基于Fisher Score和社会选择优化的特征选择方法
2021-04-01郑艺峰李国和张文杰潘雪玲魏葆雅
郑艺峰,李国和,张文杰,潘雪玲,魏葆雅
(1.闽南师范大学计算机学院,福建漳州363000;2.闽南师范大学数据科学与智能应用福建省高等学校重点实验室,福建漳州363000;3.中国石油大学石油数据挖掘北京市重点实验室,北京102249;4.中国石油大学信息科学与工程学院,北京102249)
机器学习主要目地是从数据中提取有用的知识.在实际应用过程中,数据量都随着时间的变化而呈指数增加,高维数据可能存在大量的冗余信息,容易造成“维度灾难”.对于分析模型而言,冗余信息会直接影响最终的分析结论.因此,在海量信息中,如何有效消除无效信息,已经成为提取潜在的有效信息的至关重要步骤.特征选择(或称属性约简)是维度约简重要的数据优化方法,其目的为:从原始特征空间获得合适的特征子集,同时不改变特征子集的原始特征内涵.
根据特征评估准则的不同,特征选择方法可以分为三类:封装式特征选择、嵌入式特征选择和过滤式特征选择.与另外两种方法相比,过滤式特征选择完全独立于分类算法,不需要考虑分类模型的性能.因此,其所获得的特征子集更能表征原始数据空间[1].Νayak 等提出一种基于多目标差分进化的过滤特征选择方法,其目标函数综合考虑特征之间的线性和非线性相关性[2].Lyu 等提出最大信息系数和Gramm-Schmidt正交化用以解决不相关的冗余问题[3].M.Labani等提出一种基于多变量相对判别准则的文本分类方法,使用每个术语的文档频率来估计其可用性[4].Hancer等提出一种利用信息论和进化计算技术提取最优特征子集的过滤式特征选择方法,并提出两种不同的准则来构造单目标和多目标算法[5].
然而,上述过滤式特征选择方法并未考虑样本多样性和全局性,仅获得局部最优的特征子集.为了解决上述问题,本文提出了结合Fisher Score和社会选择优化用于充分考虑样本空间的全局性,从而获得近似全局的特征优先序.此外,采用平均冗余度量,有效的去除冗余特征信息.
1 相关概念
1.1 决策信息系统
信息系统可表示为IS=<U,A,V>,其中U={u1,u2,…,un}是非空对象域(|U|表示对象域的基),A表示属性集合,V则表示属性的值域.对于IS=<U,A,V>,V可以表示为{Vα|α∈A}.∀u∈U,α(u)∈Vα,Vα表示α∈A的值域.令C表示条件属性集合,D表示决策属性集合,若A=C⋃D且C⋂D=∅,则信息系统IS=<U,A,V>可称为决策信息系统,表示为DT=<U,C⋃D,V>.
特征选择过程可以描述为:对于DT=<U,C⋃D,V>,Fs⊆C为条件属性集C的子集,可得到DT′=<U,Fs⋃D,V>,DT′与DT具有相同的信息表示能力.这意味着根据DT′构建的分类模型在分类准确率上不低于DT构建的分类模型.
1.2 社会选择理论
社会选择理论是采用某种与群众成员的偏好有关的指标来反映群体意愿的过程,即如何将社会成员的个体偏好集结为群体(社会)的偏好的过程.在社会选择过程中,最为常用的指标为简单多数准则.可将其形式化描述为:
对给定两个方案x,y进行决策,有n个成员对方案的偏好表示为(a1,a2,…,an)∈Yn.ai取决于成员i对两个方案的偏好,若x≻i(y即x优于y),则ai=1,反之ai=−1;若x∼i(y即x等同于y),则ai=0.
对于∀(a1,a2,…,an)∈Yn,社会选择函数φ(a1,a2,…,an)可表示为:
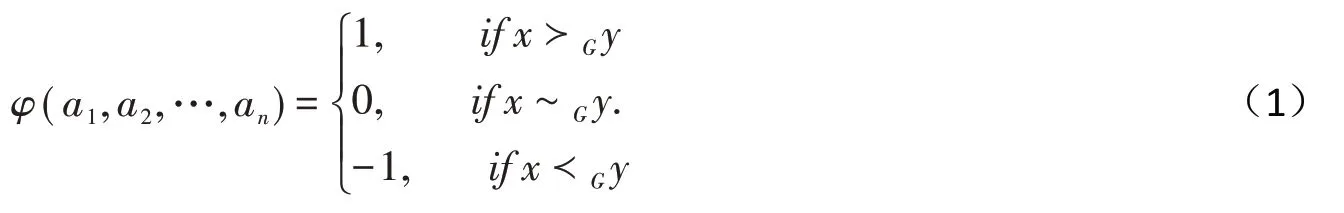
其中,≻G表示群体的偏好.
