基于知识图谱问答系统的技术实现
2021-04-06魏泽林张帅王建超
魏泽林 张帅 王建超


摘 要:知识图谱是实现对话机器人的一类重要工具。如何通过一套完整流程来构建基于知识图谱的问答系统是比较复杂的。因此,本文从构建基于知识图谱的问答系统的全流程角度总结了多个主题:知识图谱类型、知识图谱构建与存储、应用在知识图谱对话中的语言模型、图空间内的语义匹配及生成。进一步,本文在各主题的垂直领域归纳了常用方法及模型,并分析了各子模块的目的和必要性。最后,本文通过总结出的必要模块及流程,给出了一种基于知识图谱的问答系统的基线模型快速构建方法。该方法借助了各模块的前沿算法且有效地保证了拓展性、准确性和时效性。
关键词:知识图谱;问答系统;对话机器人;语言模型;语义匹配
Abstract: Knowledge graph is an important tool for realizing chatbots. The lifecycle of constructing a question answering system based on knowledge graph is a complex task. This paper summarizes a number of topics from the perspective of building a knowledge graph-based question answering system. The topics include knowledge graph types, knowledge graph construction and storage, language models used in knowledge graph dialogue, semantic matching and generation in graph space. Furthermore, this paper summarizes commonly used methods and models in vertical areas of topics, and analyzes the purpose and necessity of sub-modules. A method for quickly constructing a baseline model of a knowledge graph based question answering system will be presented. The proposed method relies on the cutting-edge algorithms and effectively guarantees scalability, accuracy and timeliness.
Keywords: knowledge graph; question answering system; chatbot; language model; semantic matching
1 引言(Introduction)
知识问答系统在二十世纪五六十年代时就已经出现。近年来对话系统不断发展,对话功能不断增多,对数据内容和数据结构也提出了更高的要求。在开放域问答对话中,由于涉及的数据量及不同领域间的特征差异较大,基于问答对匹配的检索式问答系统并不是最好的解决方法。而知识图谱的发展则正为这部分需求提供了解决方案。知识图谱作为大规模信息的载体,是实现对话机器人中大规模推理及问答的一类重要方法。知识图谱中的三元组数据能够为问答系统提供大量的事实数据以及实体间的复杂关系,因此,基于知识图谱的问答对话系统逐渐成为人们关注的重点。近年来,由于知识图谱以及自然语言处理的快速发展,新型的知识图谱、语言模型、图嵌入、图神经网络等大量技术被广泛应用于知识图谱问答系统的构建中,其中各类方法的目的、功能、效果不同。在整体过程中,如何构建知识图谱以及如何将知识图谱中的海量信息准确、高效地融入语言模型中是问答系统设计的要点。同时,知识图谱图结构的数据形式使得基于知识图谱的多跳问答、联想式对话、多轮对话也成为研究的热点。知识图谱问答系统整体框架如图1所示。
2 知识图谱的类型(Knowledge graph type)
2.1 知识图谱
