基于BP神经网络的特殊客户群体金融服务优化研究
——以小微企业信用评级研究为例
2021-02-16陈伟等
陈伟等
(中国人民银行铜仁市中心支行,贵州 铜仁 554300)
一、引言
2016 年,我国首次将普惠金融纳入国家战略规划,并出台《推进普惠金融发展规划(2016-2020)的通知》,指出普惠金融立足机会平等与商业可持续性原则,能够有效提高金融服务的覆盖率、可得性和满意度,我国普惠金融的服务对象重点包括小微企业等特殊群体。G20 普惠金融指标体系的三个维度是金融服务可获得性、金融服务使用情况、金融产品与服务质量,放在首位的就是金融服务的可获得性。
小微企业在活跃市场、保障就业、推动创新等方面发挥巨大作用。截至2020 年末,中国人民银行统计数据显示,全国存款类金融机构人民币贷款余额172.72 万亿元,其中小微企业贷款余额42.7 万亿元,普惠小微企业贷款余额15.3万亿元,小微企业和普惠小微企业贷款余额占比分别为24.72%、8.86%;银行业金融机构累计发放普惠小微企业信用贷款3.9万亿元,信用贷款占比为25.49%。上述数据表明我国小微企业贷款余额和信用贷款比重偏低。我国小微企业普遍存在经营管理能力弱、持续盈利能力差、财务管理不规范等问题,难以满足抵押担保要求,导致小微企业信贷获得率较低,严重制约小微企业发展。因此,要切实提升小微企业金融服务的可获得性,还需要加大小微企业信用建设和银行信用贷款支持。金融机构以信用评级为基础,决定授予评级对象某笔商业交易或具体的融资金额(郑建华等,2020)。由于小微企业制度不健全、财务信息不透明等原因,依赖于财务数据的信用评级难以直接适用于小微企业。随着大数据时代来临,获取企业信息数据的渠道多样化,为多维度评估企业信用提供机遇。本文认为,优化小微企业金融服务的关键在于放宽信用准入条件,构建适合小微企业的信用评估体系,完善小微企业增信机制,提高小微企业金融可获得性。利用多维度、多类型的大数据对企业信用展开动态评级,通过整合社保、司法、工商、税务等公共信息搭建线上信贷风险管理平台,为小微企业提供自动化、免抵押的循环信贷服务,实现金融机构与小微企业的精准对接,切实提升小微企业融资的可获得性。
二、文献综述
(一)信用评级定义
蒋辉等(2019)提出信用评估是评估机构利用专家判断或数学模型,对借款人如期足额还本付息的能力和意愿进行评价,并按照其违约概率大小以等级或分数的形式给出评估结论的行为。阎维博(2019)认为信用评级是专业第三方依据科学、客观、公平的原则标准,采取全面规范的评级指标体系和科学合理的模型方法,对评级对象违约风险进行全面评估。综合来说,信用评估是指独立第三方按照科学的原则标准,对评估对象客观公正的等级评价,并以简洁的形式作为标识。
