基于机器学习的心音识别分类研究
2021-02-05马晶蔡文杰杨利
马晶,蔡文杰,杨利
前言
受人口老龄化等因素影响,我国心血管疾病的发病率和死亡率近年来快速增长。据国家心血管病中心编撰的《中国心血管病报告2016》显示,心血管病死亡占城乡居民死亡原因的首位,占疾病死亡构成的40%以上,及早诊断与及时治疗是应对这一危机的有效措施[1]。心脏听诊操作简单,但主要靠医生的主观经验来判断病症。在大数据的热潮下,通过机器学习方法来判断心脏是否健康成为了一个备受关注的研究热点。机器学习是人工智能的核心,通过计算机模拟和实现人类的学习行为,利用已有数据寻找规律,并对未知的数据进行预测,目前已广泛应用于图像、音频、语言处理等领域[2]。
机器学习已在心脏信号辅助诊断方面取得了很多成功。Zheng等[3]提出了基于心脏储备指数的混合特征提取方法,并采用最小二乘支持向量机实现慢性心力衰竭计算机辅助智能诊断,诊断准确率、灵敏度和特异性均达到了90%。Hadi 等[4]提出了用STransform(S变换)技术提取特征,并运用多层感知器网络进行心音病例的分类,达到了很高的正确分类率。Maragoudakis 等[5]提出了一种基于马尔科夫链的贝叶斯推理方法,在198个心音信号数据集中已得到验证,分类效果高于其他分类器。
心音是心脏搏动过程中产生的一种振动信号,能够很好地反映心脏活动、血液流动和心脏的健康情况,特别在诊断血流动力学异常方面比心电图更具优势[6]。心音在疾病诊断中提供初步线索,有助于医生对疾病进行评估,因其方便快捷在临床上被广泛应用[7]。目前将数据挖掘应用到分析心音特征重要性的研究非常少见。本研究将基于多种新型机器学习算法的心音特征进行分类预测,并运用数据挖掘算法分析心音特征的重要性排序,实现了高准确率的心音正异常分类。
1 实验方法
1.1 数据集的准备
1.1.1 获取数据集实验数据来源于physionet的开源数据库[8]。心音记录(wav 格式)共3 153 条,其中正常心音记录2 488条、异常心音记录665条。
1.1.2 心音特征提取特征提取的第一步是心音分割。基于隐半马尔科夫模型的分割算法是目前分割心音效果较好的算法[9]。图1为运用隐半马尔科夫模型分割心音的结果,可看出图中信号共有5个完整的心动周期。

图1 心音信号分割结果Fig.1 The result ofheart sound signal segmentation
特征提取算法主要有时频域、梅尔频率倒谱系数(Mel Frequency Cepstral Coefficents,MFCC)[10]、连续小波变换。时域分析方法是将信号x(t)的能量分布表示为时间t的函数;频域分析方法是通过傅里叶变换获得信号频域及其能量频域分布。信号x(t)的小波变换为:

