SF6气体绝缘电气设备故障分解物检测的多组分交叉干扰及校正算法综述
2021-02-01陈图南马凤翔袁小芳邱宗甲张国强
陈图南,马凤翔,袁小芳,邱宗甲,李 康,韩 冬,张国强
(1. 中国科学院电工研究所,北京100190; 2. 中国科学院大学,北京 100049;3. 国家电网安徽省电力有限公司电力科学研究院,安徽 合肥 230601)
1 引言
六氟化硫(SF6)具有良好的绝缘和灭弧性能,因此被广泛地应用于气体绝缘电气设备中。但是在电气设备的运行过程中,不可避免地会产生局部放电等故障[1]。在放电或过热条件下,SF6会分解产生一系列低氟硫化物[2],进一步的,在微水和微氧条件下,还会产生SO2、SOF2、SO2F2等硫氧化物[3-5]。SF6的分解产物会对电力设备的安全运行及运检人员的人身健康造成危害,因此有必要对设备中的气体成分及含量进行测量,用以监控设备内部绝缘状态[6,7]。
在目前常见的气体检测方法中,光学检测法由于其所具有的测量范围大、可检测气体的种类多、检测速度快、检测灵敏度高等优点,成为了气体检测的理想工具[8]。典型的光学检测法包括差分吸收光谱法[9-11]、可调谐二极管激光器吸收光谱法[12,13]、光声光谱法[14-16]等。这类检测法均基于气体分子对特定波长光的选择性吸收现象。但是,由于气体分子所含的不同跃迁能级,其光谱通常呈现出连续带状。此外,由于分子本身的性质,气体分子在吸收光子后在特定波段上表现出来的谱线并非理想线段,而是具有一定带宽。因此,当吸收峰较为相近的分子处于同一波段的光源照射下时,多种气体分子均会对该光束产生吸收,产生谱线的重叠,这种现象就称为气体分子的交叉干扰。
当气体分子产生交叉干扰时,在进行光电转换后,检测得到的电信号的值会由多种气体分子共同决定,从而使得检测信号不仅携带待测气体的信息,同时也包含其他气体的信息,导致在使用检测信号进行反演时,得到的待测气体的体积分数不准确,从而难以正确判断气体绝缘设备内部的绝缘状况。因此,有必要对交叉干扰的产生机理及校正方法进行深入研究,降低交叉干扰对待测气体定量检测的影响。
本文针对使用光学检测法检测微量气体时产生的交叉干扰现象,从产生机理、常用的校正方法、校正后的评估三个方面出发进行综述,并对交叉干扰校正方法的改进策略进行了展望,旨在为使用光学检测法对气体绝缘设备进行绝缘状态监测的相关人员提供参考,从而提升气体绝缘设备状态监测系统的可靠性。
2 交叉干扰产生机理
光具有波粒二象性,光子是电磁辐射的媒介,只能传递量子化能量。理论上,当光通过某一气体时,气体只吸收能量刚好等于它某两个能级之差的光子而发生能级跃迁。在宏观上,表现为特定波长的光因气体的吸收而光强减弱,这就是气体对光的选择性吸收,如图1所示[17]。

图1 气体分子跃迁示意图Fig.1 Diagram of gas molecular transition
当气体分子在不同能级之间发生跃迁时,对外表现为吸收光子或发射光子,形成谱线,吸收或发射光子的频率满足玻尔理论,即:
ΔE=E2-E1=hγ
(1)