(二)信用评估方法
企业信用风险研究已从传统的定性分析,发展到以大数据为基础的人工智能分析。传统的信用分析方法有综合模糊评判法、五级分类法等,这些评价方法简单易懂,不足之处在于主观性太强。随着数据维度不断增加,数据量也呈爆炸式增长,传统基于简单统计的信用评估方法局限性逐渐显现。近年来,人工智能的运用更为引人关注,如许多学者将机器学习算法引入企业信用风险评估研究中,常用的信用评估模型包括随机森林、支持向量机(SVM)、人工神经网络(ANN)等(肖进等,2015)。温小霓和韩鑫蕊(2017)选用66 家中小企业板企业,利用因子分析简化指标体系和特征降维,验证MLP 神经网络评估模型在科技型中小企业中的适用性。刘伟江等(2020)基于Lend⁃ing Club客户信用数据,建立基于卷积神经网络的客户信用评估模型,实验结果表明,基于卷积神经网络的新模型在信用评估实验中与传统以特征处理为基础的信用评估模型相比有显著提升,在客户违约特征信息提取和违约可能性的预测上具有良好性能。
李慧洁(2020)建立Logistic 回归分析模型,对支持向量机(SVM)模型与随机森林、BP 神经网络模型进行对比,结果表明SVM 模型在中小微企业信用评级领域适用性更高。仵晓溪和李云飞(2020)运用因子分析方法筛选评价指标,以优化后的指标体系构建基于LM算法的三层BP神经网络模型,实验结果表明基于LM 算法优化的BP 神经网络模型对训练样本的评估准确率高达100%,对测试样本的评估准确率为84%。综合来看,BP 神经网络应用最为广泛,且预测效果较佳,所以本文选择BP 神经网络对小微企业的信用风险进行评估,并结合LM 算法对网络进行优化以提高收敛速度。
(三)评估体系
目前针对小微企业信用评价指标的选择主要包括企业主个人特征、小微企业特有信息、行业情况、宏观经济形势等,其中企业主特征对信用评级的影响更为重要。如梁迪(2015)从企业主个人素质、企业经营类状况、银行动态风险等三个维度构建纳税信用评价体系。周针竹等(2017)基于现代信用学诚信资本、合规资本和践约资本三维信用理论构建小微企业信用评价指标体系。郑建华等(2020)从企业发展潜力、企业发展环境、企业经营者信息、企业行为合规度等四个维度构建小微企业信用评级模型,并采用层次分析法确定各指标权重。吴金菊(2018)从企业经营情况、营运能力、获利能力、成长能力、守法经营五个维度构建纳税信用评价体系。
