稳健边界强化GMM-SMOTE软件缺陷检测方法
2021-03-31罗森林苏霞潘丽敏
罗森林, 苏霞, 潘丽敏
(北京理工大学 信息与电子学院,北京 100081)
软件目前被广泛用于自动化和操作系统,在软件开发过程中不可避免的会产生功能、算法、交互等多种类型的缺陷(Bug),若未能及时发现软件产品中存在的缺陷而直接上线应用,可能会带来不可预期的后果[1].随着“持续交付模型”的广泛应用,系统、软件的开发日趋快速化与实时化,即时准确地进行自动化软件缺陷检测变得日渐重要.
研究表明,软件是否有缺陷与某些软件度量指标有很强的相关性,例如McCabe度量和Halstead度量等[2].因此,通过提取这些度量指标来构造特征向量,并训练机器学习模型以识别有缺陷的软件已成为行之有效的检测方法,与传统的匹配检测相比,检测速度更快,精度更高[3].但面临着数据不平衡这一挑战,即被人工准确标记了缺陷的正样本稀少,与之相应的则是大量被认定为无缺陷的负样本,由此导致分类器易忽略正类实例特征,使分类结果更倾向将实例判定为负类,引发判别规则偏移问题,降低了软件缺陷的识别精度.如何解决软件缺陷检测中数据不平衡的问题逐渐成为研究热点.
目前针对数据不平衡问题的解决方案主要可分为3大类:数据层面、特征层面和算法层面[4].其中数据层面主要是通过对原始数据进行采样来改变数据的分布状况,改善不平衡情况,可解释性强,与学习算法耦合性低、普适性好,因而在软件缺陷检测领域受到广泛关注.
现有研究中,针对软件缺陷检测中数据不平衡的问题提出了一系列基于采样方法的学习算法.Naufal等[5]使用SMOTE进行数据平衡,并采用模糊关联规则挖掘(FARM)及CFS选择复杂性指标实现软件缺陷检测.Bennin等[6]的研究提出了一种基于染色体遗传学理论的软件缺陷数据集的新型高效合成过采样方法MAHAKIL.Huda等[7]使用不同的过采样技术来构建集合分类器,该分类器可以减少缺陷数据中少数样本的影响.可以看出,在基于平衡化采样的软件缺陷检测方法中,为避免因欠采样过程删除多数类样本所导致的关键信息丢失问题,研究普遍使用过采样来丰富原始数据中的少数类,一定程度上提高了分类器的判别性能.
过采样方法通常可从数据层面直接解决其多数类、少数类不平衡性问题,广泛应用在各类机器学习任务中[8].随机过采样是最基本的过采样方法之一,通过随机的复制少数类样本,达到类别平衡的目的.随机过采样简单易实现,但是由于只是单纯复制少数类样本,容易导致过拟合.为解决该问题,Chawla等[9]提出了少数类样本合成过采样技术(SMOTE),通过随机选择少数类样本以及其相邻的少数类样本,对其线性插值来生成新样本,可以显著改善过拟合问题.然而该方法中,当噪声点被选中来进行线性插值时,会进一步放大数据中的噪声问题.为此,Georgios等[10]提出了K-means SMOTE方法,利用K-means聚类筛选高置信度样本,可缓解采样过程中的噪声放大问题,但易将边界点视为低置信样本,降低其采样率,模糊分类边界.相反,Han等[11]提出的borderline-SMOTE方法,只在边界附近的少数类样本进行过采样,虽解决了边界模糊问题,但仍会受到噪声影响,限制其稳健性.
综上,现有软件缺陷检测方法在数据平衡过程中,对噪声点、边界点的无区别对待或是不准确区分,是导致训练数据噪声加剧、边界模糊的主要原因,由此限制了后续判别模型的稳健性及准确性.为此,提出一种稳健边界强化GMM-SMOTE方法,通过建立簇内类别比与后验概率约束,精准识别噪声点与边界点,并以此为基础进行加权过采样,实现数据集的优化平衡,提升软件缺陷检测模型的训练及泛化性能.
