融合多级语义特征的双通道GAN事件检测方法
2021-03-31潘丽敏李筱雅罗森林吴舟婷
潘丽敏, 李筱雅, 罗森林, 吴舟婷
(北京理工大学 信息与电子学院,北京 100081)
随着互联网信息爆炸式增长,面对海量信息,如何从大量非结构化文本中提取有用信息成为一个亟待解决的问题,信息抽取技术应运而生.事件抽取任务是信息抽取中一个重要问题,主要目的是将包含事件信息的非结构化文本通过结构化的形式表示出来.近些年来,MUC(message understanding conference)会议、ACE(automatic content extraction)会议对事件抽取技术的发展起到了极大的推动作用.事件检测作为事件抽取的一个重要子任务,其目的是抽取事件触发词并将其分类到特定事件类别中,能够帮助用户从文本中检测出需要的事件信息,这些信息对于机器翻译、情报研究、文本检索、趋势分析、技术监测[1]等领域均具有广泛意义.
目前大部分的事件检测方法往往将句中事件视为独立个体,忽视了事件之间的相关关系[2-4].为实现触发词的正确识别与分类,往往需要对特定语境进行分析,而同一句子及文档中事件往往基于同一场景,存在一定主题相关性,能够为特征的正确表示提供有效信息[5-8].如例1中,同一文档的4个句子中,“caught”、“arrested”以及“it”为触发词,均触发了“Justice.Arrest-Jail”事件.最后一个句子“we had no part in it”中的代词触发词 “it”指代上文“arrested”以及“caught”触发的事件,若只在该句子水平进行分析,代词触发词“it”则较难识别,但若联系上文提及的两个语义相关事件,则可以获得更多的信息以实现“it”的正确识别与分类.
例1:The way wecaughtthat guy was by coordinating with our allies.We now have a foreign policy in Iraq that is putting enormous strain on those allies.The same weekend theyarrestedthe guy, we had no part init.
译文:我们以协调盟友的方式去抓那个人.我们现在在伊拉克实行外交政策,给这些盟友带来巨大的压力.在同一个周末,他们逮捕了那个人,我们没有参与其中.
早期一些由专家精心设计及依赖复杂的自然语言处理工具得到的特征能够有效获取事件之间的相关关系[9-10],但是这些方法需要耗费大量人力,且缺乏泛化能力.随着神经网络在自然语言处理上的巨大成功,提出了基于卷积神经网络(convolutional neural networks, CNNs)[3,11-13]以及基于循环神经网络(recurrent neural networks, RNNs)[14-15]的事件检测算法来获取事件之间的相关关系,这些方法实现了特征的自动提取,为编码高维特征空间提供了便利,减轻了特征工程的复杂性.
但是,某些触发词在不同语境下可能会触发不同的事件,而在多种语境下训练得到的词向量会在自动特征提取时引入与当前语境无语义关联的噪声,例如,在词向量的训练过程中,经常同时出现的词会被判定为语义关联词,使其在特征空间中的距离相近,而与候选触发词距离相近的词会影响其特征表示,从而影响最终事件的识别与分类.然而在某些特定语境下,经常同时出现的词之间可能并无语义关联,但在神经网络的训练过程中,候选触发词在特征空间中的映射会保存这些与其并无语义关联的噪声.如例2中,触发词“taken”实际触发了“Movement.Transport”事件类型,但考虑到上下文语境,上文提到的词“Prison”和当前候选触发词“taken”由于经常同时出现而被认为语义相关,但这两个词在当前语境下并无关联,错误的上下文语境判定使得在特征提取时引入噪声,从而导致事件被误分为“Justice.Arrest-Jail”事件.
例2:Prisonauthorities have given the nod for Anwar make him to betakenhome in the afternoon.
译文:监狱当局已经同意Anwar在下午被带回家.
