基于层级注意力机制的链接预测模型研究
2021-04-09赵晓娟贾焰李爱平陈恺
赵晓娟,贾焰,李爱平,陈恺
(1.国防科技大学计算机学院,湖南 长沙 410073;2.湖南工业大学商学院,湖南 株洲 412007)
1 引言
在资源描述框架(RDF,resource description framework)下,知识可以表示为事实三元组,即(头实体,关系,尾实体)的形式,例如“A 是一名运动员”可表示为(A,职业,运动员),其中,“A”“职业”“运动员”分别是三元组的头实体、关系和尾实体。知识也可以表示为有向多关系图,即知识图谱,其中,每个节点对应一个实体,连接节点的每条边对应一种关系。知识图谱中的一个三元组或者事实h,r,t表示一对实体及实体之间的关系。图1为RDF 表示与知识图谱表示的示例。
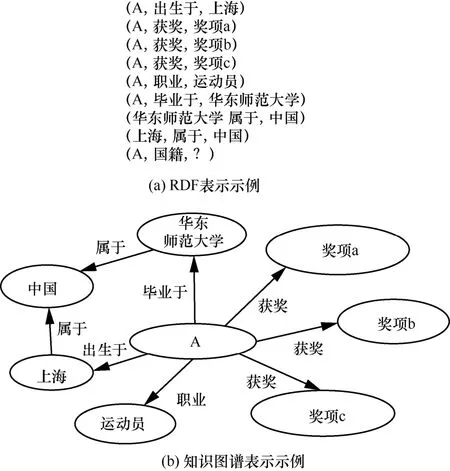
图1 RDF 表示与知识图谱表示的示例
知识图谱嵌入旨在学习知识图谱中的每个元素(实体和关系)在连续低维度向量空间中的潜在表示,使知识图谱具有可计算性,并且更容易与深度学习模型集成。它支撑着许多实际应用,包括知识问答[1-3]、推荐系统[4-6]和其他自然语言理解任务[7-9]。然而,即使YAGO[10]、DBPedia[11]、Freebase[12]这样包含了数十亿个事实的大型知识图谱,也不能避免关系或者节点缺失的问题[2,13-14],从而引出了知识图谱补全任务的研究。这类研究任务一方面利用知识图谱中已经存在的信息来自动推断缺失的事实,另一方面预测三元组是否有效。
在知识图谱中,实体存在的意义很大程度上取决于其连边的关系类型,同一个实体在不同的关系下,其表示的重点也应有所不同。例如,对于图1中的实体“A”作为(A,职业,运动员)的头实体,在嵌入表示时更多地体现作为一个运动员的属性;作为(A,毕业于,华东师范大学)的头实体,在嵌入表示时则更多地体现作为学生的一些属性。考虑(A,国籍,?)这样一个链接预测问题,根据问题中的关系“国籍”可知,“职业”和“获奖”这2 种关系对推理“国籍”的贡献不会比“出生于”和“毕业于”这样的关系大,因为与“出生于”和“毕业于”相连的尾实体才是与国籍有关的地点。
事实上,当使用知识图谱嵌入技术将实体和关系投影到低维连续向量空间时,根据已知事实(A,出生于,上海)和(上海,属于,中国),本文可以把“A”和“中国”都映射到“上海”附近的向量空间,所以它们在向量空间中的距离比较近,而且,在关系嵌入的向量空间中,相对于“职业”和“获奖”,“出生于”与“国籍”的嵌入向量所表达的语义更接近。因此,通过“出生于”推导出“国籍”的尾实体比通过“职业”或“获奖”推导出的结果更可信。
