Deep Learning for EMG-based Human-Machine Interaction: A Review
2021-04-16DezhenXiongDaohuiZhangMemberIEEEXingangZhaoMemberIEEEandYiwenZhao
Dezhen Xiong, Daohui Zhang, Member, IEEE, Xingang Zhao, Member, IEEE, and Yiwen Zhao
Abstract—Electromyography (EMG) has already been broadly used in human-machine interaction (HMI) applications.Determining how to decode the information inside EMG signals robustly and accurately is a key problem for which we urgently need a solution. Recently, many EMG pattern recognition tasks have been addressed using deep learning methods. In this paper,we analyze recent papers and present a literature review describing the role that deep learning plays in EMG-based HMI.An overview of typical network structures and processing schemes will be provided. Recent progress in typical tasks such as movement classification, joint angle prediction, and force/torque estimation will be introduced. New issues, including multimodal sensing, inter-subject/inter-session, and robustness toward disturbances will be discussed. We attempt to provide a comprehensive analysis of current research by discussing the advantages, challenges, and opportunities brought by deep learning. We hope that deep learning can aid in eliminating factors that hinder the development of EMG-based HMI systems.Furthermore, possible future directions will be presented to pave the way for future research.
I. INTRODUCTION
ELECTROMYOGRAPHY (EMG) is the recording of electric signals generated during muscle contraction.EMG contains a large amount of information and reflects the movement intentions of a subject. EMG can be viewed as the summation of the motor unit action potential (MUAP) with noise, and can be decomposed into motor unit (MU), which are the minimum entity of the human muscle [1]. It can be classified into two classes, i.e., surface EMG (sEMG) and intramuscular EMG (iEMG), according to the electrodes’location. The former is collected from the surface of human skin, while the latter is collected from needle electrodes planted inside the human muscle. sEMG has been widely used for hand gesture classification [2], [3], silent speech recognition [4], [5], stroke rehabilitation [6], [7], robot control [8],[9], and other applications, mainly because it is cheap and easy to collect and it provides a method for more natural human-machine collaboration.
Many approaches, such as video, inertial measurement units(IMU), and EMG, can be used to decode the movement intention of humans. The video-based method requires relatively higher computational resources, and it can be easily affected by environmental factors such as light change,background noise, and camera position. The IMU-based method can estimate joint angles while moving with high precision. For example, the Noraxon motion capture system1https://www.noraxon.com/estimates the human joint angle using an IMU attached to the body. However, it has a larger time delay compared with EMG signals, which occur approximately 50-100 ms earlier[10], before the action happens. Moreover, it is invalid under some conditions, such with rehabilitation training of patients after stroke or prosthetic hand control of amputees, because it cannot predict actions when the limbs do not move. In contrast, an EMG provides a method for obtaining a more natural and fluent human-machine interaction (HMI) that reflects human intent physiologically.
In [11], a review of EMG pattern recognition algorithms was presented. According to this paper, the typical EMG pattern recognition pipeline can be divided into three substages: 1) Preprocessing. The EMG data will be filtered to remove noise and keep the useful information unchanged. 2)Feature extraction. Time, frequency, or time-frequency domain features will be extracted for intention recognition. 3)Classification or regression. Feature extraction is of vital importance because it determines the ceiling of the recognition performance, which leads to a rise in feature engineering, which aims to provide a feature set that is optimal for representing the information from EMG to achieve better performance. Nevertheless, it is a very time-consuming task that requires professional knowledge to find the optimal feature set, which thus promotes great interest in deep learning.
Deep learning belongs to representation learning, which aims to create a better representation from input data using multiple layers of processing blocks such as neural networks[12]. It has achieved many benchmark achievements in computer vision [13], speech recognition [14], machine translation [15], and so on. Unlike machine learning-based algorithms, which need to extract features from input data for classification or regression tasks, deep learning can extract high-level abstract features automatically from input data while using multiple hidden layers. The whole process is usually end-to-end, which is quite convenient in multifarious applications.
In recent years, the deep learning-based scheme has been widely used in EMG recognition. Many pieces of research have applied deep neural networks for EMG processing.There are some survey papers related to deep learning-based EMG pattern recognition tasks. Buongiorno et al. [16] wrote a brief survey about deep learning in EMG processing, which included tasks such as hand gesture recognition, sleep stage identification, speech, and emotion classification. This paper mainly focuses on EMG-based classification applications.Phinyomark et al. [17] discuss the problem of EMG processing under the rapid development of big data and deep learning. Faust et al. [18] review deep learning in health-care applications with biomedical signals, including EMG, EEG(Electroencephalogram), ECG (electrocardiogram), and EOG(electrooculogram). Mahmud et al. [19] summarize the application of deep learning methods, reinforcement learning methods, and deep reinforcement learning in the biological field with biomedical signals including EEG, ECG, and EMG.Deep learning has been broadly used in biomedical signal pattern recognition in fields including EEG, ECG, EMG, etc.For the issue of deep learning-based EMG pattern recognition,previous reviews, including [16]-[19], mainly concern movement classification tasks. Other sub-areas including continuous angle estimation, force/torque estimation,multimodal sensing, inter-session/subject, robustness, and applications are not concerned. One of the motivations of this paper is to provide a comprehensive map of current research involving deep learning-based EMG recognition for HMI tasks. Another motivation is to distinguish the role of deep learning in EMG-based HMI tasks from other biomedical signals like EEG or ECG to analyze the benefits deep learning brings to us in EMG-based HMI and how it can help us in the future.
This paper attempts to provide a comprehensive review of deep learning in EMG pattern recognition for human-machine interfaces. By illustrating typical applications, such as movement classification, joint angle prediction, and so on, this study attempts to present penetrating analyses of the functions of deep learning in EMG-based HMI. It also analyzes the challenges and the corresponding solutions to make up for disadvantages, and discusses the chance that it will provide us more stable and accurate HMI systems. The primary contributions of our article can be summarized in the following parts:
1) The general scheme and basic knowledge needed for deep learning in EMG-based HMI will be introduced. Typical processing schemes, frequently used network structures, and preprocessing methods will be introduced in general. An overview of general processing procedures will be provided and compared with traditional methods.
2) A thorough review of EMG-based HMI tasks will be introduced. We will talk about three tasks, namely, discrete movement classification, joint angle estimation, and force/torque estimation.
3) New topics, such as inter-session/subject, electrode shift,multimodal sensors fusion, will be discussed to convey the latest progress. Applications in physical systems will also be considered.
4) The advantages, challenges, and opportunities to solve questions in EMG recognition through deep learning will be summarized in Section VI. Moreover, four future directions that we believe are important for future development will be covered.
The remainder of this article is organized as follows:Section II covers the basic knowledge of deep learning-based decoding approaches. Section III introduces EMG-based tasks that can be addressed with deep learning methods. Section IV presents new hot-spot topics in this field. Section V covers applications in real systems. Section VI presents a discussion that is relevant to the main issues in this paper. Section VII gives the conclusions of this article and the prospects for future work.
II. BASIC KNOWLEDGE AND SCHEME
This section discusses deep learning-based EMG recognition procedure, which mainly includes three parts:deep neural networks widely used in EMG decoding, normal processes of EMG preprocessing, and the whole scheme.
A. Basics of Deep Learning
Neural networks have a long history that can even be traced back to the 1940s. Since then, many new network structures,such as multiple layer perceptron (MLP), recurrent neural networks (RNN), and convolutional neural networks (CNN),have been proposed for fitting the input data with the corresponding labels. Recently, deep neural networks have shown outstanding performance in many research areas, as described in [12]. They can be used to classify objects into corresponding types or regress data into continuous sequences through an end-to-end method without feature extraction and selection. This section will introduce deep neural networks that are usually used in EMG processing. A few types of neural networks, including CNN, RNN, autoencoder (AE),deep belief network (DBN), and mixed structures, will be introduced in brief. Furthermore, deep transfer learning, which shows great potential in EMG decoding, will be presented.
As is known, the networks mentioned above have a long history since they were first proposed. They are basic components of deep learning, but they are not equal to deep learning. The notion of “deep learning” originates in 2006 when Hinton et al. [20] proposed a novel and fast method for training deep belief networks using unsupervised greedy training methods. Deep learning involves the learning of highlevel characterizations of input data using multiple hidden layers. The deeper a network is, the larger the number of hidden layers it includes.
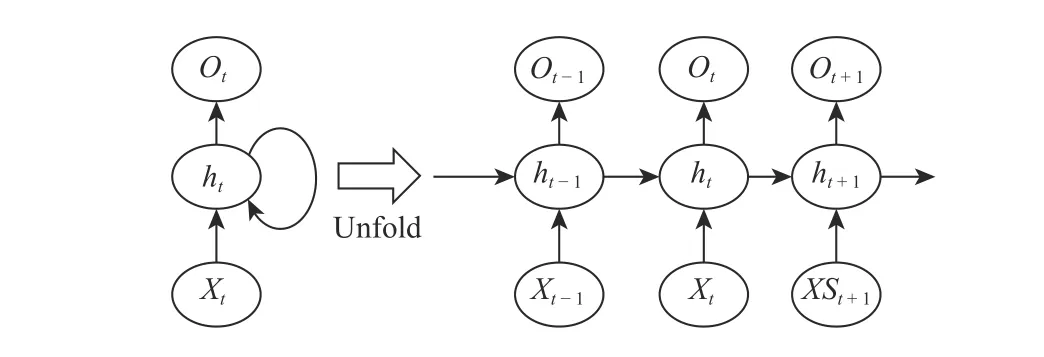
Fig.2. The structure of the RNN.
1) CNN: LeCun et al. [21] proposed the CNN for the first time in the 1980s, which was used to classify handwritten digits. Many deep learning models, such as VGGNet, LeNet,AlexNet, and the Google Inception series, have been designed based on the CNN. It usually consists of two operations:convolution and pooling. Multiple filters are used for the convolutions to extract edges, corners, or other high-level features from an image automatically. Then, a pooling layer follows, such as max-pooling, which selects the largest number in a box, which aims at keeping the most significant features of the original picture while decreasing the number of input dimensions. After undergoing a few layers of convolution and pooling, the abstract features extracted by the CNN will be used for tasks such as classification through several fully connected layers and an output layer. CNN is not the same as MLP, which is composed by fully connected layers, where every neuron connects with all of the neurons in the next layer. CNN has only local connections among the neurons and adjacent layers, instead. It also shares the same parameters for different parts of the image. These characteristics save on the number of parameters and thus promote more efficient training. An example of 2D-CNN based image classification is shown in Fig.1. In addition to the 2D CNN, there is 3D or 1D CNN, which can be used for handling a 3D spatial array or a 1D sequence, respectively.

Fig.1. The structure of a CNN.
CNN is of vital importance for EMG decoding using deep learning methods. Most research decodes human intention with an “EMG image” using a CNN. The features learned by the CNN have resulted in state-of-the-art performance for EMG recognition. By adjusting the network structures, a better result can be accomplished.
