基于分组TCAM的T比特高性能路由器快速查找更新技术
2021-02-25刘宗宝李之乾
刘宗宝,赵 鑫,张 力,李之乾,张 琨
(中国航天科工集团第二研究院 七〇六所,北京 100854)
0 引 言
信息技术的发展推动核心路由器的线速转发率达到40 Gbps以上[1],路由查找是核心路由器实现高性能线速转发的关键技术。目前路由查找算法主要有软件查找算法和硬件查找算法,基于软件的路由查找方法需要多次内存操作才能完成路由查找,无法满足高速接口线速转发的要求。基于硬件的路由查找算法大多基于TCAM(ternary content addressable memory)[2-4]技术实现,执行速度快,可以在一个时钟周期内完成路由表项的匹配查询,优先级编码器(priority encoder,PE)从多个匹配结果中选择最长前缀匹配(longest prefix match,LPM)作为查找结果,因此TCAM特别适合于高性能路由器,实现快速路由查找和转发。但是,传统TCAM的更新性能较差[5]:路由表是动态变化的并且规模大幅增长,TCAM中路由表项按照前缀长度降序排列,为保证路由表项的优先级,对路由表项的插入、删除等更新操作会造成大量的内存移动[6],最坏情况下的更新算法复杂度为O(N)(N为TCAM中的路由表项数量),导致路由查找性能大幅下降,无法满足高性能路由器线速查找转发的要求。
针对TCAM路由表项的更新算法国内外学者进行了大量的研究,提出了许多性能优化的算法,参见文献[7-9]等。PLO-OPT更新算法是对选择移动更新算法的改进,即空闲前缀表项从TCAM的底部移动到了TCAM的中间,因此一次更新操作最多需要L/2次(L是路由前缀的长度)路由表项移动。