《证据体中受试者结局数据缺失相关偏倚风险的评估》文献解读
2021-03-12罗双红
罗双红
1 问题、现状和解读目的
评价受试者结局数据缺失(简称缺失数据)相关的偏倚风险在多大程度上降低对证据体某特定结果的信心,即缺失数据对证据质量的影响,是系统评价中的关键问题之一。Cochrane手册应对这一问题的方案侧重于判断单个研究缺失数据偏倚风险的“高”、“低”或“不清楚”,并鼓励在针对证据体某特定结局指标统计的Meta分析中基于不同假设进行敏感性分析。但是这种方案难以评价单个研究缺失数据偏倚风险对整个证据体证据质量的影响,就如何在Meta分析中基于不同假设进行敏感性分析也无具体指导,这涉及考虑缺失数据多少、干预组和对照组中的事件发生率、缺失数据的分布以及数据缺失的原因等多种现实因素。
为给系统评价中证据体二分类变量和连续性变量缺失数据相关的偏倚风险判断提供方法学指导,GRADE 工作组组织有丰富的系统评价工作经验的临床流行病学、方法学和生物统计学家组成研究小组,进行系统的文献调查[1-3],复习和评价目前所有的Meta分析时处理缺失数据的可能方法,迭代式讨论并在已有的系统评价案例中测试评价过的方法,筛选出最合理的处理缺失数据的方法[4-6],并通过2次会议对前期研究赞同的方法再次评价和修订,最终产生判断证据体缺失数据相关偏倚风险的GRADE方法[7]。为帮助临床医生理解GRADE方法,以便更好地理解临床实践循证指南的证据质量,现将其介绍并解读如下。
2 方法介绍和解读
2.1 方法的应用范围及相关定义 该方法用于临床试验数据的Meta分析,不适用于系统评价人员可获得的个体水平数据的Meta分析;且仅用于处理缺失数据相关偏倚风险的判断,不涉及系统评价中的其他偏倚风险判断。
在GRADE方法中,“缺失数据”指系统评价人员不能获得的受试者结局数据,包含两类数据:①原始研究人员无法获得的数据;②原始研究人员可以获得,但既未发表也未能提供给系统评价人员的数据。处理缺失数据首先需确定一组受试者是否有缺失数据(例如,撤回同意或违反治疗方案的受试者),而困难在于原始研究作者有时不清楚应如何报告并在统计分析中处理缺失数据(例如,排除缺失数据的受试者或对缺失数据做出假设)。因此GRADE工作组强调在进行受试者结局数据缺失相关偏倚风险评估前应尽一切可能从原始研究作者那里获得未报告但可能可用的结局数据,或者至少了解他们是如何处理缺失数据的。
GRADE方法中专门指出“缺失数据的处理”不同于意向性分析(ITT)。其理由如下:ITT强调按被随机分配的组别分析受试者数据,其就“受试者数据分析”的定义存在不同。有人认为ITT分析只在没有失访的情况下才可能实现;有人认为ITT分析需要填补缺失数据;还有人认为ITT分析应仅限于分析有可用数据的受试者,而缺失数据应作为一个单独的问题来处理。GRADE工作组是将缺失数据作为一个单独的问题放在敏感性分析中解决。
2.2 方法的基本思想/逻辑
2.2.1 确定主分析 GRADE方法只纳入有数据的受试者进行Meta分析的主分析;如果对缺失数据相关偏倚的方向和大小很有把握,也可以将直接填补后的结果作为主分析。
