基于深度学习的障碍物检测与深度估计
2021-01-27仇旭阳黄影平郭志阳
仇旭阳,黄影平,郭志阳,胡 兴
(上海理工大学 光电信息与计算机工程学院,上海 200093)
从复杂的交通场景图像中准确地检测、辨识障碍物并实现深度估计是智能汽车研究的一个重要课题[1]。随着深度学习的发展,目标检测和识别进入到一个新的阶段。与传统的使用人工设计的特征,如LBP(local binary patterns)[2], HOG(histogram of oriented gradient)[3]等对目标进行特征提取,然后将提取到的特征输入到贝叶斯(Bayes)[4],SVM(support vector machine)[5]等分类器进行检测和识别的机器学习方法不同,基于深度卷积网络的检测方法具有强大的特征提取能力,能够更好地学习目标的特征,实现更高精度的检测。目前基于深度学习的目标检测方法主要分为基于候选区域的双步(two-stage)检测方法,如R-CNN[6], Fast RCNN[7],Faster R-CNN[8]等。这类算法将检测阶段分为两步,首先提取图片中目标可能存在的候选区域,然后再将提取的候选区域输入到卷积神经网络中进行特征提取,最后再进行检测和边界框修正[9]。这类算法的特点是检测速度较慢但检测精确度较高。基于边界框回归的单步(one-stage)目标检测算法如SSD[10],YOLO(you only look once)[11],YOLOv2[12],YOLOv3[13]等,这类算法不再需要区域建议阶段,直接由网络产生目标的类别概率和位置坐标,经过单次检测即可直接得到最终的检测结果,因此,具有更快的检测速度。其中,YOLOv3不仅检测精度较高,而且速度较快。但是,对于复杂交通场景中较小的障碍物,检测效果不佳。而且这些基于深度学习的障碍物检测方法,一般采用单目视觉方法,不能检测出目标的深度信息。
