基于深度学习的智能车辆视觉里程计技术发展综述*
2021-01-24陈涛范林坤李旭川郭丛帅
陈涛 范林坤 李旭川 郭丛帅
(长安大学,西安 710064)
主题词:视觉里程计 深度学习 智能车辆 位置信息
1 前言
随着车辆逐渐向自主化、无人化方向发展,车辆的位置信息成为其执行决策时的重要参考因素。智能车的定位可分为绝对定位和相对定位,其中相对定位法主要包括惯性导航和里程计法,2种方法都不可避免地存在误差累积且难以消除。惯性导航效果的优劣受惯性测量单元(Inertial Measurement Unit,IMU)精度的影响较大,高精度IMU 的成本较高。随着计算机视觉的发展,通过视觉采集到的信息不但可以满足车辆定位的需求,而且可以进行车辆和行人的识别,同时,视觉传感器成本较低、体积较小、布置方便,因此,视觉方案是同时考虑成本、稳定性、精度和使用复杂度时的最佳方案。
视觉里程计(Visual Odometry,VO)是无接触的位姿估计过程,根据单个或多个相机的输入得到系统每一时刻之间的相对位姿,同时可以根据输入的图像序列恢复场景的空间结构。1980年,Moravec 等人首次提出从连续的图像中估计相机位姿的思想[1]。Matthies 等人于1985年提出了经典的视觉里程计框架[2],该框架主要包括特征提取、匹配和帧间位姿估计,并一直作为视觉里程计的主要框架沿用至今,根据这一框架发展得到的VO 系统称为基于模型的VO。根据图像信息利用方式的不同,基于模型的VO 可以分为直接法VO 和特征法VO。现有表现较好的VO 系统多是基于模型的[3],但是这些VO 系统必须被准确标定,而且要运行在光照稳定、纹理充足的环境中,同时,在大场景中的鲁棒性较低,无法对场景信息进行语义理解,另外,单目VO因其尺度不确定性而无法得到车辆的真实运动尺度。
目前,深度学习在物体识别、分类、同步定位与地图构建(Simultaneous Location and Mapping,SLAM)的回环检测和语义分割等方面都取得了不错的效果[4]。相较于人工设计特征,深度学习以端到端的方式从大量数据中学习特征,得到鲁棒性更好、效率更高的特征,从而能够有效解决基于模型的VO 在光照条件恶劣的情况下鲁棒性低、回环检测准确率低、动态场景中精度不高、无法对场景进行语义理解的问题,因此,基于深度学习的VO是VO系统的重要发展方向之一。
很多学者针对VO系统进行了综述:李宇波等人综述了VO的发展过程,将VO分为单目、双目、多目,从鲁棒性、实时性和精确性3个方面对VO进行分析[5];Amani等人将当时的VO 系统进行分类,根据系统的输入、输出特性分析其特点[6];Mohammad等人将VO与其他的定位方式进行比较,并将当时效果较好的VO 进行对比,分析了VO 的应用难点和存在的挑战[7];He 等人综述了单目VO的发展现状与代表性的VO系统[8];李传立等人将基于模型的VO分特征法和直接法进行了综述[9]。但是这些综述均面向基于模型的VO,而没有考虑基于深度学习的VO。由于VO 是视觉同步定位与地图构建(Visual Simultaneous Location and Mapping,VSLAM)的组成部分,一些基于深度学习的SLAM的综述中会提到基于深度学习的VO[10-14],但将重点集中于SLAM 系统,对基于深度学习的VO 的综述不够全面。本文针对有监督、无监督和模型法与学习结合的视觉里程计,主要从帧间运动估计、系统的实时性、鲁棒性等方面对基于深度学习的智能车辆VO系统进行分析,综述基于深度学习的智能车辆VO的发展现状、现存的不足与发展趋势,为基于深度学习的智能车辆VO和VSLAM前端的发展提供建议。
