基于改进音型法的多系统电能质量数据整合
2021-03-06徐思尧周刚杨强谢善益杨冬海李兆坤
徐思尧,周刚,杨强,谢善益,杨冬海,李兆坤
(1.广东电网有限责任公司电力科学研究院,广东 广州 510080;2.深圳市中电电力技术股份有限公司,广东 深圳 518040)
近年来,随着高压直流输电技术、分布式微电网等技术的快速发展,电网形态发生巨大改变。这些新技术所引发的电网电能质量机理越发复杂,且向超高压和配电网延伸,因此可以认为现代电力系统各个环节都存在电能质量问题[1-5],亟需开展覆盖全网的电能质量分析和治理。相比之下,电网公司已安装的电能质量监测装置非常少,且主要覆盖10 kV及以上电压等级母线。以广东电网为例,仅3 000条线路部署了电能质量监测装置,导致电能质量数据存在巨大缺口。随着电网的发展,以含有电能质量数据的同步相量测量单元等装置构成的电网生产系统使得获取覆盖全网的电能质量数据成为可能。数据整合技术的发展和应用,为集成多系统电能质量数据提供了技术路线。早在20世纪70年代,美国就开始启动数据整合的研究,1984年成立了数据整合专家组。1991年后,国内一些高校和研究所相继对信息融合的理论、系统框架和算法开展大量研究,并取得一定理论研究成果[6]。
基于以上情况,本文以包含电能质量数据的生产系统为对象,提出构建多系统的电能质量数据中心技术框架,围绕实现技术框架中的数据整合功能,将各系统划分为台账数据和生产数据并分析两者的关系,确定台账数据整合是实现多系统数据整合的关键,进而选择台账名称作为台账数据整合的属性。为实现台账名称整合,在现有的音型法基础上进行改进,采用Bhattacharyya距离计算单汉字全拼相似度,其特点在于增加了匹配对象并转化为归一化的数值。此外,考虑到系统间台账名称长度不等,使用改进的动态时间规整(dynamic time warping,DTW)实现台账名称整合。最后,以广东电网的调度自动化系统、地理信息系统(geographic information system,GIS)、电能质量系统、电压监测系统开展管理单位名称和台账名称整合试验。
1 构建多系统的电能质量数据中心技术框架
1.1 整合多系统的电能质量数据中心技术方案
经甄别后选择了包含电能质量数据的生产管理系统、调度自动化系统、电压监测系统、配电网自动化系统、计量自动化系统、GIS、营销系统及电能质量监测系统整合构建电能质量数据中心。
本文设计的多系统电能质量数据中心技术方案由数据接入、数据清洗、数据整合组成,数据接入是基础,数据清洗可提高数据质量,数据整合是目的,具体如图1所示。
1.2 整合多系统的电能质量数据中心技术框架
本文设计的整合多系统的电能质量数据中心技术框架为4层,数据源层实现数据“接入”,数据整合层完成数据清洗及数据整合,数据管理层实现整合后的数据存储和检索,数据应用层完成数据分析和数据挖掘,具体如图2所示。
1.2.1 数据源层
根据各系统数据格式特点,使用不同技术获取8套系统数据。利用CDH软件的Sqoop组件接入存储于关系型数据库的数据[7-8],设计解析电能质量装置数据的API读取装置数据,而FTP可获取特定接口数据(如调度自动化系统的E文件接口)。

图1 基于多系统电能质量数据中心技术方案Fig.1 Technique scheme of power quality data center based on multi-system
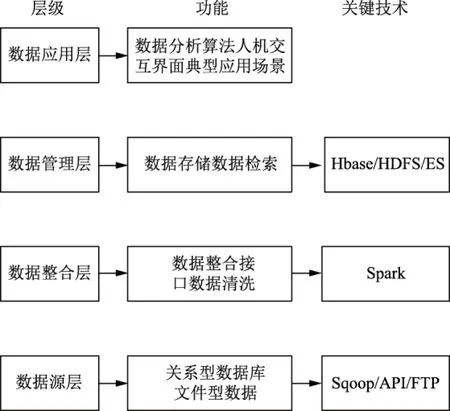
图2 整合多系统的电能质量数据中心技术框架Fig.2 Technique framework of power quality datacenter based on multi-system integration
