深度多分支模型融合网络的胡萝卜缺陷识别与分割
2021-04-02谢为俊郑招辉杨光照杨德勇
谢为俊,魏 硕,郑招辉,杨光照,丁 鑫,杨德勇
(中国农业大学工学院,北京100083)
0 引言
胡萝卜(Daucus carotaL.)是世界上主要的块根块茎类蔬菜,富含胡萝卜素、多酚及多种微量元素。中国胡萝卜产量最大且出口最多,2018年产量达2000万t,接近世界总产量的一半[1]。及时剔除缺陷胡萝卜有助于提高胡萝卜的市场竞争力,因此对胡萝卜的外观品质评价十分必要。传统的胡萝卜缺陷识别分拣具有劳动力消耗大、成本高、主观性强等缺点,而机器视觉识别技术具有快速无损、客观标准等优点,越来越多地应用于农业生产中,提高了农业生产现代化水平与生产效率[2]。
20世纪末,有学者开始利用机器视觉技术对胡萝卜外观进行评价。但限于当时的技术条件,机器视觉仅能识别胡萝卜的肩部与根部位置[3]、表面颜色缺陷[4]、部分形状缺陷[5]、根尖形状特征[6]等,且识别准确率低,鲁棒性差。随着机器视觉技术的飞速发展,研究人员开始利用先进的软硬件条件对胡萝卜分级进行深入研究。Hahn和Sanchez[7]开发了一种简单的算法,仅使用相距90o的两幅图像,就可以在不旋转相机的情况下准确预测胡萝卜的体积。许多学者设计了特定的图像处理算法对胡萝卜不同外观缺陷进行检测。韩仲志等[8]和Deng等[9]针对胡萝卜青头、须根、开裂、弯曲等不同缺陷分别设计了图像处理算法,平均检测准确率90%以上;Xie等[10]和谢为俊等[11]根据胡萝卜青头、弯曲、断裂、分叉和开裂等不同缺陷特点设计不同的图像处理算法,总体识别率达90%以上。上述图像处理算法可实现胡萝卜缺陷的检测,但存在准确率较低、算法复杂、鲁棒性差等缺点。
机器学习和深度学习技术在图像分类领域获得巨大成功,在农业生产领域也得到了大量应用[12],越来越多学者将其引入胡萝卜分级领域。Xie等[13]提取正常胡萝卜的12个特征作为反向传播神经网络(Back Propagation Neural Network, BPNN)、SVM、极限学习机(Extreme Learning Machine, ELM)的输入,将正常胡萝卜分为4个等级,分级准确率达96.67%,但该方法未涉及缺陷胡萝卜的分级研究。Zhu等[14]和倪建功等[15]利用深度学习对胡萝卜的黑斑、须根、弯曲缺陷进行检测,平均识别准确率达95%以上,但对胡萝卜外观影响更大的机械损伤、断裂、分叉、畸形和开裂等缺陷识别研究还未涉及。
缺陷胡萝卜通常用作动物饲料或直接丢弃,降低了胡萝卜种植效益。而分叉、开裂等缺陷胡萝卜可作为深加工原料,制作胡萝卜汁、胡萝卜粉等。但开裂胡萝卜开裂处会藏有泥土,清洗不彻底会影响胡萝卜制品质量,甚至导致食品安全问题,因此在深加工前对胡萝卜开裂区域进行修整十分必要。胡萝卜开裂区域的精准分割是实现开裂胡萝卜自动化修整的必要条件。韩仲志等[8]、Deng等[9]和谢为俊等[11]利用胡萝卜开裂区域与正常区域的颜色、纹理差异提取开裂区域,但提取精准度较差。因此对胡萝卜开裂区域的精准提取研究十分必要。