2 基于模型的VO
基于模型的VO 主要包括相机标定、图像特征匹配、相机位姿估计,当考虑VO的全局位姿信息时,还包括相机位姿的全局优化。如果将整幅图像视为一个矩阵来考虑,不但增大了计算量,同时也很难准确估计相机位姿,因此一般考虑图像的部分像素信息,并据此估计相机位姿。根据图片像素信息的2种不同利用方式,将基于模型的VO 分为特征法VO 和直接法VO,图1 所示为基于模型的车辆VO位姿估计过程,A0、A1分别为空间点A在I0、I1帧上的投影。

图1 基于模型的车辆VO位姿估计
2.1 特征法VO
特征法VO首先在图像中选取特征,这些特征在相机视角发生少量变化时保持不变,于是可以在各图像中找到相同的点,在此基础上对相机位姿进行估计。一组好的特征对位姿估计的最终表现至关重要,其中角点相较于边缘和区块更容易区分,是特征法VO 的研究重点。角点提取算法有很多,如Harris 角点、FAST 角点、GFTT 角点等[8]。为了增加角点的可重复性、可区别性、高效率和本地性,研究者设计了更多稳定的图像局部特征,最具代表性的有SIFT(Scale Invariant Feature Trans⁃form)、SURF(Speed-up Robust Features)、ORB(Oriented FAST and Rotated BRIEF)等[8]。
根据已经匹配好的特征估计相机位姿时,由于相机类型和特征点不同,相机位姿估计算法也不相同。当相机为单目相机时,已知2D 的像素坐标,根据所有的2D匹配点使用对极几何法计算相机的相对运动;当相机为双目或深度相机时,已知特征点的3D坐标,通常用迭代最近点(Iterative Closest Point,ICP)算法估计相机位姿;当已知一些特征点在世界坐标系下的3D坐标和像素坐标时,常用PnP(Perspective-n-Point)、EPnP(Efficient Perspective-n-Point)、P3P(Perspective-Three-Point)算法。此外,为了使得到的位姿达到全局最优,常用光束法平差(Bundle Adjustment,BA)算法或滤波算法对相机位姿进行全局优化。
MonoSLAM 是由Davison 等发明的第一个成功应用单目摄像头的纯视觉SLAM 系统[15],系统以扩展卡尔曼滤波为后端,追踪前端是非常稀疏的特征点;PTAM(Parallel Tracking and Mapping)是首个以优化为后端的SLAM系统,该系统首次区分出前、后端的概念,同样引领了后期很多VSLAM 的设计[16];Mur-Artal 等人提出的ORB-SLAM 是特征点法SLAM 的集大成者[17],首次提出了基于ORB的BOW(Bag of Words)回环检测方法。
