边缘计算驱动的对话机器人终端部署
2021-04-06马壮杨威
马壮 杨威


摘 要:目前,大部分内置对话功能的终端只是用户文字语音传输的“中转站”,并不承担计算功能。这导致用于计算的云服务需要承担较高的网络负载和计算负载。随着硬件性能的不断提升,终端设备也能运行部分自然语言处理算法,分担云服务的压力。本文讨论了使用边缘计算技术实现对话机器人终端部署的可行性,并设计了基于云+边缘协同计算的对话系统架构。通过将部分对话机器人部署在终端,可以降低云服务的访问频率,从而降低网络和计算负载。
关键词:对话机器人;边缘计算;深度学习模型部署
Abstract: At present, most information terminals with built-in dialogue function are only transit stations for users' text and voice transmission, and they do not undertake calculation functions. As a result, cloud services for computing have to carry high network load and computing load. With hardware improvement, terminal devices can also locally run some natural language processing algorithms to share pressure of cloud services. This paper discusses feasibility of using edge computing technology to realize deployment of chatbot terminals, and designs a dialogue system architecture based on cloud + edge collaborative computing. By deploying some chatbots on terminals, access to cloud services can be reduced, thereby lowering network and computing load.
Keywords: chatbot; edge computing; deep learning model deployment
1 引言(Introduction)
基于自然语言处理技术的对话机器人正在深刻地改变人机交互的模式。依托于文本相似度匹配、命名实体识别等自然语言处理算法,对话机器人能够在一定的封闭域内理解人类的语言,并给出符合常识的响应。但受制于这些算法的高计算复杂度,对话机器人的算法部署大多采用云部署的方式,使用云端的高性能计算集群完成算法任务[1]。随着用户数量的增加,云端需要更大规模的计算集群来完成高并发的对话服务响应,这样一来系统部署的成本就会显著提升。
在硬件设备计算能力不断高速提升的今天,许多终端设备(例如中高端手機和平板电脑)都配有高主频多核心的中央处理器。如果使用边缘计算技术充分调动这些计算资源,终端设备便具备了实时语音视频信号处理、深度学习算法前向推理的能力。在边缘计算技术的支撑下,经过优化的终端设备就能够独立完成自然语言处理任务,初步实现语义理解和高频问题的应答,分担云服务器的部分计算压力。云服务器可以将计算资源集中在低频、高精度、依赖海量常识信息的用户问题的应答中。将对话机器人的云端部署与边缘设备部署相结合,能够充分发挥二者的优势,在保证对话机器人能够准确回答用户问题的前提下,尽可能地降低部署难度和部署成本。