为更加全面地评价胡萝卜外观品质和开裂胡萝卜的自动化修整,本研究提出一种集缺陷识别与分割为一体的深度多分支模型融合网络(CS-Net)。该网络由胡萝卜缺陷识别分类网络C-Net和开裂区域分割网络S-Net组成,C-Net将ImageNet数据集上预训练的ResNet-50作为胡萝卜图像特征提取器,将提取的特征作为SVM的输入,得到不同的分类模型,再利用模型融合思想将不同分类模型融合得到最终的分类模型;S-Net将预训练的ResNet-50作为编码器,根据不同的分割网络构造思想设计解码器,构造胡萝卜开裂区域分割提取网络。该网络为胡萝卜外观品质评价和开裂缺陷修整奠定了基础。
1 材料与方法
1.1 试验材料
试验用胡萝卜购自绿龙食品加工有限公司(山东省潍坊市)。试验共包括7203幅胡萝卜图像,包括正常胡萝卜2109幅、断裂1424幅、开裂998幅、畸形665幅、机械损伤1029幅和分叉978幅,胡萝卜形态种类如图1所示。对于分类网络C-Net,每种形态胡萝卜随机选取80%作为训练集,20%作为测试集。训练集共包含5765幅图像,其中断裂、机械损伤、开裂、分叉、畸形和正常胡萝卜图像分别为1140、824、799、783、532和1687幅。因不同形态胡萝卜的图片数量不平衡,本研究在训练时采用分层5折交叉验证,保证每次划分中包含类别比例与原数据相同。测试集共包含1438幅胡萝卜图像,其中断裂、机械损伤、开裂、分叉、畸形和正常胡萝卜图像分别为284、205、199、195、133和422幅。对于分割网络S-Net,随机选取543幅开裂胡萝卜图像,按照6∶2∶2划分训练集、验证集和测试集。
1.2 图像获取及预处理
胡萝卜图像由彩色CCD相机(DFK-33UX265)采用8 mm镜头(The Imaging Source,Germany)获得。胡萝卜图像采集系统[11]如图2所示,该系统在光照箱中配置了两块互成120o的平面镜,胡萝卜放在两块镜子中间,上方的相机可同时捕捉到3幅胡萝卜图像,以尽可能多地获得胡萝卜表面图像,图像尺寸为1920×1080像素。图像处理算法和卷积神经网络(CNN)搭建基于Python 3.7、计算机视觉库OpenCv4.0.0和深度学习库Keras 2.3.1、Tensorflow 2.0.0。电脑配置为Intel corn Xeon 3.70 GHz CPU,128 GB运行内存,NVIDIA Quadro P2000(5 G)GPU,Windows 10.1操作系统。
图像预处理中,利用灰度直方图双峰法提取胡萝卜区域图像并删除背景[11]。为使胡萝卜图像不变形,将图像用0填充为尺寸1024×1024×3的图像,再利用线性插值算法将图像统一调整为适合CNN输入的尺寸(224×224×3)。为去除图像边缘高频噪声,提出一种基于圆形区域的均值滤波器,如图2a所示。
对于给定中心点(xd,yd),其邻域像素位置(xp,yp)由式(1)计算得到。
式中R为圆形滤波器半径,P为采样点总数,p为采样点序号。通过此操作得到的采样点坐标可能均不是整数,因此通过插值获得其位置的像素值,本研究采用双线性插值法,数学表达式如式(2)
式中f(xp,yp)为点(xp,yp)的像素值,f(ip,jp) (ip,jp=0,1)为点(xp,yp)相邻四点像素值。则中心点(xd,yd)像素值由式(3)计算
图像三维空间显示是将图像灰度值作为图像Z轴进行三维显示。
