教育领域多轮对话机器人的算法设计与实现
2021-04-06闫晓宇彭苏婷
闫晓宇 彭苏婷

摘 要:随着自然语言处理技术的发展,对话机器人以节省人工和易于嵌入等特点受到业界青睐。为了满足在线教育的需求,本文提出的教育领域多轮对话机器人具备和用户针对知识点进行深入对话的能力。本文介绍了此对话机器人的实现全流程:采取用户模拟器生成教育领域语料,使用意图识别和槽位填充实现自然语言理解,通过对话状态追踪和对话策略设计多轮对话逻辑。这为学生提供了答疑解惑的新渠道,为线上教育的智能创新带来更多选择。
关键词:教育;对话机器人;多轮对话
Abstract: With the development of Natural Language Processing (NLP) technology, chatbots are favored for their advantages of labor saving and easy embedding. In order to meet the needs of online education, this paper proposes to design multi-turn chatbots with ability to conduct in-depth dialogue with users on knowledge points in the field of education. This paper introduces a lifecycle of realizing multi-turn chatbot: adopting user simulator to generate educational corpus, using intention recognition and slot filling to realize natural language understanding, and designing multi-turn dialogue logic through dialogue state tracking and dialogue policy. This chatbot provides students with a new way to solve their puzzles and brings more choices for intelligent innovation in online education.
Keywords: education; chatbot; multi-turn dialogue
1 引言(Introduction)
在傳统的教育模式中,学生会遇到层出不穷的学习难点,理想的情况是他们可以得到及时准确的帮助,但需要教师投入大量的时间与精力。教师在讲授某门课程时需要解答的问题是有限的,这意味着他们的工作存在很大重复性。幸运的是随着互联网教育的兴起,人工智能技术已经渗透教育行业的多个领域。目前,市场急需具备线上教学能力的产品来填补空白,既可以随时为学生答疑解惑,又可以节省教师劳动力的对话机器人不失为一个好的选择。
现今已上线的对话机器人有很多,从功能上大致可以分为两类:非任务导向型对话机器人和任务导向型对话机器人。非任务导向型机器人以小冰为代表,旨在和用户在开放域,即开放的话题空间中闲聊互动。任务导向型机器人以小度为例,旨在和用户在封闭域,即有限的话题空间中完成特定任务,比如播放歌曲、查询天气等。任务导向型机器人多出现在生活领域,通过语音、文字等方式控制家居产品等,给用户带来智慧生活的体验。但令人遗憾的是,这类机器人却极少出现在教育领域。
虽然一些平台和软件也嵌入了简单的对话机器人,但其任务设定较为简单,大多只能完成单轮对话,即其仅能对用户发出的最后一句话做出回应。此类对话机器人只具备问答功能而非对话功能,这显然是不够智能的。
本文提出的对话机器人具有多轮对话功能,它可以根据用户对话历史和当前的对话信息与用户产生互动。另外,此对话机器人服务于教育领域,是一个可以在教育领域完成多轮对话的机器人,可以和用户深入探讨关于知识点的各种问题。它可以实时回答学生的问题,为学生减轻负担,同时避免教师的重复劳动,更可以为学校和其他教育机构提供新鲜的学习方法,带来新的学习选择。
实现这一机器人的技术挑战主要有三个:一是缺乏语料库,获得符合预期的教育领域语料库是很困难的;二是设计合理清晰的多轮对话逻辑;三是大体量预训练语言模型的工业部署。
2 相关工作(Related work)