2) RNN: The original RNN is called the Elman network,which was presented by Elman et al. [22] in 1990. Ordinary neural networks fit input data to their labels individually, and they are not concerned with the relationships between the different individual input data instances. The RNN was proposed to model the temporal information inside a sequence, especially the relationship of the current input and former input. It is composed of an input layer, an output layer,and hidden layers, similar to the MLP. The unusual aspect is that the current nodes of the hidden layers are connected with the former nodes. The structure of the RNN is illustrated in Fig.2, in which the current input Xttogether with the state of the previous hidden layer St-1will be sent into the current hidden layer. Thus, the information between the input sequences can be learned by the network.
One drawback is that the RNN cannot remember content very long due to gradients disappearing or exploding. To solve this question, the long-short term memory (LSTM) [23]network, which contains the forget gate, was introduced. The forget gate can determine the proportion of preceding information that should remain or be thrown away. In addition, gated recurrent units (GRU) [24] have a similar effect as the LSTM, but they require less computing cost. A normal RNN predicts only the output of a specific moment based on the information from the past, but the current output can also be associated with the input in a future moment. The bidirectional RNN (Bi-RNN) [25] can resolve this question by stacking two RNNs in the forward and backward directions together, to make decisions that are based on not only previous states but also future states.
Unlike the CNN, which normally views EMG as an“image”, RNN takes the EMG data as a sequence. It can obtain information among the adjacent inputs. The EMG is biologically time-dependent, which implies that the temporal information extracted by the RNN can also be used for intentional recognition.
3) AE: The auto-encoder (AE), which was initially proposed in 1987, is the first type of neural network that benefits from unsupervised pre-training [26]. AE has been used in fault detection [27], medical image processing [28], and other applications. It contains two parts: an encoder and a decoder.The input data of the encoder is usually the same as the output label of the decoder. This type of network attempts to ensure that the differences between the input data and output labels are minimized with loss functions, such as mean square error(MSE). The procedure is unsupervised, and can learn the structure of the input data without the corresponding labels.After the pre-training process, the encoder will remain for a further operation, such as being stacked with an output layer and fine-tuned by the back-propagation algorithm or as a feature extractor combined with machine learning algorithms for data pattern recognition. Fig.3 illustrates the simple structure of the AE. The number of neurons at the top of the encoder is usually less than the input, which will lead to a decline in the data dimension. Sometimes, the AE is used for data dimension reduction, similar to principal component analysis (PCA). There are many variants of AE, such as sparse auto-encoder [29] and denoising auto-encoder [30].
The AE can be used to extract hidden information inside an EMG to obtain better performance. It can be used for feature extraction from raw data or for feature mining from handcrafted features. The features stand for the inherent information of the EMG data, which has nothing to do with the target labels.

Fig.3. Structure of the auto-encoder network with three hidden layers.
4) DBN: Before the introduction of the DBN, we will talk about the restricted Boltzmann machine (RBM), which is the basic component of the DBN. The RBM belongs to a special type of Markov Random Field, which is comprised of two layers: the visible layer and the hidden layer, as depicted in Fig.4 (a). The connections among the two layers of the RBM are bidirectional, while no neuron connections exist inside the visible layer or hidden layer. The weights and bias of the RBM are usually trained by a contrastive divergence learning method iteratively. The RBM is an unsupervised machine learning method that can reconstruct data without a predefined label, which is similar to AE. It can extract a better distribution of the input data, and thus, it can be adopted to pre-train deep neural networks.
The DBN is cascaded by multiple RBMs, as shown in Fig.4 (b). The Network will be trained layer-to-layer using a greedy algorithm. For each RBM, the hidden layer will turn into the visible layer for the next RBM, which means that the former output layer will be the next input layer. After several layers of stacking, an output layer such as softmax will be added onto the top of the stacked RBMs. In the end, the entire network will be fine-tuned by the back-propagation method to fit the corresponding labels. The DBN has many applications,such as health diagnosis [31], speech recognition [32], and natural language processing [33].
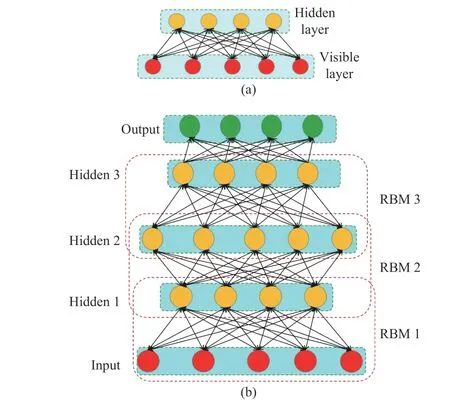
Fig.4. Structure of the DBN. (a) is the structure of the RBM; (b) is the structure of the DBN stacked by three RBMs and an output layer.
Similar to the AE, the DBN attempts to learn a better distribution from the EMG data without prior knowledge of the corresponding tasks. Both raw data and EMG features have been used for EMG analysis.
5) Mixed Network: There are various deep neural networks that are geared to mixed networks that are composed of the networks enumerated above that have displayed good performance in EMG pattern recognition. The outcome of mixed networks is ordinarily better than for one structure alone because higher dimensional EMG features can be extracted.
Combining two types of networks, such as CNN stacked with RNN, is the most popular mixed structure used in EMGbased applications [34]-[36]; they can extract both spatial and temporal information of EMG data at the same time. Network 1 is connected to network 2, where the output of network 2 will be placed into several fully connected layers, which can create a fusion of extracted features for classification or regression, as described in Fig.5 (a). Analogous research that combines deep networks with machine learning methods [37],[38] can also be illustrated similarly. Other network structures,such as a dual-stream network [39], [40] or multi-stream network [41], [42], assemble several blocks for feature extraction and combine features to make a final decision. The input data will then be placed into all of the sub-networks, and the results are fused by fully connected layers. A diagrammatic sketch of this structure is shown in Fig.5 (b).

Fig.5. Mixed structures of deep neural networks. (a) is the structure in series; (b) is the multi-stream network if n > 2, and dual-stream network if n = 2.
These mixed networks usually show better performance than single type. More hidden information in the EMG data can be separated from these complex structures. However, the main shortcoming of this approach is that it contains too many parameters, which results in a very high computational cost.
6) Deep Transfer Learning: The applications of machine learning algorithms are usually under the assumption that the training dataset and the testing dataset are analyzed within the equivalent feature space, and their feature sets obey indistinguishable probability distributions. Nonetheless, this situation is almost impossible for EMG recognition because of the many interchangeable factors under various scenarios.Transfer learning, which attempts to solve new questions with the help of the knowledge learned before, permits different distributions of the source dataset and target dataset, even for different tasks [43]. It is usually used under the assumption that the source problem is the same as the target problem to some extent. For example, the knowledge that helps to classify a dog from a cat can also help to distinguish an airplane from a car.
Deep transfer learning attempts to improve transfer learning using deep neural networks. This learning method can be classified into four categories, namely, instance-based transfer learning, mapping-based transfer learning, network-based transfer learning, and adversarial transfer learning, according to [44]. It improves the applicability of deep learning, which is exceedingly data-dependent, while retaining the ability to learn features using deep neural networks. Deep transfer learning has been applied to object detection [45], [46], image classification [47], [48], and so on. It also shows great potential for EMG pattern recognition under data-shift conditions caused by cross-subject, electrode shift, and so on,which will be further discussed in Sections V-B and V-C.
B. EMG Signal Processing Approach
1) EMG Data Acquisition: One source of an EMG dataset is the publicly open datasets. There are several benchmark datasets, such as Ninapro2http://ninapro.hevs.ch, CapMyo [49], cls-hdemg (CSL)[50], which have been extensively applied for assessing the performance of the proposed algorithm by many researchers.Ninapro is most likely the largest dataset for EMG-based hand gesture recognition, which includes ten sub-datasets for now.DB1 to DB7 are for hand gesture classification. DB8 is for finger angle regression. DB9 is the kinematic data captured with Cyberglove-II. The last one, named MeganePro, is a multimodal dataset for prosthetics control. Amputees have access to this project thus those datasets are of helpful to improve the quality of their life. CapMyo and CSL are EMG datasets that were captured by electrode arrays, and the signal is in high density, called HD-EMG. These datasets are easy to access and make it easy to evaluate the algorithms’performance, thus contributing substantially to deep learningbased EMG recognition schemes.
In addition to the publicly open datasets, self-made datasets are also widely used for performance evaluation. There are sensors that are normally used for EMG capture, such as the Myo armband3https://support.getmyo.com/hc/en-us, Delsys Trigno4https://delsys.com/trigno/, and so on. For gesture classification tasks, sensors will be attached to the skin to acquire EMG signals while the subject performs various movements under the guidance of prompt information. For joint angle estimation tasks, spatial movement capture systems, such as the Vicon motion capture system5https://www.vicon.com/or IMU together with EMG electrodes, will be adopted to obtain the angles of human joints and EMG signals at the same time. For force/torque estimation tasks, a system that can record the forces implemented by human muscles and EMG signals will be designed for simultaneous EMG-force data acquisition.These systems capture EMG signals with their predefined labels, such as joint angle or force, synchronously for human intention prediction.
2) Filtering and Segmenting: The raw data contains a large amount of noise, which makes filtering necessary. The bandpass Butterworth filter with different bounds, such as 5-500 Hz [51], [52], 10-450 Hz [53], or 10-500 Hz [54], are often used for rejecting environmental noise. Other studies select high-pass filters together with a low pass filter for noise removal [55], [56]. Then, the data will be rectified, and a 50 Hz/60 Hz notch filter will be used to dislodge the disturbance of the power line. Nevertheless, any type of processing could lose valid information from EMG data, which leads to that some studies feed raw signals into deep neural networks [34],[40], [57].
After filtering, the sliding window method is usually selected to segment the EMG signals into a series of envelopes. A window with length W slides across the EMG signals with a step length of T, which is depicted in Fig.6 (a).To guarantee efficient real-time performance, the length of the sliding window is usually within 300 ms [58]. Windowing is the approach that is most often used in machine learning or deep learning-based EMG pattern recognition schemes.

Fig.6. Illustration of the segmentation method. (a) is the sliding window method with window length W and sliding step T; (b) is the instantaneous EMG method with ti as the sampling time.
The instantaneous value of EMG signals, which can be interpreted by Fig.6 (b), has also been proven to be effective for gesture classification [49], [59]. Geng et al. [59] showed that the instant EMG value can be used for hand gesture classification using a CNN for the first time. Their scheme shows good performance in sparse channel EMG, such as Ninapro DB1 and DB2, or HD-EMG, such as CapMyo.Compared with the sliding window-based scheme, it can be more natural and fluid for HMI due to having less time-delay.Other studies [60], [61] attempt to estimate the limb angle during movement with instant EMG data, which is downsampled to 100 Hz. In general, it has been verified that instant EMG data contains effective information that can be used for EMG recognition directly. However, the performance of single-frame data is relatively poor, and therefore, it usually chooses the majority voting method as an assistant strategy[59].