特征点法VO 因其较强的鲁棒性和较高的精确性成为目前主流的VO,但是特征的提取与描述子的计算耗时较多,使用特征时忽略了图片的其他信息,VO的运行环境遇到特征缺失的情况时无法找到足够的特征计算相机运动是特征法VO的主要缺点。
2.2 直接法VO
直接法VO是为了克服特征点法VO的不足而存在的,直接法根据像素的亮度信息估计相机运动,可以不寻找特征和描述子,既节省了计算时间,也避免了特征缺失的情况,只要场景中存在明暗变化,直接法就能工作。根据使用像素数量的多少,直接法分为稀疏、稠密和半稠密3种。与特征点法只能重构稀疏特征点相比,直接法还具有恢复稠密和半稠密结构的能力。
LSD-SLAM[18-19]是Engel 等为了构建半稠密三维地图提出的算法,该算法采用直接法进行数据关联,由深度估计、跟踪和建图3个线程组成。该方法对图像点建立随机深度图,并在后续帧中对深度进行调整,直至收敛。该方法的初始化不需要多视图几何约束,不会陷入多视图几何退化的困境,但初始化过程需要多个关键帧深度图才会收敛。直接稀疏里程计(Direct Sparse Odometry,DSO)[20]是直接法的拓展,其使用光度值误差最小化几何和光度学参数。DSO对图像中有梯度、边缘或亮度平滑变化的点均匀采样以降低计算量,并且对光度学模型校正、曝光时间、透镜光晕和非线性响应都进行了校准。为了提高速度、降低计算量,DSO 使用滑动窗口方法,对固定帧数的位姿进行优化;DPPTAM(Dense Piecewise Planar Tracking and Mapping)[21]基于超像素对平面场景进行稠密重建,该方法对图像中梯度明显的点进行半稠密重建,然后对图像中其他点进行超像素分割,通过最小化能量函数完成稠密重建。
此外,直接法的缺点也很明显:完全依靠梯度搜索达到降低损失函数的目的,但图像是强烈的非凸函数,这很容易使得优化算法陷入局部最优;单个像素的区分度不明显;灰度不变性是个很强的假设,在很多情况下不会满足。
基于模型的VO 已经可以达到很好的效果。以ORBSLAM为代表的特征法VO和以DSO为代表的直接法VO都可以在特定环境下达到很高的精度,同时保证系统的实时性,但是在缺少特征、光照变化明显、车载相机运动剧烈的恶劣环境中,这些系统的鲁棒性很难得到保证。深度学习在计算机视觉领域的成功应用给了研究者们一些启示,利用深度学习的方法可以从输入图像中自动提取特征,相较于人工设计的特征,其充分利用了图像的信息。因此,通过提高对环境的学习能力来提高VO的鲁棒性和精度是一条有效的解决途径,并已经成为现阶段VO研究路线的一个重要分支。图2所示为3种视觉里程计框架。
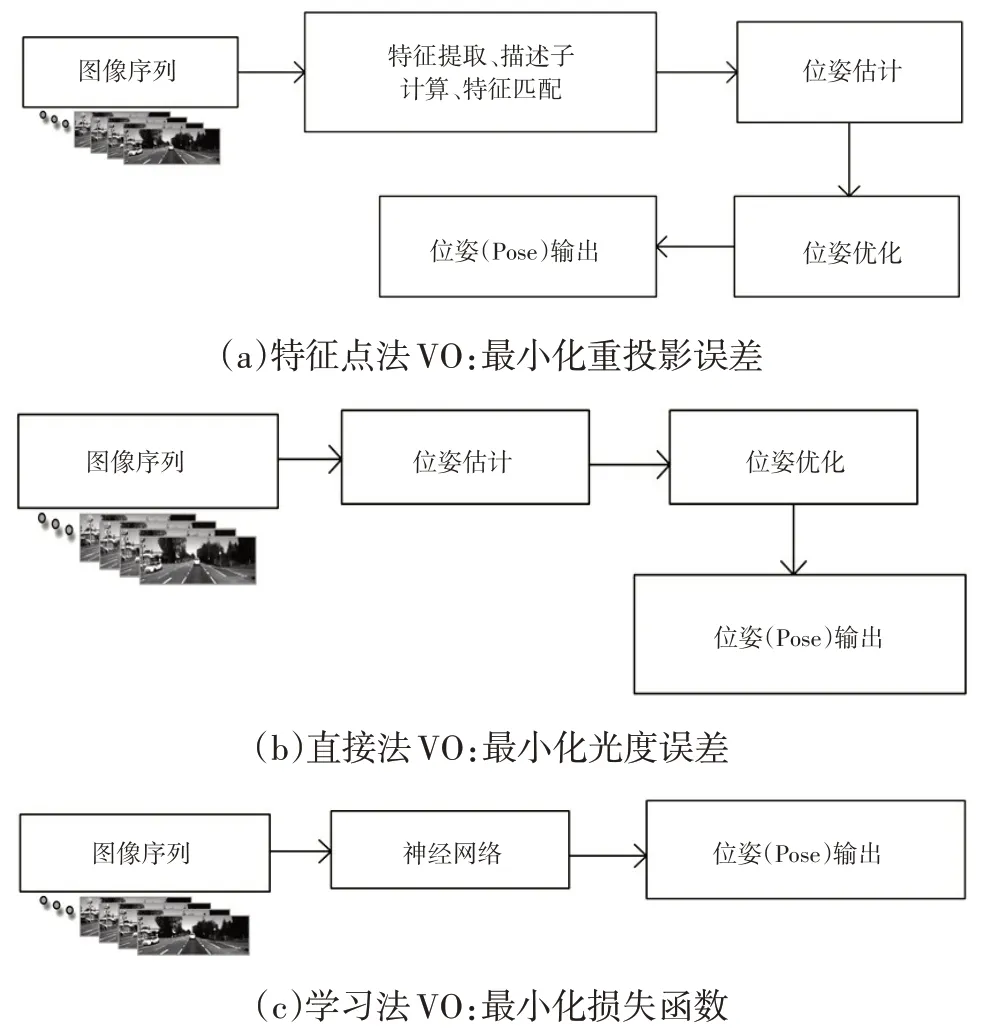
图2 3种视觉里程计框架
3 基于深度学习的VO
基于深度学习的VO 以端到端的方式进行帧间位姿估计,输入为图像序列,输出是图像的相对位姿,包括位移和旋转,位姿估计效果往往取决于网络的架构和损失函数的形式。卷积神经网络(Convolution Neural Network,CNN)是位姿估计网络中常用的网络结构,主要由卷积层、池化层、全连接层组成,其中卷积层是CNN的核心,不同的卷积核从图像中自动提取不同的特征,得到的特征可以更充分地代表图像的信息。由于车载相机的位姿变化具有连续性,循环神经网络(Recurrent Neural Network,RNN)也已经用于位姿估计网络。RNN通过反馈循环来保持隐藏状态的记忆,并对当前输入与之前状态间的依赖关系进行建模。训练模型时根据训练数据是否带有标签,可以将基于深度学习的VO分为有监督的VO、无监督的VO和半监督学习的VO。