深度学习的注意力机制模拟人类的选择性视觉注意力,从众多信息中选择与当前预测目标最相关的信息,并根据这些信息做出预测,近年来被各个领域的不同任务广泛采用。文献[15]提出一种在知识图谱推理中关注关系的方法,对不同的关系赋予不同的注意力,但是该方法与其他图神经网络一样,在训练过程中,随着网络层数的增加和迭代次数的增加,每个节点的隐层表征会趋向于收敛到同一个值,即通常所说的过度平滑问题。
基于前述问题,本文提出一种新的层级注意力机制的链接预测模型。模型的主要思想是通过分层聚合来避免过度平滑问题,同时,在关系子图之间的信息聚合时,设计一种更简洁的关系注意力机制,可以根据预测问题中的目标关系对知识图谱中给定实体不同类型的关系给予不同的注意力。具体来说,在低维向量空间中,学习给定实体及其多跳邻域的实体和关系的特征,根据与目标关系的距离分配注意力,通过将更多的注意力分配给语义更接近的关系来获得更准确的尾实体预测结果。
本文的主要贡献是设计了一种基于分层注意力机制的嵌入模型,并将模型应用在知识图谱链接预测任务中。分层注意力机制除了关注多跳邻居实体特征外,能更加关注关系特征以找到符合目标关系的关系类型。
2 相关研究工作
以图神经网络(GNN,graph neural network)[16]为基础的图卷积网络(GCN,graph convolutional network)[17]能同时对节点特征信息与结构信息进行端对端学习,是目前对图数据学习任务的最佳选择。从GCN 开始,研究者越来越多地关注将卷积运算引入图领域,这里的图是指图论中用顶点和边建立相应关系的拓扑图。但是,传统的离散卷积在知识图谱这种非欧几里得数据上无法保持平移不变性,如何定义能够处理大小可变的邻居集和共享参数的操作是一个具有挑战性的问题。
为了解决这个问题,文献[18]提出GraphSAGE(graph sample and aggregate)模型,从每个节点的邻居节点中提取固定数量的节点,然后使用聚合函数融合这些邻居节点的信息。当然,这也意味着模型不能采样到所有的邻居。与文献[18]类似,图注意力(GAT,graph attention)[19]也是该研究领域一个典型的模型,这个模型是基于所有邻居节点,而且对邻居节点的顺序没有要求。虽然该模型在图网络结构中取得了成功,但不能直接用于知识图谱,因为这个模型仅考虑了节点,而忽略了知识图谱中非常重要的一部分信息,即知识图谱中实体之间的关系。本质上,GCN[17]和GAT[19]都是将邻居节点的特征聚合到中心节点,利用图上的局部平衡状态学习新的节点特征表达式;不同之处在于GCN 使用了拉普拉斯矩阵,而GAT 使用的是注意力机制。CompGCN[20]是一个考虑多种关系信息的图神经网络框架,它通过共同学习多关系知识图谱中关系和节点的向量表示,解决了传统GCN 的难点。为了避免随着关系数量增加,参数数量显著增加的问题,CompGCN 使用一组基作为可学习的基向量,而不是为每个关系定义嵌入。
