数、L2范数相结合的梯度计算方式,主要是针对当预测框与ground truth差别过大时,梯度值不至于过大;当预测框与ground truth差别很小时,梯度值也能够足够小。针对输入x<1的部分使用L1范数(式(7)),使梯度更平滑且求导方便,针对输入x>1的部分使用L2范数(式(8)),有效地避免梯度爆炸,减少离群值的出现[18]。
计算Loss前必须先设置anchors的正、负样本标定规则,假设anchor对应的预测框与GT的重叠度IoU>0.7,标记为正样本;假设anchor对应的预测框与GT的重叠度IoU<0.3,标记为负样本;余下的样本既不属于正样本也属于负样本,负样本不参与最终训练。
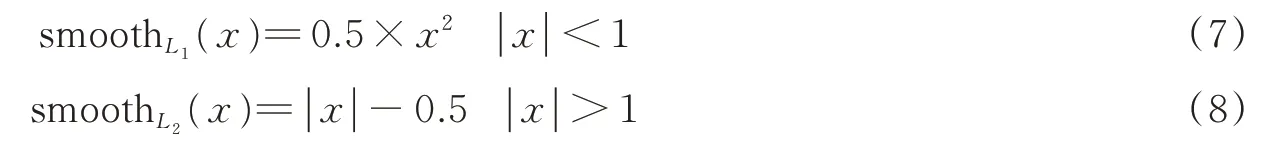
不妨定义Mask定位的损失函数为Lmask_loc,预测平移缩放参数为tu,真实平移缩放参数为v,通过2个参数的比较来评估检测框定位的损失率。

在车辆表面的掩膜分类中仍存在两个缺点:首先所有像素在评估损失函数中起着相同的作用,这可能会忽略pi的特殊位置信息。其次,原损失函数更适合平衡正例/负例的情况,而大多数车辆划痕的数据集可能无法满足此要求。针对上述问题,本算法采用改进的交叉熵损失函数来考虑像素空间位置的影响以及严重的不平衡正负示例的影响。改进Mask的损失率定义为
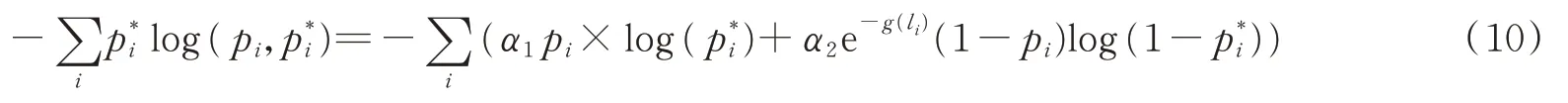
式中:pi表示预测的第i个锚框是一个目标物体的概率,发现目标时pi为1,否则pi为0。g(li)为约束系数,当li=0时,g(li)=0;当0<li<T时,;当li>T时,,li表示第i个
像素与划痕的欧氏距离,T=0.3max{li}为像素与划痕距离的阈值。α1、α2为正负样本的比例。
最后通过式(10)和式(9)得到最终的损失,即有
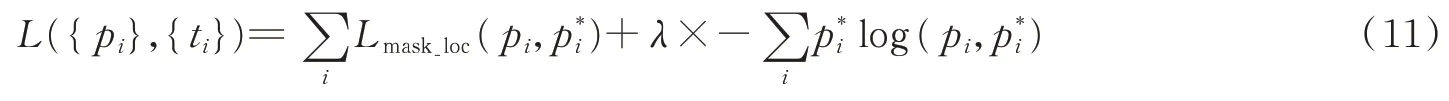
式中:ti为对应于正锚点的GT坐标;Lmask_loc为预测边界框和GT框的smoothL(1,2)损失函数。Mask的总损失率归一化由smooth_loss、binary_cross_entroy和λ(平衡权重)合并得到[19],本文将λ设置为0.5,这样设置可以使Mask的两部分loss值保持平衡,最后通过训练获得一系列Mask特征区域。
2.3 车体表面损伤目标定位解决方案