针对现有事件检测方法在特征提取时未充分考虑句子级和文档级事件间相关性以及由于在多种语境下训练得到的词向量会引入与当前语境无语义关联的噪声问题,本文提出了一种融合多种语义特征的双通道GAN事件检测方法,首先使用多级门限注意力机制提取句子级和文档级事件间的相关性特征;然后利用双通道GAN及其自调节学习能力在有效特征提取时减轻与当前语境无语义关联的噪声信息的影响.在ACE2005英文语料上进行实验,结果表明该方法能够有效提取事件间的语义相关性,并提高语境判定的准确性.
1 相关工作
事件检测是事件抽取过程中的一个子任务,由TDT(topic detection and tracking)项目提出,目的是识别句子中的事件触发词并将其正确分类.目前大多数的事件检测任务均沿用ACE2005定义的抽取方法,下面列出相关概念,
事件(Event):在真实事件中已经、可能或将要发生的事情,一般包括时间、地点和人物等角色,如出生、地震和车祸等事件.
触发词(Trigger):表示事件发生的词语,又称为锚,是事件的基本要素之一.如“出生”、”生于”为“Be-Born”(出生)事件的触发词.事件识别的关键就是识别事件的触发词.
论元(Argument):与事件相关的实体实例,是构成事件的基本要素之一.
事件实例(Event Mention):描述一个事件的短语或句子,包含一个触发词与任意数量论元.
事件类型(Event Type):事件的类别,每个事件触发词对应一种事件类型.在ACE语料中共描述了34种事件类型(包括非事件类型).
早期基于人工构建特征的方法使用AMR(abstract meaning representation)获取和表达触发词的深度语义知识[7],但这种特征构建的方式需要丰富的领域知识与外部资源,对于某些语言来说缺少自然语言处理工具,因此特征提取困难.考虑到事件论元与触发词之间的关系,Li等[10]利用最大熵分类模型获取了触发词与事件论元之间的相关关系.随着神经网络在事件检测任务上取得成功,Nguyen和Grishman首次采用卷积神经网络(convolutional neural networks, CNNs)实现了事件检测的领域适应性[3],随后,针对CNN的连续卷积操作不能获取句子之间长距离依赖关系的问题,提出了NC-CNN[11]以及GCNs[12],另外,Chen等[13]采用动态多池化的卷积神经网络模型自动获取字符级以及句子级特征,但这些基于CNN的方法仅考虑了句子级局部及全局结构信息,忽视了序列信息.为了实现对事件块(即触发词由多个词组成)的识别,Ghaeini等[14]应用了双向循环神经网络(FBRNN),考虑了文本序列信息,同时引入位置信息,证明了句子中的词语位置信息对于事件检测任务的有效性.随后,Feng等[15]设计了混合神经网络(hybrid neural network, HNN),利用CNN获取局部块状信息,同时利用Bi-LSTM获取句子的时序信息,证明了块状结构信息与序列信息对事件检测任务的有效性.针对之前的方法未考虑事件论元对事件检测的重要性,Chen等[16]通过有监督的注意力机制挖掘事件论元信息,有效提升了事件检测的效果.Huang等[17]使用一个自下而上的事件检测算法,独立识别候选事件,使用该信息以及话语属性对文本衔接建模.Liu等[18]设计了一种基于对抗模仿的知识蒸馏的方法,解决了从原始句子中获取事件的问题.由于神经网络自动提取特征时可能会引入语义伪相关性的噪声,Hong等[19]在对抗多任务学习模型基础上,构建了一个双通道模型来优化真实特征表示.但是,上述方法仅构建了句子级特征,忽视了文档级特征的有效性.
为了引入文档级事件之间的语义相关性.Liu等[5]使用概率软逻辑(probabilistic soft logic, PSL)模型,获取了句子级和文档级事件之间的相关关系,但该方法需要人工构建规则.随着神经网络在自然语言处理任务上取得巨大成功,Zhao等[6]使用文档嵌入增强的Bi-RNN模型,实现了文档级特征与句子级特征的融合.Duan等[20]使用PV-DM预训练文档向量,并在嵌入层引入,证明了文档级特征在事件检测任务上的有效性,但是在文档嵌入的训练过程中需要固定窗口大小,会造成全局特征提取不充分.