知识图谱是对事实的一种结构化表示方法,由实体、关系和语义描述组成。知识图谱的数据结构以图形式存在,由实体(节点)和实体之间的关系(边)组成。本质上,它是一种表示实体间关系的语义网络,以诸如“实体-关系-实体”的三元组来表达,可以作为事实解释和推断的知识库。通常使用RDF(Resource Description Framework)模式来表达数据中的语义。
超图的概念源于图论,是图结构的一种补充和扩展。传统知识图谱的一大缺点是其“二元一阶谓词逻辑”的本质结构,较难处理超过两个实体的复杂关系,例如:“玛丽·居里和皮埃尔·居里共同获得了1903年的诺贝尔物理学奖”中,“玛丽·居里”和“皮埃尔·居里”作为两个实体在知识图谱里无法通过一个边指向“诺贝尔物理学奖”实体,这种连接超过两个实体的边称为超边。为处理此类多元组复杂关系,传统的知识图谱需要人为设计大量的规则,使其满足三元组的统一格式。由于此类复杂关系在客观世界的语义系统中是普遍存在的,当知识图谱的数据规模较大时,难以保证人工规则的有效性和完备性。超图的引入补充了这一空白,通过构建超边可以表示此类多对一或一对多的复杂关系。
2.2 事理图谱
事理图谱(Event Evolutionary Graph,EEG)中的事件用抽象、泛化、语义完备的谓词短语来表示,其中含有事件触发词,以及其他必需的成分来保持该事件的语义完备性。事理图谱也可以看作知识图谱的一种形式,其邊的含义为事件间的关联性。
2.3 认知图谱
认知图谱[1]在2019年被提出,可以将其理解为在构建知识图谱的过程中,保留较为原始的文本信息,能够为后续的自然语言理解和推理提供实体间关系抽象化的认知过程。由于知识图谱的格式固定,即便使用超图对知识图谱进行优化,还是无法解释客观世界的多种关系,而保留更多文本信息的认知图谱能够进一步加大图谱中存储的信息量。然而,实体关系的抽象度与信息熵相互制约,认知图谱在构建过程中对实体间关系的抽象程度较传统知识图谱低,所以在利用认知图谱构建问答系统的过程中,需要语义模型承担更大的理解与推理压力。
2.4 开源知识图谱
当前的大规模开源知识图谱通常是以百科知识数据为基础进行构建的。在实际使用中,常见的英文开源知识图谱包括Wikidata、Freebase、DBpedia及YAGO,它们包含大量的结构化与半结构化数据,并且具有较高的领域覆盖面。中文开源知识图谱包括CN-DBpedia、思知知识图谱等,其中CN-DBpedia是由复旦大学研发维护的大规模通用领域知识图谱;思知是一个中文开放项目,其中的知识图谱拥有超过1.4亿条RDF数据。
3 知识图谱构建与存储(Knowledge graph construction and storage)
3.1 命名实体识别
命名实体识别(Named Entity Recognition,NER)是在文本中查找和分类命名实体的过程。命名实体的内容较为广泛,在一般领域中包括组织、人物名称和位置名称等,在各垂直领域如医学领域中,包括基因、蛋白质、药物和疾病名称等。基于规则的NER传统方法包括:LaSIE-II、NetOwl、Facile、SAR、FASTUS和LTG。
机器学习方法一般分为非监督学习方法与监督学习方法,其中非监督学习方法通常指基于文本相似度的聚类算法。
由于深度学习的快速发展,通过深度学习进行NER的方法在一定程度上取代了传统方法。其方法一般分为三个部分,如图2所示。
(1)输入的分布式表示,一般包括预训练的词编码、词性标签等,可以分为针对词组编码、针对字符编码以及混合编码等方式,常用方法包括Word2vec、Glove。其中,Bi-LSTM-CNN[2]、BERT[3]模型是目前最常见、效果最好的方法。
(2)文本编码,通常使用CNN、RNN、Transformer等。
(3)标签解码,通常使用Softmax、CRF、RNN等。目前来看,在NER众多方法中,BiLSTM+CRF[4]是使用深度学习的NER中最常见的架构。
3.2 关系抽取
关系抽取(Relation Extraction,RE)的主要目的是从文本中识别实体并抽取实体之间的语义关系。
