基于高性能包处理架构VPP 的带内网络遥测系统
2021-04-09潘恬林兴晨张娇黄韬刘韵洁
潘恬,林兴晨,张娇,黄韬,2,刘韵洁,2
(1.北京邮电大学网络与交换技术国家重点实验室,北京 100876;2.网络通信与安全紫金山实验室,江苏 南京 211111)
1 引言
随着云计算技术的飞速发展和云计算市场的持续繁荣,数据中心网络规模迅速增长。为了提升数据中心内硬件资源利用率以及解决高能耗问题,大量虚拟化技术被广泛使用[1],通过硬件资源动态共享和弹性分配,可以节省硬件购买和运维成本,提高资源整体利用率,降低整个数据中心的能耗开销。数据中心的硬件资源通常包括服务器和连接它们的网络设备。服务器的虚拟化可以使单台物理机的硬件资源被多台虚拟机共享[2]。而网络设备的虚拟化则需要能支撑服务器虚拟化之后引入的大容量虚拟地址表和虚拟机在物理机之间的动态迁移[3]。此外,网络设备虚拟化还需要满足不同网络业务之间的流量隔离、隐私控制、安全防护等刚性需求。近年来,基于x86 等通用硬件开发的虚拟网络设备在数据中心网络内被大量部署[4]。这些虚拟网络设备承载了很多高速网络功能(包括隧道网关、交换机、防火墙、负载均衡器等)的软件处理,支撑并发部署多个互不干扰的网络业务,以满足用户多样化、复杂化、定制化的网络业务需求。其中OVS(open vswitch)[5]和VPP(vector packet processor)[6]是两款工业界广泛使用的虚拟网络设备。
随着数据中心网络规模的迅速扩张,网络故障出现的概率急剧上升,且故障感知定位的过程变得复杂而漫长。另一方面,随着数据中心网络定制化业务的逐渐增多,付费用户对网络拥塞所导致的业务服务质量下降也变得更敏感。如何高效地监控和管理数据中心网络流量,快速定位网络故障,开展精细化的流量工程正成为亟待解决的技术挑战[7-8]。在传统网络中,通常使用网络测量的手段来感知网络流量的实时变化。然而,传统的网络测量方案在数据中心网络中的应用面临新的挑战。一方面,在传统的流量监控中,运营商往往通过物理分接端口(例如分光器或流量镜像技术)来采集数据包,这些方案需要在交换机或路由器的物理端口上实施抓包动作。而在数据中心网络中,大多数流量是东西向的,甚至有可能只是从一个虚拟机通过虚拟网络设备传输到位于同一台物理机上的另一个虚拟机,这意味着流量有时不需要离开物理服务器。此时,通过物理分接端口采集数据包的方法就无法满足对虚拟网络设备的监控需求。另一方面,传统的网络测量方案一般采集网络设备中的流量统计信息,例如数据包的接收数、丢弃数、字节量等,所采集的数据类型较少且粒度较粗,无法精确实时地反映流量瞬时的拥塞状态,这就大大限制了网络故障的快速定位以及细粒度网络流量工程的有效实施。
随着协议无关转发体系架构[9]和P4 数据平面编程语言[10]的提出,带内网络遥测(INT,in-band network telemetry)[11]作为P4 语言的重要应用之一,能够支持低时延、细粒度的网络设备状态测量。它能将网络设备更加底层的实时状态信息,例如网络设备的包缓存队列长度、数据包的路由信息、到达或离开设备的时间戳信息等,嵌入沿路到达的数据包中,并由数据包随路携带,最终上报给远端的控制器[12]。控制器将基于采集到的实时网络拥塞信息对故障潜在位置或流量优化策略进行判断或规划[7]。由于整个端到端的遥测过程只在数据平面进行,不需要与控制平面进行频繁交互(除了最后一跳的信息采集上报),INT 大大降低了遥测时延和对控制平面的中断频率。虽然带内网络遥测的以上特性显示了其对数据中心网络实时测量的潜在价值,然而带内网络遥测依赖于协议无关转发体系架构,目前仅有少量可编程硬件交换机支持该能力,大多数虚拟网络设备均无法运行P4 程序,以提供对带内网络遥测的直接支持。
鉴于虚拟网络设备已在数据中心内大范围部署,本文面向工业界流行的高性能开源虚拟网络架构及设备VPP(作架构讲时,VPP 全称为vector packet processing;作设备讲时,VPP 全称为vector packet processor)[6],给出针对性的带内网络遥测的设计和实现,为在虚拟网络设备中研究网络测量问题提供新的解决思路。具体地,本文基于带内网络遥测协议规范定义了相关数据包的报文格式,基于VPP 的数据包处理框架,构造了数据平面的流水线处理模块,并在此基础上在包头引入源路由机制,实现了一种带内全网遥测方案。最后,本文基于虚拟机组网方式,搭建网络拓扑并进行了网络性能评测,实验展示了不同背景流量速率和不同探测频率下的遥测性能开销。系统实现包含1 017行C++代码,并在GitHub 网站进行开源。
2 带内网络遥测
2.1 研究背景
网络测量能在网络管理和运维过程中为网络故障快速定位、网络容量合理规划以及网络安全有效防护等任务提供有价值的基础数据。面对日益增长的网络流量以及复杂多样的业务场景,为了更加快速及时地反映流量瞬时变化情况,网络测量应满足精细化和实时性的探测需求,同时尽可能降低网络测量本身的开销以及对被测网络性能的影响,做到轻量化测量。
在传统的网络测量方案中,最常见的方法是基于简单网络管理协议(SNMP,simple network management protocol)[13]实施测量。SNMP 可以从网络设备侧采集设备以及流量的实时统计数据,如报文的接收数、丢弃数和错误数等。SNMP 配置简单且性能开销较低,被长期用于各类网管系统中。然而,SNMP 周期性地轮询网络设备以采集设备内部状态的行为将引入数据平面与控制平面的频繁交互,进而导致SNMP 具有较大的查询时延,从而无法对突发网络故障或数据平面的动态流量变化做出及时的反应,也无法对全网链路状态进行精细化的探测覆盖。尽管文献[14-15]分别提出了基于管理信息库(MIB,management information base)表组织模式和MIB 表查询方式的性能优化,但仍然无法从根本上消除SNMP 控制平面和数据平面频繁交互的性能瓶颈。