本文提出了一种融合多级语义特征的双通道GAN事件检测方法.该方法使用多级门限注意力机制获取了句子级和文档级的事件间语义相关性,并利用双通道GAN减轻了由多种语境下训练得到的词向量引入的与当前语境无语义关联的噪声信息的影响.
2 算法原理
2.1 原理框架
图1为融合多级语义特征双通道GAN事件检测方法的原理框架图,主要由嵌入层、多级特征编码层、自调节学习层3部分组成,其中嵌入层实现词及其实体类别的编码,多级特征编码层利用多级门限注意力机制用于获取句子级和文档级事件之间的关联关系特征,并将两部分特征融合,最后自调节学习层利用双通道GAN进行协同和对抗式训练,利用其自调节学习能力减少了与当前语境无语义关联的噪声,从而提高提取特征的准确性.
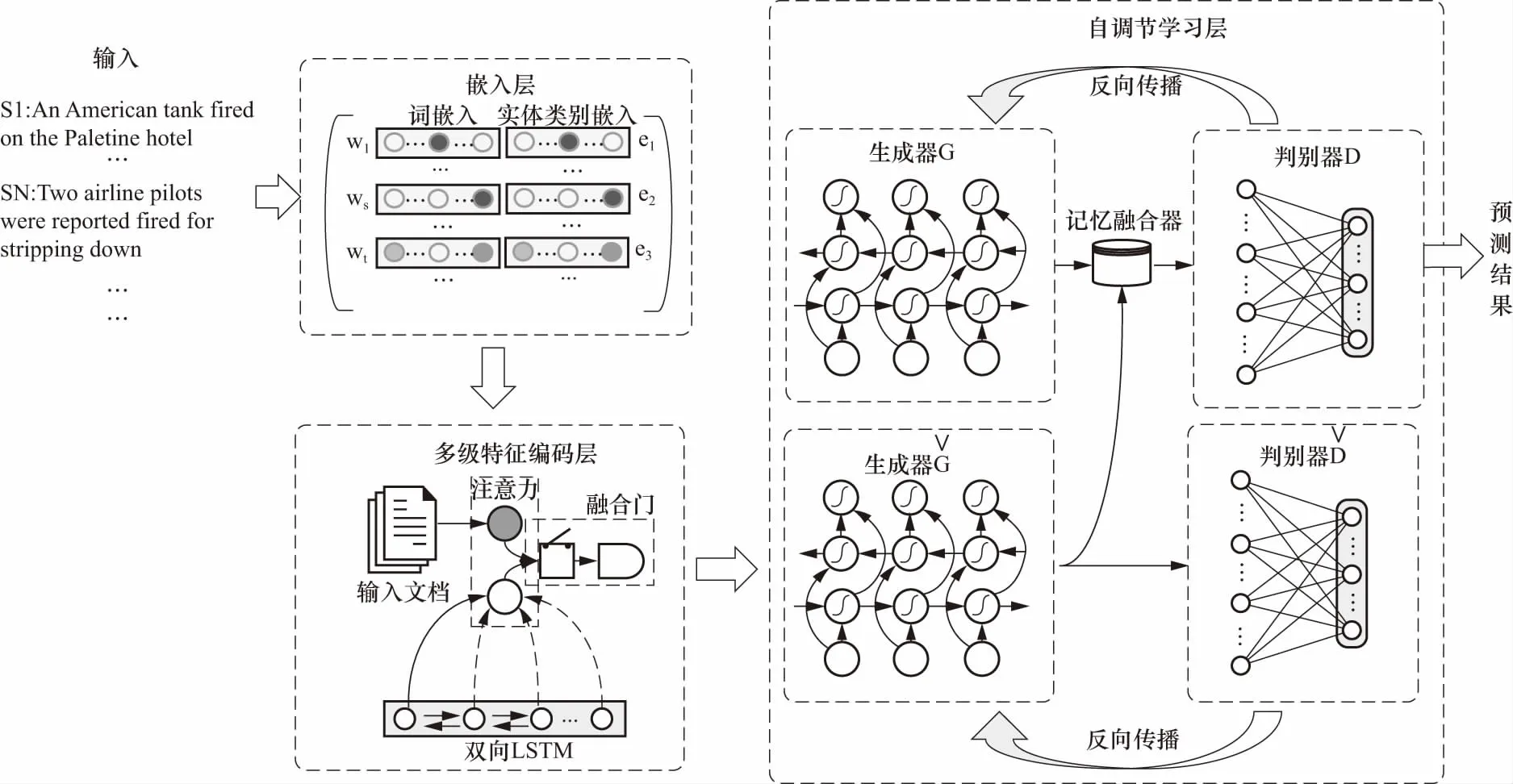
图1 原理框架图
2.2 嵌入层
大部分研究往往将事件检测任务看作多分类任务.给定一个含有NS个句子的文档d={s1,s2,…,si,…,sNs},假设第i个句子si有Nw个词,因此表示为si={w1,w2,…,wt,…wNw},想要预测当前词wt是否为事件触发词,通过拼接下列词向量与实体类别向量,将每个词wt转换为真值向量et.