针对上述问题,提出一种稳健边界强化GMM-SMOTE软件缺陷检测方法,其主要贡献包括:(1)稳健边界强化数据平衡,可在防止判别规则偏移的同时,实现训练数据的噪声抑制及边界强化;(2)在此基础上,构建多种基于集成学习、神经网络的软件缺陷检测模型,并在NASA公开的多个数据集上实验证明该方法的有效性.
1 算法原理
1.1 原理框架
针对软件缺陷检测中数据不平衡问题,通过GMM-SMOTE对训练数据进行稳健边界强化过采样,在平衡优化后的数据集上通过随机森林、XGBoost和多层感知机等分类器进行缺陷检测模型的构建.其中(1)针对SMOTE方法易将噪声点作为种子生成新样本,使噪声加剧的问题,通过高斯混合模型进行聚类,利用簇内约束比进行非噪声可靠样本选择;(2)针对稳健过采样方法易将边界点识别为低置信度样本,降低其采样率而使边界模糊的问题,利用后验概率确定边界点提高其采样率.稳健边界强化GMM-SMOTE软件缺陷检测方法的原理框架图如图 1所示.
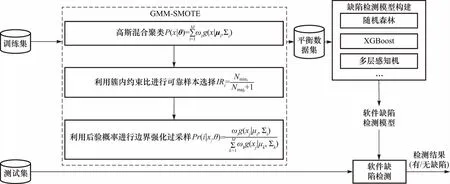
图1 原理框架图
1.2 GMM-SMOTE
软件缺陷中的类不平衡问题会对分类模型的判别性能产生重大影响,对缺陷数据进行预处理,提升训练数据集质量是缺陷检测模型构建的关键初始步骤.GMM-SMOTE是一种处理不平衡问题并提升数据质量的优化算法,该算法可分为3步:高斯混合聚类、可靠样本选择以及边界强化过采样.
1.2.1高斯混合聚类
高斯混合模型(GMM)由于其多峰特性在实际应用中拟合范围广,在理论上能逼近任意分布[12].为挖掘软件缺陷数据分布情况,采用高斯混合聚类方法进行拟合数据结构并进行群集划分.高斯混合模型由M个单高斯分布加权线性组合而成,其样本分布为
(1)
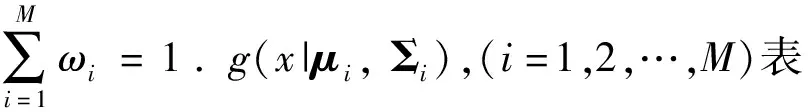
高斯混合模型可以由参数θ=(ωi,μi,Σi)来确定.给定样本数据X={x1,x2,…,xN},通常用极大似然估计来求解模型参数θ.由于似然函数是θ的非线性函数,无法直接对参数求偏导来进行求解,可通过期望最大化(EM)算法[13]来迭代优化.E步根据当前参数来计算每个样本属于每个高斯成分的后验概率,第i个成分的后验概率为
(2)
M步通过固定E步中的后验概率来更新模型的混合系数、均值和方差.
1.2.2可靠样本选择
SMOTE通过对少数类进行线性插值来合成新少数类样本[14],但在对位于多数类样本中的噪声少数类样本进行线性插值时,生成的新样本大概率也是噪声样本,这样就放大了数据中存在的噪声.
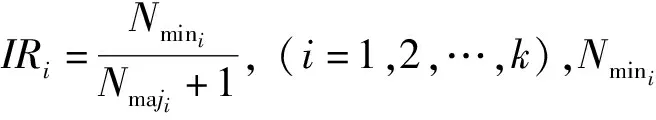
1.2.3边界强化过采样
类别边界上的样本点对分类器分类边界的训练具有很强的指导意义,在采样过程中提高边界点的采样率,将有助于加大模型分类间隔,提高泛化性能.SMOTE算法无法识别边界点,且稳健过采样方法易将边界点视为低置信度样本,产生模糊边界的问题,对后续的训练产生负面影响.为了解决上述问题,GMM-SMOTE利用后验概率来识别边界点并提高其采样率.