由图3b、3c使用圆形滤波器滤波前后胡萝卜图像的三维空间显示图可知,圆形滤波器对图像的高频噪声有很好的抑制效果。图像经预处理后,既去除了背景又将胡萝卜图像变为适合CNN输入的正方形图像,同时保证了胡萝卜无变形,保留了原始图像的拓扑结构,避免识别结果受胡萝卜变形的影响。
2 深度多分支模型融合网络
2.1 网络总体结构
本研究提出了一种集胡萝卜缺陷识别分类与开裂缺陷区域分割提取为一体的深度多分支模型融合网络(CS-Net),该网络由胡萝卜缺陷识别网络(C-Net)和胡萝卜开裂区域分割提取网络(S-Net)组成,总体结构如图4所示。ResNet-50包含的残差模块能够解决深度网络训练退化问题[16],大量研究表明残差网络是十分优秀的图像特征提取器[17-18],因此本网络以预训练的ResNet-50为基础,C-Net将ResNet-50作为图像特征提取器,输出不同层的卷积特征,将其作为SVM[19]的输入,训练得到不同的分类模型,再通过不同的模型融合策略(硬投票(Hard voting)、软投票(Soft voting)和Stacking法)将各个分类器融合为最终的胡萝卜缺陷识别网络。S-Net将ResNet-50作为分割网络的编码器,使用三种经典分割网络(U-net[20]、FCN[21]和SegNet[22-23])的构造思想设计分割网络的解码器,构造胡萝卜开裂区域分割提取网络。
2.2 缺陷识别网络(C-Net)
2.2.1 池化方法
池化层是CNN中重要组成部分,它能够实现图像特征下采样、去除图像冗余信息、简化网络复杂度从而减少模型的参数量。常见池化方法包括一般池化、重叠池化和空间金字塔池化(Spatial Pyramid Pooling,SPP)。在C-Net中采用的池化方法包括平均池化(Average Pooling,AVP)、全局平均池化(Global Average Pooling,GAP)和SPP。AVP如图5a所示,通过计算池化区域的平均值作为该区域池化后的值;GAP是平均池化的一种特殊形式,此时池化窗口尺寸与特征图尺寸相同;SPP将一个池化操作分成若干个不同尺寸的池化操作,用不同大小的池化核作用于上层的卷积特征,如图 5b所示。SPP能使任意大小的特征图转换成固定大小的特征向量,实现特征图的多尺度提取。图像卷积特征通过池化操作再经过全连接层后输出4096维数据,作为SVM的输入。
2.2.2 数据降维方法
通过CNN提取的特征维度较高,维度越高的数据在每个特征维度上的分布就越稀疏,这不利于机器学习模型的训练,因此对高维数据进行降维十分必要。本研究采用主成分分析(Principal Component Analysis,PCA)和Relief降维方法[24]。PCA通过某种线性映射将高维向量转为低维空间表示,并使得在所投影的低维空间上数据方差尽可能大。PCA具有使用较少的数据维度,保留尽可能多的原数据信息。ReliefF是一种基于特征权重的特征选择算法,其设计了一个“相关统计量”来度量特征的重要性,该统计量为向量,它的每个分量是对其中一个初始特征的评价值。特征子集的重要性就是子集中每个特征所对应的相关统计量之和,因此这个“相关统计分量”也可以视为是每个特征的“权值”。指定阈值,选择大于阈值的相关统计量分量所对应的特征。
本研究中,PCA降维后数据维数分别为256、500、1000、2000;ReliefF方法中K近邻参数k的取值为150,阈值选择为0.05。