谷歌的研究人员在2018 年甚至提出了“SNMP is dead”的观点。根据前人对SNMP的性能测量[16-17],SNMP 控制平面与数据平面的单次查询时延约为0.4~21.1 ms;根据本文第5 节的实验数据,基于VPP 的带内网络遥测系统能够以10 Mbit/s 的速度向网络系统注入探测包,从而将设备状态查询间隔降至0.13 ms。在高速硬件可编程交换机上,带内网络遥测探测包的注入频率还能大幅提高,从而进一步提升网络状态探测精度。除了SNMP,还有其他的一些基于被动探测方式的网络测量工具,例如NetFlow[18]、sFlow[19]、IPFIX[20-21]等。这些工具基于IP 流进行统计,即网络设备把报文划分为不同的流,并统计每个流的包数、字节数等信息。当流内报文传输完毕或流记录更新超时后,该流的统计结果就会被上传到收集器以便后续数据分析。基于流统计的测量方法能够有效支撑业务流量的分析、统计和计费,但它们无法获取网络设备更加底层的实时状态信息,例如包缓存的队列长度、数据包的路由信息、包到达或离开设备的时间戳等。此外,微软公司在2015 年提出的Pingmesh技术能够基于端到端发送的Ping 包,形成对整个数据中心网络的覆盖[22]。然而,Pingmesh 只能采集端到端的拥塞信息,仍然无法进一步监测网络中间设备的内部状态。综上所述,传统的网络测量方法数据采集时延较大,且可采集的网络实时数据类型较少,或无法支持在网络设备侧采集,这就大大限制了网络故障快速定位以及细粒度网络流量工程的有效实施。
随着协议无关转发体系架构和P4 编程语言的提出,网络数据平面的可编程能力被极大释放。这使网络设备在理论上能够任意解析和编辑报文头部。随后,越来越多的P4 程序被提出,它们定义了数据平面包处理的诸多有趣功能[11,23-26]。INT 就是其中的一个高级应用。INT 允许数据包在通过数据平面包处理流水线时,查询并携带网络设备的内部状态,例如队列长度和排队时延等。也就是说,INT 可以采集端到端转发路径上每一跳网络设备的内部状态。同时,整个状态采集过程只在数据平面进行,与控制平面尽量解耦,最终由末梢网络设备或接收终端将遥测结果上报给收集器。这种测量方式既能采集逐跳网络节点上的多种内部状态,又不需要频繁与控制平面发生交互,所以整体的测量时延大大降低。INT 自提出以来一直由P4 联盟的工作小组维护相关的协议规范[27]。目前,INT 正受到华为、Broadcom、Barefoot 等多家设备和芯片厂商的关注。一些厂商已将INT 功能嵌入其最新的商用交换芯片中[28-29]。
2.2 带内网络遥测原理
INT 实施框架如图1 所示,该框架定义了以下技术术语。

图1 INT 实施框架
1) INT 头部,即INT 定义的报文首部字段。INT头部既可用于携带收集到的网络状态信息,又能告知支持INT的设备需要收集哪些信息以及怎样将信息写入报文中。目前INT 规范并未强制规定INT 头部在报文中的插入位置,只要所插入的位置能够提供足够的容纳空间即可。例如,可将INT 头部作为TCP/UDP 层的有效载荷,还可以基于VXLAN GPE协议对INT 头部进行封装。
2) INT 元数据,即所采集到的网络状态信息。INT 元数据将被写入INT 头部的特定位置。
3) INT 数据包,即携带INT 头部的报文。普通流量或特殊探测包都可以被标记为INT 数据包。若把普通流量标记为INT 数据包,则可以进行指定用户流量的随路监测或随流监测。
4) INT 源端,即能创建INT 数据包的实体,例如应用程序、终端主机网络协议栈、物理网卡或与发送方直接相连的ToR(top of rack)交换机等。INT源端负责把INT 头部封装到数据包中。
5) INT 接收终端,即能提取INT 头部并解析其中携带的INT 元数据的实体(通常既可以是最后一跳网络设备,也可以是终端主机)。INT 接收终端接收INT 数据包,解析INT 头部,生成探测结果,并将探测结果上报给收集器。
6) INT 转发设备,即根据INT 头部的指示,采集INT 元数据并将其写入INT 头部的网络设备。
INT 采用带内测量模式,其遥测过程如图2 所示。INT 源端把INT 头部插入原始数据包中,从而指示沿途网络设备添加所期望采集的INT 元数据。在网络传输过程中的每一跳,INT 转发设备将根据INT 头部的指示,在其中插入采集到的各个INT 元数据。INT 接收终端在处理原始数据包之前会提取携带INT 元数据的INT 头部,并生成探测报告。该探测报告包含了数据包经过沿途网络设备时所采集到的逐跳实时网络状态信息。同时INT 接收终端还会把探测报告发送给收集器。收集器一般部署在集中式控制器上,负责收集并分析从数据平面采集到的INT 元数据,为控制平面后续的决策动作(如流量工程)提供有效的数据支撑。根据INT 协议规范[27],理论上INT 自身并不约束支持采集的数据类型。但受到网络设备的实际硬件限制,最终INT 能够采集到的元数据通常包括报文出入端口号(用于分析报文端到端的转发路径)、报文处理时延和设备内部排队状态(用于感知端到端的逐跳拥塞情况)。
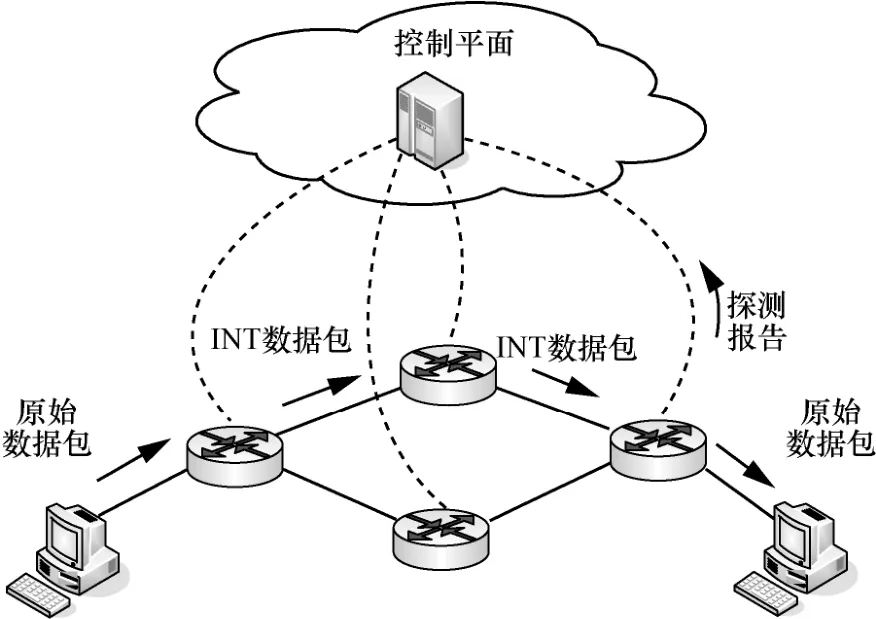
图2 INT 的遥测过程
3 矢量数据包处理
3.1 研究背景
在数据中心网络中,虚拟网络设备被大量使用。一方面,高可靠、低时延、高吞吐率等多样化的应用需求要求网络设备支持差异化的数据包转发方式,例如多路径路由、最短路径路由、源路由等。而虚拟网络设备支持数据平面可编程,能灵活修改数据包转发方式,这满足了多样化的应用需求。另一方面,数据中心包含了海量服务器的互联,并通过虚拟机和物理机的形式对外提供服务,且不同服务之间还存在流量隔离、隐私控制、安全防护等需求。虚拟网络设备则可以通过x86 等通用硬件以及虚拟化技术来承载诸多网络功能的软件处理,从而能够在一台物理设备上同时运行多个性能与故障互相隔离的实例,因此可以支持多个网络业务的并发部署,达到硬件资源共享的目的。