实际上,对于每个节点,模型选取它的一些邻居,每个邻居对节点都有一定的影响,但每个邻居的影响力都可能不同,文献[17,20]没考虑每个邻居对节点的影响力的差异。因此,文献[21]提出了一种端到端的模型,该模型在聚合每一层节点特征时考虑了知识图谱中的关系,但是,该模型在计算注意力时只考虑了关系和实体表示的简单拼接,并没有反映不同关系对特定推理任务的重要程度不同。文献[22]的Minerva模型将每一种关系设置为一种任务类型,在预训练中针对特定任务进行模型训练,这实际上是一种考虑知识图谱中不同类型关系的实践,该模型根据关系对三元组进行分类,并没有分别考虑邻居节点和关系对目标节点嵌入的影响。
3 任务描述
在知识图谱链接预测任务中,目标是当u或v丢失时,推断一个三元组(u,r,v)是否是有效三元组,即给定(r,v)推导u或者给定(u,r)推导v,本文研究的任务包括(u,r,?)和 (?,r,v)。对于这2 种情形,本文并没有单独为每一种情况训练一个模型,而是训练了同一个模型用于这2 种情况的评估。对于每个测试三元组(u,r,v),本文用知识图谱中存在的所有实体替换每个头实体,构造(n-1)个被损坏的三元组,然后对每一个这样的三元组评分。最后将这些分数按升序排序,得到正确的三元组的排列。本文也可以用同样的方法替换三元组的尾实体。
知识图谱用G=(E,R,V)表示,这里的E、R、V分别表示实体、关系、三元组的集合。V={(u,r,v)∈E×R×E},其中,u,v∈E是实体,r∈R是实体之间的关系。嵌入模型尝试学习一个有效的函数f(g),对于给定的输入三元组T=(u,r,v),f(T) 给出T是一个有效三元组的可能性。
4 模型设计
4.1 模型整体框架
本节将详细描述本文提出的模型。异构图注意力[23]在异构图神经网络中使用分层注意力机制,包括节点级别的注意力和语义级别的注意力。受该思想的启发,本文提出了一种新的基于层级注意力机制的链接预测模型。整个链接预测模型主要由两部分组成:编码部分和解码部分,RAKGR(relation attention based knowledge graph reasoning)作为编码器,ConvKB[24]作为解码器。RAKGR 由多层组成,整体框架如图2 所示,其每一层由GAT 和关系注意力(RAT,relation attention)两部分组成。每一个GAT 和RAT 都由多个注意力头组成。本文假设RAT和GAT 的注意力个数相同。图2 中的多头注意力拼接展示了将每个注意力头的输出结果concat 之后再降维,也可以直接求各个注意力头输出的平均值。ConvKB 由一个二维卷积Conv2D 表示,其相关内容详见文献[24]。
