基于得分系数的跟车工况驾驶风格识别研究
2021-03-31金辉吕明
金辉, 吕明
(北京理工大学 机械与车辆学院,北京 100081)
驾驶风格是表征驾驶员固有驾驶方式的整体性评价指标,研究该指标对于驾驶安全辅助系统具有重要意义,也是人机共驾场景下极其重要的参考指标.通常将驾驶风格分为2~5类,以三分类居多[1].由于缺乏先验知识,难以用人工方式来赋予标签,故传统的驾驶风格评估方法是结合机器学习中无监督学习算法和有监督学习算法使用,这种方法的特点在于分类结果最后呈现为多个离散的类别,对于引入的全新测试数据,只能给出预测结果和整体正确率,无法校正单个样本[2].
为了提高结果的准确性和易用性,近年来有学者开展了连续性聚类算法的初步研究.温柳英等[3]通过对数据特征使用无向加权图调节权重实现了数据点边界的模糊化;Wang等[4]也提出了通过运用隶属度和支持度来生成蕴含式类集实现分类算法从有级结果向连续结果转化;Augustynowic[5]提出以Elman型的递归学习神经网络的形式构建一个驾驶的基础评分系统来衡量驾驶员的驾驶风格.前人所做的连续性聚类或评分算法主要存在评分机制复杂,或者在决策边界处分类准确率低的问题.
本文主要研究能够实现快速计算的基于数据库分析结果的驾驶风格评价系统,针对快速路跟车工况的纵向动力学特征进行研究和分析.识别算法流程如图1所示,本文提出的方法将轨迹数据通过表征参数和阈值分区进行碰撞危险性评价,评价结果转化为危险等级来参与客观性得分系数的计算,同时评价结果也会输入K-Means算法用以校验SCO,新方法不需要赋予标签,最终结果会以0~1之间的得分来标准化地呈现,相比于已提出的部分连续性聚类算法,在数据集质量要求、计算简便性和速度方面存在一定优势.
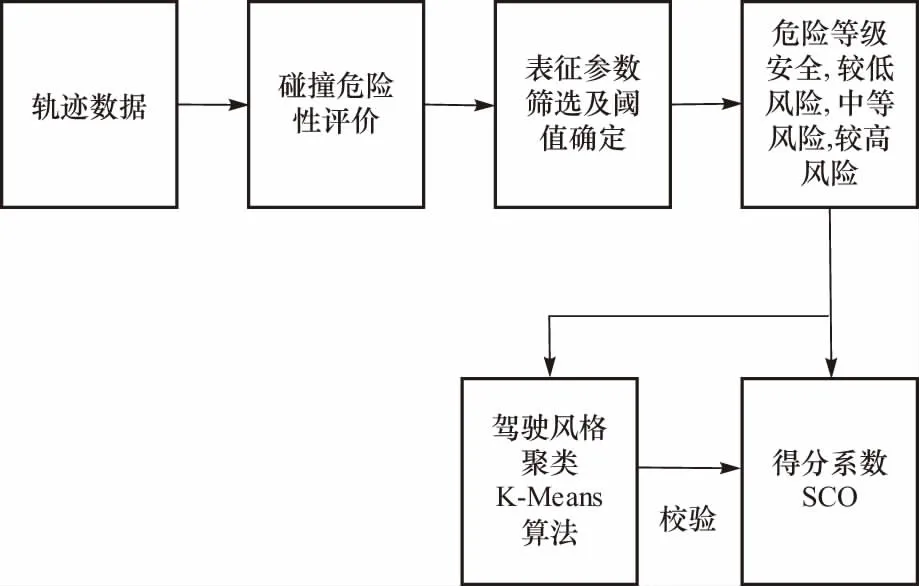
图1 算法流程框架
1 NGSIM数据库
本文所使用的数据来源于美国Next Generation Simulation(NGSIM)数据库.数据采集自美国加州洛杉矶Lankershim大道US101公路中的一段.用固定摄像头以频率10帧/s采集,其示意图如图2所示,一共记录了3 109辆车的行驶信息.本文选取的是处在跟车工况的乘用车进行研究,每辆车的速度均在0~55 km/h范围内变化,每辆车加速度均在±3.5 m/s2范围内变化,研究选取的每辆车跟车行驶时间均超过60 s,行驶距离均超过400 m.