式中,ΔE为分子吸收的能量;E1、E2分别表示分子能级跃迁前后的能量;h为普朗克常数;γ为光子频率。
在气体分子中,不仅有电子的运动,同样还有组成气体分子的各原子之间的振动和分子整体的转动。气体分子中这三种不同的运动状态都对应有一定的能级,且这三种不同的能级都是量子化的。当气体分子受到光的照射,并吸收一定能量的电磁辐射后,分子会由较低的能级跃迁到较高的能级。考虑到电子能级、振动能级、转动能级的能量差之间的数量级差异,在同一电子能级之间往往存在有许多振动能级和更多的转动能级。因此,宏观上来看,当发生电子能级的跃迁时,同时会产生许多不同振动能级和转动能级的跃迁,从而得到一光谱带系,这些光谱带均对应同一个电子能级的值[18]。
此外,气体分子的谱线并非理想的几何线,而是具有一定的展宽。这是由于粒子从高能级向低能级跃迁时,粒子会在高能级上存在一定的时间,即具有一定的寿命Δt。由海森堡不确定关系可得[19]:
(2)
式中,Δt为粒子的寿命。
式(2)表明这个能级的能量存在相应的宽度,即分子辐射的总功率分布在中心频率ΔE/h附近一个很小的频率范围内。由原子物理学的知识可知,气体分子吸收或发射的线状光谱是一个中心频率为ν0=ΔE/h的分布[20],即呈现出一个峰状。
考虑到分子的光谱特性是由分子结构决定的,当不同种气体分子具有相似的结构(如包含相同的官能团)时,其光谱特性较为相似。因此,对于同一束入射光而言,结构相似的气体分子的带状吸收光谱可能会因为距离较近而产生重叠。在进行光电转换得到检测信号后,检测信号的值会由多种气体对光的吸收共同决定,从而难以从中分离出待测气体的信息。这种会对待测气体的检测产生干扰的现象即为交叉干扰。
3 交叉干扰校正方法
对多组分气体检测的交叉干扰进行校正,降低交叉干扰对检测的影响,通常可以从两个方面入手。
一方面是基于设备进行校正。这类方法的基本思想是减小入射光的波长范围,从而尽量使得在入射光的波段内仅有待测气体会产生吸收,降低其他气体对检测信号的影响,这种方法可以从根源上降低交叉干扰产生的可能性。这类方法的代表有可调谐激光器[21-23]、单色仪[24-27]、滤光片[28]等,但是除了滤光片外,其他设备成本较高、移植性较差,在实验室中不易进行更换。因此需要脱离设备条件限制的校正方法,从而有效扩大校正方法的适用范围,使其适用于多种检测仪器、多种待测气体的交叉干扰分析。
另一个方面是基于算法进行校正。基于算法的交叉干扰校正方法是基于已有的实验检测数据,通过特定的算法对实验数据进行分析,建立检测信号与混合气体中各组分气体的体积分数之间的关系,然后计算得各组分气体的体积分数。本质上来说,该方法并没有消除交叉干扰,而是通过解算算法得到了待测气体的相关信息。
本文以更为常用的基于算法的校正方法为重点,分别对几种典型的交叉干扰校正算法进行介绍。
3.1 多元线性回归
当体系的响应与输入呈线性关系,并且输入之间无共线性,干扰较低时,多元线性回归(Multiple Linear Regression,MLR)是一种能够良好处理多输入响应的方法[29]。