其中,a为伸缩因子,b为平移因子,ψ(t)为母小波。本文取单频率正弦Morlet小波为母小波,运用Matlab小波工具箱中的一维连续变换函数cwt对信号进行小波变换。
MFCC表达了一种常用的从语言频率到“感知频率”的对应关系[11]。通常对梅尔频率[12]做以下转换:
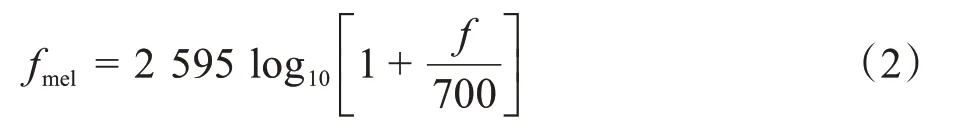
MFCC特征提取的具体步骤为:对信号进行预加重,帧移位取10 ms,帧长取25 ms 对信号进行分帧,加海明窗并进行快速傅里叶变换,通过26 个滤波器进行滤波和刻度转换,对取对数能量后的信号做离散余弦变换和均值归一化。
1.1.3 心音特征数据预处理由于数据样本的异常样本数量要远少于正常样本数量,若数据非线性可分,则会导致在分类过程中判断失误,分类效率严重下降。本研究采用smote 人工合成数据的方法扩充异常心音数据[13]。smote 算法的实现步骤可描述为:①从所有异常样本中找到异常样本xm的K个近邻,记为n。②从n中随机抽取一个样本xn,生成一个范围为(0,1]的随机数δ,按照xm1=xm+δ*(xn-xm),生成新样本xm1。③重复步骤②i次,即可生成i个新样本。
对缺失值的处理方法为:用数据集中缺失值所在的特征(列)的均值来代替缺失值。使用零均值标准化方法对数据集进行归一化处理。
1.2 心音特征分类器工作原理及超参数优化
所用机器学习分类器主要有Light Gradient Boosting Machine(LightGBM)、支持向量机(Support Vector Machine,SVM)、eXtreme Gradient Boosting(XGBoost)、梯度提升决策树(Gradient Boosting Decision Tree,GBDT)、随机森林。本文采用Python语言调用分类器工具包实现该功能。
LightGBM 采用梯度提升的方式,将基于学习算法的分类树和回归树进行有效的叠加。SVM 建立在统计学习理论的VC 理论和结构风险最小化原理基础之上[14]。SVM 的主要思想是将训练数据通过一定的函数变化到高维度的空间,在高维空间寻找最优的分类面。XGBoost 是华盛顿大学陈天奇对Gradient Boosting Machine 算法的C++实现[15],能够自动利用单机CPU 的多核进行并行计算降低计算复杂度。GBDT 最早由Friedman 提出这个概念。GBDT通过采用加法模型,以及不断减小训练过程中产生的残差来将数据进行分类[15]。随机森林是一个包含多个决策树的分类器,并将它们合并在一起以获得准确率更高的预测[16]。
在实际应用中比较常用的参数优化方法有网格搜索法和随机参数优化法。本文使用随机参数优化法寻找最优参数。
1.3 数据挖掘
数据挖掘是从大量、随机的数据中,提取隐含在其中并且潜在有用信息的过程[17]。本研究采用递归特征消除(Recursive Feature Elimination,RFE)方法进行数据挖掘,其通常和很多分类算法联合使用[18]。RFE 的主要流程为:(1)用预处理后的特征训练所选择的分类器;(2)按照最优特征子集进行特征的筛选,保留最优特征。
1.4 分类效果评价标准
在分类学习中,常用的分类评估指标有准确率(Accuracy)、灵敏度(Sensitivity)、精确率(Precision)、F1 值。在实验中,TP 代表将正常信号预测为正常的总数,TN 代表将异常信号预测为异常的总数,FP 代表将异常信号预测为正常的总数,FN 代表将正常信号预测为异常的总数。
准确率表达式为:

灵敏度表达式为:

精确率表达式为:

F1值表达式为:

2 结果
2.1 心音特征提取及数据扩充
心音信号经过滤波、去波峰、降采样等处理后,运用隐半马尔科夫模型分割每个心动周期的S1、收缩期、S2、舒张期,利用时域、频域、MFCC以及小波变换算法共提取145个特征。第1~36个特征为时域特征;第36~72个特征为频域特征;第73~90个特征为MFCC特征;第91~145个特征为小波变换、时间复杂度和光谱复杂度特征,提取的特征数据集的维度为3 153×145。在正常和异常心音特征数据中随机抽取800条作为测试集,其余数据作为训练集和验证集,通过smote 算法将异常的训练数据由465 条扩充为1 860条,即扩充之后训练集和验证集中正常心音特征数据与异常心音特征数据分别为1 888条和1 860条,比例接近1:1。表1为在采用相同分类器LightGBM的情况下原始数据集与扩充数据集的分类效果对比,可看出扩充前的各项分类指标都较低,扩充后数据集比原始数据集在分类准确率、灵敏度、精确度、F1值上分别提高了16.05%、24.6%、12.92%、20.58%,可证明数据扩充的必要性和有效性。