设第i个簇内有Nmini个少数类,由公式(2)计算出第j个样本属于第i个簇的概率.根据所得的后验概率计算采样权重
(3)
(4)

综上,GMM-SMOTE算法的伪代码如下.

输入:有噪不平衡数据集D={x1,x2,…,xn},簇数k,不平衡阈值α,采样后样本类别比β,过采样权重上下界max和min输出:低噪平衡数据1.创建组件数为k的高斯混合模型p(x|θ)=∑ki=1ωig(x|μi,Σi),用数据集D进行训练2.fori←1tokdo3.计算簇内少数类样本个数Nmini,多数类样本个数Nmaji4.计算高斯混合模型簇内的类别比IRi=NminiNmaji+1,(i=1,2,…,k)5.whileIRi≥αdo6.依公式(2)计算后验概率,其中j=1,2,…,Nmini7.依公式(3)、(4)计算簇内样本的采样权重8.计算簇内过采样合成需合成的样本数量Ni=(Nmaj-Nmin)βNminiNmin9.根据采样权重进行SMOTE过采样10.end11.end12.return低噪平衡数据
1.3 缺陷检测模型构建
构建基于机器学习的软件缺陷检测模型能够降低缺陷的定位和分析成本,提高缺陷识别性能.在机器学习领域中,随机森林(random forest,RF)、极端梯度提升(eXtreme gradient Boosting,XGBoost)是集成学习中的两种代表性算法,在实际分类任务中具有高扩展性和适用性.多层感知机(multilayer perceptron,MLP)是神经网络模型中的典型算法,通过仿生物神经网络实现在复杂模式或环境下进行自动预测.为了更好的评估GMM-SMOTE在不平衡软件缺陷数据集上的效果,确保结果不受特定分类器的使用约束而具有普适性,将GMM-SMOTE平衡优化后的数据输入到上述3类分类模型中进行训练,构建3种软件缺陷检测模型,以实现软件缺陷识别.
2 实验分析
2.1 采样效果验证实验
为了验证GMM-SMOTE在噪声环境下的稳健性以及边界强化效果,在模拟数据集上将该算法和SMOTE进行比较.数据样本由4簇服从高斯分布的样本组和任意添加的少数类噪声点组合而成,其具体分布为
μ1=[0 0]T,μ2=[6 6]T,
μ3=[11 6]T,μ4=[0 8]T,

其中少数类占比为20%,多数类占比80%.原始数据如图2所示.
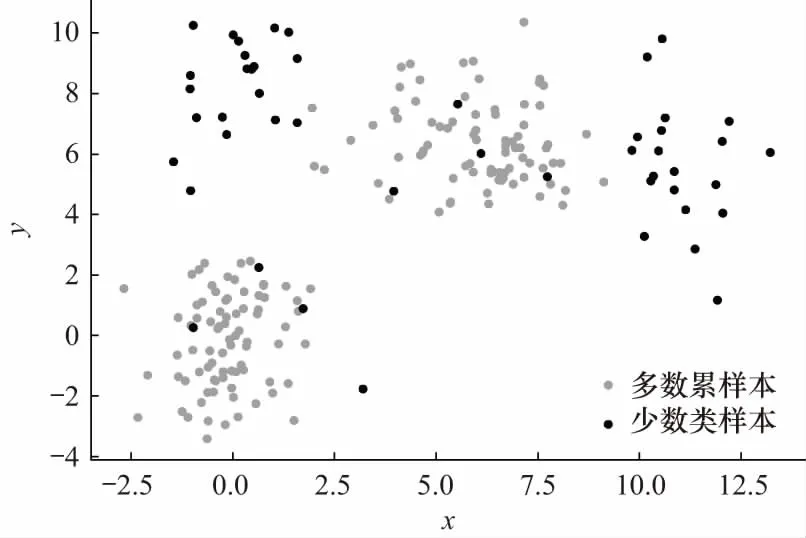
图2 原始数据分布
将原始数据分别用SMOTE和GMM-SMOTE进行过采样处理,采样后样本类别比设为1,其结果如图 3所示,其中用黑色“x”表示生成的少数类样本.从图 3(a)可以看出,SMOTE方法会对少数类噪声样本进行插值合成新的噪声数据,且随机选择采样样本使得生成的少数类整体上密度均匀.由图 3(b)可知,GMM-SMOTE有效的避免了噪声数据的产生,且该方法可提高边界样本的过采样率,使边界部分生成的少数类样本较其他部分更为密集.综上,GMM-SMOTE在噪声环境下的稳健性以及边界强化效果得到验证.