1.2.2 数据整合层
为提高数据质量,使用正态分布法[9-10]清洗数据,清洗平台为Spark。
数据整合为本文研究重点,文章后续围绕该部分展开。
1.2.3 数据管理层
数据管理层实现数据存储和查询。整合后数据量达到PB量级(1 PB=1 024 TB),故选用大数据管理平台CDH存储和管理,其结构化数据放入CDH的HBase组件,而半结构和非结构数据则存储于HDFS组件[11],最后借助ElasticSearch建立二级索引,实现数据快速查询检索[12]。
1.2.4 数据应用层
数据应用层包括基于Web人机交互、数据二次运算及典型电能质量数据场景等数据分析和挖掘功能。
2 数据整合研究
数据整合是本文研究重点和难点,实现多系统数据整合的关键是找出各系统共性。可将各系统数据划分为台账数据和生产数据,其中:台账数据是表征电力对象的档案信息,由多子属性组成,通常各属性值固定不变,如变压器的台账数据通常包括变压器名称、型号、容量、所在系统分配的ID等;而生产数据是可变的,其表征电力对象动态运行数据,通常与时间相关,如变压器运行数据包含各时序的电压、电流、有功、无功等,因而认为生产数据依赖台账数据存储。另一方面,各系统服务和面向的对象(台账数据)集相同,因此找出各系统台账数据共性是实现数据整合的关键。
基于以上分析,确定数据整合总体路线为:通过台账共性整合各个系统台账数据,再将生产数据挂载于整合后的台账数据中,具体如图3所示。
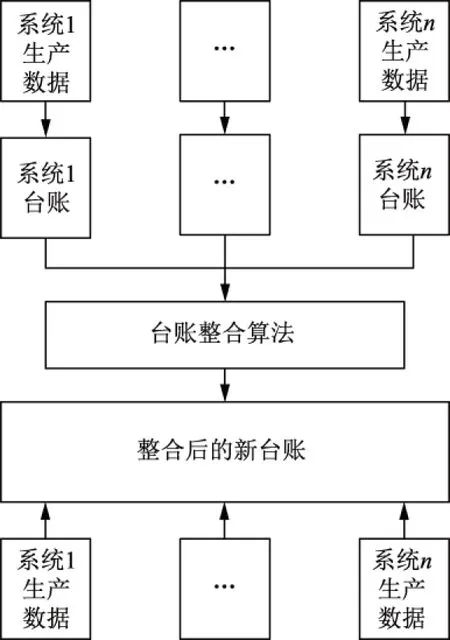
图3 多系统数据整合技术路线Fig.3 Technique route for multi-system data integration
2.1 多系统台账共性
2.1.1 共性选择
表征台账的属性众多,各系统使用的属性差异大,因此如何选择可关联各系统共性的台账属性尤为关键。经分析,所选台账属性必须满足以下3个约束条件:①该属性存在于所有系统中;②该属性在系统间含义相同;③该属性具有唯一性。
经验证,现有系统中不存在同时满足以上3个约束的台账属性,但属性“台账名称”满足约束①和约束②,若借助其他条件使得“台账名称”满足唯一性,则“台账名称”即可作为整合各系统台账数据的共性。
2.1.2 台账名称唯一性处理
台账名称是电力系统对象的命名,但各系统间或同一系统中可能重复,如电压监测系统的某2个供电局均发现台账名称为“市公安局专变”的配电变压器名称。为此,借用电网公司管理关系,将台账名称所属的管理单位自上而下进行判断,直至找到直接负责该台账的单位,其实现流程如图4所示。本次整合的系统属于省级电网公司,其下一级是供电局,供电局的下级为分县局,分县局下级为供电所或变电站,依次向下查找。另一方面,该处理是一个分类过程,可提高多系统台账整合效率。
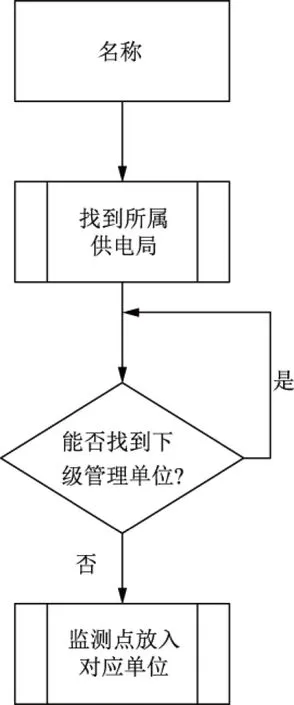
图4 查找台账直接管理单位Fig.4 Search for direct management unit of the ledger
2.2 台账名称整合
根据2.1节所述,台账名称可用于整合各系统台账数据。通常电力台账名称由汉字、数字及字母构成,其特征为专业性强、语义不明朗,如“220 kV北都变10 kVⅡ母10 kV北应线小山支线李家村公变”,使用已有中文语意整合算法难以奏效,因此本文使用音型算法实现多系统台账名称整合。
音型法是求取汉字拼音的相似性并与阈值比较,从而判断比对对象是否相同。现有一种常用的成熟算法,其将汉字拼音拆分为声母、辅音、韵母,然后求取相似度判断比对对象是否相同。其算法实现如下:
y表示某个汉字,x1、x2、x3分别表示汉字y的声母、辅音、韵母,其关系满足
y(xk)=x1+x2+x3.
