高误码率下LDPC 稀疏校验矩阵重建
2021-04-09吴昭军张立民钟兆根刘仁鑫
吴昭军,张立民,钟兆根,刘仁鑫
(1.海军航空大学航空作战勤务学院,山东 烟台 264001;2.海军航空大学航空基础学院,山东 烟台 264001)
1 引言
为了对抗信道中噪声的干扰,数字通信系统中广泛采用信道编码技术。受Turbo 码迭代译码思想的启发,LDPC(low density parity check code)被再次发现,目前,已经被广泛应用于如IEEE 802.11、DVB-S2 等数据传输协议中。从非合作通信方的角度,研究高误码率条件下LDPC 稀疏校验矩阵的重建,对于目前大量采用LDPC 编码的通信协议逆向分析具有非常重要的意义。
目前,针对信道编码参数识别的研究主要集中于分组码[1-2]、卷积码[3]以及Turbo 码[4-7]等,而对LDPC 参数识别的文献较少。同时,在有误码条件下LDPC 稀疏校验矩阵的重建问题一直是一个难点,主要原因在于LDPC 的码长较长,在有误码条件下,目前针对信道编码识别的算法,如矩阵分析[8]、Walsh-Hadarmd 变换[9]等往往失效。从已发表的论文来看,LDPC 的重建分为闭集识别和开集识别。针对LDPC 的闭集识别,文献[10-11]引入了对数似然比(LLR,log-likelihood ratio)的概念,将LDPC闭集识别问题等价于LLR 的优势统计问题,即遍历闭集中可能的LDPC 稀疏校验矩阵,求解出对应于LLR 值最大的稀疏校验矩阵,从而完成识别。为了提高算法的实时性,文献[12]详细分析了LLR 的统计特性,基于最小错误判决准则设定最优门限,快速完成闭集中LDPC 识别,但文献[12]为了简化计算,在计算LLR 时进行了近似处理,使在低信噪比下基于LLR 的识别算法性能变差。针对该问题,文献[13]提出了基于余弦符合度的识别方法,该方法计算比较简便,同时未采用近似处理,在低信噪比下性能明显优于基于LLR 的算法。虽然文献[10-13]能够在低信噪比下完成LDPC 识别,但是这种识别的前提条件是已知几类稀疏校验矩阵,严格来说这不是真正的盲识别,在某些微波通信或是短波通信系统中,通信协议往往是人为设定的,对于非合作方而言,几乎没有先验信息,故LDPC 的开集识别更具实用性,同时也更具挑战性。文献[14]最先研究LDPC 开集识别问题,首先利用截获的数据构造码字矩阵,然后采用高斯消元方法得到校验向量,同时利用校验向量对误码码字进行筛选和剔除,该方法虽然具有一定的容错性,但是在有误码条件下所需数据量较大,同时获得的校验矩阵是非稀疏的,无法用来译码。为了获得稀疏校验向量,文献[15]提出了基于2 阶行消元和P阶行消元变换的校验矩阵稀疏化算法,该算法针对双对角线形式的稀疏矩阵具有较好的实用性,但是对于非双对角线形式的稀疏矩阵,其消元的阶次较高,计算复杂度会急剧增大。为了克服文献[15]的缺点,文献[16]提出基于Canteaut-Chabaud 算法[17]的随机稀疏化方法,该方法的通用性较好,对于非双对角线形式的稀疏校验矩阵也能较好地重建,但是该方法需要多次的迭代消元,在稀疏化过程中具有一定的盲目性,这使方法的计算复杂度较高。