2.2.3 SVM训练
将ResNet-50输出的特征向量作为SVM的输入,使用非线性映射算法,通过核函数在高维空间中找到最优超平面H,使样本变得线性可分,实现胡萝卜不同缺陷种类的正确识别。超平面H可用ωTx+b表示,样本空间中任一点x到超平面的距离γ可由式(4)计算
式中ω是超平面H的法向量,b为超平面H的截距。
本研究中,选择径向基函数(Radial Basis Function, RBF)作为SVM的核函数,惩罚系数为0.5,停止训练时的误差值为10-3,多分类方式采用一对一形式(ovo)。
2.2.4 模型融合策略
模型集成学习策略已经在农业领域得到广泛的应用[25-26]。传统CNN使用单一的分类模型[27],但不能适应胡萝卜的所有特征。集成学习思想则是利用训练数据首先得到一组基模型,再利用模型融合策略将他们组合起来。集成学习综合各个基模型的优点,往往可获得比单一模型更显著的性能[26]。本研究由ResNet-50的第1、10、22、40、49层输出特征作为输入训练得到5个支持向量机(SVM)模型作为基模型。在此基础上,利用硬投票、软投票和Stacking集成方法,得到最终胡萝卜缺陷分类模型。本研究所采用的三种模型融合策略执行步骤如下:
1)硬投票,又叫相对多数投票法。首先获得5个基模型在测试集上的预测类别Ci(i=0, 1, 2, 3, 4),然后统计5个基模型输出结果中每个类别的票数,最终输出结果为得票最多的类别。当票数相同时,则随机选择一个类别作为最终输出结果。
2)软投票,又叫加权平均法。首先获得5个基模型在测试集上的每个类别的预测概率pri(i= 0,1,2,3,4),再利用式(5)计算出每个类别融合后的预测概率。
式中N为分类器个数,ki根据各分类器在测试集上的准确率排序确定,准确率最高的ki=5,最低的ki=1。
3)Stacking集成方法由两级分类器构成,其中低级别的模型称为基模型,高级别的称为元模型。本研究中低级别模型所用分类器为SVM,高级别模型所用分类器为梯度提升决策树(Gradient Boosting Decision Tree, GBDT)[25]。本研究中GBDT算法的学习率为0.01,最大迭代次数为150,树的深度为10。具体训练步骤如下(图6):①将胡萝卜图片数据集根据4∶1划分为训练集与测试集,数据集在经过ResNe-50网络特征提取,分别输出第1、10、22、40和49层的训练集(it=1, 10, 22, 40, 49)和测试集数据(it=1, 10, 22, 40, 49)。②将第1层输出的训练集数据利用5折交叉验证的方法随机均等划分为5个子集D1、D2、D3、D4、D5,依次选取其中一个子集Div(iv=1, 2, …, 5)作为验证集,其他4个作为训练子集③将D-iv作为SVM的训练集,Div作为验证集并输出验证集的预测结果aiv,同时对原始测试集进行预测,输出预测结果biv。④对(3)循环5次得到{a1,a2,a3,a4,a5},将这5次结果按列合并得到和标签Y相同长度的向量A1,对测试集预测值{b1,b2,b3,b4,b5}取平均值得到和标签Y相同长度的向量B1。⑤对另外四个数据集(第10、22、40、49层输出特征)执行上面步骤得到由原始训练集(it=10, 22, 40, 49)产生的A10,A22,A40,A49和原始测试集(it=10, 22, 40, 49)产生的B10,B22,B40,B49。⑥将A1,A10,A22,A40,A49和原始训练集DitTrain的标签Y合并得到新样本数据{(A1,A10,A22,A40,A49),Y}作为二级分类器GBDT的输入特征,{(B1,B10,B22,B40,B49)}作为GBDT测试集生成最终结果。
