高光谱影像子空间分析孤立森林异常目标探测方法
2021-04-01黄远程薛园园李朋飞
黄远程,薛园园,李朋飞
西安科技大学测绘科学与技术学院,西安 710054
遥感中的异常信息通常以低概率的形式出现在地表环境中,且与周围环境存在光谱或空间属性上明显差异[1-2]。异常目标检测被认为是一个二分类问题,它将待测像素分为异常类或背景类[3],它的特点是在背景和异常目标无先验知识的情况下识别出感兴趣目标[4-5]。而高光谱图像具有数百个光谱波段,为每个像素提供了丰富的光谱信息,这一优势使其成为异常目标检测最有价值的遥感手段[6-7],比如利用高光谱影像检测海洋环境背景下的船舶溢油[8]和机场的飞机,发现地表的矿物[9]等。
异常目标检测有两类代表性的方法:①基于统计模型的异常检测,这类方法假设背景服从特定的概率分布,而背离该概率分布的样本则为异常。其中,应用最为广泛的是RX算子[10-11],它建立在背景服从高斯分布假设的基础上,通过计算待探测像素与背景的马氏距离来判断像素点是否属于异常目标。但由于背景并不一定简单地服从单一的高斯分布,故而产生较高的虚警率。局部RX算子则在背景的协方差与均值估计时容易受潜在的异常信号影响。②基于误差重建的异常检测,这类方法不对背景的概率分布做一般假设,而是采用构建背景字典来对待检测像元进行重构[12-13],以重构误差来反映异常。但该方法多以线性稀疏表达为主,无法有效地处理线性不可分问题;此外字典构建是关键,全局字典依赖于非监督学习算法获得,局部字典则由局部邻域像素构成,局部构建的字典也易受可能的异常像元影响[14]。
与上述方法不同,孤立森林(isolation forest,iForest)异常检测定义异常样本为分布稀疏且易被孤立的离群点[15],如图1(b)点x0。iForest在子采样的基础上使用随机超平面切割特征空间来构建孤立树(isolation tree,iTree),如图1(a)中正常的样本点xi需多次切割到达更深的树叶节点上才能被孤立;图1(b)中异常点x0只需较少的切割次数就能够被孤立,它靠近孤立树的根部,有较短的路径长度。t个iTrees组成iForest,然后用生成的iForest来评估测试数据,iForest中具有短的平均路径长度的点被识别为异常,而这个异常度值是通过将森林里的所有树用集成的方法计算得到的。它为解决异常检测问题提供了一个新的视角,即不需要对背景概率分布做出假设,且具有集成多种不同特征的优势。但孤立树的构建将决定着iForest模型异常检测的性能。特别的,若将iForest直接应用于高维高光谱遥感影像进行异常检测,则容易出现两个主要的问题:①遥感影像中地物复杂,对输入特征进行随机阈值剖分时不易有效的区分背景与目标;②仍有重要的光谱特征易在建完树后没被使用[16-17]。这是因为高光谱影像波段众多且相邻波段之间相关性大,iTrees的每一个结点对应的特征均采用随机的方式定义,无法有效地保证具有区别能力的关键特征被选中。
