多角度标签结构和特征融合的多标签特征选择
2021-04-01周忠眉
周忠眉,孟 威,2
(1.闽南师范大学计算机学院,福建漳州363000;2.福建省粒计算及其应用重点实验室,福建漳州363000)
近年来,多标签学习在机器学习领域发挥着重要作用[1].与单标签数据一样,多标签数据也拥有大量的特征,且这些特征中存在着一些不相关和冗余的特征,会降低算法的分类性能.特征选择作为一种重要的数据预处理技术,在多标签学习中得到了广泛的应用[2].多标签特征选择是从数据中去除不相关和冗余的特征,用一组精简的特征子集代替原始特征集合,所以如何降低数据维数,选择一组较优的特征子集是多标签学习中的一个热点问题.
现有的一些多标签特征选择方法结合信息理论,选择与标签相关性较强的特征.Lin 等[3]提出了一种基于最大依赖和最小冗余的多标签特征选择算法,该算法提出了一种将互信息与最大依赖最小冗余算法相结合的评价度量方法.Zhang等[4]提出了一种多标签特征选择方法来区分两种类型的标签,该算法将标签分为独立标签和依赖标签,通过结合新的特征相关项和特征冗余项,选择最佳的特征子集.Chen等[5]提出了一种基于对齐的多标签特征选择学习方法,它考虑标签空间中每个标签的理想内核,并度量特征空间与标签空间的一致性,选择排序后的最优特征.不难看出,上述多标签特征选择算法从某个方面角度考虑了标签结构,取得了较好的分类性能.
事实上,多标签数据中存在着复杂的标签结构,如果仅仅从单方面去考虑标签结构可能是远远不够的.所以如何从多个角度考虑标签结构,选择一组较优的特征子集是一个重要的研究问题.本文提出了一种多角度标签结构和特征融合的多标签特征选择算法(Multi-viewpoint Label Structureand Feature Fusion for Multi-label Feature Selec-tion,MLSFF).首先,利用不同的标签结构提取不同的特征子集.其次,根据不同特征子集间的相互融合,将特征空间划分成不同重要性的子空间.最后,在每个子空间中设置特征选取比率,并分别选取低冗余的特征.实验结果表明,该算法选取了一组较优的特征子集,且取得了较好的分类效果.本文的主要贡献如下:
1)从三个角度考虑标签结构,并分别提取三个重要的特征子集.
2)融合三个特征子集,将整个特征空间划分成三个不同重要性的子空间.
3)在每个特征子空间中设置选取比率,分别选取低冗余的特征.
1 相关描述和定义
在有q个标签的多标签数据集中,样本向量组成的集合记为W={W1,W2,…,Wt},t表示样本数,Wi是W中第i个样本向量,且1 ≤i≤t,样本向量Wi记为Wi=(xi1,xi2,…,xid,yi1,yi2,…,yiq)T.特征向量组成集合为X={X1,X2,…,Xd},d表示特征数,Xj是X中第j个特征向量,且1 ≤j≤d,特征向量Xj记为Xj=(x1j,x2j,…,xtj)T.标签向量组成的集合记为Y={Y1,Y2,…,Yq},Yk是中Y第k个标签向量,且1 ≤k≤q,标签向量Yk记为Yk=(y1k,y2k,…ytk)T.Wi的标签集合记为C={c1,c2,…,cq},当Wi拥有ck标签时,yik=1,当Wi没有ck标签时,yik=0,且Wi中可能含有多个标签.
定义1(信息熵)设A为任意一个向量,且A=(a1,a2,…,am)T,则A的信息熵定义为:

其中,p(ai)表示ai在数据集中发生的概率.
定义2(互信息)设A和B为任意两个向量,且A=(a1,a2,…am)T,B=(b1,b2,…,bn)T,则A和B的互信息定义为:
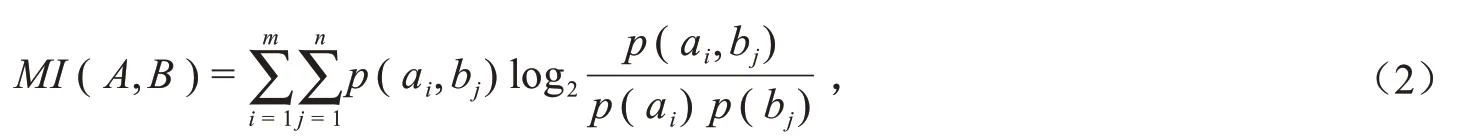
其中,p(ai,bj)表示ai和bj在数据集中同时发生的概率.