例如:爱因斯坦创立了相对论<爱因斯坦,创立,相对论>,从而将非结构化文本抽取成可以理解的结构化知识。早期实现这一过程的方法多为有监督学习,可以视为分类问题。为了降低标注数据的成本,远程监督(Distant Supervision)方法被提出,其主要基于以下假设:如果在知识库中两个实体存在某种关系,则包含该两个实体的非结构化句子均能表示出这种关系。Riedel等人在原方法的基础上增强了远程监督的假设[5]。随后斯坦福大学的团队通过引入多实例、多标签学习来缓解远程监督的噪音问题[6]。
从2013年开始,神经网络模型开始应用在关系抽取上。Zeng等人提出了基于卷积深度神经网络的关系分类模型[7]。之后的诸多研究都开始侧重神经网络方法,BRCNN模型[8]使用了双向递归卷积神经网络模型,是一个基于最短依赖路径(SDP)的深度学习关系分类模型,模型分为两个RCNN,一个前向(SDP为输入),一个后向(反向的SDP为输入)。Multi-Attention CNN[9]模型将Attention机制加入神经网络中,对反映实体关系更重要的词语给予更大的权重,辅以改进后的目标函数,从而提升关系提取的效果。BiLSTM+ATT模型[10]运用双向LSTM加Attention自动提取包含整个句子语义信息的关键词汇或者字符。ResCNN-9[11]模型探索了更深的CNN模型对远程监督模型的影响,并且设计了基于残差网络的深层CNN模型。实验结果表明,较深的CNN模型比传统方法中只使用一层卷积的简单CNN模型具有较大的提升。文献[12]的方法对少样本的情况做出了一定的优化。
常见的关系抽取方法如表1所示。
3.3 知识图谱优化
3.3.1 实体融合
实体融合还可以叫作实体消歧、实体对齐或实体链接,它的目的是将实体提到的内容链接到知识图中相应的实体。比如,“北大是中国非常好的大学之一”,这句话中的实体“北大”应该链接到图结构中的实体“北京大学”。图嵌入方法是解决这一问题最普遍的方法。图嵌入是指将图数据映射为低维向量,从而将图中的节点和边转化为可以计算的向量。通过对向量的相似度计算,可以计算出实体之间的相似度和边之间的相似度,从而将相似度高的实体进行融合。2013年提出的TransE模型是图嵌入模型中较为适用于知识图谱对话系统中的算法。之后陆续有研究者基于该方法提出了TransH、TransR和TransD等方法。近年来,应用于跨语言的实体对齐图嵌入算法,以及应用于多个知识图谱实体融合的算法[13]也被人们提出。
3.3.2 知识推理
知识推理是在已有的知识图谱数据基础上,进一步挖掘拓展知识库的过程。其常用方法一般分为基于逻辑的推理和基于圖算法的推理[14]。
3.4 知识图谱的存储
在知识图谱的存储方式上,图结构没有了库表字段的概念,而是以事实为单位进行存储,所以关系型数据库在存储知识图谱上有着一定的弊端。通常知识图谱用(实体1,关系,实体2)、(实体、属性,属性值)这样的三元组来表达事实,可选择图数据库作为存储介质,例如开源Neo4j、Twitter的FlockDB、sones的GraphDB。其中Neo4j是由Java实现的开源NoSQL图数据库,是图数据库中较为流行的高性能数据库。
4 基于自然语言的检索方法(Semantic model based on retrieval method)
基于自然语言算法的目的是将与用户对话时,用户说出的句子进行关键信息的提取,然后在知识图谱数据库中对问题进行检索。简单来说,是使用自然语言处理的方法对知识图谱中的信息进行检索。
4.1 文本语义匹配
文本语义匹配是通过文本之间的相似度进行计算的,是传统检索式问答系统中最重要的匹配环节,需要将问句与问题库中的问题转为向量来计算相似度。在知识图谱问答系统中,同样可以利用该方法检索出我们需要的答案。
与传统QA检索相区别的是,在知识图谱中检索通常首先需要对问句进行命名实体识别。该过程的一般方法与上文所提到的构建知识图谱中的方法是一致的,目的在于检索出问句中所包含的主语,从而在知识图谱中定位节点。其意义类似于大规模QA系统中的召回环节,召回一般是指大规模QA中为了加速问题回答,在语义匹配前进行粗检索的过程。