目前,已有多个开源项目提出了多种网络设备虚拟化的解决方案。OVS[5]是一个开放的多层虚拟软件交换机,其设计目的是通过软件编程的方式实现大规模的网络自动化部署,非常适合作为软件交换机部署在虚拟机管理平台上。VPP[6]是一种高效的数据包处理架构,基于该架构核心思想实现的高性能转发设备能够运行在通用CPU 上,实现可供生产环境使用的高速虚拟软件交换机或路由器。VPP 最早由思科公司开源,发展至今已成为Linux基金会的开源项目FD.io 中最核心的组件。此外,还有专门用于 P4 程序验证的开源仿真平台BMv2[30],它实现了具备协议无关转发架构的软件交换机,并通过运行P4 程序,产生程序定义的转发行为。以上3 种典型的开源虚拟网络设备均具备良好的编程扩展能力以及一定的数据包处理性能,所以正受到越来越多网络开发者的关注。当需要为报文处理逻辑扩展新的功能或自定义新协议时,对于OVS,需要修改其核心软件代码或定义流表规则;对于VPP,由于其本身采用了模块化的设计思想,因此能够独立于核心代码创建新的协议功能逻辑;至于BMv2,它是基于P4 的转发引擎,所以只需编写并加载对应功能的P4 代码,天然具备协议扩展能力。另一方面,在报文处理性能上,VPP 采用矢量化包处理技术,大幅降低包转发开销,所以包处理性能优于OVS;而BMv2 主要关注如何实现P4 程序定义的协议无关转发功能,所以包处理性能并非它优化的重点,其处理性能远低于VPP 和OVS[8]。综上所述,本文拟基于VPP 实现带内网络遥测,以求兼具高性能和可扩展性。
3.2 VPP 数据包处理架构
VPP 基于批处理思想提升报文处理效率,同时基于模块化的架构解耦添加新协议逻辑的复杂度。VPP 数据包处理架构如图3 所示。首先,VPP从网络I/O 收取输入流量并将到达的数据包组织成一个个的包集合,即“数据包矢量”。然后,输入流量以数据包矢量为单位,一批批通过VPP 的包处理结构来执行数据包的批量操作。该包处理结构是由多个图节点构成的有向图,而每个图节点则代表数据包处理流程中的某一个操作环节。通常来说,图节点可分为2 种类型:一种是包含收发数据包操作的节点,如dpdk-input 节点是基于DPDK 接收数据包的节点;另一种是处理数据包的节点,如ethernet-input 节点是解析数据包以太网头部的节点。此外,值得注意的是,VPP 对数据包的处理顺序不再是传统的标量方式(即将数据包逐个送入图节点进行处理),而是把整个数据包矢量整体送入当前图节点进行处理,处理完成后再整体送入下一个图节点。使用矢量处理相较标量处理的好处是,若以标量方式处理数据包,则每处理一个包都需要重新逐层调用协议栈处理函数,这很容易产生CPU 指令缓存的访问时延抖动,即每个包被处理时都有可能产生一组相同的指令缓存缺失事件,这将大大影响处理效率。若以矢量方式处理,那么在一个图节点的处理过程中,由于数据包矢量中第一个报文有缓存预热作用,因此能大概率地减少包矢量中后续数据包处理时的指令缓存缺失事件,也就能以一组数据包来分摊第一个数据包引发的指令缓存缺失开销,从而整体提升数据包矢量通过图节点的效率。
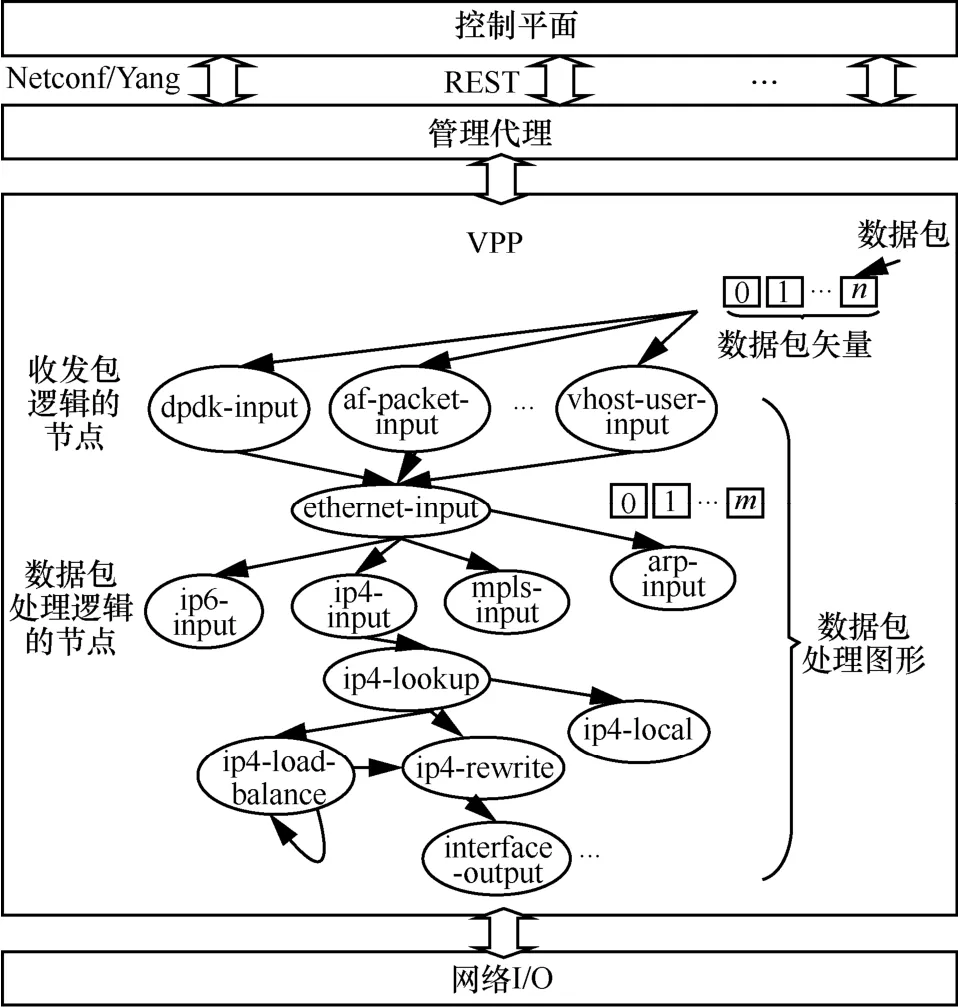
图3 VPP 数据包处理架构
VPP 数据包处理架构具备良好的可扩展性。具体而言,VPP 数据包处理架构中模块化的图结构有助于实现协议功能的快速迭代更新。如图4 所示,若开发者希望定义新的报文处理逻辑,只需在程序库中为VPP 编译生成一个独立的二进制插件,并在系统中加载该插件,就能重新排列包处理图节点或引入新的图节点。该机制允许通过插件更新的方式引入新的包处理逻辑,而不需要修改VPP 自身的核心代码。这对网络数据平面协议功能扩展来说是非常便捷的。
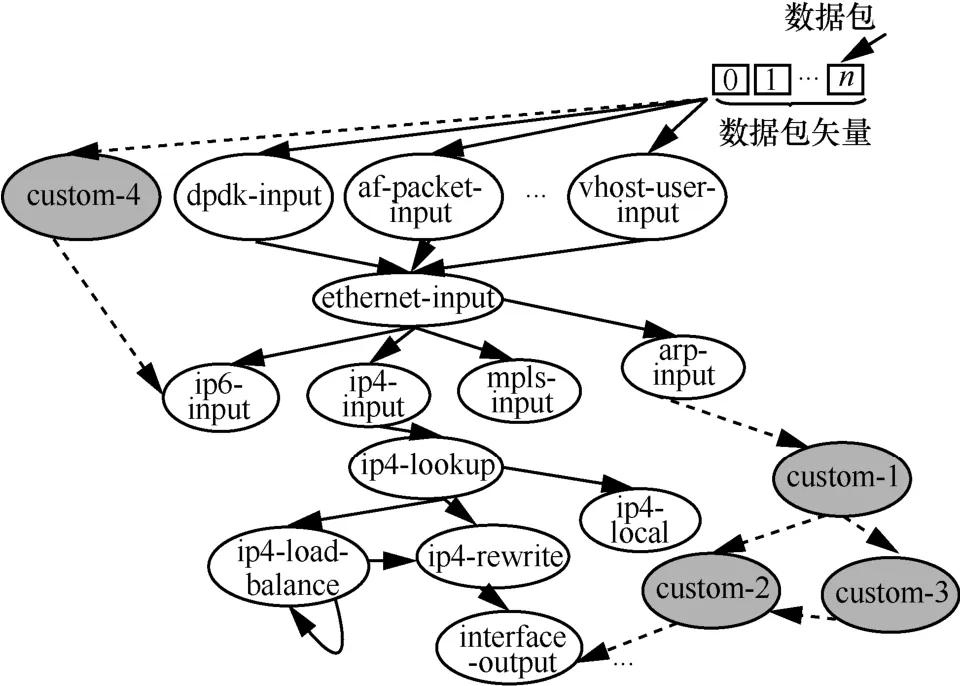
图4 VPP 数据包处理架构的图结构的扩展
3.3 VPP 图形节点结构及其初始化
如前所述,如果开发人员想要开发自定义的包处理逻辑,就需要在VPP 数据包处理架构的图结构中建立新的图节点。
如图5 所示,VPP 数据包处理架构的图结构由vlib_node_main_t 结构体定义,该结构体记录了包处理图的全局信息。其中比较重要的2 个成员变量分别为nodes 和node_registrations。成员变量nodes以向量的数据结构进行组织,存储了多个指向vlib_node_t 结构体类型的指针,用来保存所有在VPP中已注册的图节点;成员变量node_registrations 则以单链表的数据结构进行组织,链表中的各个元素类型为vlib_node_registration_t 结构体,提供给VPP的初始化函数使用,用于图节点的注册。
具体来看,vlib_node_t 结构体是单个图节点的主要数据结构,保存了单个图节点的名称、节点类型、处理函数、兄弟节点及子节点等信息。vlib_node_registration_t 结构体用于图节点的注册,开发人员可以利用 VPP 提供的宏函数(VLIB_REGISTER_NODE),把各个图节点预先挂载到以单链表组织的node_registrations 成员变量中,以供后续的初始化函数使用。图6 是通过VLIB_REGISTER_NODE 宏函数注册ethernet-input节点的示例,它定义了该图节点的处理函数等一系列注册信息。

图6 通过VLIB_REGISTER_NODE 宏函数注册ethernet-input 节点示例
