数据网格中一种高性能动态数据复制策略
2021-04-08黄守明
黄守明
(铜陵学院 数学与计算机学院,安徽 铜陵 244061)
当今,许多大型科学系统、商业应用、图像处理和数据挖掘等要处理TB甚至PB级的海量数据,需要超大的计算能力、网络带宽和存储容量。把大量的存储单元和计算资源(如CPU、内存和硬盘)集成起来生成一个网格,可以提供共享访问计算和存储资源[1-3]。数据网格是一种新型网格,提供了方便发现、调用和海量数据处理的服务及基础设施,以及对这些数据集副本的创建和管理[4-6]。
在几乎所有的数据复制(也称为副本创建)算法中,涉及3个关键问题需要解决。
(1)副本选择:在遍布整个网格的副本中挑选副本的过程。
(2)副本放置:选择一个网格站点来放置副本的过程。
(3)副本管理:在数据网格中创建或删除副本的过程。
通常,复制算法是静态的或动态的。传统的静态复制算法的缺点是不能适应用户行为的变化,而且不适合大量的数据和用户。静态复制算法也有一些优点,如没有动态算法的开销,而且作业调度很快完成[7];另一方面,动态复制策略创建和删除副本是根据网格环境的变化,即用户的文件访问模式[8]。由于数据网格是动态环境,而且用户的要求也是可变的,因此动态复制才更适合这些系统[9]。
文献[10]提出了6种不同的副本创建策略:无副本、最好的客户、级联复制、普通缓存、缓存加级联复制和多层数据网格的快速传播,还介绍了3类局部性,即时间局部性、地理局部性和空间局部性。对这些策略的评价采用了不同的数据模式,文献[11]对最新访问最大权值(Latest Access Largest Weight,LALW)策略[12]进行了扩展。LALW算法给予最近被访问的文件更高的权值,而且副本放置仅在集群级而不是站点级进行;文献[13]提出了一种基于分类的复制策略(Replication Strategy based on Categorization,RSC),通过使网络级局部性最大化并避免网络拥塞来减少数据访问时间。但策略有2个不足:一是复制的文件被放在全部请求的站点而不是合适的站点;二是只有当存储单元的容量小时,该策略才具有良好的性能。文献[14]提出了一种动态层次复制(Dynamic Hierarchical Replication,DHR)策略,把副本存放在合适的站点,而不是许多站点,但它仍存在不足,如副本选择和副本替换并不高效。文献[15]提出的改进动态层次复制算法(Modified Dynamic Hierarchical Replication Algorithm,MDHRA)对DHR策略进行了改进,还提出了一种新的作业调度算法—联合调度策略(Combined Scheduling Strategy,CSS),采用分层调度来减少对于合适计算节点的搜索时间。文献[16]针对多层数据网格提出了一种新的动态复制策略—预测分层快速传播(Predictive Hierarchical Fast Spread,PHFS),它是快速传播动态复制方法的扩展形式。PHFS不仅在多层数据网格结构的不同层中按层次复制数据对象来得到更多的访问位置,而且也使得存储资源的利用最优化。
总之,这些传统的动态数据复制策略除了具备灵活性和更加适应动态变化的数据网格环境的优点外,还存在副本选择数量过大和副本放置站点过多等缺点,从而最终导致数据复制的作业时间延长,网络开销变大,严重时甚至导致文件的大量丢失等。
对此,本文提出了一种新的动态数据复制策略,提出的动态数据复制策略主要在副本选择、副本放置和副本管理3方面进行了改进和提高。首先为了选择最佳副本,采用了一个考虑影响数据传输时间的链路带宽和影响数据传输性能的CPU及I/O的评分函数;其次计算出具有最小访问时间的存储单元(Storage Element,SE),将副本放置在最佳的存储单元(Best Storage Element,BSE)中;最后采用一个基于将来文件的访问次数n(它基于指数增长/衰减模型得到)、特定副本的大小S、当前时间CT、特定副本的最后请求时间LT和数据的可用性A计算得到的CM值作为副本替换阶段对BSE中的可用副本进行删除判决。仿真结果表明,本文提出的动态数据复制策略相比于其他算法,在平均总作业执行时间、有效网络利用和系统文件丢失率方面都有明显的改进。
1 本文提出的动态复制策略
本文提出的动态复制策略由3部分构成。
1.1 副本选择
当不同的站点存有数据集的副本时,通过选择最佳副本可以有效利用链路的带宽并减少延迟,从而直接影响数据传输时间,同时,CPU和I/O对数据传输性能也有影响。因此,提出评分函数如下:
Score=PBW×w1+PCPU×w2+PI/O×w3
(1)
式中PBW表示从选择的站点到请求文件驻留站点的可用带宽百分比,PCPU为请求文件驻留站点的CPU空闲状态的百分比,PI/O为请求文件驻留站点的可用存储空间的百分比,wi(i=1,2,3)为权值,且:
w1+w2+w3=1
(2)
这些权值可以由数据网格机构的管理员根据数据网格节点中存储系统的不同属性来设置。因此,如果几个站点有副本f,则选择一个有最大Score值的站点。
1.2 副本放置
为了提高系统的可靠性和性能,每个文件在网格中可以有一些副本,每个副本必须保存在不同的存储单元中。
如果所请求的文件存在于存储单元中,则不需要复制和拷贝它;如果所请求的文件不存在于存储单元中,则将进行复制。本文提出将副本放置在最佳的存储单元(Best Storage Element,BSE)中。因此,为了找到BSE,算法必须计算出具有最小访问时间Tmin的SE,即SETmin。在SETmin的Tmin计算中,必须考虑副本的请求频率和最后请求副本的时间,这2个参数很重要,因为它们表明了再次请求副本的概率。
(3)
式中CT是当前时间,LTi是副本i的最后请求时间,FRi是副本i的请求频率,图1所示详细描述了寻找最佳存储单元这一实现过程。