图3 给出了某一层中的某个注意力头“GAT+RAT”示例,来说明图 2 中所示的“GAT+RAT”的工作原理。这里仅表示单一注意力头,且仅说明其中一层的情况。中心节点0 有9 个一阶直接邻居,将这些邻居分成3 个邻居子图{1,2}、{3,4,5,6}、{7,8,9},这3 个子图与中心节点之间的关系分别为r1、r2和r3。图3 中右侧黑色圆圈表示每个中心节点0 为每个邻居子图设置的对应的虚拟节点。相应地,分别对应基于关系r1、r2和r3的子图在聚合邻居信息后的中心节点0 的嵌入表示。首先,用GAT 聚合子图内部各节点的信息;然后,用关系注意力机制聚合这3 个虚拟节点的信息,以获得更新后的中心节点0的嵌入表示。
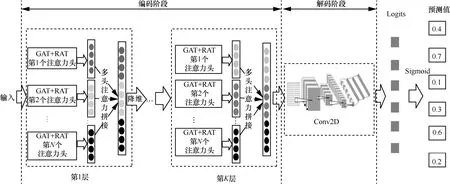
图2 RAKGR 整体框架

图3 某一层中的某个注意力头“GAT+RAT”示例
4.2 构建邻居子图
给定三元组(u,r,v)∈G,分别表示u、r、v对应的初始嵌入。本文用TransE[25]获得模型的初始嵌入,然后分别用2 种类型的转换矩阵VW和WR将节点和关系投射到相同的特征空间。本文将某个中心节点的所有一阶邻居根据其与中心节点之间的关系类型分成不同的子图,也就是说,中心节点与它的一阶邻居之间有多少种类型的关系,就会生成多少个邻居子图。每个子图中所有节点与中心节点之间的关系是一样的。与文献[23]类似,本文将聚合的过程分为2 个级别:子图内部的信息聚合和关系子图之间的信息聚合。
4.3 子图内部的信息聚合
为了获得节点v的新的嵌入表示,本文将与该节点相连的每一个实体表示为
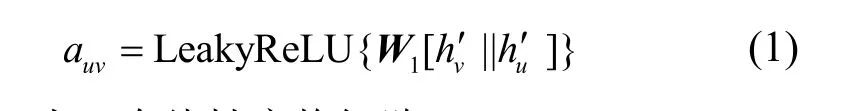
其中,W1为一个线性变换矩阵。
在考虑邻居节点对目标节点的重要性时,本文用auv表示注意力的绝对值。然后,类似于GAT[19],将上述注意力的绝对值进行归一化,如式(2)所示。
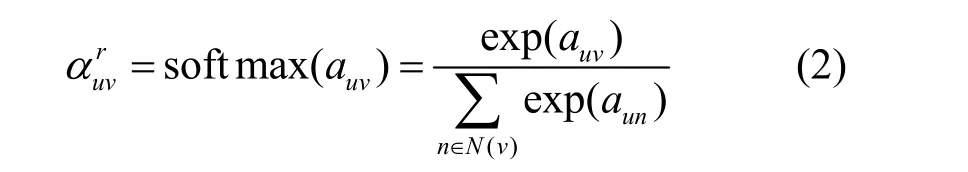
其中,为节点u与节点v在关系r下的相关权重系数,N(v) 为与节点v直接相连的邻居节点的集合。根据式(2)中得到的相关性权重系数,用式(3)将子图中每个邻居的信息进行聚合。
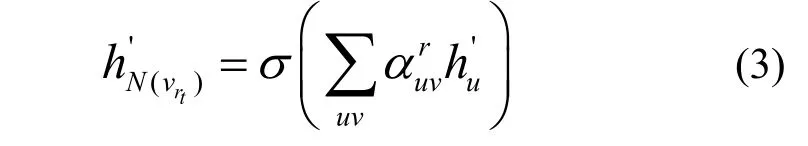
其中,为关系rt下节点v聚合邻居节点信息后的嵌入表示;N(vrt)为与节点v之间存在关系rt的邻居节点的集合。
使用多头注意力机制可以获取更多关于邻居节点的信息,因此,对应多头注意力机制的情况,可将式(3)转换为
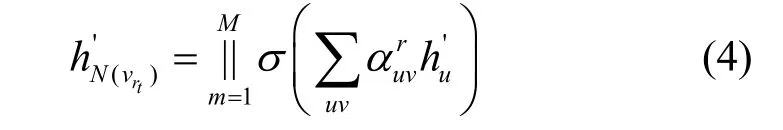