The numerical value of EMG data is small, which is often regularized using normalization algorithms such as min-max normalization, z-score normalization, or conversion into a fixed range. In addition to these, the following methods are often used to construct a better format of the input data.
3) Data Reconstruction Methods: The raw EMG data is relatively noisy, which makes it difficult for pattern recognition. Unlike applications in computer vision, where raw data is put into the networks and decoded end-to-end,EMG signals are regularly reconstructed into new formats.The distinction between data reconstruction and feature engineering is that the former is normally in a 2D format,while the latter is typically in a 1D format. The structure of the reconstructed EMG is similar to raw EMG data, while the feature extraction method reduces the dimension of input data.The following formats are often chosen for EMG conversion:
a) Time Domain: The original data after processing contains information and can be used for pattern recognition directly.Some papers [59], [62], [63] convert it into gray-scale images with the value range of [0, 255].
b) Frequency Domain: The Fourier transform (FT), fast Fourier transform (FFT), and discrete Fourier transform(DFT) are often used to obtain the spectrum of the preprocessed EMG signals, which could reflect the amplitude at different frequency levels [64]-[66].
c) Time-Frequency Domain: Approaches such as the wavelet transform (WT), continuous wavelet transform(CWT), wavelet packet transform (WPT), discrete wavelet transform (DWT), and short-time Fourier transform (STFT)could abstract time-frequency domain features of EMG signals for further operation [67]-[70]. This approach is more informative than using time-domain features or frequency domain features, although it is more time-consuming.
d) Others: Some research [41] constructs the EMG image using human-designed features. A few researchers choose classical features directly to feed into deep neural networks[71]-[73]. Moreover, there are new formats, such as fused time-domain descriptors (fTDD) [74], [75] and Hilbert spacefilling curves [76], which are used for next step processing.
These reconstruction methods could project EMG data into a more discriminant space, where different movements have a larger gap with one another. Although raw data can be used for recognition with deep neural networks, a new format for input achieves better performance. The new format for input data is worthwhile to explore because it can boost discrimination performance.
C. Algorithm Schemes Comparison
For the EMG pattern recognition strategy, there are several partition criteria according to different standards and application standards. Simão et al. [11] partition the machine learning-based approach with three main procedures:preprocessing, feature extraction and selection, in addition to pattern recognition. Bi et al. [77] classify EMG-based continuous motion prediction methods into model-based techniques and model-free techniques. Farina et al. [78]summarize the ways to control prostheses with EMG signals into the following classes: proportional control, pattern recognition, direct neural control by EMG decomposition, and multimodal sensor fusion.
For the methods besides deep learning, there are two main strategies that are usually used by researchers, including the machine learning-based method, which is often accompanied by various pattern recognition algorithms, and the modelbased method, which chooses kinematics, dynamics, or musculoskeletal models for intention identification. The machine learning-based method has been widely adopted to recognize the patterns inside EMG signals. This approach is depicted in Fig.7 (a). The model-based approach is popular in continuous movement estimation of the joint angle, force,torque, and so on. The whole process of the model-based strategy is described in Fig.7 (b). Compared with the machine learning-based method and the deep learning-based method, it models the relationship between EMG and human motion using musculoskeletal, kinematics, or dynamics model [77],which needs accurate representation of human limbs. The processing step contains preprocessing, and feature extraction[77], which is similar to the machine learning method, and thus they share the same drawbacks of feature engineering.The model-based method requires more prior knowledge about the human limb and involves more complicated parameter identification than the machine/deep learning method, which limits its application.
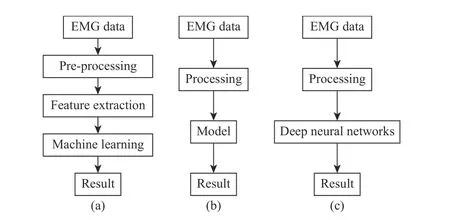
Fig.7. Process of EMG-based human intention recognition. (a) is the machine learning-based method; (b) is the model-based method; (c) is the deep learning-based method.
The deep learning-based method contains no complex feature extraction or feature selection procedures, as shown in Fig.7 (c). Deep neural networks will be used for movement prediction after three steps of processing, as illustrated in part B of this section. This approach relaxes the demand for feature engineering and kinematic modeling, which brings about new options in eliminating the original faults with traditional approaches.
III. HUMAN-MACHINE INTERFACE WITH DEEP LEARNING AND EMG
In this section, we will discuss EMG-based HMI tasks with deep learning as a recognition technique. First, we discuss EMG-based discrete movement classification questions. The movements are predefined into several classes of postures,including being open-handed, having a fist, or relaxed.However, this is not convenient for tasks such as upper limb motion prediction, which requires us to have knowledge of an accurate position of the arm in real time. A more natural and smooth interaction approach that estimates the joint angle continuously through EMG will be presented in the next section. Next will be the estimation of force/torque during body movement, which is similar to joint angle prediction.Other tasks will be discussed briefly at the end.
Generally speaking, deep learning-based EMG recognition assignments can be split into two types: classification tasks and regression tasks. The typical examples of classification questions are hand gesture classification, body movement discrimination, sign language processing, and so on, which predefine the label into several classes. Regression questions such as real-time joint angle, force, and torque estimation,where the label varies in a fixed range in real-time.
A. Movement Classification
The human hand is of great significance in our daily life.Hand gesture recognition is the most common task of EMGbased HMI, and hence, various datasets for hand gesture classification, such as Ninapro and CSL, are presented for performance evaluation. Multifarious deep learning methods have been widely employed for this task.
CNN is often selected for gesture classification, and it normally views EMG signals as an image. Park et al. [79]chose CNN to classify hand gestures of different users, and the results show better performance compared with support vector machine (SVM) for both adaption and non-adaption conditions. This study is the first time that deep learning was used in EMG-based HMI tasks [80], [81]. Afterward, more researchers paid attention to this field. Atzori et al. [82]evaluate the performance of a simple CNN on EMG data of Ninapro DB1, DB2, and DB3, which contains approximately 50 hand gestures collected from 67 healthy subjects and 11 amputees in total. The performance of CNN is superior to the average accuracy of the traditional methods but worse compared with the result achieved by SVM. This finding implies it is possible that better results can be achieved with a larger network for computer vision and object recognition tasks.
Olsson et al. [62] propose a CNN-based multi-labeled classification scheme with HD-EMG as the input. The multilabel methods express complex movements as a summation of multiple simpler movements. In this paper, 16 independent movements are used to model the state of the hand. The accuracy reaches 78.7% in 14 healthy subjects. Zhai et al. [83]propose a CNN-based strategy with self-recalibrating capacity that maintains steady performance against time-changing without retraining, where the accuracy is 10.18% higher than the uncalibrated classifier for 50 hand movements. Chen et al.[84] employ a 3D CNN for HD-EMG-based gesture classification, and the result outperforms the instant EMGbased method. However, the computation cost is higher.
An issue is that deep CNN models have too many parameters, which could cause problems for real-time applications. Chen et al. [67] propose a compact CNN model named EMGNet that has fewer parameters but better classification accuracy, which is a benefit for online working.Similar research is addressed [53], which proposes an embedded CNN to decode the HD-EMG signals on a single embedded system. A filter kernel with size 3 × 3 or 1 × 1 is selected in most CNN-based networks. However, a filter with size m × n, where m is not equal to n, exists in some studies[40], [85]. There is a narrow gap between the length and width of the EMG image, which leads to the idea of larger and“thinner” filters.
The RNN, which is usually selected to process temporal information for tasks such as natural language processing has also been applied to this question [57], [72], [86]-[88]. Nasri et al. [57] propose a GRU-based scheme to process EMG segments by the sliding window method, and the accuracy reaches 77.85% for 6 gestures performed by 35 subjects. Koch et al. [72] present a scheme using an RNN with novel weighting loss. The features of the EMG are extracted, and the performance outperforms the most up-to-date approaches using 3 types of datasets. Simão et al. [86] process the single frame EMG with several types of deep learning methods, such as RNN, LSTM, and GRU, to extract temporal information inside the EMG. Samadani et al. [87] compare several optimization methods, including the bidirectional recurrent layer and attention mechanism, together with a step-wise learning rate. The highest accurary achieve is 86.7% for 18 gestures with the Ninapro DB2 using bidirectional LSTM (Bi-LSTM). Alfaro-Ponce et al. [88] compare the performance of the time-delay neural network (TDNN), differential neural network (DifNN), and complex-valued neural network(CVNN) for two different physiological signals, including EMG and foot pressure of the gait for Parkinson disease (PD)patients, and the accuracy of all three networks was greater than 95%.
In addition to the CNN and RNN mentioned earlier, which belong to the supervised learning approach, unsupervised deep neural networks, such as auto-encoder and deep belief networks, have also been used for movement classification.
The AE-based schemes can be classified into two types according to the input format: hand-crafted feature-based methods [89] and raw data-based methods [90]. Rehman et al.[89] apply stacked sparse auto-encoders (SSAE) to multiday EMG recordings to improve the performance. The results of the SSAE is better than linear discriminant analysis (LDA) for both intact and disabled subjects with four time-domain features. Rehman et al. [90] compare the hand gesture classification performance of CNN, SSAE, and LDA. They also evaluated the SSAE with raw EMG signals and timedomain features as inputs separately, where the latter achieves better performance.
DBN usually takes hand-crafted features as the input [73],[91]. Shim et al. [73] propose the split and Merge DBN,which chooses the genetic algorithm to augment the performance of the DBN; the precision outperforms classical DBN by 12.06%. Zhang et al. [91] recognized normal and aggressive EMG signals, and each contained 10 actions using DBN with time-domain feature sets. The best accuracy reached is 90.66 ± 1.47%. Additionally, Sun et al. [55]proposed a novel method using a generative flow model(GFM), which belongs to a unsupervised learning methods similar to the DBN, for converting EMG data into factorized features and applying the features for EMG classification using a softmax classifier.
The above methods apply a single type of deep learning method for hand gesture prediction. There are mixed network structures, such as multi-stream networks, chosen for this task.Ding et al. [40] handled the hand gesture classification task using a parallel multiple-scale convolutional neural network.Wei et al. [42] decomposed EMG into multiple streams, and a CNN with multiple sub-streams is used for gesture classification. Both of the structures are as depicted in Fig.5 (b).Mixed architectures that are connected as in Fig.5 (a) have been widely used for EMG-based gesture classification[34]-[36], [39]. Gao et al. [34] proposed a dual-flow network that uses the CNN and LSTM individually to extract the EMG features simultaneously; then, the features are fed into fully connected layers for classification. Wu et al. [35] propose a system based on CNN and LSTM with the attention mechanism for hand gesture classification with CWT of EMG as the input. Xie et al. [36] combine CNN with LSTM into a unified structure, and an accuracy of 98.14% is achieved.Tong et al. [39] combine 3 layers of CNN with 3 layers of RNN for hand gesture classification.