文献[18]从提高LDPC 校验矩阵重建性能出发,引入了LDPC 反馈迭代译码方法,利用重建的部分稀疏校验向量对LDPC 译码纠错,从而改善获取的码字质量,较好地提升了算法的性能,但是该算法需要反复进行高斯消元、稀疏化以及迭代译码,导致其计算复杂度很高。从目前LDPC 研究现状来看,开集识别仍然是一个棘手的问题,还需要进一步从计算复杂和容错性能2 个方面改进。
基于此,本文提出了一种新的LDPC 稀疏矩阵重建方法,该方法首先多次随机抽取码字中部分比特进行高斯消元,当随机抽取的比特位包含稀疏校验向量的校验位时,消元后的结果张成的空间中一定包含稀疏校验向量,从而完成稀疏校验向量的获取;其次,为了使随机抽取过程中可靠出现抽取的位包含稀疏校验向量校验位,分析了一次随机抽取包含校验位的概率,得到了最小抽取次数;最后,详细分析了有误码条件下疑似稀疏校验向量的统计规律,基于最小错误判决准则,实现了LDPC稀疏校验向量的判定,最终完成稀疏校验矩阵的重建。
2 LDPC 原理以及重建问题描述
LDPC 是由稀疏校验矩阵来定义的。1962 年,Gallager 通过稀疏校验矩阵的特性定义了LDPC;Tanner 在稀疏校验矩阵的基础上结合图论提出了LDPC 因子图描述方法。下面,给出稀疏校验矩阵以及LDPC 的定义。
定义1[19]一个线性分组码的监督矩阵中元素“1”的个数占总元素个数的比例非常小,则这个监督矩阵被称为稀疏校验矩阵,这个线性分组码被称为LDPC。
对于一个维度为(n-k)×n的LDPC 稀疏校验矩阵H,通过初等行变换方式,可将其转化为标准形式,即
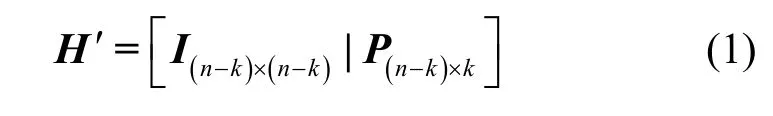
其中,I(n-k)×(n-k)为(n-k) × (n-k)维的单位矩阵。由标准形式的校验矩阵,可得到LDPC 的生成矩阵为
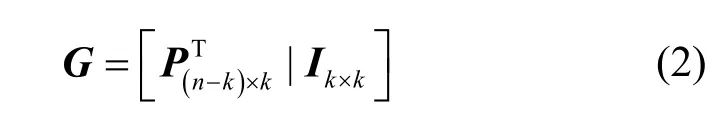
其中,Ik×k为k×k维的单位矩阵,矩阵PT为P的转置。
将待编码的信息序列按照kbit 分成一组,然后与G相乘,即可得到LDPC 的码字。在目前的通信系统中,每一帧数据都有固定的同步码,利用同步码可以快速完成LDPC 的码长以及码字起点的识别,所以LDPC 识别的重点是在有误码的条件下利用截获的码字序列重建出LDPC 的稀疏校验矩阵H。
3 传统重建算法的缺陷
传统的LDPC 稀疏校验矩阵重建主要分为两步,即非稀疏校验矩阵的获取[14]和校验矩阵稀疏化处理[15],其中非稀疏校验矩阵的获取是校验矩阵稀疏化处理的前提。传统方法将整个LDPC 的码字进行高斯消元,然后得到非稀疏的校验向量,不妨设LDPC 的码长为n,截获到的序列长度为l,构造的码字矩阵为A,即
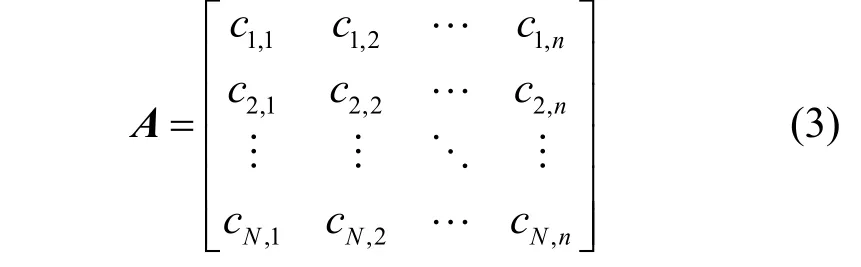
设在高斯消元过程中,A的初等行变换矩阵为RN×N,初等列变换矩阵为Sn×n,则经过初等行变换以及初等列变换后,矩阵A变为
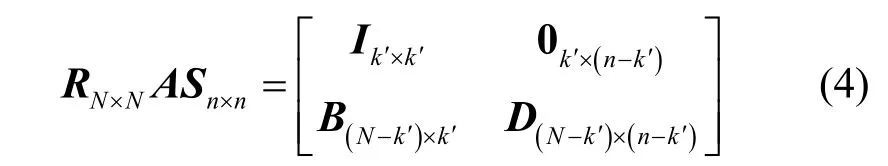