VPP 在启动之后,将对各个图节点进行注册,并创建整个数据包处理架构的图结构。相关的初始化流程函数为vlib_main(),图7 显示了该函数的主要流程。vlib_main()函数首先调用vlib_register_all_static_nodes()函数,遍历以单链表组织的 node_registrations 成员变量,从而创建各个图节点,并把它们添加到以向量组织的节点成员变量中。接着,继续调用vlib_node_main_init()函数,它会根据各个图节点所注册的兄弟节点及子节点等信息,建立节点之间的跳转关系,由此,创建出一张完整的数据包处理图。最后,在调用其他一些初始化配置函数之后,VPP 主程序将进入vlib_main_loop()函数,开始执行收发数据包和图节点调度的流程。
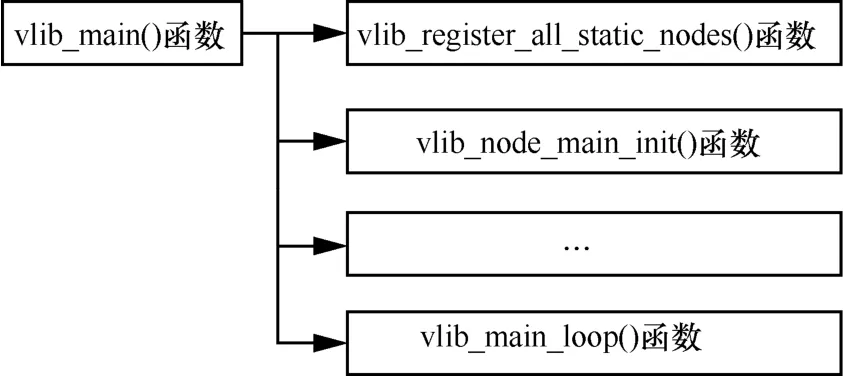
图7 VPP 数据包处理架构的图结构的主要初始化流程
基于VPP 提供的包处理图节点抽象机制,开发人员能够把更多的精力投入自定义图节点中协议逻辑功能的设计和实现里。
4 基于VPP 的带内网络遥测实现
4.1 设计思路
由INT 的实施框架可知,INT 元数据可以由用户流量携带,也可以由专门的探测包携带,二者在实现上的区别主要在于INT源端封装INT数据包的方式。目前,本文采用由专门的探测包携带INT 数据的实现方式,即标记特殊探测包为INT 数据包。基于此,使用额外的发包终端来发送特殊的UDP探测包。该UDP 探测包被第一台VPP 虚拟网络设备接收后,将被封装INT 头部,从而生成真正的INT数据包。该台VPP 虚拟网络设备实际上扮演了INT源端的功能角色。
若后续的VPP 虚拟网络设备接收到INT 数据包,作为INT 转发设备,它们需要依据INT 头部的指示,统计设备自身的INT 元数据,并将其写入INT头部的对应位置,由此完成数据采集工作。
由于目前VPP 虚拟网络设备暂时无法从自身判断INT 数据包是否已被转发至最后一跳节点,因此也无法完成INT 接收端的功能。本文将指定端侧服务器作为数据包接收终端,负责解析INT 头部中记录的各个INT 元数据。
接下来,本文基于IPv4 和INT 协议规范,阐述在VPP 中设计和实现带内网络遥测的技术细节。
4.2 系统设计与实现
4.2.1 数据包格式
在标记特殊探测包为INT 数据包的实现方式中,共出现2 种数据包,一种是特殊UDP 探测包,另一种是INT 数据包。它们的包格式如下所述。
特殊UDP 探测包由额外发包终端向VPP 虚拟网络设备发送,使用携带特殊目的端口号(55555)的UDP 包封装,表示它是生成INT 数据包的原生探测包。当INT 源端识别到携带该端口号的UDP 包后,将其封装成INT 数据包。此外,它的目的IP 地址为所发往的VPP 虚拟网络设备的网络地址。
INT 数据包的报文格式基于IPv4 协议和INT规范设计,如图8 所示。
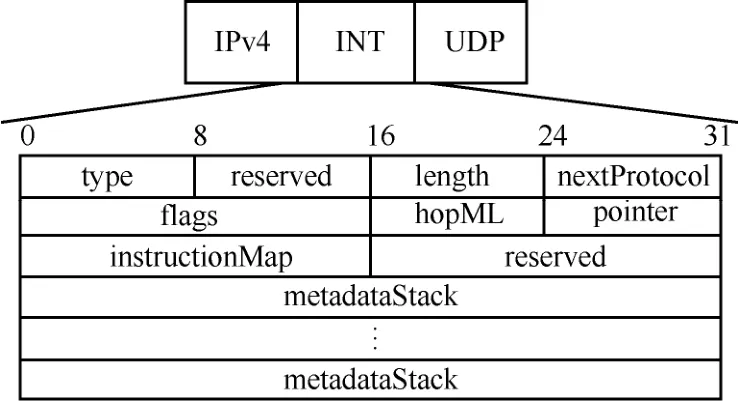
图8 INT 头部报文格式
1) 8 bit 的type 字段表示INT 数据包的类型,本文定义“1”是基于特殊UDP 探测包封装的INT数据包。
2) 8 bit 的length 字段记录了INT 头部的长度。
3) 8 bit 的nextProtocol 字段用于区分INT 头部封装的上层协议,它复制了原始IPv4 头部中的协议字段号(protocol)。这是因为,本文把INT 头部放置在IP 层之后,使用自定义的协议号200 来表示IP 层之后的上层协议是INT,所以IP 头部中原始的协议字段号需要重新被记录在INT 头部中,以指示INT 头部之后的上层协议类型。
4) 16 bit 的标志位(flags)字段,包括INT 协议的版本号等标志位信息。
5) 8 bit 的hopML 字段,表示每一跳节点需要添加的INT 元数据的最大长度。
6) 8 bit 的pointer 字段,指向在INT 元数据堆栈中下一个可填充INT 元数据的空白空间地址。
7) 16 bit 的instructionMap 字段,其每bit 代表一种INT 元数据类型,指示了每跳节点需要统计的各个INT 元数据类型的组合,例如交换机标识号、出入端口时间戳、包缓存队列长度等。
8) 后续的metadataStack 即INT 元数据堆栈,记录了在每一跳节点上采集到的各个 INT元数据。
可以看出,对于一条端到端探测路径,如果总共有n跳节点,且每一跳节点需要添加的INT 元数据的最大长度为hopML B,则INT 头部所占空间为(12+nhopML)B。
4.2.2 INT 转发设备功能
INT 转发设备完成接收INT 数据包,采集设备本地的INT 元数据并将其写入INT 头部,转发INT数据包的功能。
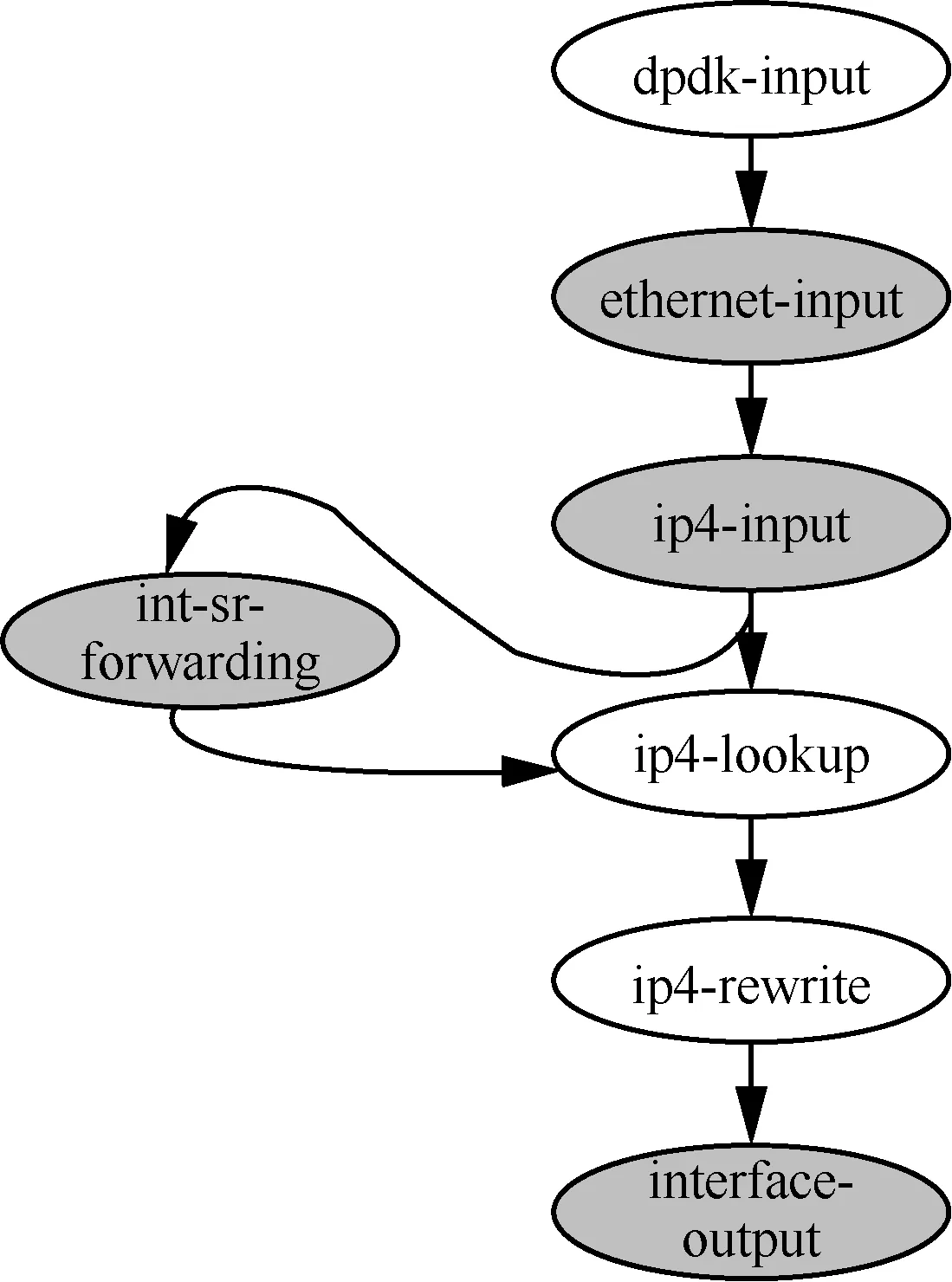
如前所述,VPP 的数据包处理架构以数据包矢量为单位,通过包处理架构的图结构对包矢量进行统一处理。本文根据转发流程设计了INT 数据包处理的VPP 图结构,如图9 所示。
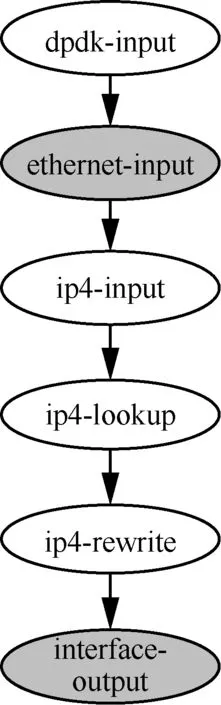
图9 INT 数据包处理的VPP 图结构
具体而言,图9 的图结构扩展了VPP 已经提供的处理普通IPv4 数据包的简单流程。
1) VPP 虚拟网络设备通过收发数据包逻辑的相应节点接收IPv4 数据包(如dpdk-input 节点)。
2) 解析数据包的以太网头部(ethernet-input节点)。
3) 解析数据包的IPv4 头部(ip4-input 节点)。
4) 依据解析结果,查找路由表项(ip4-lookup节点)。
5) 依据出端口信息,更新数据包头部对应的字段值(ip4-rewrite 节点)。
6) 转发数据包(interface-ouput 节点)。
为了进一步在IPv4 协议之上实现INT 元数据的采集工作,需要对若干原有节点的逻辑功能做相应的扩展。本文在原有的ethernet-input 节点和interface-output 节点中增加了部分代码,使数据包能在刚进入数据平面流水线进行处理以及处理结束时,分别采集所需的INT 元数据。
