基于深度学习SSD目标检测算法的混凝土结构裂缝识别
2021-04-16李想熊进刚
李想,熊进刚,b
(南昌大学a.建筑工程学院;b.江西省近零能耗建筑工程实验室,江西 南昌 330031)
钢筋混凝土产生裂缝是土木工程中不可避免的问题。当前,常用的混凝土裂缝检测方法还是以人工检测为主,但是人工检测存在工作量大、效率低、过于依赖经验等缺点。除了人工检测外,还存在热成像检测、超声波检测、荧光磁粉检测、渗透检测等无损方法,但都存在工序复杂、价格昂贵等缺点。因此,如何能够高效而又经济地检测混凝土裂缝,成为了土木工程中亟待解决的问题。
人工智能技术正处于第3次发展浪潮,随着深度学习理论的发展、计算机性能的提升和数据量的扩大,把人工智能技术应用到土木工程领域将是未来的一个发展趋势。当前,已经有许多学者进行了人工智能检测混凝土裂缝的相关研究。
徐港等[1]采用多种图像连通域特征分析裂缝和噪声的差异结合聚类算法提取出裂缝信息。刘立峰等[2]提出了一种基于高斯尺寸空间和支持向量机相结合的裂缝识别算法。张晶晶等[3]提出一种基于多尺度输入图像渗透模型的混凝土裂缝检测方法。徐国整等[4]基于经典的 U-Net 网络,提出了HU-ResNet卷积神经网络模型识别混凝土表面裂缝。吴秋怡[5]利用金字塔解析网络PSPNet实现路面裂缝检测,实现像素级的裂缝区域识别。高庆飞等[6]结合神经网络与滑动窗口算法,提出了桥梁裂缝定位技术。顾书豪等[7]设计了具有注意力机制和语义增强的特征模块,有效地融合了语义信息和裂缝特征。
根据已有研究,可以发现当前基于传统计算机视觉的裂缝识别方法普遍存在识别受噪声影响大、精度低和漏检率高的问题。而现有的基于深度学习的裂缝识别方法虽然在识别效果和精度上有所提升,但普遍是基于语义分割对裂缝进行识别,识别手段较为单一。因此,本文提出了一种基于深度学习单步多框检测[8](single shot multibox detector,SSD)目标检测的混凝土结构裂缝物体框识别方法。主要思路是利用深度卷积神经网络提取裂缝特征,利用分类预测和回归预测获得裂缝的信息,最终在原图上框选出裂缝的位置,从而达到识别裂缝的目的。
1 实验准备
1.1 开发环境
本研究以python为编程语言,使用PyTorch深度学习框架,以PyCharm2020为编程环境、Anaconda为库管理器,涉及到的依赖库主要有OpenCV、labelimg、TensorboardX、cuda和cudnn。使用的GPU为Nvidia GeForce RTX 2070 SUPER(8G),CPU为AMD Ryzen 7 3700X 8-Core。
1.2 数据集
数据集分别使用制作的CCIC裂缝图像数据集[9-10]和BCD裂缝图像数据集[11]。CCIC裂缝数据集的图像如图1所示,BCD裂缝数据集的图像如图2所示。可以发现2个数据集几乎涵盖了工程中各种常见的混凝土裂缝形式(纵向、横向和斜向裂缝等),使本文研究样本具有充分的代表性。