3.1 智能车数据集
基于学习的VO需要大量的数据对搭建的模型进行训练。KITTI数据集由德国卡尔斯鲁厄理工学院和丰田美国技术研究院联合制作,是目前国际上最大的自动驾驶场景下的计算机视觉算法评测数据集,用于评测立体图像(Stereo)、光流(Optical Flow)、视觉测距(Visual Odometry)、3D物体检测(3D Object Detection)和3D跟踪(3D Object Tracking)等计算机视觉技术在车载环境下的性能;Cityscapes 数据集采集了50个城市不同季节的街道车辆运行数据,目标是用于场景语义理解;Mapillary 数据集是由位于瑞典马尔默的公司Mapillary AB开发的,用来分享含有地理标记照片的服务,其创建者希望利用众包的方式将全世界(不仅是街道)以照片的形式存储;Comma.ai’s Driving Dataset的目的是构建低成本的自动驾驶方案,目前主要应用场景是使用改装手机来辅助自动驾驶,开源部分主要是行车记录仪的数据;Apolloscape是百度的自动驾驶数据集,有很多复杂场景的道路。目前,智能车数据集以视频和图片为主,随着越来越多公司的加入和众包方式的应用,公开的数据集会越来越丰富。表1列举了部分主要的智能车数据集。
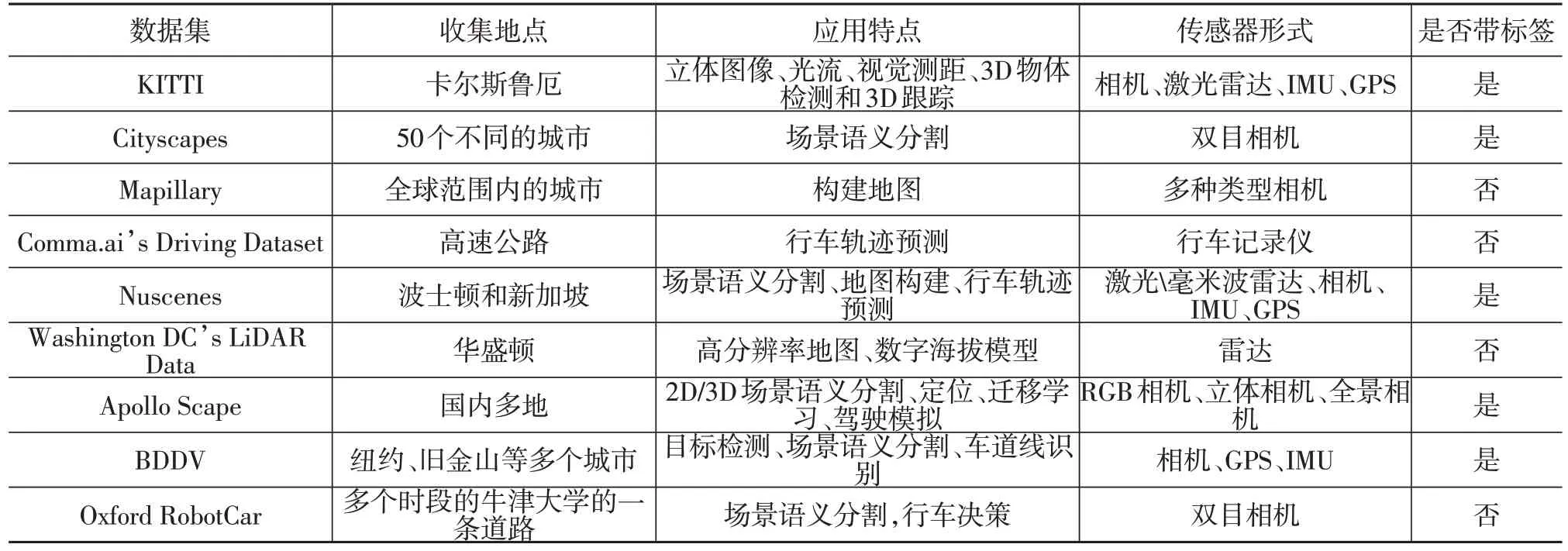
表1 部分主要智能车数据集
3.2 有监督学习的VO
A.Kendal 等人于2015 年提出的PoseNet 是早期利用深度学习进行位姿估计的典型代表[22],PoseNet 网络使用CNN 进行相机位姿估计,通过真实相机位姿的数据集进行训练,其使用的损失函数为:
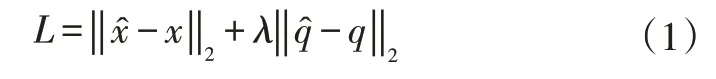
式中,x和q分别为CNN 估计的相机的三维坐标和旋转四元数;分别为相机的真实三维坐标和旋转四元数;λ为三维坐标和位姿损失函数的平衡因子。
经过充分训练后,PoseNet 的位姿估计精度与基于模型的VO相当。
为了确定位姿估计的不确定性,Kedall 等人在PoseNet 的基础上进一步增加Dropout 层,提出了Bayesian PoseNet[23],在这个网络中平衡因子λ的选择同样至关重要,之后又在PoseNet 的基础上提出了一种混合网络[24],这种网络在训练过程中可以自动调整平衡因子λ,不但使网络的性能得到提升,而且可以得到网络的不确定性。
Oliveira 等人构建了一个度量网络,进行帧间位姿估计和拓扑网络关系学习,对相机进行定位[25]。度量网络将轨迹分割成有限的位置点的集合,利用CNN 来学习拓扑网络间的关系,通过将该网络与自定位网络相结合,系统表现出了很好的定位特性。DeTone 等人提出的HomographNet用CNN来预测双目图像的单应性矩阵参数[26],使用大量数据进行长时间训练后,网络的性能优于基于ORB特征点估计的单应性矩阵参数算法。