2.3 分割网络(S-Net)
为了对胡萝卜开裂缺陷区域进行自动化修整,本研究将ResNet-50作为编码器,设计分割网络的解码器实现对胡萝卜开裂区域的精准提取。
2.3.1 构造方法
全卷积神经网络[21](Fully Convolutional Network,FCN)是最早的分割网络,它将CNN全连接结构用卷积结构代替,将原本输出的一维向量改为二维特征图的形式,保存了图像的二维信息。利用反卷积操作对特征图进行上采样,并将编码器相应尺度的特征图复制过来与上采样后的特征图进行对应像素相加(Add),再通过卷积操作组合特征后输入下一个反卷积层,如图 7a所示。U-net分割网络[20]为了使网络在上采样的过程中获得更多信息,恢复图像更多细节,将编码器对应尺度特征图与反卷积后相同尺寸特征图进行级联(Concat),再通过卷积操作后作为下一个反卷积层的输入,如图7b所示。SegNet[22]为了解决网络编码器在池化操作时丢失位置信息的问题,在编码器执行最大池化操作时,将特征最大值的位置作为最大池化索引保存。网络解码器在上采样的时候根据最大池化索引直接恢复图像特征值,如图7c所示。本研究将ResNet-50作为分割网络的编码器,分别根据FCN、U-net和Segnet网络构造思想构造网络的解码器并将ResNet-50第1、10、22、40、49层输出特征尺寸作为解码器的反卷积后特征尺寸。
2.3.2 损失函数
损失函数的选择会直接影响分割网络的分割效果,交叉熵损失函数(Cross Entropy loss)[28]、骰子系数差异函数(Dice loss)[29]、焦点损失函数(Focal loss)[30]是分割网络常用的损失函数。交叉熵损失函数主要是用来判定实际输出与标签的差异,网络即可利用这种差异经过反向传播去更新网络参数。该损失函数在分割网络中分别评估每个像素的类预测,然后对所有像素求平均,这对于类别数据不均衡时效果较差。骰子系数差异函数是一种集合相似度度量函数,用于计算两个样本之间的相似度,适用于样本不均的情况,但是会对反向传播造成不利的影响,造成训练波动大。Lin等[30]提出焦点损失函数用于解决上述两种激活函数存在的问题,焦点损失函数是动态缩放的交叉熵损失函数,通过增加动态缩放因子,实现在训练过程中动态调整简单样本的权重,让模型快速关注于困难样本的分类,由式(6)计算得到。由于本研究中胡萝卜开裂区域在图像中占比较小,因此本研究选择焦点损失函数作为分割网络损失函数。
式中pr是类别预测概率,y是标签值,β是动态缩放因子。
2.3.3 分割网络性能评价指标
为了衡量分割网络的性能,需要经过标准、公认的指标进行评估。目前常用指标包括分割网络模型尺寸、分割时间、准确率[31],其中准确率包括PA、MPA和MIoU。PA是最简单的度量标准,只需计算正确分类的像素数量与像素总数之间的比率;MPA是改进的PA,按类计算正确像素的比率并取平均;MIoU是实际区域和预测区域的交集和并集之间的比率,作为分割网络的标准度量。