对障碍物的深度估计可以使用激光雷达、毫米波雷达、超声波等传感器。与使用传感器测距的方法相比,基于双目视觉的测距方法具有信息丰富、成本低的优点。双目测距方法是利用左右图像进行匹配,获取视差,计算目标的三维信息。在复杂交通场景中,对障碍物进行深度估计,只需要获取场景的图像,然后映射到视差图中,根据双目视觉的原理就可以估计出目标的距离。而目标检测算法可以识别和定位障碍物,从而获取障碍物的坐标信息。为了获取精度高的视差图,本文使用一个端到端的立体匹配网络PSMNet[14],其由空间金字塔池化模块和3D卷积神经网络模块组成,具有利用全局环境信息寻找不确定区域(遮挡区域、弱纹理区域等)左右图一致性的能力。
针对现有的基于深度学习方法的目标检测存在的问题,本文以YOLOv3为基础框架,对其进行改进,使用密集连接卷积网络(DenseNet)[15]替换YOLOv3中尺度较小的传输层,加强特征融合和重用,提出了改进后的Dense-YOLO网络,提高了在复杂交通场景中对较小障碍物的检测精确度。在检测的基础上,采用立体匹配网络PSMNet获取双目图像的视差图,对Dense-YOLO网络检测到的目标区域利用立体视觉原理进行深度估计,实现了对各类障碍物检测的同时提供其距离信息。
1 方法总体框架
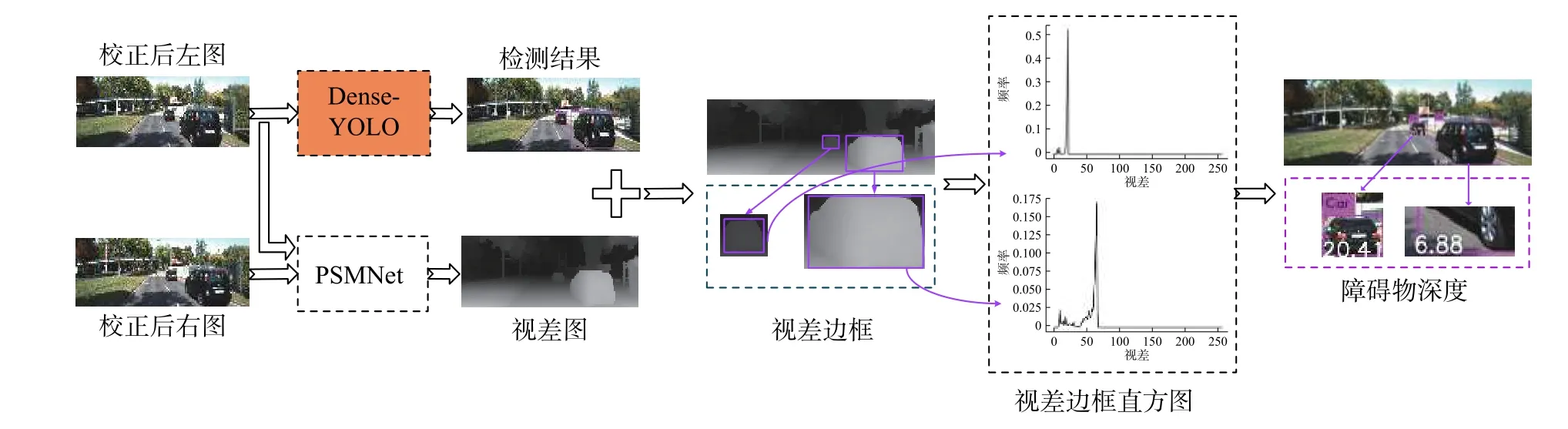
图1 方法总体框架Fig.1 Framework of the proposed method
本研究的主要任务是检测交通场景下的障碍物并计算出其距离。为了提高障碍物的检测和测距的精度,本文结合深度学习和双目视觉构建一个障碍物检测和测距系统。图1是系统的总体框架。
如图1所示,首先以校正后的双目图像作为输入,为了提高目标检测的精度,使用以YOLOv3为基础的改进的Dense-YOLO网络获得高效的检测结果。然后利用PSMNet立体匹配算法得到图像的视差图,并将检测得到的障碍物目标框映射到视差图中。为了排除背景等非障碍物视差对测距精确度的影响,使用视差直方图来统计边界框中每个像素的视差,选取频率最大的视差值作为障碍物的视差。最后利用双目视觉测距原理计算出每个障碍物的距离。
2 障碍物检测
在YOLOv3的基础上使用密集连接卷积网络(DenseNet)进行改进,得到改进后的深度卷积神经网络Dense-YOLO。
2.1 YOLOv3