要实现任务导向型机器人,学界和业界公认的经典方法是一种流水线(Pipeline)方法,该方法通过集成三个组件的功能使机器人完成对话,组件按顺序分别是自然语言理解(NLU)、对话管理(DM)和自然语言生成(NLG)。
自然语言理解将用户输入的非结构化文本转化为结构化信息,这一组件的功能实现经历了漫长的技术演变。继有限状态机(FSM)、隐马尔可夫模型(HMM)等方法之后,目前在特定的封闭域内实现自然语言理解具体可分为两个关键任务:一个是意图识别,判断用户语句的意图;另一个是槽位填充,提取语句中的关键文本信息。
意图识别属于文本分类问题,在深度学习中这类技术产生了快速的更新迭代,包括基于卷积神经网络的特征提取[1]、上下文机制[2]、记忆存储机制[3]、注意力机制[4]。槽位填充就是命名实体识别(NER),它的本质是一个序列标注问题,即给文本中每一个字符打上标签,提取文本中的槽值。其中槽是人为设定好的词槽(例如闹钟时间),槽值是文本中出现的词槽对应的值(例如上午十点)。深度学习中颇为经典的结构是论文[5]提出的两种结构,一种是LSTM-CRF,另一种是Stack-LSTM。
意图识别和槽位填充既可以作为两个单独的任务处理,也可以联合处理。由于两个任务之间存在较大的相关性,因此联合建模的效果一般会更好。而2018年BERT[6]等预训练模型出现以后,我们可以更方便地联合处理意图识别和槽位填充任务,本文的对话机器人同样应用了这种方法。
根据对话历史和当前轮次对话信息,对话管理组件记录对话状态并决定对话机器人生成何种回复,其包含两个子组件:对话状态追踪(DST)和对话策略(DP)。对话状态追踪的任务是追踪记录用户的对话历史信息,有两种实现方法可供选择:一种是选取用户的近几轮对话信息,将其拼接后统一做自然语言理解,提取出意图和槽值[7];另一种是根据自然语言理解每一轮的结构化信息作对话状态的更新。对话策略的核心目标是根据DST的结果决定当前轮次如何回应用户。其传统的实现方法是基于规则设计,这在特定封闭域内的效果很好,但是缺乏通用性,在新的域内泛化能力差,故多领域的对话机器人需要手工设计大量规则使对话策略完备。虽然学术界有很多大胆的尝试,不乏使用强化学习来替代基于规则的对话策略模型的算法,但其结果的稳定性和可解释性仍待进一步研究。
自然语言生成将对话管理返回的结果用自然语言表达出来,是由结构化文本生成非结构化文本的过程。虽然现在生成式算法层出不穷,但业界仍然更青睐基于模板和规则的方法来保证任务驱动型对话机器人输出文本的稳定性,本文的对话机器人也采用了这样的方法。
3 提出的方法(Proposed method)
本文提出的教育领域多轮对话机器人的算法设计本质是工程问题,它采用了经典的流水线方法,其组件包括自然语言理解、对话管理和自然语言生成三部分。为了保证在知识点封闭域中回答的严谨性,自然语言生成组件仅用有限的模板就可以达到理想的效果,故本文不做过多介绍。
3.1 语料准备
虽然目前面向自然语言处理技术的开源语料库很多,但满足教育领域和多轮对话两个条件的语料库几乎没有。这为对话机器人工程实现带来了巨大的困难,冷启动是需要首先解决的问题。
解决这一问题的主流方法有两个:通过众包平台获取语料或者构建用户模拟器生成模拟语料。众包方法获得的语料是由人工生成的,最符合自然语言处理的期望,但其成本造价较高,并且我们的机器人面向教育领域,众包得到的语料还面临内容不严谨、数据回流周期长和不满足模型快速迭代需求的风险。因此我们选择通过构建用户模拟器来获得语料。我们的用户模拟器对每一次完整的对话会首先生成一个总体目标,这保证模拟器可以生成上下文连贯的用户动作。这个用户模拟器最终可以生成如图1所示的语料,其展示了一个多轮的用户对话。
教育领域的对话无非是围绕知识点展开的,我们将知识点看作每个完整对话的讨论主题,故我们设定对话将在知识点域这一封闭域中展开。我们将期望机器人能够掌握的知识点列举在一个知识点清单中,用户模拟器的语料将围绕这些知识点生成。基于专家知识,我们定义了四种意图:告知、询问、比较和问候。对应于词槽,我们赋予知识点七个属性,包括名称、定义、性质、应用、优缺点、实现工具、优化改进,用户模拟器可以对知识点的这些属性产生提问。
对于知识点域,设定用户目标包括两种词槽类型:告知槽和询问槽,这分别对应告知意图和询问意图。其中告知槽在语料中对应有槽值,它是知识点的名称,而知识点名称也是我们在自然语言理解的槽位填充中需要识别出的实体,数据结构形如[‘知识点域,‘Inform,‘名称,‘二次规划]。而询问槽没有槽值对应,它对应知识点的其他六个属性,于是我们得到六种询问槽,数据结构形如[‘知识点域,‘Request,‘定义,‘]。另外,为了模拟现实生活中学生对知识点产生的疑问,我们增加了比较意图,这使得用户模拟器可以产生类似“二次规划和支持向量机有什么联系”的问题,其数据结构是[[‘知识点域,‘Inform,‘名称,‘二次规划],[‘知识点域,‘Compare,‘名称,‘支持向量机]]。最后我们使用户模拟器可以产生拟人的问候意图,即生成一些简单的问候语句,数据结构为[‘General,‘Greeting,‘none,‘]。