图1 CCIC数据集裂缝图像Fig.1 Cracks images of CCIC dataset

图2 BCD数据集裂缝图像Fig.2 Cracks images of BCD dataset
1.3 数据标签的制作
使用labelimg工具生成训练所用的数据标签。labelimg是深度学习中一种常用的标注工具,它可以方便快捷地标注出图片内物体的位置和种类。制作数据标签的详细步骤为:
1) 安装labelimg工具,工作界面如图3所示。
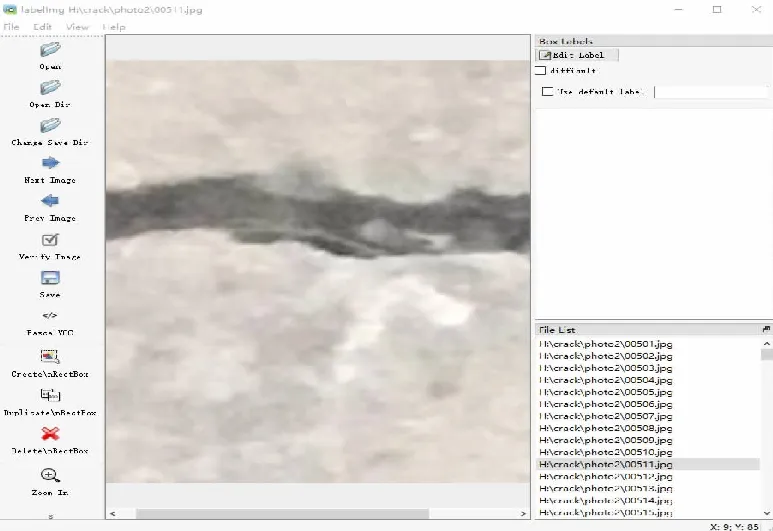
图3 labelimg工作界面Fig.3 Labelimg work interface
2) 打开labelimg工具,通过Open Dir选项指定需要标注的图片集。
3) 手动框选出裂缝的位置。
4) 设定该框选部分的类别。
5) 标注完每张图片都会生成一份XML后缀的文件,该文件用来保存放标签信息,存放XML文件的路径通过Change Save Dir选项指定。生成XML文件的流程如图4所示。
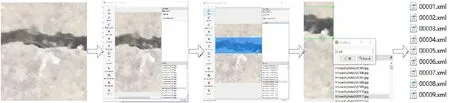
图4 生成XML文件过程Fig.4 Process of generating an XML file
XML标签文件包含原始图片的尺寸、物体的类别和物体的位置信息,如图5所示。其中width=227,height=227,depth=3表示原始图片的尺寸为227×227×3。xmin=1,ymin=52,xmax=227,ymax=114表示框选的位置的右上角的坐标为(1,52),右下角的坐标为(227,114)。name=crack表示该框选部分的类别为裂缝。
利用voc_annotation.py脚本文件,将所有XML标签文件里信息进行整合,并最终保存在crack_train.txt文件中。一个XML标签文件仅仅保存一张图片的位置信息和类别信息,crack_train.txt文件则保存了所有用来训练网络的图片中的位置信息和类别信息。