式中k为分割目标类别数,pii表示分类正确的像素数,pij表示i类被误判断为j类的像素数,pji表示j类被误判断为i类的像素数。
3 结果与分析
3.1 卷积层特征、池化方法与数据降维方法对模型性能的影响
表1为ResNet-50不同层(1、10、22、40、49)输出特征在不同池化方法和不同数据降维方法下训练的SVM模型的性能。准确率为模型在分层5折交叉训练下验证准确率的平均值。
由ResNet-50不同层输出卷积特征训练的模型性能各不相同。由表1可知,同样的池化和降维方法,高层网络(40、49)输出特征训练的模型准确率比低层(1、10、22)的高。为解释该现象,将ResNet-50模型的第1、10、22、40和49层输出特征进行可视化,如图8所示。由图可知,ResNet-50网络第1、10、22层输出特征更多的是图像的一般特征(边缘、纹理、色彩等),而第40和49层输出特征则是图像高层语义特征,其将图像特征抽象为更加容易区分的特征,因此高层网络(40、49)输出特征训练的模型准确率要比低层(1、10、22)的高。

表1 卷积特征、池化方法与数据降维方法对模型性能的影响 Table 1 Effects of convolution feature maps, pooling method and dimensionality reduction methods on model performance
不同池化方法对模型性能影响不同。由表1可知,在低层特征下不同池化层的模型性能从大到小排序为SPP、AVP、GAP,这可能是因为SPP有3个不同尺寸的池化核对卷积特征进行提取,因而可以在不同尺度上提取卷积特征,在某种程度上使用SPP相当于额外增加了1层卷积层,所以在低层特征的基础上可以抽象出更高层次的特征,因此采用SPP的模型性能最好,在第1层卷积特征上准确率达到84.07%,比采用AVP的准确率高出近10个百分点;AVP使用的池化核尺寸小于低层卷积特征尺寸,使用窗口滑动法在卷积特征上依次滑动提取特征,而GAP的池化核尺寸与低层卷积特征尺寸相同,所以在相同的低层卷积特征上AVP提取的特征要远远多于GAP,这就导致了使用AVP的模型性能要高于采用GAP的模型。在高层语义特征下不同池化层对模型性能影响较小,因为高层卷积特征图尺寸较小,包含的信息数据量少,用不同的池化方法提取得到的特征差别小。在第49层卷积特征下,采用SPP的模型性能略差于采用其他两种池化方法的,因为第49层输出的卷积特征尺寸只有7×7,使用SPP会额外提取到冗余的信息,从而降低模型性能。此时的AVP与GAP的池化核尺寸相同,因此采用GAP与AVP的模型性能表现一致。
在机器学习中,对数据进行降维处理是必要的。对数据进行降维处理不仅能减少特征数量还会提高模型的性能。由表1可知,PCA在卷积特征上对模型性能影响比ReliefF法更明显,可能是因为该方法能更有效地剔除经过池化层提取后特征包含的冗余信息。从表1中也可以看出,一些模型在降维后性能下降,原因在于降维过程中不可避免地去除了一些对分类结果有积极意义的数据,从而影响了模型性能。
3.2 不同分类模型的性能比较