针对每个完整的对话,依据意图和词槽的排列组合可以生成用户模拟器的总目标,每轮对话都会从还没被完成的总目标中挑选出一些子目标来完成该轮对话,直至所有的總目标都被完成后该完整对话结束。
此用户模拟器的优势是可以根据需要生成任意数量的语料数据,并且可通过增加知识点清单中知识点的数量使机器人可以讨论的知识点范围扩大。我们共生成了7,000 条训练数据、2,000 条验证数据和2,000 条测试数据,每条数据都是一个完整的对话,每个完整的对话都包含多轮的用户对话信息。
3.2 自然语言理解
自然语言理解在任务流水线中的作用是把非结构化文本转化为结构化信息。其中要完成两个主要任务:意图识别和槽位填充,其分别属于文本分类和序列标注任务。早期的深度学习方法将这两部分用两个模型分别处理,例如用TextCNN和Attention做意图识别,用BiLSTM和CRF做槽位填充。但这样做有一些显而易见的缺陷,两个模型叠加可能使最终结果出现误差的概率增大。
虽然一直有学者尝试意图识别和槽位填充两个任务的联合训练,但真正的突破出现在2018年BERT和GPT等预训练模型出现之后。以BERT为例,它的语料库由维基百科等数据集构成,网络结构上沿用了Attention机制的Encoder部分,由12个头的Attention层组成,并且通过MASK机制和NSP(Next Sentence Prediction)方法使模型分别学习到语料的词级别和句级别的知识。这样的设计使BERT可以完成各个类型的自然语言处理下游任务,包括句子的分类任务、阅读理解任务、问答任务和序列标注任务。
BERT有很多中文预训练版本,其中BERT-wwm[8]被广泛使用,它努力保证了原BERT的训练条件和模型结构,并针对中文词汇特点做出改善,引入了wwm(whole word mask)方法,具体是BERT在MASK机制中不再遮盖住单个中文字而是遮盖整个中文词组,这让BERT学习到更多词组的知识。基于BERT-wwm提出的BERTNLU模型[9]以用户模拟器构建的语料库作为输入,在模型的最后一层隐藏层后分别连接两组不同的输出层,两个输出层分别得到意图识别和槽值填充的logist结果,经过后处理就可以得到最终的结果。本文介绍的机器人也采用这种方法完成自然语言理解任务,槽位填充可以识别出语料中的知识点名称,意图识别可以判断语料中包含的意图是否存在告知、询问、比较、问候中的一个或多个。在训练集上训练得到的模型在测试集上的F1值可以达到0.92,这表明我们的自然语言理解组件的性能是满足预期的。
BERT模型效果固然好,但其上亿的模型参数也为工程部署带来了不可忽视的负担。为了解决这个问题,出现了许多轻量化的BERT模型,它们对原始的BERT做剪枝或者蒸馏等处理,以期BERT参数大量减少的同时其精度不会有大幅下降,甚至有些许提升。其中基于知识蒸馏的TinyBERT[10]构造十分精巧,效果也很显著,遗憾的是该模型暂时只能处理英文文本。我们尝试了可以处理中文文本的ALBERT[11]模型,它通过词嵌入参数因式分解和隐藏层间参数共享的方法达到了BERT模型轻量化的目的,虽然模型的运算速度没有提升,但其参数数量减少了十倍左右,并且模型精度在BLUE等数据集上没有显著下降。本文的机器人用ALBERT替代BERT来做预训练模型,并用相同的训练集训练模型后,在测试集上得到的F1值同样可以达到0.9以上的分数。但在人工确认模型输出效果时,我们发现基于ALBERT的模型在意图识别任务上效果没有明显波动,但在槽位填充任务上的表现却不及BERT,我们分析这可能是参数共享带来的副作用,12层隐藏层共用一组参数不可避免地使模型更难识别语料中字词的信息,从而导致序列标注能力下降。
3.3 对话管理
在得到结构化的文本信息后,机器人要根据用户对话历史和当前的对话状态做出恰当的反应。这一决策过程在对话管理组件中实现,因此对话管理可以被理解为对话机器人的大脑部件。更具体地来说,对话状态追踪组件记录更新用户的历史对话状态,对话策略组件决定提供何种反馈。
3.3.1 对话状态追踪