本文将先介绍对话机器人部署和边缘计算的研究基础;然后总结边缘计算驱动的对话机器人部署技术,论证其可行性;最后提出基于云+边缘协同计算的对话机器人部署架构。
2 相关研究(Related study)
2.1 对话机器人部署相关研究
目前,已经有很多对话机器人完成了部署并产品化,如图1所示。小米的对话机器人小爱同学已经融入小米产品生态体系中。用户可以与搭载了小爱同学的小米智能音箱对话,从而控制35大品类的智能家居设备,例如电视、扫地机器人、智能插座等[2]。高德地图的对话机器人小德主要面向导航场景,通过语音交互,向用户提供路径导航、附近公共设施搜索等服务。阿里的店小蜜在简单的配置之后就能够智能回答用户的高频问题,大大降低了人工客服的工作量。
上述三款对话机器人分别以智能音箱、手机、网页为载体,与用户产生交互。当用户通过语音或键盘输入与对话机器人沟通时,终端会将用户的语音、文本等原始数据上传到云端,由云服务器完成语义分析并将回复返回终端,最后终端将回复结果呈现给用户。在这个流程中,终端主要承担着数据收发和用户交互的任务,而核心算法都在云端的服务器上进行计算。
虽然算法的云服务部署具有扩展性高、通用性强等优点,但是随着用户与对话机器人的交流频率越来越高,云服务器的网络负载和计算负载也会越来越高,这样一来会显著提高云服务的部署成本。
2.2 边缘计算相关研究
边缘计算指在靠近数据源头的一侧就近提供服务的技术,已经被广泛应用于自动驾驶、工业物联网、智慧城市等领域[3]。基于智能终端的边缘计算设备能够实时分析传感器采集的数据,并产生快速响应,在满足实时业务的同时还能够保护用户的隐私。
为了保证一系列复杂算法(例如深度学习算法)能够顺利地在边缘设备上运行,开发者通常会从硬件和软件两个层面进行优化。硬件加速是指使用专用的高性能计算单元代替中央处理器执行复杂算法的技术。数字信号处理器(Digital Signal Processor,DSP)专用于数字信号处理任务,图形处理单元(Graphic Processing Unit,GPU)更擅长图形渲染,神经网络推理计算可以使用神经网络处理单元(Neural Processing Unit,NPU)进行加速。软件加速是指在软件层面上充分调动已有的硬件资源提升计算效率的技术,常见的软件加速技术有异构计算、内存分配优化、指令集优化等。在固定的硬件条件下,使用最适合的软件加速方案进行调优,能够最大程度地利用不同计算单元的特性,在边缘设备上实现实时的数据采集、处理与分析。
但是,毕竟终端设备的计算能力无法与云服务器相比,而且目前最新的高精度的自然语言处理算法复杂度较高,因此使用边缘计算技术部署对话机器人仍有诸多挑战。
3 边缘计算驱动的对话机器人部署技术研究现状(Research status of edge computing-driven chatbot terminal deployment technology)
在对话机器人和用户交互的过程中,算法需要解决诸如自然语言理解、文本相似度匹配等问题。目前,基于深度学习的预训练模型(BERT、GPT等)在这类问题上展现出很大的优势。但是因为这类模型需要先从海量文本中学习自然语言的多样化表示,所以参数普遍很多(超过300M个浮点数)[4]。针对这一任务,我们需要解决硬件加速、软件加速和模型轻量化三个问题。下面本文将从这三个角度介绍边缘计算技术应用于对话机器人部署场景的可行性。
3.1 硬件加速
由于目前驱动对话机器人的自然语言处理算法大多基于深度学习方法,因此如果在智能终端的硬件选型过程中考虑集成能够提升深度学习算法推理速度的计算单元,就能使智能终端具备对话机器人部署的可能性。常见的应用于深度学习算法边缘计算的高性能计算单元包括图形处理单元(GPU)、神经网络处理单元(NPU)、可编程逻辑门阵列(FPGA)等。