2017年,Wang等人提出的DeepVO单目视觉测距系统[27]是有监督学习VO 的里程碑成果,之后的很多研究是以此为基础进行的。该系统中时间图像序列通过长短期记忆网络(Long Short-Term Memory,LSTM)模块引入RCNN(Recurrent Convolution Neuro Network),以端到端的方式训练RCNN估计摄像机的运动,网络结构如图3所示。试验结果表明,该系统的精度和鲁棒性在当时的VO中有很强的竞争力。同时,Wang等人在Costante等人的研究基础上,通过改善DeepVO的网络结构实现了估计系统不确定性的功能[28]。Melekhovetal等人在DeepVO的基础上利用CNN提出了相机摄影预估系统[29]。Turan 等人提出了类似于DeepVO 的Deep EndoVO[30],并将其应用于软骨机器人领域[31],取得了不错的效果。基于学习的方法总是存在泛化的问题,为了提高基于有监督学习VO的泛化能力,Saputra等将课程学习(即通过增加数据复杂性来训练模型)和几何损失约束[32]加入到DeepVO中,知识提炼(即通过教一个较小的模型来压缩大模型)也被应用到该框架中,以减少网络参数的数量,使其更适合在移动设备上进行实时操作[33]。

图3 DeepVO的网络架构[27]
Ummenhofer 等人利用一系列编码-解码网络提出了有监督的DeMoN 系统[34]。该系统专门设计了迭代网络,可以同时估计相机运动、图像景深、场景平面和光流,但需要大量标记有相关标签的数据进行训练。Peretroukhin等人没有直接使用深度神经网络预测相机的姿势[35],而是使用基于模型的几何估计器进行位姿预测,提出了DPC-Net,然后使用CNN 进行预测位姿校正,也就是对提出的CNN进行训练,从基于模型的估计器中学习位姿真实值与预测值之间的误差,同时,该网络也可以减少相机参数标定带来的影响。
Costante 等人提出了一种CNN 体系结构,称为LSVO[36],该网络将时间图像对作为输入,以端到端的形式进行训练。LS-VO 由一个自动编码器网络组成,用于对光流的表示方式进行学习,用一个位姿估计网络来预测摄像机的位姿,但是没有解决尺度漂移的问题。为了解决这个问题,Frost 等人采用CNN 从连续的视频帧中进行速度回归[37],通过将估计速度进一步集成到集束调整中,成功实现了尺度漂移校正。
对比以上研究可以发现,有监督学习VO的基本思路为通过使用有标签的数据集训练神经网络,得到利用图片信息映射相机的位姿变化信息的网络结构,从而实现定位。得益于机器学习技术的发展和芯片计算能力的提高,这些端到端的学习方法可以直接从原始图像中自动学习相机位姿变换,并且可以达到甚至超越基于模型的VO的效果。但是,有监督学习的方法需要大量有标签的数据来训练网络,而对数据集进行标注需要大量工作,这限制了其应用范围。
3.3 无监督学习的VO
基于无监督学习的VO不需要对数据进行标注,具有更好的适应性和泛化能力,是一个重要的研究方向。
