数据库驱动的对话机器人技术实现
2021-04-06来关军于丹闫晓宇肖鹏
来关军 于丹 闫晓宇 肖鹏
摘 要:世界上很多高价值的数据信息储存在关系数据库中,访问这些数据需要掌握专门的结构化查询语言(SQL),普通人很难直接使用。基于对现有对话机器人存在的问题和相关关键技术的梳理,本文融合了数据仓库、数据同步、数据库查询、消息推送、自然语言理解及语音识别等相关技术及产品,设计了数据库驱动的对话机器人。方案可以实现用户理解、消息推送、事实数据查询和分析数据查询四个功能,使得用户能够快速地获取信息。本文提出的数据库驱动的对话机器人具有较强的泛化性和可扩展性。
关键词:关系型数据库;对话机器人;SQL;消息推送
Abstract: Many high-value data in the world are stored in relational databases. Access to these data requires a special Structured Query Language (SQL), which is difficult for ordinary people to use directly. Aiming at problems of the existing chatbot, this paper proposes to design database-driven chatbots by integrating related technologies and products, such as data warehouse, data synchronization, database query, message push, natural language understanding and speech recognition. The solution realizes four functions: user understanding, message push, fact-data query and analysis-data query, so that users can quickly obtain information. Database-driven chatbots proposed in this paper has a capability of strong generalization and scalability that enable chatbots to work with data-driven conversations.
Keywords: relational database; chatbot; SQL; message push
1 引言(Introduction)
數据库驱动的对话机器人是指人们可以通过自然语言完成信息查询或者得到关注信息推送的对话系统。数据库是指长期存储在计算机内有组织的、可共享的数据集合,它的概念比较宽泛,在本文中数据库特指关系型数据库。对话机器人是一种以自然语言在计算机与人之间进行交互的软件[1]。近年来,它开始应用于日常生活的方方面面,例如服务台工具、自动电话应答系统等,以促进教育、医疗、电子商务等领域服务质量的提升。
