基于集合运算特征提取及Stacking策略的新闻多分类方法
2021-03-27李金忠
曾 寰,李金忠,付 青
基于集合运算特征提取及Stacking策略的新闻多分类方法
*曾 寰,李金忠,付 青
(井冈山大学电子与信息工程学院,江西,吉安 343009)
文本分类是机器学习重要任务之一,如何对文本信息进行有效分类组织,对用户查找并获取有用信息具有重要作用。针对新闻文本分析,提出了一种基于集合运算特征提取及Stacking策略的新闻多分类方法,该方法基于集合运算的方法来提取文本特征,采用Stacking策略,使用SVM以及贝叶斯方法来对文本进行分类。与典型同类方法对比,在复旦大学文本分类数据集上的实验结果表明,该方法随着样本数增加,各分类指标逐渐升高并趋于稳定。
文本分类,新闻,集合运算,Stacking策略
随着互联网大数据的发展,文本信息数据量也随之急剧增长,如何对文本信息进行有效分类组织,对用户查找并获取有用信息具有重要作用。在文本信息中,新闻类文本是比较容易获取的文本信息形式,是用户了解并跟踪社会发展重要手段之一。相比于传统纸质媒体信息,互联网上新闻文本信息具有种类多、数据量庞大的特点。因此,利用程序对这些新闻进行筛选和分类,对减少人力资源,快速有效获取有价值信息,提升信息使用效率具有重要作用。程序自动文本分类以统计学理论为基础,利用提取的已知语料库的特征,学习并得到给定样本特征和类别间的关系模型,然后根据这个模型来预测用相同特征提取技术提取未知文本特征类别的过程。
文本分类包含以下过程:文本预处理阶段对文本进行分词、去除停用词;特征提取阶段使用一定方法对文本的特征筛选,得到适合分类的特征;文本表示阶段使用特定的文本表示模型,对特征进行特征权重计算;然后使用语料对可能采用的机器学习算法进行训练和评估;之后挑选出最优的分类算法对新来的文本进行分类。过程如图1所示。

图1 文本分类流程
常用的特征选择方法有:文档频率(Document Frequency,简称DF),卡方检验(CHI),信息熵与信息增益,互信息(MI)等。实验发现,对比这些常用特征选择方法,采用文档频率的方法的分类效果更好[1]。某一文档,当某一词语在其中出现次数较多时,说明该词语与其关联很大,也就是在给定该文档下该词语出现的条件概率很大;但是当该词语存在于很多文档中时,则说明该词语对于该文档的关联性小,也就是该文档与该词语的联合概率小。