其中,0k′×(n-k′)为k′× (n-k′)维的全零矩阵。
设列变换矩阵Sn×n=[s1,s2,…,sn],其中si(1≤i≤n)为Sn×n的列向量,在无误码条件下,式(4)中k′=k,此时列向量s k+1,sk+2,…,sn正好构成LDPC 非稀疏校验矩阵,同时D(N-k′)×(n-k′)为全零矩阵;当存在误码时,部分线性关系受到破坏,此时k′>k,列向量sk′+1,sk′+2,…,sn构成LDPC 部分非稀疏校验矩阵,同时D(N-k′)×(n-k′)为一稀疏矩阵。在极端情况下,k′=n,矩阵A为列满秩矩阵,未能重建出非稀疏校验向量。由上述分析可知,对A进行高斯消元时,真正对结果产生影响的是前n个码字,只有当前n个码字同时满足同一校验关系时,才能得到校验向量。
不妨设LDPC 中某一校验向量为v,其码重为w,当误码率为pe时,通过对矩阵A进行高斯消元,仍能得到校验向量v,则必须满足以下条件:向量v中元素为1 的位置对应于A中前n个码字中比特没有出现误码或出现误码的个数为偶数,此时通过模2 运算,误码没有产生影响,即单个码字满足v的校验关系概率为
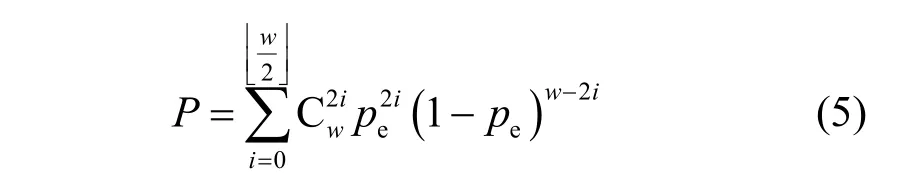
其中,C 表示求组合数运算。
对A进行高斯消元,得到非稀疏校验向量v,则至少需要n个满足校验关系的码字,即能够通过高斯消元求解得到v的概率为P1=Pn。
由此可知,对于传统算法而言,在信道误码率一定时,能够获取到校验向量的概率随码长n和校验向量码重w的增大而呈指数级下降。在实际工程中,LDPC 的码长通常很大,对应于非稀疏校验向量的码重也非常大,故误码率一旦增大,能够通过高斯消元求解校验向量的概率将非常小,同时高斯消元算法的计算复杂度近似为O(n3),由此可知,对于码长较长的LDPC 而言,计算复杂度较大。
对于非稀疏校验向量的稀疏化,传统方法采用2 阶和P阶行变换方式,对于非双对角线形式的稀疏校验矩阵,P的选取具有一定的盲目性,故计算量比较大,这导致其算法的实时性较差。
从上述分析来看,在有误码条件下,传统的重建算法与工程实用化还有一定的差距。基于此,本文提出了一种新的思路,利用LDPC 校验矩阵非常稀疏这一特点,通过多次随机抽取码字中部分比特进行高斯消元,当抽取的比特包含稀疏校验向量中校验位时,经过消元后可直接得到涵盖稀疏校验向量的对偶空间,由于抽取的是码字中部分比特,故该对偶空间维度会很小,通过遍历对偶空间中向量,可以很快提取到稀疏校验向量。由于参与消元的仅为码字的部分比特,故与传统方法相比,计算复杂度以及容错性能均会有明显改善,同时在一定程度上避免了稀疏化步骤。
4 LDPC 稀疏矩阵重建模型建立
4.1 随机抽取次数的确定