本文采集了3 种类型的INT 元数据,如下所示。
1) 入端口时间戳:ingress_timestamp_s 和ingress_timestamp_us,秒和微秒级,分别占4 B。
2) 出端口时间戳:egress_timestamp_s 和egress_timestamp_us,秒和微秒级,分别占4 B。
3) 出端口MAC 地址:switch_addr,占6 B。
以上元数据共占22 B,所以此时每一跳节点需要添加的INT 元数据的最大长度为22 B。
图10 展示了采集INT 元数据的程序流程,具体的INT 元数据采集流程描述如下。

图10 采集INT 元数据的程序流程
在ethernet-input 节点中执行原有解析动作之前,首先记录入端口时间戳。当数据包完成以太网层和IP 层的流水线处理之后,进入interface-output节点等待转发。此时,首先判断数据包是否为INT数据包(ether->type==ETHERNET_TYPE_IP4 且ip->protocol==200),若是,则继续完成下列动作,否则直接转发数据包。当判断是INT 数据包后,分别记录出端口MAC 地址以及出端口时间戳。接着,根据INT 头部的指令信息(即instructionMap 字段)和指针值(即pointer 字段),把指令要求采集的各个INT 元数据复制到INT 元数据堆栈中的空白区域。最后,更新指针值,并继续执行数据包的转发动作。
4.2.3 INT 源端功能
INT 源端接收特殊UDP 探测包,封装INT 头部以生成INT 数据包。
同样地,本文设计了如图11 所示的INT 源端包处理架构的图结构。具体而言,当INT 源端接收到特殊UDP 探测包后(dpdk-input 节点),首先执行以太网头部(ethernet-input 节点)和IPv4 头部(ip4-input 节点)的解析操作;当解析得到的IP 目的地址为本设备地址,且IP 层头部协议字段号为UDP 时,将继续解析数据包的UDP 层(ip4-local节点和ip4-udp-lookup 节点),获取UDP 头部的目的端口号;接着,根据自定义的目的端口号(55555),执行数据包头部的重新封装操作(int-probe-packet-generation 节点),使其成为INT数据包;最后,由于此时INT 源端也是VPP 虚拟网络设备,也需采集本网络设备的状态信息(即也需完成INT 转发设备的功能),因此生成的INT 数据包会被重新送到以太网头部的解析节点(ethernet-input 节点),继而执行前文所述的INT 转发设备处理流程,即采集INT 元数据并完成转发。
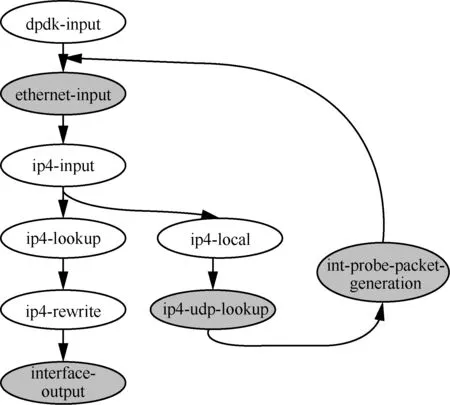
图11 INT 源端包处理架构的图结构
受限于数据包大小,INT 源端无法在INT 头部中预留无限大的空白INT 元数据堆栈空间。这就希望可以由用户指定遥测过程的最大转发跳数以及所采集的INT 元数据类型,基于此计算预留空间的大小。因此,除了封装INT 头部之外,INT 源端还应提供相应的配置接口。
综上,本文把INT 源端的功能实现划分为以下2 个模块,即指令配置模块和INT 数据包生成模块。
1) 指令配置模块
指令配置模块负责提供配置指令和初始化INT头部模板。配置指令可暴露给用户或控制平面调用,根据配置参数来计算INT 头部中需要预留的空白INT 元数据堆栈空间大小。INT 头部模板则在配置指令下发后被初始化,以便INT 数据包生成模块据此模板来重新封装UDP 探测包,生成INT数据包。
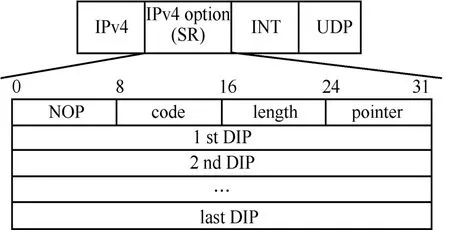
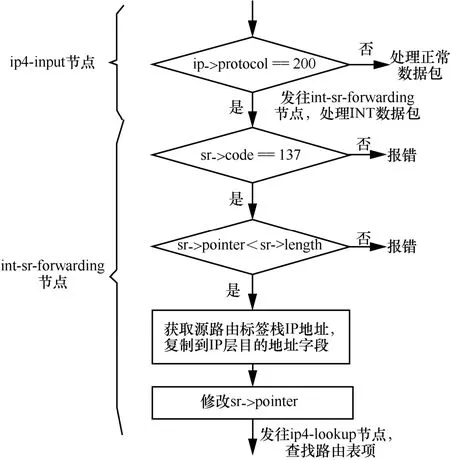
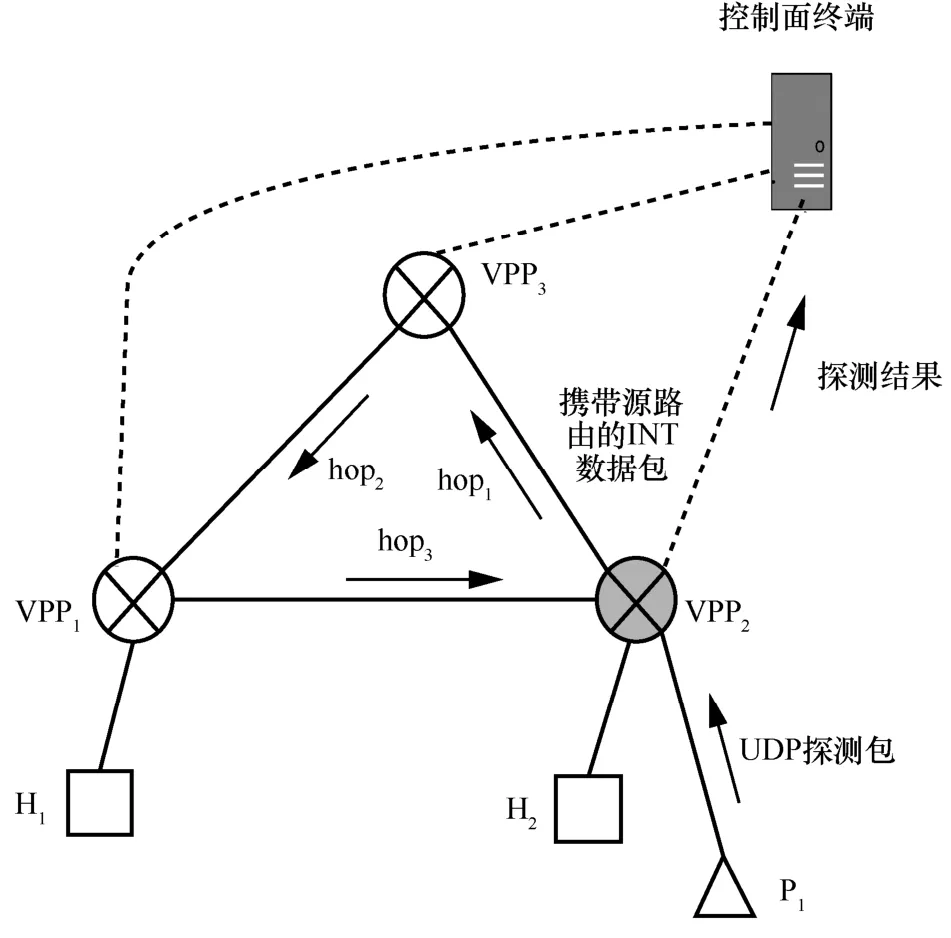
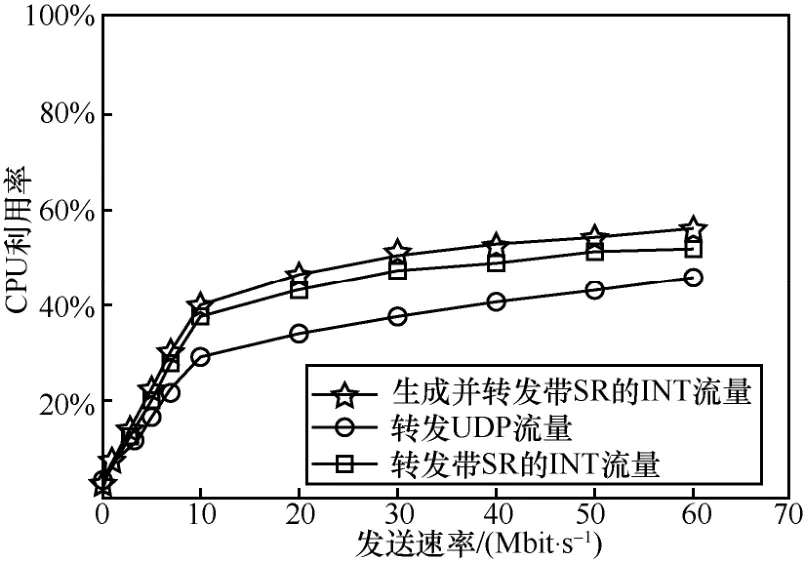
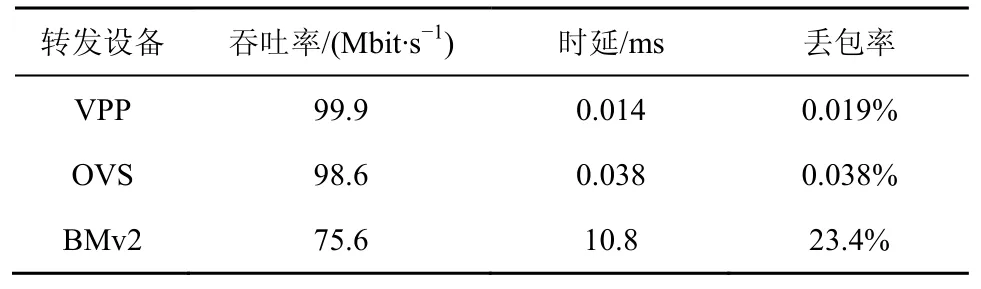
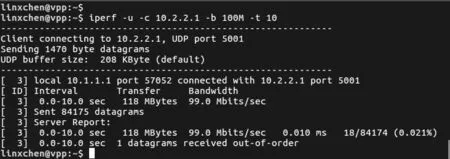
借助VPP 提供的开发接口,可以实现CLI 配置指令以及指令响应函数。指令格式为int header 指令响应函数的程序流程如图12 所示。首先,解析CLI 配置指令,得到各参数值;接着,先删除原有的INT 头部模板(即上一轮创建的头部模板全局变量),再依据指令参数值,生成新的模板。 图12 指令响应函数的程序流程 2) INT 数据包生成模块 当接收到特殊UDP 探测包后,该模块依据INT头部模板,对探测包执行重新封装操作,以生成真正的INT 数据包。如图11 所示,本文在包处理架构的图结构中增加了新的图节点(即int-probe-packet-generation 节点,该节点的注册函数如图13 所示),并在ip4-udp-lookup 节点中通过解析UDP 目的端口号是否为55555 来判断是否跳转到该新节点进行处理。INT 数据包生成模块的程序流程如图14 所示。其中,本文借助VPP 提供的开发接口,为自定义的UDP 目的端口号注册了新的节点跳转关系。此外,在int-probe-packet-generation节点中,首先,为UDP 探测包分配足够的INT 头部空间;其次,将INT 头部模板中的内容复制到UDP 探测包对应的空间中;接着,更新UDP 探测包IPv4 头部中的protocol 字段值为200(标识上层协议为INT),并将原始值记录到INT 头部中;最后,重新计算IPv4 头部校验和,再把数据包发往ethernet-input 节点,以便继续执行后续的INT 元数据采集工作。 图13 int-probe-packet-generation 节点的注册函数 图14 INT 数据包生成模块的程序流程 4.3.1 带内全网遥测机制简介 INT 数据包的遥测路径取决于该数据包如何在网络中被转发,即取决于网络设备中的路由表项。