因此,文档的重要性与该词在文档中的频率(Term Frequency,简称TF)成正相关,与存在的文档数目成负相关(Inverse Document Frequency,简称IDF)。常用的特征权重的计算方法包含:布尔权值法,基于特征频率(TF)和逆文档频率(IDF)的TF-IDF方法。唐明等[2]提出使用TF-IDF方法生成文档词权重,使用word2vec生成文档词向量的方法来对中文文本进行分类,结果显示,该方法相较于均值word2vec方法有明显提升,与doc2vec方法效果相当。
当前应用比较广泛的文本表示模型有词袋法(Bag-of-Word,BOW)和向量空间模型(Vector Space Model,简称VSM)。词袋法将文档看成一些相互独立的词的集合,它不考虑文档中词之间顺序、语义和语法的信息。词袋法将一篇文档表示成与训练词汇集合相同维度的向量,向量中每个位置的值即是该位置所代表的词在文档中出现的次数,并且随着新词汇的增加,文档向量维度也会增加。词袋法生成的文档向量存在维度过高(“维数灾难”)、过于稀疏及无法表示文档语义的问题。为了解决词袋法包含的问题,研究者们开始使用基于神经网络的向量空间模型来进行单词的向量化,词向量(Distributed representation)最早由Hinton[3]提出,通过将词映射到一个低维、稠密的实数向量空间中(空间维度大小一般为100或者200),使得相近的词在空间的距离越近。Mikolov等[4]提出word2vec语言模型能快速有效的训练词向量。2014年,Mikolov等[5]提出doc2vec语言模型,该模型能直接将句子或段落转换为固定维度的文档向量。Doc2vec语言模型是一种无监督的学习方法,它能很好地结合文档的上下文语境,词语及段落的语义信息,能减少词袋法忽略语序及词语歧义问题对分类的影响。
目前文本分类的算法很多,根据其模型可以分为概率模型如决策树、朴素贝叶斯、隐马尔科夫等,线性模型如感知机、线性支持向量机、k近邻等,非线性模型如核函数支持向量机、神经网络、集成学习算法。深度学习算法是复杂的神经网络算法[6],因此也归为复杂的非线性模型。Wang等[7]证明选择使用合适的特征表示方法,线性分类器也能取的很好的分类效果,而且包含更多信息量的二元词组相较于单元词的分类效果会更好。
1 基于集合运算特征提取及Stacking策略的新闻多分类方法
1.1 基于集合运算的特征提取