从传统识别算法来看,为了获取校验向量,算法将整个LDPC 的码字进行列消元,但是从LDPC稀疏校验矩阵特点来看,构成LDPC 码字校验关系的比特长度实际上很短,在求解稀疏校验向量过程中,没有必要将整个LDPC 码字进行消元,如果抽取码字中部分比特进行列消元,当抽取到的比特中涵盖了稀疏校验向量的校验位时,消元的结果构成的对偶空间一定含有稀疏校验向量,同时对偶空间的维度较小,很容易找到稀疏校验向量。由于一次随机抽取并不能保证涵盖一个稀疏校验向量中完整的校验位,故需要多次抽取,为了确定抽取次数,实现可靠涵盖到整个完整的校验位,需要分析一次随机抽取的比特位置能够包含完整校验位的概率。不妨设LDPC 稀疏校验矩阵中,某一稀疏校验向量为v′,对应于校验节点数目为w′,码字中随机抽取的比特数目为s,则对于码长为n的LDPC,抽取出s个位置的样本空间数目为,而这s个位置中正好包含w′的校验节点的个数为,故得到一次随机抽取可包含v′中稀疏校验节点的概率为
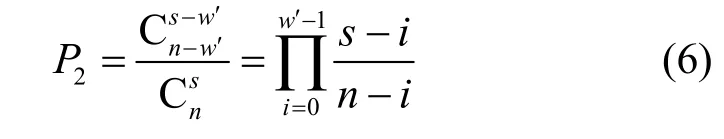
由式(6)可知,当LDPC 码长固定后,概率P2与s和稀疏校验向量的码重有关,s越大,校验向量越稀疏,则P2的值就越大。通常情况下,LDPC 重稀疏校验向量码重很小,一般不超过10;对于s而言,虽然取值越大,得到校验向量的可能性就越大,但是获取到的对偶空间的维度也会增大,这不利于稀疏向量的求取,极端情况下,s=n,算法退化为传统算法,故s的取值不宜过大。为兼顾P2与对偶空间维度,一般参考LDPC 码率来选择,设LDPC 码率为R,则每次随机抽取的比特数目可为Rn。
确定概率P2后,下面进一步探讨如何确定随机抽取的次数,从而可靠实现在抽取的比特中包含校验节点。不妨设随机抽取的次数为iter,则在iter 次的随机抽取中,能够出现包含稀疏校验节点的次数T服从二项式分布,即

当抽取的次数iter 较大时,由棣莫弗-拉普拉斯定理可得
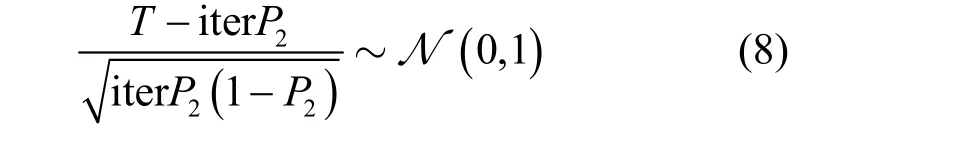
其中,N(0,1)表示标准正态分布。
在数理统计过程中,当事件发生的概率大于0.997 5 时,可将该事件定义为大概率事件,即在随机抽取iter 次过程中,至少发生一次,则iter 必须满足式(9)。
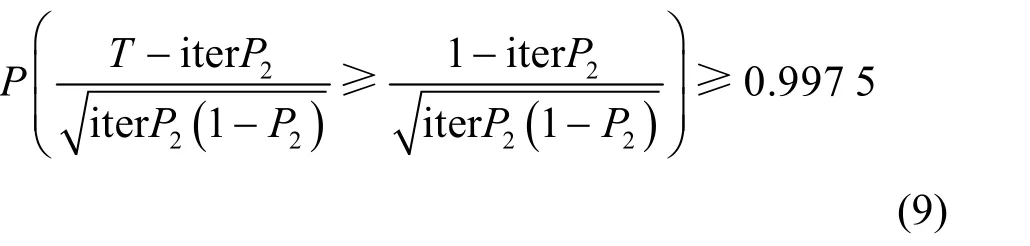
通过查询正态分布表可知
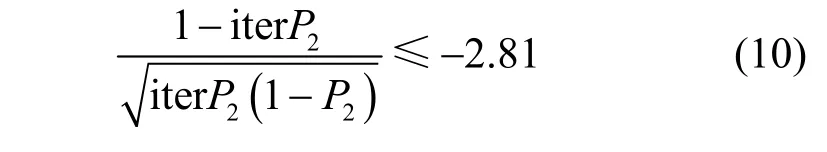
求解式(10),得到iter 的取值范围为

从而得到可靠包含稀疏校验节点的最小随机抽取次数为
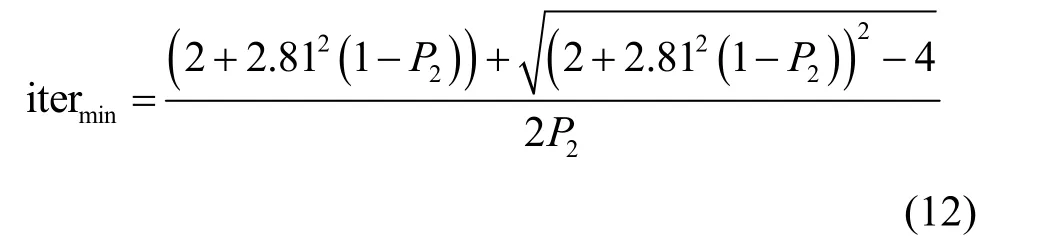
4.2 疑似校验向量判定
随机抽取码字中部分比特序列构成新的码字矩阵,通过高斯消元法得到的解向量仅能满足前s个码字,这类解向量被定义为疑似校验向量,此时需要综合考虑在疑似校验向量下整个码字成立的情况,所以需要利用真实校验向量与非校验向量下,码字校验关系成立的统计特性进行判定。不妨设得到的疑似校验向量为h,对应的码重为wh。首先,考虑以下2 类假设条件:H0表示h不是校验向量,H1表示h是校验向量。
在信道误码率为pe、假设条件为1H下,由式(5)可知,校验关系仍然成立的概率为
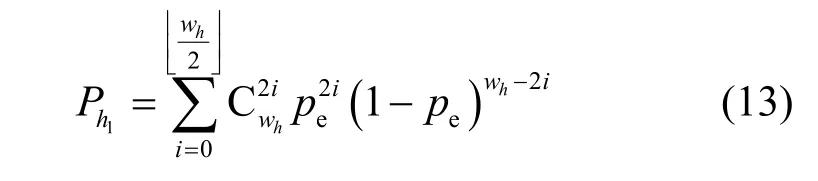
对于假设条件H0,由于h不是校验向量,因此码字校验关系成立概率随机,即Ph0=0.5。将码字成立个数与不成立个数之差t作为统计量,当码字个数N充分大时,在假设条件H1下,t服从均值为N(2Ph1-1)、方差为4N Ph1(1-Ph1)的正态分布,即