YOLOv3网络是在YOLO和YOLOv2网络基础上改进而来的。YOLOv3的检测原理如图2所示。tx,ty分别为边界框的横坐标和纵坐标,tw,th分别为边界框的宽度和高度。
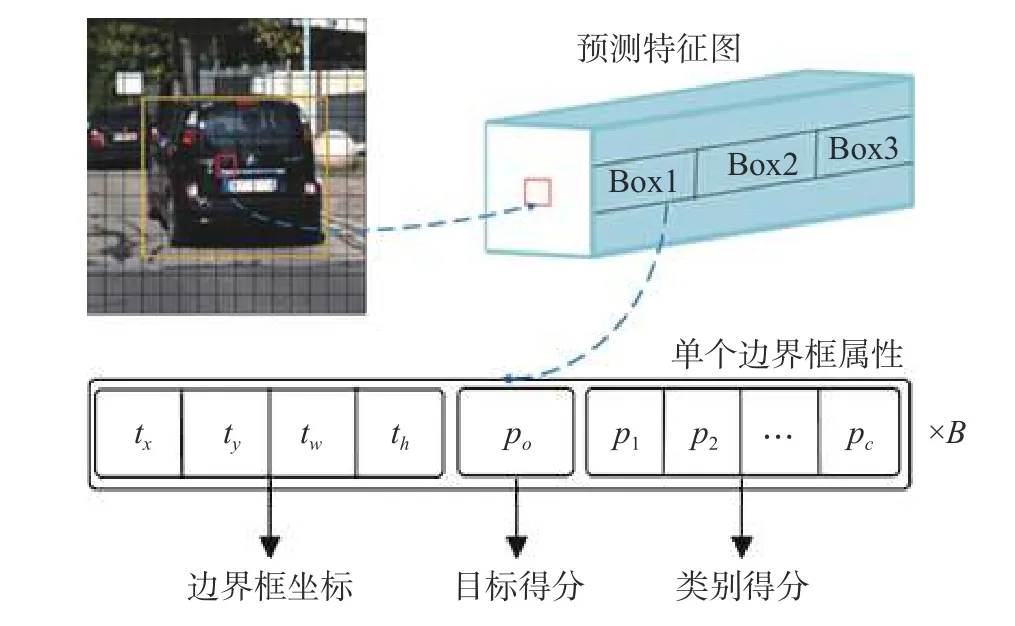
图2 YOLOv3检测原理Fig. 2 YOLOv3 detection principle diagram
网络将输入图像划分为S×S个网格,如果目标真实边界框的中心落在网格中,那么,该网格负责检测该目标。每个网格预测B个边界框、1个目标置信度得分po和C个类别得分(p1,p2,···,pC)。其中,目标置信度c定义为

置信度反映了网格是否包含对象,以及在包含对象时预测的边界框的准确性。当目标在网格中时,pr=1;否则,用于表示真实边界框与预测边界框之间的重合度。当多个包围框检测到同一个目标时,YOLOv3使用非极大值抑制(NMS)方法来选择置信度得分最高的边界框。
2.2 DenseNet
改进目标检测网络的主要方向为增加网络深度或增加网络宽度,密集连接卷积网络(DenseNet)则是从特征入手,通过对特征的极致利用达到更好的效果和更少的参数。
密集连接网络在前馈模式下将当前层与前面所有层连接起来,因此,第l层会接收x0,x1,···,xl-1层的特征映射作为输入,这样就可以实现层与层之间最大程度的信息传输。
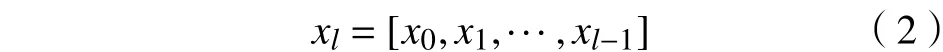
式中:xl为前 1-l层特征图的拼接结果;[x0,x1,···,xl-1]为x0,x1,···,xl-1层的特征图拼接,即作通道的合并。
2.3 Dense-YOLO
在神经网络训练过程中,由于卷积和下采样的存在,使得特征向量不断减少,在传输过程中丢失了很多特征信息,这就可能会导致对障碍物检测效果不好,出现漏检或者错检。而DenseNet网络可以有效地利用上一层或者前几层特征信息,同时当前层的特征图也会作为后面每一层的输入,从而促进特征重用。所以,本文在YOLOv3网络的基础上用密集连接网络对网络进行修改,使用DenseNet代替尺度较小的传输层,将当前层之前的多层特征作为输入传递到当前层,重复利用各层特征信息,强化特征传播,并且还可以减少网络计算量。本文所设计的网络结构如图3所示,Hl(·)为处理拼接特征图的函数。网络各层参数的设置如图4所示。