(1)
对于任意2个汉字yi、yj分别比较声母、辅音、韵母是否相同,记fk(yi(xk),yj(xk))为各部分相似值。当yi、yj任何一个不存在辅母时,k=1,2;其他情况时,k=1,2,3。若完全相同则有
fk(yi(xk),yj(xk))=1;
(2)
反之则取0,再计算总的相似值
(3)
计算汉字yi、yj相似度
Pf(yi,yj)=fsum(yi,yj)/k.
(4)
表1给出“娘”和“狼”的音型相似度示例。

表1 音形法计算示例Tab.1 Example for sound shape method
经测试发现该算法存在以下缺点:
a)误判率高。原因在于其计算相似度只考虑2个或3个属性,导致相似度只可能为0%、33%、50%、66.7%和100%,因此容易误判。
b)容错性低。需准确拆分声母、辅音、韵母,一旦出现拆分错误,至少2个部分受到影响,因此容错性低。
c)该算法不能处理台账名称长度不等的问题,而系统间相同对象命名长度基本不同。
3 改进音型法
本文提出一种适用于电力台账的音型算法。首先利用Bhattacharyya距离求取汉字全拼的相似度,再使用DTW求取台账名称相似度。
3.1 基于Bhattacharyya距离求取汉字全拼相似度
在统计学中,Bhattacharyya距离用于测量2个离散或连续概率的相似性[13-16],在同一个定义域X中,2个离散概率分布p和q的Bhattacharyya距离
DB(p,q)=-ln(BC(p,q)),
(5)
(6)
式中:BC为Bhattacharyya系数,取值范围为0≤BC≤1;DB取值范围为0≤DB≤∞。
Bhattacharyya距离处理直方图相似性时效果较好,本文将汉字全拼转换为概率直方图,利用式(5)、(6)求取任意2个汉字相似度:相似度越高则BC越接近1,DB越接近0;反之BC越接近0,DB越接近∞。因BC更易量化,将之作为判断相似性指标。
对任意汉字y,其全拼为序列H,H={h1,h2,…,hr,…,ht},hr为y全拼的第r个字母,t为全拼长度。按字母表依次编号,将编号作为直方图横坐标;统计汉字y的拼音字母总数a及各字母的数量nr,计算每个字母的占比P(hr)并作为直方图的值。