由于受到图像仿射变换技术(Spatial Transformer)的启发[38],与VO 相关的无监督深度学习方法主要集中在深度估计领域。Builtuponit 等人利用立体图像对的左右光度约束提出了一种无监督深度估计方法[39],之后R.Garg 等人采用左右目的光度误差作为损失函数,通过优化左右视图的仿射关系进一步对该算法进行优化[40]。在此基础上,Zhou等人利用单目图片对网络进行训练,可以得到含有绝对尺度的相机运动[41]。这些是早期的通过无监督方法估计相机运动的方法,展示出了无监督方法在相机位姿估计中的潜力。
Zhou等人提出了一种无监督深度学习的自我运动和深度估计系统[41],试验结果表明,系统性能与有监督的方法相当。但是,由于使用的是单目相机,系统无法恢复运动的绝对尺度。为了解决这个问题,Li等人受无监督深度估计方法的启发[40-41]提出了一种无监督学习的单目视觉测距系统UnDeepVO[42],使用双目图像对进行训练,如图4 所示。UnDeepVO 在位姿预测和深度估计中表现出良好的性能,此外,它还可以恢复6 自由度姿势和深度图的绝对比例。Nguyen 等[43]也将类似的无监督深度学习方法引入了单应性估计,并实现了不错的效果。H.Zhan 等利用双目图片恢复运动的真实尺度,在相机基线已知时,在左右图像对之间额外引入了光度误差。完成训练后,该网络可以用单张图像进行位姿估计,因此所用的测试集和训练集是不同的[44]。最近的研究结果表明,图像景深估计和相机位姿估计可以通过光度损失函数代替基于真值的损失函数,使用无监督的方法进行学习。SfM-Learner[41]是第一个同时学习摄像机运动和深度估计的自我监督方法,SCSfM-Learner[45]是在其结构基础上提出的一种方法,它通过加强深度一致性来解决SfM-Learner 中的尺度问题,该几何一致性损失会增强预测深度图和重构深度图之间的一致性。该框架将预测的深度图转换为3D 结构,并将其投影回深度图以生成重建的深度图,这样深度预测便能够在连续帧上保持尺度一致。

图4 UnDeepVO网络架构[42]
车辆运行过程中,VO采集到的场景往往是动态的,为VO的鲁棒性带来了挑战。针对这个问题,GeoNet建模了刚性结构重建器和非刚性运动定位器,分别估计静态场景结构和运动动态,将学习过程分为重建和定位2个子任务[46]。GANVO采用一种生成式对抗学习网络来估计景深,并引入时间递归模块进行位姿回归[47]。Li等利用生成对抗网络(Generative Adversarial Networks,GAN)生成更精确的深度图和位姿[48],并进一步优化目标框架中的合成图像,采用鉴别器评估合成图像生成的质量,有助于生成的深度图更加丰富和清晰。
对比分析以上研究可以看出,无监督学习不需要提前标记数据集,相较于有监督学习而言可以节省很多工作量。尽管无监督的VO 在位姿估计精度上仍然不及有监督的VO,但它在估计场景尺度和动态场景相机位姿估计问题上的表现优于其他方案,另外,无监督学习VO在网络设计的可操作性和无标签数据场景下的泛化能力方面也有一定的优势,而且无监督学习的VO通过位姿变换后的图像与实际图像的差异进行训练,比较符合人类的普遍认知习惯。随着无监督学习的网络的性能不断提高,无监督的VO有可能成为提供位姿信息的最理想解决方案。图5和图6分别展示了无监督学习的VO、有监督学习的VO和基于模型的VO在KIITI数据集上的平移误差和旋转误差。从图5和图6可以看出,有监督学习的VO 的定位精度略优于无监督学习的VO,而基于模型的VO 的定位精度一直高于基于学习的VO的定位精度。表2 分有监督学习和无监督学习展示了几种典型的基于深度学习的VO。