Tsinganos et al. [80] outperform state-of-the-art performance by 5% on Ninapro DB1 with temporal convolutional network (TCN). However, this technique chooses the whole section of the EMG data instead of the envelopes under 300 ms as the input. Zanghieri et al. [81] developed a TCN-based network named TEMPONet, which runs on an embedded system. The performance reaches 49.6% on a Ninapro DB6,which outperforms the current state-of-the-art method by 7.8%.
Some studies associate deep learning with machine learning methods, in which the latter is used to elevate the decision performance [37], [38]. Shen et al. [37] proposed a scheme using a CNN and a stacking ensemble learning algorithm with three types of inputs, including EMG data, DFT of EMG data,and discrete wavelet packet transform (DWPT) of EMG data.The CNN works as a low-level classifier, and the results are optimized by an ensemble learning-based secondary classifier.Chen et al. [38] propose a novel technique with typical CNN networks whose output layer is replaced by machine learning methods, including SVM, LDA, and K-nearest neighbor(KNN). All three methods outperform the traditional featurebased method under the conditions of inter-subject/intersession, which shows that features obtained by the CNN are efficient for human intention recognition.
EMG can be used for robot hand control for amputees.However, it is difficult for high-level amputees whose muscles are not strong enough for EMG-based multi-action classification. Therefore, Lee et al. [92] recognize foot postures based on EMG acquired from the lower limb and map the foot postures to hand gestures by the CNN. This approach is a new way for severe amputees to control prosthetics without targeted muscle reinnervation (TMR) [93],although convenience is a problem that is of concern.
Except for hand gestures, other movements can also be recognized with the analogical procedure. Shao et al. [94]present a scheme for 12 upper limbs’ motion recognition with single-channel EMG. The spectrum acquired by the FFT is first decomposed by the singular value decomposition (SVD)method and then processed by wavelet deep belief networks(WDBN). Other tasks, such as gait stages classification [95],wrist motion recognition [68], [96], and arm motion prediction[97], [98], can also be addressed by deep learning, which has no obvious difference except for the label name compared with the hand gesture classification tasks. For detailed information on typical movement classification, the relevant papers are summarized in Table I.
B. Joint Angle Estimation
Estimating human motion intentions continuously demonstrates good potential for human-robot interaction in scenarios such as exoskeleton robot control. The discrete recognition of predefined gait stages can lead to disastrous results, such as falling, if the intention is badly decoded.Another problem occurs with movement switching as most studies choose the stable section of the EMG signals and neglect the switching section, which limits the application even with high decoding accuracy. These errors can be avoided because the motion can be adjusted by the feedback of human vision or tactile sensation. Thus, it is a safer and more advantageous method for man-machine interaction.
The method for continuous movement recognition can vary.There have been approaches based on models such as the polynomial model [101], state-space model [102], [103], and machine learning approaches, such as support vector regression (SVR) [104], random forest regression [105], and neural networks [106]. Deep learning-based joint angle prediction fits the EMG toward joint angles without background knowledge about muscle physiology. It can be selected for angle prediction of various body positions, such as the wrist, hand, upper limb, and lower limb. Performance measure regulations, such as mean square error (MSE), root mean square error (RMSE), and coefficient of determination(R2), are summarized in [77].
Most studies estimate hand gestures as predefined actions because the human hand is dexterous, which makes it difficult for continuous angle estimation. There are studies [107] that estimate the continuous hand movements under the conditions of both mobile and non-mobile wrists using the RNN with simple recurrent unit cells. Adversarial domain adaption is used to improve performance. Teban et al. [108] estimate finger angle in the form of the flex angle of fingers using the RNN with LSTM cells to provide a flexion reference for a prosthetic hand.
Ameri et al. [51] decode 2 DOF (degree of freedom) wrist movements using the Fitts’ law test with a regression CNN that has 8 convolution layers. This outperforms the support vector regression (SVR) based method with five EMG features as input. It shows that deep neural networks havebetter representation abilities compared with featureextraction method. Bao et al. [56] estimate 3-DOF movement of the wrist using a spectrum image of the EMG. Several machine learning-based methods are compared with the proposed CNN, and the performance demonstrates the superiority of the CNN-based method.
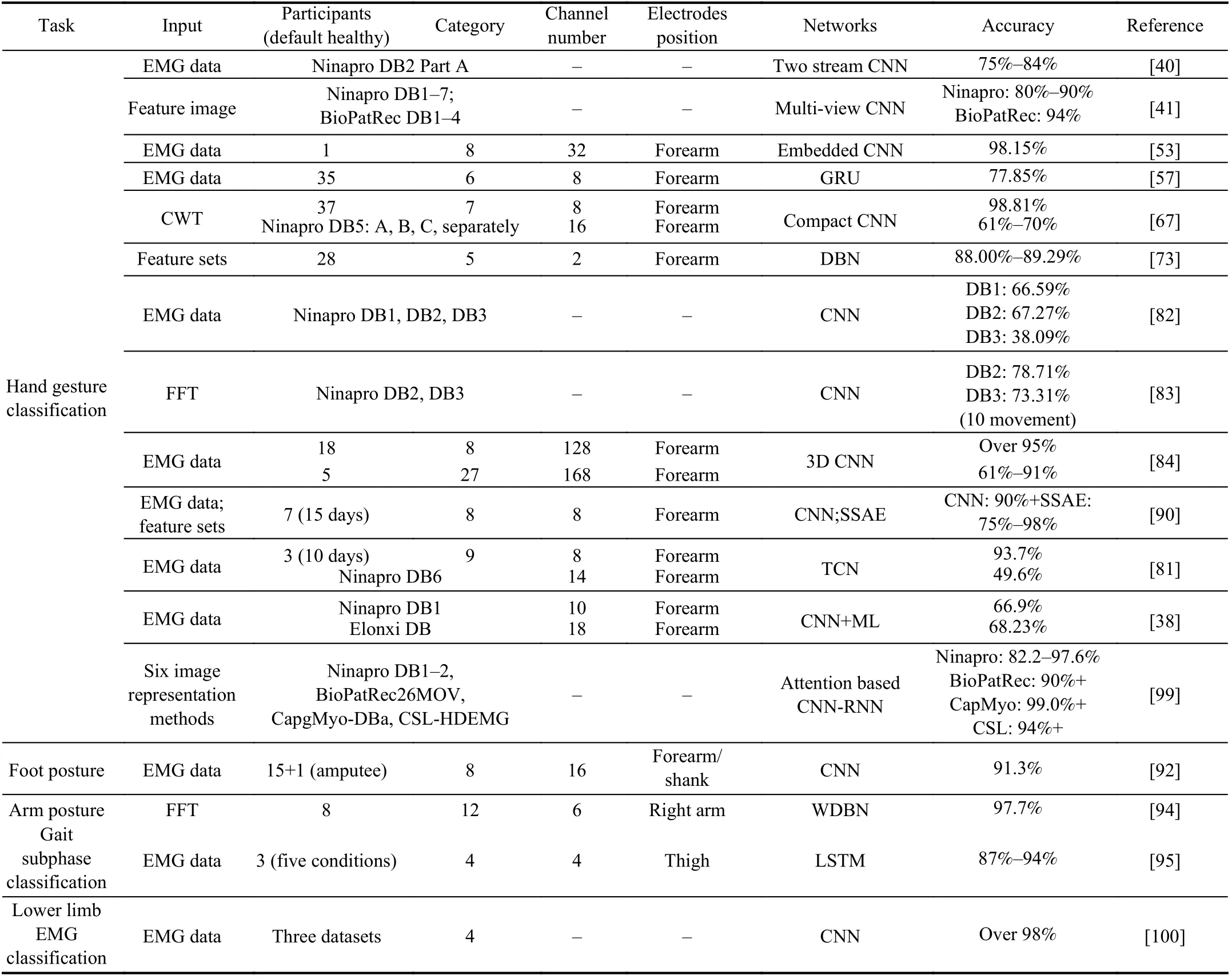
TABLE I TYPICAL STUDIES OF EMG-BASED MOVEMENT CLASSIFICATION USING DEEP NEURAL NETWORKS
Chen et al. [54] establish an LSTM-based model for upper limb angle prediction. The inputs are time-domain feature sets of EMG, while the participants perform two types of compound tasks. Ren et al. [70] predict the upper limb joint angle of both arms using the multi-stream LSTM dueling(MS-LSTM dueling) model, which selects the LSTM and convolutional LSTM (ConvLSTM) as two individual streams of the model. This model combines spatial information with temporal information in parallel, as depicted in Fig.6 (b).Unlike [70], Xia et al. [109] estimate the angle of the shoulder and elbow using the CNN consecutively combined with the RNN.
Huang et al. [110] predict the knee joint angle during walking using EMG combined with IMU data. A fully connected RNN, with the relu activation function, is employed to construct the deep neural networks. The proposed method has less computational cost compared with the LSTM or GRU. Gautam et al. [111] propose a scheme that combines the CNN with the LSTM together to classify lower limb movement and to estimate the angle of the knee joint simultaneously. Transfer learning was used to transfer the parameters learned during the angle estimation for movement classification. Instead of predicting the angle of a single joint,Chen et al. [60] estimate the angle of the hip, knee, and ankle with regard to the right leg simultaneously while those participants walk at different speeds. The DBN is used to diminish the dimensions of the EMG signals, and its performance outperforms PCA; then, MLP is used for angle prediction.
Currently, there is no definite distinction between EMGbased motion prediction and motion estimation in most studies. The former is usually used to predict the angle in the future, while the latter only estimates the angles simultaneously when motion occurs. Because it is widely acknowledged that the EMG occurs earlier before the physical actions, motion prediction is a more reasonable interpretation.Moreover, it can relieve the effects of time delays, which affects online performance.