(7)
图5为使用“唐”和“框”构建的拼音概率直方图,通过式(6)计算出“唐”和“框”的Bhattacharyya系数为0.67。
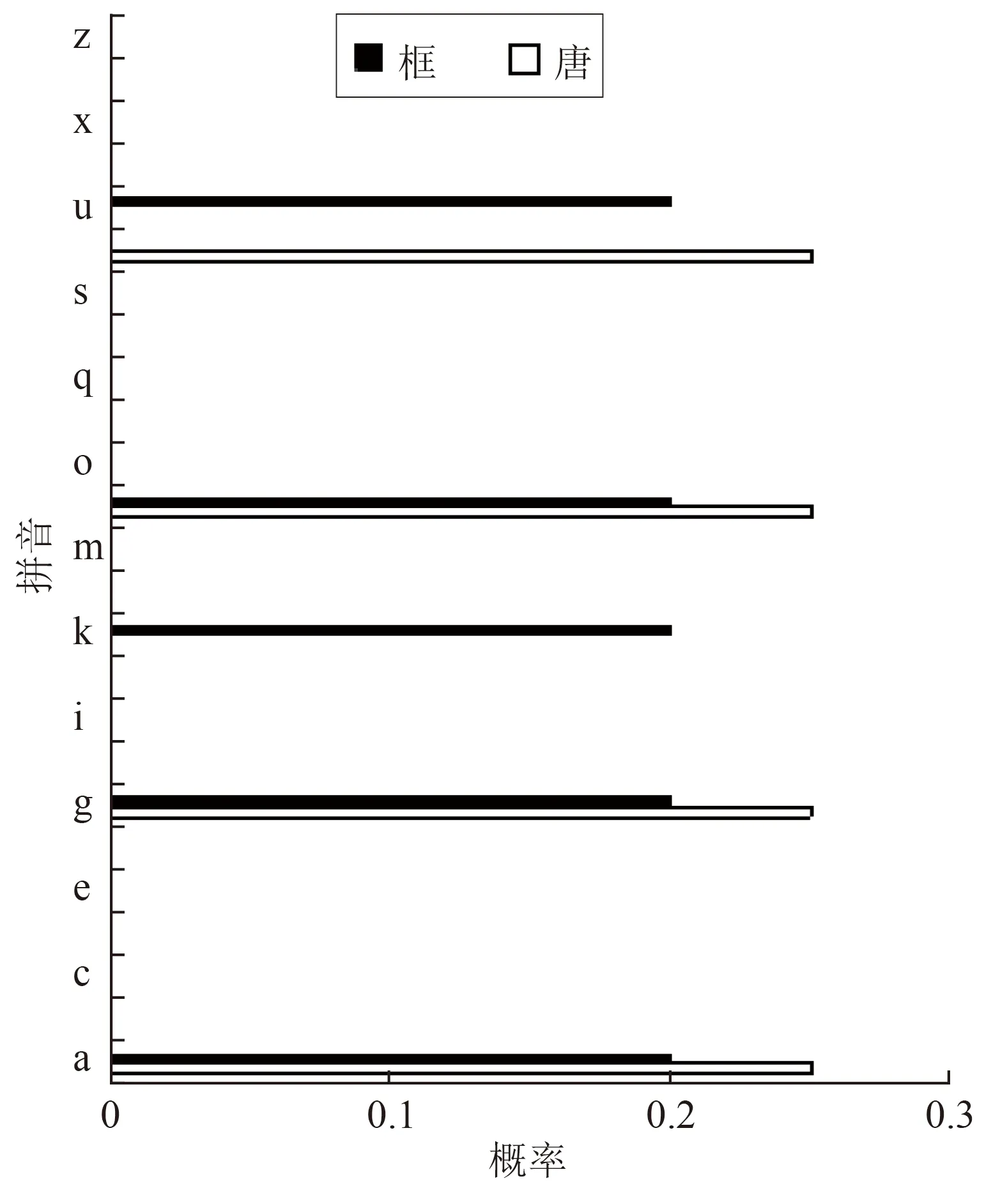
图5 “唐”和“框”拼音直方图Fig.5 Histogram of pin yin probability distribution for “tang” and “kuang”
3.2 基于改进DTW评估台账名称相似性
DTW可用于计算2个不同长度的时间序列相似性[17-18],本结开篇提到各系统中相同对象名称长度大多不等,另一方面电力系统台账名称根据供电关系命名,可以认为具有时序性,因此DTW适合于求取台账名称相似性。
对于任意2个台账名称Qa和Cg(下标表示汉字数量,a和g可以不等),求取累加距离γ:从(0,0)开始搜索,采用3.1节方法求取Qa和Cg的2个汉字相似度,依次累加所经过所有点Bhattacharyya系数,到达终点(a,g)后,即可得累积距离γ,求解公式为式(8)。需要指出的是式(8)是现有DTW的变体,其改动在于:使用Bhattacharyya系数B替代常见的欧式距离,搜索过程求取最大值,而非传统的求解最小值,这是由Bhattacharyya系数特性决定的。通过式(9)判断2个台账数据是否相同。
γ(i,j)=B(qj,cj)+
max{γ(i-1,j-1),γ(i-1,j),γ(i,j-1)},
(8)
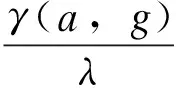
(9)
式中:λ为γ(a,g)的有效匹配次数;τ为阈值,本文取0.85。
3.3 拼音等价处理
南方人发声不标准,容易出现台账名称录入错误。为此在计算Bhattacharyya系数时,本文做了以下等价处理:
a)声母“n”和“l”等价;
b)平舌和翘舌等价,即“z”、“c”、“s”分别与“zh”、“ch”、“sh”等价;