图5 XML文件详情Fig.5 XML file details
2 网络结构
2.1 网络概述
SSD目标检测算法对输入的图片不断地进行特征提取,提取出许多特征层(Feature map),并将其中的一部分特征层设为有效特征层(Effective Feature map)。每一个有效特征层会将图像划分为大小不同的网格,每个有效特征层上的网格存在着一定数目的先验框(priors box)。再利用回归预测和分类预测来调整每个先验框的位置和种类,结合非极大值抑制(non-maximum suppression)得到最终的预测框。SSD网络结构如图6所示。
2.1.1 有效特征层
有效特征层的高度和宽度代表着将输入进来的图片划分成了高×宽的网格。以3×3×256的有效特征层为例,相当于把输入的图像划分成了3×3的网格,如图7所示。而每个网格上面存在着先验框,利用这些网格和先验框对输入进来的图片进行目标检测,从而获得需要的检测目标。
2.1.2 先验框
有效特征层上的每个网格都人为定义了先验框,这些先验框以网格的中心为中心。以划分为3×3网格的图片为例,如图8所示。每个有效特征层上的单个网格含有的先验框个数不同,先验框与有效特征层的关系如表1所示。
2.2 基础网络
SSD目标检测算法中的基础网络部分由多个卷积层、最大池化层和ReLU激活函数层组成。当输入一张图片时,SSD目标检测网络自动将图片的尺寸调整为300×300×3(宽×高×通道数)大小。将裂缝图片看作长宽都为300、通道数(Channel)为3的特征层。通过卷积核(Kernel)大小为3、填充幅度(Padding)为1的卷积运算和池化核与步长(Stride)都为2的最大池化运算,将特征层的长度和宽度进一步压缩,并且持续扩大特征层的通道数。随着卷积和池化运算的不断进行,会产生许多特征层。当进行完最后一次最大池化时,先进行一次卷积核大小为3、填充幅度为6、膨胀因子为6的卷积,用来模拟全连接层。再进行一次卷积核大小为1的卷积。最终输出的特征层长宽为19,通道数为512。再将其中一部分特征层划分为有效特征层。被划分为有效特征层的特征层有:Conv4-3和Fc7-2,它们的长宽分别为38和19,通道数都为512。基础网络各层的信息如表2所示。其中Convolution表示卷积运算、ReLU表示ReLU激活函数,Maxpooling表示最大池化运算,Kernel表示卷积核大小,Padding表示填充幅度,Stride表示步长,Dliation表示膨胀因子。
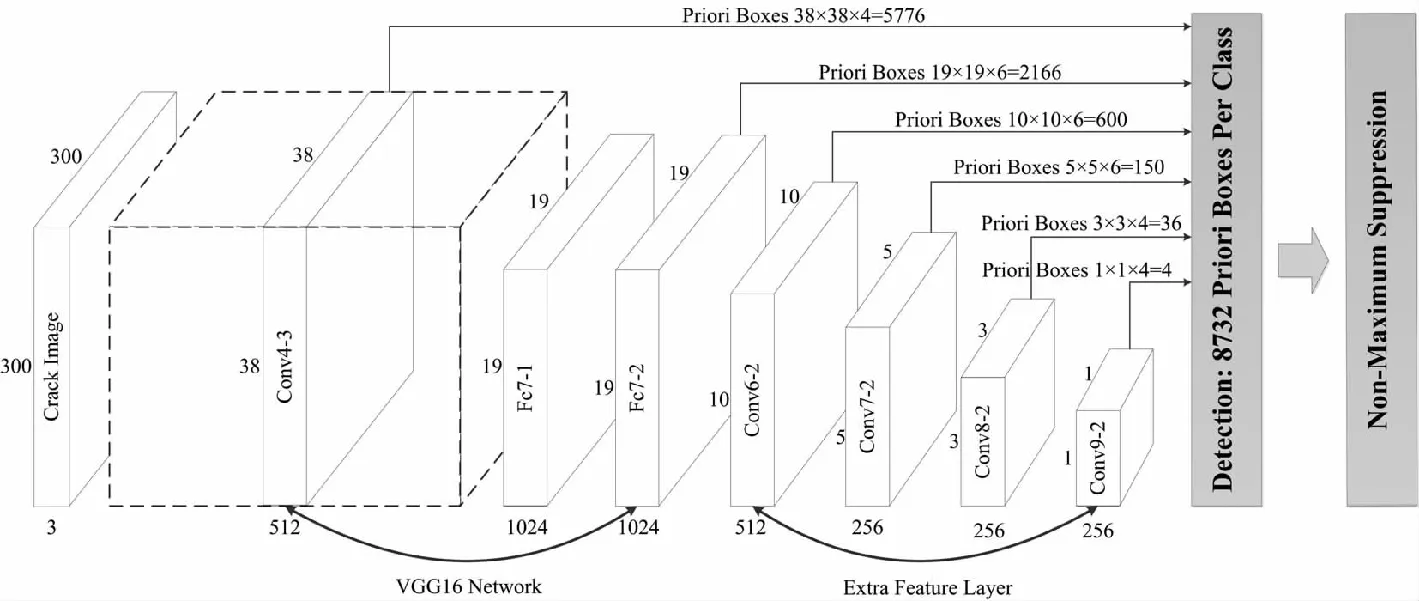
图6 SSD网络结构Fig.6 Single shot multibox detectornetwork structure