图3中,本文使用的非线性变换函数Hl(·)是一个组合操作,其包括一系列批量归一化(BN)、整流线性单元(ReLU)和卷积(Conv)操作。在分辨率为30×30的特征层中,xl由64个子特征层组成。H1(·)先对x0进行BN-ReLU-Conv(1×1)非线性计算,然后再进行BN-ReLU-Conv(1×1)非线性运算。H2也对拼接的特征图[x0,x1]执行上面相同的操作。H2,H3以相同的方式完成上述操作。最后,由[x0,x1,x2,x3]拼接的特征图和尺寸为30×30×512的特征层继续向前传播。在分辨率为16×16的特征层中,xl由128个子特征层组成。按照上述方法进行特征层拼接和特征传播,最后将所有特征层拼接成尺寸为15×15×1024的特征层前向传播。改进的检测模型预测了3种不同尺度的边界框:15×15,30×30,60×60,并能较好地实现车辆前方的轿车、行人、骑行者、卡车等障碍物的检测。
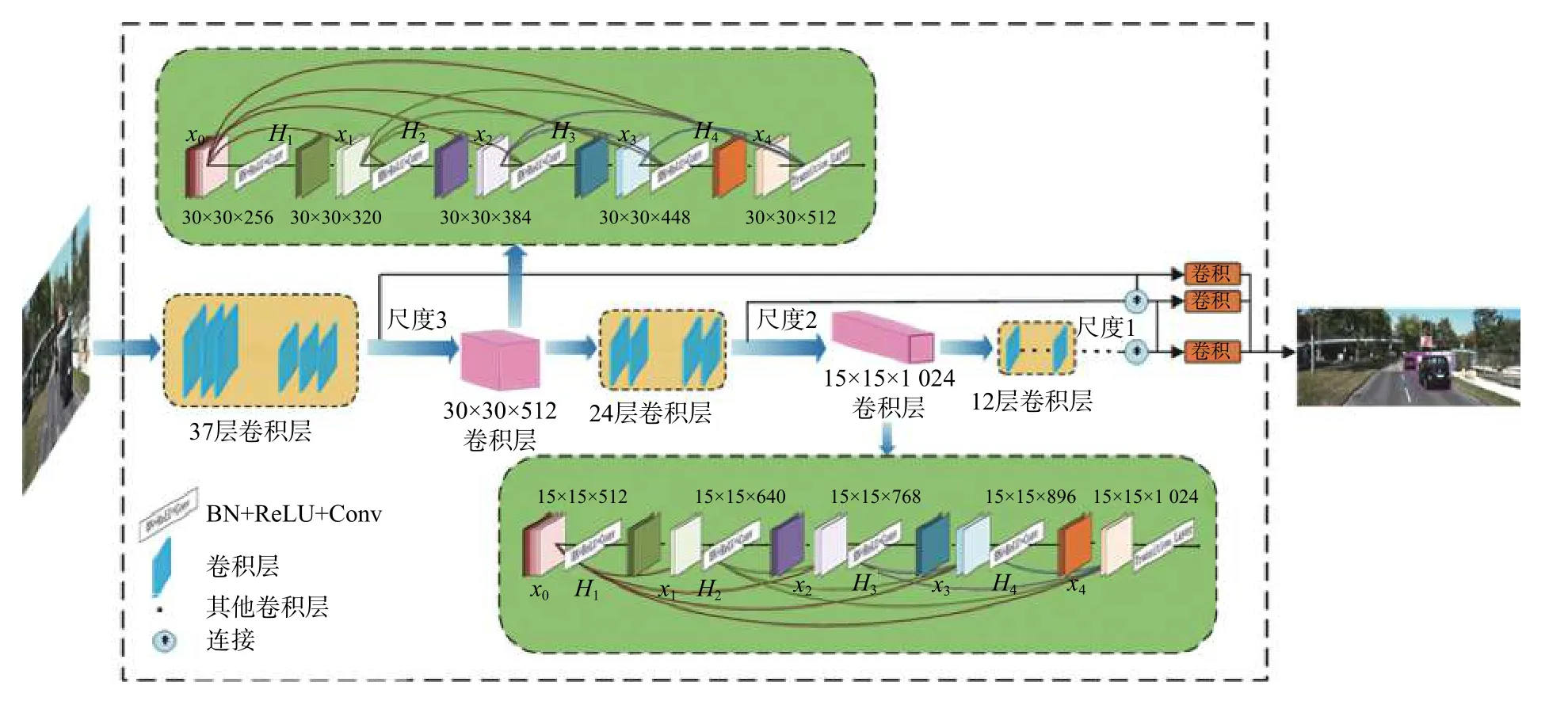
图3 Dense-YOLO网络结构图Fig.3 Dense-YOLO network structure
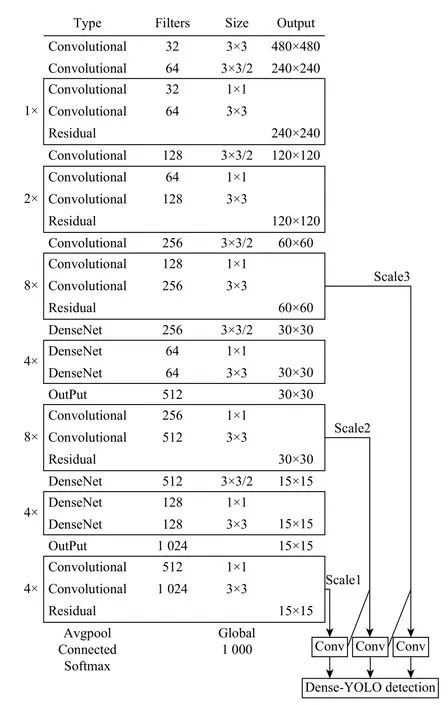
图4 Dense-YOLO网络参数Fig. 4 Network parameters of Dense-YOLO
3 障碍物深度估计
3.1 立体视觉原理
双目立体视觉是计算机视觉的一个重要分支。双目视觉遵循人眼观察物体的原理,利用2台摄像机从不同角度观察同一目标物体,同时获得两幅图像,经过极线校正、匹配等过程后可以计算图像像素点的视差,进而获得目标的三维坐标信息[16]。双目视觉模型如图5所示。
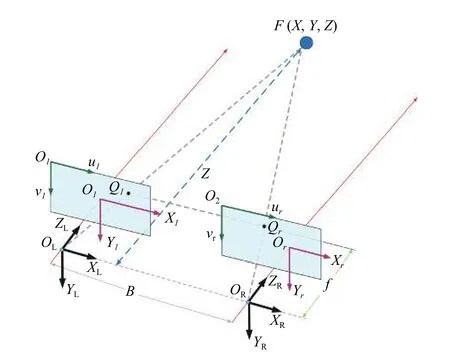
图5 平行双目视觉模型Fig. 5 Parallel binocular vision model