图5 3种VO在KITTI数据集上的平移误差

图6 3种VO在KITTI数据集上的旋转误差

表2 典型的基于学习的VO
为了比较3种VO的实时性,在KITTI数据集中选择试验平台为双核2.5 GHz 和单核2.5 GHz 的试验结果进行对比,如表3和表4所示。
从表3 和表4 可以看出,基于学习的VO 在实时性上明显优于基于模型的VO,主要原因是,虽然神经网络有大量参数需要计算,但其支持并行计算,可以用GPU实现运算加速,而基于模型的VO 有大量复杂的公式,计算速度很难提升。
3.4 模型法与深度学习相结合的VO
上述基于深度学习的方法的问题在于没有显式地考虑摄像机运动引入的多视图几何约束。针对这个问题,有学者提出了将基于学习的方法和基于模型的方法进行不同程度结合的技术,并取得了显著的效果。CNN-SLAM[51]在直接法VO 系统中融合单视图CNN 深度。CNN-SVO[49]在特征位置进行深度初始化,而CNN提供的深度可减少初始图像中的不确定性。Yang[52]等人将深度预测融入DSO[20]中作为虚拟的立体测量值。Li 等人通过位姿图对位姿估计进行优化[53]。Zhan 等人利用CNN 对景深和相机位姿进行预测,构建了一个有效的单目VO 系统,但该系统无法恢复真实尺度。Yin等人将通过学习得到的深度估计值直接应用到基于模型的视觉里程计中,以恢复运动的真实尺度[54]。

表3 双核2.5 GHz下3种VO的帧率 帧/s

表4 单核2.5 GHz下3种VO的帧率 帧/s
通过上述深度预测模型,将深度估计结果直接应用到基于模型的VO中能有效解决尺度问题。Barnes等人将深度学习得到的深度图和掩膜模型加入到基于模型的VO 中以提高模型的动态场景处理能力[55]。Zhang 等人将学习到的深度估计和光流预测集成到传统的视觉里程计模型中,达到了优于其他模型的性能[3]。几何算法往往在混合系统中为神经网络提供先验信息,例如D3VO将深度、位姿和深度预测合并到直接法VO中,取得了不错的效果[50]。
与仅依赖深度神经网络来估计位姿的端到端VO不同,混合VO将经典几何模型与深度学习框架结合在一起,基于成熟的几何理论,使用深层神经网络替换几何模型的各部分,以达到更好的效果。基于模型与深度学习相结合的VO 的性能往往优于端到端的VO,混合模型相较于一些基于模型的单目VO的性能更优越,例如,视觉惯性测距(Visual-Inertial Odometry,VIO)系统D3VO击败了几种常用的常规VO/VIO系统(DSO、ORBSLAM),因此混合VO也是一个重要的技术路线。
4 近年来研究热点和发展趋势
4.1 动态场景中的鲁棒性优化
在很多VO 算法中,场景被假设为静态的,只能容忍很小一部分动态场景,场景中出现动态物体时多数会被系统作为异常值处理。场景不变假设在多数情况下不能满足,如何使VO 系统可以准确、快速地处理动态场景是智能车辆VO技术发展中不可避免的问题。