当光源的波段内存在多种气体的吸收峰时,根据朗伯-比尔定律,可以得到如下关系[30,31]:
(3)
式中,A(λ)为混合气体在波长λ处的吸光度;I0(λ)为光通过混合气体的背景气体时检测得到的原始光强;I(λ)为光通过混合气体时检测得到的吸收光强;σi(λ)为组分气体i在波长λ处的吸收截面;ci为组分气体i的体积分数;L为有效光程长。
记:
Y=[A(λ1),A(λ2),…,A(λm)]T
(4)
(5)
C=[c1,c2,…,cn]T
(6)
E=[e1,e2,…,em]T
(7)
式中,m为测量次数,即在测量过程中所取的不同波长的数量;n为混合气体中组分气体的数量;Y为检测信号矩阵;X为系数矩阵;C为体积分数矩阵;E为残差矩阵。
即可得到如下矩阵形式的线性模型:
Y=XC+E
(8)
对于该模型,有如下三种情况:
(1)n>m,此时矩阵C有无穷多解,说明MLR不能适用于此种情况。
(2)n=m,此时矩阵X满秩,矩阵C有唯一非全零解,且有E=0。应用克莱姆法则即可求解各组分气体的体积分数。
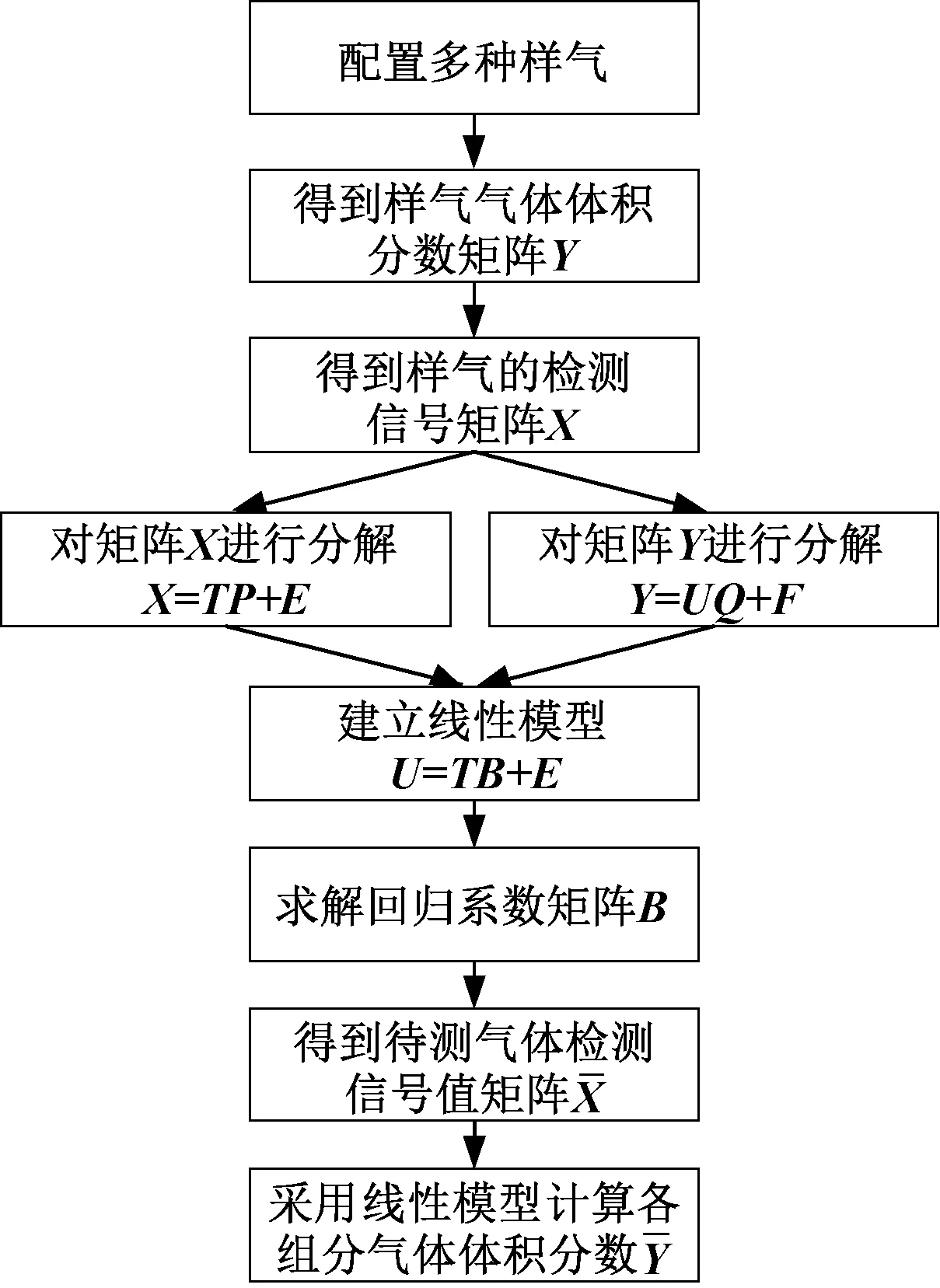
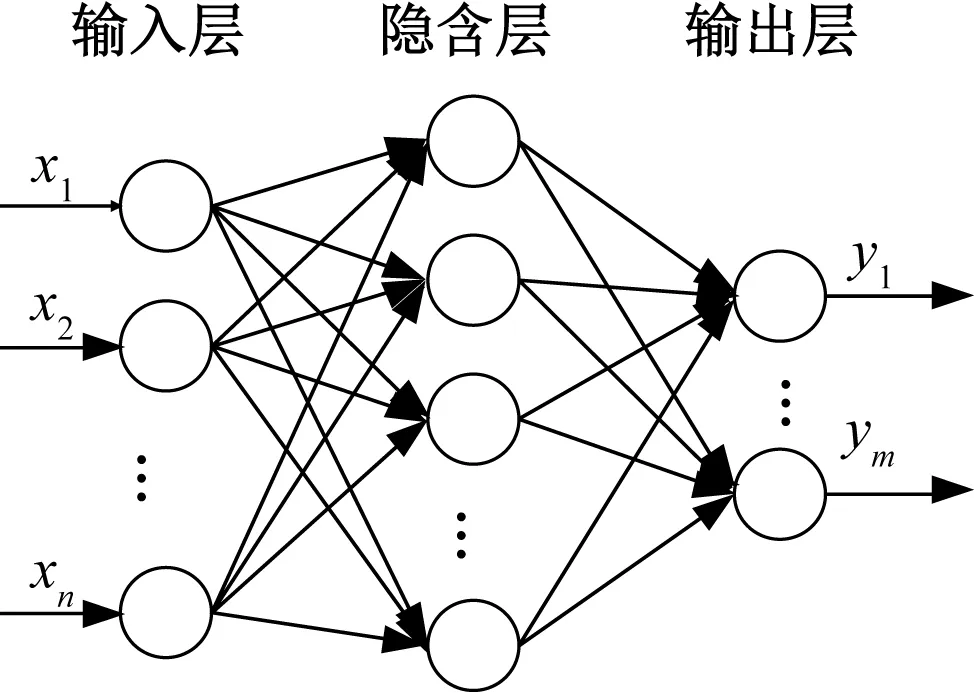
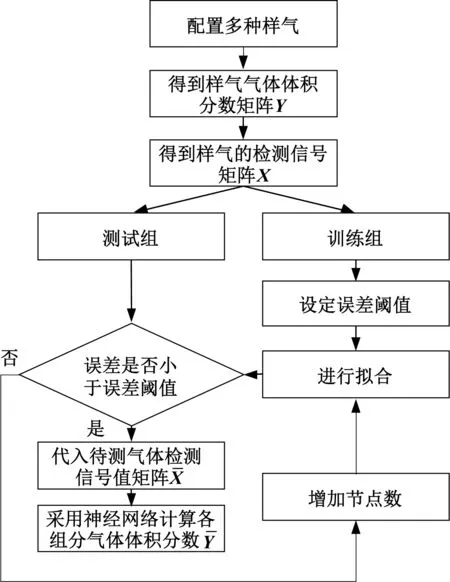
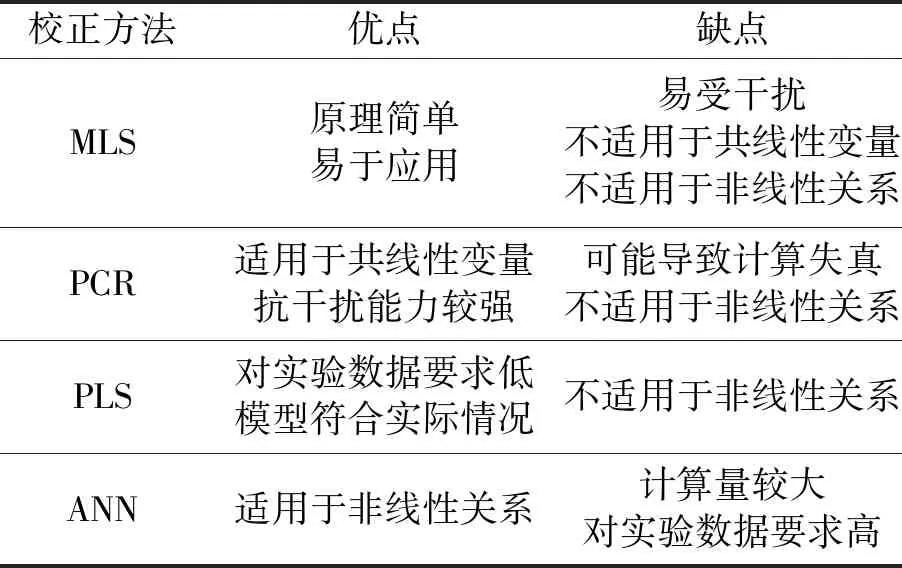
(3)n C=(X′X)-1X′Y (9) 由此可得,将MLR应用于交叉干扰校正的步骤如下: ① 分别制定多组已知各组分气体体积分数的样气。 ② 选定不同波长,得到在各波长处各组分气体的吸收截面数据。 ③ 在不同波长处,分别测量各样气的检测信号值。 ④ 采用MLR计算各组分气体的体积分数。 由上,可以得到使用MLR进行交叉干扰校正的流程图如图2所示。 图2 MLR流程示意图Fig.2 Process diagram of MLR MLR的应用过程较为简单,可以适用于多种情况。但同时,MLR也有其固有的不足,当干扰较强时,或自变量之间的共线性较为显著时,线性模型均可能失真。 主成分回归(Principle Component Regression,PCR)是基于主成分分析的回归方法[32,33]。主成分分析的核心思想是将数据降维,以排除多组分气体共存时存在的相互重叠的信息。主成分回归可分为两步进行:测定主成分,将原矩阵降维;对降维的原矩阵进行线性回归分析。其基本原理介绍如下。 主成分是原变量的线性组合,用它来表征原变量时所产生的平方误差最小。应用主成分分析,原变量矩阵可以表达为得分矩阵,而得分矩阵由原矩阵在本征矢量上投影所得。主成分回归的基本原理可以阐述如下。 设原矩阵为Xm×n,对原矩阵进行标准化,然后计算矩阵X的相关系数矩阵R,其元素的计算式如下: (10) 式中,i,j=1,2,…,n;m为测量次数;n为混合气体中组分气体的数量。由雅克比迭代法可得到相关系数矩阵R的特征值和特征向量,由特征向量组成的矩阵即为载荷矩阵P,并满足: T=XP (11) 式中,T为得分矩阵。 