图7 裂缝图片的网格划分Fig.7 Grids division of crack images

图8 网格上的先验框Fig.8 Priori boxes on the grid
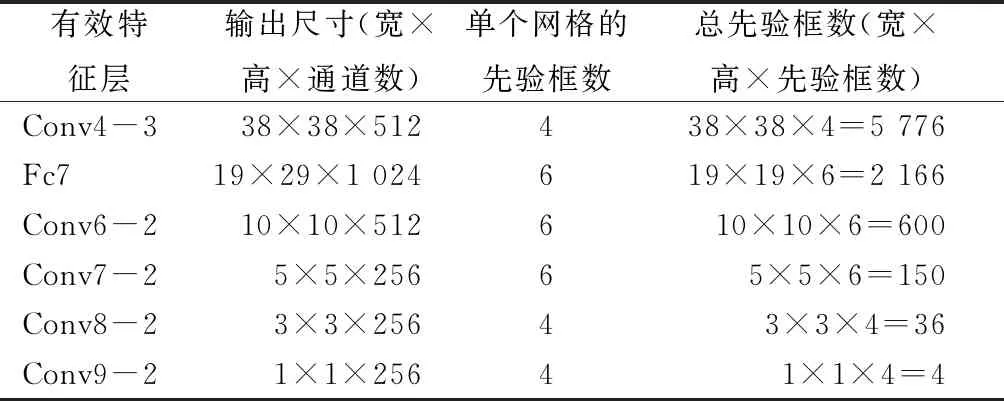
表1 先验框与有效特征层的关系Tab.1 Relationship between the prior frame and the effective feature layer
2.3 辅助网络
特征层经过基础网络之后继续向后传递,进入辅助网络。辅助网络利用卷积运算,继续压缩特征层的长度和宽度。随着卷积运算的进行,同样会生成许多特征层。当进行完最后一次卷积运算时,会输出一个长度和宽度都为1、通道数为256的特征层。将其中一部分特征层划分为有效特征层。被划分的有效特征层有:Conv6-2、Conv7-2、Conv8-2、Conv9-2。辅助网络各层的信息如表3所示。
2.4 预测网络
预测网络主要用来完成回归预测和分类预测的任务。回归预测用来获得预测框的位置,分类预测用来获得预测框的类别。预测网络的各层信息如表4所示。
进行回归预测时,需要对有效特征层的所有先验框进行计算。利用卷积运算对先验框进行调整,从而得到最终预测框的位置。因此,对获取到的有效特征层进行通道数为4×np的卷积,其中np为该有效特征层的单个网格拥有的先验框数量。因为调整一个预测框的位置需要中心点坐标的偏移量x0、y0,预测框的宽度w和高度h,所以进行卷积运算的通道数为4×np。
进行分类预测时,同样需要对有效特征层的所有先验框进行计算。所以,对获取到的有效特征层进行一次通道数为nc×np卷积,其中nc是需要区分的类别数。因为本文只针对图像是否存在裂缝进行研究,共计2类:背景类和裂缝类,所以nc=2。
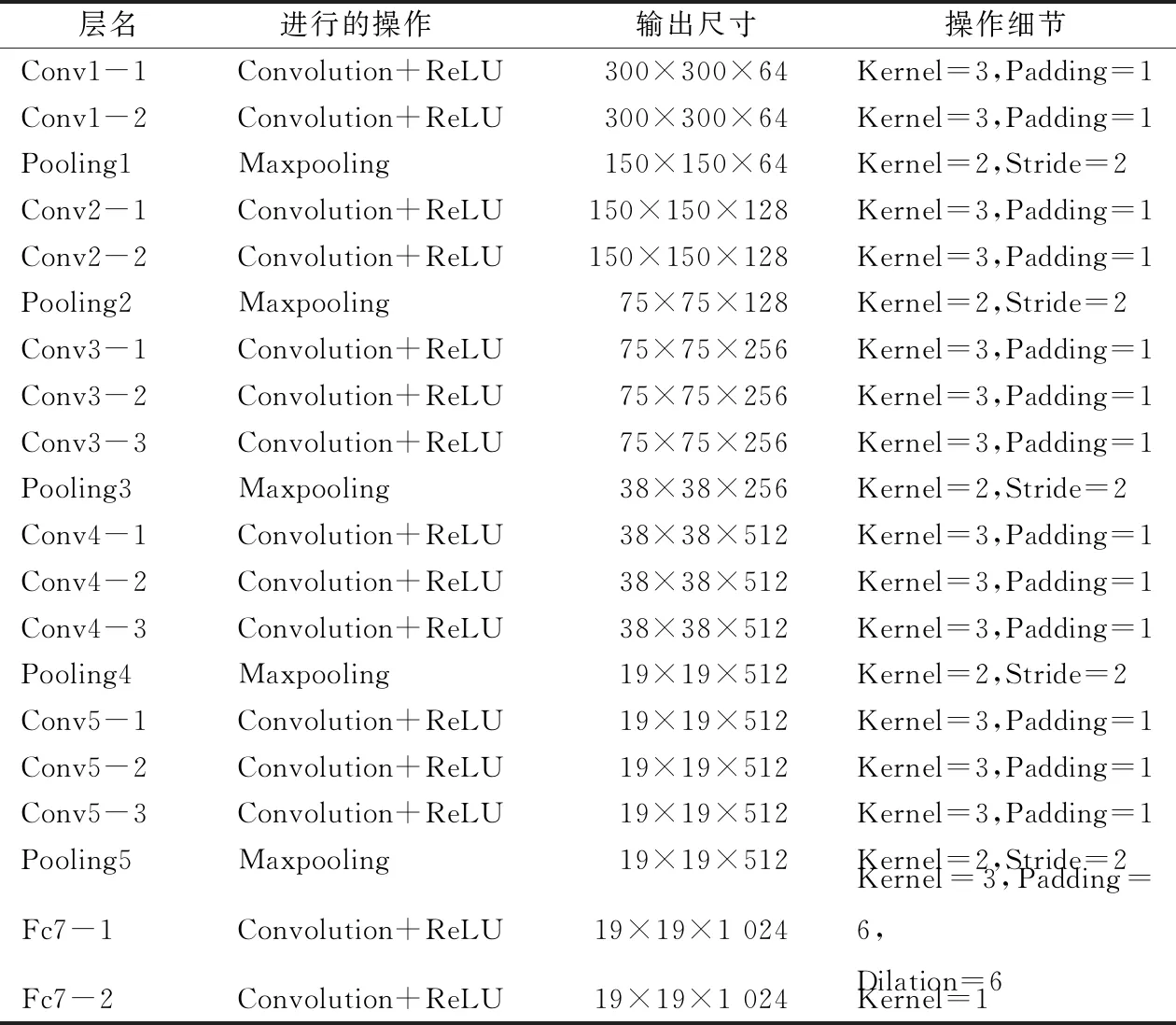
表2 基础网络的各层信息Tab.2 Layers of information in the basic network