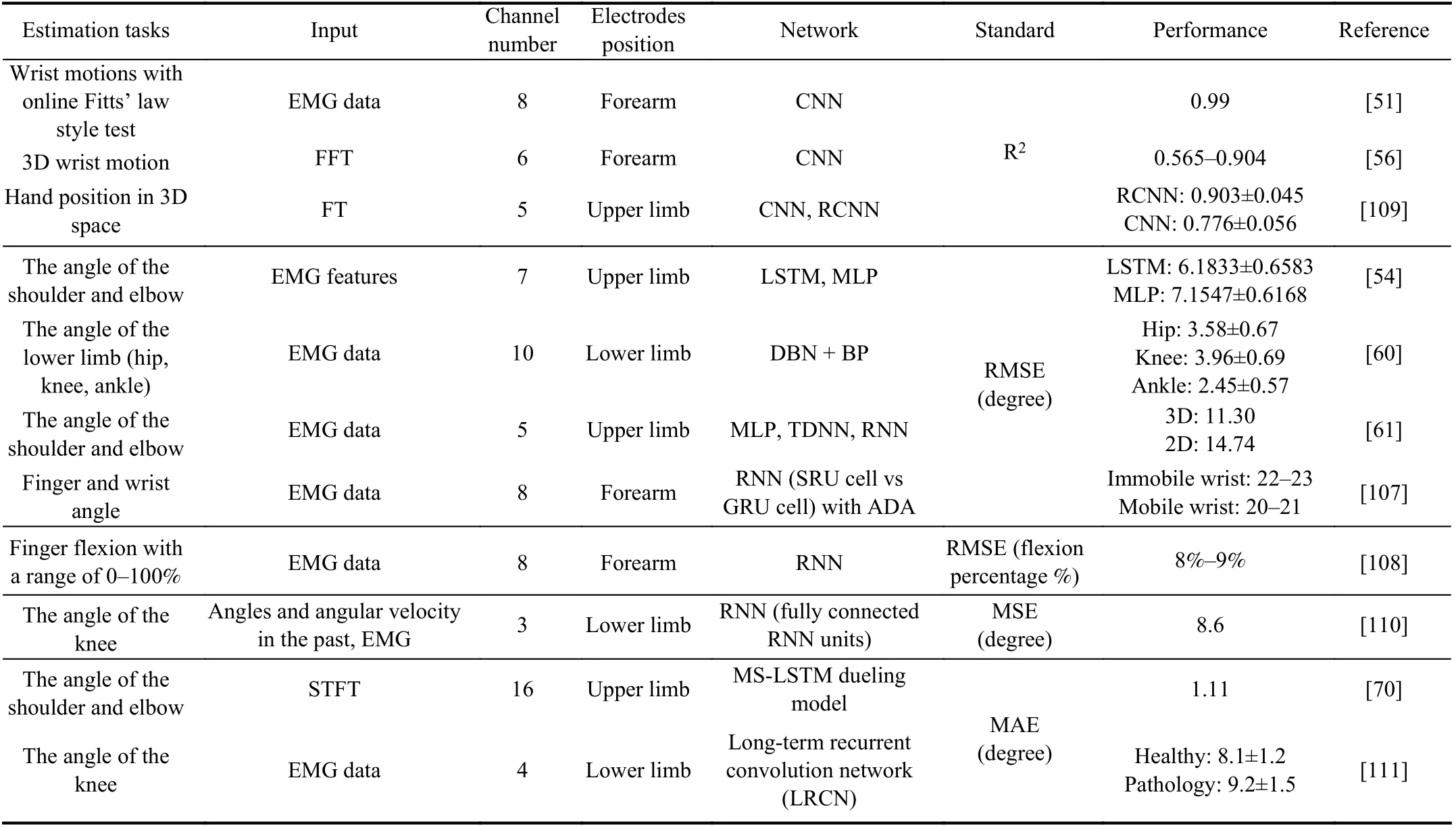
TABLE II DEEP LEARNING-BASED CONTINUOUS ANGLE PREDICTION
In general, the deep learning-based method attempts to portray the interrelationships between the EMG signals and the limb angles without prior knowledge about muscle structure, feature engineering, regression models, etc. This technique is more intuitive than the gesture classification approach. All of the detailed information relevant to the papers mentioned before about this task is included in Table II.
C. Force/Torque Estimation
Research that studies the relationship between the EMG signals and the muscle force have a long history that can be traced back to 1952 [112]. The core dilemma of the EMGbased muscle force prediction include precision and representativeness [113]. There are model-based methods such as [114], [115] that estimate the EMG-Force relationship based on the Hill model [116]. It bridges the gap between the EMG and the muscle force through an explainable technique.However, the parameters of the model are complicated, and it requires special knowledge about human muscle, which is similar to the angle prediction tasks. Furthermore, the parameters are difficult to optimize due to individual differences, sensor noise, electrode shifts, and so on. In addition to the model-based method, machine learning has also been used for this question, which maps EMG signals toward force by regression algorithms such as linear regression [117], polynomial regression [118], support vector regression [119]. However, it is limited by the same drawbacks of feature engineering.
Deep learning has been used for EMG-based force/torque estimation. In [120], [121], a framework estimates that the force of the elbow was developed using HD-EMG as the input. In [120], the raw data is filtered, segmented, and normalized. Then, the dimensions are reduced using principal component analysis (PCA), and finally, the output is fed into the DBN for force prediction. In [121], the raw data is preprocessed, spatially filtered by PCA and, then, dimension reduced by nonnegative matrix factorization (NMF) to remove the redundancy of the electrode array. Finally, it is constructed to train three types of deep neural networks, including the CNN, LSTM, and C-LSTM, and their results are compared.
Unlike [120], [121], which choose an electrodes array to record the EMG signals, Li et al. [122] choose the Myo armband as the EMG capture sensor. The data is filtered,segmented, and then feature extracted for further operations,and the dimension of the features is reduced by PCA; finally,two layer stacked autoencoder (SAE) networks are used to divide the force into eight levels. The predicted force is placed into a fuzzy controller to control a prosthetic hand.
Yang et al. [123], [124] develop a system to map the force of 3-DOF wrist motion toward the position of the cursor on the screen. A deep CNN is imposed for the 3-DOF wrist force regression task, with the raw EMG data as the input. In [125],a system is designed to recognize the direction and the magnitudes of the diverse forces acting on a designed facility by a hand simultaneously. In [126], Yokoyam et al. predict handgrip forces using MLP with multiple hidden layers using electrodes placed on the back of the hand. In [127], Chen et al.estimate the force of the multi-DOF finger continuously withHD-EMG data as the input. This study compares the performance of the CNN and CNN plus RNN with classical methods that are based on linear regression with channel merging methods such as common spatial pattern (CSP) and so on, while the CNN combined with the LSTM achieves the best performance.
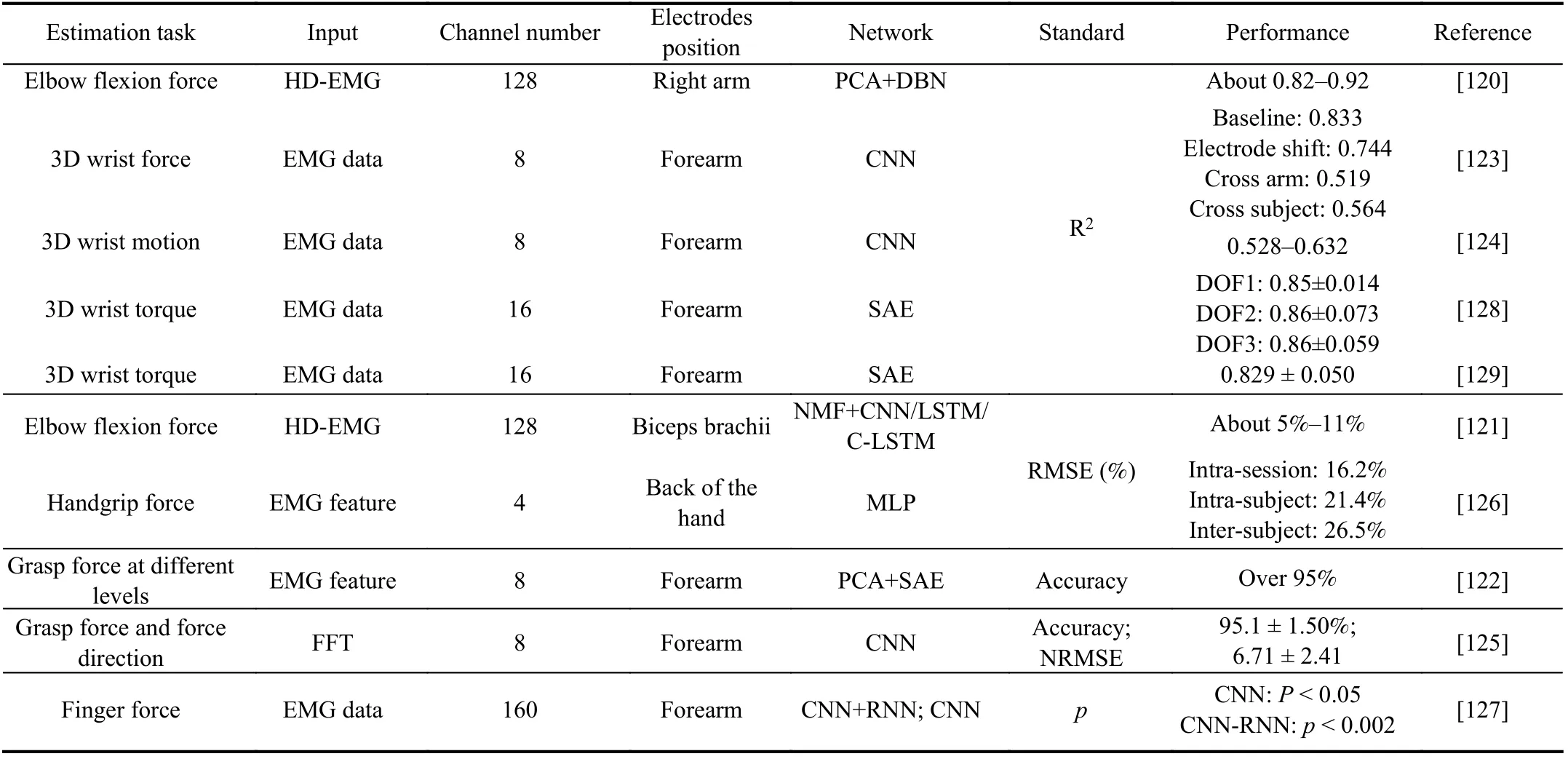
TABLE III DEEP LEARNING-BASED FORCE ESTIMATION
In addition, there is a study that estimates joint torque as in[128], [129]. In [128], Yu et al. estimate the torque of the wrist continuously using a five-layer stacked auto-encoder(SAE) based deep neural network. The SAE plays the role of data dimension reduction and then, the fully connected layers are for torque regression. In [129], the wrist torque is estimated using high-density EMG signals with an SAE-based method, and the performance outperforms several machine learning-based methods.
In general, deep learning for muscle force/torque estimation is almost the same as continuous limb angle estimation. It is more convenient to predict muscle force using a regression deep network without complicated models. The performance is comparable with state-of-the-art strategies. Detailed information about the relevant research articles is described in Table III.