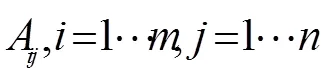
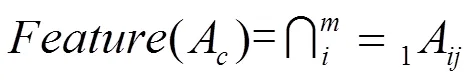
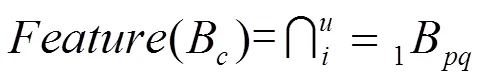
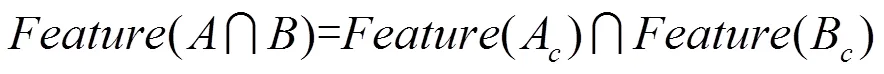
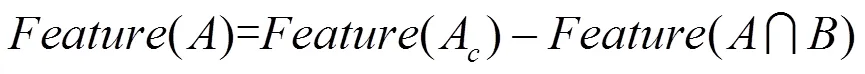
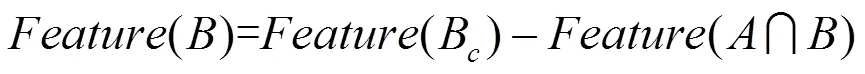
具体运算过程如图2所示。
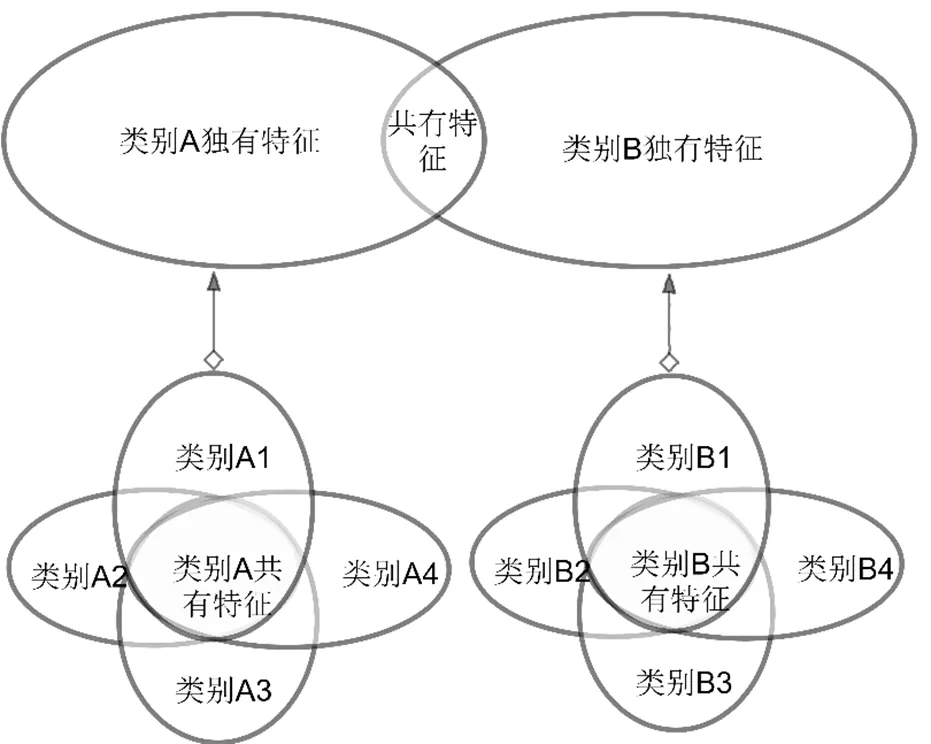
图2 基于集合运算特征提取过程
1.2 Stacking策略
1.3 基于集合运算特征提取及Stacking策略的新闻多分类方法流程图
基于集合运算特征提取及Stacking策略的新闻多分类方法流程包含输入,特征提取,特征表达,模型训练及输出五个阶段,特征提取阶段包含文本预处理即文本清洗(分词,去停用词),之后使用基于集合运算的方法选取特征;接着分别使用词袋模型、词向量模型和TF-IDF模型表达特征,最后使用特征训练模型,本文挑选的算法为支持向量机(SVM)和贝叶斯算法采用Stacking来对文本特征进行训练。具体流程如图3所示。
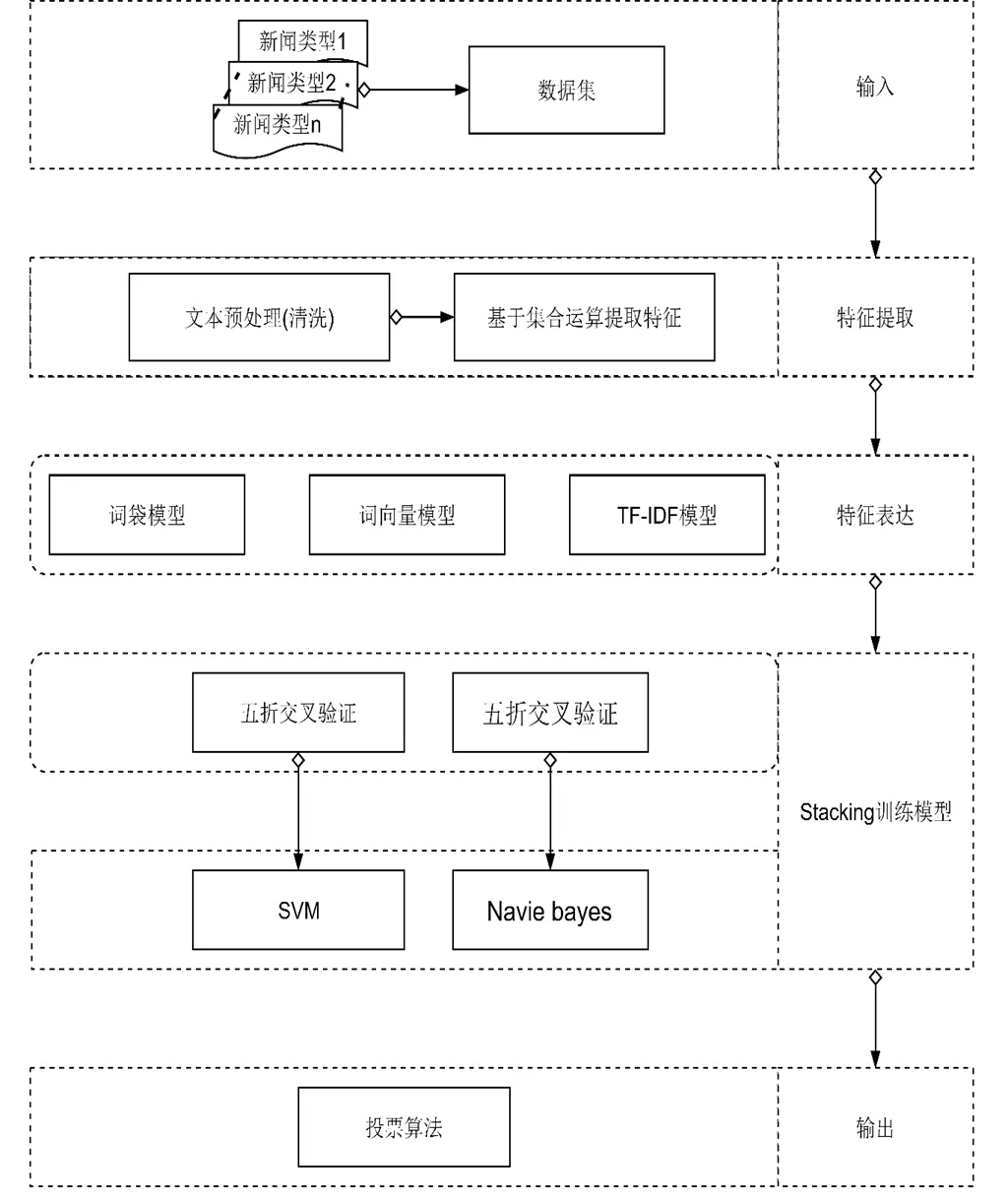
图3 算法流程图
2 实验
2.1 实验环境及数据集
为了验证算法,本文所采用的实验环境为Python3.7,实验使用由复旦大学李荣陆提供的文本分类语料库1http://www.nlpir.org/wordpress/category/corpus/,answer.rar为测试语料,共9833篇文档;train.rar为训练语料,共9804篇文档,分为20个类别。为了便于分析我们将测试语料(answer.rar)和训练语料合并为同一个语料,总计19637篇文档,语料库的类别及对应类别的文档数分布情况如表1所示,在表1中Total number表示样本总数。
表1 数据集各类别分布信息
Table1 Data set distributes by category