本节介绍了车体表面损伤目标定位问题的解决方案[20],过程如图3所示,主要分为6步:
(1)图像输入。通过视频采集生成大小为550像素×550像素的车体表面损伤区域图像(图3(a)),输入到主干网络中进行特征提取,并将提取的特征张量送入PedictionHeader和ProtoNet两个并行处理分支中处理。
(2)生成原型掩膜。通过ProtoNet对特征区域进行一系列卷积操作后生成原型掩膜(图3(b))。

图3 车体表面损伤目标定位过程Fig.3 Target location process of vehicle body damage
(3)生成原型掩膜系数。通过PedictionHeader对一系列原型掩膜生成对应掩膜系数。
(4)原型掩膜提取。通过原型掩膜张量与掩膜系数计算出最优的原型掩膜(图3(c))。
(5)目标分割。结合原型掩膜的目标定位,分割出损伤区域范围。
(6)生成目标掩膜。在分割出的目标上生成相应的掩膜(图3(d)),从而实现车体表面损伤区域识别定位的过程。
3 实验结果
3.1 数据集准备
本实验所用数据集是利用爬虫程序从网络上爬取的车辆损伤图片,由于YOLACT++对输入图片大小要求,将数据集图片改成550像素×550像素大小,并使用LabelMe对图像中的车体表面损伤目标所在的区域进行标注。LabelMe是由麻省理工学院计算机科学与人工智能实验室(MIT CSAIL)创建的一个开放的注释工具[21]。通过LabelMe软件,能够方便地完成对图像中各种车体表面损伤区域目标边界的标注并保存图像。实验前首先使用LabelMe制作MS-COCO标准数据集,其中包括训练集30 000张,验证集15 000张。
3.2 实验参数
在本实验中训练周期设置为127次,每周期内迭代100步,训练步数通常根据数据集规模大小而定。采用上述改进的YOLACT++模型进行大规模的数据集训练,需要耗费大量的内存资源和时间,对硬件要求较高,用于训练的硬件环境参数为2颗CPU:Intel(R)Xeon(R)Gold-6150 72核,内存1 TB,3颗GPU,NVIDIA tesla v100;软件环境采用Python3.6,pytorch1.1,cuda10.1。上述软硬件环境结合改进后的YOLACT++网络进行训练,较之前的YOLACT++架构在训练所用时间及梯度损失率等方面均有一定优化。
3.3 主干网络优化分析