若想由用户控制遥测路径,则可以为INT 数据包添加源路由[31],使INT 数据包可以预先被指定转发时的下一跳地址。基于这种源路由机制可以主动规划全网范围的遥测路径,以实时获取覆盖全网的所有网络设备及链路的状态信息[32]。下面,本文基于VPP 给出一种带内全网遥测的实现案例。 图15 给出了一种带内全网遥测机制,该机制包含数据平面和控制平面的实现。在数据平面上,INT 源端向网络周期性地发送INT 数据包。这些INT 数据包同时还会被封装源路由标签栈。当INT转发设备接收到它们时,除了采集INT 元数据并写入INT 头部之外,还需解析源路由标签栈,获取下一跳INT 转发设备的地址。综上,INT 数据包在网络中的遥测路径由其携带的源路由信息唯一指定。 图15 一种带内全网遥测机制 源路由标签栈的内容则需由网管人员或控制器预先进行规划。也就是说,控制平面除了分析遥测结果之外,还要借助完整的网络拓扑图进行全局遥测路径的设计。然后,控制平面把计算出的各条遥测路径下发到数据平面的INT 源端。INT 源端据此信息封装INT 数据包中的源路由标签栈。 4.3.2 方案实现思路 基于前文设计的基于VPP 的INT 功能方案,本节阐述带内全网遥测机制的实现思路。 为了在IPv4 数据包中增加源路由信息,可借助IPv4 头部的可选字段(option)。图16 展示了源路由标签栈的报文格式,介绍如下。 图16 源路由标签栈的报文格式 1) 8 bit 的NOP 字段是填充字符,使后面的字段能与4 B 长度对齐。 2) 8 bit 的code 字段标识了可选字段的选项类型,其中137 表示严格的源路由选项。 3) 8 bit 的length 字段记录了整个可选字段的长度。 4) 8 bit 的pointer 字段记录了指向下一个可使用的路由地址的指针。 5) 后续的DIP 标签栈以4 B 为单位,记录着数据包在网络中传输时被指定的每一跳节点的网络地址。 对于INT 转发设备,为了解析源路由标签栈,可以在包处理架构的图结构中增加新的图节点(如图17 所示的int-sr-forwarding 节点,该节点的注册函数如图18 所示)。新的图节点位于ip4-input 节点和ip4-lookup 节点之间,其程序流程如图19 所示,具体描述如下。在ip4-input 节点中解析IPv4 头部之后,判断其protocol 字段值是否为200(自定义协议号,表示上层为INT 协议),若是,则把数据包发往新增加的int-sr-forwarding 节点;否则说明该数据包为普通数据包,继续执行IP 层后续的操作。在int-sr-forwarding 节点中,首先分别判断IPv4 头部中的可选字段是否为源路由选项(sr->code==137),以及可选字段存储的指针是否已经超出头部长度(sr->pointer < sr->length);其次,根据指针值获取源路由标签栈中指定的下一跳IP 地址,并将其复制到IPv4 头部的目的地址字段中;接着,更新可选字段中的指针值;最后,把数据包发往ip4-lookup 节点,继续执行后续的路由表查找操作。 对于INT 源端,除了为特殊UDP 探测包添加INT 头部之外,还需为其封装源路由标签栈。由于前文已经在INT 源端中设计了指令配置模块和INT数据包生成模块,因此只要对这2 个模块进行适当的扩展,就能支持源路由标签栈的封装操作。 图17 扩展案例中INT 转发设备报文处理逻辑对应的VPP 图结构 图18 int-sr-forwarding 节点的注册函数 图19 INT 转发设备解析源路由标签栈的程序流程 一方面,由于源路由标签栈的内容由控制平面下发,因此可以扩展指令配置模块中的指令,以暴露给控制平面调用。增加源路由信息后的配置指令格式为int header 新格式中增加了next 参数,它按序记录了源路由中每一跳节点的IP 地址。相应地,在指令响应函数的程序流程图中,也需解析next 参数值,据此创建源路由标签栈模板,并在模板中填充指定的各跳节点的地址。 此外,在INT 数据包生成模块中,新增加的int-probe-packet-generation 节点除了为特殊UDP探测包封装INT 头部之外,还应该继续在IPv4头部的option 字段中复制源路由标签栈模板的内容,使该INT 数据包能够携带源路由信息。 基于VPP,本文实现了上述带内全网遥测机制。系统包括1 017 行C++代码,并在GitHub 网站开源。下面,基于虚拟机组网的方式,对系统进行网络仿真实验,以验证遥测结果的有效性。仿真实验环境包括一台具有Intel i5-6500 四核CPU、16 GB内存以及1 TB 硬盘的台式计算机。在这台物理机上,本文又基于VirtualBox 虚拟机,创建了如图20所示的网络拓扑。该拓扑由3 个VPP 虚拟网络设备(VPP1、VPP2、VPP3)、一个控制面终端、一个UDP 发包终端(P1)以及2 个主机终端(H1、H2)组成。它们分别运行在具有单核CPU、2 GB内存、Ubuntu 16.04 操作系统的VirtualBox 虚拟机中,并使用由虚拟机提供的虚拟网卡以及桥接模式进行组网。 基于不同的实验场景,本文希望回答以下问题。1) 单个VPP 节点在转发普通流量和INT 流量时的性能怎么样?本文也将比较VPP 与同类软件(如OVS 和BMv2)的转发性能差异。2) INT 探测包能否真正地感知到因为背景流量速率变化引发的网络拥塞?且INT探测包自身的采样频率设置为多少是合适的?其中,实验场景2)的背景流量速率设置会参考当前实验环境的虚拟网络链路最大带宽的测量结果。 图20 仿真实验网络拓扑 首先,UDP 发包终端(P1)借助Iperf 发包工具向VPP 虚拟网络设备(VPP2)发送具有特殊目的端口号(55555)的UDP 探测包。