2 FBMΝ特征选择方法
为了有效保留原始特征的内涵,本文提出一种特征选择方法FBMΝ,其特征选择过程包括特征相关性分析和冗余性分析两部分,具体算法过程如图1所示.

图1 FBMΝ算法过程Fig.1 The process of FBMΝ algorithm
2.1 特征相关性分析
1)特征权重计算
Fisher Score是评价特征相关性的有效方法,其核心思想为:同类样本方差尽量小,而不同类样本之间的样本均值支持尽量大.
给定DT=<U,C⋃D,V>,D={d1,d2,…,dt},决策属性的等价类簇可表示为:UD={Ud1,Ud2,…,Udt},满足Ud1⋂Ud2⋂…⋂Udt=∅且Ud1⋃Ud2⋃…⋃Udt=U.对于特征fi,其值分别属于K个类别,其类内间隔SW定义如下:

同样,其类间间隔SB定义如下:

由式(2)和式(4),可得特征fi的相关性rfi,定义如下:

2)特征优先序融合
在社会选择过程中,Borda函数主要用于判断各候选人优劣.其核心思想为:设A中有m个候选人,则将m−1,m−2,…,1,0这m个数分别赋予排在第一位、第二位….最末位的候选人,然后计算各候选人的得分总数(即为Borda Score),并将Borda Score得分最高的候选人作为获胜者.Borda函数表示为:

其中,N(·)表示候选人中认为x≻iy的人数.
在特征选择中,m个候选人表示为在m个样本子空间中获得的特征子集,采用上述Borda函数对其进行融合,以获得近似全局最优的特征排序.
2.2 特征冗余性分析
给定DT=<U,C⋃D,V>,对于任意B1,B2∈C,如果P(D|(B1⋃B2))≈P(D|B1),则意味着,将B2与B1合并之后,并未增加更多的额外信息量,此时,可认为B2是冗余特征.在特征选择过程中,互信息可用于度量信息的不确定性.因此,本文的冗余性评估度量可定义为:给定DT=<U,C⋃D,V>,对于ci,cj∈C(i≠j),当且仅当满足条件NMI(ci,D)≥NMI(cj,D)且NMI(ci,cj)≥NMI(ci,D),则称ci是cj的近似马尔可夫毯.
为了更加合理的评估特征的冗余性,本文提出平均冗余性度量,计算当前特征与已有特征子集关联最大的q个特征的平均相关性.给定DT=<U,C⋃D,V>,特征子集FC∈C,对于任意特征fj∈C−Fc,其平均相似性定义如下:

其中,Γq表示已有特征子集中与fj相似性最大的q个特征,Γq⊆FC.
结合近似马尔可夫毯和平均冗余相似度,给定DT=<U,C⋃D,V>,特征子集FC⊆C,对于任意特征fj∈C−FC,如果ϖ(fj)≥NMI(fi,D),则fj为冗余特征.
3 实验结果
在本节中,将本文所提出的FBMΝ 方法与已有的方法进行一系列实验对比.为了验证特征选择方法的有效性,使用三种不同的分类模型进行验证,包括决策树(简称CART)、k 近邻模型(简称kΝΝ)和支持向量机(简称SVM).实验主要在8 个数据集上进行分析对比,数据集来自UCI(University of California Irvine)和ASU(Arizona State University),如表1所示.