基于原算法复杂的主干网络带来的效率问题,本算法对主干网络进行了优化,并对掩膜系数生成、原型掩膜生成以及掩膜生成3个过程中的激励函数进行改进,分别进行训练。首先,在不同主干网的对比实验发现,主干网络的更换提高了整个模型对目标识别平均准确度,在实验中分别采用ResNet101/50、DarkNet53、VGG16、MobileNetV2和EfficientNet等作为模型主干网络进行训练。当主干网络设置为EfficientNet时,有效地降低了YOLACT++的网络规模,同时采用加大训练规模和调整学习率等方法,有效地解决了大型网络的梯度冻结问题。在本算法中将EfficientNet-B0作为主干网络,生成模型总大小为46.1 MB,小于采用ResNet-50的129.9 MB,EfficientNet-B0的参数大小为10.93 MB,小于ResNet-50的20.2 MB。经过127个周期的训练,达到35.57帧/s,且还未完全收敛。值得注意的是,生成的YOLACT550++-EfficientNet-B0模型大小仅为46.1 MB。表1为各主干网络训练参数对比。
3.4 损失函数优化分析
3.3节中分析了采用EfficientNet+FPN作为主干网络所带来的模型压缩和训练效率上的优势,但主干网络的更换也使得损失值升高。为解决这一问题,本文采用改进的损失函数降低梯度损失值,提高了检测效果和精度。改进前后的梯度损失值对比如表2所示。
从表2中可以看出,基于改进的损失函数训练模型梯度损失值均小于原损失函数的梯度损失值,同时表3给出了损失函数改进前后的平均精度均值(Mean average precision,mAP)对比。实验结果表明,改进的损失函数对于模型精度的提升较为明显。
同时,与传统的主干网络相对比,损失函数的改进使得本模型对Mask的梯度损失率的优化效果更为显著,生成梯度损失走势,其对比图如图4所示。从图4中可以看出,改进实验模型所产生的Mask梯度损失值最低,效果更好。

表1 不同主干网络YOLACT++模型参数表Table 1 YOLACT++model parameter table of different backbone networks

表2 改进前后YOLACT++梯度损失值对比表Table 2 Comparison table of YOLACT++gradient loss befor and after improvement