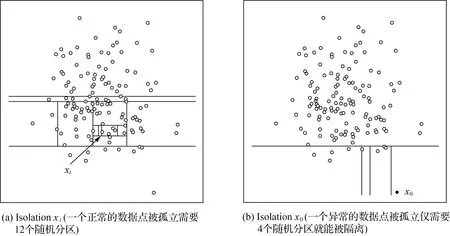
图1 孤立森林对特征空间中数据点切割Fig.1 Schematic diagram of data point cutting in feature space
为了利用iForest求解异常目标问题的优势,同时克服其直接应用于高光谱影像分析的困难,本文提出了一种子空间分析孤立森林异常目标探测方法,其总体流程如图2所示。针对问题①,采用正交子空间分析[18]技术增强输入特征影像中潜在异常目标与背景之间的对比度,以减少背景的干扰;针对问题②,对增强的目标特征影像利用主成分分析方法将其投影到一个低维子空间进行降维[19],从而降低维数过高给iForest算法带来的不确定性;在此基础上,采用在整幅图像中随机采样的方式来构建孤立森林获得初步检测结果,称之为全局iForest异常检测;最后利用滑动窗口进行局部的iForest异常检测来细化初始异常检测结果,得到最终的异常分布。
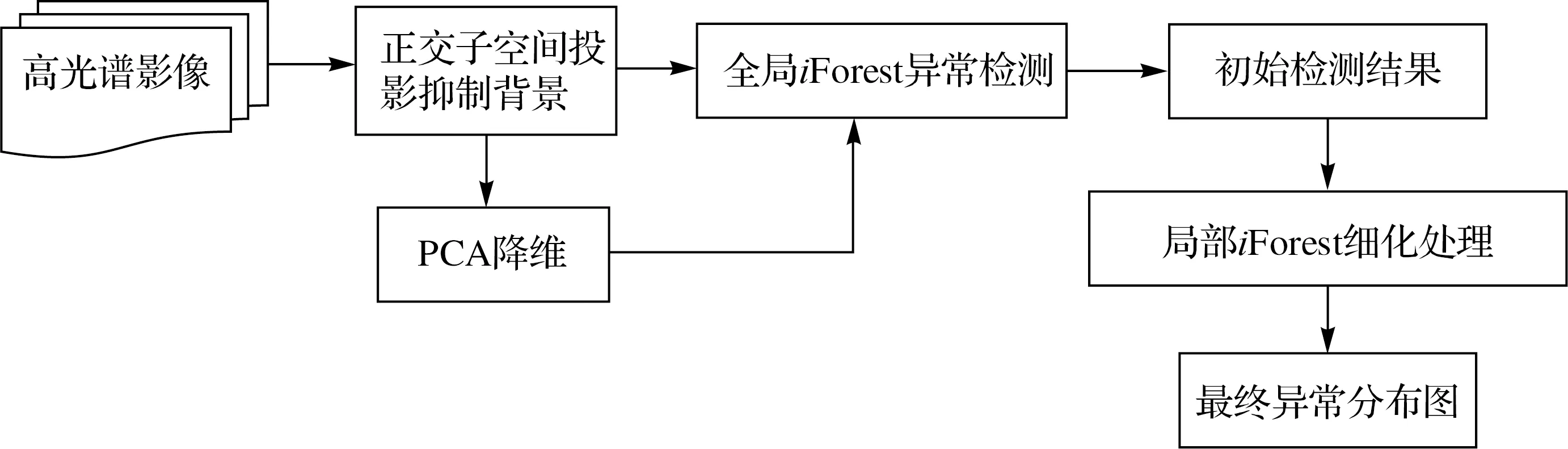
图2 基于子空间分析的iForest异常目标检测流程Fig.2 iForest anomaly detection flowchart with subspace analysis and global-local processing
1 本文方法
1.1 正交子空间抑制背景类信息
假设r∈RL×1为L维高光谱图像的任意像元,根据正交子空间分析理论,假设目标子空间为S∈RL×c,背景子空间U∈RL×k,它们构成了影像的特征空间,则图像的每个像元可由目标子空间S和背景子空间U进行线性表达,其中c和k分别是目标子空间和背景子空间的大小。如式(1)所示
r=Sα+Uγ+ε
(1)
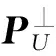
(2)
然后将其乘以每一个像元矢量如式(3)
(3)
即像元向量投影于背景的正交子空间中,这样消除了式(1)的第2项,使得与U相关的背景信息被抑制后仅剩下目标相关的信息。这一思想称为高光谱影像正交子空间投影(OSP)的分析[20]。
本文采用两种方法定义式(1)的U,分别为主成分特征子空间法和典型类判别特征子空间法。这两类方法定义的背景子空间和目标相关子空间符合式(1)的线性模型。