研究数据库驱动的对话机器人具有深远的应用价值。对于企业的各种应用系统,其信息更多地存储在业务数据库中,包括Oracle、SQL Server、MySQL等关系型数据库。而关系型数据库的查询还是一个比较专业的领域,对大众并不友好。采用人机对话的方式,通过对话机器人来查询数据是一个很好的方向,它使用户直接以自然语言的方式,向数据库系统发问并获得所需信息,从而大大提升人机交互的容易程度;另一方面,当人们关注的主要信息在数据库中有所更新时,也能第一时间主动地通知用户。这样的对话机器人能够提高用户获取信息的友好性和便捷性,具有更广泛的实用价值和社会意义。
关于数据库驱动的对话机器人的研究和技术实现,遇到的主要问题包括以下三个方面:
(1)对话机器人理解用户的需求和自然语言非常困难。由于自然语言的创造性、递归性、多义性、主观性和社会性等特点[2],既让人类的自然语言具备强大的表达力和生命力,同时呈现出非常复杂且难以捉摸的情景,因此让计算机去准确理解人类语言是首要的问题。
(2)现在对话机器人对于数据库的查询通常是被动的,缺少主动推送信息。即针对用户的提问和聊天,对话机器人或者被动应答,或者被动查询数据库,总之,被动地提供反馈,主动性不足。
(3)现在对话机器人对业务数据库进行直接查询通常会对现有业务系统造成性能和安全影响,特别是对统计性结果的查询影响更大。
针对以上问题,本文基于现有开放的软件产品和服务,提出了数据库驱动的对话机器人的一种技术实现方案。该方案可以方便快捷地构建对话机器人,使用户通过语音或者文本查询数据库内容,并在数据库相关内容更新时主动地向用户发送推送信息,使用户能够更便捷地获得数据库中的内容,简化了用户的信息获取方式。
2 相关研究和技术(Literature review)
数据库驱动的对话机器人技术实现所面临的主要技术挑战分别是自然语言理解、消息推送以及数据库设计和优化。
在自然语言理解和实现方面,随着1995年以来信息检索技术的发展,Baidu、Google等搜索引擎公司计算能力的飞速提升,以及2005年后互联网业的蓬勃发展和移动终端的迅速普及,自然语言理解的研究进展迅猛,也产生了一系列比较成熟的聊天系统,比如苹果的Siri、微软的Cortana、Facebook的Messenger、Google的Assistant等[3]。这些跨平台型人工智能机器人借助本公司在大数据、自然语义分析、机器学习和深度神经网络方面的技术积累,精炼形成自己的真实语料库,在不断训练的过程中通过理解对话数据中的语义和语境信息,实现超越一般简单人机问答的自然交互。相比国外,我国在智能聊天领域的投入规模和研究水平上都有着不小的差距,研究成果并不显著。但是有多所高校在此领域成绩显著,主要集中在自然语言处理工具的开发上,比如哈尔滨工业大学的HIT工具(中文词法分析、句法分析和语法分析)以及台湾“国防大学”的CQAS中文问答系统(侧重于命名实体及其关系的处理)等[4]。因此,借助现有成熟的自然语言理解平台和工具,开发对话机器人可以起到事半功倍的效果。