其中,||表示拼接操作,是一种集成多个注意力头输出结果的聚合方式。多头和单头的区别在于每个注意力头的权重系数不一样,但模型是一样的。
假设用一个虚拟节点来表示某个邻居子图的所有信息,那么中心节点与邻居子图之间的关系就简化成了节点与节点之间的关系。对应于关系tr的虚拟节点可表示为
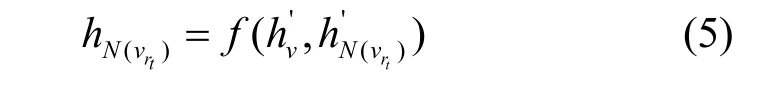
其中,f(·) 是转换函数,是中心节点v在高维空间中的嵌入表示。由此可以得到T组特定关系的节点嵌入为{hN(vr1),hN(vr2),…,hN(vrt)}。
4.4 关系子图之间的信息聚合
根据目标关系给每个邻居子图分配不同的注意力值,也称为关系子图级别的聚合。本文要给每个邻居子图计算一个注意力分数atr。区别于A2N(attending to neighbor)[15]的注意力机制,本文将子图之间信息聚合环节的注意力分数表示为
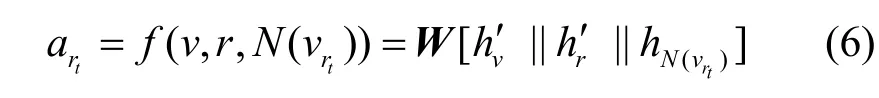
对上述注意力分数atr进行标准化处理,得到每个邻居子图对中心节点v的相关性权重值为
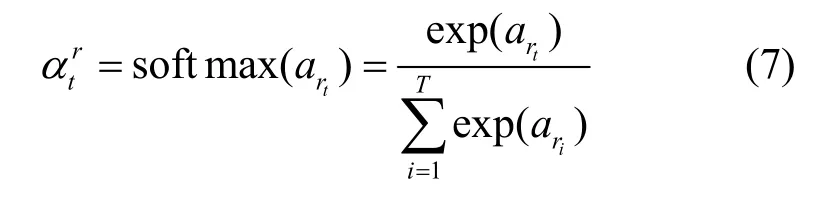
将学习到的权重作为系数,聚合这些特定关系的嵌入,得到节点v更新后的嵌入表示为
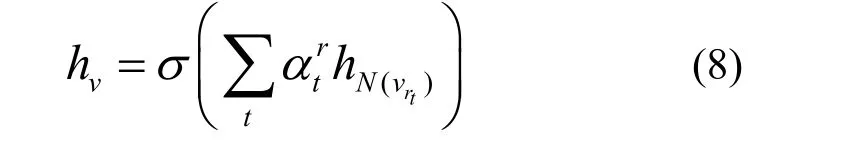
其中,代表与中心节点之间存在关系rt的邻居集对中心节点v的嵌入表示的影响,也就是hN(vrt)对hv的影响;hv是中心节点v更新后的嵌入表示。上述过程仅描述了RAKGR 模型的单层单头注意力聚合过程。同理,可以采用多头注意力机制获得更丰富的邻居信息。类似地,M个注意力的情况表示为
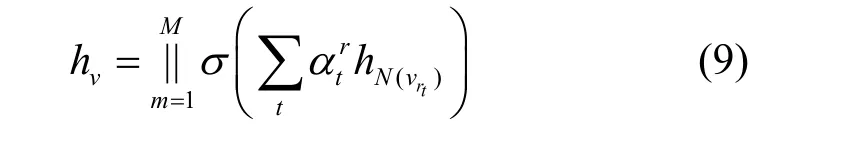
上述聚合过程可以扩展到多层,使模型具有高阶传播的特点,即
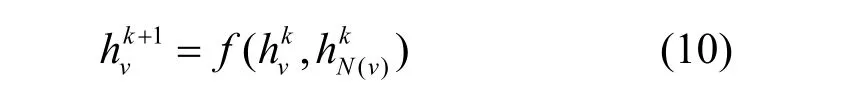
对于一个节点与另一个节点之间存在多个关系的情况,本文将这个节点复制n次得到n个不同的节点,因此,本文在后续知识图谱推理的应用中根据知识图谱中边的数量来构建邻居子图。
4.5 模型优化目标
本文的模型第一阶段训练目标借鉴了TransE[25]的平移平分函数的思想。对于一个给定三元组=(u,r,v),学习一种嵌入表示,其能量函数定义为
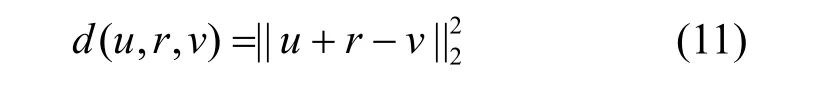
本文使用基于边际的评分函数作为训练目标,定义为
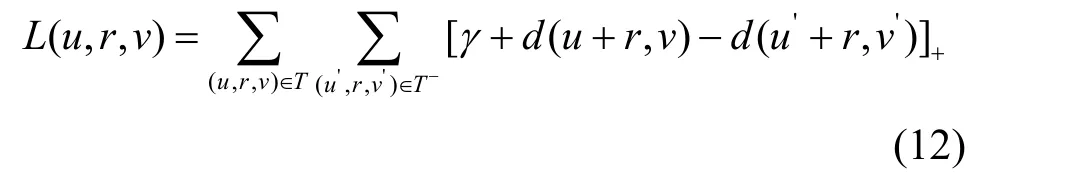
其中,[x]+表示取x正的部分,γ>0 表示一个边际超参数,(u,r,v)∈T,T表示有效三元组集合,也称之为正样本,而T-则是负样本,表示为