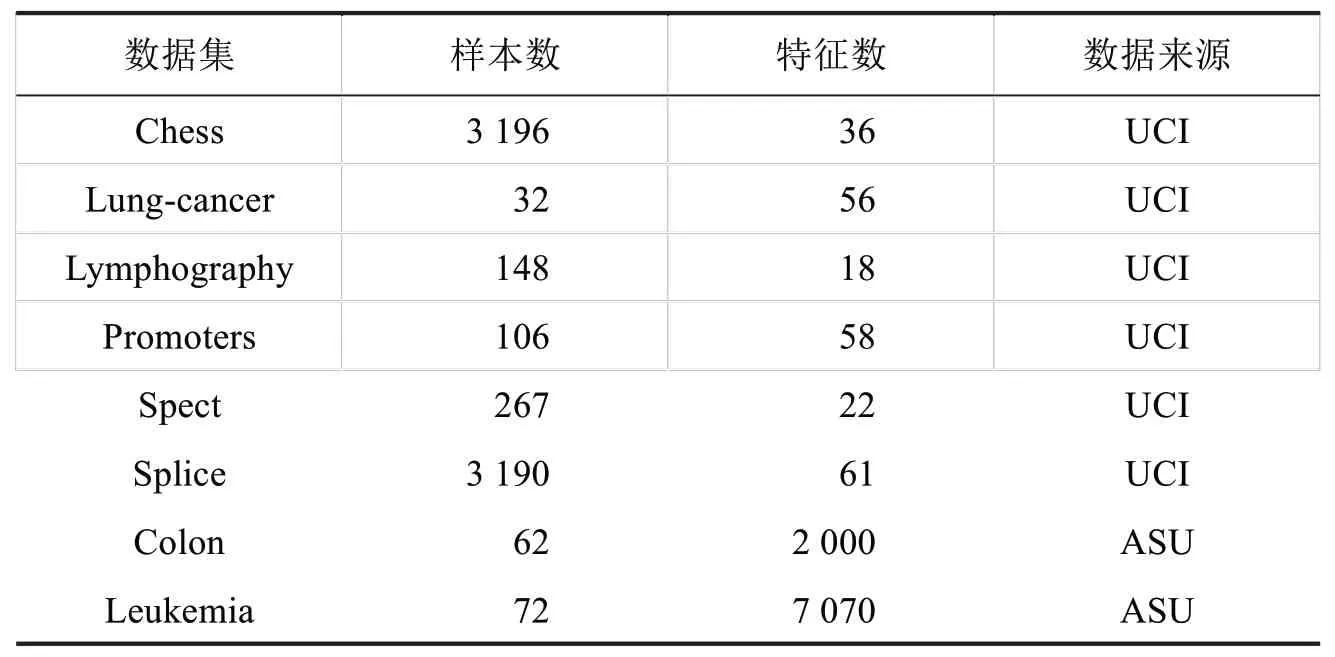
表1数据描述Tab.1 Data description
3.1 实验分析
为了验证特征选择算法的有效性,在6 个低维度的UCI 数据集和2 个高纬度ASU 数据集,分别使用DISR[6]、MRMR[7]、CMIM[8]、JMI[9]、CIFE[10]和FBMΝ 进行特征选择,用于构建不同的分类模型.对于kΝΝ 模型,k 值设置为3;SVM 模型采用高斯核函数.为了保证不同算法之间对比分析更加合理,在每个数据集上,均重复执行50次十折交叉验证以获得平均准确率.
不同分类模型的详细实验结果如表2至表4所示.从表2至表4的结果可以看出,FBMΝ 在CART 分类模型仅在chess数据集劣于CMIM,在kΝΝ分类模型仅在promoters数据集上劣于DISR,而在SVM 分类模型上在chess数据集、promoters数据集和splice数据集上劣于DISR.此外,不同特征选择方法在8个数据集上不同分类模型的平均准确率对比如图2所示.
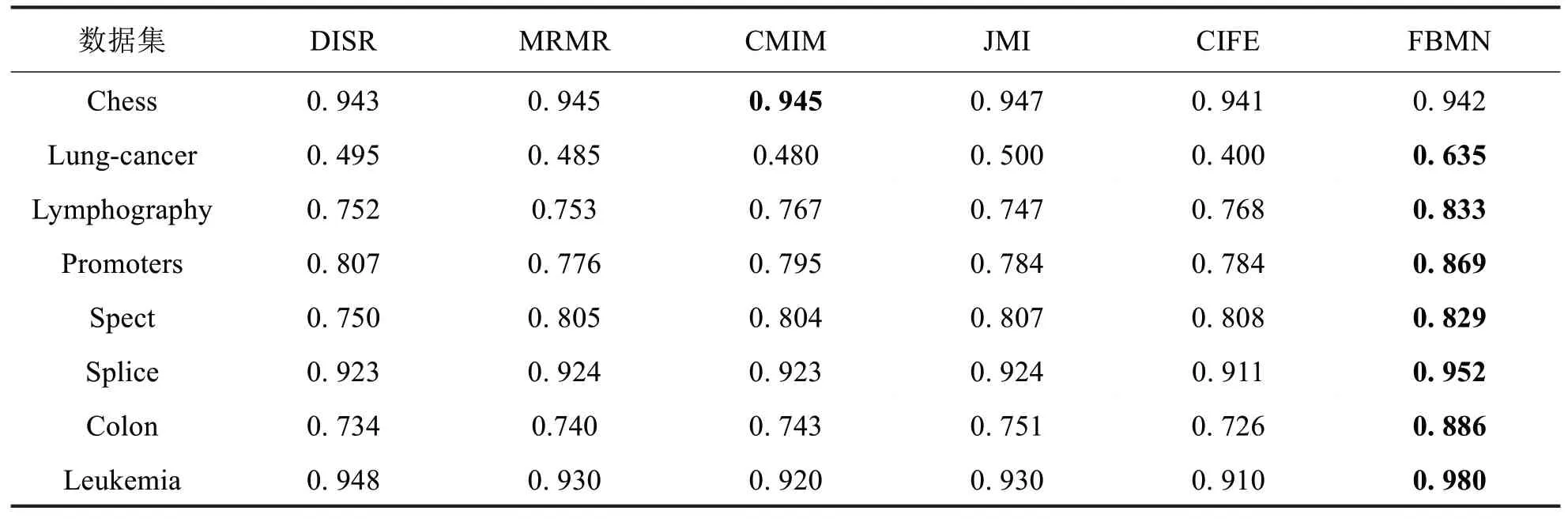