在基于知识图谱的问答系统中,在确定了知识图谱节点后,将节点与相应的边组成问题组后,即可以将问题转为QA系统中的检索问题。使用语义匹配做问句与问题组的匹配,在开放领域知识图谱中,这种基于语义匹配的问答检索方式是较为适用的方法。文本语义匹配的常见方法如图3所示。实现该过程的传统方法包括词编码和加权方法两个步骤,对于编码方式来说,传统One-hot编码无法精准地衡量文本中的语义相似度,很难解决同义词等隐含在文中的信息特征。随着Word2vec、Glove等模型的出现,基于词向量将单词或短语转化为特征向量后再进行计算的方法逐渐受到重视,这类方法能够捕捉词语之间的相似度。词编码后再通过TF-IDF等方法可以得到句编码。但这种基于词编码的方法通常忽略了词语顺序,还是存在一定的问题。于是直接对句子进行句编码的方式陆续被提出,如TextCNN、Doc2vec、Skip-Thought。其中基于LSTM的孪生网络模型InferSent以及基于此加入Attention机制的Universal Sentence Encoder是效果非常好的句向量生成模型。近两年来随着自然语言处理中的热点模型BERT被提出后,Reimers等人通过对模型使用孪生网络提出了Sentence-BERT[15]模型,极大优化了BERT模型处理语义匹配的速度。该方法成为近年来文本语义匹配任务中效果最为优秀的模型之一。针对该模型的优化方法也成为热点的研究模块。
这里我们注意到,由于预训练模型的流行,一些研究也在使用知识图谱进行预训练,而在知识图谱对话中,直接使用数据库的知识图谱进行预训练可以更好地适配基于知识图谱的问答系统。K-BERT[16]模型较早地提出了将知识图谱中的边关系引入预训练模型,其主要通过修改Transformer中的Attention机制,通过特殊的mask方法将知识图谱中的相关边考虑到编码过程中,进而增强预训练模型的效果。
4.2 意图识别
意图识别一般指对语句中的意图进行分类,在知识图谱问答系统中同样是在命名实体识别后对边进行检索的方法,它是通过文本分类来完成的。通常情况下,意图识别方法在垂直領域知识图谱构建的对话系统中有较好的效果,原因在于垂直领域知识图谱中边的类型有限,通过文本分类可以将问题的意图对应到知识图谱的边,从而对问题进行回答。例如在医药知识图谱中,边的类型为药品的适用症、药品的用量等固定的几种,这种情况下通过意图识别模型可以了解到用户希望问的是药的用量还是药品的适用症。在具体问答系统构建的过程中,在通过实体识别定位到问题的主体后,再使用意图识别定位到边,边指向的节点就是问题的答案。在一些情况下意图识别过程可以由文本语义匹配代替,也可以作为优化方法优化意图识别结果。意图识别现阶段通常由神经网络模型完成,例如较为经典的方法TextCNN使用CNN方法来进行句子分类[17]。文献[18]引入Attention机制对该方法进行了改进。现阶段效果较为优秀的算法有FastText、BERT、ERNIE。
4.3 语义优化方法
4.3.1 指代消解
指代消解在对话系统中是指当用户的问题中缺少实体或意图时,通过对话的上下文,对问题缺失的部分进行补充的过程,是构建多轮对话中较为常见的方法。传统方法通常使用分词、词性标注、实体识别、意图识别等对问句中缺失的实体、意图或使用代词替换的实体和意图进行识别,然后通过上下文信息中的内容进行指代消解,或通过多轮问答进行补充。2017年Kenton等人提出的端到端的指代消解模型[19]很好地解决了指代消解这一问题,但该方法是针对长文本提出的方法,而在知识图谱问答机制中,通常文本长度较短,所以需要通过存储之前的对话进行指代消解,或者对模糊部分再次询问后应用。
4.3.2 长难句压缩
长难句压缩可以理解为文本摘要或句子压缩,目的是将句子中无意义的口水词成分或语义倒装等进行信息提取,去除用户句子中的噪声。知识图谱问答系统中,该模块可以作为优化输入信息的方法被引入。主流方法有两种,一种是抽取式,如TextRank;另一种用神经网络做生成式摘要,而后使用RNN、CNN单元处理,再引入Attention、Self-Attention等机制[20],使得生成摘要这一领域的效果提升得非常优秀。
4.4 检索优化方法
当知识图谱中包含的实体以及边的数量较大时,在实际检索中优化检索速度是影响最终效果的重要环节。Elasticsearch、MatchPyramid、MatchZoo等框架都是能够优化文本匹配的方法,其中Elasticsearch是目前比较流行的全文检索框架,它使用倒排索引算法,能够极大地提高文本检索效率。虽然Neo4j数据库中自带了全文检索功能,但在实际使用中,Elasticsearch+Neo4j联合的方式是更流行的方法,并可以在实际应用中覆盖大多数场景。在实际测试中,3,000 万左右的实体数量能够在200 ms内实现全文检索。