为进一步提升模型的分类精度,本研究采用模型融合的思想对模型进行集成学习。根据表1,在保证融合后模型包含图像多尺度特征,本研究最终选择的基模型L1、L2、L3、L4、L5分别为ResNet-50第1、10、22、40、49层输出卷积特征训练的SVM模型,池化方法、降维方法如表2所示。采用硬投票、软投票、Stacking方法分别得到3个不同的元模型,各模型在测试集上的准确率排序为硬投票<软投票<Stacking方法。硬投票以简单的少数服从多数原则,对模型的性能提升不明显。软投票根据各个分类器在验证集上的准确率排序给予不同的权重,使得表现更好的模型在最终的预测输出中占有更大的比重,因此软投票方法对模型提升作用大于硬投票方法。Stacking方法则是利用各模型在验证集和测试集上的预测结果作为新的训练集和测试集训练二级分类器,它能以任意函数形式逼近真实值,因此Stacking法所获得的模型在测试集上的精度最高,达98.40%,相比单一分类器性能提升了3个百分点以上。传统的HOG+SVM和LBP+SVM模型性能仅相当于第1层卷积层提取特征模型L1的性能,说明CNN自动提取特征优于人工手动提取特征。
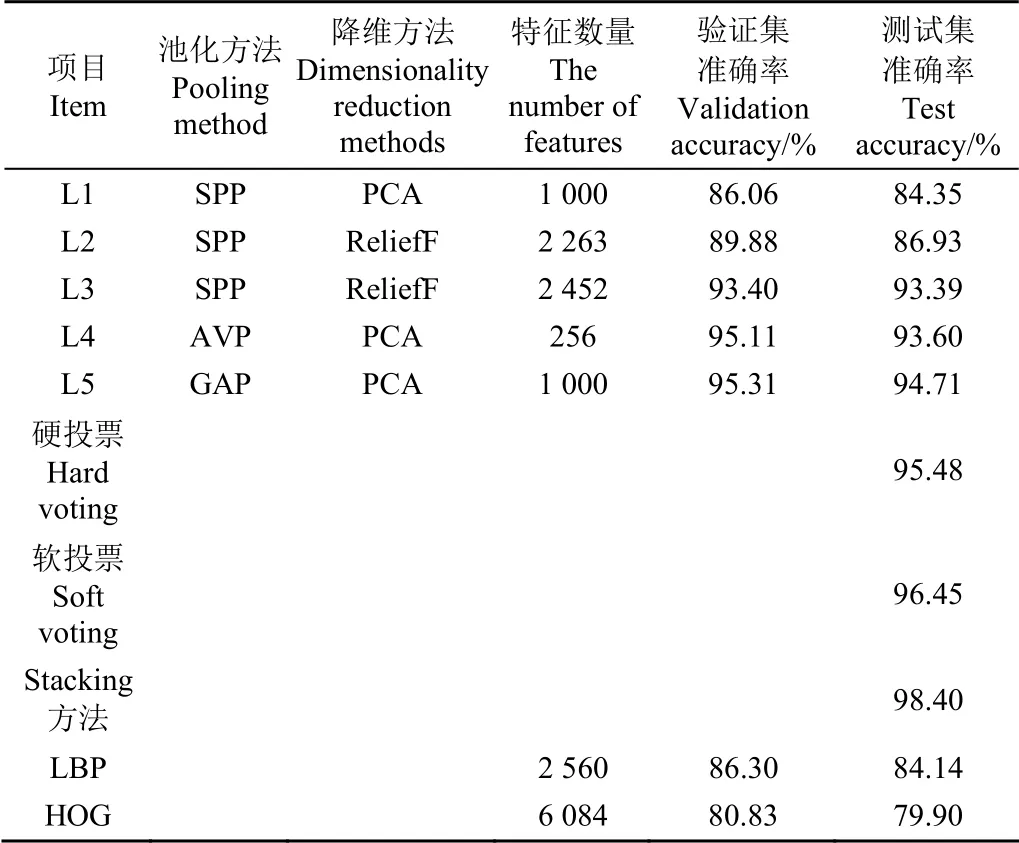
表2 模型性能比较 Table 2 Performances comparison of different models
计算由Stacking方法获得的模型在测试集上的混淆矩阵,由图9可知,模型共正确识别出断裂、机械损伤、开裂、分叉、畸形和正常胡萝卜分别为278、203、195、194、127和418幅,识别率分别为97.89%、99.02%、97.99%、99.49%、95.49%和99.05%,总体识别率为98.40%,表明融合后的模型可以正确区分各缺陷的类间差异与类内差异,但误识别情况依然存在,因为所有的图片并不都是完美的,存在一些不可避免的瑕疵。
3.3 不同方法构造的分割网络性能比较
本研究以ResNet-50为编码器,分别以FCN、U-net、Segnet思想构造出3种不同的解码器,得到3种分割模型Res-FCN、Res-U-net、Res-Segnet。由表3可知,Res-U-net综合表现最好,在测试集上的PA、MPA、MIoU分别为98.31%、96.05%、92.81%,且模型最小,为0.24G,单幅图像分割时间为0.72 s。Res-FCN的表现略低于Res-U-net,但其模型大小达到1.5 G,不适合配置较低的设备使用。Res-Segnet的表现最差,MIoU仅为88.68%,但其模型尺寸相比Res-FCN减少了78%,原因在于Res-Segnet复制了编码器的最大池化索引,而Res-FCN则是复制了编码器特征,因此在内存占用上Res-Segnet比Res-FCN更高效。为更好地说明本研究设计的网络模型的先进性,将其与目前先进的分割模型DeeplabV3+[32]进行比较,Res-U-Net的PA、MIoU与DeeplabV3+的相当,而MPA优于DeeplabV3+,模型大小仅为DeeplabV3+的一半,单幅图像分割速度快于DeeplabV3+,说明本研究设计的网络结构可以快速分割出胡萝卜开裂区域。
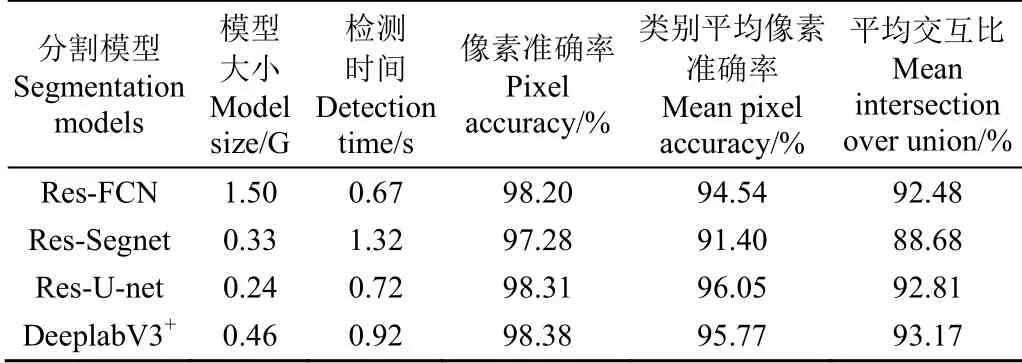