在图5中,2个相机水平放置,焦距均为f。oL和OR分别是左右相机的光心,2个光心之间的距离称为基线B。OLOl和OROr是2条平行线,分别表示左、右相机的光轴。F(X,Y,Z)是世界坐标系里的一个目标点,它透过透镜的投影中心投影到像平面上的点Ql(xl,yl)和点Qr(xr,yr)。将世界坐标原点设为光心OL。然后通过简单的数学模型,可以得到三维世界坐标的表达式:OL(0,0,0),OR(B,0,0),Ql(xl,yl,f),Qr(xr+B,yr,f)。对于世界坐标中的任意一点F,Ql和Qr的y值相等,即yl=yr。△FQlQr和△FQLQR相似。根据相似三角形原理,可以得到如下关系式:
xl-xr为视差,令d=xl-xr,式(5)可改写为
即

如式(5)所示,如果能够获取左、右图像对应像素点的视差,就可以估计出目标的深度。
3.2 立体匹配预测距离
立体匹配是利用校正后的左、右图像获得场景视差图的过程。考虑到需要稠密视差图来提取整个目标的像素点,利用PSMNet算法获取视差图。为了消除背景视差对测量距离的影响,本文利用视差直方图来描述检测边框中的视差的分布。首先将视差值量化到[0,255],并计算每一个视差的频率f(disparity)。在直方图中,障碍物视差的频率f(disparity)是较大的,并且应该是一个峰值。然后选取每一个直方图的峰值所对应的视差作为障碍物的视差。最后根据式(5)可得到障碍物的深度。
4 实 验
4.1 数据集
采用智能车计算机视觉算法评测数据集KITTI[17]中的图片,并对原有的8类标签信息进行处理,保留实验需要的4个类别标签,即轿车、行人、骑行者和卡车,并将Van归并到Car类。同时选取该数据集中7481张图像作为实验数据。为了使得网络充分学习待检测目标的特征,通过车载Point Grey相机采集了实际场景中的3000张图像,并使用YOLO_mark标注工具进行标注。最后将2个数据集混合作为实验的数据集,并随机选择80%的图片作为训练集,其余20%的图片用于测试。
4.2 训练