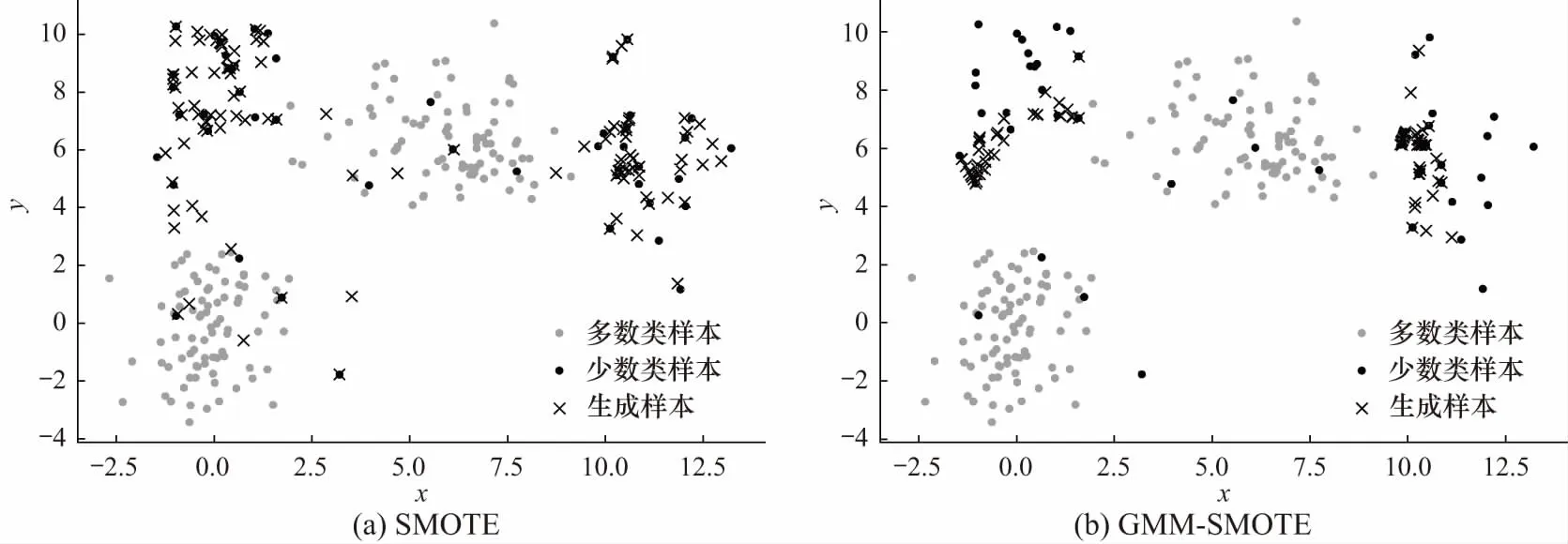
图3 模拟数据集实验结果
2.2 缺陷检测对比实验
2.2.1实验目的
为了验证GMM-SMOTE对软件缺陷检测模型判别能力的提升效果,在7个NASA MDP软件缺陷数据集上将所提算法与SMOTE[9]、BorderlineSMOTE[11]和KMeansSMOTE[10]3种对比算法进行比较.