c)前鼻音与后鼻音等价,即“en”、“in”、“un”分别与“eng”、“ing”、“ong”等价;
d)声母“h”和“f”等价。
3.4 台账名称整合实现流程
根据3.1节和3.2节描述,本文设计的基于台账名称实现台账数据整合总体步骤如下:
步骤1,搜索台账名称直接管理单位,可直接利用各系统已有管理节点树完成;
步骤2,利用式(7)求取台账名称中各汉字全拼概率;
步骤3,利用3.2节的方法求解其相似性并判断是否为相同台账。
4 验证实现
4.1 管理单位整合
管理单位是一类特殊台账,本文设计的台账数据整合方案中管理单位尤为重要,需准确整合。表2为广东电网电能质量监测系统、调度自动化系统及电压监测系统部分供电局的台账名称。
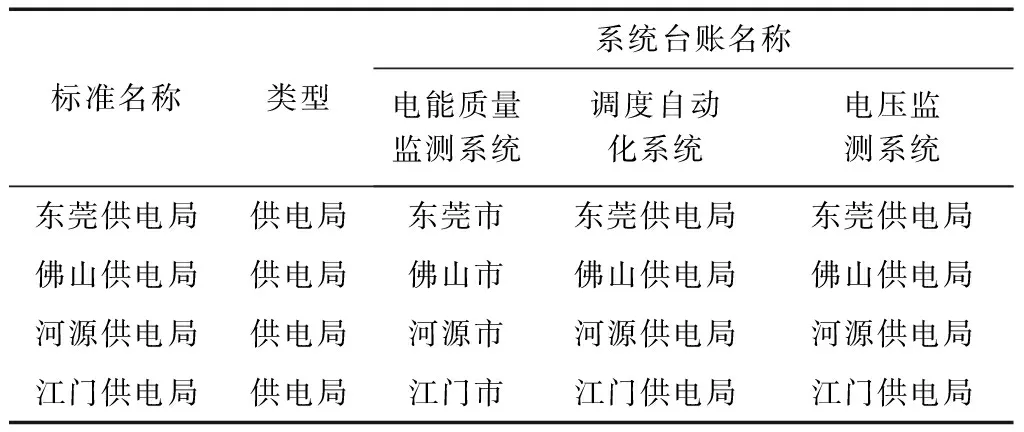
表2 部分供电局台账名称Tab.2 Ledger names of power supply bureaus
利用本文所提算法和原有音型法开展调度自动化系统和现有电能质量监测单位整合,本文所提方法成功率达到100%,结果详见表3。
4.2 测点台账名称整合
测点名称是生产数据直接挂载的对象,但各系统台账规模和对象存在差异,某些系统间交集很少,导致整合成功率看上去很低,例如:调度自动化系统主要面向发电、变电,而营销系统的对象主要是用户,因此交集较少;电能质量监测系统与电压系统台账不到3 000条,调度自动化系统台账则超过100 000条,因此存在整合对象数据量失衡问题。
本文选取对象范围极为相似的调度自动化系统和GIS的某地市局测点名称进行验证,验证的台账条数为18 268。使用文献[19]中汉字形码和四角编码进行整合,计算汉字形码和四角编码相似度的方法与3.2.1节类似。将该地市局划分为18个子单位并分别开展整合试验,整合成功率结果如图6所示。
同时,为验证各算法的整合效率,分别选择600条台账数据,其中100条台账包含10个汉字,以此递推至100条包含5个汉字的台账,各算法运行速度如图7所示。表4为各方法整合该地市局18 268条台账的成功率和可靠率结果。