上述小微企业信用评价指标体系都将非财务指标作为重要评价内容,信用指标选取更加丰富,范围更加广泛,但针对已有评价指标体系侧重角度各有不同,缺乏全面性和系统性,且部分指标可行性较差。本文选取普惠金融特殊服务群体中的小微企业作为研究对象,从小微企业信用评级体系的现状、困难、适用模型的构建等展开研究,以充分调动银行服务小微企业的积极性,提升小微企业等特殊群体金融服务可得性,为有效缓解小微企业“融资难”问题提供决策支持。
三、信用评价体系设计
信用评级体系的选取应坚持独立性、客观公正性、可行性、系统性与针对性相结合、定量与定性相结合原则(李慧洁,2020)。本文结合我国小微企业实际情况,坚持重要性、客观性、独立性和可行性原则,降低对财务数据的依赖,运用大数据思维从企业主特征、企业信息及税务管理三维度建立信用评级指标体系,如表1所示。

表1 小微企业信用评估指标体系
四、BP神经网络模型构建
对银行而言,客户信用直接影响贷款损失和利润收益。经过实地调研了解到,各银行均建立了独立的企业信用评估体系,但由于标准不一,结果不尽相同,且部分大型银行信用评估缺乏灵活度,降低了评估效率。本文采用BP 神经网络模型,对已知样本信用信息进行训练得出一个抽象模型,进而对新样本进行信用评估。
BP神经网络模型是包含多个隐藏层的前馈神经网络,具备处理线性不可分的能力,信息正向反馈,误差反向传播,经过学习训练得出抽象的评估模型。如图1所示,BP神经网络包括输入层、隐藏层和输出层。网络由多层构成,为便于理解,图中仅显示1 个隐藏层,层与层之间全连接,同一层之间无连接,输入层由m个元素组成,记为Xm,表示影响小微企业信用的m个因素;隐藏层包含n个元素(m与n不一定相等),记为Kn;输出层包含1个元素,记为Yi,表示小微企业信用状况为正常或违约。从Xm到Kn的连接权值为ωmn,从Kn到Yi的连接权值为λni。隐藏层的传递函数为Sigmoid函数,输出层的传递函数为线性函数。
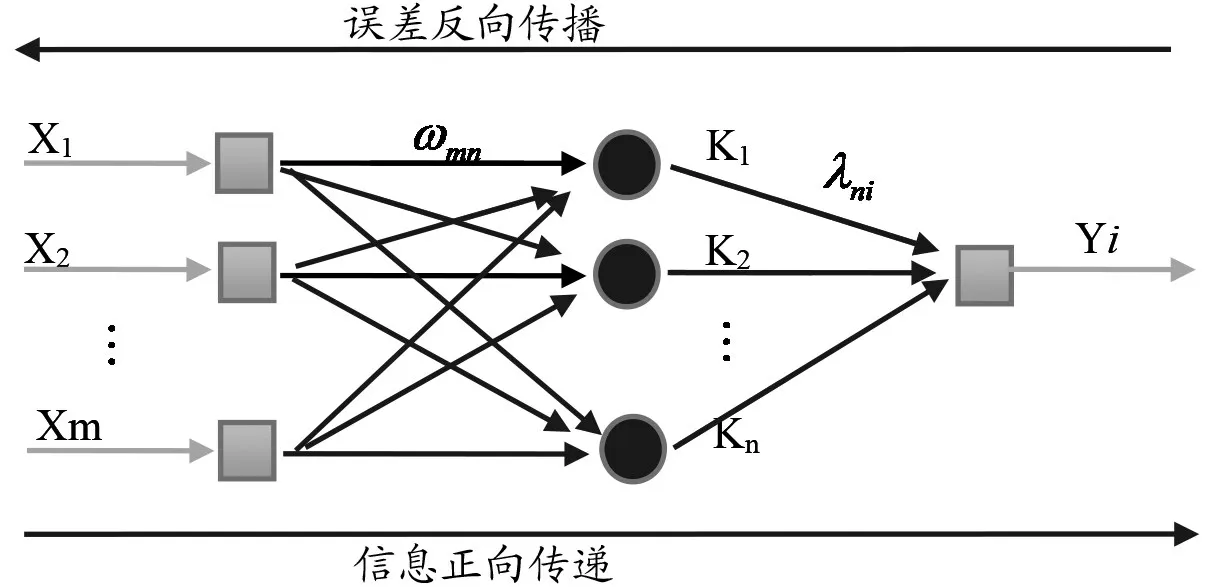
图1 BP神经网络拓扑结构图
(一)隐藏层的输出计算
隐藏层中第n个神经元的输出如公式(1)所示。
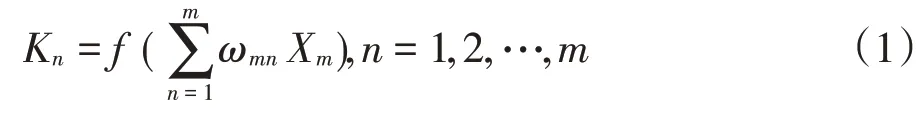
其中f(•)为隐藏层的Sigmoid 传递函数,即。
(二)输出层的输出计算
输出层中第i个神经元的输出如公式(2)所示。

其中g(•)为输出层的线性传递函数。
(三)网络误差计算
(四)误差信号反向传播
根据网络总体误差e,沿着网络逐层反向更新连接权值,权值调整的目的是减小误差。首先调整隐藏层与输出层之间的权值λni,如公式(3)所示。