在消息推送的研究和实现方面,目前服务端给客户端推送消息,普遍做法是客户端与服务端维持一个长连接,客户端定时向服务端发送心跳以维持这个长连接。当有新消息过来的时候,服务端查出该消息对应的TCP Channel的ID,并找到对应的通道进行消息发放[5]。在此之上,又衍生出针对消息的发布/订阅模型,客户端可以订阅某一个Topic,服务端根据Topic找到对应的Channel进行批量的消息发放。在此基础上又衍生出了如MQTT等开源协议用于定义以上过程[6]。在如今动辄成千上万用户量的情况下,如何应对大规模的消息下发以及如何保证消息推送的及时性、高可靠性和高可用性是消息推送的技术难点。目前,国内较为常用的第三方推送服务工具有极光推送、腾讯信鸽、百度云推送、华为推送、小米推送等。通过基于第三方的消息推送云服务,来保障消息推送的及时性、高可靠性和高可用性。
在数据库设计和优化方面,近年来各种数据库层出不穷,解决各领域内具体的业务问题。经过了60多年发展的关系型数据库主要存储和管理结构化的数据,应用于联机事务处理系统(On-line Transaction Processing, OLTP),但对超大规模的数据管理,特别是横向扩展方面支持不足[7]。NoSQL数据库是关系型数据库的一种补充,不使用模式(Schemaless)或使用灵活的模式追求高性能和高吞吐量,可以支撑超大规模数据的横向扩展,主要管理非关系型数据,但它不支持ACID和事务,不支持关联,缺少标准接口[8]。随着数据量的增加以及数据统计、分析和挖掘的需求,各种数据仓库和大数据处理平台也同步快速发展,包括MPP平台和Hadoop生态平台,可以广泛应用于联机分析处理系统(On-line Analytical Processing, OLAP)。针对不同的业务需求以及数据规模,采用不同的适合的数据库并进行优化,是实现技术方案适用性的首要准则。
3 技术方案(Solution)
一个数据库驱动的对话机器人应该包括四个功能。首先,该对话机器人能够通过文字或语音理解用户的意图;其次,该对话机器人在用户关心的信息发生变化后能够主动通知用户;第三,该对话机器人能够帮助客户在不知道数据库表结构的情况下,从数据库中查询到特定的事实数据;最后,该对话机器人能够从数据库中查询到分析型的数据。
基于以上四种功能,本文提出的总体框架包括用户理解、消息推送、事实数据查询、分析数据查询四个服务,具体如图1所示。
首先,用户理解服务实现对话机器人能够通过文字或语音理解用户意图的功能,包括文本处理模块、语音识别模块和自然语言理解模块三个部分。
其次,消息推送服务实现对话机器人在用户关心的信息发生变化后主动通知用户的功能,包括文本处理模块、数据库监听模块和业务数据库三个部分。
第三,事实数据查询服务实现对话机器人帮助用户在不知道数据库表结构的情况下从数据库中查询到特定事实数据的功能,包括SQL解析器、以个体为中心的数据集市、业务数据库及ETL四个部分。
最后,分析数据查询服务实现对话机器人从数据库中查询分析型数据的功能,包括SQL解析器、分析型多维数据仓库、业务数据库及ETL四个部分。
3.1 用户理解服务
用户理解服务是与用户沟通的接口,主要功能是理解用户的语音和文本,并将结果或者消息告知用户。其结构如图2所示。