表2不同特征选择方法在CART上分类准确率Tab.2 Classification accuracies of CART with different feature selection algorithms
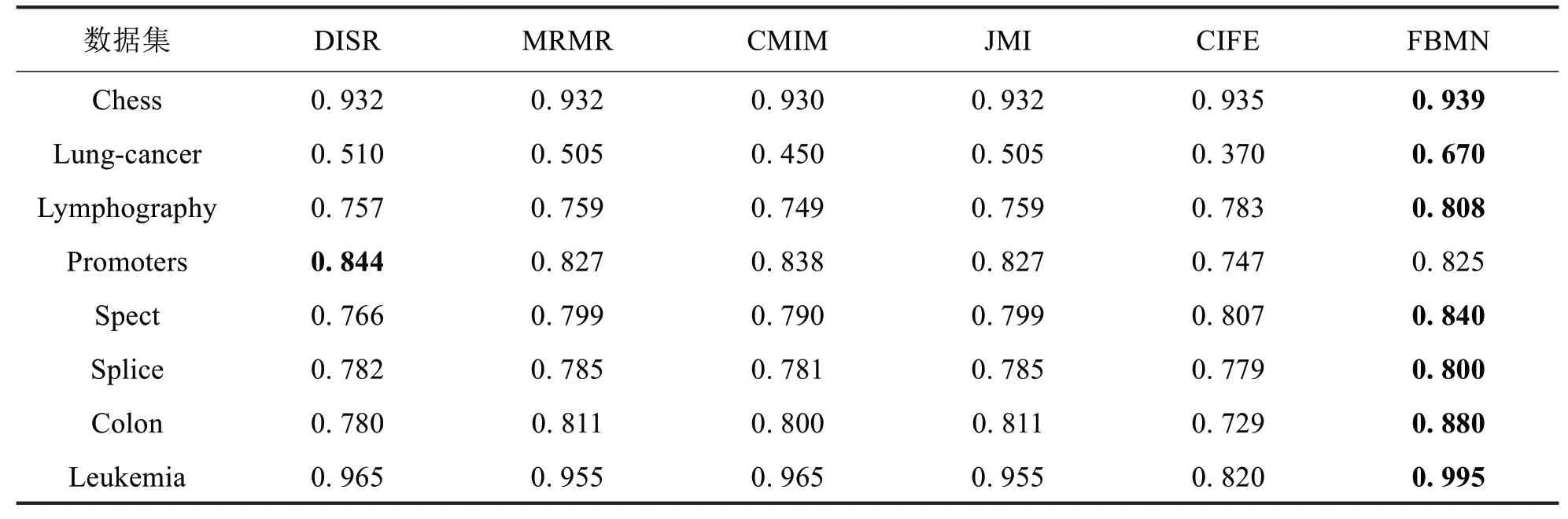
表3不同特征选择方法在kΝΝ上分类准确率Tab.3 Classification accuracies of kΝΝ with different feature selection algorithms
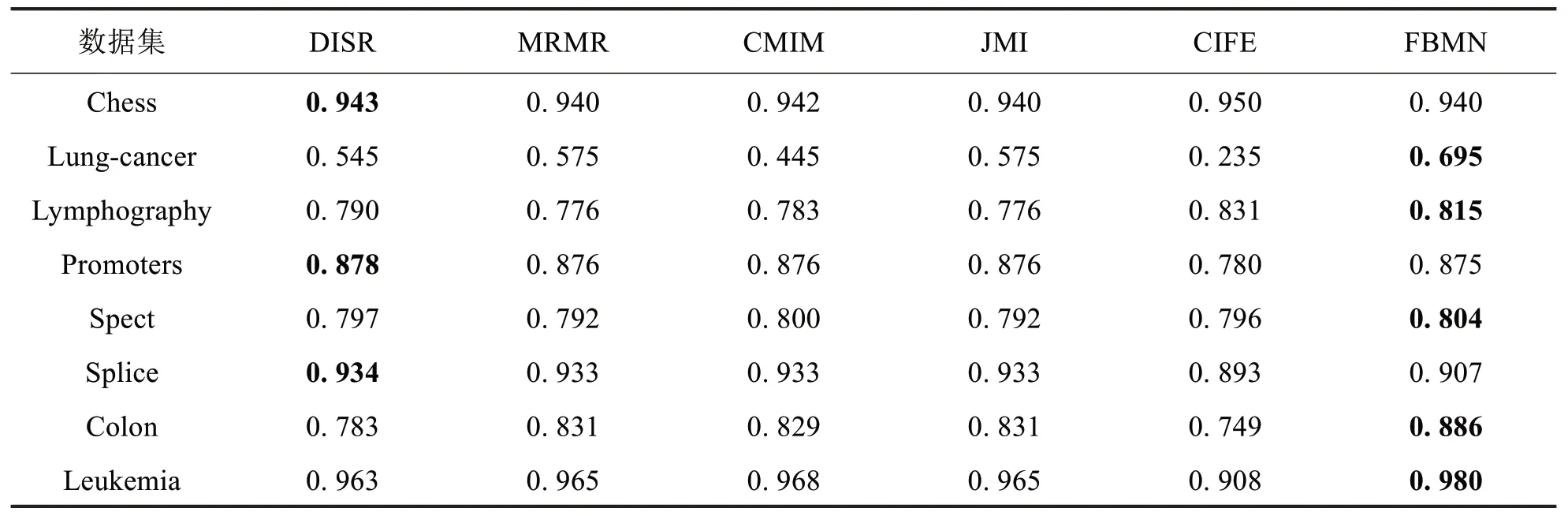
表4不同特征选择方法在SVM上分类准确率Tab.4 Classification accuracies of SVM with different feature selection algorithms

图2 不同分类模型下的平均准确率对比Fig.2 Average accuracy comparison with different feature selection algorithms
3.2 统计分析
基于统计方法的性能分析是有效进行方法评估的重要任务之一.仅仅依靠分类准确率无法有效的评估模型性能,因此,本文采用Contrast Estimation 评估(简称CE 评估)[11],其假设不同算法的性能预期差异在数据集之间是相同的.在实验分析过程中,在每个数据集上,采用成对比较方式,计算不同方法之间的差异程度,公式如下:

其中,i=1,…,Ndata表示数据集索引,μ,ν=1,…,Nalgorithm表示比对方法索引.
通过ωμ−ων计算特征选择方法的整体差异程度,ωμ计算公式如下所示:

其中,Zμj表示所有数据集上的差异程度均值.
因此,本文使用CE 评估FBMΝ 和DISR、MRMR、CMIM、JMI 和CIFE 的性能差异.表5至表7分别表示不同特征选择方法在CART、kΝΝ 和SVM 三种模型上的分类性能CE 评估对比数据(需要注意的是,表中数据越大越好,“-”表示前者性能劣于后者).从实验数据中可以看出,FBMΝ 在不同分类模型上的性能均优于DISR、MRMR、CMIM、JMI和CIFE.