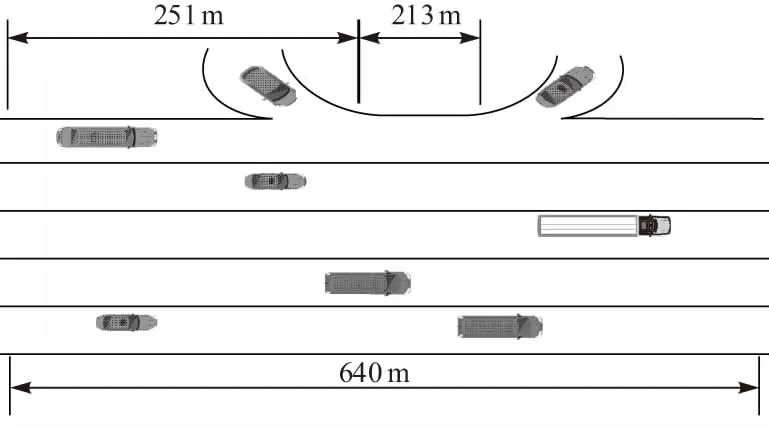
图2 US101公路示意图
2 跟车工况的行为特征提取
2.1 数据处理及筛选
在该公路上行驶的车辆种类较多,本文针对普通型乘用车的驾驶员进行研究.由于数据量大,同时考虑计算机处理能力和效率,车辆序号在1 500~2 000的500辆的乘用车中跟车工况较多,故随机选择了224辆共19 488条处在跟车工况的车辆数据记录进行研究,数据库包含每辆车的速度、加速度、观测范围内的行驶里程、行驶时间和前后车跟车情况等特征参数.
2.2 特征参数选取
对于驾驶员而言,找到能够描述碰撞危险性的特征参数具有重要的实际意义,仅仅使用自身车辆的速度和加速度变化可能无法很好地反映前后跟车工况下的碰撞危险性,通过研究分析认为与前车的车头时距(time headway,THW)和碰撞时间的倒数(inversed time to collision,ITTC)两个参数能够更好地表征碰撞危险性[6].因此本文也采用这两个参数作为特征参数,车头时距反映当前车刹车时,后车驾驶所具有的最大反应时间,其计算方法如图3和式(1)、(2)所示.
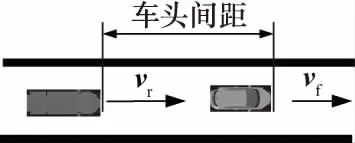
图3 跟车工况示意图
tTHW=S/vr
(1)
ITTC=(vf-vr)/(S-Lf)
(2)
式中:S为车头间距,m;Lf为前车的车身长度,m;vf为前车速度,m/s;vr为后车速度,m/s.
为了建立正交二维的阈值分区体系,首先需要判断THW和ITTC的相关性,为此引入了统计学中的Pearson相关系数(Pearson correlation coefficient).它是重要的表征相关性的参数,当Pearson相关系数的绝对值低于0.2时则认为两个变量相关性极低或者不相关.经计算,选取的224辆车,每辆车THW和ITTC这两个参数的Pearson系数均低于0.2,所有车总体的ITTC和THW的Pearson系数为0.05,可认为THW和ITTC的相关性极低.基于此可认为它们是两个相互正交的向量,可据此构建如图4所示的坐标系.将坐标系分为了4块区域,分别是安全、较低风险、中等风险和较高风险.根据文献[7]中提出的划分方式和阈值的确定THW可以作为一个评价驾驶危险等级的指标使用,并给出了2 s作为安全和危险的阈值;文献[8]中提到ITTC也是评价驾驶危险等级的重要指标,并且给出了一个行业比较公认的在城市非拥堵道路上的TTC的阈值为3.5 s(ITTC=0.28),极限碰撞危险的TTC阈值为2.0 s(ITTC=0.50)[9].