D. Other Tasks
In addition to the tasks mentioned earlier, other HMI tasks,such as disease diagnoses [130], [131], fall detection [132], or personal authentication [133], can also be solved with deep learning methods. Qin et al. [130] predict tremor severity levels of Parkinson’s disease by EMG with a lightweight CNN named S-Net. Sengur et al. [131] classify amyotrophic lateral sclerosis (ALS) patients from a normal person using EMG with time-frequency representations as input. Liu et al.[132] detect falling using the dual parallel channels of CNN with EMG spectral features as input, and an accuracy of 92.55% is achieved. Morikawa et al. [133] choose lips EMG for identity authentication with CNN. Khowailed et al. [134]detect the timing EMG that occurs using an RNN. Wang et al.[135] predict EMG data of the future using historical EMG signals. Nodera et al. [136] successfully classify six forms of resting needle EMG using several deep neural networks,including VGGNet, ResNet, and Inception v3. Data augmentation and transfer learning techniques are also used for optimizing the result. Nam et al. [137] classify needle EMG using Inception v4, and an accuracy of 93.8% is achieved.
In general, the EMG is used to fit predefined target labels using deep neural networks, and thus, it can be used on various tasks with the defined labels. Their processing procedures have no obvious difference with gesture classification or angle prediction tasks theoretically. The relevant papers have been listed in Table IV.
IV. RECENT HOT-SPOT ISSUES
This section will introduce several hot topics in EMG-based human-machine collaboration, including multimodal sensing,inter-subject/session, and robustness toward disturbances,which can contribute to building practical and stable muscle computer interfaces.
A. Multimodal Sensing
The EMG signals can be easily affected for various reasons,and thus, it could be difficult to develop a reliable HMI system using only EMG signals. Other modal information,such as IMU data or video stream, can help to improve the reliability of the online performance. Thus, combining multiple modal sensors can provide a novel path for HMI.
We choose multimodal data because different modal inputs contain different information that can compensate for eachother for better performance [138]. Determining how to fuse various sensors’ data to make a better decision is a tough question due to the heterogeneity gap between different inputmodals. The machine learning-based method usually solves the feature gap of different input-modals by two methods[138]: 1) Eliminating the correlations between the inputs; 2)Projecting these features into a common subspace. The method needs to extract features from every kind of input,which needs the expert knowledge of every modal of data.The deep learning-based method can learn high-level representations from each modal of input data, and the feature gap can be eliminated by constructing a fusion layer [138].The whole scheme is usually end-to-end, which does not require complicated feature extraction and selection/projection, and as a result, better performance can usually be achieved.

TABLE IV OTHER APPLICATIONS
For sign language recognition (SLR) tasks, two problems of the traditional algorithms are inconspicuous subsections and the diversity of input data. A multimodal deep learning-based framework that merges the information of EMG and IMU is widely adopted to enhance the recognition accuracy of sign language recognition [139]-[142]. Yu et al. [139] fuse the EMG, accelerometer (ACC), and gyroscope (GYRO) at the data level, feature level, and classification level using a DBN,and the best accuracy achieved is 95.1%. Wang et al. [140]fused three types of data by a Siamese network that is designed based on CNN, and the accuracy is over 94%. Shin et al. [141] also chose a CNN for data fusion, and the best accuracy achieved is 99.13%. Zhang et al. [142] propose a mixed architecture comprised of CNN, Bi-LSTM, and connectionist temporal classification (CTC), and the whole network is trained with an end-to-end method. In addition,EMG signals combined with IMU data could also be used for hand gesture classification, as shown in [41], [143], [144].Other research like [145] classifies dynamic postures from static gestures using features of EMG combined with IMU,which shows better results than IMU or EMG alone.
In addition to EMG and IMU, pressure data and video data could also be used for hand gesture classification. Zhang et al.[146] recognize hand gestures using the EMG and IMU data of the Myo armband together with pressure data captured by a smart glove. LSTM is chosen for gesture recognition with hand-crafted features as input. Gao et al. [147] combine EMG images with the RGB images and the depth images of human hands captured by Kinect to construct five-channel images that are for hand gesture discrimination through the multiscale parallel CNN. Li et al. [148] mingle EMG data with kinematics data, which is captured by the CyberGlove II motion capture system together for the gesture classification task. Huang et al. [110] choose the angle and angular velocity of the past, together with EMG signals to predict the joint angle in the future.
With the combination of different sensors, the performance can be improved compared with single modal data. Deep multimodal learning makes it easy to perform gesture classification by an end-to-end approach that is more convenient and efficient than the machine learning-based method. Table V gives detailed information on the relevant papers.
B. The Inter-Subject/Session Problem
The inter-subject/session problem can lead to a sharp decline in the precision of the previously trained model. Intersession means that the data for training and the data for testing do not belong to the same session but the same person, while inter-subject means that the model is trained by one subject toanother. EMG changes after even a few moments for the same action of a participant, which leads to the inter-session problem. The inter-subject problem is more complex compared with the inter-session problem because of the development degree of muscle, the thickness of fat, individual habits, and so on, of different people.
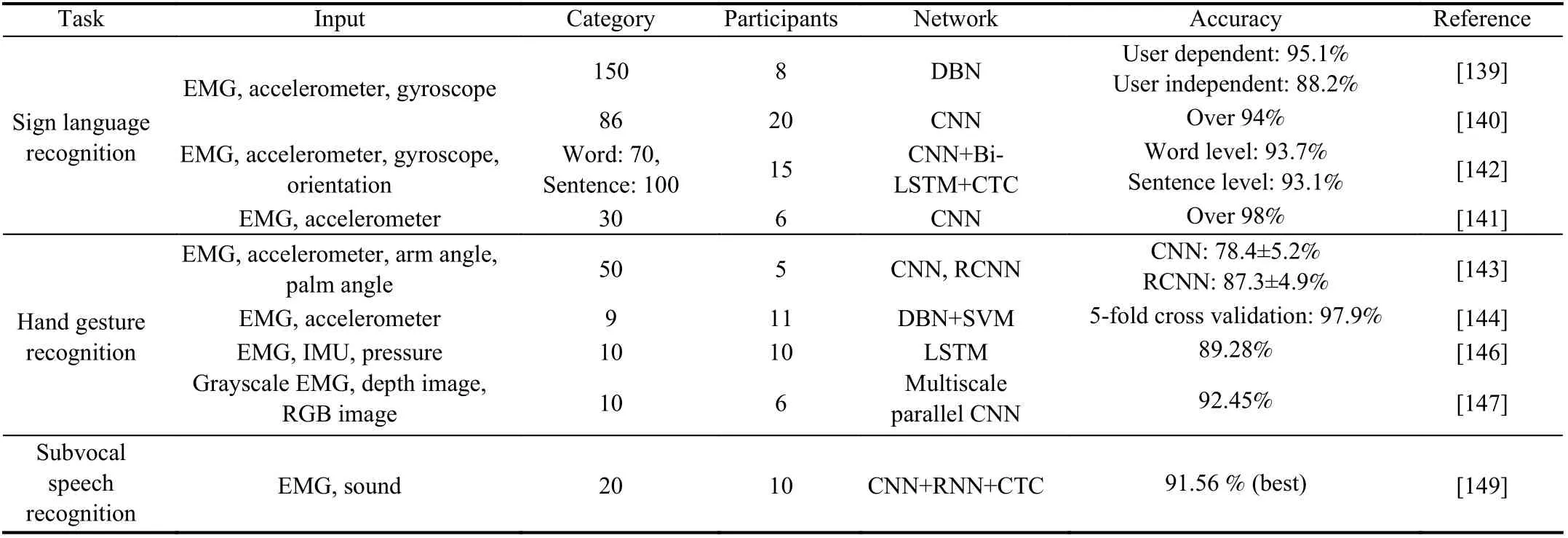
TABLE V MULTIMODAL SENSOR FUSION TASKS
Deep transfer learning takes advantage of both deep learning and transfer learning by combining the feature learning ability of deep learning with the distribution adaption ability of transfer learning. Fine-tuning is widely used for deep transfer learning-based frameworks [150], [151]. To reduce the error of subject-transfer, Kim et al. [152] propose a framework that decodes hand movements robustly using supportive CNN classifiers. The classifiers are pre-trained by the data from several subjects, and then, they are fine-tuned by part of the target data. Finally, the gesture is decided by the voting of the supportive CNN classifiers. The results show improvement for both healthy and amputee subjects.
Du et al. [49] handle the inter-session problem using the deep learning-based domain adaptation mechanism, which is a multi-stream extension of AdaBN [153]. It selects instantaneous EMG with majority voting instead of the classical sliding window method to make a decision. Côté-Allard et al. [154] proposed the self-calibrating asynchronous domain adversarial neural network (SCADANN) to solve the inter-session problem, and the best accuracy improves by 8.47%. Côté-Allard et al. [155], [156] propose a framework of CNN augmented by transfer learning. The architecture was inspired by progressive neural networks [157] together with a multi-stream AdaBatch scheme [49] to transfer stable and general features to a new subject.
Sosin et al. [107] estimate continuous hand gestures using RNN and adversarial domain adaptation (ADA). The result shows improvement for inter-subject accuracy but a decline for inter-session accuracy. Côté-Allard et al. [158] improve the inter-subject performance with the adaptive domain adversarial neural network (ADANN), which increases the accuracy by 19.40% more when compared with a baseline algorithm. Moreover, the topological structures of deep learning-based features are analyzed in contrast with handcrafted features, which give the facility to the hybrid featurebased classifier.
In addition, deep transfer learning has also been used for augmenting the performance of within-session gesture classification tasks solely for improving accuracy [159].Within session means a shorter time interval of the training dataset and the testing dataset, with no prolonged time rest within the same session. EMG signals are unstable, and it changes even within the same session, which leads to the distinction of their feature domain. Deep transfer learning can help to learn a better representation between the two domains,thus improving the evaluation accuracy. The results of [159]show that deep transfer learning can improve the generalization ability on the test dataset.
For the inter-session problem, a factor that affects long-term performance is user adaption, which means user adapts to HMI devices with time passing by. The way man adapts to the machine can involve two aspects: short-term adaption by visual feedback [160] or long-term adaption even without feedback [161]. EMG signals change its attribute after a period, but users can adapt to the changes to some extent.However, it can be time-consuming because of complicated user recalibrations. To realize a more intuitive and efficient human-machine interface, we should determine some common and invariant information from EMG signals directly despite the diversification of EMG signals and user adaption. Deep transfer learning may be the right choice for solving this question by determining invariant information inside EMG signals at different sessions.
In addition to deep transfer learning, the performance of deep learning for inter-session/subject has also been evaluated in [121], [123], [126], [162]. The features learned by deep neural networks can share similar distributions that are constant across different subjects/sessions.
The representative papers are depicted in Table VI. In general, deep transfer learning can provide a chance for a more opportune human-machine interface in which the pretrained models can be adapted to the same user after a while,or to new users with less time or even no re-calibration time.