CAO_OPT更新算法把路由表转化为trie树,只对同一条链路(从根节点到叶子节点)上的规则排序[10],一次更新操作最多需要D/2次(D是相互重叠的前缀的最大个数)路由表项移动。目前大部分基于TCAM的路由表项更新算法都要求前缀表项按照前缀长度排序,时间复杂度高,影响了路由查找更新性能。为满足高性能路由器数据交换对快速路由查找功能的需求,本文提出了一种基于分组TCAM的T比特高性能路由器查找更新方法。
1 T比特高性能路由器系统架构
T比特高性能路由器的系统架构为分布转发、集中控制,如图1所示,主要由热备份主控板、交换网板和多个接口业务板组成,各板之间通过高速背板总线互联。主控板是T比特高性能路由器的核心,完成以太网数据包处理、网络管理等功能,并为其它各板提供高精度的时钟源。交换网板具有高性能交换芯片,完成T比特级的高速数据包转发。接口业务板具有单独的控制系统,支持IPv4、IPv6、MPLSVPN、Qos/H-Qos、GRE、组播VPN等全业务功能。
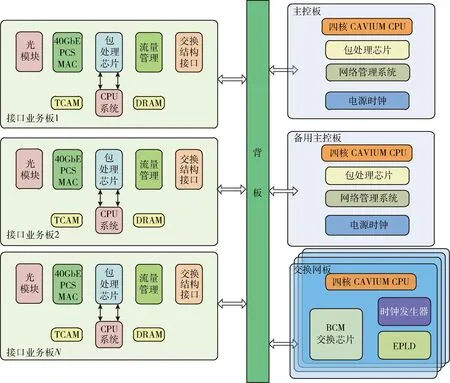
图1 T比特高性能路由器系统架构
2 基于分组TCAM的路由查找更新
2.1 路由查找更新架构
本文提出的基于分组TCAM的路由查找更新架构如图2(a)所示,TCAM被分成几组TCAM1~TCAMmax,每组内各TCAM表项的前缀互不相交,即TCAMi,j∪TCAMi,k=Ф,因此TCAMi(i∈{1,max})是互不相交路由表项的集合,TCAMi中最多只有一个匹配前缀。max为路由表项前缀的最大长度,根据网络环境的不同可动态变化。由于在执行某项前缀的插入、删除等更新操作时,不需要对其它前缀进行操作,因此相比于传统TCAM,本文提出的路由查找更新架构的操作执行速度更快,算法复杂度低,高性能路由器的查找转发效率更高。本文提出的架构中还有一个TCAMex为传统TCAM结构,用于存储无法放在TCAMi中的路由表项。选择逻辑基于最长前缀匹配算法(LPM)实现。