然后,VPP2作为INT 源端,接收特殊UDP 探测包,并依据CLI指令配置内容,为探测包封装INT 头部以及源路由标签栈。实验中设置的源路由路径为hop1→hop2→hop3→控制面终端。此时,3 个VPP虚拟网络设备(VPP1、VPP2、VPP3)都将执行INT转发设备功能,以采集本设备的INT 元数据。接着,在控制平面终端接收到INT 数据包后,将执行INT接收终端功能,即解析INT 头部,获取逐跳节点统计的INT 元数据。本文依据Raw Socket 提供的API,使用C++语言实现了该解析功能。最后,主机终端(H1、H2)也借助Iperf,向网络中发送特定速率的UDP 背景流量,这将引起沿路网络转发设备(VPP1、VPP2)内部排队处理时延的增加。在对单台VPP设备进行转发性能测试时,本文也会直接由P1向VPP2发送普通UDP 流量。 5.4.1 VPP 单节点的转发性能 首先,本文测量单个VPP 节点在分别转发普通流量和INT 流量时的性能。实验过程中,P1向VPP2分别发送2 种不同类型的UDP 包:一种为普通UDP包,即VPP2按照正常数据包的处理流程执行转发操作;另一种为前文所述的特殊UDP 探测包,即VPP2作为INT 源端,为其封装源路由标签栈以及INT 头部,并将采集本设备的INT 元数据嵌入INT头部中,最后完成转发操作。为了公平比较,普通UDP 包以及INT 数据包的包长度均为162 B。在不同发送速率下,本文使用Linux top 命令分别测量了VPP2处理这2 类数据包的CPU 利用率,实验结果如图21 所示。实验结果表明,随着输入包速率的增大,VPP 虚拟网络设备的CPU 利用率也在上升。此外,由于增加了封装额外包头部信息和采集INT元数据等操作,相比转发普通UDP 流量,处理和转发INT 流量需要消耗更高的CPU 算力。经统计,CPU 利用率平均增加的百分比约为25.6%。值得注意的是,以上增加部分包括INT 源端生成源路由标签栈和INT 头部的开销,如果单纯执行INT 的源路由转发操作,根据在VPP3上进行的测量,这部分增加比例会降低到20.6%。在实际部署时为了降低INT 的开销,可以考虑使用基于采样的INT 头部添加策略进行INT 开销分摊,避免为每个包添加INT头部所带来的较大开销。 图21 单台VPP 虚拟网络设备的CPU 利用率随流量变化情况 此外,为了横向比较,本文对VPP、OVS 和BMv2 的单跳转发性能也进行了测量。转发流量为由Iperf 产生的100 Mbit/s 的流量,3 类设备均设置为L3 最长前缀匹配转发,包含单条转发表项,收发包终端与转发设备直接相连,测量结果如表1 所示。由表1 可知,具备矢量包处理能力的VPP 在100 Mbit/s 流量冲击下具有最高的吞吐率、最低的时延和最小的丢包率。OVS 在这3 项指标中均接近VPP 但仍然存在一定差距。具体而言,OVS 和VPP 吞吐率较接近,但OVS的转发时延达到了VPP 的2 倍多,且产生了2 倍的丢包率。相比之下,BMv2 的转发性能较有限,并在100 Mbit/s 流量的冲击下产生了23.4%的丢包,且转发时延达到了惊人的10.8 ms,这和BMv2内部使用软件模块逼真模拟P4 交换机的硬件流水线的设计实现机制有关。BMv2 为了模拟P4 交换机的硬件流水线,在自身内部引入了多级的计算和缓存单元,且计算单元完全通过软件指令模拟真实硬件转发行为,这就使数据包处理时延大幅增加。但因为BMv2 内部包含大量缓存,吞吐率和丢包率降低的数量级相对时延增加来说仍然较有限。 表1 VPP、BMv2、OVS 单跳转发测量结果 5.4.2 虚拟网络的链路带宽测量 由于是在单个物理机上采用虚拟机组网,每个虚拟机可分配到的CPU 及内存等资源较有限,这导致了组网规模较小,且无法满足非常高速的网络转发性能需求。本文借助Iperf,对虚拟网络的实际链路带宽进行了测量。在如图20 所示的网络拓扑下,本文从H1主机终端发送UDP 报文到H2主机终端,测量结果显示虚拟网络转发UDP 流量的链路最大带宽约为100 Mbit/s。在100 Mbit/s 的发包速率下,产生了0.021%的轻微丢包,如果超过这个发包速率,链路丢包率将急剧增大,如图22 所示。 图22 虚拟网络中UDP 流量的最大带宽测量值(无丢包或轻微丢包) 5.4.3 INT 网络状态探测实验过程描述 在验证INT 探测包效果的实验中,本文仍然借助Iperf 发包工具,从H1主机终端向H2主机终端发送不同速率的UDP 背景流量。同时,通过改变P1向VPP2发送特殊UDP 探测包的速率,来控制INT探测频率。如前所述,目前系统仅支持采集3 种类型的INT 元数据。其中,可依据出端口MAC 地址来定位采集数据的网络设备,由出入端口时间戳来计算数据包在网络设备中的单跳处理时延,从而初步判断当前网络设备的负载压力。 本文通过改变背景流量速率和INT探测速率这2 个变量,分别完成了3 组实验,并观察INT 数据包采集到的各个虚拟网络设备的单跳处理时延变化情况。为了增强结论的可靠性,本文对每组实验重复进行了10 次。考虑到网络的UDP 最大(无丢包)带宽约为100 Mbit/s,在每组实验中,在15~25 s时间段内发送速率为90 Mbit/s 的UDP 背景流量,在30~40 s 时间段内发送速率为200 Mbit/s 的UDP背景流量(尽可能耗尽链路带宽)。此外,第一组的INT 探测速率为100 kbit/s(最大带宽的0.1%),第二组的INT 探测速率为1 Mbit/s(最大带宽的1%),第三组的INT 探测速率为10 Mbit/s(最大带宽的10%)。每组实验中的INT 数据包大小均为162 B。为了方便观察,本文只绘出了拓扑中hop2(VPP3)和hop3(VPP1)两跳的处理时延,3 组实验结果的一次记录分别如图23~图25 所示。另外,表2 还分别列出了10 次重复实验下,3 组实验在不同背景流速率下统计出的hop3单跳平均处理时延。 