定义3(标准互信息)设H(A)为向量A的信息熵,H(B)为向量B信息熵,MI(A,B)为A和B间的互信息,则向量A和B间的标准互信息定义为:

引理10 ≤NMI(A,B)≤1.
证明由信息理论知,因为MI(A,B)=H(A)-H(A|B)≥0,H(A|B)≥0,所以有MI(A,B)≤H(A).同理,MI(A,B)≤H(B).又因为H(A,B)=H(A)+H(B|A)=H(B)+H(A|B),所以得,H(A)-H(A|B)=H(B)-H(B|A),即MI(A,B)=MI(B,A).所以2MI(A,B)/(H(A)+H(B))≤1,当A和B完全相关时,取到最大值1.又知A和B完全独立时,MI(A,B)取到最小值0.所以,
0 ≤NMI(A,B)≤1.
两个向量间的标准互信息是对互信息进行了归一化处理,使得不同向量间的相关性度量在同一个范围[0,1]中,且具有可比性.
定义4(向量间的强相关性)设A和B为任意两个向量,δ为给定一个正数,若A和B间的标准互信息满足:

则说明向量A和B有强相关性.对于∀Xi∈X,∀Yj∈Y,∀Yk∈Y,若特征Xi和标签Yj间的标准互信息满足式(4),则说明Xi是Yj的强相关特征,或Yj是Xi的强相关标签.若标签Yj和标签Yk间的标准互信息满足式(4),则说明标签Yj和Yk间具有强相关性.
定义5(标签重要度)设∀G⊆Y,且G={Y1,Y2,…,Ym},对于∀Yi⊆G,则Yi在G中的标签重要度定义为:

定义6(特征与标签组间的相关性)设∀Xi∈X,∀G⊆Y,则Xi和G之间的相关性定义为:

定义7(特征与标签组的强相关性)设∀Xi∈X,∀G⊆Y,e为给定的一个正数,若Xi和G间的相关性满足:

则称Xi是G的强相关特征,或G是Xi的强相关标签组.
定义8(特征重要度)设∀Xi∈X,Y={Y1,Y2,…,Yq}为整体标签集合,对于∀G⊆Y,G是Xi的相关标签组,且G={Y1,Y2,…,Ym},m≤q,则特征Xi的重要度定义为:

定义9(冗余度)设∀F⊆X,且F={X1,X2,…,Xn},n为特征集合F的特征数,对于∀Xi∈F,则Xi在F中的冗余度定义为:

2 MLSFF算法
在本节中,首先给出了三种不同特征子集的提取过程.其次,详细描述了根据三种不同特征子集的融合过程,将特征空间划分成三种不同重要性的子空间.最后,说明如何在每个子空间中选择最小冗余特征.
2.1 特征子集的提取
2.1.1 基于标签组的特征提取
基于标签组方法的特征提取首先根据定义4 中标签间的强相关性,将标签集合中的强相关标签划分为一组.其次,根据定义7 中标签组的强相关特征,选取每个标签组的强相关性特征.标签集合分组主要步骤如下:
1)给定阈值δ(0 <δ<1),根据定义4 中标签间的强相关性,对于∀Yi∈Y,在标签集合Y中,将所有与Yi的标准互信息大于阈值δ的标签称为Yi的强相关标签,并聚为第一个标签组,记为G1.
2)去除Y中属于G1的标签,即(Y-G1).根据定义4中标签间的强相关性,对于∀Yj∈(Y-G1),在标签集合(Y-G1)中,将所有与Yj的标准互信息大于阈值δ的标签称为Yj的强相关标签,并聚为第二个标签组,记为G2.