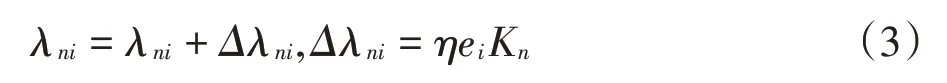
其中,η为学习效率。误差信号继续反向传播,对输入层与隐藏层之间的权值ωmn进行调整,如公式(4)所示。
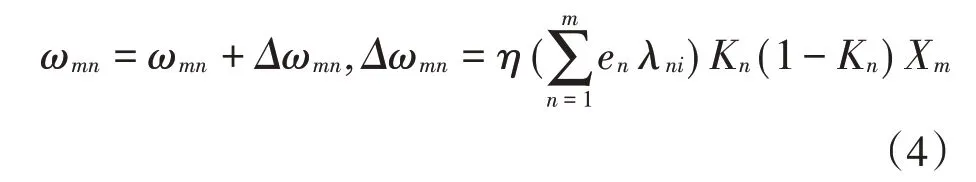
上述隐藏层计算、输出层计算、网络误差计算机误差信号反向传播等过程的主要流程如图2所示。
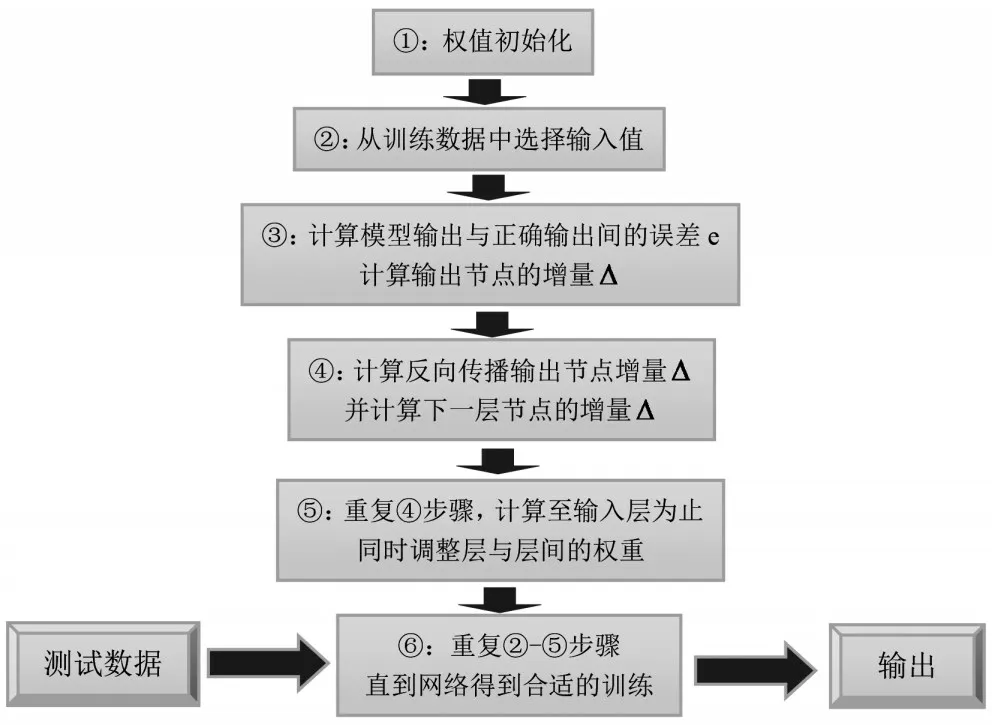
图2 BP神经网络学习的建模与预测流程图
(五)模型优化
BP 神经网络具有实现复杂非线性映射的能力,但也具有一些难以克服的局限性,如需要参数较多,容易导致学习不稳定,收敛速度较慢,还可能陷入局部最优;且对初始权重敏感,较为依赖样本,如果样本代表性差且存在冗余样本,网络就很难达到预期性能。在网络训练过程中,若能使用更优的权重调整方法,则能得到更高的稳定性和更快的收敛速度,主要的改进方法有:动量BP法、拟牛顿法、LM算法等。训练算法的选择与问题本身、训练样本个数等有关,由于LM算法兼具随机梯度下降法和拟牛顿法收敛速度快、均方误差小等优势,适合用于小样本神经网络设计,因此对BP神经网络学习选择LM算法进行优化改进。
五、实证结果分析
(一)样本选取与数据处理
本文选取铜仁市200户小微企业作为调查对象,其中包含15%的违约对象,通过与银行、税务部门、企业主体等单位进行实地调研,详细了解小微企业2020年信贷经营情况。最终收回有效问卷199份,包含182 份守信问卷和17 份违约问卷。由于每个维度指标的单位和性质不同,所以对不同性质的指标进行归一化标准处理。
(二)参数设计
本文选取115个训练样本(含违约样本10份),84个测试样本(含违约样本7 份)。本文每个用户包含26个属性,因此输入层包含26个神经元节点,隐藏层神经元个数及初始参数为程序默认数值。本文研究的内容属于针对信用好/差的二分类问题,因此输出层只包含1 个神经元,用0 表示信用好,1 表示信用差;在程序输出中,设置0.5为阈值,小于0.5的输出判定为0(信用好),否则判定为1(信用差)。
(三)结果分析
本文运用MATLAB软件编写基于BP算法的神经网络程序,设置最大训练次数为1000次,目标误差为“1e-13”,调用trainlm 函数进行训练。第一次测试结果正确率为88.10%,图3 所示为网络误差下降曲线,由横坐标可以看出,网络进行了5次迭代即收敛。经过数据核查,补充了2个缺失数据后,第二次训练8次后收敛,测试结果正确率提高到95.24%。结果表明BP 神经网络达到预期目标,较为准确地对用户信用情况进行评估预测。