选择k(k X=TP+E (12) 然后将得分矩阵与因变量矩阵Y进行MLR,即: Y=TB+F (13) 式中,B为回归系数矩阵;F为残差矩阵。 可得回归系数矩阵B的最小二乘解为: B=(T′T)-1T′Y (14) 通过求解回归系数矩阵,即可得到未知混合气体各组分的体积分数。具体步骤如下: (1)分别制定多组已知各组分气体体积分数的样气,并取各组分气体的体积分数构成矩阵Y。 (2)分别测量不同样气的检测信号值,并构成矩阵X。 (3)由主成分回归,得到回归系数矩阵B。 由上,可以得到使用PCR进行交叉干扰校正的流程图如图3所示。 图3 PCR流程示意图Fig.3 Process diagram of PCR 主成分回归具有如下优点:由于各个主成分之间不存在线性相关关系,因此主成分回归可以解决共线性问题;在去除相对次要的成分后,主成分回归具有较好的抗干扰能力;适用于复杂体系的测量,不需要辨别干扰组分。同样,由于主成分回归本身的原理,可能存在错误去除有用主成分的情况,造成计算结果信息缺失、模型产生偏差。 在实际测量中,当测量次数少于待测气体的数量时,难以应用MLR等方法。此时可以通过偏最小二乘(Partial Least Square,PLS)进行交叉干扰的校正[34-36]。PLS的特点在于对自变量矩阵X和因变量矩阵Y同时进行分解,使用于描述矩阵Y因子的同时也用于描述矩阵X。从数学上来看,是以矩阵Y的列参与矩阵X的因子的计算。由此可以得到PLS的数学模型: X=TP+E (15) Y=UQ+F (16) 式中,T、P、E分别为X的得分矩阵、载荷矩阵和残差矩阵;U、Q、F分别为Y的得分矩阵、载荷矩阵和残差矩阵。 考虑T和U之间的线性关系,有: U=TB+E (17) 此时,系数矩阵B的最小二乘解为: B=(T′T)-1T′U (18) 由此,可以得到使用PLS测量未知混合气体各组分的体积分数步骤,具体如下: (1)分别制定多组已知各组分气体体积分数的样气,并取各组分气体的体积分数构成矩阵Y。 (2)分别测量不同样气的检测信号值,并构成矩阵X。 (3)由PLS,得到回归系数矩阵B。 由上,可以得到使用PLS进行交叉干扰校正的流程图如图4所示。 图4 PLS流程示意图Fig.4 Process diagram of PLS PLS的优点主要在于:可以在样本点数量较少、待测量较多的情况下进行分析;PLS将数据矩阵的分解和回归合并,在定量分析中所得到的特征向量直接与待测组分相关联,更符合实际情况。PLS同样具有其局限性,例如,当被测组分体积分数范围较大时,非线性因素过强时,会导致PLS模型内的线性关系不准确,使得模型失真等等。 在上述交叉干扰校正算法中,均是以朗伯-比尔定律为基础进行校正。但是朗伯-比尔定律的应用具有前提条件,当超出一定浓度范围时,该定律不成立。人工神经网络(Artificial Neural Network,ANN)具有很强的非线性映射能力,能够很好地表征这种非线性系统[37]。在目前的研究中,使用较多的是径向基函数神经网络(Radial Basis Function,RBF)[38,39]。