表3 辅助网络的各层信息Tab.3 Layers of information in the auxiliary network

表4 预测网络的各层信息Tab.4 Layers of information in the predict network
3 训练和检测
3.1 训练过程
分别使用2 000、4 000、6 000、8 000张含有裂缝的图片。其中90%作为训练集,用于进行模型的训练;剩下10%作为测试集,用于测试模型检测的效果与精度。
先进行超参数设置。由于GPU的显存不充足,所以将一次训练所用的样本数(Batch Size)设置为8。将学习率(Learning Rate)设置为1×10-5,学习率表示网络训练的快慢程度。学习率大,网络训练速度快,但是容易出现损失值振荡;学习率小,损失值收敛效果好,但是训练速度慢。定义最小置信度为0.5,代表着预测结果的得分若大于0.5,则将这个结果留存待用。总共训练200个轮次(Epoch),更新一个轮次表示训练中所有训练数据均被使用过一次,即训练了一个周期。应用迁移学习的思想,使用预训练好的权重达到加速模型的训练的目的。之后读取crack_train.txt文件获得进行训练的样本信息。
之后开始训练。载入SSD目标检测算法模型,将每个批次(Batch)所用的图片和标签传入到网络当中。然后进行梯度清零、计算损失值和反向传播进行模型的参数更新。每一个轮次保存一次权重,共有200份权重文件。之后的预测环节使用第200个轮次生成的权重文件进行预测。训练过程示意图如图9所示。
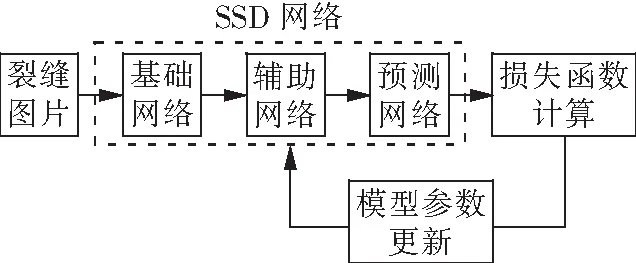
图9 训练过程示意图Fig.9 Schematic diagram of training process
3.2 检测过程
因为使用的图片尺寸为227×227,而SSD目标检测算法需要使用300×300尺寸的图片。因此,需要检测的图片进行预处理,具体做法为对进行检测的图片进行填充使图片尺寸变为300×300。之后把图片传入网络当中进行检测并获得置信度最高的200个预测框的位置信息。之后对这200个预测框的置信度进行遍历,依次判断先验框的置信度是否大于最小置信度,如果预测框的置信度都小于最小置信度,那么将原图返回。如果存在大于最小置信度的预测框,那么结合非极大值抑制(非极大值抑制就是只保留最大值)只将置信度最大的预测框进行绘制,得到最终的检测结果。检测过程示意图如图10所示。
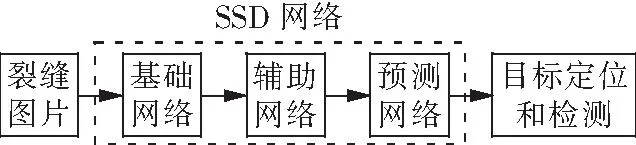
图10 检测过程示意图Fig.10 Schematic diagram of detection process
4 识别效果和精度
4.1 识别效果
利用测试集图片进行检测的结果如图11所示,列举出测试集中的部分(40张)图片的识别结果如图12所示。其中方框为预测框,将被识别的裂缝框选出来,左上角的标签“crack 0.84”代表这张图片识别的种类和置信度。可以发现,该模型对于横向、纵向和斜向裂缝都能进行较为精确的识别。再进行随机图片的裂缝识别,以验证模型的普适性,如图13。可见,该模型对于网络上随机选取的裂缝图片也有较好的识别效果。