(1) 主成分特征子空间法:假设[U1,U2,…,UL]为高光谱影像的主成分特征向量,其对应的特征值由大到小排列[21]。由于异常目标在影像中分布稀少,其信息主要表现在较小特征值对应的特征中,故可定义背景子空间为最大的k个特征值对应的特征向量组成,即U=[U1,U2,…,Uk]。
(2) 典型类判别特征子空间法:首先对高光谱图像进行k-means聚类[22],统计聚类后的每一类像元数的占比,并定义预估异常像元占比δ,将像元数量占比大于这个值的类视为正常类或称背景类。接着采用Fisher判别分析[23],最小化类内散度和最大化类间散度,对所有的k个背景类样本进行判别分析计算,得到的判别特征向量组成背景子空间U=[U1,U2,…,Uk-1]。
1.2 背景正交子空间增强变换的孤立森林异常检测
结合正交子空间分析的特点和经典的iForest算法提出如下计算方法。首先采用主成分特征子空间法或典型类判别特征子空间法估计得到的背景子空间对输入图像进行正交子空间投影,从而抑制背景,增强目标,使主要的信息与异常相关;为降低因高光谱影像维数过高给算法带来的风险,接着对输入的特征继续采用主成分分析进行降维处理,使主要的异常信息集中在几个主成分中。在此基础上利用iForest对主成分特征影像进行训练和对待检测样本进行测试。具体的训练和测试方法如下。
(1) 训练阶段是建立孤立森林。假设孤立树iTree的数目为t,由t棵iTree构成孤立森林iForest。iTree的建立是通过对训练集的递归分割来建立的,递归分割结束的标志是所有的样本被孤立,或者树达到了指定的高度。假设树的高度限制为l,l与子样本数量n的关系为l=ceiling(log2(n)),近似等于树的平均高度。以下为树的构造过程。
Step1:从被背景子空间抑制后的高光谱影像中随机选择n个样本作为子样本集,X={x1,x2,…,xn},样本的特征维数d是主成分分析降维后的特征维数。
Step2:为了构建一棵孤立树,需要从d个特征中随机选择一个特征q及其分割值p,p值介于该特征的最小值和最大值之间,与经典的iForest不同在于p对输入特征的随机剖分能更容易区分背景与目标像元。
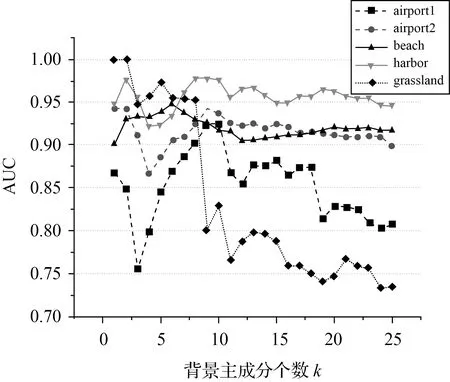
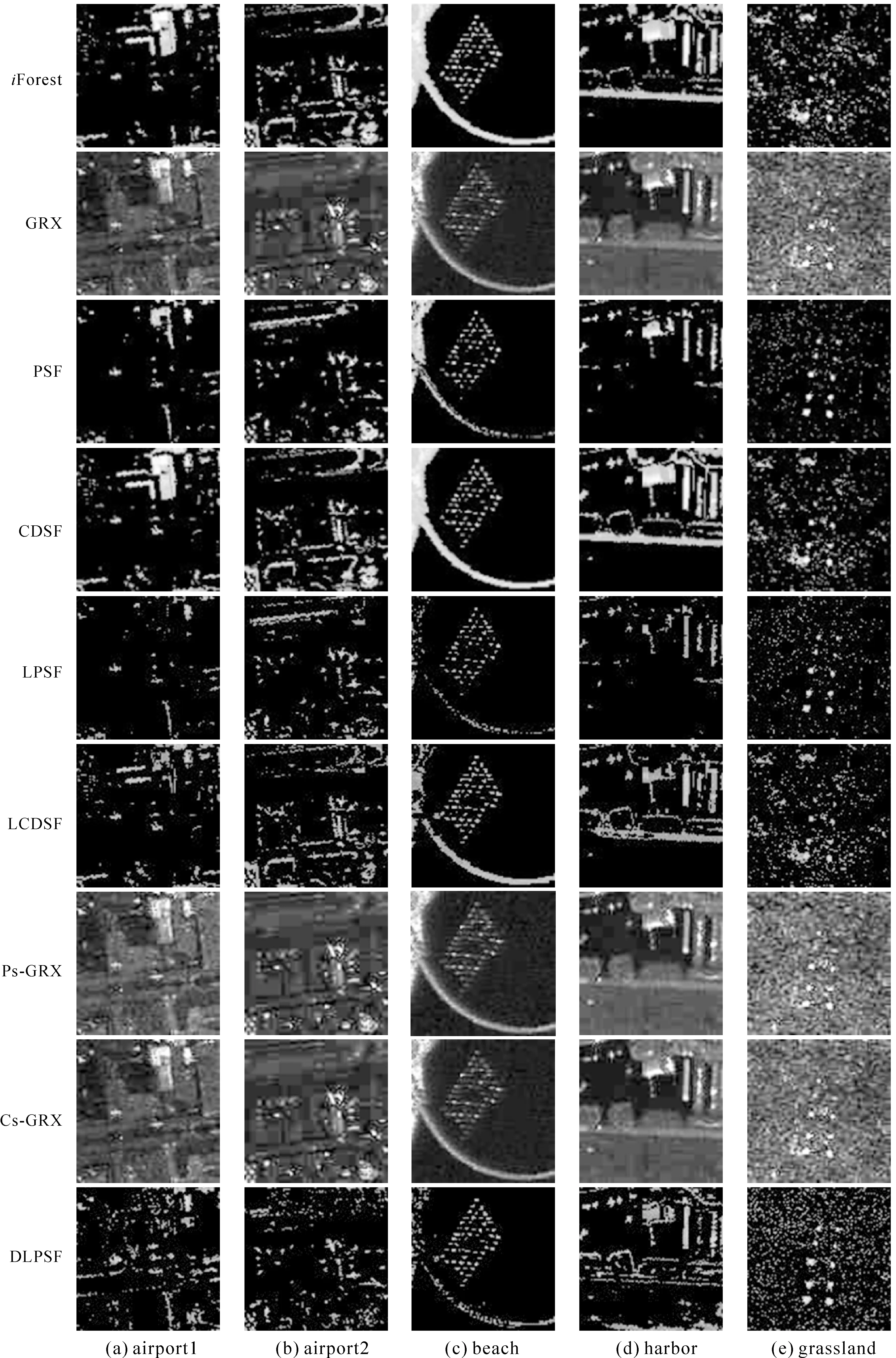
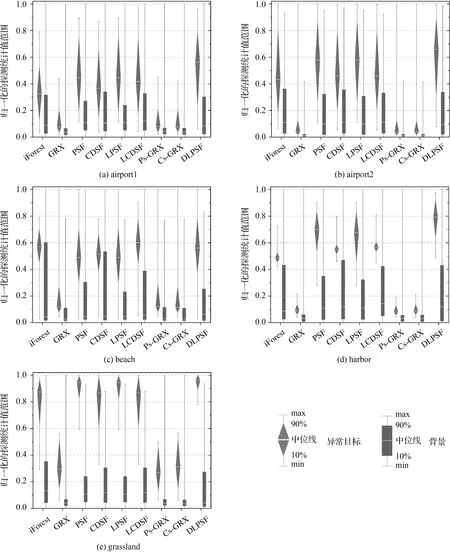
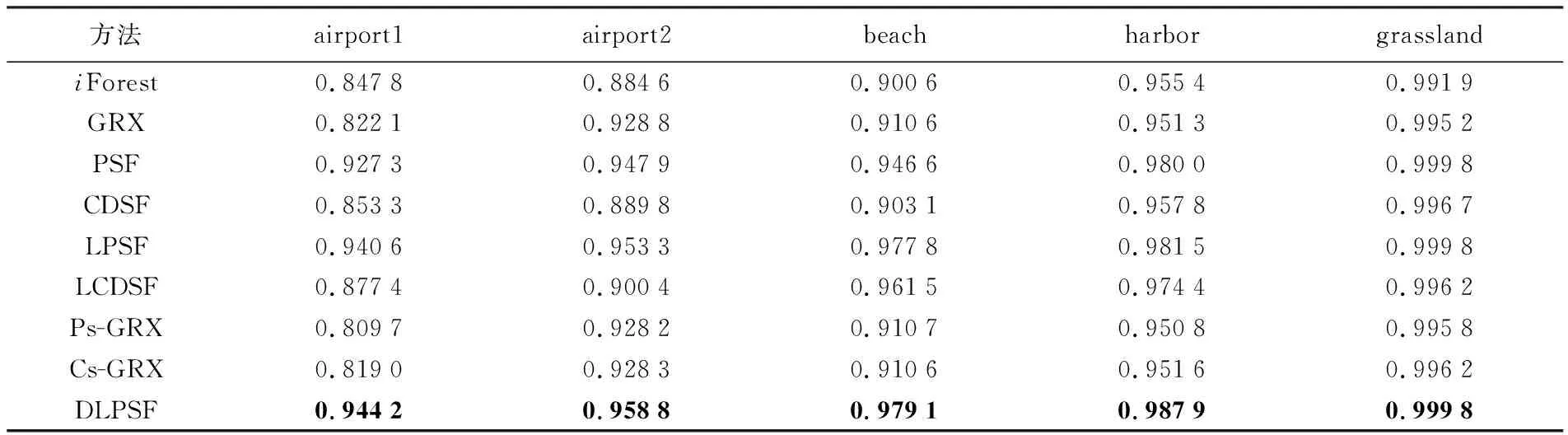