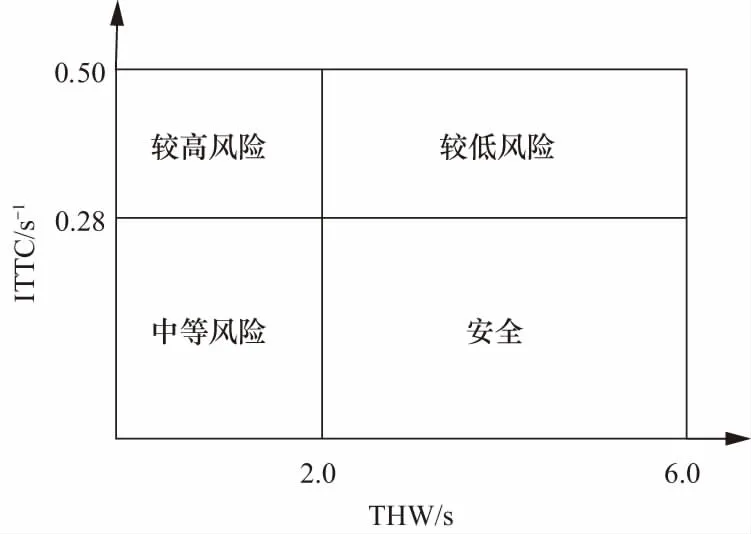
图4 阈值分区图
3 驾驶风格评价系统
3.1 客观性得分系数
本文运用客观性得分系数(简称“得分系数”)来表征驾驶员的驾驶风格激进程度.将所获得的4种危险等级各自所占比例带入式(3)中即可求出SCO值,该值越大,则代表采样期间的驾驶风格越激进,驾驶危险性越高.
fSCO=(WsPs+WlPl+WmPm+WhPh)/3
(3)
式中:fSCO值是每个驾驶员驾驶风格的客观性得分系数;Ws,Wl,Wm和Wh分别为安全、较低风险、中等危险和较高风险4种等级对应的得分权重,其赋值为Ws=0,Wl=1,Wm=2,Wh=3,该权重的给定是一个主观化的评价过程,目的主要在于能够区分安全、较低风险、中等危险和较高风险4种等级在得分上的相互大小关系,同时由于在SCO值运算中包含了归一化过程,因此权重具体取值不影响最后结果表达;Ps,Pl,Pm和Ph分别为安全、较低风险、中等危险和较高风险4种等级出现的时间在整个行程中所占的百分比.
权重赋值的合理性体现在:当较高风险等级的所占比例最高时(100%),SCO值等于1;当安全等级所占比例最高时(100%),SCO值等于0,保证了SCO值的取值在0~1之间,且随着较低风险、中等风险和较高风险3种等级比例增加,SCO值也会变大,故其能够反映出驾驶的激进程度.
从图5频次分布直方图中可以看出,对于这224辆车,随着SCO值从0向1逐渐增大,对应SCO值出现的频次是在显著下降,此现象也符合现实中的实际驾驶情况,对于在公路上安全正常的驾驶过程而言,其安全等级和较低风险等级所占的比例应该比较高.因此SCO值应该接近于0的频次较多.
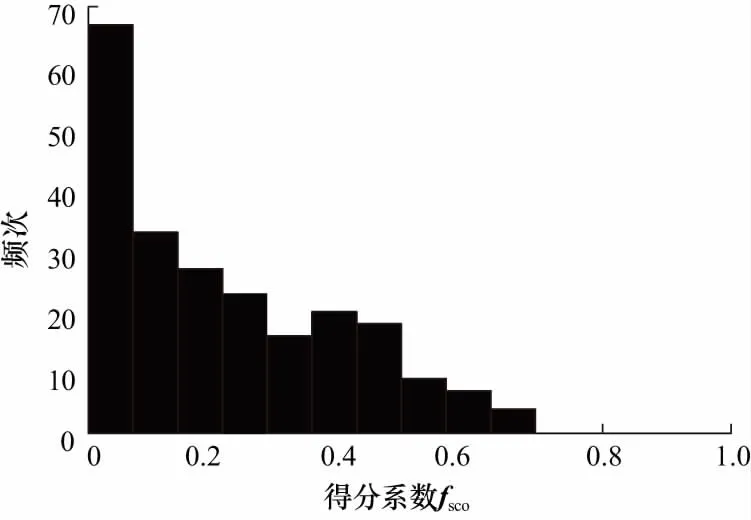
图5 SCO频次分布直方图
3.2 K-Means聚类算法
聚类是指给事物赋予标签,寻找同一组内个体之间的一些潜在的相似模式,力图达到数据的自然分组.K-Means是最著名的划分聚类算法,由于使用简便和计算效率高使它在所有聚类算法中使用最广泛.给定某个数据集合和需要的聚类数目k,K-Means算法根据某种规定的距离函数反复把数据分入k个聚类集合中计算,最终实现聚类平方和的最小化.