图11 单张测试集图片识别效果Fig.11 Recognition effect of single test set image
4.2 识别精度评价
利用损失函数的收敛情况和所有类的平均精确度(mAP)值来评价模型的好坏。通过损失值这个指标来反映训练时的状态,从而更新权重参数。具体的表现形式为损失值越小,权重越优化,模型越精确。通过mAP来量化模型的精确度,具体表现形式为mAP值越大,模型越精确。

图12 部分测试集图片识别效果Fig.12 Recognition effect of some test set image

图13 互联网图片识别效果Fig.13 Recognition effect of Internet image
4.2.1 回归预测损失值
进行回归预测的目的是获得预测框的位置。训练过程中回归预测损失值变化曲线如图14所示。横坐标为轮次数,最大轮次数为200;纵坐标代表回归预测损失值。可以看出,在不同训练样本数的条件下,回归预测的损失值变化并不明显,但都是在运行到第40个轮次附近时收敛。当回归预测的损失值收敛时,表示回归预测的损失值不会继续下降,所以网络的权重不会更新太多,获得预测框位置的准确度也不会继续提升。
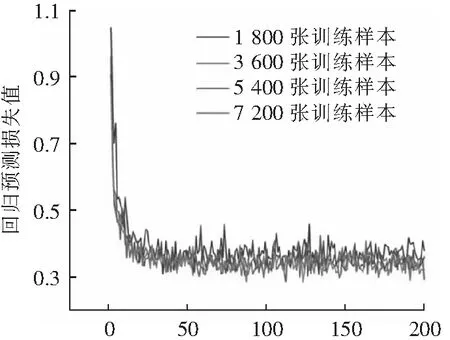
轮次数图14 回归预测损失值变化曲线Fig.14 Regression prediction loss curve
4.2.2 分类预测损失值