其中,文本处理模块把用户的文本输入直接传递给自然语言理解模块;语音识别模块把用户的语音输入转换成文本传递给文本处理模块,并最终传递给自然语言理解模块。另外,文本处理模块接收来自自然语言理解模块的文本,并将文本展示给用户查看。语音识别模块主要是接收语音,并把语音转化为文本,在本技术实现中采用百度的语音识别服务。自然语言理解模块则接收文本,理解文本,并进行语义表示,生成意图和实体,在本技术实现中采用Google的API.AI服务。
在语音识别模块中,当用户输入为语音时,需要将语音转换为文本,采用的技术为语音识别技术(Automatic Speech Recognition, ASR)。ASR是以语音为研究对象,通过语音信号处理和模式识别让机器自动识别和理解人类口述的语言,本质上是一种模式识别系统,包括特征提取、模式匹配、参考模式库等三个基本单元[9]。目前市场上有很多家的语音识别接口可用,国内的百度、阿里巴巴、腾讯、华为和科大讯飞,国外的微软和谷歌都提供了中文的语音识别接口,包括SDK和Web API。百度语音识别技术领先,近场中文普通话识别准确率达98%,简单快速且支持API及多种SDK接入。本文采用百度语音识别接口,完成语音向文本的转换。
在自然语言理解模块中,根据用户的自然语言输入来理解用户的意图,其目标是将自然语言文本信息转换为可被机器处理的语义表示。语义表示可以用“意图+槽位”的方式来描述。意图即这句话所表达的含义,槽位即表达这个意图所需要的具体参数。自然语言理解(Natural Language Understanding, NLU)的挑战主要包括三个:首先,语音识别错误率通常在10%—20%,这会影响语义理解的准确性;其次,通过自然语言表达的语义存在不确定性,同一句话在不同语境下的语义可能完全不同;最后,在自然语言中往往存在不流畅性、错误及重复等情况[10]。针对这些挑战,目前有一些公司将NLU作为一种云服务提供,方便其他产品快速地具备语义理解能力,比如Facebook的WIT.AI、Google的API.AI
和微软的LUIS。使用者上传数据,平台根据数据训练出模型并提供接口供使用者调用。
API.AI是一个为开发者提供服务的机器人搭建平台,帮助开发者迅速开发一款bot并发布到各种message平台上。使用API.AI可以将用户输入的自然语言翻译成一种“程序能读懂”的语言,并以JSON的格式返回结果。使用API.AI包括五個步骤:首先是自定义Entity,然后是自定义Intents和Action,接着上传数据,再使用API.AI的训练器进行模型的训练并得到分类器,最后是整合和发布,可以用Web Service的方式提供服务。使用API.AI的好处是能够快速地搭建出数据驱动的NLU模块,本文采用API.AI提供的云服务完成自然语言理解的功能。
3.2 消息推送服务
消息推送服务的主要功能是监控数据库中用户特别关注的信息的变化,当相应的信息发生变化后,准实时且主动地通知用户。其结构如图3所示。
其中,业务数据库为关系型数据库,具体选择为MySQL数据库,用于存储数据和信息;数据库监听模块监控MySQL的Binlog日志,准实时增量更新用户关注的信息,并将更新的信息以消息的形式发送至消息推送模块;当消息推送模块接收到要推送的消息任务后,将消息推送给相关用户的文本处理模块;文本处理模块则将消息以文本的方式展示给用户。其中,数据库监听模块采用阿里巴巴的Canal工具,消息推送模块采用百度云推送。