本文通过用其他实体替换三元组的头实体或者尾实体来得到负样本。
第二阶段的ConvKB 采用与文献[21]类似的方法,定义评分函数为

其中,ei、er和ej分别表示头实体的最终嵌入、关系的最终嵌入和尾实体的最终嵌入;concat 表示将这些嵌入表示拼接起来;*表示卷积操作;κ表示卷积核的个数;ωm表示第m个卷积核;W表示一个线性变换矩阵,用于计算三元组的最终得分。本文使用soft-margin 损失对模型进行训练,表示为

表1 数据集的统计情况

5 实验
5.1 实验数据集
本文提出的层级注意力机制中,子图之间的注意力分配重点考虑了关系在预测任务中的意义,所以,本文选取FB15k-237[26]、WN18RR[27]这2 个数据集评估前述模型。一方面,FB15k-237 中有237 种关系,是一种典型的多关系数据集,可以用来验证本文的模型在关系类型较多的情况下其优势更加明显,WN18RR 的节点数比较多,但关系只有11 种;另一方面,由于WN18[28]和FB15K[25]中存在很多逆关系,这些逆关系会影响本文预测任务的结果,因此,本文使用的是WN18 和FB15K 删除了逆关系之后的子集WN18RR 和FB15k-237。数据集的统计情况如表1 所示。
5.2 实验设置
本文的实验中用到的初始实体嵌入和关系嵌入用TransE[25]获得。模型的训练分成2 个步骤。首先,使用RAKGR 模型对知识图谱中的实体和关系进行编码;然后,使用ConvKB 对得到的节点和关系表示进行解码,以得到符合链接预测任务的知识表示方式。
在这类任务中,通常的做法是将正确答案的排列顺序记录在有序列表中,以便确定是否可以将正确答案排列在错误答案之前。常用的3 个评估指标是平均排序(MR,mean rank)、平均倒数排序(MRR,mean reciprocal rank)和N个正确排序所占的比例(Hits@N)。MR 是所有排序的均值;MRR 与MR 类似,但是MRR 是一种比MR 更稳健的衡量方法,因为某一的特别糟糕的排名可以在很大程度上影响平均排名;Hits@N中的N可以取1、3 和10。对于本文模型,MRR 和Hits@N的值越大意味着模型性能越好,MR 的值越小意味着模型性能越好。本文选择MRR 和Hits@1、Hits@3、Hits@10 作为评估指标。
为了评估RAKGR 模型性能,本文选择了几类目前较先进的知识图谱嵌入模型进行对比,包括A2N[15]、Minerva[22]、ConvKB[24]、TransE[29]、DistMult[29]、Complex[30]、ConvE[28]。
5.3 实验结果与分析