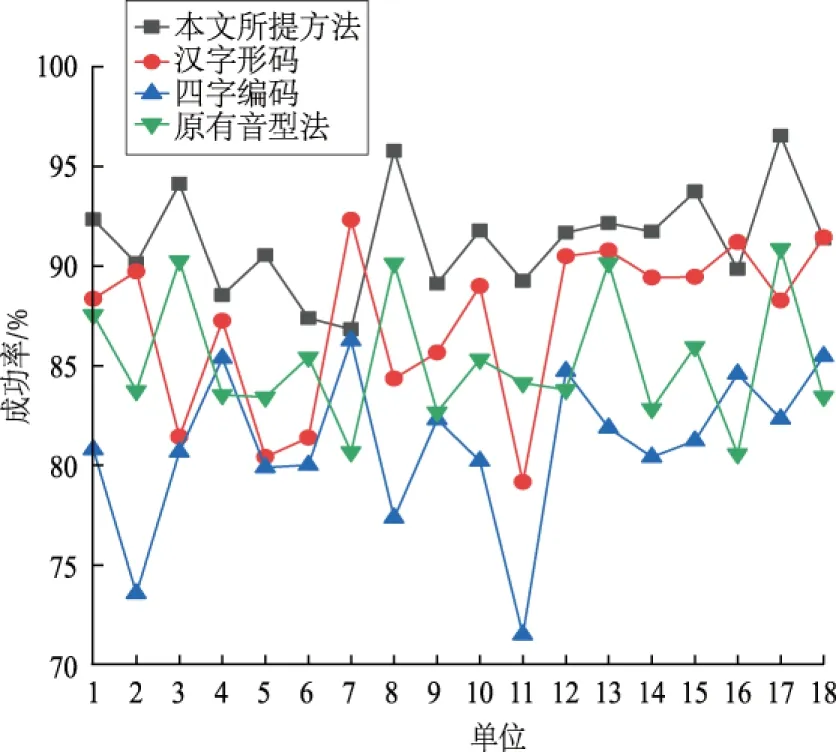
图6 某地市局18个单位整合成功率Fig.6 Integration success rates of 18 units of a municipal bureau

图7 4种算法运算速率Fig.7 Calculation rates of four algorithms

表4 测点名称整合结果Tab.4 Integration results of measuring point names %
4.3 结果分析
从4.1节和4.2节的整合结果可以看出:
a)因单位名称较短,本文所提方法可实现整合成功率100%;同时,得益于单位名称数据的高质量,原有的音型法效果也较好。
b)从图6来看,各方法处理18个单位数据集时整合成功率发散性强,以汉字形码算法为例,在单位7中整合成功率超过90%,而单位11中成功率只有78%。
c)通过图6,可以认为不同方法所适应整合对象有所差异,但均值与表4中整合成功率趋近。以四角编码为例,虽然总体成功率仅为81.5%,但其在单位7中也取得接近90%的成功率。
d)从图7可以看出,针对不同长度的台账数据时:四角编码算法效率最低;本文所提方法效率最高;原有音型法与汉字形码法处理效率几乎相似,源于2个算法考虑维度较少。
e)表4中本文所提方法在整合成功率和正确率上都优于其他算法。由于仅选用某供电局的数据,本文是通过人工校核验证整合数据的正确性。
f)与本文所提方法相比,汉字形码和四角编码均从汉字字形角度评估汉字相似度。但汉字形码只用1个属性考量相似性,容易误判;而四角编码将汉字拆分为4个部分,可提高正确率,但受限于编码原则,其整合成功率最低。
5 结束语
本文将调度自动化系统、电能质量监测系统等8套电力业务系统进行整合后,搭建电能质量数据中心,为电网新形态下的电能质量分析提供可靠、完整的大数据。使用Bhattacharyya距离克服音型法容错性的问题,同时考虑电力系统命名特性,使用改进DTW法完成台账名称整合。最后,通过工程数据验证了该算法的可行性和可靠性。