网络参数设置如表1所示。实验条件为:Intel Xeon(R)Silver 4110 CPU,主频2.1 GHz,内存32 GB;NVIDIA GeForce GTX 1080Ti GPU。

表1 Dense-YOLO的初始化参数Tab.1 Initialization parameters of Dense-YOLO
在确定训练参数后对YOLOv3和改进的YOLOv3分别进行训练。训练次数设置为50000次,学习率在35000次后下降到0.0001,在45000次后下降到0.00001,使损失函数进一步收敛。同时利用旋转、调整饱和度和色调等方法对数据集中的图像进行增强和扩充,以增强模型的鲁棒性。
4.3 评价指标
现介绍评价模型有效性的相关指标。
精确率和召回率定义为
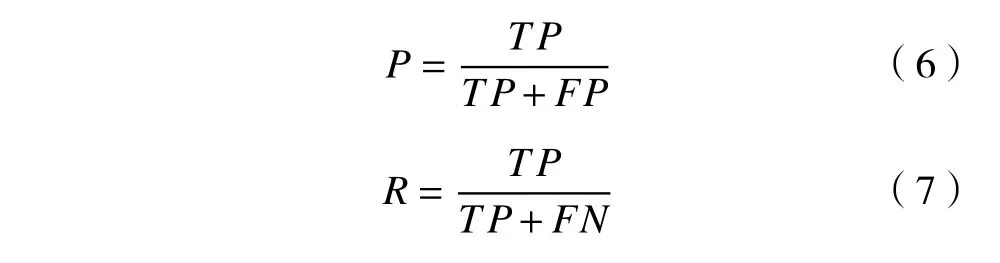
式中:TP表示真阳性数;FP表示假阳性数;FN表示假阴性数。
交并比IoU是定义目标检测精度的标准。通过计算预测边界框与真实边界框的重叠率,对模型的性能进行评估。IoU的定义为
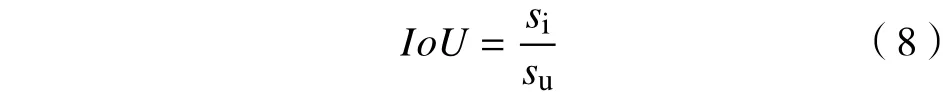
式中:si为预测边界框与真实边界框的交集面积;su为2个边界框的并集面积。
IoU重叠阈值采用与KITTI相同的标准,IoU对轿车的检测阈值为0.7,对行人、骑行者和卡车的检测阈值为0.5。
平均精确度AP也用来评估模型的性能。AP即P−R曲线下的面积,其定义为
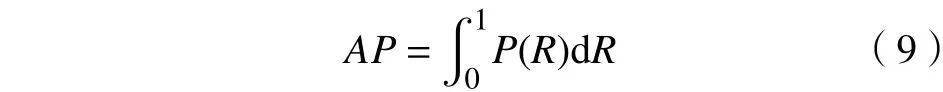
式中,P(R)为不同召回率所对应的精确率。
AP值越大,性能越好。而对于每一个类别的AP求均值即可得到平均精度均值mAP。
4.4 结果分析
4.4.1 障碍物检测结果分析
Dense-YOLO与YOLOv3检测精度对比数据如表2所示。对比表2中2种检测算法的检测结果可知,本文提出的算法在测试数据集中各类障碍物检测的AP和mAP与YOLOv3相比分别提高了约3%~5%和4%。其中,对于轿车的检测平均准确度最高,为91.33%;对卡车的检测平均准确度最低,为79.83%。