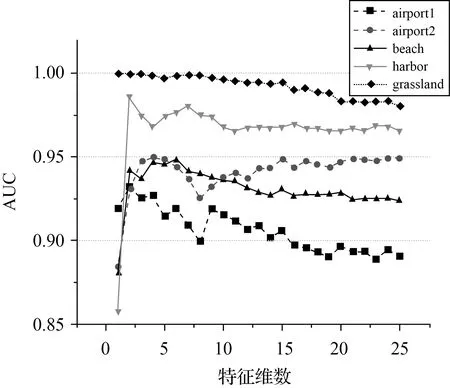
Step3:假设T是孤立树的一个节点,它要么是没有子节点的叶子节点,要么是只有两个子节点(Tl,Tr)的内部节点,每一步分割,都包含特征q和分割值p,对特征q的任一样本qi,若其满足qi Step4:子节点递归的重复Step2和Step3,直到树的高度达到了限制值l或节点上的样本都相同。 (2) 测试阶段计算待检测样本的异常值。每一个测试样本x(x∈Rd×1)的异常值由期望路径长度E(h(x))表达得到,树的路径长度h(x)表示样本x从iTree的根节点到叶节点过程中经过的边的数目。为了便于评价异常值,对E(h(x))采用归一化处理(4)来定义最终的异常分值 S(x)=2-E(h(x))/C(n) (4) 式中,C(n)是n个样本构建二叉树的平均路径长度,定义如式(5) C(n)=2H(n-1)-(2(n-1)/n) (5) 式中,H(·)为调和函数,用ln(·)+0.577 215 664 9(欧拉常数)估算。对高光谱影像中的每一个像元均进行上述步骤,得到异常检测结果图D∈Rh×w,h和w分别为影像的行数和列数。 异常值0 影像中亮度值比较大的像元具有离群的特点,易被误检为异常。这类地物与感兴趣的异常目标不同在于它们往往成面状或线状。为了消除其对异常的影响,采用二次iForest计算,称之为局部iForest细化处理,其实质是在局部范围内再进行一次iForest异常检测,并将1.2节的处理结果称为初始异常检测结果。具体步骤如下。 (1) 二值化:将初始的异常检测结果图D转换为二值化图像B∈Rh×w (6) 式中,阈值s由Otsu[24]算法确定;Bi和Di分别为B和D对应的像元。 (2) 基于分块分析的iForest异常检测:对二值图像进行形状分析,找出二值图像B的所有连通分量,并计算连通分量内的像元数。接着对图像进行分块,相邻块之间设置一定的重叠度。评估每一个块内最大的连通分量的像元数与块内像元总数的比值θ,如果该值大于给定的阈值,则在块内构造一个局部iForest来重新定义该窗口中像素的异常分数,并以此值代替全局值。不失一般性,本文设置的图像块的大小为20×20,块间重叠度为4个像素,比值θ的阈值设置为0.3。若相邻块均有局部操作,则重叠区域的异常分数取相邻块的异常分数的平均值。 利用5组高光谱数据集来验证本文方法的性能,如图3(a)、(b)、(c)和(d)为4幅分别命名为airport1、airport2、beach、harbor的AVIRIS高光谱传感器获取的影像[25],4幅影像进行目标检测前去掉了水吸收波段和信噪声比低的波段;图3(e)是用具有46个波段的CRI高光谱成像仪[26]获取的真实高光谱数据影像(grassland),图3中的二值图像为影像中对应的目标分布的参考图。