图2 基于分组TCAM的高性能路由器查找更新架构
TCAMi(i∈{1,max})和TCAMex采用基于统计预测的预留表项空间设计,如图2(b)所示,灰色部分表示预留的空间,预留空间大小由前缀的概率密度函数确定,对于TCAMi,前缀长度为m的表项预留空间为ni[m]=NTCAM×pdf[m]/(max+1),前缀为k的表项预留空间为ni[k]=NTCAM×pdf[k]/(max+1),详细计算过程在2.2.2节。通过基于统计预测的预留表项空间设计,有效减少了路由表项前缀的插入操作引起的其它表项的移动,路由表项更新效率大幅提升。
2.2 路由查找更新算法
2.2.1 搜索算法
搜索算法基于最长前缀匹配(LMP)搜索技术,具体实现过程为:对于TCAM1~TCAMmax,每个TCAMi独立地并行执行前缀匹配过程match(TCAMi, ip_addr),其中ip_addr为目的IP地址。由于TCAMi中的前缀互不相交,因此每个TCAMi中最多搜索到一个与ip_addr匹配的前缀;然后从多个匹配的前缀中选择entry[k].length值最大的前缀,相应的entry[k]即为ip_addr的路由查找结果,并返回路由转发表中相应的输出端口号(entry[k].outport)。如果所有TCAMi中没有匹配的前缀,前缀长度entry[i].length值为0,根据路由转发表中默认的表项信息进行转发。搜索算法的步骤如下:
Search(ip_addr)
(1) fori= 1 to ex
(2) entry[i] = match(TCAMi, ip_addr)