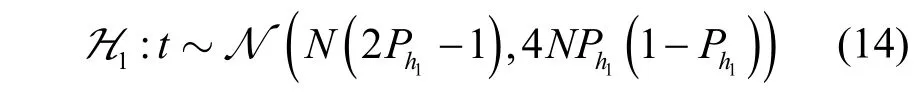
在假设条件0H下,t服从均值为0、方差为N的正态分布,即
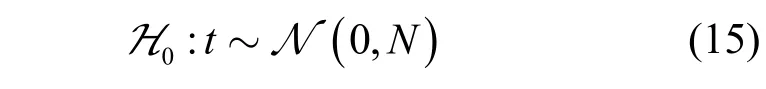
为方便描述,不妨记μ0=0,=N,μ1=N(2Ph1-1),=4N Ph1(1-Ph1)。设2 类假设的判决门限为Λ,则虚警概率Pf为
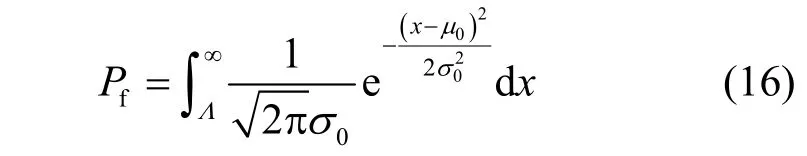
漏警概率Pa为
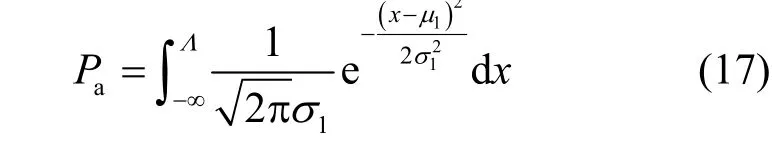
综合2 类错误判决概率,得到平均错误判决概率为
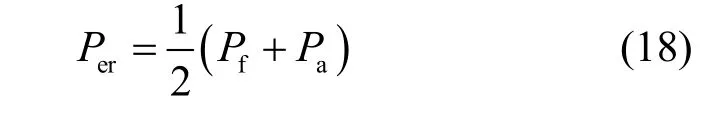
利用Per对Λ求导数,并令其等于0,得到
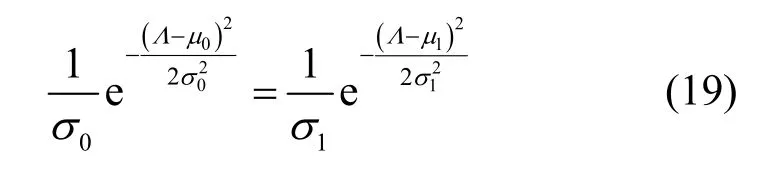
对式(19)两边取对数,将其化为一元二次方程,求解得到最小错误判决门限Λopt为
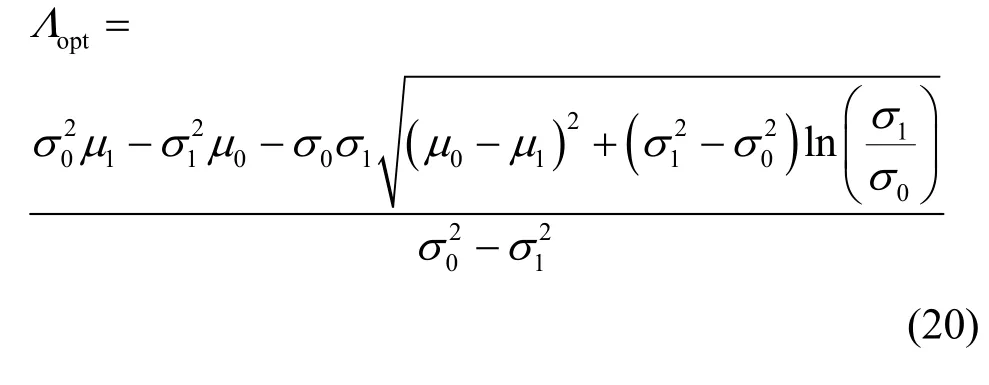
当N足够大时,Λopt可近似为

通过高斯消元得到疑似校验向量后,求取对应的统计量t,然后计算最小错误判决门限Λopt,当t≥Λopt时,即可判定为校验向量。需要注意的是,由于每次高斯消元仅利用了前s个码字,为了增大疑似校验向量获取的概率,充分利用截获的码字,可以采用多次迭代随机选择s个码字进行消元,直到出现疑似校验向量。
4.3 LDPC 稀疏校验矩阵重建算法步骤
所提算法充分利用了LDPC 校验矩阵非常稀疏这一特点,即对于任一稀疏校验向量而言,码字中实际参与校验的比特位是非常小的,当随机抽取的比特位置中正好涵盖了校验节点时,通过高斯消元可得到包含稀疏校验向量的对偶空间,且对偶空间的维度较小,通过遍历的方式,可以快速获取稀疏向量,具体的算法步骤如下。
步骤1初始化参数s,迭代消元次数iter1,i1=1,i2=1,用截获的数据构造LDPC 码字矩阵AN×n,其中N为码字数目,n为LDPC 码长。
步骤2计算随机抽取次数itermin,从而保证可靠出现涵盖稀疏校验向量节点位置。
步骤3随机抽取AN×n中s列数据,构造新的码字矩阵CN×s,同时i1=i1+1。
步骤4随机选取CN×s中s行数据构成方阵Bs×s,同时采用高斯消元法得到Bs×s的对偶空间基向量。
步骤5若对偶空间为非零空间,则利用对偶空间基遍历整个解空间,寻找稀疏校验向量;否则i2=i2+1,重复步骤4,直到i2>iter1。
步骤6计算稀疏向量对应的统计量t以及最小错误判决门限Λopt,若t≥Λopt,则保存该稀疏校验向量于集合H中,同时重复步骤3,i2置1;否则i2=i2+1,重复步骤4,直到i2>iter1。
步骤7判断i1>itermin是否成立,若成立,则输出稀疏校验矩阵H;否则转至步骤3,直到i1>itermin。
在步骤5 中,由于随机抽取了实际码字中部分比特进行高斯消元,故其对偶空间维度远小于实际LDPC 对偶空间维度,通过遍历解空间中向量,能很容易地求解对偶空间中稀疏向量。