各数据的场景特点和目标空间分布相关信息描述如表1,比如图3(a)为机场环境下有13架飞机目标,异常像元个数为144个。 根据采用的背景子空间估计方式的差异,以及是否进行主成分分析降维处理,对异常检测方法有不同形式的实现。主成分背景子空间变换iForest异常检测,记为(PCA subspaceiForest detector,PSF),即背景子空间由主成分特征子空间法构造,影像经正交子空间背景抑制后,各像元的异常值的计算由全局iForest计算得到;局部细化的PSF,记为(locally refined PSF,LPSF),即利用局部iForest对PSF得到的结果检测结果图再进行细化;聚类判别背景子空间变换iForest异常检测,记为(cluster discriminant subspaceiForest detector,CDSF),与PSF不同的在于背景子空间由典型类判别特征子空间法得到;局部细化的CDSF,记为(locally refined CDSF,LCDSF);主成分降维的局部细化主成分背景子空间变换iForest异常检测,记为(dimension reduced LPSF,DLPSF),即对高光谱影像进行正交子空间背景抑制处理后用PCA主成分分析降维,之后各像元的异常值的计算与LPSF的计算方式相同。 图3 高光谱影像及其对应的异常目标参考Fig.3 Hyperspectral images and their target reference images 表1 试验数据描述及其试验参数设置 为便于分析,将本文方法处理结果与其他全局化异常检测方法的结果对比。包括不做任何预处理的全局iForest,全局RX(Global RX-GRX),和经正交子空间背景抑制后的GRX,分别是主成分背景子空间变换GRX异常检测(PCA background subspace GRX,Ps-GRX)和聚类判别背景子空间变换GRX异常检测(cluster discriminant background subspace GRX,Cs-GRX)。 2.2.1 试验的参数设置 本文所有基于iForest的算法中树的数目t统一设置为100,样本随机采样大小n为256。背景子空间参数设置方面。 主成分特征向量背景子空间参数k则通过AUC(area under the curve)[27]评价方法生成每一个试验数据用不同值时PSF异常目标检测结果。