RBF神经网络是具有单隐含层的三层前向网络,第一层为输入层,输入层仅起到传输信号的作用,其基本结构如图5所示。 图5 RBF神经网络模型结构Fig.5 Basic structure of RBF neural network 当多种气体产生交叉干扰时,混合气体的体积分数和检测信号的关系可抽象为: A=fn(c1,c2,…,cn) (19) 式中,A为检测信号值;ci(i=1,2,…,n)为混合气体中第i个组分的体积分数;fn为表征ci与A之间映射关系的隐函数。 当组分气体之间产生交叉干扰时,需要计算各组分气体准确的体积分数时,可以用式(20)计算: ci=fn-1(A1,A2,…,An) (20) 式中,Ai为第i次测量时得到的检测信号值;fn-1为函数fn的反函数。 实验测得的数据往往只能表示气体体积分数与检测信号的映射,而难以对隐函数fn进行准确的求解。采用RBF神经网络可以对大量离散数据进行拟合,从而逼近隐函数fn,达到求解反函数fn-1的目的。由此可知,将RBF神经网络应用于交叉干扰校正的步骤如下: (1)分别制定多组已知各组分气体体积分数的样气,并取各组分气体的体积分数构成矩阵Y。 (2)分别测量不同样气的检测信号值,并构成矩阵X。 (3)将测量得到的数据分为训练组和测试组两组。 (4)用训练组的数据作为RBF神经网络的训练样本,对RBF神经网络的参数进行训练。 (5)设定误差阈值,并将测试组的数据放入训练后的RBF神经网络中进行误差测试。 (6)如果误差测试得到的误差小于设定的阈值,则训练完成;如果误差大于设定的阈值,则增加RBF神经网络节点数量,直至误差小于设定阈值。 由上,可以得到采用RBF神经网络进行交叉干扰校正的流程图如图6所示。 图6 RBF流程示意图Fig.6 Process diagram of RBF 在使用ANN时,需注意两个问题是过拟合和过训练。在试样数量和输入节点确定后,若隐含层节点过多,会发生过拟合问题,导致模型结构不稳定;过训练则是在训练集的均方根误差降低的同时,测试集的均方根误差上升,同样会导致模型结构不稳定。 虽然基于算法的校正方法能够适用于大部分实验室实际测量情况,但是也存在其固有的不足:首先,一般来说大部分算法需要大量的实验数据支持,特别是需要对不同配比的多组分气体样气进行多次测定;其次,算法中的参数也需要根据实际算例进行调整;再者,从本质上来说,基于算法的方法未能从根源上消除交叉干扰,因此可能存在未知的气体对计算结果产生干扰。 为了更好地对各种校正方法进行说明,本文对基于算法的校正方法进行了分析与讨论,以期对实验或工程中选择合适的校正算法提供参考。 由多元线性回归方法的原理可知,将多元线性回归应用于交叉干扰分析的数学模型是解由实验数据构成的非齐次线性方程组[40]。因此,多元线性回归方法具有原理简单、易于实现等优点。但同时,由于多元线性回归的求解部分使用了线性方程组,与其他方法相比,多元线性回归方法需要检测样本数量不少于待测气体数量[41]。此外,当检测对象受到外界干扰时,线性方程组可能难以正确描述光声信号与气体体积分数之间的关系。