在实际仿真中,算法对每次得到的校验向量都要进行筛选和判定,当向量的码重与码长之比小于0.03 时,将其判定为稀疏校验向量,保存的校验向量不仅要满足稀疏条件,同时还必须满足与已保存的稀疏向量相互线性不相关的条件,故稀疏校验向量的个数等于重建矩阵的秩。在后续算法性能验证过程中,本文将重建的稀疏向量个数与定义的稀疏矩阵秩之比定义为重建率,在不同误码条件下,利用重建率这一指标来表征算法的性能。由于LDPC 译码依赖于稀疏校验矩阵,故在信道较恶劣的条件下,利用本文重建的部分稀疏校验矩阵可以对LDPC 进行迭代译码,从而改善截获的码字质量,进一步提升算法的性能。
4.4 计算复杂度分析
设随机抽取的列数为s,随机抽取的次数为itermin,构造方阵Bs×s并进行高斯消元的最大次数为iter1;由于进行一次高斯消元的计算复杂度为O(s3),则在最不利条件下,本文算法的最大计算量为O(iterminiter1s3)。由于本文算法仅抽取码字中部分比特进行消元,故得到的对偶空间维度较小,可以很容易地找到稀疏校验向量,而且在绝大多数情况下,能直接得到稀疏校验向量。对于传统算法而言,针对码率为k/n的LDPC,需要将整个码字进行高斯消元,其最大计算量为O(iter1n3),由于得到的是非稀疏校验向量,故还需要进行稀疏化处理,在稀疏化处理过程中,采用P阶行变化处理,其计算复杂度为,故传统算法[14-15]总的计算复杂度为,对于非双对角线形式的LDPC,P的取值一般会比较大,此时传统算法的复杂度会急剧增加,由此可知,本文算法的通用性要优于传统方法。
5 仿真验证
本节首先验证本文算法的有效性,即能够在有误码条件下,完成双对角以及非双对角线形式的稀疏校验矩阵重建;其次考察在不同迭代消元次数、不同截获码字个数、不同码长以及码率条件下,算法的重建性能;最后将本文算法与传统的LDPC 重建方法[14-15]进行对比。
5.1 算法有效性验证
5.1.1 双对角线稀疏校验矩阵重建
本节设定LDPC 的稀疏校验矩阵为协议IEEE 802.11n 中定义的LDPC(648,324),其稀疏校验矩阵具有明显的双对角线,如图1(a)所示。设截获的码字个数为5 000 个,误码率为0.001 5,高斯消元迭代次数为20 次,本文算法重建结果如图1(b)所示。由于重建稀疏矩阵行顺序是随机的,为了方便与图1(a)对比,将图1(b)的行顺序参照图1(a)的行顺序重新排列,得到结果图1(c)。为了与本文算法进行对比,在同等条件下,传统算法也对该稀疏校验矩阵进行了重建,图1(d)为传统算法重建的非稀疏校验矩阵,而图1(e)为稀疏化后的结果。
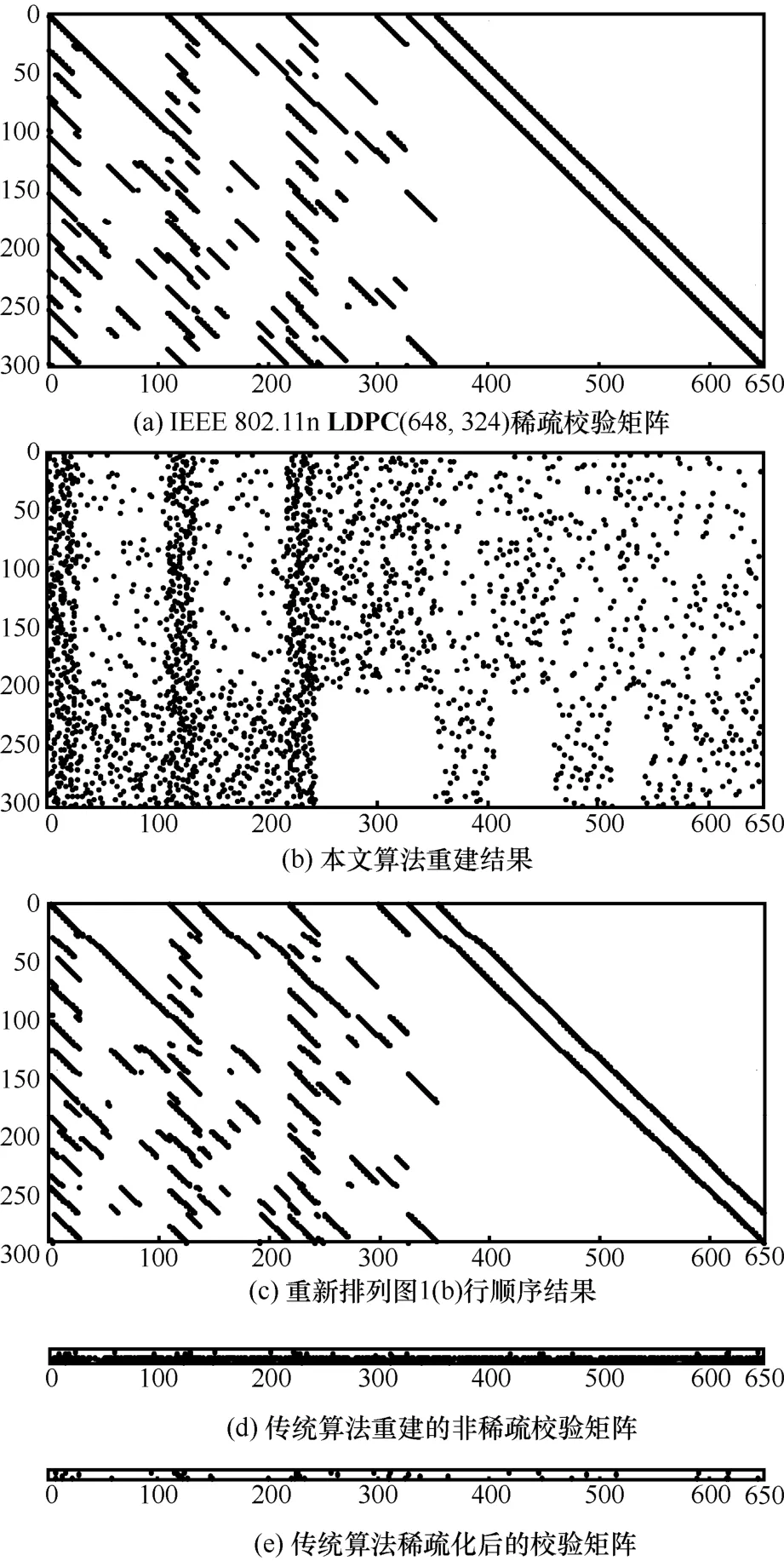
图1 2 种算法针对双对角线稀疏校验矩阵的重建过程
从图1 可以看出,当误码率为0.001 5 时,本文算法直接重建出306 个稀疏校验向量,即重建率达到94.44%。与原始稀疏校验矩阵对比发现,重建的稀疏校验向量与原始稀疏校验矩阵中向量完全一致(重新排列得到的图1(c)与图1(a)是一致的),这说明本文算法能够很好地重建稀疏矩阵;相反,传统重建算法在误码率为0.001 5 时,仅得到8 个非稀疏的校验向量,经过稀疏化处理后,得到6 个稀疏校验向量,重建率仅为1.85%,这说明传统算法对误码的稳健性较差。