进行分类预测的目的是获得预测框的种类。训练过程中分类预测损失值变化曲线如图15所示。横坐标为轮次数,最大轮次数为200;纵坐标代表分类预测损失值。可以看出,在运行到第50轮次附近时损失值收敛。可以看出,在训练样本越多时,分类预测损失值收敛时越小,且在样本数较少时明显,随着样本数的提升,损失值收敛变化的越小。与回归预测类似,当分类预测的损失值收敛时,获得预测框种类的准确度也不会继续提升。
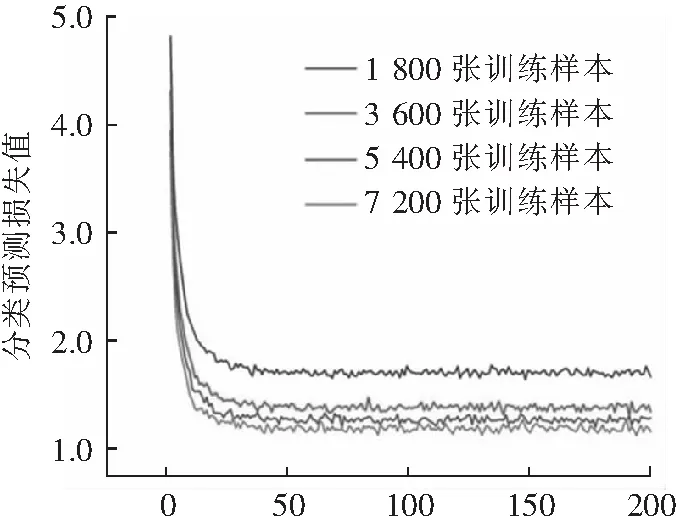
轮次数图15 分类预测损失值变化曲线Fig.15 Classification prediction loss curve
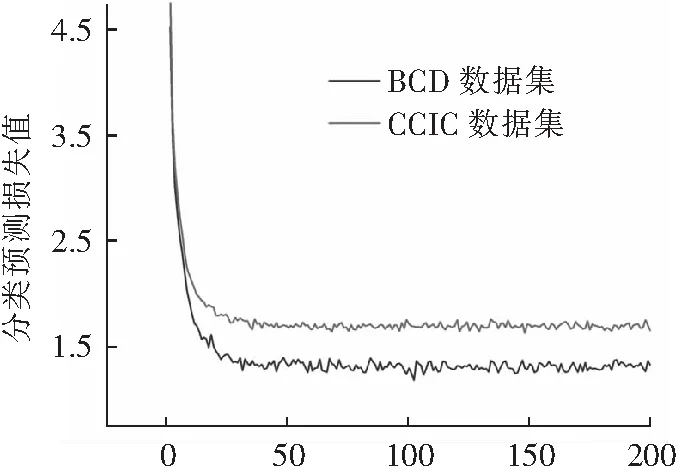
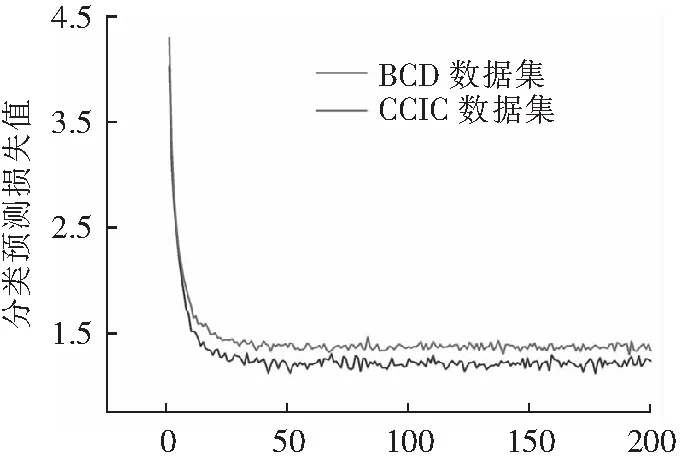
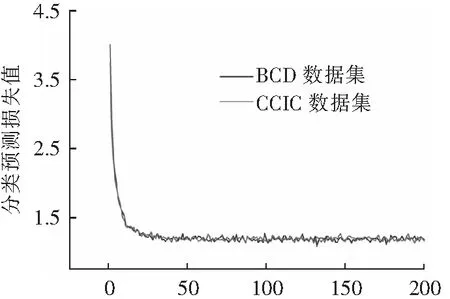
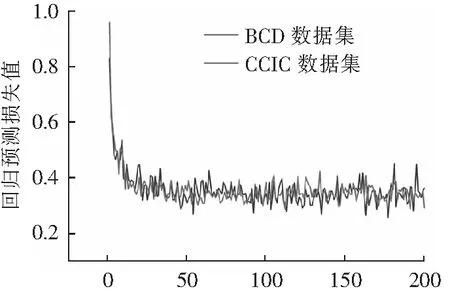
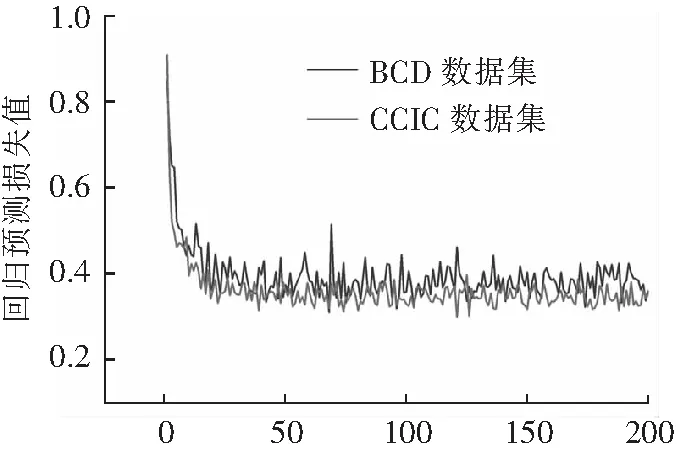
4.2.3 CCIC数据集和BCD数据集训练对比
为了检验裂缝训练图像的样本代表性,使用CCIC和BCD 2种不同的数据集样本进行训练,并将二者的损失值进行对比,图16为2种数据集的分类预测收敛后的损失值对比,图17为2种数据集的回
轮次数(a) 1 800张裂缝图片
轮次数(b) 3 600张裂缝图片