对话状态追踪通过不断获得用户每一轮的对话信息,相应更新维护用户的对话状态,基本的数据结构为词槽和槽值的组合。随着深度学习的发展,学术界出现了一些对话状态追踪的端到端生成方法,例如TRADE算法以用户历史的几轮对话信息作为模型输入,输出结果是用户相应多轮的历史对话状态。这样的方法将自然语言理解和历史对话状态更新整合在一起,省去了基于专家知识面向对话状态追踪的规则设计,但模型的输出结果不能保证稳定可控的效果。而工业界多数采用稳定且易于部署的基于规则的方法,首先设定好需要维护的状态包含哪些字段,再由每一轮对话获得的结构化信息更新。这样虽然需要一些人工来保证规则的完备,但在知识封闭域内的工作量不会很大并且效果是显著的。
3.3.2 对话策略
对话策略也经历了几个阶段的发展,由最初基于规则的方法,发展到基于部分可见马尔可夫决策过程等基于统计的方法,最后是近期学术界青睐的强化学习等深度学习方法。
基于规则方法的ELIZA心理医疗聊天机器人就采用模板匹配的方法完成了对话策略,在当时它的出现引起了轰动,由此可见其对话效果是出人意料的。但基于规则的对话策略有扩展性差、需要强人工干预等缺点,而可扩展性差主要体现在意图识别和槽位填充结果的不稳定性上。前面我们已经提到过,自然语言理解会识别出用户对话中的意图和相应词槽对应的槽值。但在现实应用中,尤其是当对话机器人需要处理多个封闭域甚至是开放域的任务时,用户的意图、词槽和对应的槽值是很难穷举的。即用户的对话中会出现自然语言理解组件识别不了的意图和词槽,例如当用户和机器人在进行电影域内的谈话时,用户突然提及了一个机器人训练集中没出现过的电影名称,这时机器人很难将这个电影名称用槽位填充的方法识别出来,进而就不能和用户产生关于该部电影的互动。为了解决这个问题,前文提到的TRADE算法利用拷贝网络,提升了对不可穷举的词槽的识别能力。
部分可见马尔可夫决策过程等基于统计的方法也取得了不错的效果,此类算法摒弃了人工设计决策规则,但是面对较为复杂多变的状态时无法获得很好的效果。
与强化学习相关的一些算法也在学术界取得了进展[12],但强化学习应用到自然语言处理任务中还是较为困难的,因为语言的复杂性,我们很难设定合适的奖励函数,所以这方面仍需学者们更进一步探索。
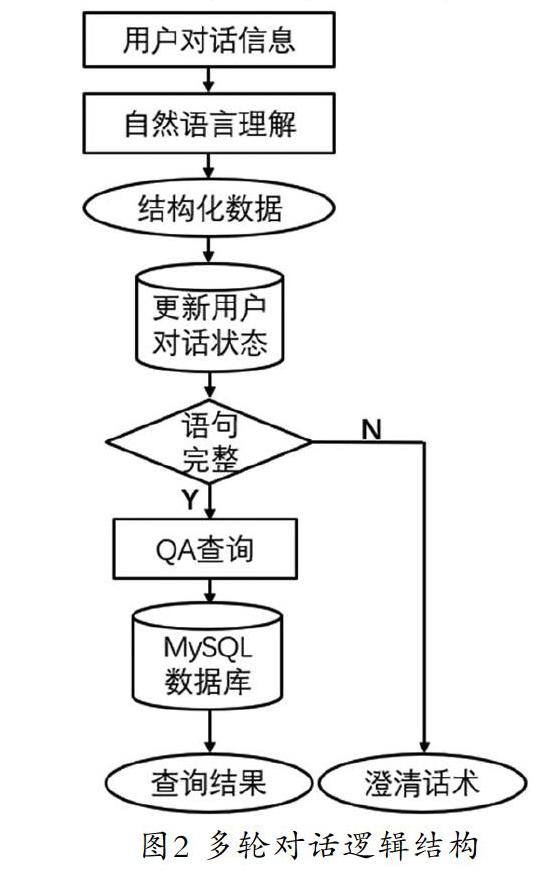
因为本文介绍的机器人被应用在教育领域,用户的意图和词槽的槽值是可能穷举的,尤其是仅针对某一门课程来设计机器人时。因此我们选用基于专家知识的模板设计,通过如图2所示的逻辑架构使机器人可以进行多轮对话。对话策略组件首先会根据用户的当前对话判断其提供的信息是否完整,若完整则执行查询数据库等操作,若不完整则需要用澄清话术对需要填充的词槽做出提问。而在知識点域信息完整性的判断方法是知识点的告知槽和需求槽都不为空。
本文机器人的流水线设计舍弃了自然语言生成的部分,因为机器人的对话输出为:当机器人查询到用户对话相应结果时,直接返回该结果;当查不到时则输出澄清话术,这是可以枚举的,故不需要额外的自然语言生成组件来形成输出结果。当然,如果期望机器人可以产生多样化的输出,采用自然语言生成可以带来更智能的效果。
4 实验效果(Experimental results)
为了展示本文介绍的教育领域多轮对话机器人的对话效果,以下将举例说明。假设用户在一句话中就完整表达出他想了解的信息,例如,“你知道二次规划和支持向量机的关系是什么吗?”此时无须多轮对话功能,机器人根据这些信息就可以在数据库中查询到相应的答案反馈给用户。
但在现实的人际交往中,对话双方往往会省略一些他们谈论过的历史信息。例如,A:“今天天气真好啊”,B:“的确,太阳光暖融融的”,A:“是啊,昨天也是这样呢”。这里A所说的“昨天也是这样呢”,其实想要表达的完整意思是“昨天的太阳光也暖融融的”。我们的对话机器人在教育领域也可以用多轮对话技术达到这样具有历史记忆的效果。例如,用户在第一轮询问“二次规划的定义是什么”,而后又问“那么它的应用和优化改进是什么呢”,此时机器人会自动补全对话信息,分别去数据库查询“二次规划的应用”和“二次规划的优化改进”这两个问题并返回结果。另外,如果用户提问“这和支持向量机有什么联系呢”,机器人会补全信息,在数据库中查询“二次规划和支持向量机的联系”并返回答案。进一步地,如果用户想要转换提问的知识点“那么随机森林呢”,此时机器人会识别出用户想要比较新的知识点“随机森林”和二次规划的区别,因此会查询“随机森林和二次规划的联系”,最后将答案返回给用户。
5 结论(Conclusion)
本文介绍了一种应用在教育领域的多轮对话机器人,在线上教育风行的今天,它可以和学生在学习方面进行人机互动,这样既保证了及时为学生解惑,也为教师减轻了教学压力。并且本机器人还可以被泛化在各门课程,普适性较强。在未来的工作中我们希望可以让此机器人具有双语甚至多语对话的功能,同时更智能完备的逻辑结构和更自然的交互模式也需要我们继续探索。