① 词嵌入(word embedding):一个固定维度的真值向量,用于表示某个词的隐藏语义特性,通过查找预训练的词向量表得到.
② 实体类别嵌入(entity type embedding):表征一个词的实体类别的特征,对每个实体类别(包括N/A类别)随机初始化并在训练过程中更新.
2.3 多级特征编码层
2.3.1双向LSTM网络
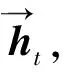
2.3.2多级语义特征提取及融合
多级门限注意力层主要包括两个部分,句子级注意力层和文档级注意力层.句子级注意力层用于获取句子级事件相关性的语义特征.对于每个候选触发词et,其句子级别语义信息计算方式如下,
(1)
(2)
(3)
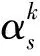
同理,文档级注意力层用于获取文档级事件相关性的语义特征,对于第i个句子,其计算方式如下.
(4)
(5)
(6)
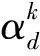
最后,利用特征融合门将文档级特征与句子级特征融合表示,得到上下文信息表示为
Oht=Gt⊙sht+[(1-Gt)dhi]
(7)
其中融合门计算方式如下,
G=σ(Wg[sht,dhi]+bg)
(8)
2.4 自调节学习层
由于在多种语境下训练得到的词向量会引入与当前语境无语义关联的噪声,采用基于自调节学习的双通道GAN模型来减轻的噪声信息的影响,
如图2所示,主要包括协同式网络[22]与生成式对抗网络[23]两个通道模型,最后应用记忆融合器将两个模型融合,实现噪声过滤,从而提高特征表示的准确性.
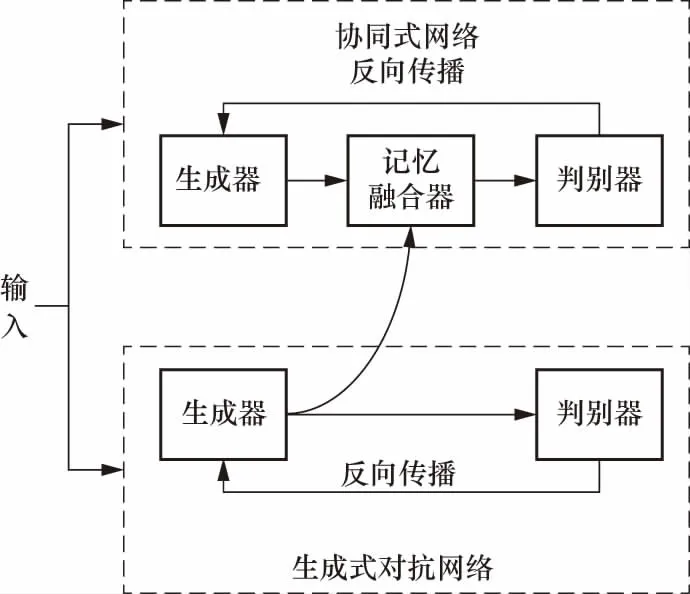
图2 自调节学习层原理框架
2.4.1双通道模型
协同式网络主要目的为挖掘文本的有效特征,由生成器G与判别器D组成,其中使用双向LSTM作为生成器,以多级特征编码层获得输出Oh作为输入,得到隐层特征表示,
og=LSTM(Oh;θg)
(9)
依赖于该输出og,采用全连接网络作为判别器,得到候选触发词触发某一类别事件的可能性,
(10)
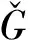
(11)
(12)
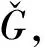
许云等[24]曾通过实验验证了语义相似度能够有效减轻句法分析中的结构性歧义.