图4结果展示的点线图反映5幅影像采用的主成分个数与AUC值之间的关系,根据图4试验结果设置每一个试验数据的最优参数见表1中“PCA子空间数目k”。CDSF方法中背景子空间的确定涉及两个参数,分别为聚类数目和异常像元占影像面积的比例[28]。根据本文所用数据的特点,并进行多次试验后选择了效果最好的参数,各场景的上述两参数设置见表1最后两行。 图4 PCA子空间参数k的确定Fig.4 Determination of PCA subspace parameter k 2.2.2 试验对比分析 2.2.2.1 背景正交子空间增强结果对比 基于表1给定的参数,图5展示了9种不同异常检测方法在5个高光谱数据上进行处理后异常目标响应强度的灰度图。其中基于iForest的方法异常值根据式(4)的定义将小于0.5的像元全部设为0。 图5 异常目标检测结果Fig.5 Detection maps for anomaly targets 对照目标参考图计算目标与背景分离的箱状表达图[29](图6),箱状图表现了异常检测特征图像中背景和目标响应值的分散情况,红色和蓝色分别代表异常目标与背景检测值的主体分布,距离越远,则说明算法的性能越好。在计算GRX的箱状图之前先将其检测得到的特征图进行归一化。由图6中可以看出iForest相对于GRX在harbor和grassland两幅图像的目标响应值的数字范围总体上好于GRX,但与GRX相同的是目标的响应最大值比背景的小;在airport2中GRX结果明显优于iForest;从Ps-GRX和Cs-GRX的分离图中可以看出正交子空间投影对GRX的数值动态变化范围影响甚微,甚至结果不如GRX;两种类型的子空间增强方法中PSF在各试验数据的背景与目标的分离性比CDSF好,也比其他方法的分离性好。 图6 目标与背景分离Fig.6 Separability maps of target and background 表2计算了图5各结果的AUC(area under curve)值,AUC越接近1.0,检测方法可靠性越高。采用子空间分析的iForest的AUC值比GRX,以及同样采用子空间分析的Ps-GRX和Cs-GRX的都高,也比经典iForest高。以airport1为例,PSF的AUC值相对于经典iForest,GRX、Ps-GRX和Cs-GRX分别提高了9.38%、12.8%、14.52%和13.22%;而CDSF则分别提高了0.65%、3.8%、5.4%和4.2%。精度提高非常明显说明经子空间背景抑制处理后异常目标检测变得更容易。同时也注意到子空间分析并没有提高经典GRX的结果。 