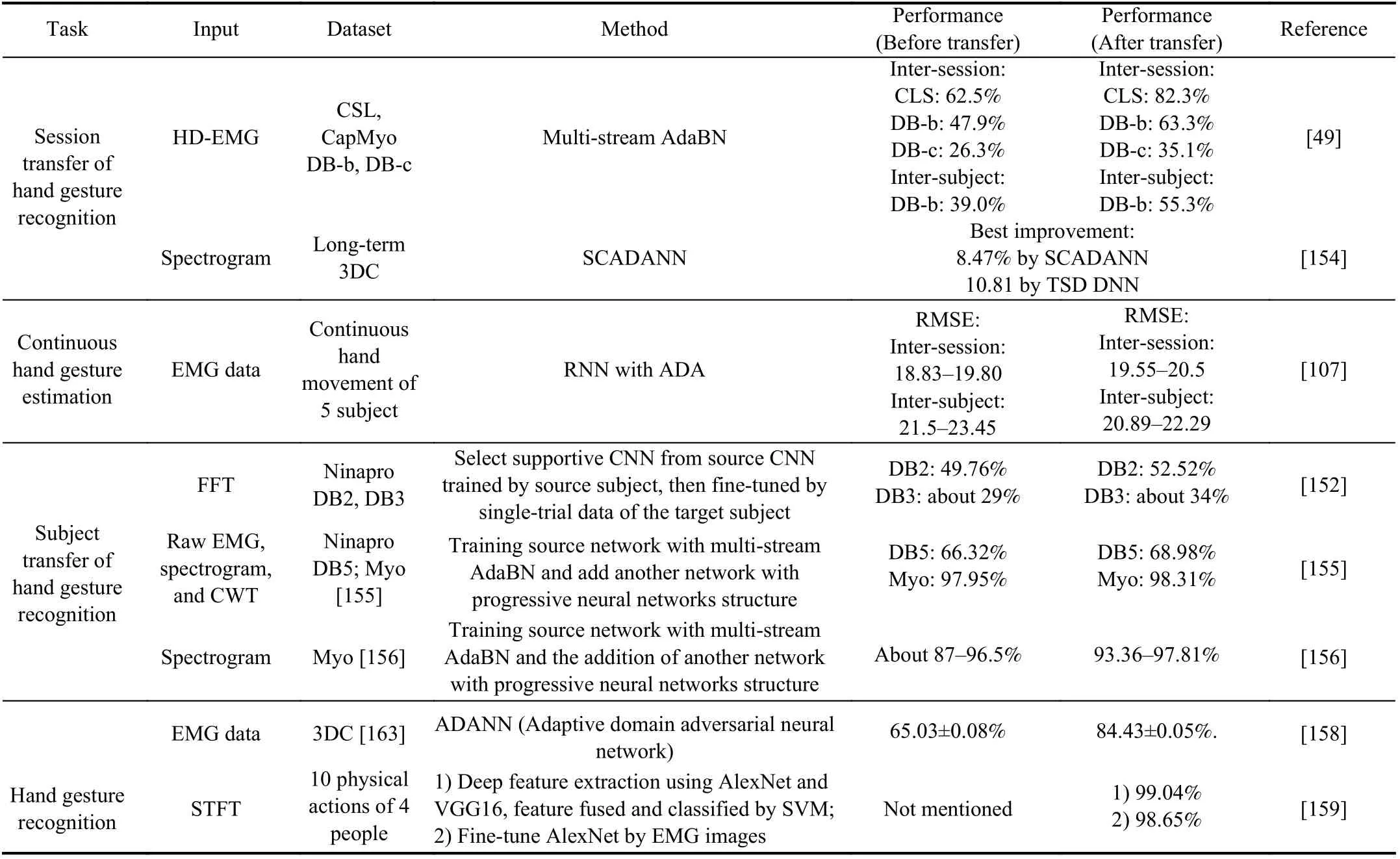
TABLE VI REPRESENTATIVE STUDIES OF INTER-SUBJECT/SESSION
C. Robustness Under Non-ideal Conditions
It is generally accepted that the performance of EMG pattern recognition is easily affected by many surrounding noise sources, such as electrode shift, muscle fatigue, physical friction, sudation, and so on. These factors can be called nonideal conditions [164], which often occur out of the laboratory. Deep learning can pave the way for designing robust and stable algorithms for these problems. This section focuses on four questions: electrode shifts, data augmentation,limb position, and muscle fatigue.
Although the pattern of an EMG can be decoded accurately in the laboratory, the performance is not strong against the electrode shift [165], which occurs when the subject wears the electrodes during daily life, and the consequences can be catastrophic. Even a 1 cm shift can lead to a sharp decline in the performance [165]. Deep transfer learning, which has been used in the question of inter-subject/inter-session, can also be used to relieve the effect of electrode shift. Ameri et al. [52]attempt to solve the problem using the deep transfer learning method. A CNN-based deep neural network is pre-trained using EMG data acquired before electrode shift and then finetuned using data after a roughly 2.5 cm shift. The performance is based on the outcomes of an SVM-based method and adaption approaches based on LDA and QDA [166]-[168].
Data augmentation can raise the amount of EMG data and improve the durability of external disturbances. The transformed data with added white noise or wrong placement of electrodes [124], in combination with the original data will be used for pattern recognition. The algorithm can improve online performance if human-added noises occur in the online testing phase. Yang et al. [124] choose several data augmentation approaches, including reverse placement of electrodes, random switch of channels, cross-arm, electrode shifts, and electrode breakdown, according to common errors during EMG acquisition. The results show that data augmentation can improve precision and durability under disturbances. Dantas et al. [169] develop a dataset aggregation approach named DAgger that can improve long term performance within 150 days. On one hand, deep learning is data-dependent, and thus, more data means better performance. On the other hand, it is more stable, and abstracted features can be obtained through deep neural networks with augmented datasets.
Limb position can be another critical factor that often leads to poor testing performance if the limb position is different from the training stage while performing the same gesture. Yu et al. [170] solve this problem by a mixed-LDA classifier,which reaches an accuracy of 93.6% over five upper limb positions for seven hand gestures. Mukhopadhyay et al. [74]choose fully connected DNN with multiple hidden layers for recognizing eight hand gestures under five arm positions. The accuracy is 98.88%, which outperforms four types of traditional machine learning-based methods. The DNN-based method simplified the feature extraction/selection step, which can determine invariant features under different limb positions in a unified scheme.
Muscle fatigue ordinarily occurs after long periods of strenuous exercise. It is usually divided into states that include fatigue, non-fatigue, and transition-to-fatigue [171]. Fatigue can cause serious injury in the course of man-machine cooperation. The correct prediction of muscle fatigue is of great significance to the safe and stable human-machine interface. Su et al. [172] address muscle fatigue of the upper limb using DBN with raw EMG as input. The result is comparable to the SVM-based method.
Methods of multimodal sensing and inter-subject/session are also techniques that attempt to improve the robustness in real life. There are fewer studies that focus on these questions with deep learning techniques, and thus, further attention should be given to it in the future.
V. APPLICATIONS
Deep learning has been widely used in EMG-based HMI systems. However, most studies focus on offline performance with multifarious datasets. Online performance in physical systems, such as with prosthetic hand control, exoskeleton robot operation, and so on, should be seriously considered.This section will discuss the online performance evaluations of deep learning-based systems.
EMG-based hand gesture classification can serve for prosthetic hand control, robot arm control, and so on.Yamanoi et al. [85] propose a CNN-based framework to control a myoelectric hand, which was motivated by 13 motors with wire-pulling methods. The STFT of the EMG is reconstructed as an image to submit to the network. Once the posture is classified, the hand will move to the predefined position if the posture remains unchanged. The whole system runs in a notebook PC using the pre-trained model. Similar studies as in [71], [173], [174] control robot hands using EMG with deep learning methods. In addition to the robot hand,Redrovan et al. [175] control several quadrotors with hand gestures that are recognized through CNNs with EMG signals.Allard et al. [65] guide a 6-DOF robot arm named JACO using hand gestures captured by the Myo armband. The spectrogram of the EMG is used for classification by the CNN network. Seven gestures are mapped to different actions of the robot arm. The whole system runs on a laptop with a GPU.The performance is in a class with state-of-the-art performance guided by joysticks. Côté-Allard et al. [156] also guide JACO with EMG and IMU of Myo Armband, and the performance is similar to the joystick being controlled by a human. Nasri et al. [173] teleoperate a robot named Pepper with hand gestures recognized by GRU network. Mendes et al. [176] control a collaborative KUKA iiwa robot using EMG-based hand gestures recognized by CNN.
Most studies train deep neural networks using a highperformance server with a powerful GPU. There are studies such as [53] that provide an online system based on a low-cost GPU named the Nvidia Jetson Nano. Zanghieri et al. [81]train the offline data by TCN using an embedded platform based on an 8-core low power processor named GAP8. In addition, Donati et al. [177] present a neural processing system to classify EMG into two types of hand gestures. It employs a recurrent spiking neural network that runs on a low-cost neuromorphic chip. It shows the potential of designing new network structures that can run on an embedded system. However, the network is specially designed, and thus, it still has a long way to go before running ordinary deep neural networks such as CNN or LSTM on platforms like this.
Some studies estimate the joint angles in real-time, such as[70], [110]. Ren et al. [70] control the exoskeleton robot named NTUHII for upper limb rehabilitation training. A PID controller dominates every DOF of the robot. The deep learning-based model predicts the angle of the future with EMG signals and the angles of the past as input. Then, the predicted angles are fed into the control system with the speed of the velocity that is calculated by the first order of difference of the joint angle. The result of the experiment shows good stability and precision for the online movements of the fourdegree manipulator. Huang et al. [110] prove the possibility of deep learning running in embedded systems with the STM32F4 processor for online angle predicting. It chooses a simple RNN with the relu activation function to make decisions faster and at a lower cost. However, the performance of online controlling devices, such as lower limb exoskeletons is not evaluated.
A combination with other sensors, for example, a camera,can improve online reliability for grasping. The hand posture must stay unchanged if the subject wants to hold an object and place it somewhere else, with EMG signals as the input alone.The object can fall to the ground if any error occurs. Gao et al.[147] design a system for controlling a 7-DOF robot hand using the fusion of EMG, RGB images, and depth images of hand grasping. The three types of data are reconstructed into a 5-dimensional image and sent into a multiscale parallel CNN for gesture classification. The amount of input data is relatively large, but the performance is improved significantly.In this study, EMG, together with visual information is used for gesture recognition. However, research as in [178] decides the target hand gesture by mainly relying upon computer vision, while EMG only works as a trigger signal that reflects whether a user wants to grasp or not. Although this method could be affected by various environmental noise that is inherently in computer vision, it can release human attention during grasping. It improves the flexibility of the system,which means that the user does not need to pay all of their attention to the grasping task to avoid falling or any other errors.
Various applications in the online system are summarized and illustrated in Table VII. In general, deep learning has been used in some real systems, and the performance shows that the decoding method is effective for real-life applications.However, there are still questions such as computational cost,environmental disturbances, satisfaction, and so on.Additional research should focus on these questions.