(3) endfor
(4) 对于满足上述条件的路由表项entry[i](i∈{1,ex}), 根据LMP原则, 寻找k∈i, 使得entry[k]. length值最大
(5) return entry[k].outport
2.2.2 基于统计预测的预留表项空间算法
对于骨干网络,路由表项前缀的统计特性变化较小。基于统计预测的预留表项空间算法根据高性能路由器的历史表项数据,计算路由表项前缀的统计分布特性,进行预留表项空间的预测和分配,当有新的表项插入时,直接添加在预留空闲位置。算法步骤如下:
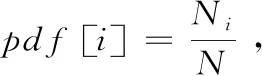
(2)计算长度为i的前缀的总预留空间大小n[i]=NTCAM×pdf[i];
(3)TCAMi中为长度为i的前缀预留大小为n[i]=NTCAM×pdf[i]/(max+1)的空间,路由表项动态更新时,新的路由表项直接插入预留空间内。
2.2.3 插入算法
路由转发表中插入一个新的路由表项(前缀为p)的过程如下Insert(p)函数所示。首先,从TCAMi~TCAMmax中寻找出前缀p可以插入的所有TCAMi(i∈{1,max}),要求前缀p与TCAMi中的任意前缀互不相交;如果存在满足上述条件的TCAMi,并且TCAMi中至少有一个空闲表项位置,标志变量available[i]值为true;否则,前缀p的预留空间被占用,available[i]值为false。如果available[i]值为true并且存在多个TCAMi,插入函数insert_to_tcam()从可用的TCAMi中随机选择一个插入位置;如果available[i]值为false,则TCAM0~TCAM6中不存在可用的空闲表项位置,前缀p插入传统TCAMex。