3)去除(Y-G1)中属于G2的标签,即(Y-G1-G2).根据定义4 中标签间的强相关性,对于∀Yk∈(Y-G1-G2),在标签集合(Y-G1-G2)中,将所有与Yk的标准互信息大于阈值δ的标签称为Yk的强相关标签,并聚为第三个标签组,记为G3.
4)以此类推,直至标签集合(Y-G1-G2-…-Gh)中没有标签,标签分组停止,Gh为标签集合分组得到的最后一个标签组合,得到标签组集合为{G1,G2,…,Gh}.
根据标签集合分组得到的{G1,G2,…,Gh}和定义7 中特征与标签组的强相关性,依次选取每个标签组的强Xp∈X相关特征子集,主要步骤如下:
1)对于G1⊆Y,根据定义6 中特征与标签组间相关性,给定自适应阈值e1,即Xp∈X,d表示特征集合X的特征数.根据定义7 中特征与标签组间强相关性,在特征集合X中,将所有与G1的相关性大于e1的特征称为G1的强相关特征,并聚为第一个特征子集,记为F1.
2)以此类推,对于剩余标签组G1,G2,…,Gh,分别选取每个标签组的强相关特征子集为F1,F2,…,Fh,并将所有特征子集取并集,并记为S1,S1是标签组方法最终提取的重要特征子集.
2.1.2 基于特征重要度的特征提取
在基于特征重要度的特征提取中,首先给定一个阈值λ(0 <λ<1),根据定义4 中特征与标签间的强相关性,选取每个特征的强相关标签并聚为标签组.其次,根据定义8 中的特征重要度,在已知每个特征的相关标签组后,计算每个特征的特征重要度.最后,对全部特征的特征重要度降序排序,提取重要度较高的特征.基于特征重要度的特征提取主要步骤如下所示:
1)对于X1∈X,根据阈值λ和定义4中特征与标签间的强相关性,在标签集合Y中,将所有与X1的标准互信息大于λ的标签聚为一个标签组,并称为X1的相关标签组,记为G1.
2)以此类推,对于特征集合X中剩余每个特征分别选取强相关标签,得到每个特征的相关标签组,即G1,G2,…,Gd,d表示特征数.
3)根据每个特征的相关标签组和定义8中的特征重要度计算公式,得到每个特征的特征重要度值,即Fsig(X1,G1),Fsig(X2,G2),…,Fsig(Xd,Gd).
4)给定提取比率a,根据得到的全部特征重要度值,对其进行降序排序,提取前个特征并聚为一个特征子集,记为S2,则S2是特征重要度方法最终提取的重要特征子集.
2.1.3 基于标签重要度的特征提取
基于标签重要度的特征提取方法的主要步骤如下所示:
1)在整体标签集合Y={Y1,Y2,…,Yq}中,q是标签数,根据定义5中标签重要度的计算公式,得到每个标签的标签重要度值,并聚为一个集合,即{Lsig(Y1,Y),Lsig(Y2,Y),…,Lsig(Yq,Y)},对其进行降序排序,即{Lsig(Y1,Y),Lsig(Y2,Y),…,Lsig(Yq,Y)},取前n1个标签聚为重要标签组,记为G1,且将剩余标签聚为非重要标签组,记为G2.
2)在重要标签组G1中,令G1={Y1,Y2,…,Yn1}.对于∀Yj∈G1,根据定义4 中特征与标签间的强相关性,给定一个基于Yj的自适应阈值在特征集合X中,将所有与Yj的标准互信息大于λj的特征称为Yj的强相关特征,并聚为一个特征子集,记为Fj.以同样方法,分别选取每个标签的强相关特征,得到每个标签的强相关特征子集所组成的集合,即{F1,F2,…,Fn1},将所有的特征子集取并集,记为P1,即P1=F1⋃F2⋃…⋃Fn1,P1为重要标签组选取的特征子集.
3)在非重要标签组G2中,令G2={Y1,Y2,…,Yq-n1},根据定义6中特征与标签组的相关性,给定自适应阈值e,即根据e和定义7中特征与标签组的强相关性,在特征集合X中,将所有与G2的相关性大于e的特征称为G2的强相关特征,并聚为一个特征子集,记为P2.P2是非重要标签组选取的特征子集.最后,将得到的特征子集P1和P2取并集,记为S3,即S3=P1⋃P2,S3是标签重要度方法最终提取的重要特征子集.