2.2.2实验数据
实验所选NASA MDP软件缺陷数据集的具体信息如表1所示.数据集涵盖了3种编程语言.每个样本数据由模块属性以及类标签组成.模块属性包括McCabe指标、Halstead指标、代码行数和总操作数等.类标签为是否有缺陷.

表1 NASA MDP软件缺陷数据集
2.2.3评价方法
在分类问题中,常用准确率(accuracy)、精确率(precision)、召回率(recall)、F-measure、G-means和AUC来评估模型.其中F-measure和G-means综合考虑了精确率和召回率,广泛应用于不平衡分类问题.本文采用F-measure和G-means作为评估指标,结果越高,则算法表现越好.
分类的混淆矩阵如表 2所示.其中TP表示将属于正类的样本预测为正类,FN表示将正类预测为负类,FP表示将负类预测为正类,TN表示将负类预测为负类.
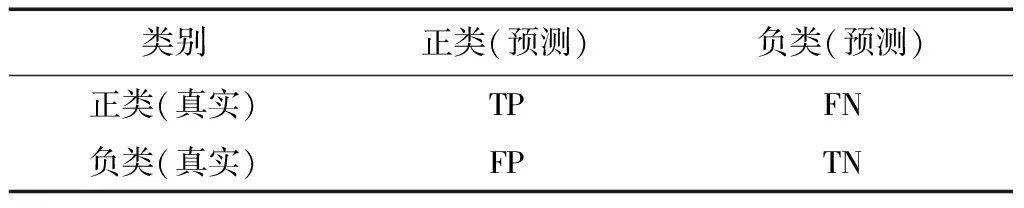
表2 混淆矩阵
F-measure和G-means计算方法为
(12)
(13)
其中
(14)
(15)
γ表示召回率和精确率的重要程度,实验中γ=1.
2.2.4实验过程
将GMM-SMOTE及对比算法在上述7个数据集进行10次交叉验证并取其平均结果进行对比分析.实验的具体步骤为:
(1)数据预处理.对数据集中的缺失值进行删除或填补,将数据按7∶2∶1分为训练集、验证集与测试集;
(2)对训练集进行过采样.不平衡阈值α设置过低,则易将噪声点忽略,若设置过高,部分正常样本将无法被选中进行过采样,根据数据集的类别比例,将α设为0.05.采样后样本类别比β设为1.根据BIC和AIC来确定高斯混合模型的最佳组件数k;
(3)构建软件缺陷检测模型.随机森林中决策树个数设为100.XGBoost学习率为0.025,树最大深度为4.多层感知机的隐藏层为2层,神经元个数需根据验证集表现进行调整;
(4)性能评估.在测试集上对模型进行测试,使用F-measure和G-means对模型性能进行评估.
2.2.5实验结果
实验结果如表3所示.

表3 NASA MDP数据集实验结果
实验结果表明:(1)使用GMM-SMOTE对软件缺陷数据集进行过采样后,相同模型在F-measure和G-means两个评价指标上的整体表现优于其他对比算法,且在使用随机森林和XGBoost作为分类器时,该算法在全部数据集上有效地提升了分类算法的判别性能;(2)MLP相较有一定抗不平衡能力的集成学习方法提升更显著,验证了该算法对有噪不平衡数据的过采样效果.
为了更好地比较算法的性能,对共21组实验结果进行统计排名,所提算法及对比算法实验结果排名前n位的比率如图 4所示,可以看出,GMM-SMOTE在F-measure和G-means指标下Top-1和Top-2的比率均排名第1,性能优于对比算法.