表3 采用不同损失函数的mAP比较表Table 3 Comparison of mAPs using different loss functions
表4给出了改进的YOLACT++与其他不同主干网络的YOLACT++梯度损失值,比较结果展示了本实验在Mask上损失值最低,优化效果较为显著。
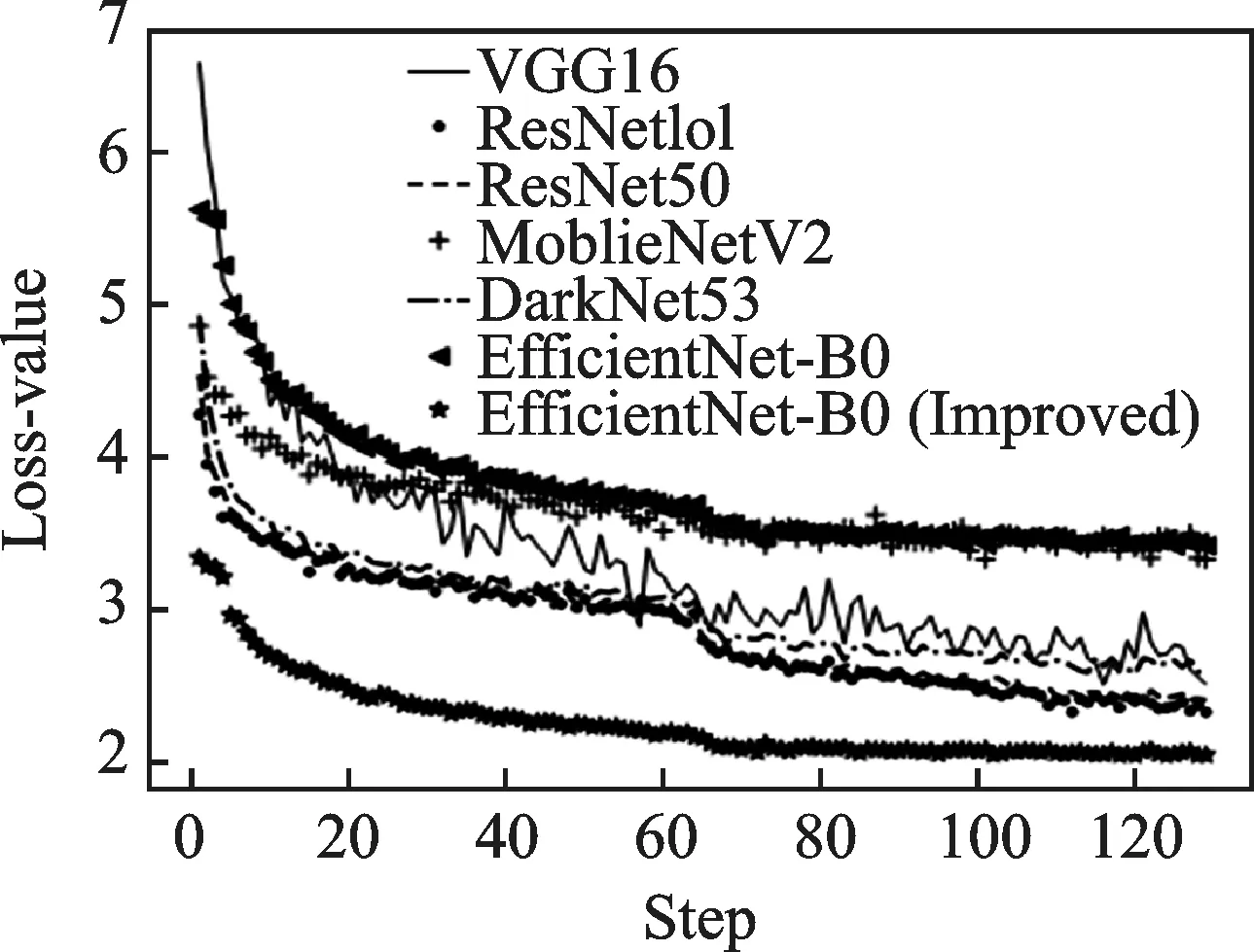
图4 Mask生成梯度损失率走势对比图Fig.4 Comparison of trend of gradient loss rate generated by the Mask
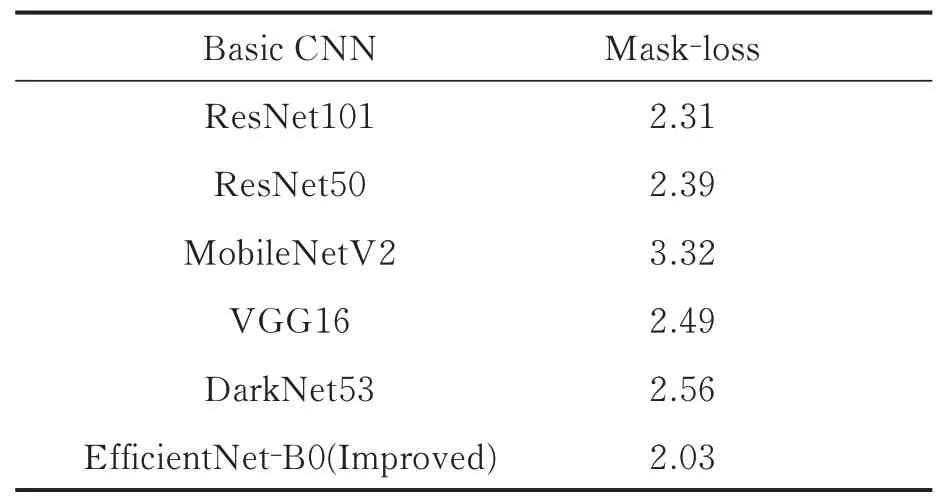
表4 不同主干网络的Mask损失值对比表Table 4 Mask loss comparison of different backbone networks
另外,在训练中将主干网络VGG16、MobileNetV2和EfficientNet-B0分别与MaskIOU-Net生成的方法相结合,并对训练结果的mAP进行对比,比较结果见表5。
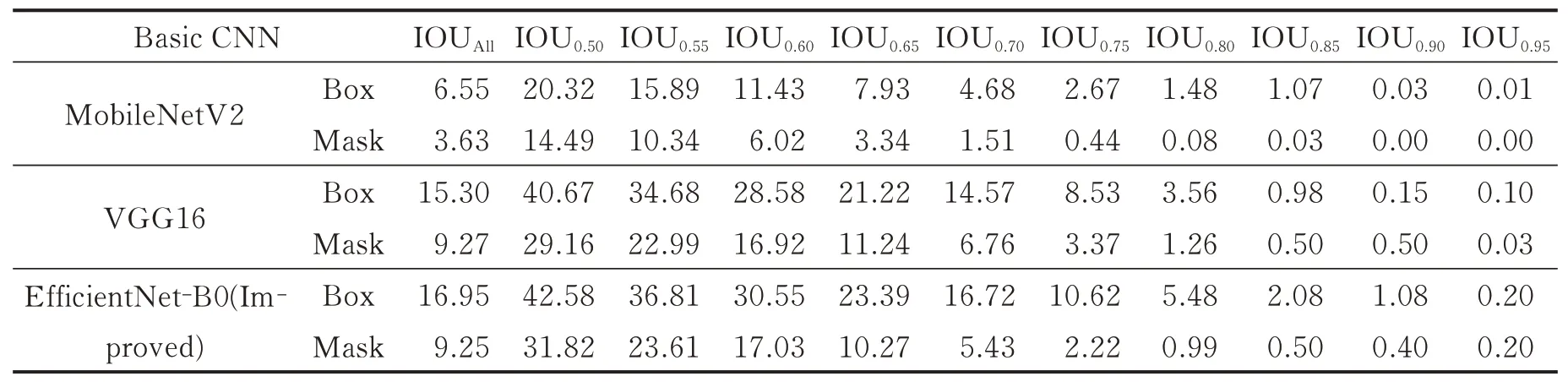
表5 采用不同基础主干网络的mAP比较表Table 5 Comparison of mAP using different basic backbone networks
由表5可见,采用EfficientNet跟移动端的主流模型MobileNetV2和VGG16相比,识别精度有了显著提升。说明本模型在保证精准的识别效果的前提下,进一步削减了模型的规模,并显著地提高了模型的识别速度。特别是在移动端的应用上,比其他模型更快速、更精确,有着很好的应用前景。
3.5 查准率分析
从数据集中提取了1 000张图像作为测试集,将本算法与其他方法的多组对照实验结果进行比较。评估指标主要包括查准率(Precision)以及召回率(Recall),利用这两个指标来衡量模型对车体表面损伤目标定位效果,表达式为

式中:TP代表被期望为正样本的,实际识别也为正样本;FP代表期望为正样本,但实际识别为负样本。TP取准确定位出车体表面损伤目标的图像数,FP取没有定位出车体表面损伤目标或定位出部分车体表面损伤目标的图像数,FN取完全没有定位出车体表面损伤目标,通常采用测试精度低于某个比较低阈值的图像数。