实验结果如表2~表5 所示。A2N、DistMult、Complex、ConvE 的实验结果来自文献[15],该文献下载了公开的源代码来复现所有的结果;ConvKB、TransE 在2 个数据集上的实验结果是本文下载公开源代码并复现的结果;Minerva 在2 个数据集上的结果来自文献[22]。文献[21]指出,对于一个n层模型,其输入信息是从n跳的邻域上累积的。所以,本文实验设置为2 层模型,相当于聚合了2 跳邻域的信息。当然,本文提出的模型是可以扩展到任意层数的。
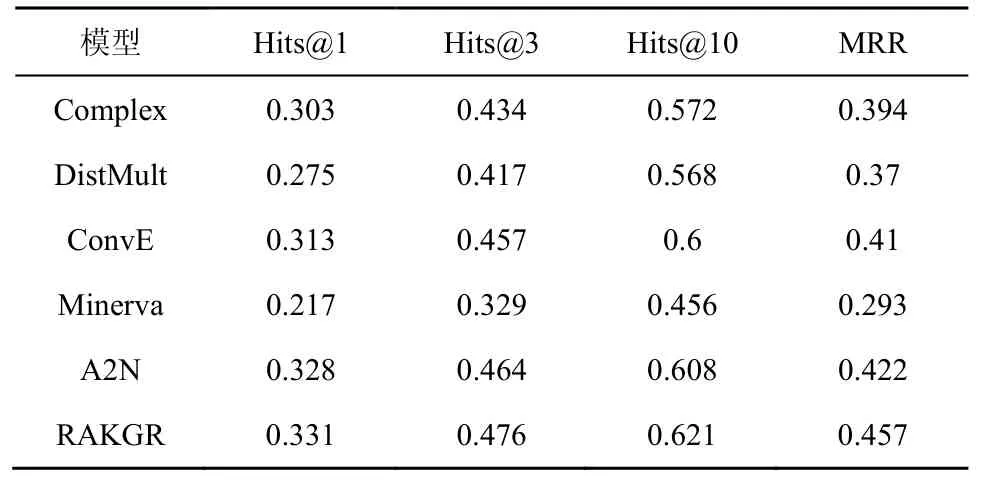
表2 数据集FB15k-237 预测尾实体的实验结果
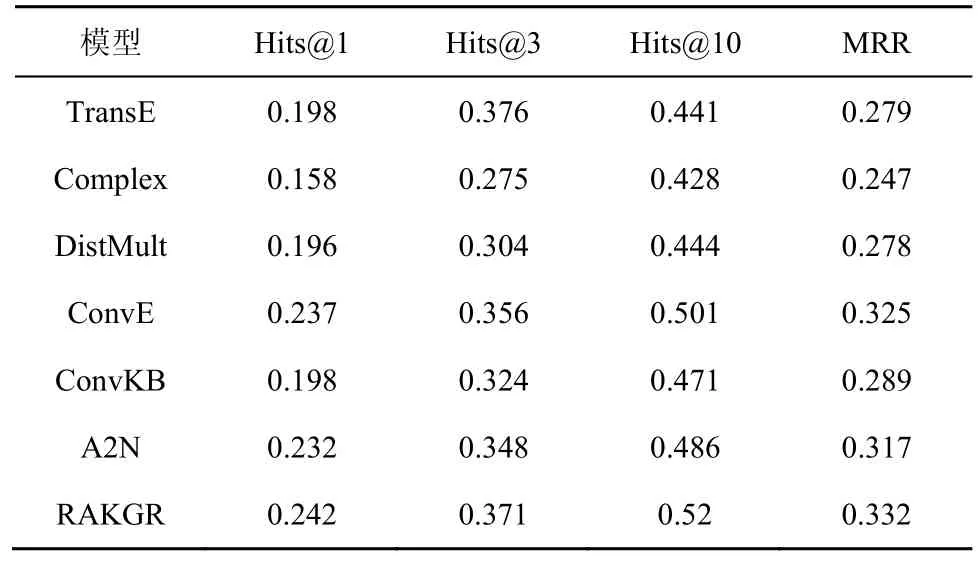
表3 数据集FB15k-237 预测尾实体或者头实体的实验结果

表4 数据集WN18RR 预测尾实体的实验结果

表5 数据集WN18RR 预测尾实体或者头实体的实验结果
表2 和表4 中提到的预测尾实体是指单独针对(h,r,?)这样的任务模型得到的结果,ConvKB、TransE 的源代码中并没有提供单独预测尾实体的代码,所以本文没有展示其结果。表3 和表5 中的结果是指测试集中同时存在头实体缺失(?,r,v)或者尾实体缺失(u,r,)?这2 种情况。文献[21]没有提供Minerva 在同时预测头实体或者尾实体缺失情况下的实验结果,所以在本文的表3和表 5 中没有相应的结果展示。表 2 展示了FB15k-237 在已知头实体和关系,预测尾实体的结果。可以看出,本文模型的所有4 个评价指标都具有较显著的优越性。表3 展示了在测试集中同时存在头实体缺失或者尾实体缺失的情况,尽管这种情况下模型性能比表2 中展示的结果稍逊色,但本文模型性能明显优于其他模型。
表4 和表5 展示了WN18RR 数据集上的实验结果。可以发现,在WN18RR 数据集上,本文模型性能与A2N 接近,并没有绝对优势。因为WN18RR 有40 943 个实体,但是仅有11 种类型的关系。本文模型在较多关系的数据集上具有优势,对于这一类关系较少而节点数又较多的数据集并不能很好地体现模型的优越性。
从上述结果可以看到,所有的模型在已知头实体和链接预测尾实体情况下的实验结果普遍比同时预测尾实体或者头实体的情况好。这是因为FB15k-237 与WN18RR 中删除了逆关系,这种逆关系对于已知尾实体和关系预测头实体的情况会有影响,但对已知头实体和关系预测尾实体的情况基本没有影响。另外,在2 个数据集上的实验结果表明,本文模型具有较好的稳健性,在不同的数据集上性能稳定。
5.4 模型的输出结果测试实例