表1 扩充数据前后分类效果对比图(%)Tab.1 Comparison of classification effects before and after data expansion(%)
2.2 心音特征分类效果评估
将数据集随机打乱,按照4:1的比例分配给训练集和验证集。测试集的维度为800×145。实验中分别采用LightGBM、SVM、XGBoost、GBDT、随机森林对数据进行训练和预测。参数优化结果如下:对于LightGBM, learning_rate=0.15, max_depth=60,n_extimators=150,num_leaves=300;对于SVM 模型,高斯径向基函数为核函数,C=1,gamma=0.01;对于XGBoost 模 型,colsample_bytree=0.8,gamma=0.1,learning_rate=0.3, max_depth=10, reg_alpha=0.1,min_child_weight=1,subsample=0.6;对 于GBDT,learning_rate=0.1,max_depth=40,n_extimators=200,min_samples_split=70;对于随机森林模型,max_depth=156,max_features=30;n_extimators=120,min_samples_leaf=70。
经过填充均值、归一化、调节最优参数等处理后,各分类器预测后得到的分类效果如表2表示,其中各分类指标结果均为正常与异常两种类别的的平均值。
在分类准确率方面,由表2可看出,在相同的数据集下,LightGBM 效果最好,准确率为90.32%,XGBoost次之。由于正样本更被医学上重视,将正样本误判为负样本的代价要远远大于将负样本误判为正样本的代价,因此灵敏度、精确率、F1 值往往也是很好的评判标准。每个分类器指标中的准确率、灵敏度、精确率、F1 值差距较小,除了随机森林外基本差距在1%左右。结合这4个指标可看出,LightGBM效果最好。
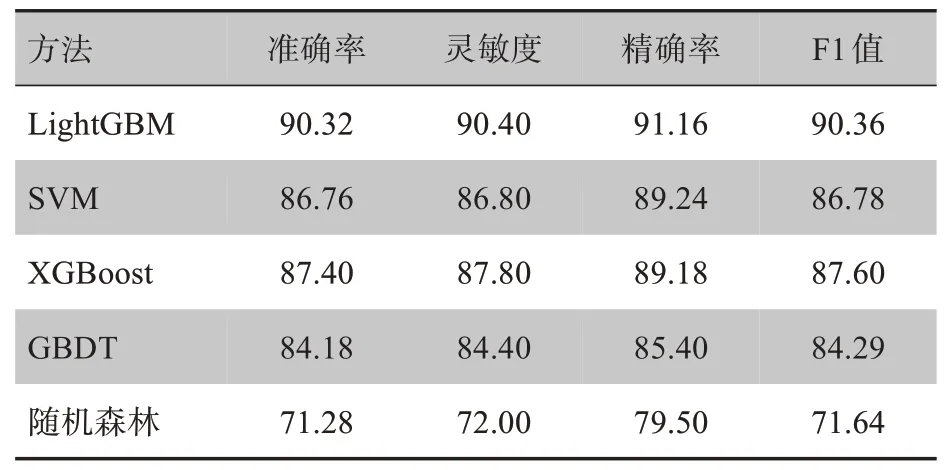
表2 各分类器心音分类效果(%)Tab.2 Heart sounds classification effects of each classifier(%)
2.3 数据挖掘结果
根据分类效果的对比可看出LightGBM效果最好,故本文选用LightGBM与RFE结合,选择LightGBM算法作为递归特征消除算法的分类器。通过数据挖掘从145个特征中提取出重要性前8名的特征,分别是第75、73、77、17、78、93、79、52个特征,代表的含义依次为“倒谱系数偏度中心距离”、“倒谱系数最小值”、“信号谱分析系数”、“收缩期和S1振幅比”、“信号谱分析频率”、“小波变换谱系数”、“线性预测系数”、“收缩期加窗傅里叶变换中位数值”。
在数据集划分比例相同、分类器均为LightGBM、调参参数设置相同的情况下,这8 个特征构成一个特征子集,分别将145个特征组成的数据子集和从145 个特征中随机抽取8 个特征组成的特征子集进行比较评估各项指标。对比结果如表3所示,可以看出:数据挖掘特征子集与由145个特征组成的特征集分类效果差不多,而随机抽取的特征子集从准确率、灵敏度、精确率、F1 值上看效果都跟前两者有很大差距。数据挖掘的特征子集比随机抽取特征子集分类准确率高0.225 1,提高了33.51%;灵敏度高0.114,提高了14.54%;精确率高0.155,提高了20.61%;F1 值高0.173 9,提高了24.04%。以上足以证明数据挖掘的8个特征的重要性。