L2范数又称为欧几里得范数,常用于表示两个矩阵之间的距离,这里使用L2范数来衡量两个生成器之间的相似度,计算如下,
(13)
式中l表示输入的句子长度.
2.4.2训练过程
该双通道模型使用交叉熵作为损失函数,
(14)
其中对于协同式网络,生成器与判别器协同训练得到,
(15)
式中:θ为LSTM以及全连接网络的所有参数;N为训练数据的批尺寸(batch size);另外,y为N维向量,λ为超参数.
对于生成式对抗网络,这里生成器用于生成错误特征,使数据偏离正确的分布,而判别器则用于纠正错误,因此生成器与判别器对抗训练得到,
(16)
(17)
3 实验分析
3.1 实验数据与评价指标
为验证融合多级语义特征的双通道GAN事件检测方法的有效性,与先进算法进行对比实验分析.
实验基于ACE2005英文语料库,该语料库包含599个文件,覆盖6个不同领域:broadcast conversation(bc), broadcast news(bn), telephone conversation(cts), newswire(nw), usenet(un)and webblogs(wl).在该数据集上对模型效果进行评价,其中以40个newswire类别的数据为测试集,从不同类型的文档中随机抽取30个样本作为验证集,剩余的529个文档为训练集.该数据集被标注为8个大类和33个子类,将非触发词分类为“None”,则可以将该任务看作一个34分类问题.
对于事件检测结果的验证标准,如果识别的触发词的偏移量及其类别与参考触发词一致,则证明触发词被正确识别和分类,这里使用精确率(precision)、召回率(recall)、F1值(F1score)作为评价指标.
3.2 参数设置
沿用Chen的参数设置方式以及使用Skip-gram方法在NYT数据集上的词向量预训练结果[25],初始化为100维真值向量,实体类别向量在[-1,1]范围内随机初始化为50维真值向量.设置dropout rate=0.2,mini-batch size=10,λ=0.1+1,LSTM的输出维度设为150维,学习率设为0.3.
3.3 实验结果
3.3.1对比模型
将事件检测的对比方法划分为两类,基于句子级特征的事件检测方法以及基于文档级特征的事件检测方法.
1)基于句子级特征的事件检测方法如下:①Joint model[10]:该方法基于结构化感知机,并将句中局部及全局特征结合;②CNN[3]:使用CNN在句子水平挖掘文本局部结构信息;③NCNN(Non-consecutive CNN)[11]:使用skip-gram实现非连续卷积操作,考虑到句子中远距离词之间的相互依赖关系,引入了句子水平的全局信息;④GCN[12](Graph-based CNN):该方法是一种引入外部特征的方法,利用依存分析图为CNN引入句中词之间的长距离依赖关系;⑤Hybrid[15](Bi-LSTM+CNN):利用Bi-LSTM与CNN相结合的方法同时考虑了句子中的局部结构信息与文本的序列信息;⑥JRNN[14](Joint RNN):使用RNN获取句子中事件之间的相互依赖关系;⑦SELF[19](Bi-LSTM+GAN):使用GAN挖掘错误特征信息,并使用双向LSTM挖掘句子级的有效信息.
2)基于文档级特征的事件检测方法如下:①Cross-Event[9]:基于最大熵分类模型,将文档特征嵌入到特征空间中;②DEEB-RNN3[6]:使用attention机制获取句子级和文档级特征,将两部分特征拼接与词嵌入、实体类别嵌入拼接,利用Bi-GRU检测事件;③DLRNN[20]:使用PV-DM进行文档嵌入,与词嵌入拼接,利用Bi-LSTM检测事件;④HBTNGMA[24]:将事件检测任务看作序列标注任务,利用attention机制获取句子级和文档级特征作为输入,并使用两层LSTM实现了触发词标注.