DatasetNumberDatasetNumberDatasetNumber Space1282Economy3201Art1482 Energy65Law103Environment2435 Electronics55Medical104Agriculture2043 Communication52Military150Education120 Computer2715Politics2050Philosophy89 Mine67Sports2507History934 Transport116Literature67Total number19637
2.2 评价指标
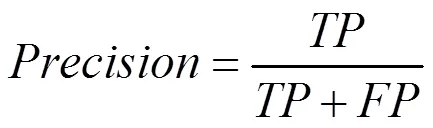
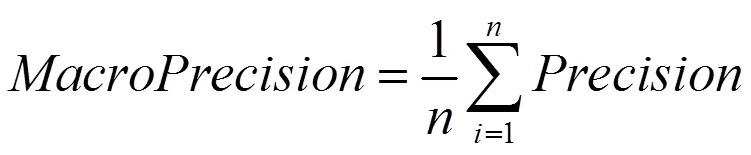
2.3 数据清洗阶段
实验使用jieba2https://github.com/fxsjy/jieba进行分词;使用的停用词表由中文停用词表(cn_stopwords),哈工大停用词表(hit_stopwods),百度停用词表(baidu_stopwords),四川大学机器智能实验室停用词表(scu_stopwords)去除重复合并而得,总共包含2690个停用词;在生成词向量上使用的word2vec模型[9]为公开发布的中文词向量模型3https://github.com/Embedding/Chinese-Word-Vectors,该模型生成的词向量为300维,最后进行加权平均求得文本词向量。
2.4 训练集大小的影响
为了对比算法在不同特征表示及在训练集不同样本数量上的分类效果,实验对语料库进行训练集和测试集划分时,首先将语料库按8/2比例划分为训练集和测试集,保持测试集不变,将训练集等分为10份,然后依次以10%,20%,…,100%的训练集对算法进行训练。考虑到数据集不同类别上数量的差异,如果对数据集随机划分,会使得有些类别数量非常小甚至可能没有,所以实验实际是对各类别按比例划分,再将其组合成最终的训练集和测试集。
2.5 算法对比实验
为了对比基于集合运算特征生成策略在使用算法在不同特征表达上的分类效果,实验使用的参照分类算法包含:贝叶斯算法(Navie bayes),SVM算法分别在One Hot,TF-IDF,word2vec特征表示上的分类效果。之后在此基础上结合Stacking策略再对比各算法的分类效果。
2.6 实验结果及分析
在特征提取上,基于集合运算的特征提取,该方法适用于提取新闻各类别样本的所具有的独有特征,比如关于计算机的词汇常涉及处理器,内存,显卡,驱动等,由于篇幅限制,表2列出5个新闻类别的部分词汇。