在消息推送模块中,消息推送是指通过后台将用户强烈关心的信息主动地发送给用户,可通过短信、即时信息(Instant Message, 如微信、钉钉等)、非即时消息(比如手机App中新闻资讯类、活动推送类、产品推荐类、系统功能类的通知)等方式发送,其中短信的用户查看率高,但价格昂贵,非即时消息成本次之,即时信息免费。消息推送的实现有两种主要方式,第一种方式是自己研发,但由于研发成本较高,难度非常大,大多数App都会选择使用第二种方式,即使用第三方工具进行推送。本文采用百度云推送。百度云推送(Push)是百度云平台向开发者提供的消息推送服务,通过云端与客户端之间建立稳定、可靠的长连接来为开发者提供向用户端实时推送消息的服务。
在数据库监听模块中,需要实时监控业务数据库的变化,当数据库中用户最关心的数据发生变化时,要将相应的变化发送给特定的人。监控业务数据库变化的方法有多种,一种方法是在数据库增加触发器(Trigger)。触发器是由事件来触发某个操作,这些事件包括INSERT语句、UPDATE语句和DELETE语句,当数据库系统执行这些事件时,会激活触发其执行相应的操作。这种方法操作简单,但是会对原业务系统造成很大的影响,特别是性能压力方面。第二种方法是通过第三方软件平台,比如阿里巴巴的开源框架Canal,监控数据库的Binlog,进而同步增量数据。这种方法对原业务系统的影响更小。Canal的工作原理是模拟MySQL Slave的交互协议向MySQL Mater发送Dump请求,MySQL Mater收到请求后,向Canal推送Binlog,然后Canal解析Binlog,再发送数据到存储目的地,实现数据库镜像、数据库实时备份、增量数据处理等。Canal的好处在于对业务代码和数据库没有侵入,实时性也能做到准实时,因此是在很多企业中广泛应用的一种比较常见的数据同步方案。
本文采用Canal监控用户关心的增量数据,并将数据发送到消息队列,然后通过百度云推送,发送给用户。
3.3 事实数据查询服务
事实数据查询服务的主要功能是根据意图和实体,查询数据库中用户关心的实际数据(业务数据、存储的数据),并将查询结果反馈出去,其结构如图4所示。
其中,SQL解析器根据意图和实体,生成相应的数据库查询语句(SQL):意图是指要查询的表;实体(槽)是参数,包括主键和需查询的列名。以个体为中心的数据集市是一种数据仓库,内容是根据用户的所有业务活动,使用ETL(Extract-Transform-Load)工具重新组织的业务数据。业务数据库为关系型数据库,具体选择为MySQL数据库。
在构建以个体为中心的数据集市方面,由于业务数据库逻辑复杂,且运行稳定,通过SQL解析器生成的SQL直接访问业务数据库,一方面会对原始业务造成很大的影响,另外一方面也会增加上游自然语言理解模块的训练复杂度,因此需要将原始的业务数据库通过ETL转化为以主数据为中心的新型数据仓库。ETL将数据从来源端经过抽取(Extract)、转换(Transform)、加载(Load)到目的端。其中,Extract即数据抽取,就是把数据从数据源读出来;Transform即数据转换,就是把数据转换为特定的格式;Load即数据加载,把处理后的数据加载到目标处。