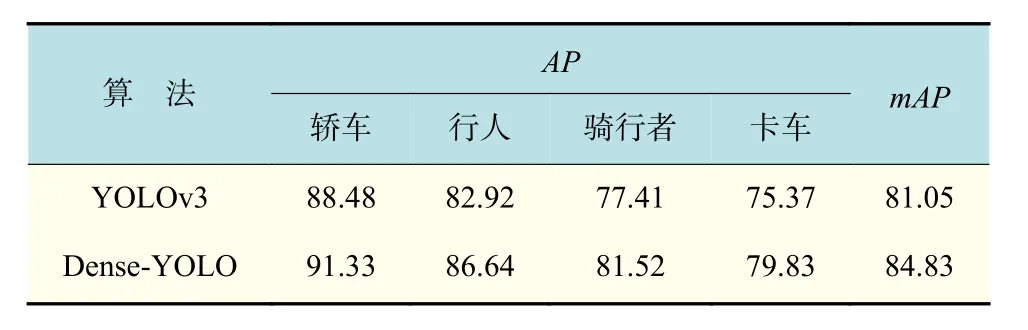
表2 YOLOv3和Dense-YOLO对4类障碍物检测结果对比Tab.2 Comparison between the detection results of the fourclass of obstacles by YOLOv3 and Dense-YOLO %
图6分别展示了测试集中对轿车、行人、骑行者、卡车这4类障碍物采用Dense-YOLO和YOLOv3这2种模型进行测试的精确率−召回率曲线。通过比较曲线下的面积,可以看出本文方法(Dense-YOLO)在4个类别中均取得了更好的检测效果。
图7是YOLOv3和本文方法障碍物检测结果对比图。图7(a)选取KITTI数据集中的2个场景,左边是YOLOv3检测效果,右边是本文方法检测结果。从图7中可以看出,对于第一个场景,YOLOv3漏检了一个骑行者;对于第二个场景,YOLOv3漏检了一辆车,而本文方法没有出现这种情况。图7(b)是在校园中采集的2个交通场景图,对于第一个场景,YOLOv3漏检了一辆车、一个骑行者和2个行人等尺寸较小的障碍物;对于第二个场景,YOLOv3漏检了2个行人。本文方法同样能准确地检测出YOLOv3漏检的障碍物。因此,与YOLOv3算法相比,本文方法无论是在KITTI数据集中还是实际交通场景中,都有良好的检测效果。
4.4.2 障碍物深度估计结果分析
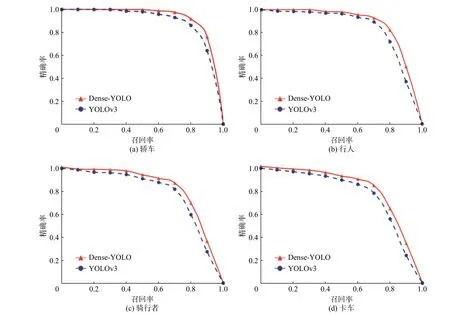
图6 Dense-YOLO和YOLOv3对4类障碍物的P-R曲线图Fig.6P-R curves using Dense-YOLO and YOLOv3 to detect the four classes of obstacles
定性分析:使用本研究方法对KITTI数据集进行深度估计,并将结果与来自KITTI数据集的真实值进行比较。图8给出了KITTI数据集中2个场景障碍物检测的结果和被检测障碍物的估计深度和真实值。图8(a)是障碍物的距离真实值,图8(b)是Dense-YOLO检测结果以及本文方法所估计出的被测障碍物深度。从图中可以看出,Dense-YOLO能准确地检测和定位到障碍物,并且能识别出障碍物的类别。在障碍物检测结果的基础上,本文的深度估计方法能够较好地估计出障碍物的距离,具体的对比结果如表3所示。