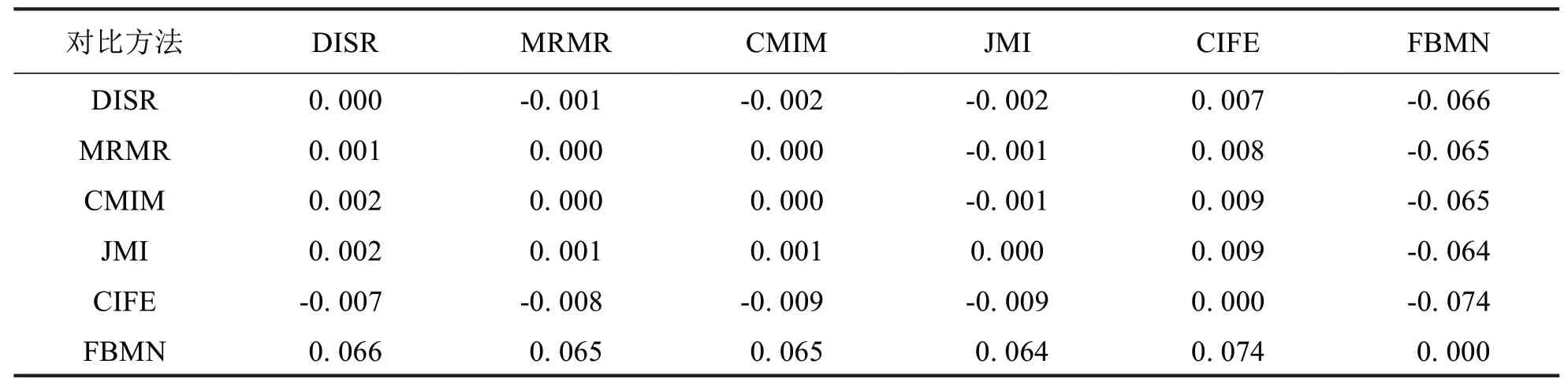
表5基于CART的CE统计分析对比Tab.5 Statistical analysis with CEbased on CART
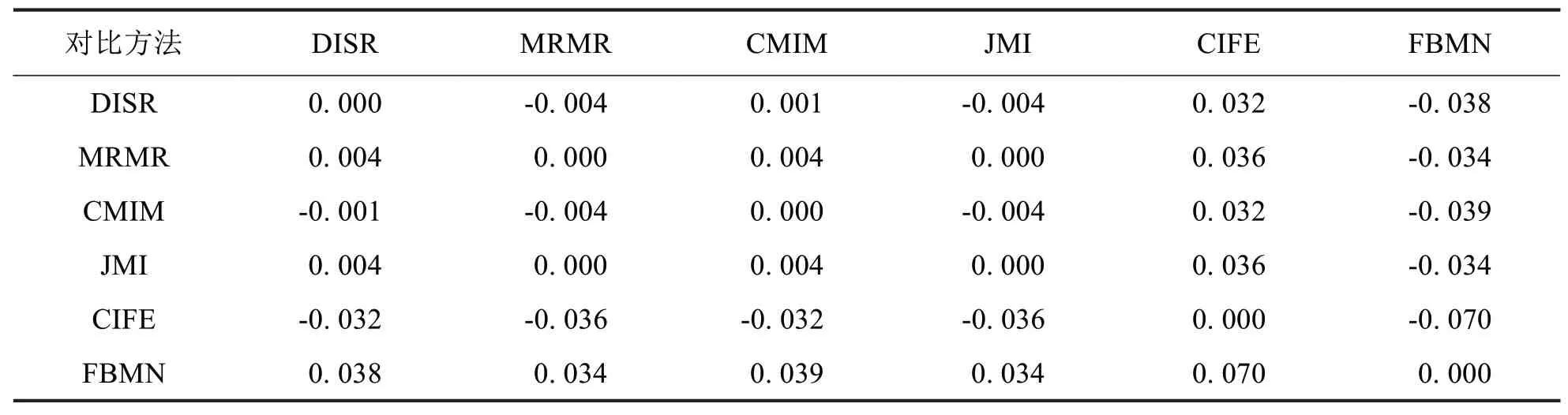
表6基于kΝΝ的CE统计分析对比Tab.6 Statistical analysis with CEbased on kΝΝ

表7基于SVM的CE统计分析对比Tab.7 Statistical analysis with CEbased onSVM
4 结束语
特征选择是机器学习和数据挖掘中重要的数据优化方法,可对原始样本空间进行有效压缩,以可获得潜在的有价值的信息,进而提高模型性能.本文提出的FBMΝ 方法将Fisher Score与社会选择优化相结合以构建近似全局最优的稳定的特征优先序,同时提出平均冗余相似度,将其与近似马尔科夫毯和信息不确定性相结合去除冗余特征信息.在8个不同类型的数据集上的实验表明,FBMΝ的性能明显优于其他5种方法.但是,如何通过自适应平均冗余相似度的特征数量,是本算法有待改进的方向之一.