表2 5个不同新闻类别的部分词汇列表
Table2 A partial words list of five different news categories
类别词汇 C16-Electronics'解码板', '高亮度', '插件机', '韩国三星电子', '张东文', '一抢而光', '压题', '肖克莱', '陈坤林', '赵志文', '传捷报', '中晨', '华晶', '沈孝泉', '天利', '张祖忠', '硅超', '华越', '超低压', '岭上', '电子装置', '四通公司', '山不转', '外三层', '揭幕典礼', '电饭锅',… C32-Agriculture通州区', '工按', '以和苗', '不言而谕', 'ProtectionClarendon', '平武', '赵仲实', '晚耘', '指小块', '排不出', '仍种', '粳交', '串友', '出乡', '茶市', '曾剑秋', '粮不慌', '黄羊', '油茶籽', '玫瑰油', '肆处', '病均系', '砂农', 'FARM', '集产', '刘河', '安微', '今言', '方开炳', '将露', '石亚兰', '忽闪', '船大', '俱准', '再拉回', '广水', '焦磷酸', '田国忠', … C36-Medical‘临桂县', '作开', '麻醉师', '王国瑞', '黄度', '子宫颈', '造产围', '日公', 'ss002003bfn', '樊英利', '弧形导', '董玉翔', '徐机玲', '苏连峰', '杜新', '脉管炎', '生精散', '对麻', '麻疹', '西红', '二医大', '以针''类风湿', '激光治疗', '牛肝', '易消化', '粉针', '难星村', '角膜', '产羔', '津华', '孕产妇', '艾罕', '生瓜娃', '王成标', '杰尼索夫', '基层医院', '看病难',… C37-Military‘直升机', '常规裁军', '2000H', '八吨', '物会', '建到', '制敌于', '275in', '磅湛', '航空史', '加莱亚诺', '徐帅', '分列式', '第四群', '印两国', '惊险刺激', '阿里亚斯', '中型机', 