由于4种驾驶危险等级所占比例之和为1,故可选择其中3个等级作为3维直角坐标系的X、Y、Z轴.根据本文作者先前的研究成果[10],将获得的驾驶风格分为激进型、普通型和温和型3类比较合理,运用K-Means算法聚类后,处理获得的数据点3维空间聚类分布如图6所示,聚类中心如表1所示.
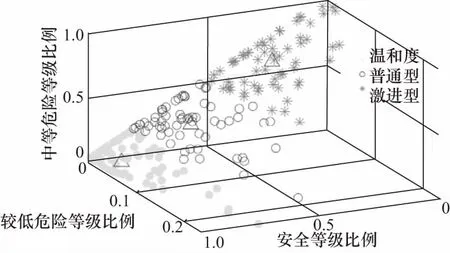
图6 数据点三维空间聚类效果分布
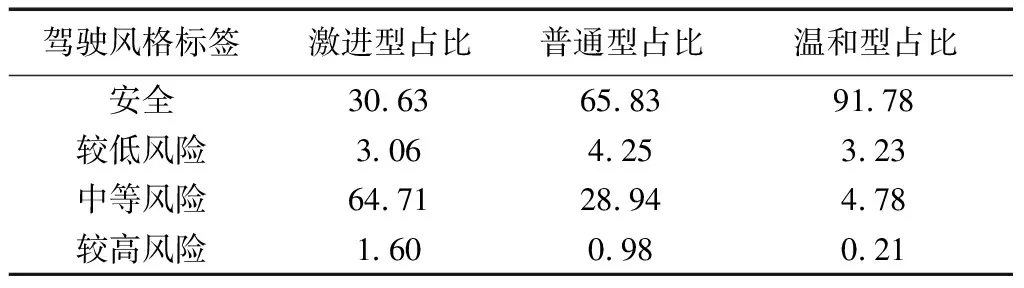
表1 聚类中心的SCO值
从表1中可得3种等级驾驶风格对应的聚类中心差异明显,从3种等级所占比例和得到SCO值来看都有明显差异,且符合3种风格特点,也说明了SCO值具有较好的区分度;同时可以得出即使是激进型风格的驾驶员,其驾驶过程中较高风险等级所占的比例也很低,其激进型驾驶风格的体现主要依赖中等风险等级所占比例.
4 结果分析与评价
4.1 决策边界模糊性
聚类算法在其决策边界处容易出现误判,这是聚类算法的弱项.处理获得的SCO值聚类效果如图7所示.
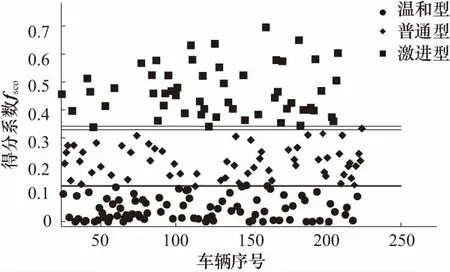
图7 SCO点空间聚类效果分布
虽不可避免会出现一些交叉,但交叉程度不高,且即使出现了交叉对后续的控制过程影响并不会很大,交叉区域的情况如表2所示,不可避免会存在模糊误判的情况,但从表中数据来看进入误判区的数据点比例并不高,所有处于交叉区域的点所占总点数的比例为4.46%,这一结果认为是可接受的.
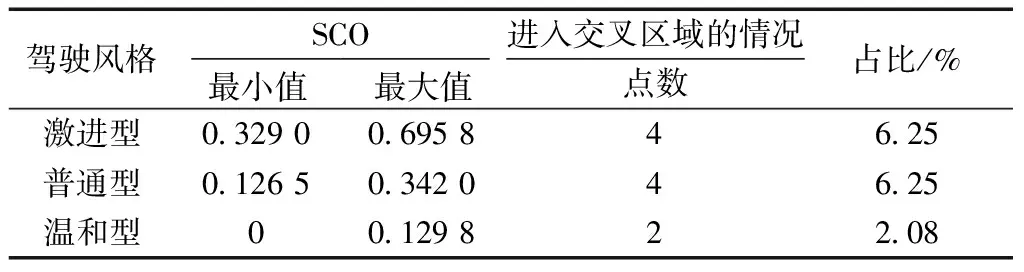
表2 SCO分类交叉情况
4.2 得分系数评价准确性
行业中通常将总体平均值+2σ作为上控制限(up control limits, UCL),总体平均值-2σ作为下控制限(low control limits, LCL)来作为标准差比对的控制限,数据点处于这控制线之间则认为数据是合理的,使用该方法来对比评价SCO值的准确性,结果如图8及表3所示.