5 基于图空间的检索方法(Graph model based on retrieval method)
利用图嵌入算法能够将语义图谱、领域知识图谱及常识知识图谱中的实体和关系映射至不同的图空间中,进一步补充语义空间中难以表征的自然语言信息。在此基础上,基于图空间的检索方法在一定程度上结合图空间和语义空间的优势,通过图模型分担语义模型在自然语言处理上的压力,充当对话系统的知识库,为模型提供海量的结构化信息。除此之外,目前效果较好的BERT和GPT等预训练模型均为端到端设计,通过大量的模型结构参数来隐式存储客观世界的结构化知识信息,难以通过一种显式方法将人类能够理解的结构化知识引入模型当中,而知识图谱为人类能够理解的显式结构知识和黑盒模型的隐式训练过程提供了互通的桥梁。
5.1 图嵌入方法
图嵌入(Graph Embedding,也叫Network Embedding)是一种将图数据(通常为高维稀疏稠密的矩阵)映射为低维稠密向量的过程,也就是将图结构转化为可以计算的向量。对话系统中常用的Trans系列的图嵌入方法总体是将三元组的头实体-关系-尾实体(如:中国-首都-北京),转换为向量(h-r-t),使得t=f(h,r)。
5.1.1 基于平移变换的图嵌入方法
基于平移变换的图嵌入方法如表2所示。
5.1.2 基于神经网络的图嵌入方法
图卷积神经网络是通过针对图结构特殊设计的卷积核来实现的,可以理解成通过Laplacian算子来实现图中节点间的特征能量传递,进而获得节点的Embedding。
相比于传统图算法和基于随机游走的图嵌入方法,图卷积神经网络能够同时考虑图结构信息和节点特征信息。将节点特征信息设置为节点的语义信息时,图卷积神经网络能够实现图结构信息与语义信息的有效结合。
基于神经网络的图嵌入方法如表3所示。
5.2 语义空间与图空间的映射
KEQA[29]是较早提出通过图空间检索来代替实体和关系检索的框架,将实体与边通过图嵌入转换为图空间向量,再通过BiLSTM+Attention的网络模型,将语义向量与头实体和边关系进行映射,从而使语义检索通过图空间的计算来完成,达到了较好的效果,如图4所示。
基于图算法的检索方法,目的是将整体模型全部或部分放在图中计算,通过新型的知识感知对话生成模型(TransDG)进行问句的句向量生成以及知识匹配。
5.3 自然语言生成
通常自然语言生成涵盖了许多内容,包括摘要生成、简化、翻译、更正等,在这一部分里我们的自然语言生成特指通过数据生成文本的过程。在基于知识图谱的问答系统的实现中,自然语言生成作为流程的最后一环,其本质是将知识图谱的子图转化为自然语言。
CCM[30]提出了一种基于图注意力机制的常识域对话生成方法,如图5所示。在自然语言生成模块,通过将语义空间的词向量与基于图注意力机制得到的知识表示向量进行拼接,并作为Embedding输入GRU构造的解码器中,以实现知识信息融入对话生成的目的。
6 知识图谱问答系统快速构建实例(Implement of QA framework based on knowledge graph)
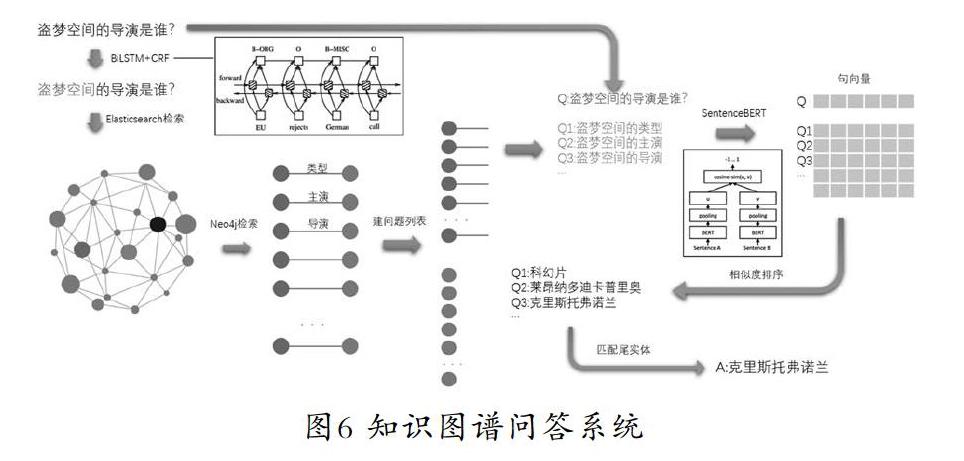
通过上面的介绍,我们提供了一套基于知识图谱问答的实现方法,通过该流程能够快速地构建基于知识图谱的问答系统,通过整体框架的构建我们完成了一个基于知识图谱的问答系统。其流程如图6所示:
(1)将思知知识图谱存入Neo4j中,将实体字符串列表存入Elasticsearch搜索引擎。
(2)使用《人民日报》数据集训练BiLSTM+CRF命名实体识别模型。
(3)当问句进入系统后,识别出问句中的实体,并通过Elasticsearch搜索引擎确定若干实体。
(4)在Neo4j中查询出实体以及对应的所有边,将实体与其相应的边拼接成問题列表。
(5)通过预训练的SentenceBERT模型将问句与问题列表进行相似度排序。
(6)给出问题列表中相似度最高的所对应的尾实体作为答案。
7 结论(Conclusion)