图1 寻找BSE的过程
1.3 副本管理
如果没有足够的复制空间,则1个或多个文件必须作为替换阶段的候选文件,采用下列计算公式确定替换:
(4)
式中n是将来文件的访问次数,它基于指数增长/衰减,S是特定副本的大小,CT是当前时间,LT是特定副本的最后请求时间,A是数据的可用性(Availability,A)。对BSE中的可用副本基于CM值的升序进行排序作为删除。
下面对式(4)中的2个重要参数的确定进行分析。
(1)可用性(A):每个存储单元都有数据可用性,它表明了一个文件存在的概率。假设存储单元中保存的全部文件有相同的可用性,存储单元j中的文件可用性用ASEj来表示。由于可能存在一个文件的多个副本,因此每个文件fi的可用性用Ai表示,计算如下:

(5)
式中N为文件fi的副本数量。显然,对于访问一个文件的每次操作来说,不可用性的概率为1-Ai,假设文件的访问操作是各自单独完成的。
(2)将来文件的访问次数(n):我们采用指数增长/衰减的概念来预测文件的下一个访问次数。现实世界的许多现象如细菌繁殖、放射性同位素衰减和信用支付等都可以采用这个概念来建模,这种模型也适用于数据网格访问。设n0是时刻t文件f的访问次数,则时刻t+1该文件的访问次数是n(t),其指数增长/衰减模型为:
n(t)=n0×e-rt
(6)

因此,根据指数增长/衰减模型,可得到:
(7)
式中α为增长/衰减率,求解式(7)有:
(8)
全部时间间隔的平均增长/衰减率为:
(9)
于是,可以得到下一个时间间隔的访问数为:
(10)
例如,我们可以用指数模型找到文件f的下一个访问数。如23、20、12、10分别为文件f在4个时间间隔的访问数,则首先要计算出文件f的平均增长/衰减率:
(11)
最后,估计出文件f的下一个访问数:

(12)
替换仅在保存新副本的可用性值大于删除现有文件的可用性值情况下进行。现在,复制文件fi的可用性值可通过下式得到:
(13)
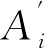
删除候选文件的可用性值将由下式得到:
(14)

这样,如果通过复制fi得到的可用性值大于从BSE中删除候选文件损失的累计值,则要求在BSE中复制所请求的文件fi,即:
(15)
式中Ni是文件fi的副本数量。实现替换策略的伪代码如下。
从BSE中的文件生成列表L且对于每个文件按式(4)计算CM值;
按CM值升序排序列表L;
Sum=0;
while(L不为空&&对于新副本没有足够的空间)
{
从列表L中选择文件fi;
Sum=Sum+ΔAi×Ni;
}
end while
if(ΔAF×NF>Sum)
{
删除BSE的L中的候选文件;
}
end if
if(对于BSE中F的新副本有足够的空间)
{
存储F的新副本;
}
end if
1.4 算法复杂度分析
从前面分析可知,本文算法实现主要由3个阶段构成,即副本选择、副本放置和副本管理。在副本选择阶段,如果副本数量为f,则选择一个有最大Score值的站点的复杂度为O(f);在副本放置阶段,为了将副本放置在最佳的存储单元,副本列表大小为L,副本i的请求频率为FRi,则完成该阶段的复杂度为O(LFRi);在副本管理阶段,复杂度主要由替换算法决定,要完成副本数量为f、列表大小为L的副本管理,其复杂度为O(nfL)-O(Nj),其中n为访问次数,Nj为候选文件数量;故本文算法总的实现复杂度为O(nfL)+O(LFRi)-O(Nj)。
2 算法仿真结果及分析
2.1 网格仿真单元及配置
我们采用OptorSim数据网格仿真器来仿真所提出的动态复制策略。OptorSim为用户提供了数据网格体系结构和编程接口,OptorSim中包括了许多组件,如计算单元(Computing Element,CE),存储单元(Storage Elements,SE)、资源代理(Resource Broker,RB),副本管理器(Replica Manager,RM)和副本优化器(Replica Optimizer,RO)。每个站点由0或多个CEs和0或多个SEs构成,图2所示为算法仿真所采用的OptorSim数据网格仿真器的体系结构示意图。
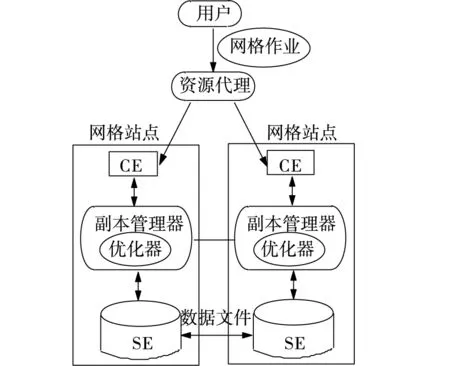
图2 OptorSim体系结构
一个作业通常会请求数据访问的一组逻辑文件名,被请求的文件顺序由访问模式规定。仿真中考虑3种不同的访问模式:顺序式,即文件按在作业配置文件中规定的顺序被访问;单一随机式,即文件请求与先前文件请求是一个单元,但方向是随机的;随机Zipf访问式,这里Pi=K/iS,Pi是第i项排名的频率,K是最被频繁访问的数据项的受欢迎程度,S决定分布的形状;数据复制策略通常假设数据在数据网格中是只读的;表1所示为仿真中设置的参数值。