GPU最早应用于解决图形渲染问题,它能够调用计算能力不高但数量众多的计算核心,并行地完成诸如3D坐标变换等简单计算操作,从而实现复杂三维物体的实时渲染。自2012年Alex提出了AlexNet并使用GPU加速了神经网络训练过程之后,GPU被广泛应用于深度学习模型的训练和云端部署任务中。在边缘计算场景下,手机等智能终端的系统级芯片(SoC)中都包含负责画面渲染的GPU,这些GPU能够辅助加速神经网络的前向推理。同时,NVIDIA尝试将高性能的GPU嵌入开发板中,推出了Jetson系列开发板。该系列产品在神经网络计算任务上的表现远超同价位的树莓派开发板,为开发者硬件选型提供了新的选项。
NPU是专用于神经网络计算的计算单元,架构设计上模仿了生物神经网络,以“神经元”为基本单位。在计算过程中,模型中每层神经元的结果无须输出到主内存,直接按照网络结构传递给下层神经元。这使NPU无须像CPU和GPU一样频繁访问内存,这样不仅提升了整体计算速度,还能够大大降低功耗。目前,高端手机的SoC芯片(华为麒麟990、三星Exynos980等)中都集成了专用于执行深度学习算法的NPU。
FPGA是一种半定制电路,开发者可以使用硬件描述语言(Verilog、VHDL等)修改芯片中门电路和存储器之间的连线,从而实现算法的部署。依托于硬件电路天然的并行特性,FPGA能够拥有更快的计算速度、更高的带宽,同时保持较低的功耗。但是,受制于硬件开发的复杂性,将算法部署在FPGA上需要更多的时间。2020年,百度推出了基于FPGA的开发板EdgeBoard,同时提供了Paddle-Mobile到FPGA的模型转换工具。这一产品大大简化了深度学习算法在FPGA上的部署过程,使在FPGA上快速迭代算法成为可能。
综上,在对话机器人载体终端的硬件设计过程中,如果采用系统级芯片(SoC)解决方案,可以在芯片设计过程中为GPU和NPU模块分配相应的空间。如果采用板级解决方案,可以选用配有GPU模块或FPGA模块的开发板,然后基于开发板中的Linux/Android系统进行软件开发。两种方案都能够在硬件层面提升终端执行深度学习算法的能力,从而辅助实现对话机器人的边缘部署。
3.2 软件加速
与云服务器不同,边缘计算设备受功率和成本的限制,往往无法通过单纯累加硬件的方式實现深度学习算法加速。因此,为了让有限的硬件资源最大程度发挥出最高的性能,小米、阿里、腾讯等公司都研发了针对边缘计算设备的深度学习算法前向推理框架。这些框架都包含以下软件加速技术:
异构计算:当智能终端在硬件层面集成了高性能计算单元之后,为了更好地调度不同的计算单元协同完成复杂的计算任务,需要有一个跨平台的通用软件编程标准。2008年,苹果公司提出了一个这样的标准,命名为OpenCL。此后,Intel、NVIDIA、AMD等公司硬件产品的驱动程序中都陆续提供了OpenCL的API支持。前向推理框架可以使用OpenCL调度GPU等计算单元实现加速[5]。但在智能终端,尤其是Android平台上,硬件设计没有统一的标准。仅GPU一项就有高通的Adreno系列、ARM的Mali系列、Imagination的PowerVR系列、NVIDIA的Tegra系列,每个系列的硬件架构和纹理压缩格式不尽相同,这导致前向推理框架想要兼容所有设备是非常困难的。目前,腾讯TNN和阿里MNN都做到了Android平台和iOS平台的深度调优;小米mace仅支持高通、联发科、松果等系列芯片的异构计算,尚不支持iOS平台。
算符级优化:在深度学习模型训练过程中,为了提升神经网络结构搭建的灵活性,网络都被划分成粒度较小的基础算符(例如,卷积、激活函数、矩阵乘法等)。由于每个算符计算完成之后都要将计算结果从低层内存搬运到高层内存,因此会反复读取内存造成不必要的数据传输开销。因此,前向推理框架往往会采用算符融合的方式,把一些常见的同时出现的算符(Conv+bn+ReLU)合并为一个粒度较大的算符,这样能够显著提升推理速度。另外,对一些常用算符的实现方式进行单独优化也是有效地加速方案。TNN等框架中都使用了Winograd等快速卷积方法替换传统的卷积实现方式,虽然损失了一定的精度,但是计算速度能够至少提升四倍[6]。此外,基于Strassen算法的矩阵乘法加速算法还能够显著提升全连接层运算速度。