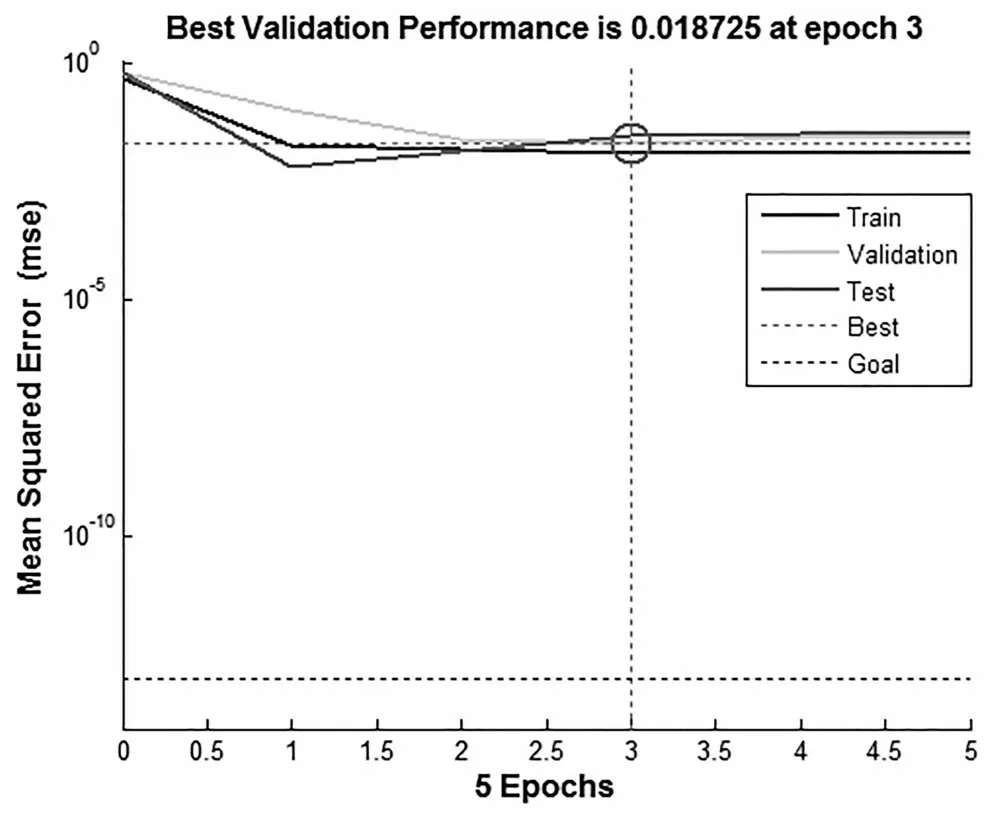
图3 误差下降曲线
为了抵消随机因素的影响,本文选取相同的训练和测试样本集运算50 次,统计正确率与训练次数。结果显示,测试50次的平均正确率为95.40%,最高正确率为98.81%,最低正确率为91.67%;平均迭代次数为6.5次,最低迭代5次,最高迭代10次(图4)。如表2 所示,BP 神经网络模型混淆矩阵输出结果表明,守信小微企业(预测值为0)的预测正确率为99.5%,违约小微企业(预测值为1)的预测正确率为94.1%,整体预测准确率为98.99%。
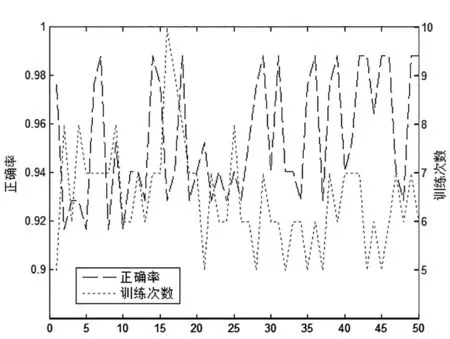
图4 BP网络正确率与训练次数
(四)模型预测能力检验
1.ROC与AUC方法。BP神经网络模型的预测准确率由预测守信情况与实际守信情况比较得出,而模型输出结果的二值分类又由设定的阈值决定。因此,为了评估上述信用评估预测BP神经网络模型的二值分类是否准确有效,本文采用ROC(Receiver Operat⁃ing Characteristic)曲线下面积(AUC)对模型进行检验。
本文的BP 神经网络将输出结果映射在(0,1)区间内,通过设定阈值F 对样本做出二值分类,即当输出值低于F时预测为信用好(0),高于F时预测为信用差(1)。设BP 神经网络模型将实际违约企业预测为违约企业定义为TP(True Positive)真正类,将实际违约企业预测为守信企业定义为FN(False Negative)假负类,将实际守信企业预测为违约企业定义为FP(False Positive)假正类,将实际守信企业预测为实际守信企业定义为TN(True Negative)真负类,真正类率(TPR)=TP/(TP+FN),负正类率(FPR)=FP/(FP+TN),ROC曲线则是由TPR为纵轴、FPR为横轴绘制成的曲线,当模型预测准确率为100%时,ROC 曲线由(0,0)(0,1)(1,1)三点组成,当模型完全没有区分能力时,此时预测结果完全服从随机概率,一般而言,实际模型的ROC 曲线大多呈现一条向左上角弯曲的曲线,其弯曲程度越高代表区分能力越高。但鉴于ROC曲线在模型间不具备可比性,因此需要引入AUC 统计量,即能直观表示各评级模型的区分能力的统计量,等于ROC曲线与FPR=1、TPR=0两条曲线构成的区域面积,如公式(5)和公式(6)所示。