图7 障碍物检测结果:轿车、行人、骑行者、卡车Fig.7 Results of obstacle detection: car, pedestrian, cyclist, truck

图8 方法对KITTI数据集的深度估计Fig.8 Depth prediction of KITTI by the following method
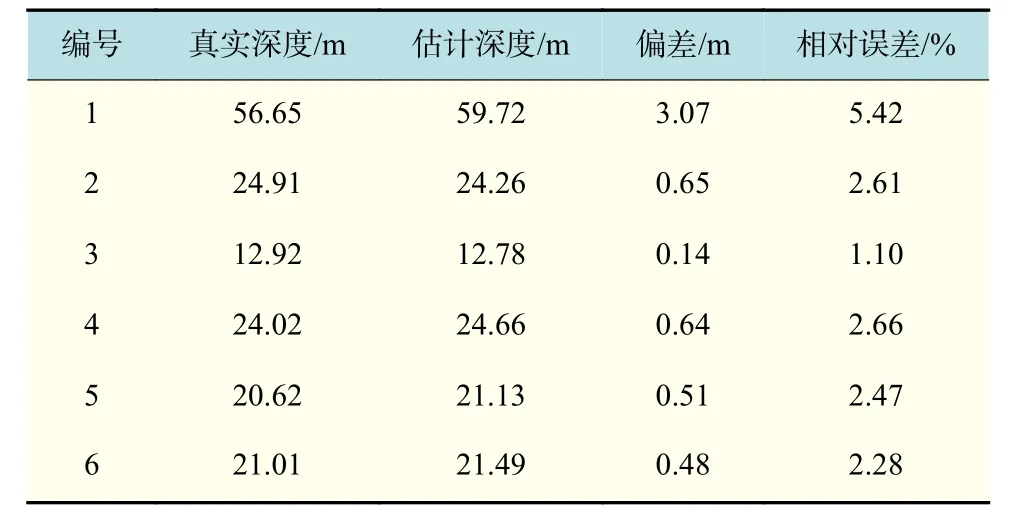
表3 估计深度与真实值比较Tab.3 Comparison between the estimated and ground-truth values of depth
定量分析:对本研究方法估计的深度的相对误差进行了性能评价,相对误差定义为式中:dp为本方法估计出的障碍物深度;dt为真实值。

表3给出了上述2个场景中被测目标的深度估计结果以及与真实值的比较。由表3可知,当障碍物深度真实值在10 m左右时,相对误差约为1%;当障碍物深度真实值在20 m左右时,相对误差约为2.4%;当障碍物深度真实值在25 m左右时,相对误差约为2.7%。随着真实值的增加,相对误差也在增加。
5 结束语
为了满足自动驾驶车辆安全智能的需求,提出了一种交通场景中的障碍物检测和深度估计方法。首先,使用DenseNet网络对YOLOv3网络进行改进,得到一个新的障碍物检测网络(Dense-YOLO),对输入的图片进行检测和识别,得到障碍物的类别和边界框;然后,结合立体匹配模型PSMNet获取视差图,将目标框映射到视差图中,根据双目测距原理估计出障碍物的深度。在KITTI数据集和真实交通场景的实验结果表明,本文方法的检测精度优于YOLOv3算法,并且对被测障碍物的深度估计结果接近于真实值。本文方法对单个图像测试的时间成本分别约为0.276 s。综上,本文方法基本满足自动驾驶场景中障碍物的检测与深度估计。