2.2.2 数据填补及敏感性分析 对于主分析显示试验组干预措施有益且统计学上效果显著的结果,敏感性分析的目的是检测“针对某特定的结局指标,试验组干预措施确实有益且效果显著”这一推断的稳定性。具体方法是在纳入的原始研究中进行一系列逐步严格的缺失数据填补,即假设缺失数据受试者的结果比数据可用受试者的结果更不利于显示试验组干预措施有效,且这种倾向性逐步增高,则逐次对经不同倾向性填补后的各项研究进行Meta分析,观察不同倾向性数据填补对Meta分析结果点估计和区间估计的影响。
对于主分析显示试验组干预措施有害且统计学上效果显著的结果,可以进行类似的敏感性分析检测“针对某特定的结局指标,试验组干预措施确实有害且效果显著”这一推断的稳定性。即假设试验组缺失数据受试者不良事件的发生率比同组数据可用受试者更低,和/或对照组缺失数据受试者不良事件的发生率比同组数据可用受试者更高,且这种倾向性逐步增高,则逐次对经不同倾向性填补后的各项研究进行Meta分析,观察不同倾向性数据填补对Meta分析结果点估计和区间估计的影响。
依此类推,可以通过假设试验组缺失数据受试者中不良事件发生率高于同组数据可用受试者,和/或假设对照组缺失数据受试者中不良事件发生率低于同组数据可用受试者的敏感性分析来检测“干预措施无害”推断的稳定性;假设试验组缺失数据受试者中有益事件的发生率高于数据可用受试者,和/或对照组缺失数据受试者中有益事件的发生率低于数据可用受试者的敏感性分析来检测“干预措施无益”推断的稳定性。
2.3 二分类变量结果缺失数据的处理 传统的缺失数据处理采用极端估计值填补与最差情况演示分析的方法,因缺乏合理性,可适用的临床问题有限。在前述基本思想的基础上,GRADE工作组采用“按率填补”(imputations using ratios)的方式来填补缺失数据并进行敏感性分析,该方式涉及使用RIMPD/FU代表缺失数据填补倾向性的大小,其定义如下:
举例说明如下,并可依此类推。
若以不良事件发生率(如:艰难梭菌感染)为结局指标的主分析显示试验组干预措施(如:益生菌)有益(如:预防接受抗生素治疗患者艰难梭菌感染),则试验组缺失数据按照RIMPD/FU=1.5、2.0、2.5、3.0、···、5.0依次填补,即试验组缺失数据受试者不良事件发生率依次按试验组数据可用受试者不良事件发生率的1.5、2.0、2.5、3.0、···、5.0倍进行填补;和/或对照组缺失数据按照RIMPD/FU=0.7、0.6、0.5、0.4、···、0.1依次填补,即对照组缺失数据受试者不良事件发生率依次按对照组数据可用受试者不良事件发生率的0.7、0.6、0.5、0.4、···、0.1倍进行填补。逐次对不同RIMPD/FU策略填补缺失数据后的研究进行Meta分析,观察随试验组RIMPD/FU不断递增和/或对照组RIMPD/FU不断递减,以不良事件发生率为结局指标计算的“试验组干预措施有益”的效应值(如RR值)结果(包括点估计和区间估计)是否会被反转,并结合临床实际讨论这种反转的情况是否可能出现,以检测“试验组干预措施有益”这一推断的稳定性。若结果稳定,则证据质量不因数据缺失的相关偏倚风险而降级,否则应降低证据质量等级。