低精度优化:目前绝大部分深度学习算法的权重数据类型都是32-bit浮点数。但是大量研究表明,在模型计算尤其是模型前向推理的过程中,如此高的数据精度是不必要的[7]。如果将权重数据量化到FP16(16-bit浮点数)或INT8(8-bit整数)形式,在一定调优的前提下不仅能保证模型推理的准确性,还能显著提升计算效率并降低内存带宽。为了在硬件层面上加速低精度计算,ARM的GPU从Mali-G76起全面支持INT8计算指令,寒武纪等NPU厂商也都在芯片中集成了INT8压缩方案。
此外,软件加速还包括Neon向量化优化、内存优化等方法,通过对处理器底层资源调度的优化,能够减少不必要的计算开销。目前,深度学习前向推理框架仍处于快速发展阶段,常规的框架并不能完美兼容所有硬件设备和计算算符。因此在对话机器人的边缘部署过程中,需要综合考虑目标设备的硬件条件和待使用的网络模型,选用兼容性最好的框架。
3.3 模型轻量化
目前,基于语言模型预训练的自然语言处理算法在诸多任务上表现出出色的准确度,最具代表性的模型有BERT和GPT等。这些模型为了从海量文本中学习多样化的自然语言表示,往往在设计过程中没有考虑计算复杂度,模型参数数量往往是上亿级别,这导致了此类模型几乎无法直接部署到任何终端设备上。因此,如果想实现对话机器人的终端部署,在自然语言处理模型的设计上就要关注轻量化的问题。
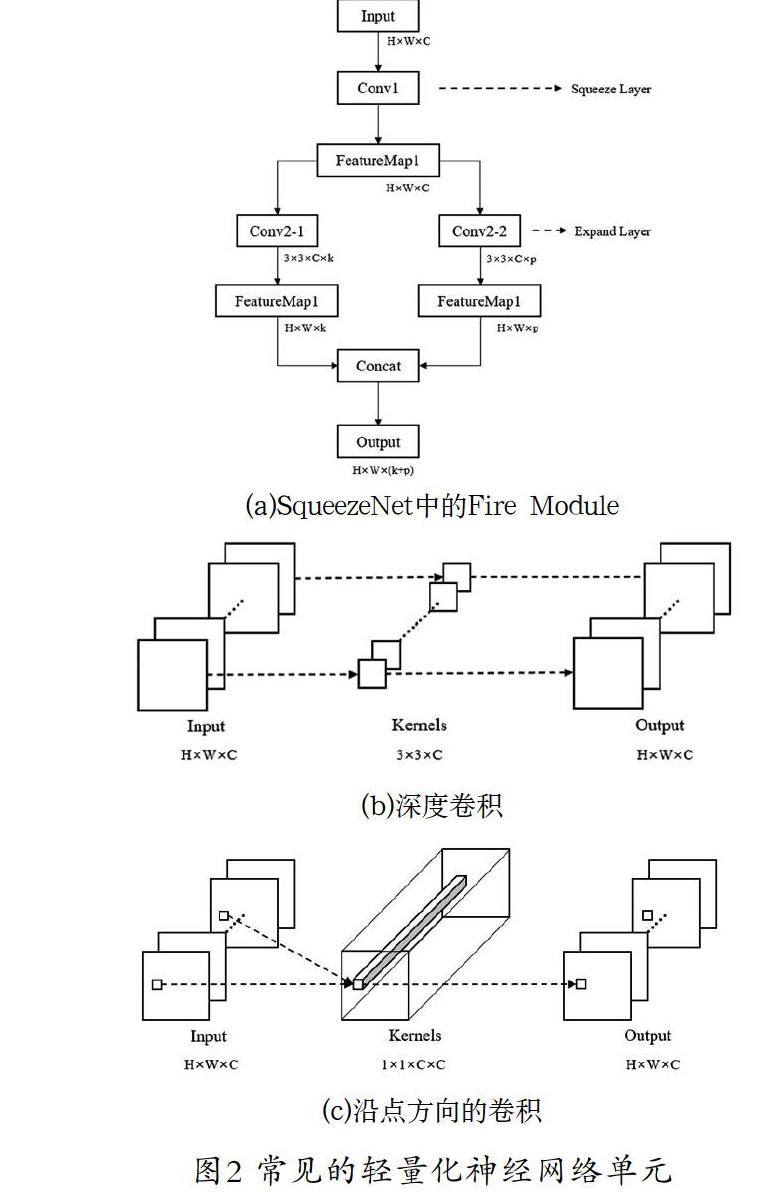
在神经网络结构设计(Network Architecture Design,NAD)域,在保证模型特征提取能力的前提下减少模型的计算量是重要的研究方向之一。常见的轻量化神经网络单元如图2所示。SqueezeNet[8]中设计了一种Fire Module结构,先使用1×1卷积将通道数降为输入的一半,然后再分别用一个1×1和3×3的卷积核对得到的特征图进行卷积操作,最后将这两层的结果整合之后输出。用该结构代替普通的3×3卷积核,不仅能够提升网络的特征提取能力,还能将参数量减少为原来的1/4。MobileNet[9]中使用Depth-wise Convolution和Point-wise Convolution替代普通的卷积核,前者对每个通道的特征图仅采用一个3×3的卷积核进行操作,整合单个通道特征图的空间信息;后者使用1×1的卷积核,整合单个位置多个通道之间的信息,从而在实现传统卷积功能的基础上,减少参数量的效果。
当模型设计和训练完成之后,通过分析每一层的参数,研究者们发现神经网络模型中有些层的参数对最终输出结果的贡献不大,所以可以使用剪枝算法删除这些贡献不大的参数或层,从而显著减小模型的体积,提升模型计算速度。剪枝算法中首先会利用L1、L2正则化等方式评价神经网络权重参数的贡献度,然后删除贡献度低的参数或层。这个过程会不可避免地带来模型精度的损失,因此剪枝后的模型需要重新训练。在上述过程中,如果单次剪枝掉过多的参数,会导致模型参数崩溃,需要通过重新训练恢复精度。因此通常情况下的剪枝操作是迭代进行的,即单次剪枝掉少量参数,重新训练之后再次评估参数贡献度,而后继续进行剪枝,直至模型参数减少到目标值。针对自然语言处理中常用的BERT模型,Michel等人[10]提出可以将模型中的多头注意力模块剪枝为单头注意力模块,McCarley等人[11]进一步通过剪枝操作将BERT前馈子层的宽度减小。以上方法都能实现模型的轻量化。