insert_to_tcam()函数对传统TCAMex的插入操作需要满足传统TCAM的顺序约束,插入过程需要进行多次的内存移动;而TCAM1~TCAMmax中的路由表项无顺序约束,因此对TCAM1~TCAMmax的插入操作可在任意空闲位置执行。
Insert(p)
(1) fori= 1 to max
(2) Initialize available[i] = false
(3) If(对于任意的前缀ep∈TCAMi,p和ep是不相交的, 并且TCAMi中有空余位置)
(4) available[i] = true
(5) endif
(6) endfor
(7) if(available[i] = false, 对于任意的0≤i≤max)
(8) insert_to_tcam(p, TCAMex)
(9) else
(10) 从available[i]中任意选取k, insert_to_tcam(p, TCAMk)
(11) endif
2.2.4 删除算法
从转发表中删除前缀p的过程如下Delete(p)函数所示。首先,需要寻找哪个TCAM含有前缀p(假设为k);然后,前缀可从TCAMk中删除。对于TCAM1~TCAMmax,删除过程不需要任何内存移动。对于传统TCAM,内存移动次数因更新算法的不同而有差异;如果相邻位置是空闲的,每次删除过程需要至少一次前缀移动操作。
Delete(p)
(1) 寻找k,使得p∈TCAMk
(2) delete_from(p, TCAMk)
3 实验验证与分析
为验证本文提出算法的性能,搭建了测试验证环境,如图3所示,由T比特高性能路由器、Spirent网络测试仪、以太网交换机、便携式PC机等组成。其中网络性能测试软件使用Spirent公司的TestCenter STP-N11U,版本为v4.33.0086。