图23 100 kbit/s 的INT 探测速率下的交换机时延测量结果 图24 1 Mbit/s 的INT 探测速率下的交换机时延测量结果 图25 10 Mbit/s 的INT 探测速率下的交换机时延测量结果 表2 3 组实验的hop3单跳平均处理时延 5.4.4 INT 网络状态探测实验结果分析 图23~图25中的每个数据点表示在对应的出端口时间戳上,INT 数据包所采集到的单跳网络设备处理时延(通过出端口时间戳减去入端口时间戳得到)。由于端口时间戳的时间精度是微秒级的,因此INT 能够提供较高精度的探测结果。在每组实验中,由于背景流量经过的路由路径为VPP1→VPP2,而不经过VPP3,因此hop2(VPP3)的处理时延总是较低且稳定,基本不受背景流量的影响。在图24和图25 中,个别hop2数据点的增高主要是在高负载压力下,运行在同一台资源受限物理机上的各个虚拟机之间互相竞争资源所导致的。而由于背景流量最终会经过hop3(VPP2),当背景流量显著增长,甚至超过图22 中虚拟网络中测试得到的网络最大带宽时,就会出现明显的拥塞现象。此时背景流量数据包与INT探测包共同在设备队列中经历较长的排队过程,INT 探测包能够将该排队时延精准记录并传送到控制面终端上。 从这3 组实验hop3(VPP1)的数据点可以看出,在不发送背景流量时,hop3的处理时延与hop2基本一致;而在15~25 s、30~40 s 时由于引入背景流量,导致hop3的处理时延有所增高。特别地,当背景流量速率为200 Mbit/s 时(30~40 s,背景流量速率已经大于网络最大带宽),INT 探测包实时采集得到的处理时延也相应地大幅增加,由此能判断出此时hop3链路已经出现拥塞。另外,如表2 所示,经过计算,在第二组实验1 Mbit/s 的INT 探测速率下,由于背景流量的变化(无背景流量、90 Mbit/s、200 Mbit/s),采集到的INT 数据包所携带的hop3单跳平均处理时延分别为6.1 μs、10.8 μs、41.8 μs。由此也可以判断出,当背景流量为200 Mbit/s 时,hop3链路出现了较严重的交换机内部队列排队现象。 此外,通过对比各组实验结果,本文还观察到不同的INT 探测速率对探测效果的影响。例如,通过对比100 kbit/s 和1 Mbit/s 的实验结果(图23 和图24)可以看出,更高的INT 探测速率在一定程度上有利于提高探测结果的精度。但是,INT 探测速率越高,其所占用的网络带宽也越大,且INT 探测包在设备队列中的排队行为也将大大提升背景流量的转发时延。如表2 所示,在10 Mbit/s 的INT探测速率下,在无背景流量、90 Mbit/s 背景流量、200 Mbit/s 背景流量时,计算得到的hop3单跳平均处理时延分别为15.9 μs、52.9 μs、137 μs,均大大高于1 Mbit/s 的INT 探测速率下测得的6.1 μs、10.8 μs、41.8 μs。这也说明如果INT 探测速率太大,INT 数据包本身在网络设备中的处理开销就会大幅提高,使转发处理时延大大增加,反而不利于提升探测结果的精确度。因此,在实际部署中,需要依据具体的探测精度需求和探测开销评估,设计合适的INT 探测速率。 综上,本节对本文提出的方法与其他网络测量方法进行比较分析。对于非INT 方法来说,存在测量效率和测量功能的缺陷。例如基于Poll 模式的SNMP 控制平面对数据平面的数据采集时延往往为0.4~21.1 ms[17]。而本文方案的探测时间间隔在目前的机器配置下能够轻松达到0.13 ms。对于NetFlow、sFlow、IPFIX 等方法[18-21],本文方案可以探测到交换机端口的拥塞和排队信息,而不仅仅局限于包计数或流量计数等宏观信息。相较于Pingmesh[22],本文方案除了能够监测路径拥塞状态,还能监测路径上逐跳交换机的拥塞状态。对于基于协议无关转发架构实现的P4 硬件交换机[9,10,33]来说,本文方案更好地支持虚拟网络设备,而不依赖于协议无关转发架构本身。对于BMv2 软件交换机[30]来说,表1 显示VPP 的转发性能远高于BMv2,这也意味着本文方案可以在实际生产环境部署,而不是仅仅局限于网络功能验证的场景。 虚拟网络设备在数据中心内被大量使用。在虚拟网络设备上增加低时延、高精度的带内网络遥测功能有助于在大规模数据中心内开展实时流量可视化、故障快速定位、细粒度流量工程等网络优化任务。作为P4 的重要应用之一,带内网络遥测依赖于协议无关转发架构,目前仅有少量可编程硬件交换机支持该能力,大多数虚拟网络设备均无法运行P4 程序,以提供带内网络遥测的直接支持。本文首先基于开源虚拟网络设备VPP,设计了带内网络遥测的实现方案;然后基于带内网络遥测协议规范定义了相关数据包的报文格式,基于VPP 的数据包处理框架构造了数据平面的流水线处理模块,并在此基础上实现了一种带内全网遥测机制的扩展案例;最后基于虚拟机组网方式,搭建网络拓扑并进行了网络性能测试,通过实验展示了不同背景流量速率和不同探测频率下的遥测性能数据。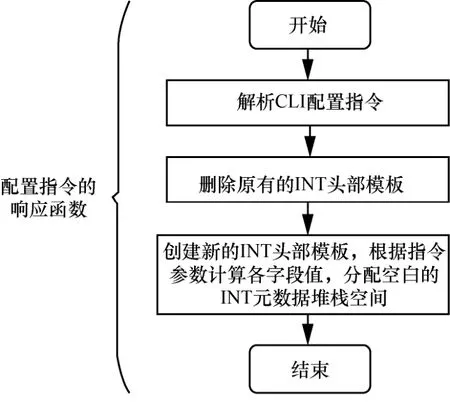


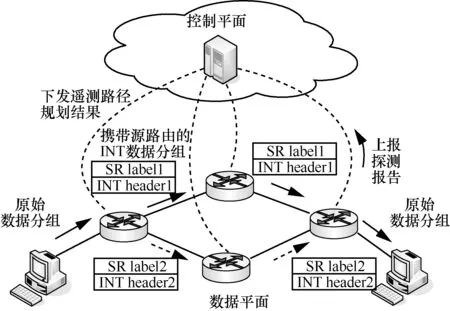
4.3 扩展案例:带内全网遥测

5 系统功能和性能评测
5.1 实验环境
5.2 实验场景及目的
5.3 测试流量生成方法及流量路径
5.4 实验过程及结果分析
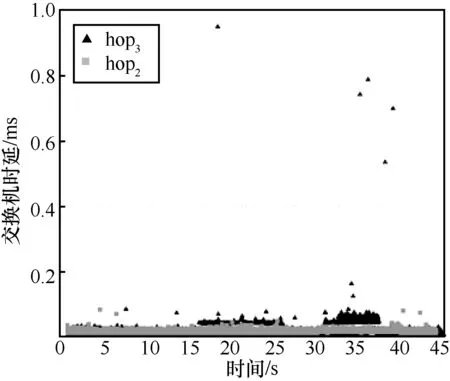
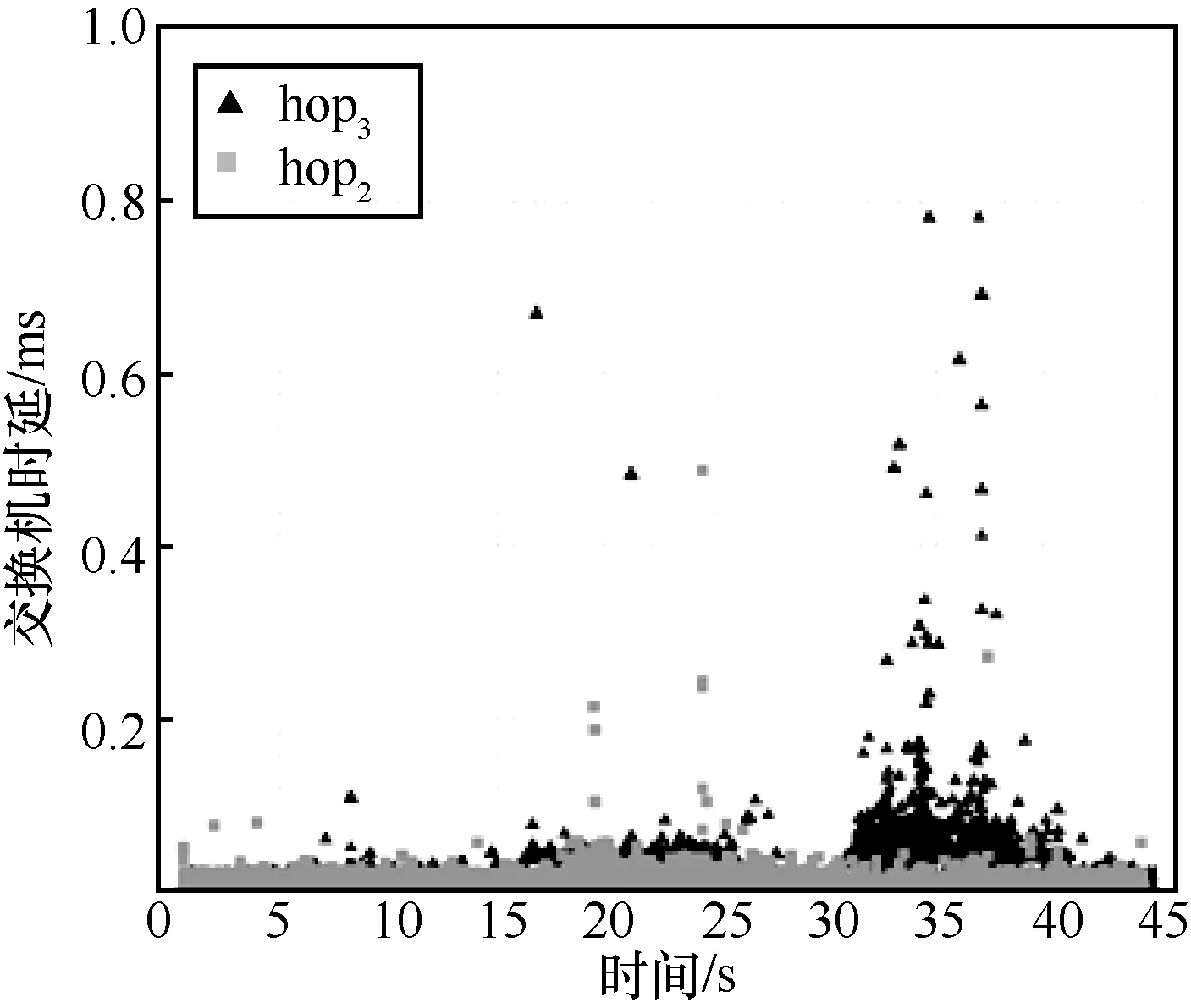
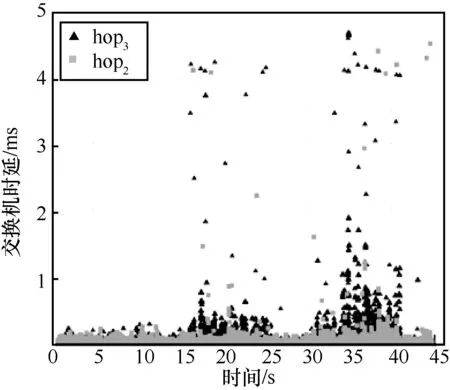
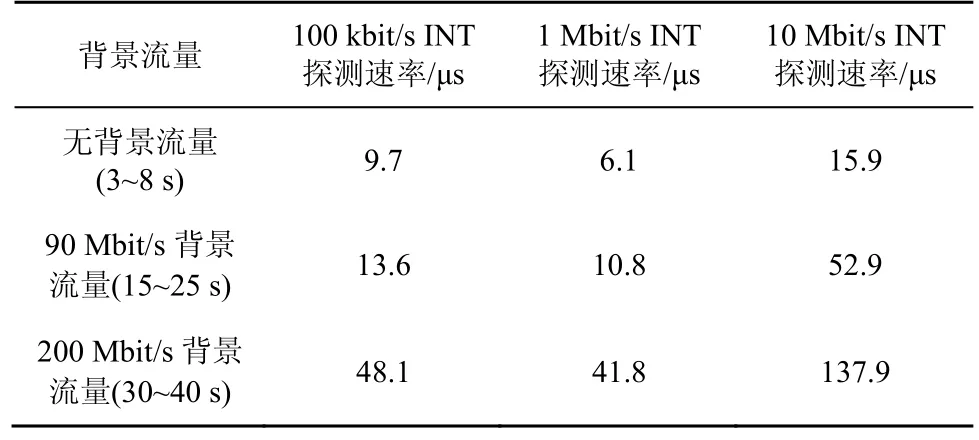
5.5 与其他网络测量方法的比较分析
6 结束语