5.1.2 非双对角线稀疏校验矩阵重建
本节设LDPC 为QC-LDPC(600,300),该稀疏校验矩阵不再具有双对角线形式,如图2(a)所示,生成的LDPC 码字个数为5 000,信道误码率为0.001,高斯迭代消元次数为20。本文算法重建结果如图2(b)所示,为了方便与原始稀疏校验矩阵对比,同样将图2(b)的行顺序参照图2(a)的行顺序进行重排列,得到图2(c)结果。在同等条件下,利用传统重建方法首先得到如图2(d)所示的非稀疏校验矩阵,然后稀疏化处理得到如图2(e)的结果。
从图2 可以看出,本文算法有效恢复出了295 个稀疏校验向量,虽然实际的稀疏校验向量个数为300 个,但由于该稀疏校验矩阵是非满秩矩阵,其秩为295,故本文算法重建的LDPC 稀疏校验矩阵和原始矩阵等效;同时由图2(c)可知,本文重建的稀疏校验向量和原始的稀疏校验向量是完全一致的,这进一步说明本文算法能够较好地重建出稀疏矩阵。虽然传统的重建方法能够得到295 个非稀疏的校验向量,但是通过多次行消元稀疏,得到的结果仍然不够稀疏,同时存在大量4 环(稀疏矩阵的设计应避免出现4 环),这说明传统算法针对非双对角形式的稀疏校验矩阵重建效果不佳。
5.2 算法容错性验证
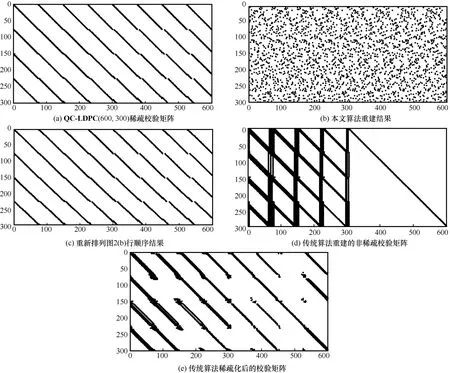
图2 2 种算法针对非双对角线形式的LDPC 重建过程
本节主要考察消元迭代次数、截获码字个数、码长以及码率几个因素对算法性能的影响,记录在某一因素、不同误码率下的重建率。
5.2.1 迭代次数的影响
仿真设定LDPC 稀疏校验矩阵为协议IEEE 802.11e 中定义的LDPC(576,288),设截获的码字个数为1 500 个,在高斯消元过程中,迭代次数分别设定1 次、5 次、10 次、15 次、20 次;设定误码率范围为0~0.005,取值间隔为0.000 25,统计在不同迭代次数以及不同误码率下,LDPC 稀疏校验矩阵重建率,结果如图3 所示。
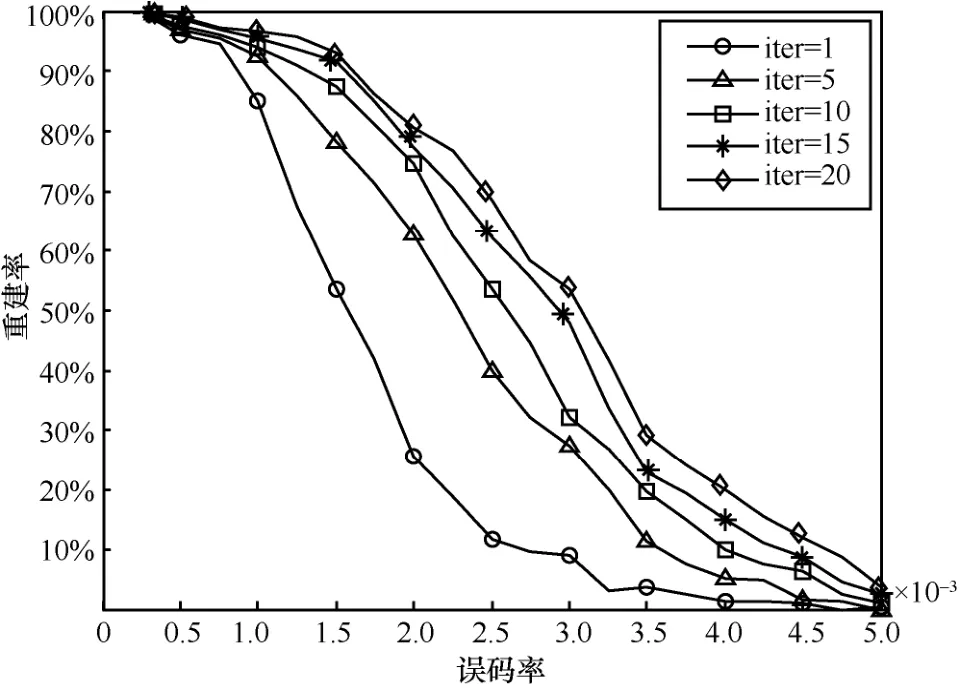
图3 不同迭代次数对算法的影响
从图3 可以看出,增加迭代次数可以有效提高LDPC 稀疏校验矩阵的重建率。主要原因在于,在高斯消元过程中,迭代次数一旦增加,满足同一校验关系的码字被抽到的概率就会增加,此时重建出的稀疏校验向量也会相应增多。此外,本文提出的重建算法具有较好的容错性,在误码率为0.001 的条件下,稀疏校验矩阵重建率能达到95%以上。
5.2.2 截获码字数目影响
同样设定LDPC 稀疏校验矩阵为协议IEEE 802.11e 中的LDPC(576,288),设信道误码率为0.000 5、0.001、0.001 5、0.002、0.002 5,高斯消元迭代次数为20 次,截获的LDPC 码字个数范围为500~2 000,取值为间隔100,统计5 种信道误码率情况下,不同截获码字个数对应的稀疏矩阵重建率,结果如图4 所示。