不同于剪枝算法迭代地降低模型参数,知识蒸馏方法先直接设计一个目标小模型,以该小模型为“学生”,以预训练的大模型为“教师”,构建Teacher-Student架构。通过使用数据真实标签(Hard Target)和教师模型的输出(Soft Target)构建损失函数以训练学生模型,能够使学生模型获得教师模型所学习到的“知识”,由此训练出的轻量化模型的性能显著优于直接使用数据真实标签训练得到的模型。在Tiny BERT[12]模型的训练过程中,研究者将预训练BERT模型的Embedding层、隐藏层和输出層分别蒸馏到小模型中,在保证模型在多项自然语言处理任务中表现稳定的前提下,推理速度提升了9.4倍。
在实际应用中,神经网络结构设计、剪枝和知识蒸馏三种方法通常被联合应用于模型轻量化任务。为了构建ALBERT[13]模型,研究者首先应用神经网络结构设计技巧搭建了轻量化的ALBERT模型,然后使用知识蒸馏方法将预训练的IB-BERT中的知识迁移到轻量化模型中,最后使用参数剪枝操作降低模型参数数量。轻量化的自然语言处理模型能够从根本上降低边缘计算设备的计算压力,从而保证对话机器人能够成功部署在智能终端上。
4 基于云+边缘协同计算的对话系统架构(Chatbot system architecture based on cloud + edge collaborative computing)
虽然边缘计算驱动的对话机器人部署技术已经较为成熟,但边缘设备的计算和存储能力依然无法和云端的服务器相比。在面对海量知识库检索等复杂对话任务时,云计算仍然有着无可替代的地位。因此本文结合边缘设备和云端设备的性能特点及对话机器人系统的业务特殊性,提出了一种云+边缘协同计算的对话系统架构。
在对话机器人的业务层面,可以将其业务分成封闭域问答和开放域问答两部分。封闭域问答是指对话机器人回复产品相关问题的功能,比如小爱同学会介绍小米相关产品的常见问题和进行新品推荐,淘宝客服机器人可以回答关于产品规格、发货时间和特价信息等问题。因为封闭域问答面向的应用场景较为单一,场景中涉及的高频对话语料是有限,所以语义解析和信息检索的难度相对较低,可以由智能终端直接生成回复。开放域问答的范围相对宽泛,与业务内容没有强关联的部分都可以定义为开放域问答。由于用户与对话机器人讨论的话题可能横跨多个领域,因此这意味着支持开放域问答的对话机器人背后需要有庞大的知识库作为支撑。如果想实现海量知识库中的知识检索和事实检索,就必然要使用云服务器的计算资源。因此在解决开放域问题时,智能终端只负责完成最开始部分的语义解析和文本分类任务,后续的回复生成交由云服务器完成。
综上,在云+边缘协同计算的对话系统架构(图3)下,用户输入问题后,智能终端会使用文本分类算法确认问题的类型(封闭域、开放域),然后使用语义解析算法提取问题中的关键信息。如果问题为封闭域问题,则由终端在本地知识库中检索答案并回复给用户;若问题无法解答或为开放域问题,则由终端上传到云服务器,由云服务器在大规模知识库下进行答案的检索。
此外,云端可以统计不同问题的交互频次,基于此动态更新保存在终端的高频对话语料库,保证终端能够尽可能地解答用户的高频问题,分担云端的计算压力。同时,终端可以利用空闲时间使用本地数据训练模型并发送给云服务器,云服务器借由安全多方学习等方法聚合来自多个终端的更新参数,获得新的精度更高的语义解析模型,并返回每个终端。数据和模型的更新提供了对话机器人持续成长的可能性。
5 结论(Conclusion)
本文从硬件、软件和算法三个层面论述了边缘计算技术应用于对话机器人部署任务的可行性。使用专用于深度学习模型推理的框架,驱动硬件架构中的GPU、NPU等高性能计算单元,执行经过轻量化设计的自然语言处理模型,使智能终端也能够完成自然语言处理任务,从而实现对话机器人的终端部署。
基于现有边缘计算技术和对话业务,本文提出了一个云+边缘协同计算的对话系统架构。在该框架下,部署在边缘设备上的对话机器人能够自主回答一定封闭域下的高频问题,部署在云端的对话机器人则负责回答终端无法回复的复杂问题。通过这种方式,边缘设备的计算资源能够得到充分的利用,云计算平台的网络负载和计算负载也会显著降低。