3.3.2触发词识别
表1显示了触发词识别效果,可以看出,与联合模型(Joint model),混合模型(Bi-LSTM+CNN)以及SELF模型(Bi-LSTM+GAN)进行对比实验,融合多级语义特征的双通道GAN事件检测模型与先进模型SELF相比F1值提高了1.0%,精确率较高,而召回率稍低,原因可能在于ACE数据存在正负样本不平衡问题,正样本数量远远小于负样本数量,在批量处理文档级特征时每批数据中正样本特征过少,特征提取不够完全与准确,使预测结果倾向于比例较大的负样本,从而造成召回率降低的结果.但是整体上看来,精确率、召回率以及F1值与先前的方法相比更加均衡,均达到了80%.
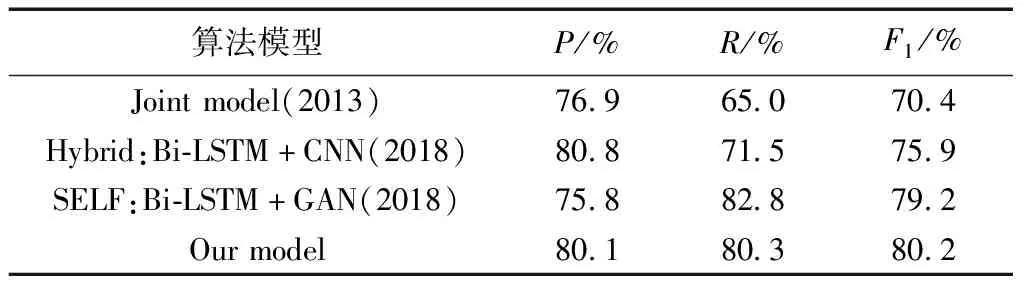
表1 发词识别效果对比
3.3.3事件分类
表2显示了与先进的句子和文档级事件检测模型进行对比实验的结果.
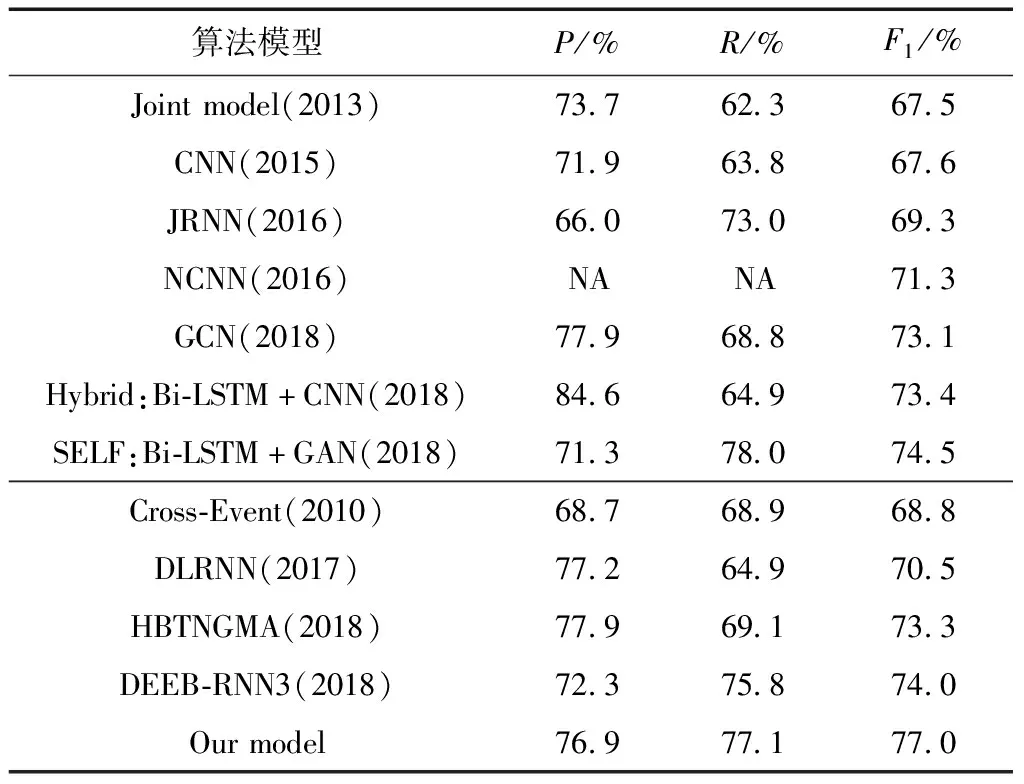
表2 与句子级模型及文档级模型的事件分类效果对比
在句子级事件检测模型中,融合多级语义特征的双通道GAN事件检测模型与SELF模型相比F1值提高了2.5%,与混合模型(Hybrid)相比提高了3.6%;在文档级事件检测模型中,与DEEB-RNN3相比召回率提高了1.3%,F1值提高了3%,精确率相比于DLRNN以及HBTNGMA分别降低了0.3%以及1%,以损失少许精确率为代价,换取了召回率以及F1值的显著提高.可以看出该模型与传统模型相比,能够减轻句子级及文档级噪声信息的影响,从而有效提高了事件检测的效果.