因此,多元线性回归方法容易受到外界干扰,且对非线性关系难以适用[42]。 主成分回归会根据相关性对影响输出的成分进行排序,从而将实验得到的数据矩阵进行降维,然后再进行线性回归。从原理上来看,主成分回归能够去除较为次要的成分,从而不需要辨别干扰成分。这使得主成分回归方法与其他方法相比具有较好的抗干扰能力[43]。但是,考虑到实际对变压器油中溶解气体进行检测时,待检测的主要成分往往都是已知的。因此,使用主成分回归反而可能会导致信息缺失、忽略部分因素对结果的影响,致使计算结果不够准确[44]。 偏最小二乘方法集中了主成分回归及多元回归分析的优点,模型较为简洁,且对数据量的要求并不高[45]。与多元线性回归、主成分回归相比,偏最小二乘求得的残差平方和往往更小,因此该模型具有更高的准确性[46]。但与多元线性回归和主成分回归类似地,当检测对象受到外界较大干扰时,偏最小二乘方法内部的线性模型可能失真,使得计算结果出现偏差。 与前述方法相比,神经网络的优势在于可以很好地描述非线性系统。由神经网络的特点可知,根据不同的应用场景,需要适当对神经网络采用的建模函数进行调整。因此,当测量场景变化时,需要对神经网络的函数进行调整,以确保其收敛性。同时,也需要对神经网络中的神经元数量进行调整,避免过训练、过拟合等问题[47]。所以,相较于其他算法而言,神经网络算法的移植性较差,且对数据量要求较大[48]。由此,基于神经网络的校正方法更适用于在实验室中使用,或是针对某一特定场景进行高精度检测。 结合上述内容,可将各种算法的特点总结如表1所示。 表1 基于算法的交叉干扰校正方法特点Tab.1 Features of crossover interference modification based on algorithm 鉴于各校正方法所具有的特点,为了进一步提高交叉干扰校正算法的准确度与可靠性,有学者在典型算法的基础上加以延伸,提出了众多改进的衍生方法。例如,基于最小二乘的基本原理,提出了最小二乘支持向量机回归(LS-SVR)方法用于复杂成分微量元素的检测[49,50];在文献[51]中,作者在PLS中加入非线性函数替代线性函数,用以增加回归的泛化性。 此外,也有学者将多种方法进行结合,从而得到组合方法来提高校正精度。例如,在文献[52]中,作者采用MLR和PLS联用的方法对质谱数据进行分析;在文献[53]中,作者将主成分分析与RBF神经网络相结合,以解决输入自相关严重时,RBF神经网络精度下降问题;在文献[54]中,作者将PLS与BP神经网络相结合,改善了PLS的非线性适应能力。 在采用交叉干扰校正方法得到校正模型后,需要建立评价体系对交叉干扰的校正结果进行评估。通常采用的方法是交叉验证,结合评价指标,用以检测校正模型的精确程度与可靠程度[55,56]。 (1) 残差平方和 对于校正模型而言,较为通用的评价方法是计算其校正值与实际值的差距,即残差,从而评判校正模型的准确度。残差是最基本的评价校正模型好坏的标准,进一步地,为了对校正后的数据进行整体评价,可以引入残差平方和(Residual Sum of Squares,RSS),其计算式如下: (21) 残差平方和是较为基本的评价校正算法结果的评价指标。