目前,有很多提高VO在动态场景中性能的方案,主要面向2个问题:一是如何分辨场景中的动态物体和静态物体;二是如何处理被动态物体遮挡的静态场景。Leung和Medioni以地平面为基准进行车辆位姿估计[56],提出的方法在动态环境中具有不错的试验结果,但是,由于该系统假设1个场景中只有1个主平面,很难将其应用于多个平面的环境中。Tan等通过将地图特征投影到当前帧中检测物体的外观和结构,从而检测场景中发生的变化[57]。Wangsiripitak和Murray通过跟踪场景中已知的3D 对象来确定相邻帧间的场景变化[58]。类似地,Riazuelo 等通过检测和跟踪行人来检测行人的运动[59]。Li和Lee使用深度边缘点来检测运动物体,这些深度被赋予相关的权重,可以表明其属于动态对象的概率[60]。
深度学习在动态物体检测方面已经达到了很好的效果,但如何很好地恢复被遮挡的静态环境,为位姿估计提供更多的约束,仍需要不断探索。
4.2 多传感器融合
GPS和IMU是传统的车辆定位装置,在车辆上的应用已相对成熟,IMU与相机优势互补,GPS可以为VO提供绝对的位置信息,而且不同类型的传感器会带来不同的环境特征,因此,多传感器融合的定位往往是智能车辆最终的应用方案。但是,不同传感器体现环境信息的方式不同,如何在VO中充分利用每种传感器一直是一个开放的问题。除基于常规最优状态估计的多传感器融合外,在深度学习框架中进行传感器融合和管理的优势越发明显。很显然,基于深度学习的方法可能会催生新的自适应多传感器融合的VO。
Clark 等人结合DeepVO 得到的位姿估计结果和利用LSTM 得到的惯性传感器读数提出了基于深度学习的视觉与IMU 融合的VINet[61],该网络以端到端的方式训练,可以达到优于模型法的效果。Turan 等人利用同样的思路通过结合视觉和磁传感器预测相机6 自由度位姿[62]。Pillai 等人将GPS、IMU、相机和轮式里程计融合进行车辆位姿估计,利用神经网络处理不同相机产生的光流信息[63]。Li 等人提出的Recurrent-OctoMap 通过学习大量的3D 激光雷达数据能够细化语义建图,是一种融合语义特征的学习方法[64]。
4.3 场景语义理解
在智能车辆视觉里程计系统中,理解语义信息至关重要。利用深度学习得到的语义级对象在大规模复杂环境下的VO系统中发挥着重要作用,能够了解对象属性和对象间的相互关系将使机器人与人、机器人与环境之间取得更好的交互效果。此外,语义级对象可以提高位姿估计的准确性和鲁棒性,同时,良好的位姿估计有利于场景语义分割。借助对场景的理解以提高VO 的效率和泛化能力是一个很好的探索领域。
5 结束语
本文分析了有监督、无监督和模型法与深度学习相结合的智能车辆视觉里程计技术发展路线,结合近年来的主要研究成果发现,基于学习的智能车辆VO主要是将VO 变为端到端的系统,使其输入1 张或若干张图片后直接输出车辆的位姿。但是,通过深度学习的方法永远存在泛化的问题,VO在特定的环境中训练后,在其他环境的表现往往有所下降。另外,设计神经网络时将场景的语义信息考虑在内,加入多传感器作为视觉信息的补充来提高基于深度学习的VO 的鲁棒性和精度是一个可行的方案。基于深度学习的方法作为一个很好的补充,虽然在车辆的位姿估计方面得到了一些结果,但是目前还不能取代基于模型的方法。