2.2 特征空间划分为子空间
根据三种不同特征提取方法提取的特征子集,对其进行特征融合,将特征空间划分为三种不同重要性的子空间,即重要特征子空间、次要特征子空间、非重要特征子空间.三种子空间的生成如下所示:
1)在特征子集的提取过程中,融合三种特征提取方法同时提取的特征子集,将其分为第一个特征子集,即重要特征子空间,记为SUB1,SUB1=S1⋂S2⋂S3.
2)在特征子集的提取过程中,融合一种特征提取方法提取的特征子集和两种特征提取方法同时提取的特征子集,将其分为第二个特征子集,即次要特征子空间,记为SUB2,SUB2=S1⋃S2⋃S3-S1⋂S2⋂S3.
3)在特征子集提取过程中,融合三种特征提取方法同时都未提取特征子集,将其分为第三个特征子集,即非重要特征子空间,记为SUB3,SUB3=X-S1⋂S2⋂S3,X表示整体特征集合.
2.3 设置选取比率与选取低冗余特征
在本小节中,首先设置一组选取比率,记为{μ1,μ2,μ3}.μ1为重要特征子空间SUB1的选取比率,μ2为次要特征子空间SUB2的选取比率,μ3为非重要特征子空间SUB3的选取比率.其次,算法在每个子空间中选择冗余度较低的特征,主要步骤如下所示:
1)在重要特征子空间SUB1中,根据定义9中特征在特征子集中的冗余度,对于∀Xi∈SUB1,计算Xi在SUB1中冗余度,即m1为SUB1中的特征数.每个特征冗余度值组成的集合为{R(X1,SUB1),R(X2,SUB1),…,R(Xm1,SUB1)},对所有特征的冗余度值进行升序排序,得到排序后冗余度值集合为{R′(X1,SUB1),R′(X2,SUB1),…,R′(Xm1,SUB1)}.令算法在SUB1中选取的特征数记为n1,根据选取比率,在排序后的冗余度值集合中,算法最终选取前n1个特征,且组成的特征子集记为F1.
2)以同样方法,在次要特征子空间SUB2和非重要特征子空间SUB3中分别选取冗余度值排序后的前n2、n3个特征,记为F2和F3.最后,算法将得到的特征子集F1、F2、F3取并集作为最终选取的重要特征子集,即F=F1⋃F2⋃F3,F为MLSFF算法最终选取的重要特征子集.
3 实验
3.1 数据集和实验设置
在本实验中,采用了六种来自不同领域的多标签数据集[6],这六种数据集的详细信息描述如表1所示.

表1数据集描述Tab.1 Description of data sets
为了验证MLSFF 算法的有效性,整个实验过程在windows 系统下的matlab 平台上完成.在提出的MLSFF 算法中,阈值δ设置为0.01,λ设置为10-6,提取比率a设置为0.8.实验对比算法有PMU 算法,MDDM 算法,MFSEF 算法[8]以及MLACO 算法[9],其中,MDDM 算法分为MDDMspc 和MDDMproj,MLACO算法中参数nCycle设置为10,nAnt设置为25.实验采用ML-KΝΝ算法[10]作为分类器,其中,近邻参数k设置为10,平滑参数s设置为1.实验采用了Hamming Loss,Ranking Loss,One-error,Subset Accuracy 四种多标签评价指标来验证算法最终分类性能的好坏,其中Hamming Loss、Ranking Loss、One-error 值越小,表示算法的分类性能越好,Subset Accuracy值越大,表示算法的分类性能越好.
3.2 实验结果与分析
为了更好比较所提MLSFF 算法与对比算法PMU、MDDMspc、MDDMproj、MFSEF、MLACO 的分类性能,实验设置每种算法分别在六个数据集上各自选取30%的特征,选取比率{μ1,μ2,μ3}设置最佳比率。在Hamming Loss、Ranking Loss、One-error、Subset Accuracy四种评价指标上,提出的算法与五种对比算法在六个数据集上的分类性能进行比较,实验对比结果如下表2至表5所示,粗体为最优值,“↑”表示评价指标值越大越好,“↓”表示评价指标值越小越好.