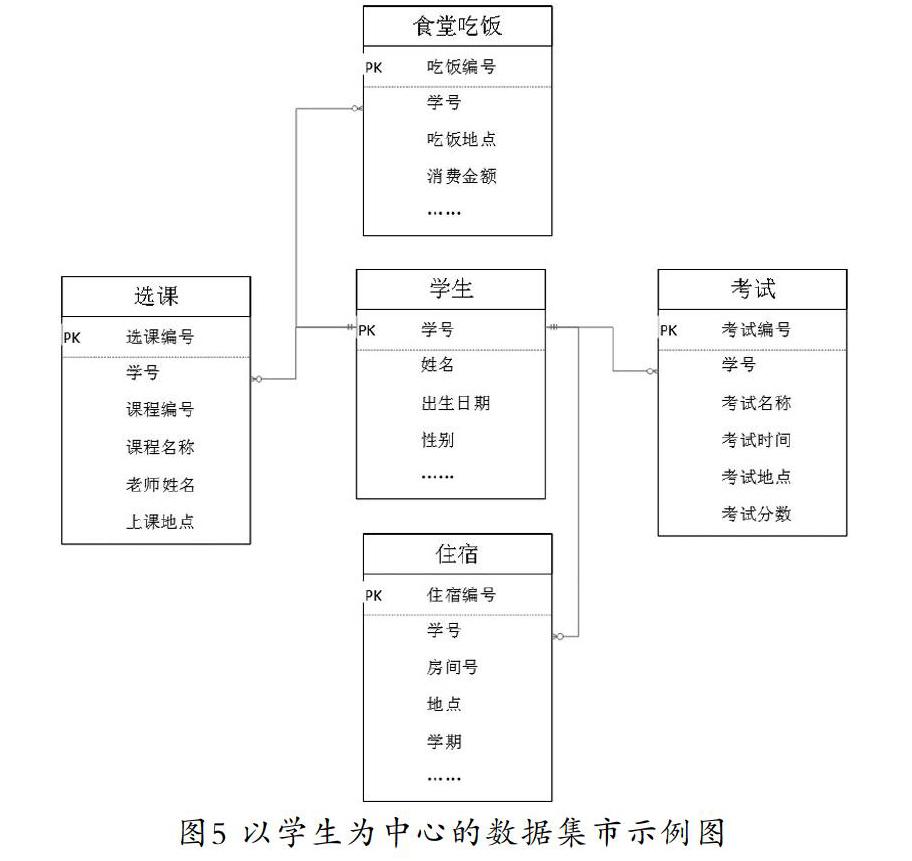
在构建以个体为中心的数据集市中,主数据(Master Data)是指具有高业务价值的、可以在企业内跨越各个业务部门被重复使用的数据,是单一、准确、权威的数据来源,比如教学系统中的学生、老师等。建立以主数据为中心的数据库是指首先识别出主数据,然后将所有的业务数据同主数据直接关联。以学校管理系统中的学生为例,其数据库ER图如图5所示。
学生是学校中各个部门都要使用的基础数据,必须要保证准确唯一,通过学号可以确定唯一的学生。学生会涉及选课、住宿、考试、食堂消费等活动,这些活动的数据即是业务数据,所有这些业务数据都可以通过学号与学生关联起来。这样在对数据库进行查询时,只需要知道学号以及要查询的具体内容(选课、考试、住宿、食堂),即可由SQL解析器生成相应的SQL,查询得到相应的结果。这样的好处是可以将原始的业务数据同对话机器人的数据库进行隔离,提高了系统的稳定性和安全性;另一方面,在自然语言理解方面,可以更明确地定义意图和相关的语义,在不需要了解底层数据库结构的情况下得到相应信息。
3.4 分析数据查询服务
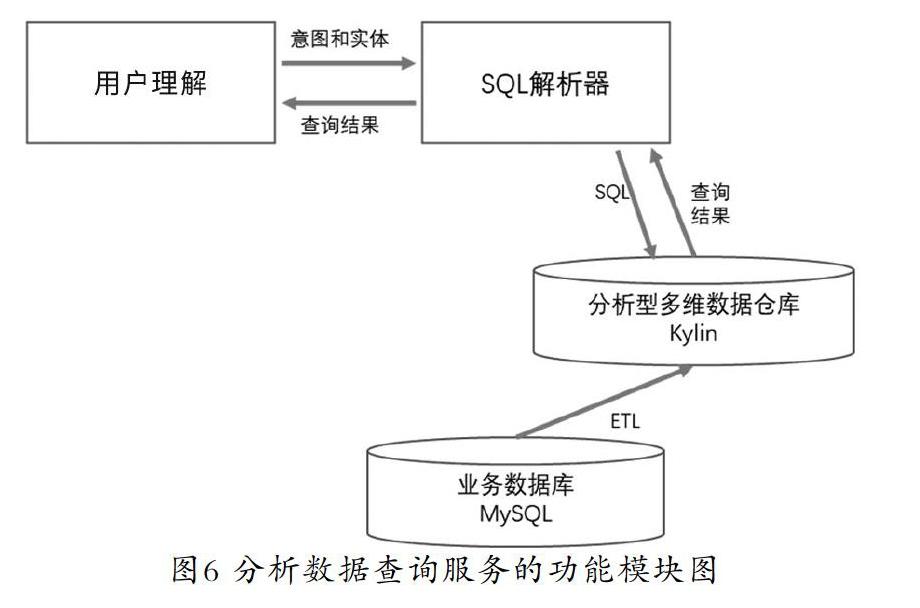
分析数据查询服务的主要功能是根据意图和实体,查询数据库中用户关心的分析型结果,并将查询结果反馈出去。其结构如图6所示。
其中,SQL解析器和业务数据库内容与事实数据查询服务中的内容相同;分析型多维数据仓库是将业务数据库中的数据经过ETL过程整理得到的多维数据仓库模型。本文选用Apache Kylin对多维数据仓库中的统计结果进行提前计算,以备查询需要。
在构建分析型多維数据仓库方面,用户对数据库的查询并不都是对某一条记录的查询,有时查询的内容是统计结果,比如某门课的学生人数是多少,食堂里每人的平均消费是多少等,本文称这类查询为分析型查询。同理,基于数据安全性、业务数据库的压力以及查询的效率考虑,需要通过ETL将业务数据库中相对分散和孤立的数据转换到分析型多维数据仓库中。
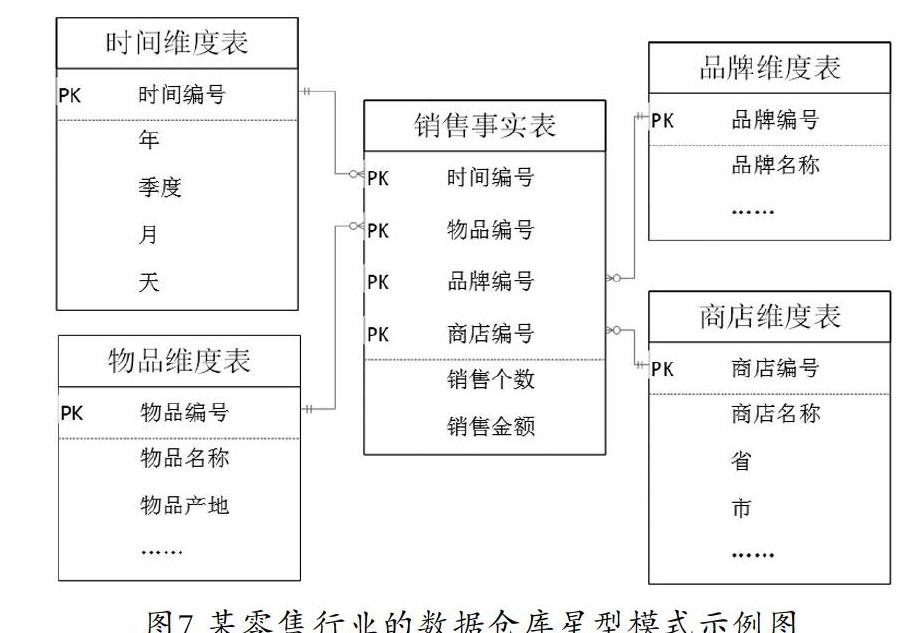
本文的多维数据仓库具体采用星型模式。星型模式的核心是一个大的中心表(事实表)和一组小的附属表(维表)。其中,事实表用来记录具体事件,包含每个事件的具体要素和具体发生的事情,主要包含维和度量两方面的信息。维的具体描述信息记录在维表,事实表中的维属性只是一个关联到维表的键,并不记录具体信息。度量记录事件的相应数值,比如商品销售中产品的销售数量、销售金额等。某零售行业的数据仓库星型模式示例如图7所示。
其中銷售为事实表,时间、物品、品牌和商店为维度表,这样对于销售事实表来说,时间、物品、品牌和商店是维,销售金额和销售个数是度量值。
采用星型模式这种多维数据仓库模型的优点是其面向分析优化的数据组织和存储模式。由于在实时查询统计信息时,直接计算速度比较慢,本文选择Apache Kylin对多维数据仓库进行管理和计算。Apache Kylin是一个开源的、分布式的分析型数据仓库,提供Hadoop/Spark之上的SQL查询接口及多维分析(OLAP)能力以支持超大规模数据,它能在亚秒内查询巨大的表。
4 结论(Conclusion)