表1 仿真参数值
3.2 仿真结果及分析
为了评价不同复制策略实施的有效性,采用以下性能指标。
(1)总作业执行时间,包括数据传输和作业执行时间,这是网格用户评价其算法执行的一个最重要的指标。
(2)有效网络利用(Effective Network Usage,ENU),用于估计网络资源的使用效率,计算公式如下:
(16)
式中Nrfa是CE从远程站点读取一个文件的访问次数,Nfa是文件复制操作的总次数,Nlfa是CE读取一个本地文件的次数,ENU的值在0~1之间,ENU值越低,表示网络带宽的利用越有效。
(3)系统文件丢失率(System File Missing Rate,SFMR),SFMR表示潜在的不可用文件数量与全部作业请求的文件数量之比,它用于测量数据的可用性,定义为:
(17)
式中n表示作业的总数量,mj表示每个作业的文件访问操作数,Ai为式(5)定义的文件fi的可用性概率。越小的SFMR值表现出越好的系统数据可用性。
图3所示为在3种不同访问模式时采用包括本文提出的动态复制策略在内共6种动态复制策略得到的平均总作业执行时间。
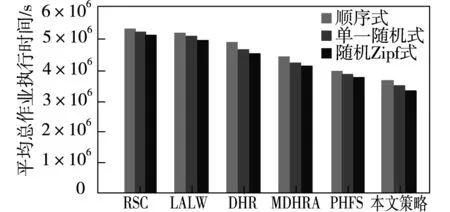
图3 3种访问模式时不同复制策略的平均总作业执行时间
从图3可以看出,RSC策略的平均总作业执行时间最大,是因为RSC策略将副本存储在有高带宽的站点,并复制那些在区域内可能会很快被访问的文件。由于在每个站点的SE的大小不足以存储全部数据的大部分,故采用站点级替换策略对性能没有太多的改进;LALW的平均总作业执行时间比RSC快大约9%,因为LALW选择一个受欢迎的文件作为复制,通过分配不同的权值给每个历史数据访问记录,对每个记录的重要性进行区分;DHR的平均总作业执行时间相比于采用顺序访问模式的RSC算法降低了12%,是由于它选择最佳副本位置作为执行作业,考虑存储中等待的请求数量和数据传输时间;MDHRA比RSC的平均总作业执行时间约快25%,比采用Zipf分布的DHR快11%;在全部算法和全部文件访问模式中,本文提出的策略有最小的平均总作业执行时间。
由于采用随机访问模式,一组特定的文件更容易被网格站点请求,请求文件的大部分在之前已被复制。因此,全部复制策略在随机文件访问模式(包括单一随机式和随机Zipf访问式)下相比于顺序访问模式的平均总作业执行时间要小。
图4所示为在随机Zipf访问模式时6种动态复制策略得到的有效网络利用。

图4 随机Zipf访问模式时不同复制策略的有效网络利用
从图4可见,PHFS的ENU相比于RSC约低37%,主要原因是对于PHFS,网格站点在需要时才会有他们需要的文件,因此副本总数将减少,而本地访问总数增加;本文提出的策略是最佳的,带宽消耗最小,从而也减少了网络流量。
图5所示为在3种访问模式时得到的6种方案的SFMR。

图5 3种访问模式时不同复制策略的SFMR
显然,从图5可见,对于全部访问模式来说,本文提出的策略的性能要优于其他的策略,这是因为本文提出的策略仅当来自于复制文件的增益值大于复制文件的损失值时才决定创建副本。
结语
数据复制策略已广泛应用于数据网格中复制被频繁访问的数据到合适的站点。本文提出了一种动态数据复制策略,选择最佳副本位置作为执行作业,还同时考虑了CPU和I/O等因素。算法还将副本存储到最佳站点,而不是很多站点,从而使得文件大部分时间可被访问,使得数据丢失率最小化和文件的可用性最大化,从而减少响应时间、访问延迟和带宽消耗,提高了系统的性能。