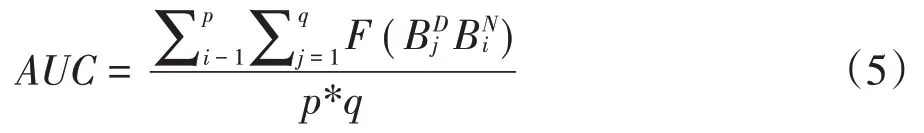
其中,p代表守信企业的数量,q代表违约企业的数量,代表BP 神经网络对违约企业j的输出值,代表BP 神经网络对守信企业i的输出值,0 由于AUC 是ROC 曲线与FPR=1、TPR=0 两条曲线构成的区域面积,因此0≤AUC≤1,当AUC=0.5 时,代表模型没有区分能力,AUC越接近1代表区分能力越高,即预测结果越准确。参照已有相关研究,在实际操作中,仅通过AUC进行预测力度量仍不够全面,需结合ROC曲线的形状对模型进行综合判断。 本文在原样本数据基础上对BP神经网络信用评估模型进行预测力检验,通过MATLAB检验结果可看出ROC 曲线是一条无限向左上角弯曲的曲线,且AUC=0.9947,说明本文建立的BP 神经网络模型能较好地对企业信用状况进行评估。 2.与Logistic模型预测结果对比。Logistic模型常用于多变量数据分析中因变量是分类变量的情况,本文要考察的因变量为守信还是违约(0 或1),是一个二分类变量,此时基于同方差、线性和正态性等假定的线性回归不再适用,故通过构建二元Logistic 回归模型,并将预测结果与上述BP 神经网络模型进行对比。首先,考虑到本文构建了涵盖26 个影响因素的指标体系,由于神经网络模型具有鲁棒性(Robust),能控制系统相对稳定以不会受线性共线影响,即存在多重共线性时,也不需要调整输入神经网络模型的特征值,因此采用因子分析法,并结合各指标间的相关性情况对指标进行降维,按照各指标对主成分的贡献程度排序,筛选出年龄、违约金额、工商年检、社保、法律诉讼、员工人数、年收入、贷款占比、税务登记、纳税增长率等十个指标引入模型。其次,建立Logistic 模型,设y为因变量,且服从于二项分布,记:p=p(y=1),q=p(y=0),p=1-q,Logistic 回归解释了自变量和因变量概率取值之间的关系,如公式(7)所示。 其中,β0,β1,β2,…,βn为待估参数,为优势比率,即事件发生与不发生的概率比,ln()称为y的Logit。 从Logistic模型混淆矩阵输出结果可看出(表3),虽然总体预测正确率达97.5%,处于较高水平,但仍低于BP 神经网络的预测准确率,并且可以看到,Lo⁃gistic模型中的违约企业预测率仅为76.5%,综上可看出,无论是模型内部的预测力评估,还是模型间预测准确率的比较,本文建立的BP 神经网络都能较好地对企业信用状况进行评估。 