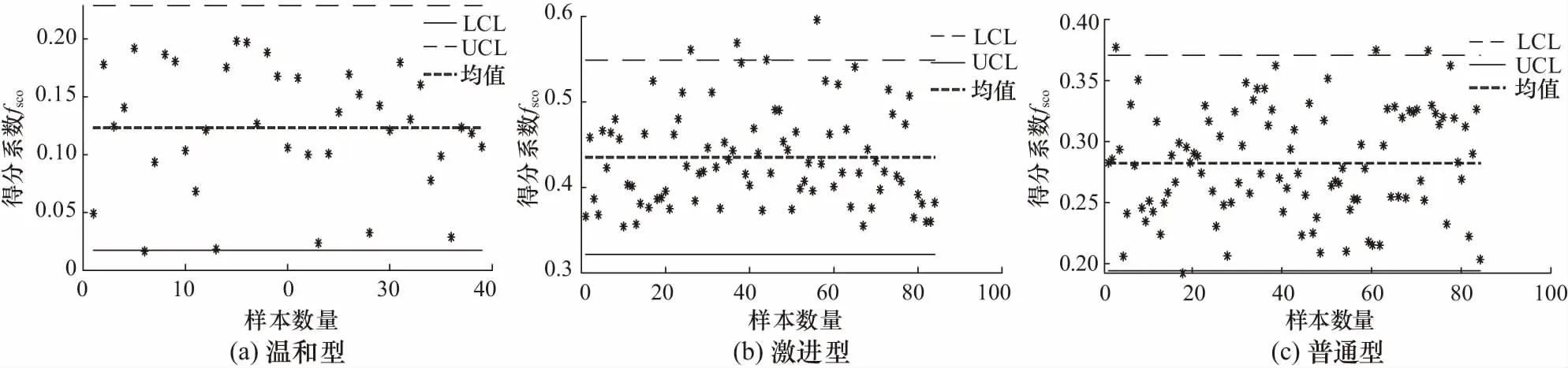
图8 得分系数评价质量控制图
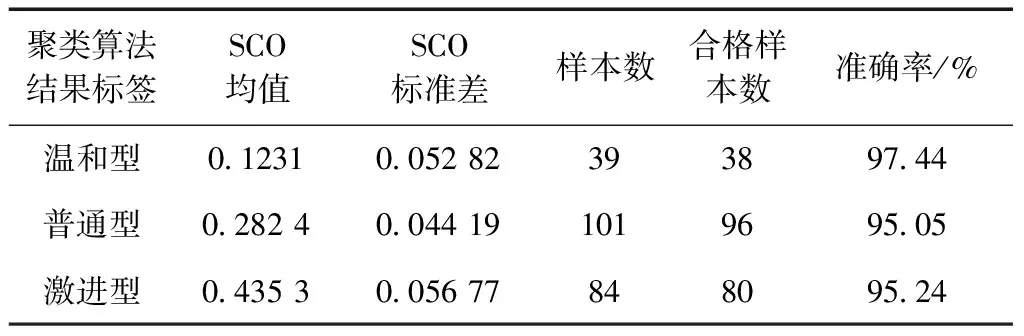
表3 SCO准确性评价结果
从表3知SCO的评价结果和聚类算法的契合度比较好,3种类型的样本数总共为224份,合格样本数为214份,总体准确率可以达到95.54%,在类似应用场景中使用支持向量机(support vector machine, SVM)和卷积神经网络(convolutional neural networks, CNN)理论情况下总体准确率可以达到90%以上[11],本文的计算结果符合传统的驾驶风格认知,且准确率较高,对于表征驾驶员的驾驶风格具有显著的实际意义.
4.3 计算速度
实时性对本算法较为重要,代码运算在M2017环境运行(CPU:Intel i7-8750,RAM:8 G),224辆车中最长采样时间为107.6 s,平均采样时间为78.58 s,处理得到SCO所用最长时间为8.18×10-2ms,平均处理时间为4.31×10-2ms,处理所用时间与数据记录时间关系如下图9所示,处理速度能够满足实时性能计算和滚动迭代的要求.