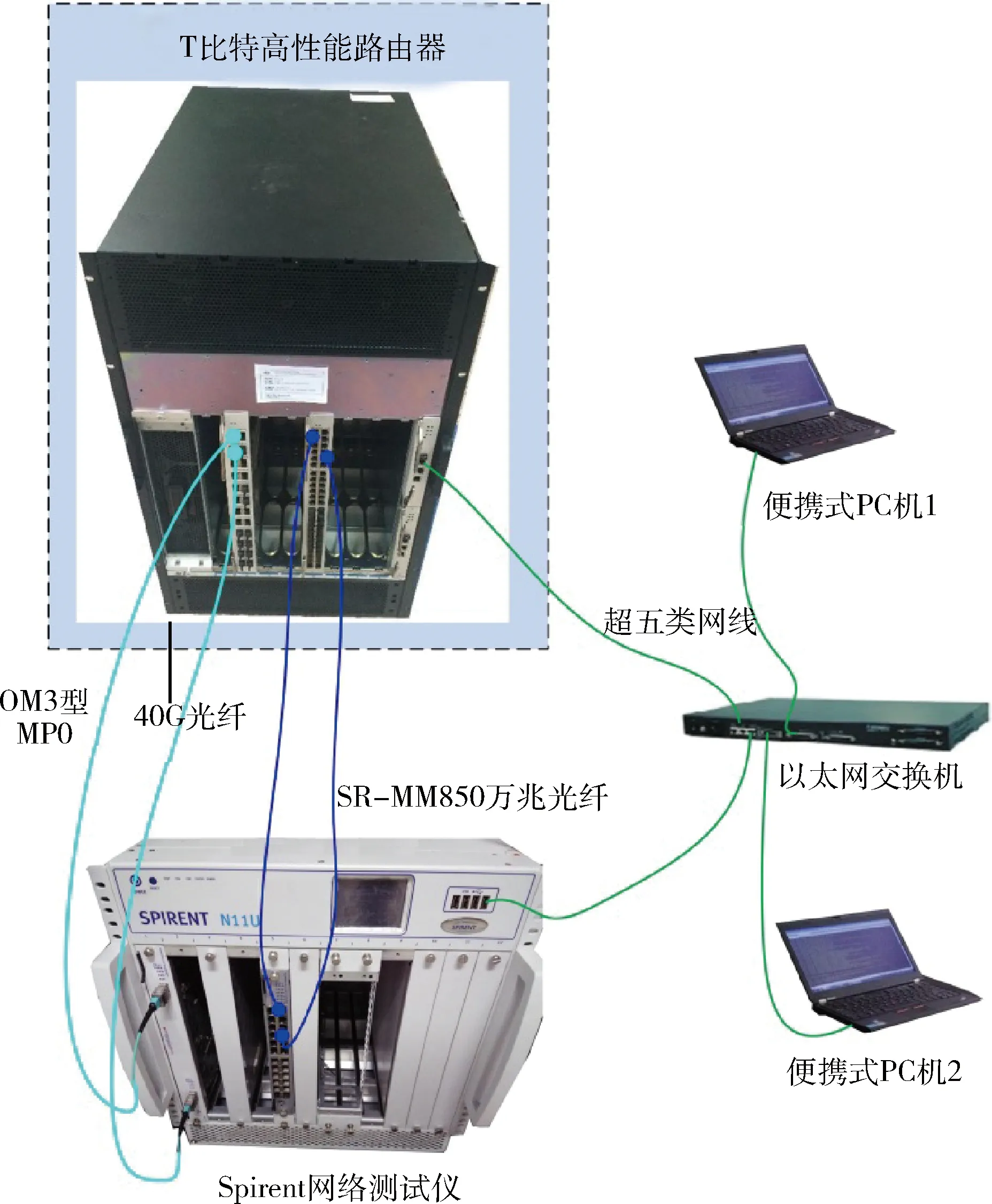
图3 测试验证环境
本文采用IPMA的MAE-WEST和MAE-EAST[11,12]路由表作为仿真数据来源,见表1。

表1 仿真数据统计
图4是数据1和数据2的前缀数量和内存移动次数关系,可以看出,96%的前缀只需要1次内存移动,仅有不到4%的前缀需要2次以上的内存移动。
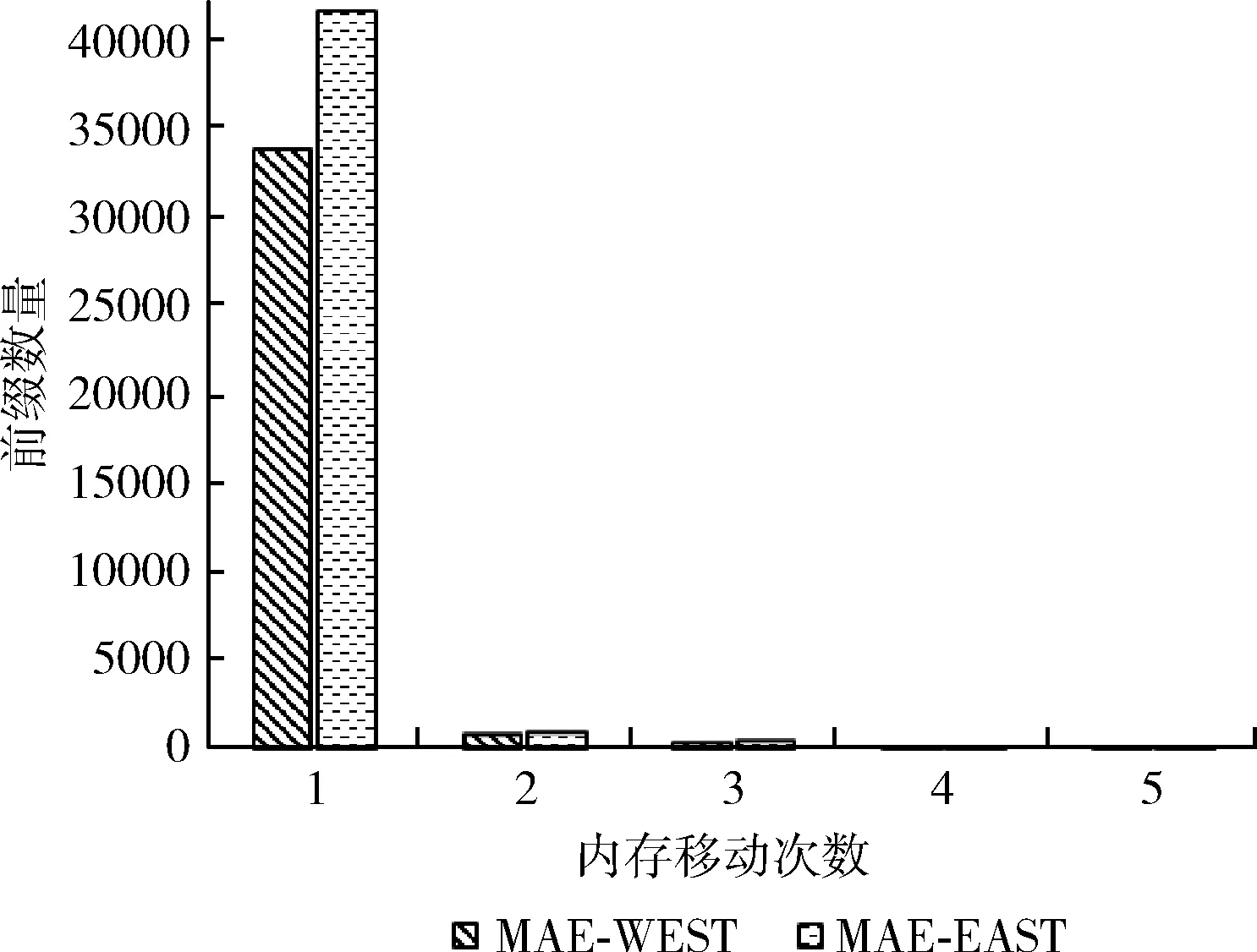
图4 前缀数量和内存移动次数关系
分别采用本文提出的算法以及经典的PLO_OPT算法、CAO_OPT算法,计算MAE-WEST和MAE-EAST路由表每次更新操作(插入、删除)的平均内存移动次数,结果见表2和表3。从对比结果可以看出,由于本文算法的路由表项没有顺序约束和优先级编码器,并且进行了预留表项空间的设计,对于插入和删除操作,本文算法的平均内存移动次数远小于PLO_OPT算法和CAO_OPT算法。由于传统TCAMex的存在,本文算法的插入操作和删除操作所需的平均内存移动次数不相同。需要指出,该算法以计算概率密度函数为代价,通过减少内存移动次数降低了路由表项更新的时间复杂度, 但相比于频繁的内存移动操作,概率密度函数的计算复杂度较小。

表2 不同算法每次更新操作的平均内存移动次数(MAE-WEST)

表3 不同算法每次更新操作的平均内存移动次数(MAE-EAST)
对采用本文提出的算法的T比特高性能路由器的转发性能(吞吐量、时延)进行测试,测试中选用的数据包长分别为64、128、256、512、1024、1280、1518,测试时间为30 s,端口流量负载为100%,网络的转发方式选择Full meshed全双工对发。运行Spirent公司的TestCenter RF2544测试集,测试界面如图5所示。