表3 Logistic模型混淆矩阵输出结果 本文基于人工智能中的BP 神经网络模型,通过LM 算法对系统进行优化,建立针对普惠小微企业的信用风险评估模型,并通过第一手实地调查数据进行实证校验,同时采用ROC 曲线下面积对模型进行检验,并与Logistic 模型预测结果进行对比分析。结果表明BP 神经网络对实际信用数据实现了较好的预测,以平均95.40%的正确率成功预测小微企业的信贷情况,且准确率高于Logistic 模型预测结果。根据评估结果,对不同客户作出分类管理,实现市场细分,为小微企业提供差异化的信贷服务。为进一步优化小微企业等特殊群体的金融服务工作,提出以下政策建议。 银保监会督促银行深化机制建设,在“三个不低于”的基础上提出“两增两控”要求,引导小微金融业务稳步健康发展,不断提升普惠金融服务覆盖率。但在促进提升“覆盖率”的时候忽略了“可得性”,经实地调研发现,大部分金融机构对于小微企业贷款仍然要求提供足额的抵押担保和健全的财务报表,这对于以轻资产为主的初创期小微企业来说,无异于直接拒之门外。根据本文的研究结论,建议银行机构建立以非财务指标为主的信用评估体系,运用BP 神经网络开展小微企业信用风险评估,以评估结果为依据,尽可能降低抵押担保要求,创新信贷产品,降低小微企业金融服务门槛,提高普惠小微企业金融服务可得性。 基于大数据的小微企业信用评级具有全面、可信、高效、低成本的优势,有助于打破以财务信息为主的传统小微企业信用评级模式。建议加强税务、司法和住房公积金缴纳等领域信用信息整合共享,健全信用数据实时采集更新机制,提高信息采集的准确性、实效性和完整性,缓解银行信息收集成本和信息不对称问题,通过大数据和人工智能多维度开展信用风险评估,降低银行信贷风险,落实金融供给侧结构性改革要求,破解小微企业融资难题,提升基层银行服务小微企业的积极性和主动性。 现场调研了解到,不良贷款率考核机制严重限制了银行提高小微企业金融服务可得性的积极性和主动性。目前,对于金融不良贷款等坏账核销仍有诸多限制,为银行服务小微企业埋下隐患。因此,优化特殊群体金融服务,还需要从监管上放宽不良容忍度和坏账核销规定,落实好“放管服”精神,从根本上解除银行机构的顾虑,调动银行服务小微企业的主动性,让银行根据市场化原则促进金融资源分配,让小微企业等特殊群体都能享受普惠金融服务。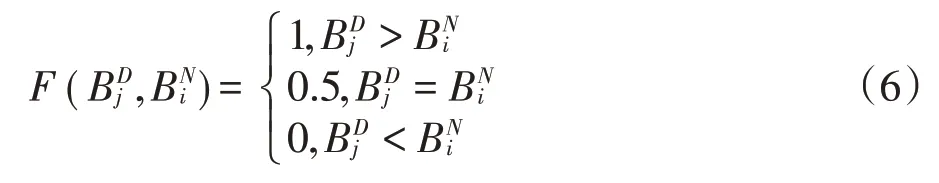
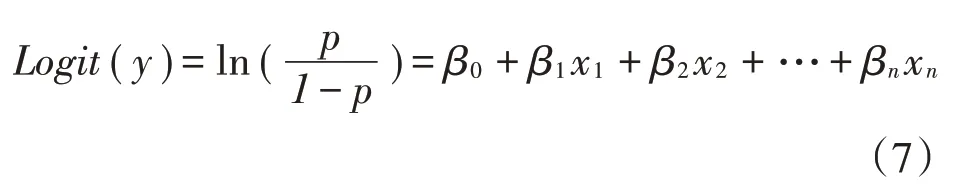

六、结论与建议
(一)创新信贷审核方式,提升小微企业金融服务可得性
(二)整合大数据资源,降低金融机构信贷风险
(三)完善监管考核机制,促进金融资源市场化配置