通过累加每一个校正点与实际值的差值,可以得到校正模型结果与实际值相比整体的偏离情况。残差平方和是实验及工程中最为常用的评价指标之一。 (2) 相关系数 相关系数反映了校正值与实际值变化趋势的关系。相关系数的计算式如下: (22) 除了校正算法得到的残差外,通常还需要对校正后得到的数值变化趋势进行评价,从而判定校正算法中模型的稳定性。在此,相关系数是较为常用的评价指标。相关系数越接近1说明校正值集合的变化趋势越接近实际值集合,同时也说明校正值中没有单个偏差较大的点。 (3) 拟合优度 拟合优度R2的计算公式如下: (23) 式中,ymean表示实际目标值的均值。 拟合优度表征了线性模型对实际数据的拟合程度,拟合优度越接近1,说明校正算法中的线性模型能够接近越多的实际数据。该指标可用于评价包含线性模型的校正算法,但是不适用于非线性模型的校正算法。 (4) 建模集均方误差 建模集均方误差(Root Mean Square Error of Calibration,RMSEC)的计算式如下: (24) 建模集均方误差表示模型中计算得到的点与实际值的均方误差。该值越小,说明所建的模型与建模集的实际情况越相近,从而能够表明所建模型的合理性。 (5) 验证集均方误差 验证集均方误差(Root Mean Square Error of Validation,RMSEV)的计算式如下: (25) 建模集均方误差和验证集均方误差可以用于评价模型的稳定性。验证集均方误差用于表示模型预测未知数据验证集中的目标值与实际值的差距,由于验证集的数据并未参与建模,该指标可以有效反映所用的算法建立的模型应用于实际检测时的表现[57]。 由上述分析可知,当实际对检测数据进行分析时,通常情况下会首先关注残差平方和,以此来初步推断校正算法的表现。当残差平方和能够满足测量精度要求时,可以对相关系数、拟合优度进行计算,用以进一步确定校正算法的精度及模型的准确性。此外,建立合适的校正算法后,还可以采用建模集均方误差、验证集均方误差作为评价指标,进一步从理论的角度分析校正算法中模型的稳定性,用以帮助进行算法的优化。 随着高电压与绝缘技术的发展,以SF6或环保气体为绝缘介质的气体绝缘电气设备大规模投运,该类设备内部绝缘状况的检测已成为相关领域的研究焦点。其中,对SF6及其分解气体进行定量检测来判断气体绝缘电气设备绝缘状态并分析故障类型和程度是近年来的研究热点。因此,多组分气体检测的相关问题具有重要的理论意义和实用价值。本文对气体绝缘电气设备中多组分气体检测的交叉干扰问题及其校正方法进行了综述,对交叉干扰的产生机理、校正方法的研究现状进行了总结。在目前的研究中,在交叉干扰的产生机理、校正方法、评估指标等方面均有众多成果: (1) 交叉干扰的本质是气体分子的吸收峰重叠。由于气体分子的谱线展宽特性,对同一束入射光而言,可能有多种吸收峰相近的气体分子均会产生吸收。从结果上而言,这会使得测得的电压信号携带了待测气体以外的信息,从而不能准确表征待测气体的体积分数。