为了对层级注意力机制有更加清晰的支持和解释,本文从 UMLS(unified medical language system)数据集[31]的测试集中随机选取了一个实体n79和一个关系r40来进行链接,然后预测(n79,r40,?),这个测试用例在训练集中是没有出现过的。模型的输出结果测试实例如图4 所示,中心节点n79的一阶邻居节点共56 个,关系类型共8 种。其中,17 个节点与n79之间的关系是r17,9 个节点与n79之间的关系是r10,21 个节点与n79之间的关系是r0。为了简化,图4 只表示了主要关系和节点,邻居节点集合分别用N(vr17)、N(vr10)、N(vr0)表示,且这3 个邻居节点集合中所有节点在训练集中都没有作为n90的头实体。将式(6)进行修改,直接用类似RAT 的机制计算关系注意力分数,如式(16)所示。
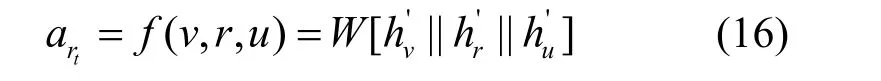
观察图4 可以得到以下2 个重要的结果。
1) 图4(a)是用修改后的RAT 得到的结果。注意力分数排名前三的关系分别为r0(0.321 4)、r10(0.140 7)、r17(0.230 5)。n79有56 个一阶邻居,该方法中,注意力分数在56 个三元组中进行分配,前述注意力分数对应所有与n79之间存在该类关系的三元组注意力分数之和;三元组(n79,r43,n41)、(n79,r43,n39)、(n79,r43,n29)得到的注意力分数分别是0.020 3、0.0180 4、0.016 5。图4(b)是利用本文的层级注意力机制得到的结果,排名前三的关系分别为r43(0.136 6)、r0(0.131 7)、r38(0.111 4)。该方法中,注意力分数在8 种不同的关系中进行分配。
2) 注意力模型可以加强链接预测结果的可解释性。从关系的语义可以看到,本测试实例的关系r40(adjacent_to,与…相邻)属于空间上相关,r43(surrounds,包围)也属于空间上相关,两者在语义上比较接近;排名第二的关系r0(location_of,位于)属于空间上相关;排名第三的关系r38(developmental form of,…的发育阶段)属于概念上相关。
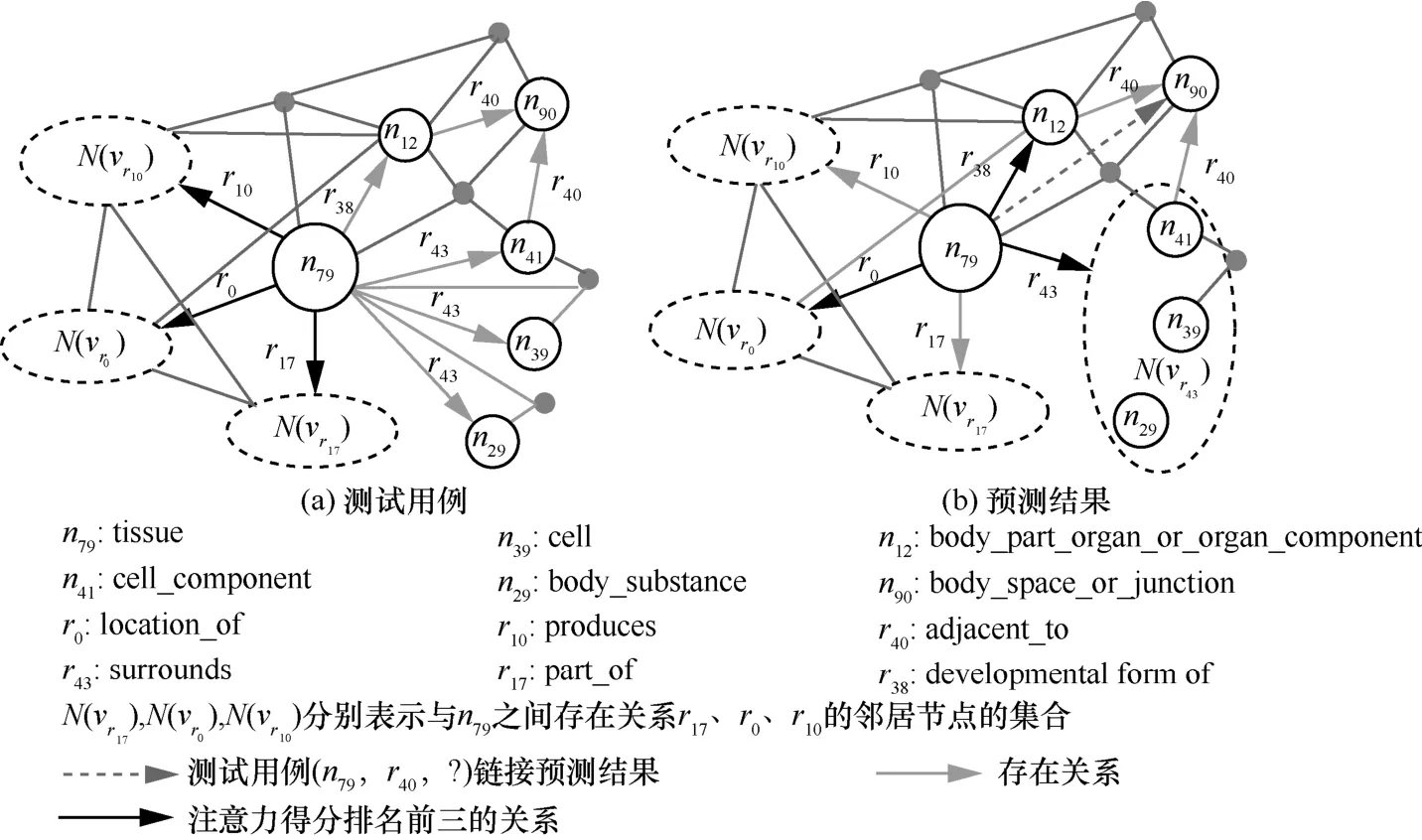
图4 模型的输出结果测试实例
6 结束语
本文介绍了一种基于层级注意力机制的链接预测模型,并将其应用于知识图谱链接预测任务。所提模型取得了比目前较先进的模型更好的结果。在未来的工作中,可以扩展所提模型,针对不同类型的节点设计不同的线性变换矩阵,在考虑知识图谱结构的同时,考虑节点的语义信息。另外,可以考虑在嵌入表示时融合知识图谱中实体和关系的相关描述信息和文本信息,从而进一步提高知识图谱推理的性能,而不是仅考虑知识图谱内在的信息。本文提出的模型具有高阶传播特性,可以捕获给定实体周围多跳的关系信息,在未来的工作中可以考虑将该模型应用在基于知识图谱的多跳推理以及基于知识图谱的复杂关系问答等应用中。