表3 不同分割网络的性能 Table 3 Performance of different segmentation models
3.4 Res-U-net训练过程
Res-U-net模型训练时损失函数为焦点损失函数,α,β分别为0.25和2,优化器选择为Adadelta,不预设学习率。Res-U-net模型在训练集和验证集上的准确率、损失如图 10所示。由图可知,Res-U-net模型在前50轮训练的时候,准确率快速上升、损失值迅速下降,250轮训练以后模型准确率和损失趋于稳定,经过300轮训练后,在验证集上的准确率和损失分别为98.40%和0.072,说明设计的网络结构、选择的损失函数和优化算法可以使模型快速收敛,达到较高的准确率和较低的损失。
3.5 模型分割结果可视化比较
为更直观比较Res-U-net、Res-FCN、Res-Segnet模型的分割效果,在测试集中随机选取4幅面积、位置不同的开裂区域图像,将不同模型的分割效果可视化,如图 11所示。由图可知,Res-U-net的分割效果最接近于原始标记结果,Res-FCN分割区域边缘存在明显的锯齿状,Res-Segnet分割区域比原始标记区域小,且存在空洞现象。原因在于Res-FCN通过上采样卷积层生成比较粗糙的分割图,而Res-U-net和Res-Segnet在网络中引入跳跃连接生成边缘平滑的分割图。由Ⅰ、Ⅲ可知,Res-U-net分割效果均接近于原始标记图,表明Res-U-net分割效果不受开裂区域面积大小的影响。由Ⅲ、Ⅳ可知,Res-U-net对胡萝卜不同位置的开裂缺陷均有较好的分割效果。由Ⅱ可知,Res-FCN、Res-Segnet、Res-U-net均未将胡萝卜的周向凹陷分割为开裂,说明这些模型均很好地学习到了胡萝卜开裂区域特征。综上,Res-U-net模型分割精度高、鲁棒性强,可作为胡萝卜开裂区域自动分割模型。
4 结论
1)本文提出了一种集胡萝卜表面缺陷识别与开裂区域分割为一体的深度多分支模型融合网络,在自制的胡萝卜表面缺陷数据集上,实现了胡萝卜不同表面缺陷识别和开裂区域分割提取。
2)以预训练的ResNet-50为胡萝卜图像特征提取器,分别输出ResNet-50的第1、10、22、40、49层特征作为支持向量机(SVM)的输入,得到5个不同的分类模型。随着网络层数的增加,模型准确率不断提高,第49层输出特征训练的模型准确率最高,测试准确率为94.71%。
3)为提高胡萝卜缺陷识别分类模型的准确率,采用硬投票、软投票和Stacking方法对5个分类模型进行融合得到的3个融合模型,其准确率从小到大排序为硬投票、软投票、Stacking方法,Stacking融合方法得到的模型准确率最高为98.40%。
4)以预训练的ResNet-50为编码器,根据FCN、U-net、Segnet网络的思想构建了多个胡萝卜开裂区域分割模型。结果表明Res-U-net分割模型综合性能最好,其像素准确率、类别平均像素准确率、平均交互比为98.31%、96.05%、92.81%,模型尺寸为0.24 G,单幅图像分割时间为0.72 s。
本文提出的深度多分支模型融合网络能够准确识别出胡萝卜表面缺陷类型,并精确地分割提取出胡萝卜开裂区域,为后续更加全面地评价胡萝卜表面质量和开裂胡萝卜的修整奠定了基础。