在使用分解气体法等分析方法对气体绝缘设备内部状况进行评估时,交叉干扰会致使测量结果不能真实反映待测气体的体积分数,从而无法反映气体绝缘设备内部的实际状况,阻碍相关人员对气体绝缘设备的检修和维护。 (2) 从交叉干扰的原理出发,目前对交叉干扰的校正方法可以分为两类:设备校正法和算法校正法。设备校正法是从交叉干扰的产生机理上进行校正,基本思想是收窄入射光的波段,使得在一个较窄的波段内仅有待测气体会对入射光进行吸收,从根源上消除交叉干扰的影响,这类方法的代表有可调谐激光器、单色仪等;但是囿于现有的技术水平、成本等因素,基于设备的校正方法受限于特定的实验条件,普适性较差,因此仍需要建立移植性较好、适用范围较大的算法校正方法,即基于现有的检测系统采集到的数据,通过算法对数据进行处理,分离出所需要的待测气体的信息,进而对待测气体的体积分数进行反演。 (3) 交叉干扰校正后,需要对校正方法进行评估,用以评价交叉干扰方法的可靠性。通常对实验数据进行交叉验证,通过建立交叉干扰校正方法的评价指标,对校正方法的质量进行评价。 尽管目前对于处理交叉干扰已有众多解决方法,但是仍然存在很多值得深入探究的问题: (1) 从原理上看,解决交叉干扰最好的方法是采用窄带宽光源,从而使得仅有待测气体在光源波段内有吸收,排除其他气体的干扰。但是这类光源一般可调谐范围较小,且往往是一个光源只能对应于一种气体的吸收谱线,这导致使用此类光源研制多组分气体检测仪器的成本较高。 (2) 对于基于算法的交叉干扰校正方法,应用的前提是大量的实验数据支持,所以通常只能够用于离线分析,而较难应用于在线检测。同时,考虑到实验条件的不同,在实验室中标定、计算得到的参数,可能不完全适用实际工程场景,这会导致算法的移植性降低,需要对算法进行进一步的优化和校正。 结合上述问题,可以对光学检测方法中出现的交叉干扰的校正算法进行如下展望: (1) 由目前的研究可知,交叉干扰的校正算法通常难以兼备良好的移植性与较高的准确性。移植性良好的算法通常模型较为简单,且包含一定的简化,当实际情况较为复杂时难以准确表示。另一方面,能够准确描述实际情况的模型,通常需要大量的调试以确定参数,这使得对应的算法移植性略显不足,模型泛化能力较差。因此,有必要研究新的算法,并使其移植性与准确性均达到较高水平。 (2) 通过校正算法的联合使用,可以有效结合多种算法的优点,从而增强基于算法的校正方法的泛化能力,以满足多组分气体在线检测的需求。因此,组合算法亦是基于算法的交叉干扰校正方法的主要发展方向。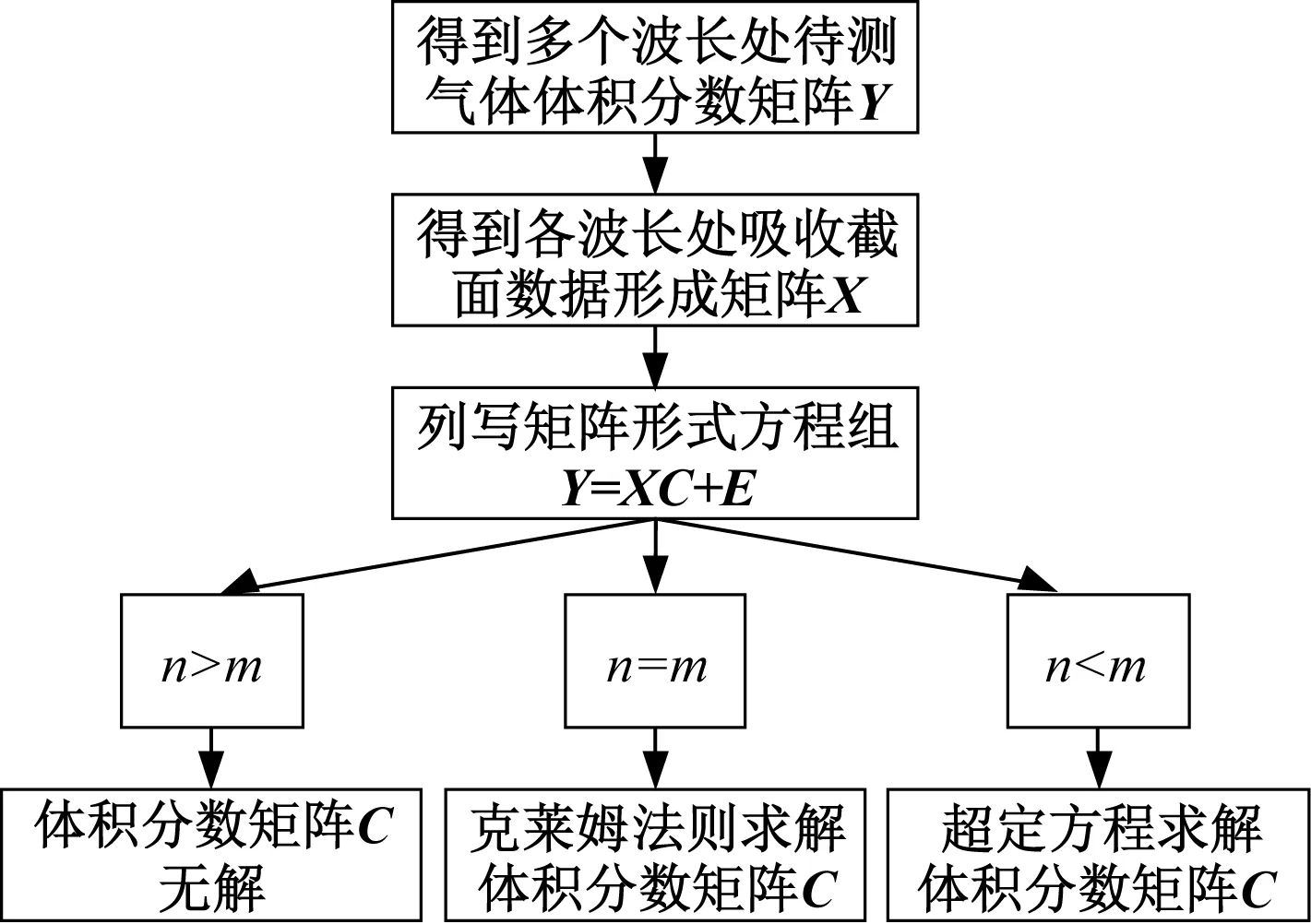
3.2 主成分回归

3.3 偏最小二乘
3.4 神经网络
3.5 小结
4 交叉干扰校正方法的评价指标
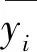
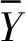
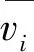
5 结论