聊天机器人是近年来重要的人工智能落地领域,而基于知识图谱的问答系统是实现聊天机器人的重要方法之一。但关于如何使用知识图谱构建问答系统的问题很少被总结,本文的目的便是总结目前实现这个问题的常用方法,并给出实现知识图谱问答系统的一套基线方法。通过测试表明,该方法能够较快部署实现,准确率较高,时效性基本能满足常见需求。
参考文献(References)
[1] Ding M, Zhou C, Chen Q, et al. Cognitive Graph for Multi-Hop Reading Comprehension at Scale[C]. Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, 2019:2694-2703.
[2] Chiu J P C, Nichols E. Named entity recognition with bidirectional LSTM-CNNs[J]. Transactions of the Association for Computational Linguistics, 2016(4):357-370.
[3] Devlin J, Chang M W, Lee K, et al. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding[C]. Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers) , 2019:4171-4186.
[4] Huang Z, Xu W, Yu K. Bidirectional LSTM-CRF models for sequence tagging[DB/OL]. [2015-08-09].https://arxiv.org/pdf/1508.01991.pdf.
[5] Riedel S, Yao L, McCallum A. Modeling relations and their mentions without labeled text[C]. Joint European Conference on Machine Learning and Knowledge Discovery in Databases. Springer, Berlin, Heidelberg, 2010:148-163.
[6] Surdeanu M, Tibshirani J, Nallapati R, et al. Multi-instance multi-label learning for relation extraction[C]. Proceedings of the 2012 joint conference on empirical methods in natural language processing and computational natural language learning, 2012:455-465.
[7] Zeng D, Liu K, Chen Y, et al. Distant supervision for relation extraction via piecewise convolutional neural networks[C]. Proceedings of the 2015 conference on empirical methods in natural language processing, 2015:1753-1762.
[8] Cai R, Zhang X, Wang H. Bidirectional recurrent convolutional neural network for relation classification[C]. Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2016:756-765.
[9] Wang L, Cao Z, De Melo G, et al. Relation classification via multi-level attention cnns[C]. Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2016:1298-1307.