3.3.4多级特征的有效性
为了验证多级特征在提高特征表示准确性上的有效性,将使用多级门限注意力的事件检测模型分别与使用词嵌入、句子级注意力以及文档级注意力的事件检测模型相比较.表3显示:①使用多级门限注意力的方法在事件检测中的效果最好,证明了同时使用句子级、文档级和词嵌入的混合特征能够更为有效地提高特征表示的准确性;②仅使用词嵌入的方法,F1值为74.5%,低于使用文档级、句子级以及混合特征的方法,可见词级别特征对于语义特征表示效果不佳;③比较使用文档级以及句子级特征的方法,使用句子级特征的方法比使用文档级特征的方法F1值高0.2%,可以看出句子级文本之间的特征关联度更为密切,能够为事件检测任务提供更为有效的语义特征表示.
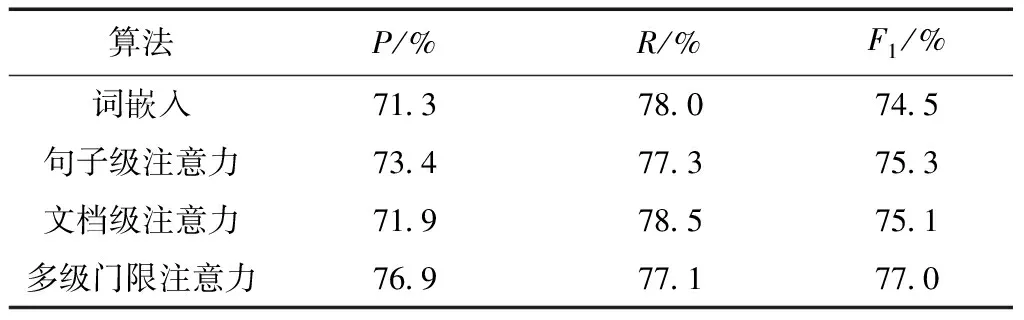
表3 多级特征有效性比较
4 结 论
提出了一种融合多级语义特征的双通道GAN事件检测方法,该方法首先利用多级门限注意力机制融合了句子级与文档级语义特征,有效获取了多级事件间的语义关联性信息,然后使用双通道GAN分别提取事件的有效特征及语义无关性噪声,并利用其自调节能力减轻了该噪声信息的影响,提高了事件特征表示的准确性.在公开数据ACE2005英文语料上进行实验,以精确率、召回率以及F1值为评价指标,与先进算法SELF相比,F1值在触发词识别上提高了1.0%,在事件分类上提高了2.5%,结果表明该方法能够有效提取多级事件间的语义相关性,并提高语境判定的准确性.但是该方法还存在一些问题,由于ACE2005数据缺乏,会导致数据存在稀疏问题,因此未来将在数据增强上进一步研究.