参考文献(References)
[1] Wang Shiyao, Minlie Huang, Zhidong Deng. Densely Connected CNN with Multi-scale Feature Attention for Text Classification[C]. IJCAI, 2018:4468-4474.
[2] Smith J, Adamczyk J, Pesavento J. Context manager and method for a virtual sales and service center[P]. U.S. Patent No.6,064,973, 2000.
[3] 华冰涛,袁志祥,肖维民,等.基于BLSTM-CNN-CRF模型的槽填充与意图识别[J].计算机工程与应用,2019,55(09):139-143.
[4] 胡文妹.基于任务导向型多轮对话系统的意图识别研究[D].北京:北京邮电大学,2019.
[5] Lample G, Ballesteros M, Subramanian S, et al. Neural Architectures for Named Entity Recognition[C]. Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, 2016:260-270.
[6] Devlin J, Chang M W, Lee K, et al. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding[C]. Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), 2019:4171-4186.
[7] Wu C S, Madotto A, Hosseini-Asl E, et al. Transferable Multi-Domain State Generator for Task-Oriented Dialogue Systems[C]. Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, 2019:808-819.
[8] Cui Y, Che W, Liu T, et al. Pre-Training with Whole Word Masking for Chinese BERT[DB/OL]. [2019-06-19]. https://arxiv.org/pdf/1906.08101.pdf.
[9] Zhu Q, Huang K, Zhang Z, et al. CrossWOZ: A Large-Scale Chinese Cross-Domain Task-Oriented Dialogue Dataset[DB/OL]. [2020-02-27]. https://arxiv.org/pdf/2002.11893.pdf.
[10] Jiao X, Yin Y, Shang L, et al. Tinybert: Distilling bert for natural language understanding[DB/OL]. [2019-11-23]. https://arxiv.org/pdf/1909.10351.pdf.
[11] Lan Z, Chen M, Goodman S, et al. Albert: A lite bert for self-supervised learning of language representations[DB/OL]. [2019-11-26]. https://arxiv.org/pdf/1909.11942v6.pdf.
[12] Abel D, Salvatier J, Stuhlmüller A, et al. Agent-agnostic human-in-the-loop reinforcement learning[DB/OL]. [2017-01-15]. https://arxiv.org/pdf/1701.04079.pdf.
作者簡介:
闫晓宇(1995-),女,硕士,初级研究员.研究领域:自然语言处理,对话系统.
彭苏婷(1995-),女,硕士,初级研究员.研究领域:人工智能,自然语言处理.