若以有害事件发生率(如:心肌梗死、脑梗死等并发症)为结局指标的主分析显示试验组干预措施(如:某种治疗慢性阻塞性肺病的药物)有害(如:增加慢性阻死性肺病患者心肌梗死、脑梗死等并发症风险),则试验组缺失数据按照RIMPD/FU=0.7、0.6、0.5、0.4、···、0.1依次填补,即试验组缺失数据受试者有害事件发生率依次按试验组数据可用受试者有害事件发生率的0.7、0.6、0.5、0.4、···、0.1倍进行填补;和/或对照组缺失数据按照RIMPD/FU=1.5、2.0、2.5、3.0、···、5.0依次填补,即对照组缺失数据受试者有害事件发生率依次按对照组数据可用受试者有害事件发生率的1.5、2.0、2.5、3.0、···、5.0倍进行填补。逐次对不同RIMPD/FU策略填补缺失数据后的研究进行meta分析,观察随试验组RIMPD/FU不断递减和/或对照组RIMPD/FU不断递增,以有害事件发生率为结局指标计算的“试验组干预措施有害”的效应值(如RR值)结果(包括点估计和区间估计)是否会被反转,并结合临床实际讨论这种反转的情况是否可能出现,以检测“试验组干预措施有害”这一推断的稳定性。若结果稳定则证据质量不因数据缺失的相关偏倚风险而降级,否则应降低证据质量等级。
特别说明,RIMPD/FU=5.0是GRADE工作组二次研究发现现有研究同一组别中缺失数据受试者相比数据可用受试者事件发生率的最大倍数[8]。
设计意图: 让学生参与教具的拼装,既帮助学生加深对相关知识的理解,还锻炼了学生的动手能力。同时,模拟抽奖转盘的游戏教学,增强了教学的趣味性,调动了学生的学习热情,打破了传统课堂教学中的沉闷气氛,寓教于乐,有助于活跃课堂气氛。
2.4 连续性变量结果缺失数据的处理
2.4.1 所有原始研究均采用相同方法测量同一结局指标的情况
2.4.1.1 只纳入数据可用受试者进行主分析 当合并估计值具有统计显著性并据此得出某种推断时,则进行敏感性分析,以检测缺失数据对该推断稳定性的影响。连续性变量结果缺失数据处理的难点是需同时估算均值和标准差(SDs)。
2.4.1.2 填补缺失数据均值最具合理性的5类数据源 A.所有纳入试验的试验组中的最佳均值;B.所有纳入试验的对照组中的最佳均值;C.本试验对照组的均值;D.所有纳入试验的试验组中的最差均值;E.所有纳入试验的对照组中的最差均值。
2.4.1.3 填补缺失数据标准差的数据源 GRADE工作组测试了许多用于填补缺失数据标准差的来源,发现填补后产生的结果非常相似,因此GRADE工作组提出所有缺失数据的标准差均采用所有纳入试验对照组标准差中的中位数,这样最为简单、合理。
2.4.1.4 敏感性分析中缺失数据均值的填补策略 针对某特定的结局指标,若因试验组结果值大于对照组且具有统计学显著性,依据结局指标的定义,可能得出试验组干预措施有益、有害、无益或无害的推断,进行敏感性分析时,在纳入的原始研究中进行一系列逐步严格的缺失数据填补,图1显示,即假设试验组缺失数据倾向于干预措施产生的结果值小,并且这种倾向性逐步增高,和/或对照组缺失数据倾向于对照措施产生的结果值大,并且这种倾向性逐步增高,具体数据填补策略如下(表1)。策略1使用数据C填补试验组和对照组中的缺失数据;策略2使用数据D填补试验组中的缺失数据,使用数据B填补对照组中的缺失数据。策略3使用数据E填补试验组中的缺失数据,使用数据B填补对照组中的缺失数据;策略4使用数据E填补试验组数据缺失,使用数据A填补对照组数据缺失。
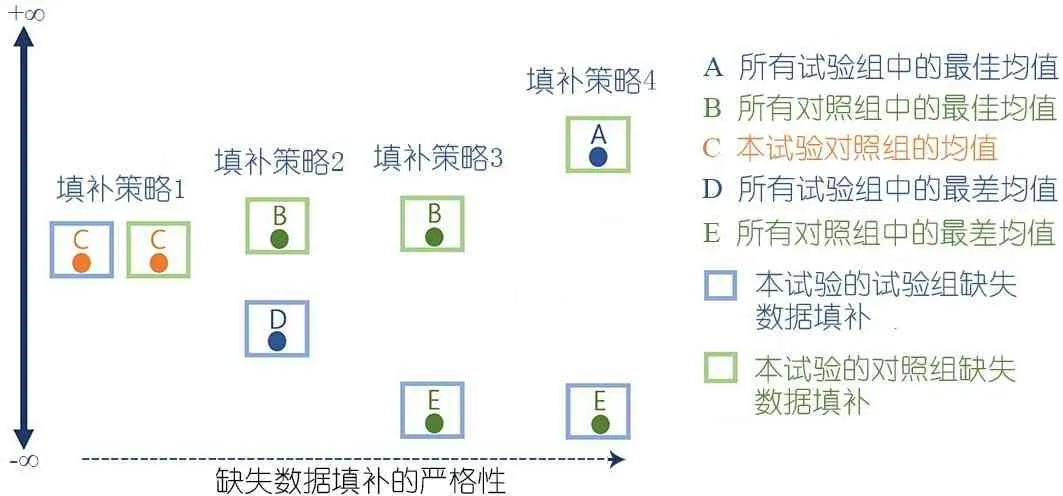
图1 连续性变量结局指标中试验组结果值显著大于对照组缺失数据填补策略图示