表2 算法的AUC分数 2.2.2.2 局部iForest对异常检测结果的影响 由图5检测图可以明显地看到全局与局部相结合的异常检测算法的误检减少更为明显。结合表2,以airport1为例,LPSF相对于PSF的AUC值得到了提高1.43%;LCDSF相对于CDSF的AUC值得到了提高2.82%。这说明局部处理进一步提高了精度。 2.2.2.3 主成分分析特征降维对iForest异常检测算法的影响 用不同维数的特征对不同数据进行异常检测的AUC统计值如图7所示,airport1、airport2、beach、harbor和grassland 5个场景分别在保留2、4、6、2、1个特征时取得最大值。可以看出背景抑制后的影像在有限个主成分特征上获得了更好的检测结果,目标的形状更为完整。其对应的AUC值见表2,以airport1为例,DLPSF相对于LPSF的AUC值提高了0.38%。 2.2.2.4 时间效率对比 在CPU为3.60 GHz、内存为8 GB配置的计算机上比较了异常检测算法的运行时间。所有算法都在Matlab软件上实现,表3给出每种方法在每个数据上的运行时间,可以看出iForest需要耗费比GRX更长的时间,时间消耗的主要原因是孤立树建立和测试过程;正交子空间投影简化了建树过程,因而其消耗时间比经典iForest少,主成分分析定义的比聚类判别分析的耗费时间更短。局部细化计算需要额外的时间,降维能使耗费时间进一步减少。 图7 AUC分数随保留特征维数的变化Fig.7 Changes of AUC scores with retained feature dimensions 不同于经典高光谱图像异常目标检测方法偏向于正常背景样本的描述,本文采用iForest异常检测思想着重于孤立异常点。但并不是直接将iForest算法应用高光谱图像,而是提出了在基于特征子空间正交分析的背景抑制和主成分降维处理后,将图像全局iForest异常值计算初步结果和局部分块计算结果结合。综合试验分析与讨论得出如下结论:①以主成分特征子空间分析为基础的LPSF的异常特征值与背景具有更好的可分性,其能够获得更高目标计算精度和计算效率;②全局和局部结合的iForest异常目标检测更灵活地检测出了感兴趣的目标,并获得了良好的检测精度,丰富了算法的内涵;③主成分特征降维使得iForest算法较好地适用于高光谱图像分析。但从图6中可以看到检测结果图中存在一定的噪声,这是论文未来需要解决的问题。 表3 试验数据集的算法运行时间1.3 局部化iForest细化处理
2 试验验证与分析
2.1 试验数据集说明
2.2 试验的实现与对比


3 结 论