[10] Cai R, Zhang X, Wang H. Bidirectional recurrent convolutional neural network for relation classification[C]. Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2016: 756-765.
[11] Huang Y Y, Wang W Y. Deep Residual Learning for Weakly-Supervised Relation Extraction[C]. Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, 2017:1803-1807.
[12] Gao T, Han X, Liu Z, et al. Hybrid attention-based prototypical networks for noisy few-shot relation classification[C]. Proceedings of the AAAI Conference on Artificial Intelligence, 2019, 33:6407-6414.
[13] Trisedya B D, Qi J, Zhang R. Entity alignment between knowledge graphs using attribute embeddings[C]. Proceedings of the AAAI Conference on Artificial Intelligence, 2019, 33: 297-304.
[14] 徐增林,盛泳潘,賀丽荣,等.知识图谱技术综述[J].电子科技大学学报,2016,45(04):589-606.
[15] Reimers N, Gurevych I. Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks[C]. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), 2019:3973-3983.
[16] Liu W, Zhou P, Zhao Z, et al. K-BERT: Enabling Language Representation with Knowledge Graph[DB/OL]. [2019-09-17]. https://arxiv.org/pdf/1909.07606.pdf.
[17] Kim Y. Convolutional Neural Networks for Sentence Classification[C]. Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2014:1746-1751.
[18] Liu Y, Ji L, Huang R, et al. An attention-gated convolutional neural network for sentence classification[J]. Intelligent Data Analysis, 2019, 23(5):1091-1107.
[19] Lee K, He L, Lewis M, et al. End-to-end Neural Coreference Resolution[C]. Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing,2017: 188-197.
[20] See A, Liu P J, Manning C D. Get To The Point: Summarization with Pointer-Generator Networks[C]. Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2017: 1073-1083.
[21] Bordes A, Usunier N, Garcia-Duran A, et al. Translating embeddings for modeling multi-relational data[J]. Advances in neural information processing systems, 2013(26):2787-2795.
[22] Wang Z, Zhang J, Feng J, et al. Knowledge graph embedding by translating on hyperplanes[C]. Proceedings of the Twenty-Eighth AAAI Conference on Artificial Intelligence, 2014: 1112-1119.
[23] Ji G, He S, Xu L, et al. Knowledge graph embedding via dynamic mapping matrix[C]. Proceedings of the 53rd annual meeting of the association for computational linguistics and the 7th international joint conference on natural language processing (volume 1: Long papers), 2015:687-696.
[24] Xiao H, Huang M, Hao Y, et al. TransA: An adaptive approach for knowledge graph embedding[DB/OL]. [2015-09-28]. https://arxiv.org/pdf/1509.05490.pdf.
[25] Xiao H, Huang M, Zhu X. TransG: A Generative Model for Knowledge Graph Embedding[C]. Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2016:2316-2325.
[26] Kipf T N, Welling M. Semi-supervised classification with graph convolutional networks[DB/OL]. [2017-02-22]. https://arxiv.org/pdf/1609.02907.pdf.
[27] Hamilton W, Ying Z, Leskovec J. Inductive representation learning on large graphs[C]. Advances in neural information processing systems, 2017:1024-1034.
[28] Veli?kovi? P, Cucurull G, Casanova A, et al. Graph attention networks [DB/OL]. [2018-02-04]. https://arxiv.org/pdf/1710.10903.pdf.
[29] Huang X, Zhang J, Li D, et al. Knowledge graph embedding based question answering[C]. Proceedings of the Twelfth ACM International Conference on Web Search and Data Mining, 2019:105-113.
[30] Zhou H, Young T, Huang M, et al. Commonsense Knowledge Aware Conversation Generation with Graph Attention[C]. International Joint Conferences on Artificial Intelligence Organization, 2018:4623-4629.
作者簡介:
魏泽林(1990-),男,硕士,工程师.研究领域:知识图谱,人工智能.
张 帅(1994-),男,硕士,初级研究员.研究领域:知识图谱,自然语言处理.本文通讯作者.
王建超(1989-),男,硕士,中级研究员.研究领域:人工智能,图像处理.