表1 连续性变量结局指标中试验组结果值显著大于对照组缺失数据填补策略
图2和表2显示,针对某特定的结局指标,若因试验组结果值小于对照组且效果具有统计学显著性,依据结局指标的定义,可能得出显示“试验组干预措施有益、有害、无益或无害”的推断时,进行敏感性分析时,在纳入的原始研究中进行一系列逐步严格的缺失数
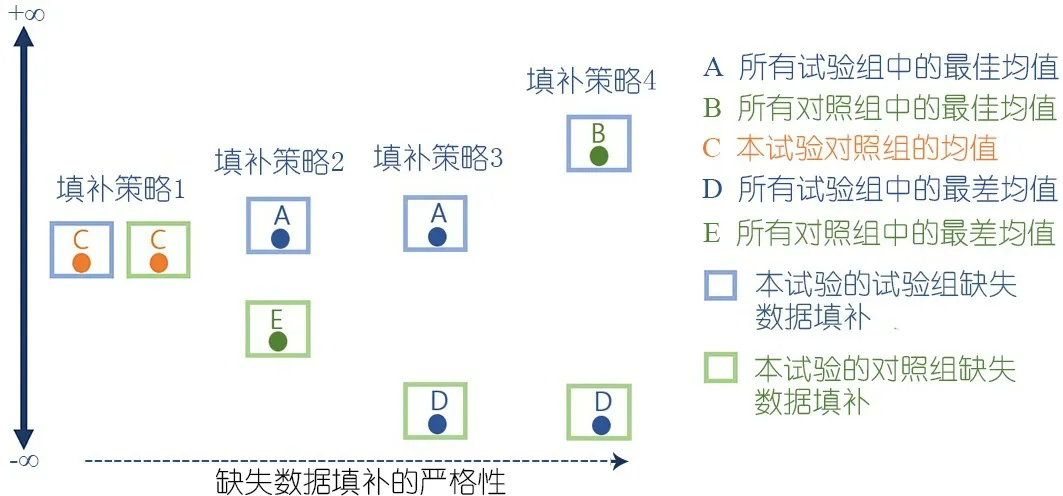
图2 连续性变量结局指标中试验组结果值显著小于对照组缺失数据填补策略图示

表2 连续性变量结局指标中试验组结果值显著小于对照组的缺失数据填补策略
数据填补,即假设试验组缺失数据倾向于干预措施产生的结果值大,并且这种倾向性逐步增高;和/或对照组缺失数据倾向于对照措施产生的结果值小,并且这种倾向性逐步增高,具体数据填补策略如下。策略1使用数据C填补试验组和对照组中的缺失数据;策略2使用数据A填补试验组中的缺失数据,使用数据E填补对照组中的缺失数据。策略3使用数据A填补试验组中的缺失数据,策略4使用数据B填补试验组数据缺失,使用数据D填补对照组数据缺失。
逐次对经不同倾向性填补后的各项研究进行Meta分析,观察该结局指标的效应值结果(包括点估计和区间估计)是否会被反转,并结合临床实际讨论这种反转的情况是否可能出现,以检测“试验组干预措施有益、有害、无益或无害”等推断的稳定性。若结果稳定,则证据质量不因数据缺失的相关偏倚风险而降级,否则应降低证据质量等级。
2.4.1.5 具体计算公式:
5nXTi=nFTi+nLTi
6nXCi=nFCi+nLCi
上述公式中,“M”表示均值,“SD”表示标准差,“n”表示组内人数,“X”表示合并估计,“F”表示组内的数据完整受试者,“L”表示组内数据缺失受试者,“T”表示干预组,“C”表示对照组,“i”表示纳入分析的试验。
2.4.2 原始研究采用不同方法测量同一结局指标的情况 选择单一的参考测量工具,将不同工具的效应值转换为参考工具的单位,然后如前所述方法进行缺失值的填补和分析。选择参考测量工具要考虑的两个关键标准:使用频率高和测量性能好。选择参考测量工具后,必须将所有结果转换为该工具的测量单位。
2.5 数据缺失偏倚风险判断与证据质量降级的阈值 GRADE工作组强调证据质量降级的阈值不应单凭统计学显著性的消失作为判断标准,还应结合临床情景进行分析,因为阈值的选择不仅是事实问题(有效/无效),还涉及价值判断,需考虑具有临床意义或临床显著性的阈值。
3 其他具有挑战性的问题
对于数据缺失率不清楚的情况,如原始研究的作者并未报告有无缺失数据,GRADE工作组建议使用所有纳入系统评价中试验的中位数据缺失率来处理缺失问题。如果有人认为这一假设过于严格,可以在上述基础上再次进行敏感性分析,即假设该原始研究试验组和对照组缺失数据率均为零。对于仅报告总缺失数据而未报告具体每个组别缺失数据的试验,GRADE工作组建议假设干预组和对照组的缺失数据率相同。对于仅报告一种数据填补后分析结果的试验,GRADE工作组建议将该结果用于系统评价的主分析和敏感性分析,并在讨论数据缺失相关敏感性分析结果时,承认这种局限性。
4 总结
证据体中数据缺失相关偏倚风险评估的GRADE方法是一种结构化、透明且相对更具可操作性的方法,该方法重点强调数据填补需兼顾严格性和合理性,以确定数据缺失的程度是否足以降低对一个证据体中某特定结果的确定性。