本文提出了一种数据库驱动的对话机器人的技术实现方案,可以实现用户通过语音或自然语言文本同对话机器人沟通,查询数据库中的事实记录和统计结果,并在用户关注的信息发生改变时主动通知用户的功能。该技术方案的主要思想是立足于“以用户为中心”的服务理念,借鉴语音识别、自然语言处理、消息推送、数据库设计和优化方面的先进技术和方案,整合成一个对用户更友好的平台,帮助用户便捷地获得高价值的信息。针对语音识别、自然语言理解、消息推送和数据库优化方面的技术难点,本技术方案分别采用了百度语音识别、Google API.AI、百度云推送、阿里巴巴Canal、Apache Kylin等成熟的云服务、技术和平台,在满足功能的同时,也能够实现可靠性、可用性、鲁棒性以及扩展性方面的需求。
不过,现有的技术方案还只是把查询结果或者推送的消息直接反馈给用户,没能实现以更自然的语音或者自然语言文本的方式告知用户,这涉及自然语言生成相关的技术。另一方面,本文提出的是一种技术实现方案,还没有针对一个行业具体落地。因此,下一步我们计划针对高校的学生,实现数据库驱动的对话机器人,以满足其对学习、考试方面信息的查询需求。
参考文献(References)
[1] 侯佳腾,常薇,林冠峰.基于自然语言理解技术的智能客服机器人的设计与实现[J].电子技术与软件工程,2019(23): 238-240.
[2] Hafezi Manshadi, Mohammad. Dealing with quantifier scope ambiguity in natural language understanding[D]. Rochester: University of Rochester, 2014.
[3] 王浩畅,李斌.聊天机器人系统研究进展[J].计算机应用与软件,2018,35(12):1-6;89.
[4] 夏艳辉,聂百胜,胡金凤.中文开放域问答系统的问题分类研究[J].价值工程,2019,38(016):147-149.
[5] 曹鹏飞,李杰,杨君.云环境下实时消息推送服务构建研究[J].计算机技术与发展,2020,30(03):204-208.
[6] 关庆余,李鸿彬,于波.MQTT协议在Android平台上的研究与应用[J].计算机系统应用,2014,23(04):197-200;196.
[7] 连乐,付杰.无线监测系统的数据处理方法研究[J].计算机科学,2018,45(0z1):580-582.
[8] 申德荣,于戈,王习特,等.支持大数据管理的NoSQL系统研究综述[J].软件学报,2013(08):96-113.
[9] 程建军,胡立志.关于深度学习的语音识别应用研究[J].科技经济导刊,2019,27(12):195.
[10] 侯沐澜.面向自然语言理解的新槽值问题研究与应用[D].北京:北京邮电大学,2019.
作者简介:
来关军(1984-),男,硕士,中级研究员.研究领域:大数据分析,人工智能.
于 丹(1976-),女,博士,研究员.研究领域:数据分析与挖掘,人工智能.
闫晓宇(1995-),女,硕士,初级研究员.研究领域:自然语言处理,对话系统.
肖 鹏(1993-),男,硕士,初级研究员.研究领域:计算机视觉,自然语言处理.