VI. DISCUSSION
EMG is fragile and can be easily affected by many factors,which affect the reliability and precision of the recognition performance. These reasons boost the productivity of deep learning in EMG processing. In this part, we will discuss theadvantages, challenges, and opportunities that are brought about by deep learning for EMG-based HMI tasks.
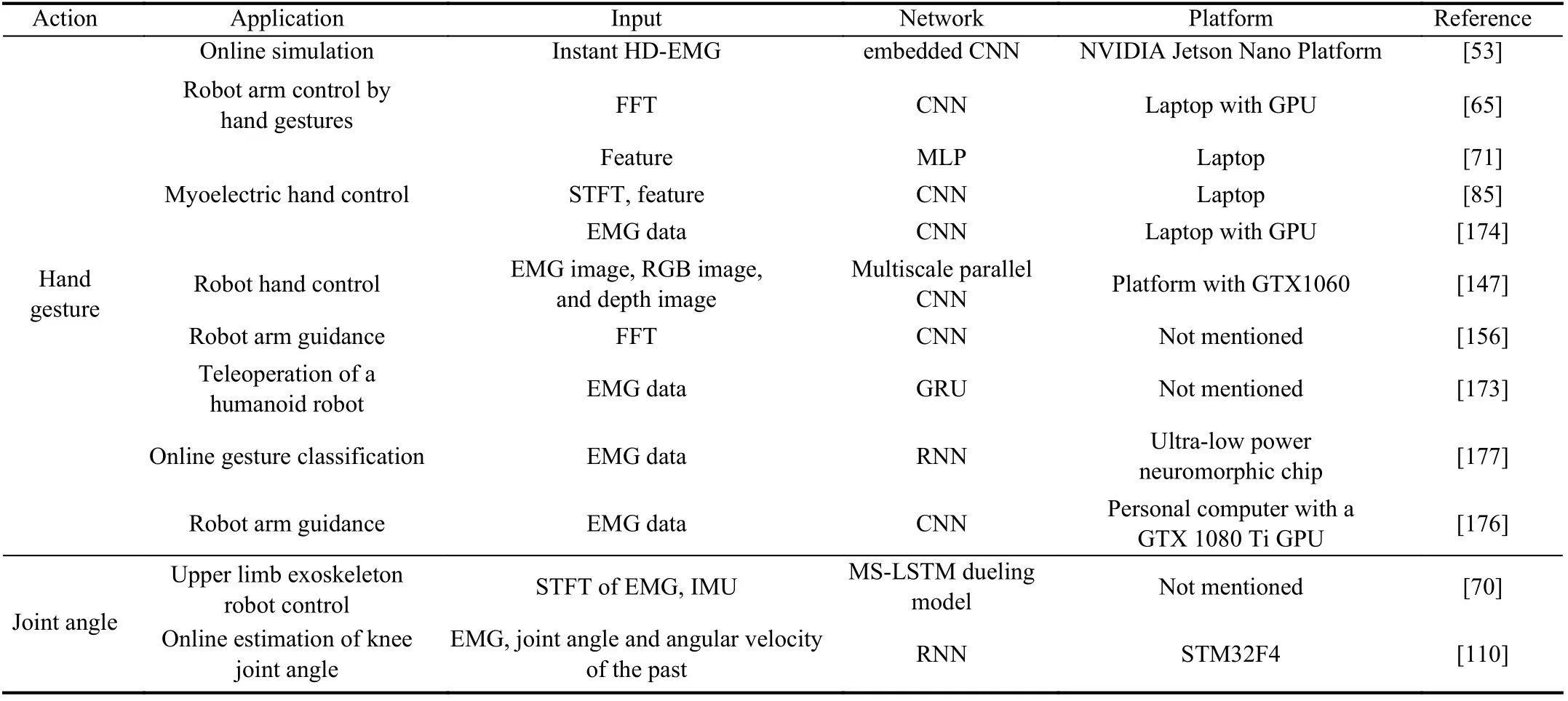
TABLE VII APPLICATIONS IN PHYSICAL SYSTEM
Deep learning has the advantage of learning a better representation from EMG data to obtain higher precision,which is better than hand-crafted features. It has shown better performance than machine learning methods with feature engineering, as shown for movement classification tasks in[79], [82], [89], [90], for angle regression in [51], [56], [70],for force prediction in [123], and so on. By adjusting the parameters of the deep neural networks and exploring new network structures, more discriminant features can be extracted. In addition, deep learning can narrow the heterogeneity gap of different sensors in high-level feature space, which is important for performance enhancement. Multiple sensor fusion is an important method for improving the reliability of the system. The heterogeneity data gap between the different sensors can lead to a decline in the performance, in which each mode of data has a bad influence on the others. Deep learning can narrow the heterogeneity gap of the different sensors in high-level abstraction space, ensuring that the performance is better than the single modal sensor method,which is important for performance enhancement.
The primary challenges that exist for now are the computational cost and the dependency of the data. For the first problem, although a high-performance computer with a powerful GPU can be easily accessed in most laboratories today, it is difficult to run the deep network online in portable systems, which influences applications in daily life. Possible solutions include designing embedded neural networks that contain fewer parameters to solve the original question,developing a system with an embedded GPU that is smaller with a lower power cost, or sending the acquired data to remote GPU servers and returning the results. For the second problem, the solution can also be varied. On the one hand,publicly open datasets such as Ninapro provide sufficient data for performance evaluation. On the other hand, data augmentation methods can be a good choice for increasing the amount of data and improving stability under noisy conditions. Furthermore, few-shot learning methods are worthwhile to try, and these require few samples to learn faster and better.
Deep learning brings us new chances to handle the questions of EMG pattern recognition. It provides a new way of determining how to enhance the robustness of the EMG recognition algorithms. A wide gap exists between laboratory EMG research and commercial myoelectric control systems owing to the lack of robustness against various disturbances[78], which is also an adverse factor for other systems.Electrode shift, electrode drop, individual differences, muscle fatigue, sweatiness, and so on, which often appear in our daily use, can lead to poor accuracy. The possible solution includes learning unchangeable features between normal EMG data and disturbed EMG data with deep neural networks, and transferring knowledge from normal data to augmented data with deep transfer learning, among other actions.
Deep learning brings an opportunity for more concise and efficient neural-machine interaction systems. It is suggested by Farina et al. [78] that neural information extracted from EMG signals could help to design extremely accurate HMI systems. Neural information extracted by blind source separation or morphological matching could be a novel path to rejecting uncorrelated information and separate information that is stable under various disturbances. This approach has been tested for motion intention estimation, as depicted in[179]-[183]. Xiong et al. [181], [182] try to estimate movement intention through sEMG decomposition, and the waveform information of MUAP is used for hand gesture classification. They are the first team to estimate movement intention by neural information decomposed from sEMG.Farina et al. [183] choose the discharging time of the MU for movement classification, and the performance is evaluated with three patients after TMR surgery. Chen et al. estimate hand gestures [179] and kinematics [180] using the discharging time information of MU, and the performance outperforms hand-crafted features. Nevertheless, learning features from MUAP is still a necessary procedure of their method, which makes it more complicated than extracting features from EMG signals directly. Deep learning has great potential for simplifying this procedure in an end-to-end form.It can be used for mining information related to human motion inside the MUAP automatically, which avoids feature extraction and selection. In addition, the MUAP can provide a new way of thinking for analyzing the feature maps that are extracted from the EMG signals by deep neural networks because similar topological structures could exist between them. Thus, feature visualization of a deep network could help improve understanding of the neural code inside the EMG.
VII. CONCLUSION AND FUTURE WORK
Deep learning has shown an expanding tendency in biomedical signal pattern recognition over the past several years. In this article, many papers that decode EMG using deep learning methods are reviewed. Typical HMI tasks, such as movement classification, angle/force prediction, and more,are introduced in detail. Several hot-spot issues, such as multimodal sensor fusion, inter-subject/session, and robustness, are also presented to convey the latest progress in recent years. These new topics are built for convenient and reliable HMI systems. The applications are introduced to show recent experimental progress. The merits, drawbacks,and prospects are discussed to present a comprehensive analysis of the current conditions and to pave the way for the coming stages.
In summary, deep learning-based methods are in their infancy for now, and there is still a certain distance to go before their adoption in commercial systems, which means great prospects for the future. In the future, attention should be paid not only to the performance improvements but also to the system implementation. With the help of this technique, more advanced systems will be developed to raise the quality of life of the user. Certain directions should be considered carefully,which are summarized as follows.
A. Feature Learning
The automatic feature learning ability from EMG data is quite appealing for improving the recognition performance.Many networks in other fields, such as natural language processing, computer vision, and newly emerged networks(capsule network [163], graph network [184], and so on) are unexplored, which shows the great potential for EMG decoding as better features can be extracted, and thus, higher performance can be achieved. Additionally, combining the features learned by deep neural networks with machine learning as in [37], [38] could also be a good choice.
B. Domain Adaption
Deep transfer learning has the ability of domain adaption,which is quite worthwhile for model generalization under nonideal conditions. It has been used by some research to solve the problem of inter-subject/session, as mentioned in Section IV.The performance might require further improvement for online use. Other problems, such as electrodes shift/drop,noise, and muscle fatigue, in which the testing data has a distinctive distribution in contrast with the training data, are seldom considered, and they are worthy of future development.
C. EMG Decomposition
Neural coding acquired by decomposing EMG signals into motor unit spikes has been used for human intention recognition, which could help build a robust and accurate neural-machine interface. Uncorrelated information can be removed, and thus, high precision can be reached. This approach retains the nature of the EMG signals, which have physiological meaning. The relationship between the MUAP and human motion intention can be estimated by deep neural networks, which is simple compared with extracting features from the MUAP.
D. Portable Systems
Future research should show solicitude for physical systems that could improve the living standards of post-stroke patients or amputees. The low equality of these patient’s EMG signals requires better decoding methods, and thus, a deep learningbased scheme could help the application of EMG in these scenarios. The designed system should be portable, and these embedded systems should be easy to carry. Methods such as parameter shrinking, embedded GPU, and remote servers should be explored for solving the question of computational cost.
杂志排行

IEEE/CAA Journal of Automatica Sinica的其它文章
- Ground-0 Axioms vs. First Principles and Second Law: From the Geometry of Light and Logic of Photon to Mind-Light-Matter Unity-AI&QI
- Nonsingular Terminal Sliding Mode Control With Ultra-Local Model and Single Input Interval Type-2 Fuzzy Logic Control for Pitch Control of Wind Turbines
- Distributed Secondary Control of AC Microgrids With External Disturbances and Directed Communication Topologies: A Full-Order Sliding-Mode Approach
- Deep Learning in Sheet Metal Bending With a Novel Theory-Guided Deep Neural Network
- Autonomous Control Strategy of a Swarm System Under Attack Based on Projected View and Light Transmittance
- Computing Paradigms in Emerging Vehicular Environments: A Review