'MICA', '共携有', '旅将', '母舰', '南划', '27R', '古巴共产党', '亚喀巴湾', '圣萨尔瓦多',, '已达全', '区和国', '有舰', '起筹', '巴向', '一百架', '团级',… C39-Sports'后攻', '应给些', '鉴拔', '降钙素', '性赛', '书写能力', '竿子', '左右脚', '五七个', '岷友', '操典', '代谢率', '握力器', '少佐', '一醉', '呕逆', '汩罗连', '练身', '不夜城', '跳及', '早惠', '关山重重', '徐恩芳', '别校', '第四站', '我委从', '区佳胤', '教则', '徐德', '中夺', '渤油', '王万明', '报到', '七万余', '脑前', '握力', '三幢', '存立', '新线路', '为费佳编', '肌酸', '麻重', '增分', '芦城', '书屏', '时随', '榜发', '攻达', '大妻', '李化树', '外语成绩', '品和餐', '石鸿翥', '泛为', '不可教', '收阅', '吸震', '维迪', '如背', '女足赛', …
经过实验分析发现,在新闻文本分类中,随着训练样本的逐渐增加,在特征表示上TF-IDF表示在宏平均精确度,准确率,f1指标优于One-Hot及VSM表示,在召回率(recall)表示上One-Hot最优。在对比算法在训练样本数量的变化趋势上,基于实验所用的语料库可以看出,各算法在样本数量小时,各指标表现差,随着样本数量的增加,各指标会随之而优,到一定阶段逐渐趋于稳定。具体各指标随样本数变化如图4所示。
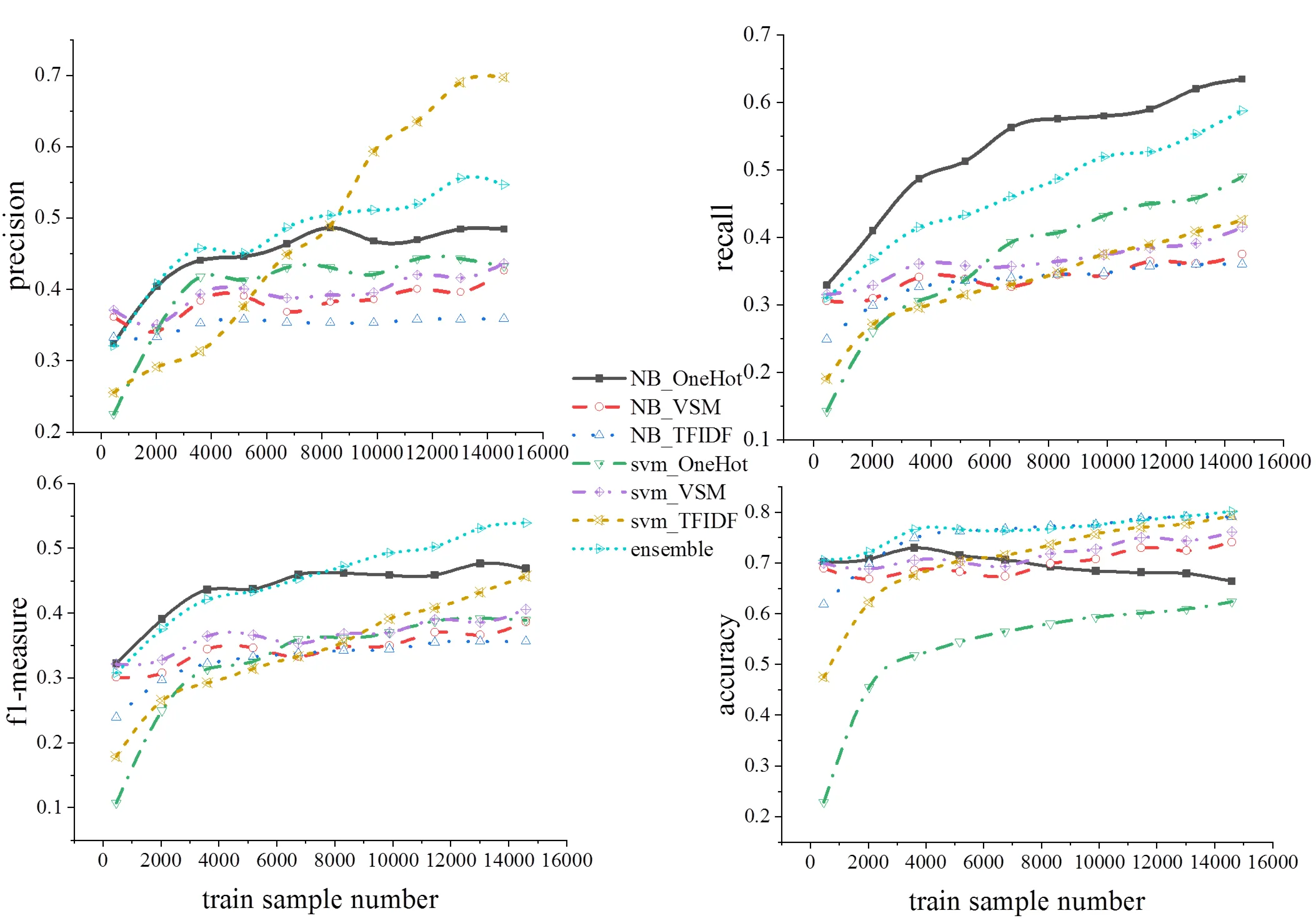
图4 各指标随样本数变化
3 结论
本文提出基于集合运算特征提取及Stacking策略的新闻多分类方法,该算法适用于提取各类别样本所具有的独有特征,当新闻类别之间样本需提取的特征存在重合且分布不平衡时,该方法不适用。当前的很多算法模型都是基于概率的方法进行挑选文本特征,其优点是不至于在文本特征上存在遗漏。基于集合的运算方法同时在健壮性上优势不够,当不同类别样本之间的特征存在干扰时,会使该特征在做集合差集运算时被筛选掉。后期考虑采用概率的方法来对算法进行改进。
[1] 魏韡,向阳,陈千. 中文文本情感分析综述[J]. 计算机应用, 2011, 31(12):3321-3323.