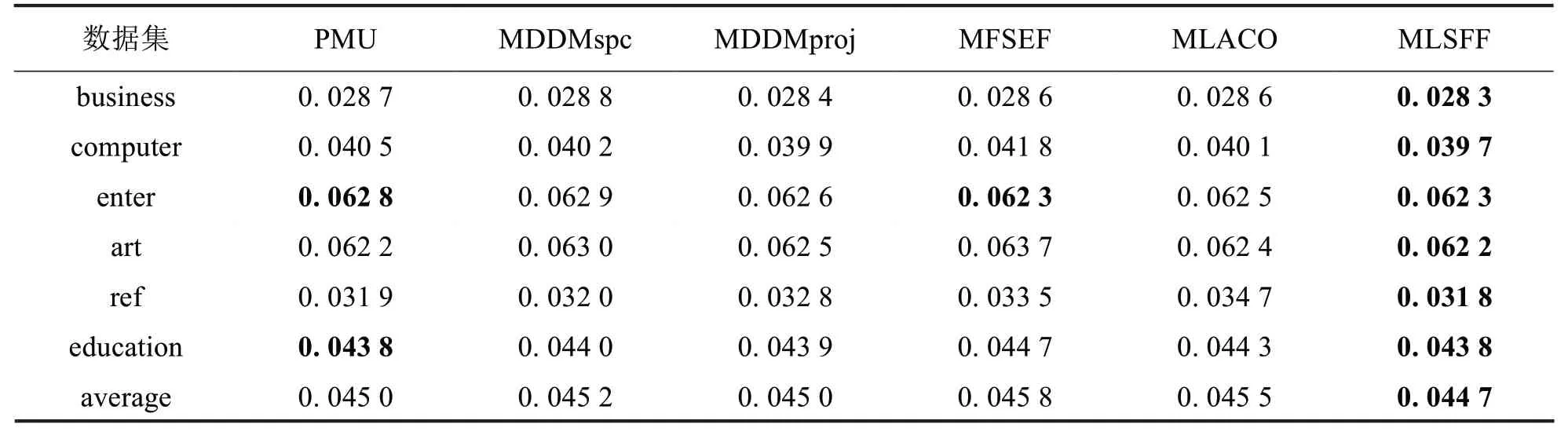
表2降维后ML_KΝΝ分类器的Hamming Loss 比较(↓)Tab.2 Comparative results of ML_KΝΝ classifier in terms of Hamming Loss(↓)
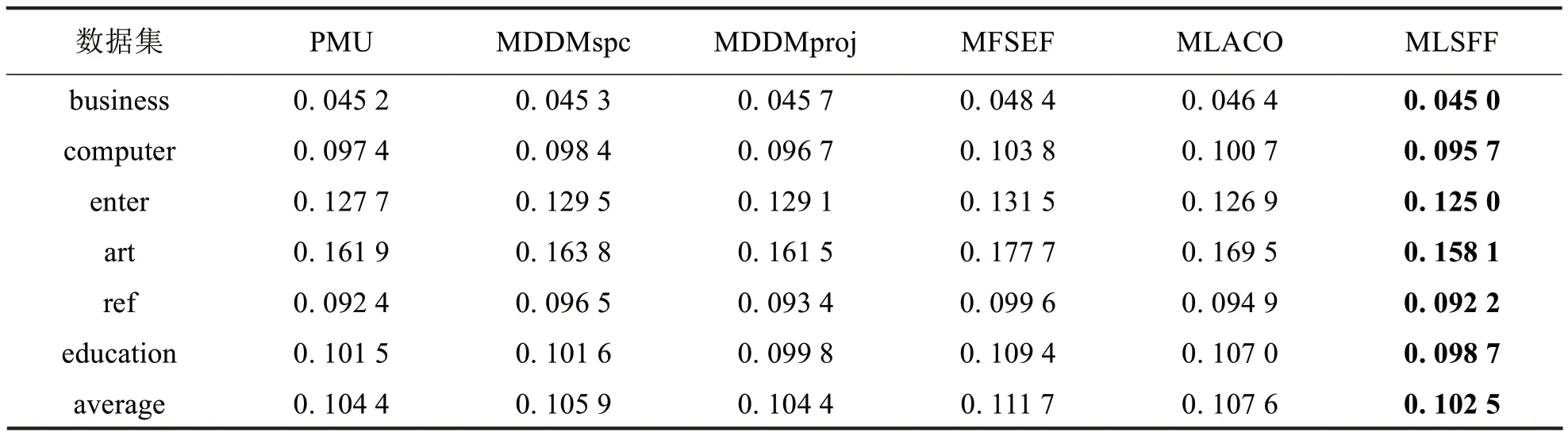
表3降维后ML_KΝΝ分类器的Ranking Loss 比较(↓)Tab.3 Comparative results of ML_KΝΝ classifier in terms of Ranking Loss(↓)
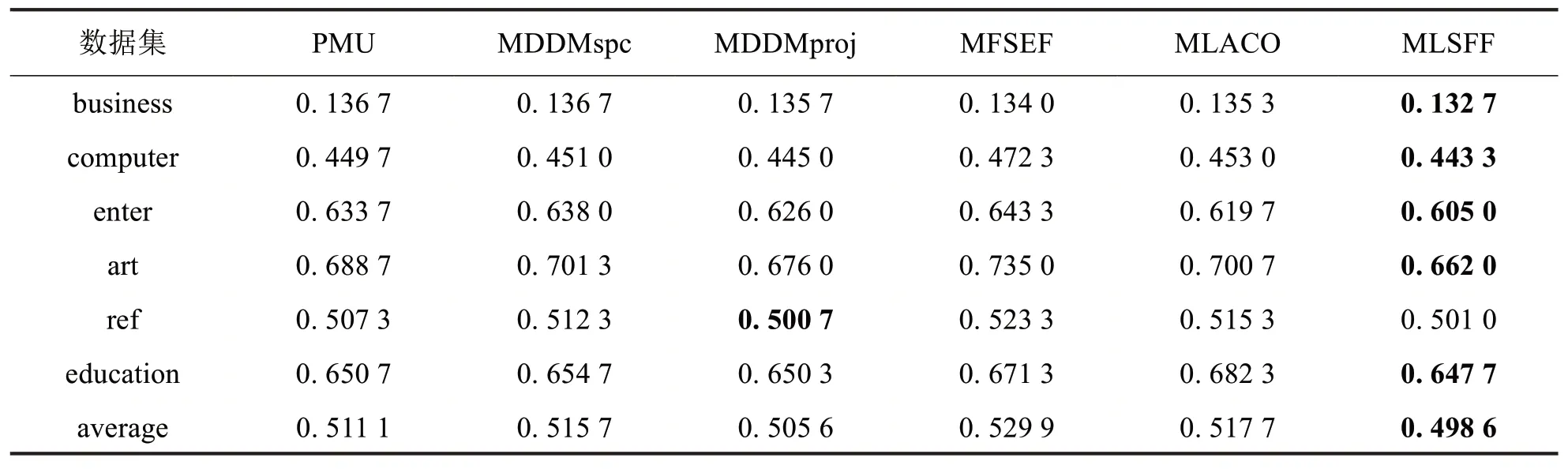
表4降维后ML_KΝΝ分类器的One-error 比较(↓)Tab.4 Comparative results of ML_KΝΝ classifier in terms of One-error(↓)

表5降维后ML_KΝΝ分类器的Subset Accuracy 比较(↑)Tab.5 Comparative results of ML_KΝΝ classifier in terms of Subset Accuracy(↑)
由表2至表5可以看出,在六个数据集和四种评价指标下,MLSFF算法总体上优于其他五种对比算法.
4 总结
本文提出一种多角度标签结构和特征融合的多标签特征选择.该算法首先提出三种不同的多标签特征提取方法,分别提取三种重要的特征子集.其次,融合提取的三种特征子集,将特征空间划分为不同重要性的子空间.最后,在每个子空间中分别设置选取比率,并选取低冗余特征.实验结果表明,提出的MLSFF算法在六种数据集上优于其他五种多标签特征选择算法,具有较好的分类效果.