轮次数(c) 5 400张裂缝图片
轮次数(d) 7 200张裂缝图片图16 分类预测损失值对比Fig.16 Comparison of loss value after classification prediction

轮次数(a) 1 800张裂缝图片
轮次数(b) 3 600张裂缝图片
轮次数(c) 5 400张裂缝图片

轮次数(d) 7 200张裂缝图片图17 回归预测损失值对比Fig.17 Comparison of loss value after regression prediction
归预测收敛后的损失值对比。结果表明:对于分类预测而言,随着训练样本数目的提升,不同数据集训练之后的分类预测收敛后的损失值趋于一致。说明数据集的种类对于分类预测的影响不大,单一数据集的样本代表性较好。而对于回归预测而言,CCIC数据集的回归预测收敛后的损失值原本是小于BCD数据集的,可随着训练样本数目的提升,CCIC数据集的回归预测收敛后的损失值变得大于BCD数据集的回归预测收敛后的损失值。说明数据集的种类对于回归预测的影响较大,单一数据集的样本代表性较差。
4.2.4 平均准确度均值(mAP)计算
如图18、图19所示,框1为真实框,框2和框3为预测框。框2为识别准确的框,框3为识别不准确的框。当预测框和真实框的IOU>0.5时被认为是识别准确,IOU<0.5时被认为是识别不准确。其中IOU衡量预测框和真实框的重合程度。计算IOU的公式为:
(1)
其中:Sn为交集的面积;Su为并集的面积。

图18 识别准确的结果Fig.18 Results of recognition accurate

图19 识别不准确的结果Fig.19 Results of recognition inaccurate
AP(average precision)表示平均精确度。而mAP表示所有类的AP求平均值。因为本模型为检测裂缝,所以只有一个类(背景类不算),因此AP=mAP。计算训练样本个数为1 800、3 600、5 400、7 200时的mAP,分别为94.78%、95.29%、96.92%和98.5%。可以发现,mAP普遍在95%以上,因此模型拥有较高的精确度。
5 结语
1) 本研究基于SSD目标检测算法为混凝土的裂缝检测提出了一种新的方式。结合无人机航拍技术可以检测到那些人工难以到达位置的裂缝,极大地节省人力物力,并且为深度学习应用到土木工程提供了参考。
2) 本文提出的识别方法对混凝土裂缝的识别效果较好,且具有一定的普适性。
3) 训练使用的数据集的样本代表性有待提升。
4) 该识别系统对细微裂缝识别效果有待提升。