[2] 唐明,朱磊,邹显春. 基于Word2Vec的一种文档向量表示[J].计算机科学,2016,43(6): 214-217.
[3] Hinton G E. Learning distributed representations of concepts.[C]. Eighth Conference of the Cognitive Science Society, 1989:46-61.
[4] Mikolov T , Chen K , Corrado G , et al. Efficient Estimation of Word Representations in Vector Space[J]. Computer Science, 2013:1-12.
[5] Le Q V , Mikolov T . Distributed Representations of Sentences and Documents.[C].Proceedings of the 31st International Conference on Machine Learning (ICML-14), 2014:1188-1196.
[6] Joulin A , Grave E , Bojanowski P , et al. FastText.zip: Compressing text classification models[J]. arXiv preprint arXiv:1612.03651.
[7] Wang S I, Manning C D. Baselines and bigrams: Simple, good sentiment and topic classification[C].Proceedings of the 50th Annual Meeting of the Association for Computational Linguistics, 2012: 90-94.
[8] 冉亚鑫,韩红旗,张运良, 等.基于Stacking集成学习的大规模文本层次分类方法[J].情报理论与实践,2020, 43(10):171-176,182.
[9] 王国薇,黄浩,周刚, 等.集成学习在短文本分类中的应用研究[J].现代电子技术,2019,42(24):140-145.
[10] Qiu Y Y. Revisiting Correlations between Intrinsic and Extrinsic Evaluations of Word Embeddings[C]. Chinese Computational Linguistics and Natural Language Processing Based on Naturally Annotated Big Data. Springer, Cham, 2018: 209-221.
A MULTI-CLASSIFICATION METHOD OF NEWS CLASSIFICATION METHOD OF NEWS BASED ON SET OPERATION FEATURE EXTRACTION ON STACKING STRATEGY
*ZENG Huan, LI Jin-zhong, FU Qing
(School of Electronics and Information Engineering, Jinggangshan University, Ji’an, Jiangxi 343009, China)
Text classification is one of the important tasks in machine learning. How to classify and organize text information effectively plays an important role in user information retrieval. For news text analysis, a multi-classification method of news based on set operation feature extraction and stacking strategy was proposed. The method, firstly uses set operation to extract text features, then uses stacking strategy, SVM and Bayesian method to classify the text. Compared with the typical similar methods, the experimental results on text classification data set of Fudan University show that, with the increase of sample size, the classification indexes of this method gradually increase and tend to be stable.
text classification; news; set operation; stacking strategy
YP391
A
10.3969/j.issn.1674-8085.2021.02.012
1674-8085(2021)02-0070-06
2020-12-07;
2020-12-28
国家自然科学基金项目(61762052);江西省教育厅科技计划项目(GJJ180574);江西省高校人文社科项目(JC19235)
*曾 寰(1990-),男,江西吉安人,实验师,硕士,主要从事数据挖掘研究(E-mail:584251395@qq.com);
李金忠(1976-),男,江西吉安人,副教授,博士,主要从事机器学习研究,(E-mail:23408545@qq.com);
付 青(1990-),男,江西抚州人,实验师,硕士,主要从事测绘科学与技术研究(E-mail:707624371@qq.com).