表3 数据挖掘效果对比图(%)Tab.3 Comparison chart of data mining(%)
2.4 模型融合
为了提高模型的性能,采用Stacking 模型融合方法将所用的5 种模型进行5 折交叉验证输出预测结果,然后将其合并为新特征并使用新模型加以训练得到最终结果。图2展示了不同数量模型融合与分类指标F1 值的关系图,分别取LightGBM、XGBoost、SVM、GBDT、RandomForest 这5 个模型的第1 个、前2个、前3个、前4个、前5个模型做模型融合。实验结果表明,LightGBM、XGBoost 和SVM 模型融合的效果最好,准确率、灵敏度、精确率和F1 值分别为92.6%、92.6%、92.7%、92.6%。
3 讨论
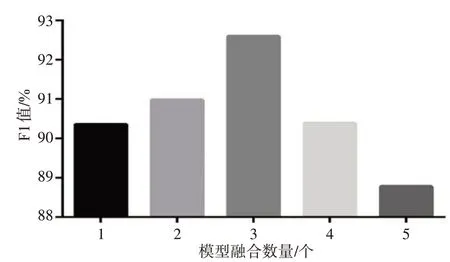
图2 模型数量与分类指标F1值关系图Fig.2 Relationship between number of models and F1 value
近年来,智能辅助诊断成为了不少学者研究的热点,在特征分类和图像分类方面有很好的应用。在实际训练时,为了提高模型的鲁棒性和泛化能力,本研究所收集的数据来源于physionet的公开数据集,并从中剔除了信号。在心音特征分类诊断过程中,采取了多种方法解决分类不平衡问题,发现smote人工合成数据能够有效扩充异常信号;对比各分类器的分类效果,发现相比于传统机器学习方法,新兴机器学习方法如lightGBM在保持各项分类指标的同时大大提高了工作效率,在实际应用中是一个很好的优点。
通过数据挖掘的分类效果对比可看出,数据挖掘出的特征子集在各项指标中都表现很好。145 个特征组成的特征集虽然在准确率、灵敏度、精确率、F1值这4个指标上略高于数据挖掘特征子集,但是数据量却是后者的19 倍。在临床实际应用中,不影响分类效果的前提下,提取的特征数目由145个减少到8 个,这不仅大大减少了特征提取所需要的时间,也提高了机器学习训练和测试的效率,可以在相同的时间内进行更多的预测。数据挖掘出来的8个特征,包含MFCC、时频域分析等,对于诊断心血管疾病来说是重要的指标,具有较强的临床参考价值。
运用Stacking 模型融合方法将多种分类器结合以提高模型性能,是有效提高分类效果的方法之一,但并不是分类器越多越好,若某个单独分类器本身性能不佳则会影响整个模型的效果。本研究结合了多种心音特征类型进行心音诊断,目的是充分利用心音的信息以提高分类准确率,运用Stacking 模型融合方法准确率可达到92.6%。尽管本文的初步研究取得良好的心音分类效果,但physionet 的心音数据来源于国外多家医院,不同品牌数字听诊器和不同环境下采集的心音信号可能会夹杂一定的干扰信息,应进一步进行广泛的研究和测试。
4 结论
本研究通过将机器学习与递归特征消除算法相结合挖掘到其中最重要的8个特征,在提高模型运行效率的同时也从某些程度上代表了诊断心血管疾病的参考指标,并采用Stacking 模型融合方法将心音分类准确率提高至92.6%,该方法具有潜在的临床应用价值。