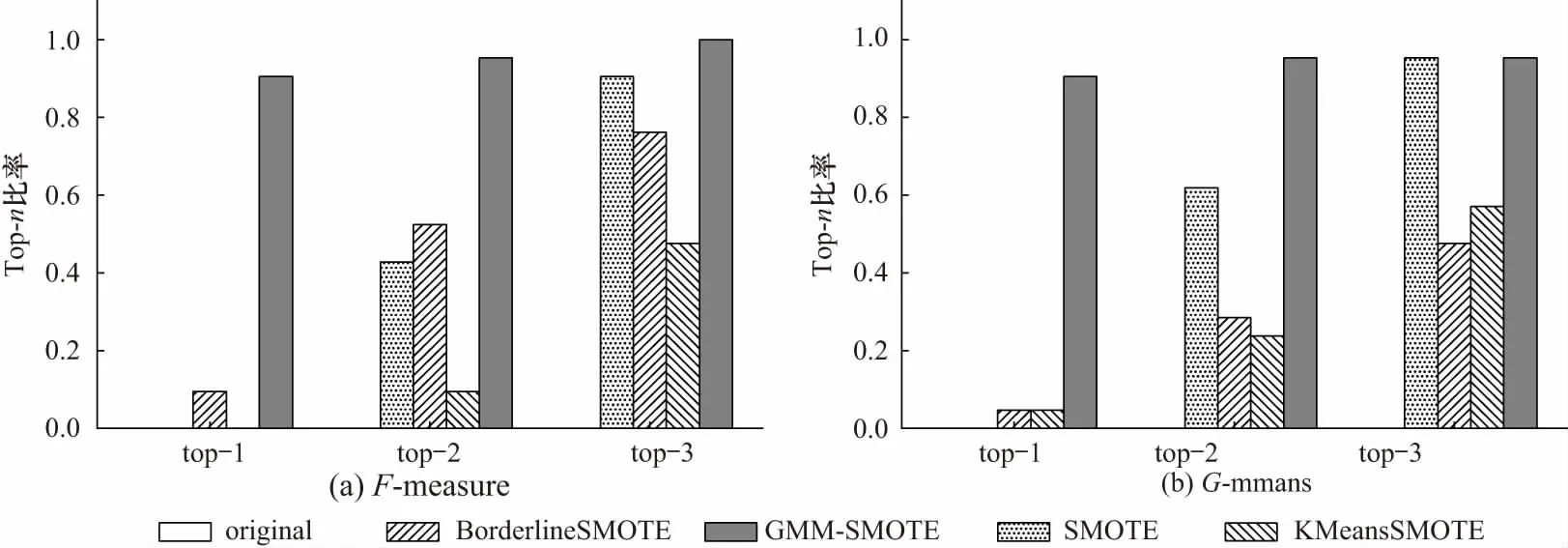
图4 各过采样算法结果统计排名
3 结 论
提出一种稳健边界强化GMM-SMOTE软件缺陷检测方法,该方法采用高斯混合模型对不平衡训练数据进行聚类,根据簇内类别比约束准确筛选可靠样本点用于数据生成,同时利用后验概率识别边界点,提高其过采样率,实现了稳健边界强化过采样,并建立了软件缺陷检测模型.实验首先在模拟数据集上验证了GMM-SMOTE的稳健性和边界强化效果,然后将GMM-SMOTE同SMOTE、BorderlineSMOTE和KMeansSMOTE等过采样算法在7个NASA MDP数据集中进行对比实验以评估该算法对软件缺陷检测模型判别能力的提升效果,依据F-measure和G-means两个指标进行评价,结果表明,GMM-SMOTE有效提升了软件缺陷检测模型的判别能力.
软件缺陷检测方法的研究具有重要的实际应用价值,所提方法通过引入高斯混合聚类,对软件数据进行分布与归属估计,有效发现了高可靠性及边界样本,解决不平衡问题提高软件缺陷识别能力.但随着软件缺陷数据维度增加,数据的不平衡处理难度增大,因此下一步的研究重点是扩展该方法以适用于高维软件缺陷数据.