从图4 可以看出,增加码字个数能够有效增大稀疏校验矩阵的重建率,原因在于,当码字个数增多时,满足同一校验关系的码字会随之增加,所以在迭代消元过程中,随机抽取到这一类码字的可能性就会增大;当码字增加后,计算的判决门限会更加准确,对疑似校验向量的误判就会减少。
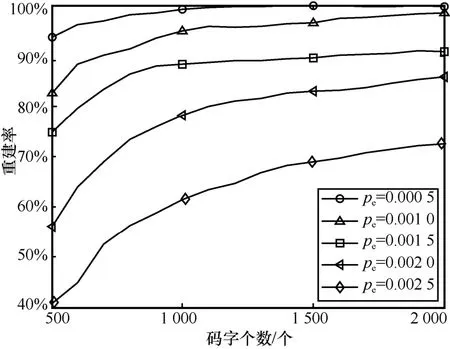
图4 不同码字个数对算法的影响
5.2.3 码长和码率的影响
仿真设定LDPC 码率为1/2 和2/3,每种码率对应的码长为576、648 以及768,选取的稀疏校验矩阵都为IEEE 802.11 协议中定义的校验矩阵,设截获的码字个数为2 000,误码率范围为0~0.004,取值间隔为0.000 25,高斯消元迭代次数为20 次,统计在不同LDPC 编码类型下,不同误码率对应的稀疏校验矩阵重建率,结果如图5 所示。
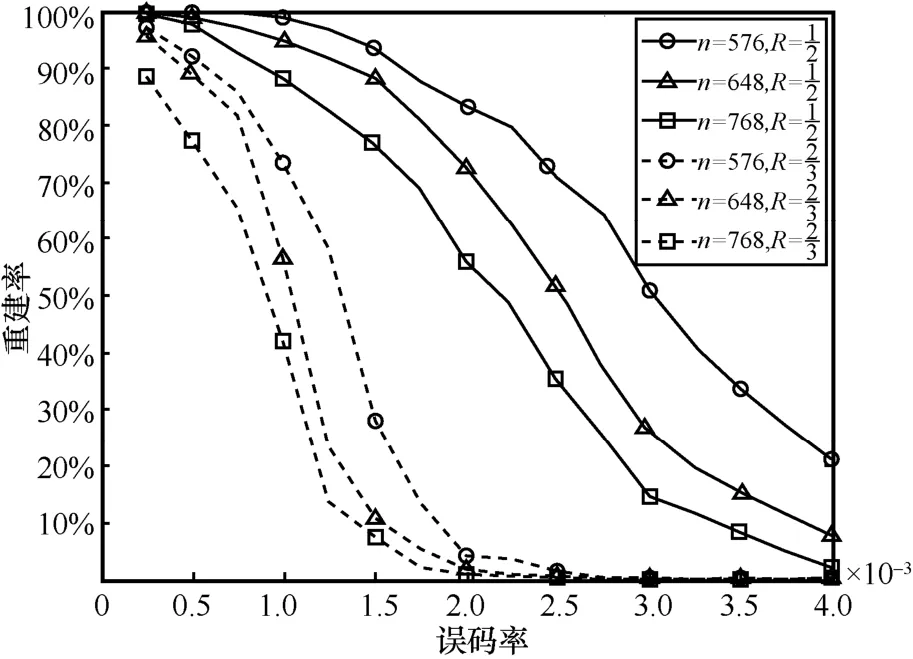
图5 不同码长和码率对算法影响
从图5 结果来看,在同一码长条件下,算法重建率随码率的增加而降低;在同一码率条件下,重建率随码长的增加而下降。主要原因在于,首先,当码长增加时,抽取参与消元的比特相应增加,此时误码会随比特消元过程而扩散,参与消元的比特越多,扩散情况越严重;其次,当码率增加时,稀疏校验矩阵中向量码重增加,此时能够抽取到包含校验节点的数据比特的概率会降低,同时码重增加后,疑似校验向量的误判概率也会增加,这2 个因素综合起来会导致算法性能降低。
5.3 与传统算法比较
本文算法与传统算法比较时,选取IEEE 802.11协议中LDPC(576,288)(码率为1/2)、LDPC(648,324)(码率为1/2)以及LDPC(648,432)(码率为2/3)。设截获的码字个数为2 000,信道误码率范围为0~0.005,取值间隔为0.000 25,统计不同误码率下2 种算法的重建率,结果如图6 所示。
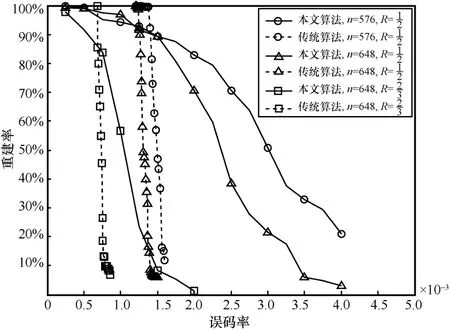
图6 本文算法与传统算法重建率对比
从图6 可以看出,本文算法重建率明显优于传统算法。主要原因在于,首先,本文算法通过随机抽取码字中部分比特进行消元,实际参与消元的比特数目远小于码字长度,所以本文算法对于信道噪声具有更强的稳健性;其次,传统算法的重建性能较差,信道误码率稍有增加,算法重建率就急剧下降。由此可见,本文算法在高误码率下具有更好的工程实用性。
6 结束语
本文基于LDPC 稀疏校验矩阵的特征,提出了可直接重建稀疏校验矩阵的算法。算法首先通过多次随机抽取码字中部分比特序列进行高斯消元,当抽取的比特序列包含稀疏校验节点时,从消元的结果中可直接获取LDPC 稀疏校验向量;其次分析了在有误码条件下,码字校验关系成立的统计特性,基于最小错误判决准则,完成疑似校验向量的判定,最终完成LDPC 稀疏校验矩阵的重建。与传统重建算法相比,本文算法不再需要单独进行稀疏化步骤,不仅具有较好的容错性能,而且对于双对角线与非双对角线形式的稀疏校验矩阵都具有很好的通用性。