参考文献(References)
[1] 姚永剛.基于云计算的人机对话系统研究与实现[D].广州:华南理工大学,2013.
[2] 王浩畅,李斌.聊天机器人系统研究进展[J].计算机应用与软件,2018,35(12):1-6;89.
[3] 丁春涛,曹建农,杨磊,等.边缘计算综述:应用、现状及挑战[J].中兴通讯技术,2019,25(03):1-7.
[4] 李舟军,范宇,吴贤杰.面向自然语言处理的预训练技术研究综述[J].计算机科学,2020,47(03):170-181.
[5] 王湘新,时洋,文梅.CNN卷积计算在移动GPU上的加速研究[J].计算机工程与科学,2018,40(01):34-39.
[6] Lavin A, Gray S. Fast algorithms for convolutional neural networks[C]. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2016:4013-4021.
[7] 尹文枫,梁玲燕,彭慧民,等.卷积神经网络压缩与加速技术研究进展[J].计算机系统应用,2020,29(09):16-25.
[8] Iandola F N, Han S, Moskewicz M W, et al. SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and < 0.5 MB model size[DB/OL]. [2016-12-04]. https://arxiv.org/pdf/1602.07360.pdf.
[9] Sandler M, Howard A, Zhu M, et al. Mobilenetv2: Inverted residuals and linear bottlenecks[C]. Proceedings of the IEEE conference on computer vision and pattern recognition,2018: 4510-4520.
[10] Michel P, Levy O, Neubig G. Are sixteen heads really better than one?[C]. Advances in Neural Information Processing Systems, 2019:14014-14024.
[11] McCarley J S. Pruning a bert-based question answering model[DB/OL]. [2019-10-14]. https://arxiv.org/pdf/1910.06360.pdf.
[12] Jiao X, Yin Y, Shang L, et al. Tinybert: Distilling bert for natural language understanding[DB/OL]. [2019-09-24]. https://arxiv.org/pdf/1909.10351.pdf.
[13] Lan Z, Chen M, Goodman S, et al. Albert: A lite bert for self-supervised learning of language representations[DB/OL]. [2019-09-30]. https://arxiv.org/pdf/1909.11942.pdf.
作者简介:
马 壮(1994-),男,硕士,初级研究员.研究领域:深度学习,神经网络部署.
杨 威(1968-),男,本科,工程师.研究领域:云计算,软件架构设计.