测试的T比特高性能路由器的吞吐量及时延分别如图6、图7所示。可以看出,在以上7种数据包大小时,路由器的测试吞吐量与理论最大吞吐量吻合,包大小为1518 bytes时可达最大80 Gbps的线速转发,报文的丢包率为0。路由器的转发时延最大为6.12 μs(包大小1518 bytes)。测试结果表明,本文提出的算法可有效提高T比特高性能路由器的线速查找转发性能。
4 结束语
针对传统TCAM查找更新方法时间复杂度高、效率低的问题,以及T比特路由器对高性能查找转发的需求,本文提出了一种基于分组TCAM的路由查找更新架构,TCAM被分成几组互不相交的路由表项的集合,路由表项不需要按优先级进行排序;提出了基于统计预测的预留表项空间算法,预留空间大小由前缀的概率密度函数确定,根据历史表项数据分配相应的空间大小。搭建了测试验证环境,测试结果表明,基于本文设计的TCAM的内存移动次数有效降低,T比特高性能路由器可达最大80 Gbps的线速转发,转发时延最大为6.12 μs。因此,本文提出的基于分组TCAM的T比特高性能路由器查找更新技术,可有效提高T比特路由器的查找转发性能,支撑未来网络发展的需要。
图5 TestCenter测试界面
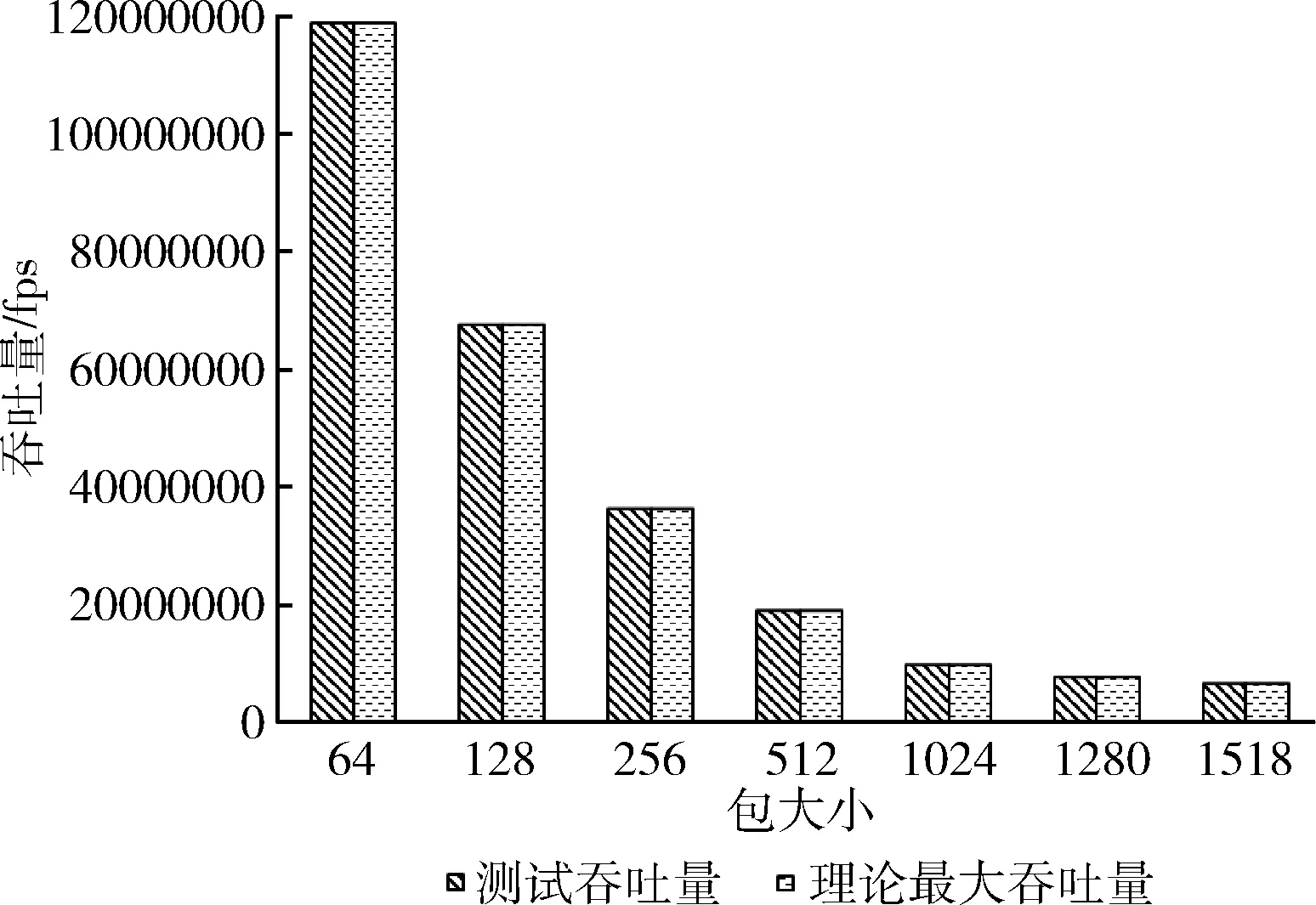
图6 包转发吞吐量测试比较
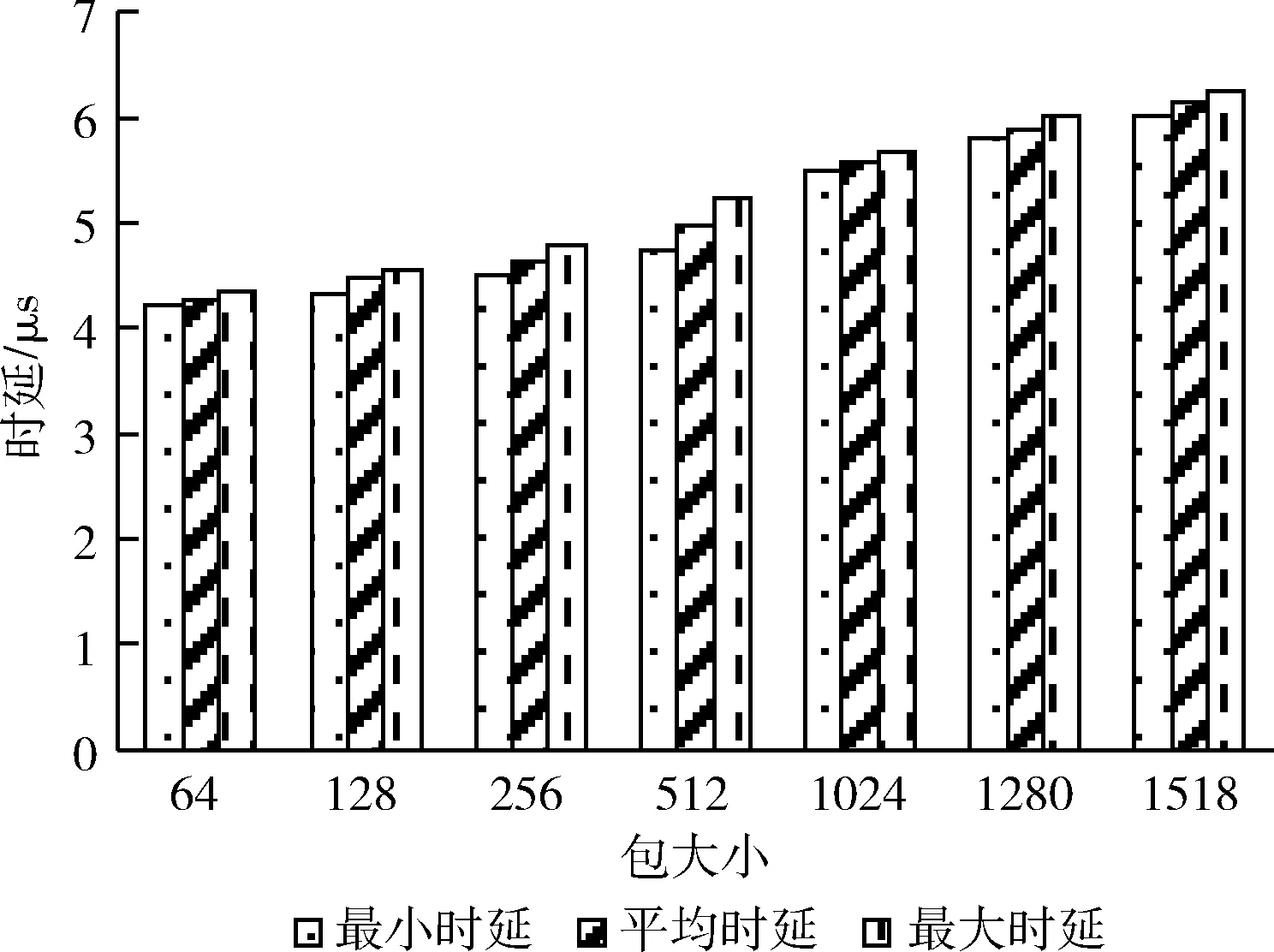
图7 系统转发时延比较
由于T比特路由器的动态变化特性,基于时变概率密度函数的预留表项空间算法是下一步的研究方向。