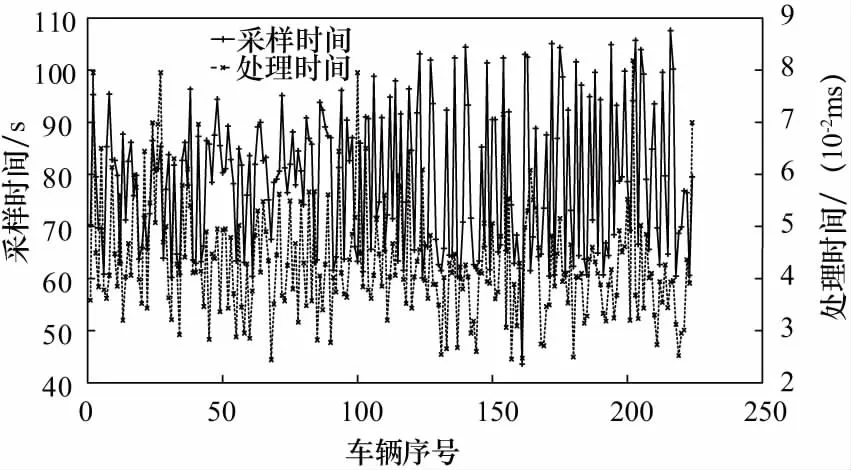
图9 采样时间与处理时间关系
4.4 场景验证
为了进一步验证本文提出的SCO评价方法的有效性,现使用NGSIM数据库中其他数据对前文所述的模型参数来做场景验证,从文献[12]中提到的序号在450~820的370辆车的数据中,筛选了50辆共3 125条处在跟车工况的车辆数据记录作为测试集进行验证,验证效果如图10所示.
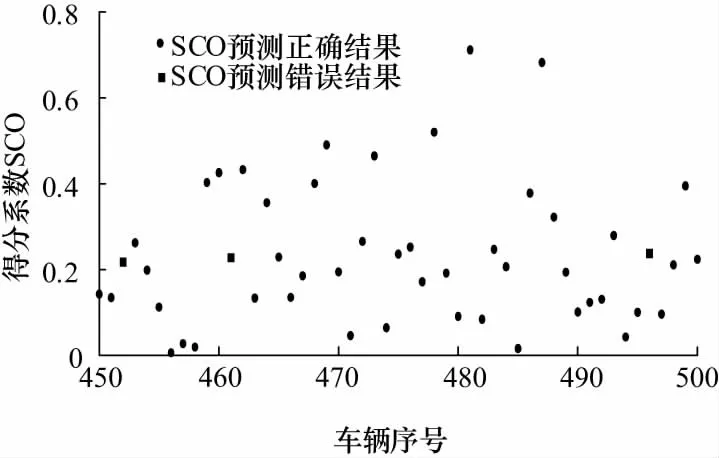
图10 NGSIM跟车工况场景验证效果
结果表明,以文献[13]中的判别结果作为标准参考,SCO评价方法正确预测了47辆车驾驶员的驾驶风格,总体准确率达到了94%,依然保持了较高的预测总体准确率,由此也证明了SCO评价方法在新场景下的有效性.
5 结 论
本文通过采用NGSIM数据库的数据,选用了THW和ITTC两个参数来评价该工况下的碰撞危险等级,针对跟车工况下驾驶的驾驶风格进行了研究.通过建立阈值分区图的方式计算采样数据中4种危险等级各自所占比例,合理加权后便形成了可快速计算的SCO值,在最长采样时间为107.6 s的情况下该方法最长的计算处理时间为8.18×10-2ms,能够满足实时反馈系统滚动实时计算的需求,同时对于结果还使用了K-Means聚类算法以校验SCO值在分类边界处出现误判的情况,结果显示仅有4.46%的数据点被误判;用2倍样本标准偏差作为控制限,来评价SCO值的准确性,结果显示总体准确率可以达到95.54%;将研究所获得的模型参数和评价方法应用于新的数据场景,也可以获得94%的总体准确率.基于本文提出的方法可以构建一套实时易用且有效准确的驾驶风格识别方法,将计算结果反馈给驾驶员以提示其驾驶状态与激进程度,同时SCO值还可以输出并运用到车辆的自动变速系统、电动助力转向系统和自适应主动悬架系统的控制中,以实现更加符合驾驶要求的个性化响应.