当阈值取0.80时,TP为识别率≥0.80的数量,FP为0.75≤识别率≤0.8的数量,FN为识别率<0.75的数量;当阈值取0.75时,TP为识别率≥0.75的数量,FP为0.70≤识别率≤0.75的数量,FN为识别率<0.70的数量;根据以上取值范围,对改进前后的方法进行测试,实验采用低于0.75测试精度的作为FN,图5为不同方法测试查准率对比。

图5 不同方法测试查准率对比Fig.5 Comparison of test accuracy of different methods
从图5可知,采用EfficientNet-B0+FPN+MaskIOU-Net方法生成的模型测试查准率达76%,比采用MobileNetV2、VGG16作为基础主干网络的模型测试查准率提高了3%~13%,说明查准率已超过一些轻量级主干网络。
3.6 效率分析
通过与现有的实例分割模型的实时性和准确性对比可知,本算法不仅可以获得较高的查准率,同时也降低了模型的响应延迟,保持了实时性,如图6所示。从图6中可以看出,改进后的YOLACT++检测帧率达到35.57帧/s,相较于其他模型速度提升显著,而Mask mAP比其他3个模型相差无几。因此,可以证明改进后的YOLACT++具备快速分割定位的特点。将本算法运用在汽车整形维修、车辆快速理赔、二手车市场以及二手车抵押贷款等领域具有重要的理论价值和应用价值。
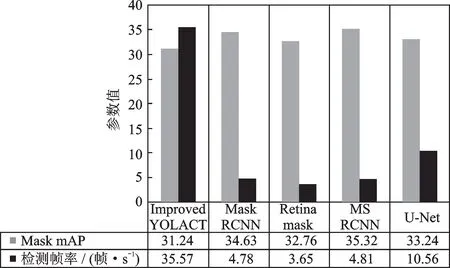
图6 不同模型实时性参数对比Fig.6 Comparison of real-time parameters for different models
4 结束语
针对实际场景中车体表面损伤的目标检测效率与精度问题,本文改进YOLACT++中对原型掩膜生成的激励函数、掩膜系数生成的激励函数以及掩膜生成的激励函数,提出一种基于改进的YDLACT++的车体表面损伤检测算法。通过与ResNet-101、ResNet-50、VGG16、MobileNetV2以及EfficientNet-B0五种基础主干网的实验对比,证明了改进的YOLACT++算法对车体表面损伤识别的准确性和检测效率。同时测试表明,利用EfficientNet-B0作为主干网络,结合能加快掩膜生成的MaskIOUNet,并改进掩膜生成损失函数的YOLACT++模型,可以大幅提高检测帧率,有效地提高了目标识别和定位的实时性。但是模型准确率仍有待提高,在后续的工作中将采用更高效的主干网络,结合采用更大样本库的方法进一步提升模型的准确率。
